

Articles:
JavaScriptでループの練習をする
ループにまつわる高速化の話
プログラムを高速化したいときは、時間計測結果を元に戦略を立てるのが前提であるべきだと思うけど、傾向としてループ部分がクリティカルな状況はよくある。
1回だけ呼ばれる処理を100ms高速化するより、
100万回呼ばれる処理を0.01ms高速化する方が効果が大きくてハードルが低い(ことが多い)
平たく言えばこういうのをどう高速化するかの話。
for(auto &&obj: objects) {
obj.update();
}
実際にこう書くと速くなるというよりは高速化手法のバリエーションの話だと思って欲しい。
これ意味ないとか逆効果とかの指摘歓迎します。
ループ内を高速化するアプローチ
Object::update内を速くするのが大前提なんだけど、一般的な議論は難しいのでよくある状況を書いとく。
フラグチェックを外に出す
もしこんなコードがあったら
void Object::update() {
if(this->shouldUpdate()) {
// updateの内容
}
}
for(auto &&obj: objects) {
obj.update();
}
これの方が無駄な関数呼び出しがない分速い(ことが多い)
void Object::update() {
// updateの内容
}
for(auto &&obj: objects) {
if(obj.shouldUpdate()) {
obj.update();
}
}
加えてshouldUpdate関数をinline指定しておくと速い(ことがある)
inline bool Object::shouldUpdate() {
return is_awake;
}
実体を使う
下記は前者よりも後者の方が、ポインタのデリファレンス分有利。
実体で良いならそもそもポインタを使う設計にしてないと思うので、使う場面はほぼないとは思う。
std::vector<Object*> objects;
for(auto &&obj: objects) {
obj->update();
}
std::vector<Object> objects;
for(auto &&obj: objects) {
obj.update();
}
ループ対象を厳選するアプローチ
shouldUpdateみたいなフラグがあるとしたら、それがfalseのやつはループから除外すれば良い。
- フラグチェックのコストが高い
- sleep状態(updateを呼ぶ必要がない)にして良いオブジェクト数が多い
- awakeとsleepの切り替わりが頻繁でない
など、フラグチェックよりもコンテナへの出し入れの方がコストが安い場合は有効(なことが多い)
ObjectArray awakeObjects, sleepObjects;
void update() {
for(auto &&obj: awakeObjects) {
obj.update();
}
}
void sleep(Object &obj) {
awakeObjects.remove(obj);
sleepObjects.add(obj);
}
void awake(Object &obj) {
awakeObjects.add(obj);
sleepObjects.remove(obj);
}
ループ自体にかかるコストを減らすアプローチ
ループ内のコストが十分安いと、ループ自体にかかるコストが無視できなくなってくる。
例えばよくある
std::vector<Object> objects;
for(int i = 0; i < objects.size(); i++) {
objects[i].update();
}
みたいなコードだとObject::update()の他に
-
vec.size()の呼び出し -
iとvec.size()の戻り値との比較 -
iのインクリメント - vector要素へのランダムアクセス
がループ回数分呼ばれるので、このあたりに無駄がないか考えてみると良い。
コンテナを選ぶ
[C++] STLの型の使い分け
この記事でほぼ話は終わってるので読むと良いと思います。
イテレーションの速度に関してだけいうなら、vectorかdequeを使っとくと良いと思う。
一度だけで良い処理はループから出す
これより
for(std::size_t i = 0; i < objects.size(); ++i) {}
for(auto it = std::begin(objects); it != std::end(objects); ++it) {}
これの方が速い(ことが多い)
for(std::size_t i = 0, end = objects.size(); i < end ++i) {}
for(auto it = std::begin(objects), end = std::end(objects); it != end; ++it) {}
よくあるこれも
for(int y = 0; y < image.getHeight(); ++y) {
for(int x = 0; x < image.getWidth(); ++x) {
}
}
こうすると速くなる(ことが多い)
int w = image.getWidth();
int h = image.getHeight();
for(int y = 0; y < h; ++y) {
for(int x = 0; x < w; ++x) {
}
}
ループ回数を減らすアプローチ
これは半分冗談だけど、発想としてはあっても良いと思う。
ループ内をひらく
for(std::size_t i = 0, end = objects.size(); i < num; i += 4) {
objects[i].update();
objects[i+1].update();
objects[i+2].update();
objects[i+3].update();
}
ループ頻度を減らす
static std::size_t counter = 0;
const std::size_t skip_length = 4;
for(std::size_t i = counter%skip_length, end = objects.size(); i < end; i += skip_length) {
object[i].update();
}
++counter;
再掲
これ意味ないとか逆効果とかの指摘歓迎します。
[PHP]while文に対してdo while文を使うメリット
while文の例
<?php
$i = 0;
while($i < 10){
echo $i;
$i ++;
}
// => 0123456789
まず\$iに0を代入し、while内で、$iが10になるまで出力されている。
do while文の例
<?php
$i = 0;
do{
echo $i;
$i++;
}while($i < 10);
// => 0123456789
こちらはdo while文。whileよりも先に、$iが出力されている。
たとえば$i=100なら
<?php
$i = 0;
while($i < 10){
echo $i;
$i ++;
}
// => (表示されない)
while文の場合、\$iが100なので、while文の1週目から「 \$i < 10 」を満たしているので、while内が処理されず、$iの出力がされない。
<?php
$i = 100;
do{
echo $i;
$i++;
}while($i < 10);
// => 100
do while文の場合、whileが最後に来ているので、1週目の$iが出力される。
N重ループの書き方
はじめに
本記事はプログラミング初心者向けにfor文の入れ子構造を簡潔に書く方法を紹介するものです。競技プログラミングを念頭に置きながら書いていますが、競技プログラミングに限らず様々なコードを書く場面で役に立つテクニックだと思うので是非覚えておいてください。
初心者にありがちな良くない書き方として過度に深いネスト構造があります。具体例として、ABC080のC問題を解く際、for文の入れ子を10回書いても間違いではありませんがコードの書き方として望ましくないのは明らかでしょう。
ABC080C問題
この書き方の問題は主に二つで、一つ目はコードを書くにしても読むにしてもとても辛いという点、二つ目はN重ループのNの値がコンパイルの時点で確定していなければ困ってしまう点です。個人の感覚にもよるところですがfor文の入れ子は3重が限度だと思います。それ以上にfor文を繰り返したい場合、簡潔なコードを書くための工夫を考えるべきでしょう。
問題設定
今回は「5桁の4進数を00000から33333まで順に出力する」という問題を通して多重for文の書き方を二つ紹介します。
いけないやり方
for文の入れ子を5回繰り返します
ダメな例
include<iostream>
using namespace std;
typedef long long LL;
//ここからメイン
int main(void) {
LL i, j, k, n, m;
for (i = 0; i < 4; i++) {
for (j = 0; j < 4; j++) {
for (k = 0; k < 4; k++) {
for (n = 0; n < 4; n++) {
for (m = 0; m < 4; m++) {
cout << i << j << k << n << m << endl;
}
}
}
}
}
return 0;
}
正しい出力は得られますが桁数が増えると大変です。
やり方1
n進数を管理するクラスを使って繰り返しを行います
やり方1
#include<iostream>
#include<vector>
#include<string>
using namespace std;
typedef long long LL;
typedef vector<LL> VLL;
//n進数を管理するクラス
class N_Number {
public:
N_Number(LL n, LL keta) {
this->N_Shinsuu = n;
VLL temp(keta, 0);
this->numbers = temp;
}
//数を足す
void plus(LL a) {
this->numbers[0] += a;
LL size = this->numbers.size();
for (LL i = 0; i < size; i++) {
if (i + 1 < size) {
this->numbers[i + 1] += this->numbers[i] / this->N_Shinsuu;
}
this->numbers[i] %= this->N_Shinsuu;
}
}
//全ての桁が同じ数字になっていればその数字を返す。それ以外の場合は -1 を返す
LL check() {
LL a = this->numbers[0];
for (LL i = 0; i < this->numbers.size(); i++) {
if (this->numbers[i] != a)return -1;
}
return a;
}
LL getNumber(LL keta) {
return this->numbers[keta];
}
LL getKeta() {
return this->numbers.size();
}
LL getShinsuu() {
return this->N_Shinsuu;
}
void setNumber(LL keta, LL number) {
if (0 <= number && number < this->getShinsuu()) {
if (0 <= keta && keta < this->getKeta()) {
this->numbers[keta] = number;
return;
}
}
cout << "er" << endl;
}
void setAllNumbers(LL number) {
LL size = this->getKeta(), i;
for (i = 0; i < size; i++) {
this->setNumber(i, number);
}
}
private:
VLL numbers;
LL N_Shinsuu;
};
//ここからメイン
int main(void) {
N_Number i(4, 5);
while (true)
{
string s;
for (LL j = i.getKeta() - 1; j >= 0; j--) {
s += to_string(i.getNumber(j));
}
cout << s << endl;
if (i.check() == i.getShinsuu() - 1)break;
i.plus(1);
}
return 0;
}
ネストが深くなりませんし桁数が変わっても簡単に対応できます。
やり方2
再帰を使います。
やり方2
#include<iostream>
#include<vector>
#include<string>
using namespace std;
typedef long long LL;
typedef vector<LL> VLL;
//再帰で繰り返しを行う
void ForCout(LL n, LL keta, VLL numbers) {
if (numbers.size() == keta) {
string s;
for (LL i = 0; i < numbers.size(); i++) {
s += to_string(numbers[i]);
}
cout << s << endl;
return;
}
for (LL i = 0; i < n; i++) {
VLL temp = numbers;
temp.push_back(i);
ForCout(n, keta, temp);
}
}
//ここからメイン
int main(void) {
VLL numbers;
ForCout(4, 5, numbers);
return 0;
}
再帰は少し難しいかもしれませんが便利な概念なので練習しましょう。
さいごに
今回はネストが深くなりすぎない多重ループの書き方を紹介しました。最初に紹介した問題とは別に今回の内容を練習できる問題を一つ記事の最後に置いておきますので、一度自分で書いてみることをお勧めします。また、間違いや直した方がいい点がありましたら指摘して頂けると幸いです。
ABC119C問題
jQueryでeachを使う
jQueryオブジェクトを複数取得した後、ループ処理をしたいのにいつも忘れてしまうeach文の使い方をまとめました。
スキップはreturn true、ブレイクはreturn falseがポイントです。
each文で取得するHTMLはこちら
<ul class="array_test">
<li>item1</li>
<li>item2</li>
<li>item3</li>
<li>item4</li>
<li>item5</li>
</ul>
javascriptはこのように記述します。
$('ul.array_test li').each(function(index, element){
console.log(index + ':' + $(element).html());
});
実行結果
0:item1
1:item2
2:item3
3:item4
4:item5
スキップする(return true)
$('ul.array_test li').each(function(index, element){
if(index == 3){
return true;
}
console.log(index + ':' + $(element).html());
});
実行結果
0:item1
1:item2
2:item3
4:item5
途中でブレイク(return false)
$('ul.array_test li').each(function(index, element){
if(index == 3){
return false;
}
console.log(index + ':' + $(element).html());
});
実行結果
0:item1
1:item2
2:item3
C#におけるループ処理の速度 ~条件/演算子編~
この記事にはミスがあります。
自身への戒めとして残しているだけであり、参考になるものではありません。
↓ミスを踏まえてテストし直した改訂版を投稿しました!↓
【改訂版】C#におけるループ処理の速度 ~条件/演算子編~
(今度はミスがないといいなぁ)
概要
プログラミングにおいて最もボトルネックとなりやすいのが、ループ処理です。
なので、ループ処理の速度向上に役立つ知識を記述していきます。
環境やループ内の処理によっても違いが出るので、あくまでも参考程度に考えてください。
テスト環境
プロセッサ :Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz 3.41 GHz
実装メモリ(RAM):32.0GB
システム :64ビットオペレーティングシステム
言語 :C# 7.3 .NET Framework 3.5
ツール :Microsoft Visual Studio 2017
テスト内容
ループ内で System.Console.WriteLine() メソッドを用いて、連続した100万件の数字を出力します。
使用するテストデータは String[] testData; に格納されています。
時間の計測は System.Diagnostics.Stopwatch を使用し、10回分の平均値を結果として算出しています。
100万件のテストデータを作成するロジック
String testData = new String[1000000];
for(Int32 i = 0, len = testData.Length; i < len; i++ )
{
testData[i] = i.ToString();
}
時間を計測する方法
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
sw.Reset();
sw.Start();
/* ループ処理 */
sw.Stop();
/* ElapsedMilliseconds メンバから経過したミリ秒を取得 */
Int64 res = sw.ElapsedMilliseconds;
ループ条件による違い
まずはループの条件による速度の違いです。
一番修正しやすい部分ではないでしょうか。
testData.Lengthプロパティを直接条件に使用する方法と、testData.Lengthプロパティを変数にキャッシュして条件に使用する方法を検証しています。
結果
結果から記載します。
詳細は後述を参照してください。
| 条件 | 経過時間(ミリ秒) | 1ループあたり |
|---|---|---|
| プロパティを使用 | 18,070 | 0.0181 |
| キャッシュを使用 | 14,609 | 0.0146 |
キャッシュした方が 3,461ミリ秒(3.461秒) 早いことが分かりました。
1ループあたり 0.0035ミリ秒 の差ですので殆ど誤差ではありますが、数千万回や数億回という膨大なループの際は効果が実感できそうですね。
大きなデータを扱う際や、ミリ秒単位での高速な処理を要求されている場合はキャッシュしてからのループが良いでしょう。
プロパティを使用
配列の長さ(List や Collection の場合は Count)を示すプロパティを使用してループ条件にする場合です。
処理
/* i < testData.Length の部分に注目 */
for (Int32 i = 0; i < testData.Length; i++)
{
System.Console.WriteLine(testData[i]);
}
結果:18,070 ミリ秒(18.07 秒)
1ループあたり0.0181ミリ秒
キャッシュを使用
配列の長さ(List や Collection の場合は Count)を変数にキャッシュしてからループ条件にする場合です。
処理
/* len = testData.Length の部分に注目 */
for (Int32 i = 0, len = testData.Length; i < len; i++)
{
System.Console.WriteLine(testData[i]);
}
結果:14,609 ミリ秒(14.61 秒)
1ループあたり0.0146ミリ秒
インクリメント/デクリメントの違い
インクリメント(i++ など、1加算する演算子)、またはデクリメント演算子(i-- など、1減算する演算子)による違いを検証していきます。
結果
結果から記載します。
詳細は後述を参照してください。
| 演算子 | 経過時間(ミリ秒) | 1ループあたり |
|---|---|---|
| i++ | 16,463 | 0.0165 |
| ++i | 14,241 | 0.0142 |
| i-- | 14,338 | 0.0143 |
| --i | 14,721 | 0.0147 |
演算子を後方に置く場合、i++ よりも i-- の方が 2,125ミリ秒(2.125秒) 早いことが分かります。
また、演算子は前方に置いた場合、++i は i++ から 2,222ミリ秒(2.222秒) 早くなっていますが、--i は i-- から 383ミリ秒(0.383秒) 遅くなっています。
100万件による検証結果なので、383ミリ秒は完全に誤差と考えても良いでしょう。
++i と --i の差も 97ミリ秒(0.097秒) と誤差。
なので、基本的には インクリメントよりもデクリメントの方が早いものの、演算子を前方に置く場合はその差はなくなると考えるべきでしょう。
効果が大きいのは、インクリメント演算子を前方に置く ++i だと分かるので、ループ時はデクリメントを使うか、演算子を前方に置きましょう。
ただし、たまにバグの原因となるので、演算子を前方に置いた場合と後方に置いた場合の動きの違いについてはしっかり把握しておきましょう。
C#におけるインクリメント/デクリメント演算子の扱い
インクリメント
演算子が後方にある場合
インクリメントの演算子が後方にある場合(つまり i++)です。
何だかんだでこれを使っている人が多いのではないでしょうか。
処理
/* 後述するデクリメントとの差異を厳密にするため、キャッシュ方式を採用 */
for (Int32 i = 0, len = testData.Length; i < len; i++)
{
System.Console.WriteLine(testData[i]);
}
結果:16,463 ミリ秒(16.46 秒)
1ループあたり0.0165ミリ秒
演算子が前方にある場合
インクリメントの演算子が前方にある場合(つまり ++i)です。
慣れている人は結構使う場面があるかもしれませんね。
処理
/* 後述するデクリメントとの差異を厳密にするため、キャッシュ方式を採用 */
for (Int32 i = 0, len = testData.Length; i < len; --i)
{
System.Console.WriteLine(testData[i]);
}
結果:14,241 ミリ秒(14.24 秒)
1ループあたり0.0142ミリ秒
デクリメント
演算子が後方にある場合
デクリメントの演算子が後方にある場合(つまり i--)です。
処理
/* キャッシュしているようなものなので、
上記インクリメントもキャッシュ方式を採用しています */
for (Int32 i = testData.Length - 1; i >= 0; i--)
{
System.Console.WriteLine(testData[i]);
}
結果:14,338 ミリ秒(14.34 秒)
1ループあたり0.0143ミリ秒
演算子が前方にある場合
デクリメントの演算子が前方にある場合(つまり --i)です。
処理
/* キャッシュしているようなものなので、
上記インクリメントもキャッシュ方式を採用しています */
for (Int32 i = testData.Length - 1; i >= 0; --i)
{
System.Console.WriteLine(testData[i]);
}
結果:14,721 ミリ秒(14.72 秒)
1ループあたり0.0147ミリ秒
シリーズ
上から順に書いていく予定です
- ステートメント編
- 多重ループ編
- 小テクニック集
Kali-Linuxでログイン画面の無限ループから抜け出した方法
はじめに
Kali-Linuxの環境設定中に、ログイン画面でユーザーとパスワードを入れた後、黒い画面がしばらく表示されたのち、ログイン画面に戻るという無限ループが発生しました。根本的な原因はよくわかっていないのですが、以下の対処をしたところ抜け出すことができたので、記録しておきます。
環境
ホストOS:Windows10
ゲストOS:Kali-Linux2019.1
仮想化:VirtualBox6.0
発生した直前の状況
Kali-Linuxの環境設定で、パッケージの更新をするために以下を実行しました。
1. apt-get update
2. apt-get upgrade
1.はすぐに終了したのですが、2.は実行に時間がかかっていたのでしばらく放置していました。30分ほどたって画面を見ると、ログイン画面が表示されていました。その後、ユーザ・パスワードを入力するも無限ループしてしまいました。
本件、「ハッキング・ラボのつくりかた」(翔泳社/IPUSIRON著)の作業中に発生したもので、Twitterでつぶやいたところ、著者のIPUSIRON様ご本人からこのページをご紹介いただきました。また、他にも何名かの方からアドバイスのコメントをいただき感謝の限りです。
原因
根本的な原因はよくわかっていません。(私が勉強不足なこともあり、今後わかったら追記するかもしれません。)
対処方法
1.ログイン画面が表示されている状態で、[Ctl]+[Alt]+[F1~F6]を押して、仮想コンソールを表示する。今回は、F1は使えなかったので、F2を使いました。
2.仮想コンソールでログインユーザとパスワードの入力を促されるので、rootユーザーでログイン。
3.ご紹介いただいた記事に従って以下を実行。
#パッケージリストの更新
apt-get update
#パッケージの更新
apt-get upgrade
ここでエラーになって「dpkg was interrupted, you must run 'dpkg --configure -a ' to correct the problem.」と表示されたので、言われるがままに以下を実行。
#パッケージの再設定
dpkg --configure -a
#cinnamon-control-center-dataのインストール
apt-get install cinnamon-control-center-data
#gdm3のバージョン確認
gdm3 --version
#gdm3のインストール
apt-get --reinstall install gdm3
#gnomeのインストール
apt-get --reinstall install gnome
#gnome-shellのインストール
apt-get --reinstall install gnome-shell
#gdm3の再設定
dpkg-reconfigure gdm3
#再起動
reboot
ここまでやったところ、無事、ログインの無限ループから抜け出すことができました。Twitterでアドバイスをくださった皆様、ありがとうございました
参考にしたサイト
Kali Linux Login Loop
http://www.kalitut.com/2018/06/kali-linux-login-loop-solved.html
【改訂版】C#におけるループ処理の速度 ~条件/演算子編~
概要
プログラミングにおいて最もボトルネックとなりやすいのが、ループ処理です。
なので、ループ処理の速度に関する事を調べて記述していきます。
環境やループ内の処理によっても違いが出るので、あくまでも参考程度に考えてください。
この記事は C#におけるループ処理の速度 ~条件/演算子編~ の改訂版です。
上記記事にミスがあったため、調べ直した結果をこちらに書いていきます。
テスト環境
プロセッサ :Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz 3.41 GHz
実装メモリ(RAM):32.0GB
システム :64ビットオペレーティングシステム
言語 :C# 7.3 .NET Framework 3.5
ツール :Microsoft Visual Studio 2017
テスト内容
10億回または1億回のループを行い、ループ内で System.Int64 型の変数に添え字を加算しているだけの処理です。
System.Console.WriteLine() で出力しても良かったんですが、そもそも時間がかかって面倒なのと、コンソールのバッファが作られているか、そもそも文字列は参照を使っている等の理由でテストに向いていないと考えたため、なるべくプリミティブな型のみを使用するように心がけました。
時間の計測は System.Diagnostics.Stopwatch を使用し、10回分の平均値を結果として算出しています。
時間を計測する方法
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
sw.Reset();
sw.Start();
/* ループ処理 */
sw.Stop();
/* ElapsedMilliseconds メンバから経過したミリ秒を取得 */
long res = sw.ElapsedMilliseconds;
演算子による速度の違い
forループの再初期化式での演算子の使い方を6つのケースで見ていきます。
インクリメントとデクリメントの前置・後置、+=代入演算子と-=代入演算子です。
結果
結果から記載します。
テストコードや解説は後述を参照してください。
※2019/04/19
何故かテスト結果の1の位が抜けていたのを修正
| 演算子 | 経過時間(ミリ秒) |
|---|---|
| i++ | 1999 |
| ++i | 1999 |
| i+=1 | 1999 |
| i-- | 1999 |
| --i | 1999 |
| i-=1 | 2000 |
すべてのテストでほぼ同じ結果が出ました。
唯一のズレも1ミリ秒なので完全に誤差と考えて良いでしょう。
では、何故同じ結果となるのでしょうか?
同じ結果となる理由
コンパイル結果を見てみれば一目瞭然です。
コンパイル前後
/* C#コード */
using System;
public class C {
private static void PostInc()
{
for(int i = 0; i < 1000000000; i++)
{
}
}
private static void PreInc()
{
for(int i = 0; i < 1000000000; ++i)
{
}
}
private static void SubInc()
{
for(int i = 0; i < 1000000000; i+=1)
{
}
}
}
/* 中間言語(CIL) */
.class private auto ansi '<Module>'
{
} // end of class <Module>
.class public auto ansi beforefieldinit C
extends [mscorlib]System.Object
{
// Methods
.method private hidebysig static
void PostInc () cil managed
{
// Method begins at RVA 0x2050
// Code size 17 (0x11)
.maxstack 2
.locals init (
[0] int32
)
IL_0000: ldc.i4.0
IL_0001: stloc.0
// sequence point: hidden
IL_0002: br.s IL_0008
// loop start (head: IL_0008)
IL_0004: ldloc.0
IL_0005: ldc.i4.1
IL_0006: add
IL_0007: stloc.0
IL_0008: ldloc.0
IL_0009: ldc.i4 1000000000
IL_000e: blt.s IL_0004
// end loop
IL_0010: ret
} // end of method C::PostInc
.method private hidebysig static
void PreInc () cil managed
{
// Method begins at RVA 0x2070
// Code size 17 (0x11)
.maxstack 2
.locals init (
[0] int32
)
IL_0000: ldc.i4.0
IL_0001: stloc.0
// sequence point: hidden
IL_0002: br.s IL_0008
// loop start (head: IL_0008)
IL_0004: ldloc.0
IL_0005: ldc.i4.1
IL_0006: add
IL_0007: stloc.0
IL_0008: ldloc.0
IL_0009: ldc.i4 1000000000
IL_000e: blt.s IL_0004
// end loop
IL_0010: ret
} // end of method C::PreInc
.method private hidebysig static
void SubInc () cil managed
{
// Method begins at RVA 0x2090
// Code size 17 (0x11)
.maxstack 2
.locals init (
[0] int32
)
IL_0000: ldc.i4.0
IL_0001: stloc.0
// sequence point: hidden
IL_0002: br.s IL_0008
// loop start (head: IL_0008)
IL_0004: ldloc.0
IL_0005: ldc.i4.1
IL_0006: add
IL_0007: stloc.0
IL_0008: ldloc.0
IL_0009: ldc.i4 1000000000
IL_000e: blt.s IL_0004
// end loop
IL_0010: ret
} // end of method C::SubInc
.method public hidebysig specialname rtspecialname
instance void .ctor () cil managed
{
// Method begins at RVA 0x20ad
// Code size 7 (0x7)
.maxstack 8
IL_0000: ldarg.0
IL_0001: call instance void [mscorlib]System.Object::.ctor()
IL_0006: ret
} // end of method C::.ctor
} // end of class C
/* JITによるコンパイル後 */
C..ctor()
L0000: ret
C.PostInc()
L0000: push ebp
L0001: mov ebp, esp
L0003: xor eax, eax
L0005: inc eax
L0006: cmp eax, 0x3b9aca00
L000b: jl L0005
L000d: pop ebp
L000e: ret
C.PreInc()
L0000: push ebp
L0001: mov ebp, esp
L0003: xor eax, eax
L0005: inc eax
L0006: cmp eax, 0x3b9aca00
L000b: jl L0005
L000d: pop ebp
L000e: ret
C.SubInc()
L0000: push ebp
L0001: mov ebp, esp
L0003: xor eax, eax
L0005: inc eax
L0006: cmp eax, 0x3b9aca00
L000b: jl L0005
L000d: pop ebp
L000e: ret
中間言語やJITのコンパイル後の部分に注目して貰えれば、まったく同じコードが生成されている事が分かります。
最近のコンパイラは結構賢くて、多少ロスがあるコードを組んでも自動的に最適化してくれるんですね。
当然ですが最適化されていなければ(まずそんな環境に出くわす事はないとは思いますが)内部で行っている処理が違うので、速度にも差が出ることになります。
ですが、その辺りまで詳しくやると記事の情報がとっちらかってしまうので、気になった人は自分で調べてみてください。
テストコード
演算子の速度の違いを調べるテストコード
using System;
using System.Diagnostics;
namespace C
{
class Program
{
static void Main (string[] args)
{
long sum;
long[] result = new long[6];
Stopwatch sw = new Stopwatch();
/* 10回分の平均速度を求める */
for (int loop = 0 ; loop < 10 ; loop++)
{
/* i++ */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 0 ; i < 1000000000 ; i++)
{
sum += i;
}
sw.Stop();
result[0] += sw.ElapsedMilliseconds;
/* ++i */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 0 ; i < 1000000000 ; ++i)
{
sum += i;
}
sw.Stop();
result[1] += sw.ElapsedMilliseconds;
/* i += 1 */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 0 ; i < 1000000000 ; i += 1)
{
sum += i;
}
sw.Stop();
result[2] += sw.ElapsedMilliseconds;
/* i-- */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 999999999 ; i >= 0 ; i--)
{
sum += i;
}
sw.Stop();
result[3] += sw.ElapsedMilliseconds;
/* --i */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 999999999 ; i >= 0 ; --i)
{
sum += i;
}
sw.Stop();
result[4] += sw.ElapsedMilliseconds;
/* i -= 1 */
sum = 0;
sw.Reset();
sw.Start();
for (int i = 999999999 ; i >= 0 ; i -= 1)
{
sum += i;
}
sw.Stop();
result[5] += sw.ElapsedMilliseconds;
}
Console.WriteLine("i++:" + result[0] / 10);
Console.WriteLine("++i:" + result[1] / 10);
Console.WriteLine("i+=1:" + result[2] / 10);
Console.WriteLine("i--:" + result[3] / 10);
Console.WriteLine("--i:" + result[4] / 10);
Console.WriteLine("i-=1:" + result[5] / 10);
Console.ReadKey();
}
}
}
条件式の書き方による速度の違い
ループ処理は、ループ条件の書き方によって速度に差が出ることがあります。
例として配列を使用したループ処理でテストしてみました。
1つは配列のLengthプロパティを用いる方法、2つ目はそのLengthプロパティをローカル変数にキャッシュする方法、最後にループ回数をリテラルで指定する方法です。
配列の要素数の上限の問題で、このテストは1億回のループとなっています。
結果
結果から記載します。
テストコードや解説は後述を参照してください。
| 演算子 | 経過時間(ミリ秒) |
|---|---|
| プロパティ | 359 |
| キャッシュ | 319 |
| リテラル | 335 |
1億回のループで最大でも40ミリ秒の差ですから誤差のようなものですが、速度は違うようです。
プロパティを用いる方法が遅い理由は、単純に呼び出しに時間がかかるからですね。
1億回ループを行うという事は、条件式の部分は1億回実行されます。
なので、配列変数を呼び出す時間、そして配列のLengthプロパティを呼び出す時間だけ遅くなってしまいます。
逆にキャッシュが早い理由は、ローカル変数を1つ呼び出すだけで済むため、プロパティよりも早くなります。
リテラルがキャッシュよりも遅い理由ですが、それはコンパイルしたコードを見てみれば分かります。
リテラルがキャッシュよりも遅い理由
コンパイル結果を見てみれば遅くなる理由は分かります。
ですが、すみませんが何故そのようなコードを生成するのかは私が調べた限りでは分かりませんでした。
分かる方がいらっしゃればコメントお願いします。
コンパイル前後
/* C#コード */
using System;
class C
{
static void UseProperty (int[] dataArray)
{
long sum = 0;
for (int i = 0 ; i < dataArray.Length ; i++)
{
sum += dataArray[i];
}
}
static void UseCache (int[] dataArray)
{
long sum = 0;
for (int i = 0, len = dataArray.Length ; i < len ; i++)
{
sum += dataArray[i];
}
}
static void UseLiteral (int[] dataArray)
{
long sum = 0;
for (int i = 0 ; i < 100000000 ; i++)
{
sum += dataArray[i];
}
}
}
/* 中間言語(CIL) */
.class private auto ansi '<Module>'
{
} // end of class <Module>
.class private auto ansi beforefieldinit C
extends [mscorlib]System.Object
{
// Methods
.method private hidebysig static
void UseProperty (
int32[] dataArray
) cil managed
{
// Method begins at RVA 0x2050
// Code size 25 (0x19)
.maxstack 3
.locals init (
[0] int64,
[1] int32
)
IL_0000: ldc.i4.0
IL_0001: conv.i8
IL_0002: stloc.0
IL_0003: ldc.i4.0
IL_0004: stloc.1
// sequence point: hidden
IL_0005: br.s IL_0012
// loop start (head: IL_0012)
IL_0007: ldloc.0
IL_0008: ldarg.0
IL_0009: ldloc.1
IL_000a: ldelem.i4
IL_000b: conv.i8
IL_000c: add
IL_000d: stloc.0
IL_000e: ldloc.1
IL_000f: ldc.i4.1
IL_0010: add
IL_0011: stloc.1
IL_0012: ldloc.1
IL_0013: ldarg.0
IL_0014: ldlen
IL_0015: conv.i4
IL_0016: blt.s IL_0007
// end loop
IL_0018: ret
} // end of method C::UseProperty
.method private hidebysig static
void UseCache (
int32[] dataArray
) cil managed
{
// Method begins at RVA 0x2078
// Code size 27 (0x1b)
.maxstack 3
.locals init (
[0] int64,
[1] int32,
[2] int32
)
IL_0000: ldc.i4.0
IL_0001: conv.i8
IL_0002: stloc.0
IL_0003: ldc.i4.0
IL_0004: stloc.1
IL_0005: ldarg.0
IL_0006: ldlen
IL_0007: conv.i4
IL_0008: stloc.2
// sequence point: hidden
IL_0009: br.s IL_0016
// loop start (head: IL_0016)
IL_000b: ldloc.0
IL_000c: ldarg.0
IL_000d: ldloc.1
IL_000e: ldelem.i4
IL_000f: conv.i8
IL_0010: add
IL_0011: stloc.0
IL_0012: ldloc.1
IL_0013: ldc.i4.1
IL_0014: add
IL_0015: stloc.1
IL_0016: ldloc.1
IL_0017: ldloc.2
IL_0018: blt.s IL_000b
// end loop
IL_001a: ret
} // end of method C::UseCache
.method private hidebysig static
void UseLiteral (
int32[] dataArray
) cil managed
{
// Method begins at RVA 0x20a0
// Code size 27 (0x1b)
.maxstack 3
.locals init (
[0] int64,
[1] int32
)
IL_0000: ldc.i4.0
IL_0001: conv.i8
IL_0002: stloc.0
IL_0003: ldc.i4.0
IL_0004: stloc.1
// sequence point: hidden
IL_0005: br.s IL_0012
// loop start (head: IL_0012)
IL_0007: ldloc.0
IL_0008: ldarg.0
IL_0009: ldloc.1
IL_000a: ldelem.i4
IL_000b: conv.i8
IL_000c: add
IL_000d: stloc.0
IL_000e: ldloc.1
IL_000f: ldc.i4.1
IL_0010: add
IL_0011: stloc.1
IL_0012: ldloc.1
IL_0013: ldc.i4 100000000
IL_0018: blt.s IL_0007
// end loop
IL_001a: ret
} // end of method C::UseLiteral
.method public hidebysig specialname rtspecialname
instance void .ctor () cil managed
{
// Method begins at RVA 0x20c7
// Code size 7 (0x7)
.maxstack 8
IL_0000: ldarg.0
IL_0001: call instance void [mscorlib]System.Object::.ctor()
IL_0006: ret
} // end of method C::.ctor
} // end of class C
/* JITによるコンパイル後 */
; Desktop CLR v4.7.3324.00 (clr.dll) on amd64.
C..ctor()
L0000: ret
C.UseProperty(Int32[])
L0000: xor eax, eax
L0002: xor edx, edx
L0004: mov r8d, [rcx+0x8]
L0008: test r8d, r8d
L000b: jle L0022
L000d: movsxd r9, edx
L0010: mov r9d, [rcx+r9*4+0x10]
L0015: movsxd r9, r9d
L0018: add rax, r9
L001b: inc edx
L001d: cmp r8d, edx
L0020: jg L000d
L0022: ret
C.UseCache(Int32[])
L0000: xor eax, eax
L0002: xor edx, edx
L0004: mov r8d, [rcx+0x8]
L0008: test r8d, r8d
L000b: jle L0022
L000d: movsxd r9, edx
L0010: mov r9d, [rcx+r9*4+0x10]
L0015: movsxd r9, r9d
L0018: add rax, r9
L001b: inc edx
L001d: cmp edx, r8d
L0020: jl L000d
L0022: ret
C.UseLiteral(Int32[])
L0000: sub rsp, 0x28
L0004: xor eax, eax
L0006: xor edx, edx
L0008: test rcx, rcx
L000b: jz L0030
L000d: cmp dword [rcx+0x8], 0x5f5e100
L0014: jl L0030
L0016: movsxd r8, edx
L0019: mov r8d, [rcx+r8*4+0x10]
L001e: movsxd r8, r8d
L0021: add rax, r8
L0024: inc edx
L0026: cmp edx, 0x5f5e100
L002c: jl L0016
L002e: jmp L004d
L0030: cmp edx, [rcx+0x8]
L0033: jae L0052
L0035: movsxd r8, edx
L0038: mov r8d, [rcx+r8*4+0x10]
L003d: movsxd r8, r8d
L0040: add rax, r8
L0043: inc edx
L0045: cmp edx, 0x5f5e100
L004b: jl L0030
L004d: add rsp, 0x28
L0051: ret
L0052: call 0x7ffdb9ec2660
L0057: int3
このように、リテラルを用いたループ処理では比較や代入などが何度も行われています。
単純に処理のステップが多いため、リテラルを用いたループ処理はキャッシュを用いたループ処理よりも遅くなっているようです。
基本的にはリテラルの方が早いはずなのですが……分かる方のコメントをお待ちしています。
albireo様のコメントより ※ 2019/04/22 追記
どうやらリテラルの場合は、それが配列の要素数の範囲に収まるかがコンパイル時点では判断出来ないため、
それをループ時にインデックスが配列の範囲外ではないかのチェックを行っている事で速度に差が出てしまっているようです。
これはループに用いる配列を、ループと同じメソッド内で作成しても変わらず、コンパイラはインデックスの範囲外チェックが必要だと判断してしまいました。
上手く回避する方法が見つかれば追記しますが、現状はキャッシュを使用する方法が一番早そうです。
テストコード
条件式の速度の違いを調べるテストコード
using System;
using System.Diagnostics;
namespace C
{
class Program
{
static void Main (string[] args)
{
/* ループ処理に使用する配列を作成する */
int[] dataArray = new int[100000000];
for (int i = 0 ; i < 100000000 ; i++)
{
dataArray[i] = i;
}
/* 10回分の平均速度を求める */
long sum;
long[] result = new long[3];
Stopwatch sw = new Stopwatch();
for (int loop = 0 ; loop < 10 ; loop++)
{
/* 配列のプロパティをそのまま使う */
sw.Reset();
sw.Start();
UseProperty(dataArray);
sw.Stop();
result[0] += sw.ElapsedMilliseconds;
/* 配列のプロパティを変数にキャッシュして使う */
sw.Reset();
sw.Start();
UseCache(dataArray);
sw.Stop();
result[1] += sw.ElapsedMilliseconds;
/* リテラルを使用する */
sw.Reset();
sw.Start();
UseLiteral(dataArray);
sw.Stop();
result[2] += sw.ElapsedMilliseconds;
}
Console.WriteLine("プロパティ:" + result[0] / 10);
Console.WriteLine("キャッシュ:" + result[1] / 10);
Console.WriteLine(" リテラル:" + result[2] / 10);
Console.ReadKey();
}
/* Lengthプロパティを用いたループ処理 */
static void UseProperty (int[] dataArray)
{
long sum = 0;
for (int i = 0 ; i < dataArray.Length ; i++)
{
sum += dataArray[i];
}
}
/* Lengthプロパティをローカル変数にキャッシュしたループ処理 */
static void UseCache (int[] dataArray)
{
long sum = 0;
for (int i = 0, len = dataArray.Length ; i < len ; i++)
{
sum += dataArray[i];
}
}
/* リテラルを用いたループ処理 */
static void UseLiteral (int[] dataArray)
{
long sum = 0;
for (int i = 0 ; i < 100000000 ; i++)
{
sum += dataArray[i];
}
}
}
}
あとがき
今回は速度の違いについて書きましたが、個人的には「とにかく早ければ良い」という考えは危険だと思っています。
大抵の場合、速いコードほど読みにくいからです(程度の問題ではありますが)。
そして、読みにくいコードというのは得てしてバグの温床になりやすい。
なので、本当に必要な時以外は読みやすいコードを優先した方が良いと思います(これが一番難しい……)。
この記事でも、そこまで読みにくくはならないだろうという程度の小手先しか紹介していません。
本当に速くしたいのならメモリについての知識が必須なので、興味があれば調べてみてください。
あくまでもこの記事はちょっとしたお役立ち知識として参考にしていただけると幸いです。
また、私自身も勉強中の身のため、間違いを見つけたらコメントで指摘していただけるとありがたいです。
request をループ処理する
http request をすると response があるまで少々の時間がかかります。
しかし、node.js では response を待たずに次の処理に進んでしまいます。
そのため、response を待って処理するためには、promise または callback を利用して非同期処理を行う必要があります。
node.js には request-promise モジュールがあり、こちらを使用することにより簡単に非同期処理を行うことができます。
※request-promise については過去に記事を書きましたのでこちらをご参照ください。
Callback 使いから Promise マスターにクラスチェンジするぞ!
と、諸先輩方には釈迦に説法なお話なのですが、自分の理解の定着のために書かせていただきました。
オレ、しっかり反復する。大事('ω')
さて、前置きはこのくらいにして、本題に入りましょう。
ID から名前を取得して表示するプログラム
- 『
IDからnameを検索するAPI』をrequestする -
responseを取得したらIDとnameを表示する - 1~2 を ID リストの分だけ繰り返す
こんなループをするプログラムにしたいと思います。
for や while を使ったループで request すると…?
単純にループさせるだけなら for や while を使えば実現します。
request-loop.js
const idList = ["sample001@shop","sample002@shop","sample003@shop"];
class setOptions {
constructor(id) {
// API を request するためのオプションをセット(内容は割愛)
}
}
for(let i = 0; i < idList.length; i++){ // 3 の処理
request(new setOptions(idList[i])).then((response) => { // 1 の処理
console.log(idList[i] + " : " + response); // 2 の処理
}).catch((error) => { console.log(error) });
}
しかし、実行結果がこうなります。
sample002@shop : サンプル次郎
sample001@shop : サンプル太郎
sample003@shop : サンプル四郎
順番がバラバラですね。
結局、for や while を使う場合には非同期処理になるため、response を待たずに次の request を行ってしまうためです。
for がやっている実際の処理は、こんな感じなのでしょう。
for部分の実際の処理
request(new setOptions(idList[0])).then((response) => {
console.log(idList[0] + " : " + response);
}).catch((error) => { console.log(error) });
request(new setOptions(idList[1])).then((response) => {
console.log(idList[1] + " : " + response);
}).catch((error) => { console.log(error) });
request(new setOptions(idList[2])).then((response) => {
console.log(idList[2] + " : " + response);
}).catch((error) => { console.log(error) });
}
せっかくの request-promise でも、別々に呼び出してたら意味ありませんよね。
結局、非同期処理されて、順番は守られません。
本当は、こうしたいのです。
こんな処理がしたい!
request(new setOptions(idList[0]))
.then((response) => {
console.log(idList[0] + " : " + response);
return request(new setOptions(idList[1]));
.then((response) => {
console.log(idList[1] + " : " + response);
return request(new setOptions(idList[2]));
.then((response) => {
console.log(idList[2] + " : " + response);
}).catch((error) => { console.log(error) });
さて、これをループ処理にするには、どうしたら良いのでしょうか?
再起処理でループさせる
再起処理とは「自分自身を呼び出す処理が書かれている関数を呼び出すこと」です。
この方法であれば、response を待って処理することができます。
request-loop.js
const idList = ["sample001@shop","sample002@shop","sample003@shop"];
class setOptions {
constructor(id) {
// API を request するためのオプションをセット(内容は割愛)
}
}
function loop(i){
request(new setOptions(idList[i]))
.then((response) => {
console.log(idList[i] + " : " + response);
i++;
if(i < idList.length) loop(i); // ここでループする
}).catch((error) => { errorArart(error) });
}
loop(0);
sample001@shop : サンプル太郎
sample002@shop : サンプル次郎
sample003@shop : サンプル四郎
API で取得した値を利用して、順番通り表示することができました!(*‘∀‘)やったね!
おわりに
ここまでお付き合いいただきありがとうございました。
肝心の再起処理の部分がさらっと終わってしまったのですが、できたときは凄く嬉しかったです YO!('Д')
いや、ほんと。for 文でなんとかできないか四苦八苦していました。
まだまだ勉強が足りません。精進せな。
今回、メインではなかったので API 部分は割愛したのですが、今回の話を踏まえた上で、次回は LINEWORKS の API でやる方法を解説してみたいと思います。
ではまた!(^^)/
参考にさせていただきましたm(_ _)m
Microsoft Flow:文字列を区切ってループ処理
仕様
- 1. カンマ区切りの文字列を変数に格納。(変数の初期化により、変数宣言)
- 2. 「split」関数で、カンマ区切り。(戻り値は、配列)
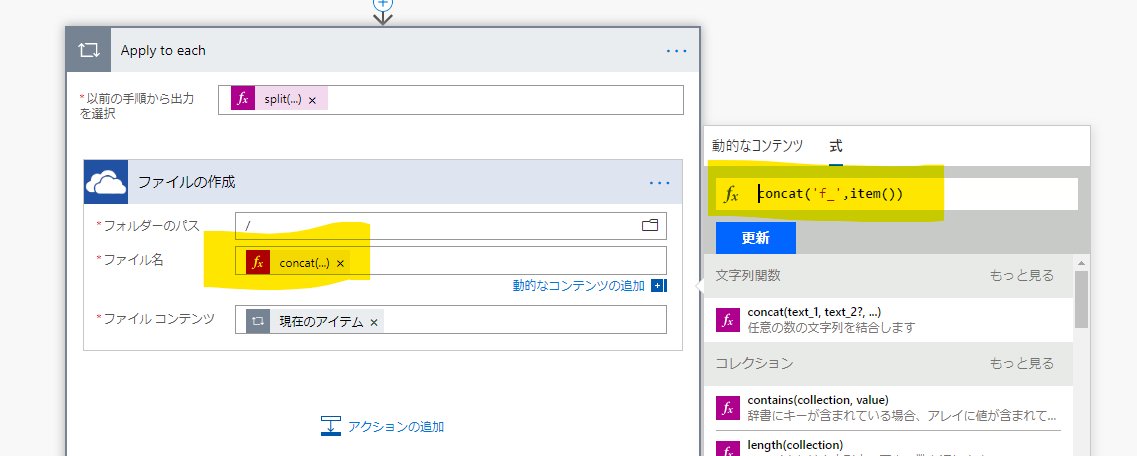
- 3. 「Apply to each」で、上記のカンマ区切りした各値をOneDriveのファイルに書き出す。
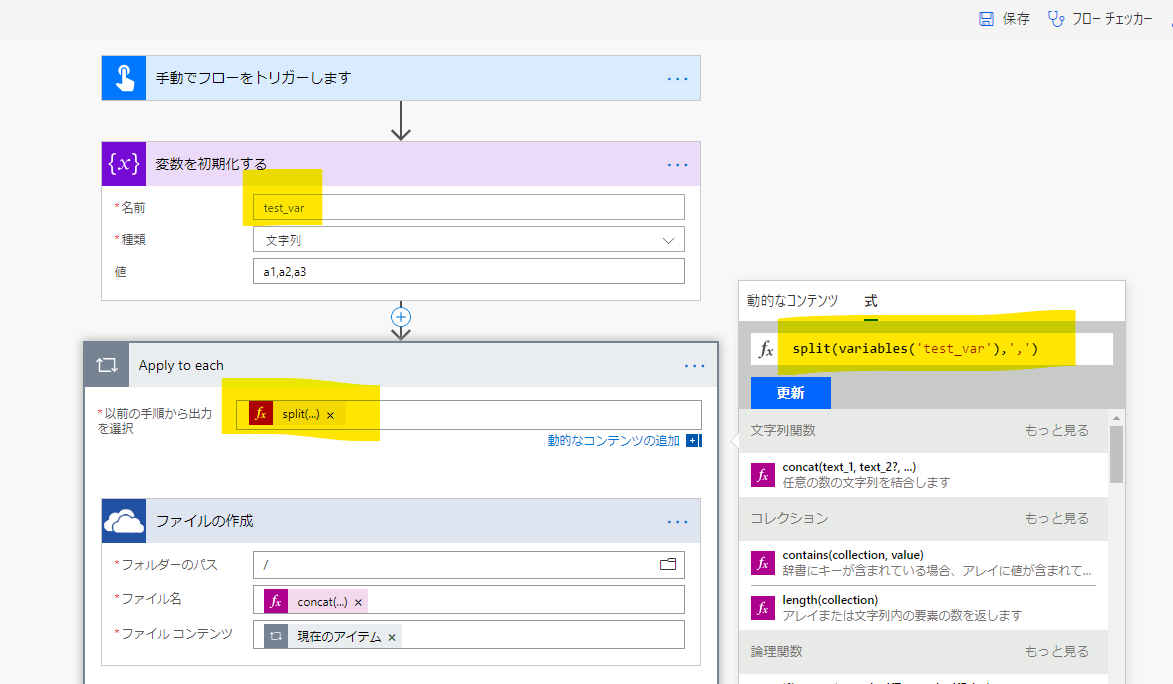
- 4.書き出すファイル名は、文字列結合の関数「concat」を使用し、以下の形式とする。「f_」は接頭辞。 - 形式:f_[区切り値]
コードの補足
変数の参照
変数の参照は、「variables('変数名')」。
split
split(variables('test_var'), ',')
「Apply to each 」の各値の参照
「item()」関数で、ループの各値を参照。
concat
concat('f_', item())
rubyのブロック処理における配列関連のメソッドメモ
チェリー本を参考にした。このあたりよく忘れるのでメモっておく
each
普通のfor文と同じ役割
num = [1,2,3,4]
sum = 0
num.each do |n|
sum += n
end
print sum #=> 10
each_with_index
eachについて配列のインデックスも扱うことができる
num = [1,2,3,4]
num.each_with_index do |i,n|
p "#{i}:#{n}"
end
#出力は以下の通り
#0:1
#1:2
#2:3
#3:4
map
ある配列の要素に対する処理結果を別配列に返す
num = [1,2,3,4]
new_num = []
new_num = num.map do |n|
n * 10
end
print new_num #=> [10,20,30,40]
エイリアスメソッドであるcollectも同様の使い方が可能
select/find_all
ある配列の要素について、条件に一致しているものを返す
num = [1,2,3,4]
new_num = num.select do |n|
n.odd? #nが奇数のものをnew_numへ格納
end
print new_num #=> [1,3]
エイリアスメソッドであるfind_allも同様の使い方が可能
reject
ある配列の要素について、条件に一致していないものを返す
要するにselect/find_allの反対
num = [1,2,3,4]
new_num = num.select do |n|
n.odd? #nが奇数でないものをnew_numへ格納
end
print new_num #=> [2,4]
find/detect
ある配列について、戻り値が真かつ最初の要素を返す
num = [1,2,3,4]
new_num = num.find do |n|
n.odd?
end
print new_num #=> 3
エイリアスメソッドであるdetectも同様の使い方が可能
inject/reduce
ある値を初期値として配列各要素を足しこむ。eachの拡張か。
num = [1,2,3,4]
sum = num.inject(0) do |result,n|
result += n #初期値0に各要素をすべて足しこむ。初期値が異なれば結果も異なる。
end
print sum #=> 10
当然ながら文字列の結合処理にも利用可能
エイリアスメソッドであるreduceも同様の使い方が可能
その他
map/collectとinject/reduceの思想の違いらしい。エイリアスというくらいなので多分map処理を名前変えてcollectとかしてんだろうな。要するに実装上の違いはないと思うがどうなのか。。。
https://magazine.rubyist.net/articles/0038/0038-MapAndCollect.html#map-%E3%81%A8-collect-%E3%81%AE%E7%99%BA%E6%83%B3%E3%81%AE%E9%81%95%E3%81%84
java Scannerループ入力
pythonの少し複雑なループ
初心者です。どのようにループを掛ければいいかわかりません。
アドバイスをいただければ幸いです。
データ a = [250, 300 , 500]
データ b = [[100,150,300],[50,60,80],[400,500,300]]
やりたいこと
250*100 + 300*50 + 500*400 合計24000
250*50 + 300*60 + 500*80 合計70500
250*400 + 300*500 + 500*300 合計400000
以上の計算式をループ等を使ってやりたいのですが
いろいろ試したのですが、どうまわしていいか
わかりません。
分かる方よろしくお願いいたします。
PHPの繰り返し処理大全
PHP7.3時代の話です。
PHP8や9のころには、また別の結論になっているかもしれません。
最初に結論
・全要素繰り返しはforeach
・途中で打ち切るのはwhile/for
・それ以外はいらん
繰り返し処理一覧
foreach
PHPのforeachは非常に優秀です。
あらゆる反復可能な値を繰り返し処理することができます。
$arr = [1, 2, 3];
foreach($arr as $val){
echo $val; // 順に1, 2, 3
}
PHPの配列は順序付きリストなので、順番も保証されます。
また、キーと値を両方とも取れるので、inとofどっちだったっけとか悩む必要もありません。
$arr = [3 => 1, 2 => 2, 1 => 3];
foreach ($arr as $key => $val) {
echo $key, $val; // 31, 22, 13 順番が変わったりはしない
}
オブジェクトにも使えます。
class Test{
public $a = 1;
protected $b = 2;
private $c = 3;
public function loop(){
foreach($this as $val){
echo $val;
}
}
}
$test = new Test();
foreach($test as $val){
echo $val; // 1
}
$test->loop(); // 1,2,3
オブジェクトに使った場合、可視なプロパティが順にアクセスされます。
すなわち外部からはpublicプロパティしか見えず、内部からならprotectedやprivateも見えるということです。
さらに他言語では御法度の、ループ中で自身や別要素を削除するという芸当がPHPでは可能です。
$array = range(0, 10);
foreach ($array as $k => $v) {
unset($array[$k - 1]);
}
var_dump($array); // [10=>10]
ループ中で、前回ループの値を削除しています。
他言語でこんなことをやるとどんな動作になるかわかったものではありませんが、PHPでは全要素をきちんとループした上で、最終的に$arrayの値は想定通りになります。
配列をforeachした時点で配列のコピーが作成されるので、ループ内で変なことをしでかしてもループ自体には影響が及ばないように対策されているのです。
おかげで何も考えずにfilterが実装できます。
$array = [1, 2, 3, 4, 5, 6];
// 偶数以外削除
foreach ($array as $k => $v) {
if ($v % 2) {
unset($array[$k]);
}
}
var_dump($array); // [2, 4, 6]
while
条件がtrueっぽい値であるかぎり、ループを繰り返します。
$i = 1;
while ($i <= 10) {
echo $i;
$i++;
}
foreachとの使い分けですが、foreachは配列などの全要素にアクセスする用途に使います。
whileは何らかの条件でループを脱出する用途に使います。
// 30回ループしたら脱出
$i = 0;
while ($i < 30) {
echo $i;
$i++;
}
// 30秒経ったら中断
while(true){
sleep(1);
if(time() - $_SERVER['REQUEST_TIME'] > 30){
break;
}
}
// 標準入力を出力
while( ($line = fgets(STDIN)) !== false){
echo $line;
}
うっかり使うと無限ループになるので使用は避けましょう。
いや嘘。
whileを使うべきところにforやforeachを使ったりはせず、適切に使い分けましょう。
for
whileで多くの場合必要となる『初期値設定』『カウント処理』を最初から文法に組み込んだものです。
// 30回ループしたら脱出
for ($i = 0; $i < 30; $i++) {
echo $i;
}
whileではループ前後に書かざるをえなかった定型処理がひとつの文にまとまったことで、わかりやすくなって見た目もすっきりしました。
whileは常にforで書き換え可能なので、実はwhileは必ずしも存在する必要はありません。
しかし初期値設定などが必要ない簡易的なループはwhileで書いた方がわかりやすいので、forとwhileは処理内容によって使い分けるとよいでしょう。
// forを使うほどではない
for(; true; ){
sleep(1);
if(time() - $_SERVER['REQUEST_TIME'] > 30){
break;
}
}
PHPでは、配列要素などにアクセスする用途でforを使用する理由はありません。
$array = [1, 2, 3];
for ($key = 0; $key < count($array); $key++) {
echo $key, $array[$key]; // 01, 12, 23
}
$array = [0 => 1, 2 => 3]; // 死
$array = ['answer' => 42]; // 死
歯抜けのない純粋配列にしか使用できず、うっかり連想配列や歯抜けのある配列にforでアクセスすると死にます。
要素に対するアクセスには必ずforeachを使いましょう。
forの存在価値はループのためではなく、条件分岐のためにあります。
for(; time() - $_SERVER['REQUEST_TIME'] <= 30; sleep(1));
条件部分やループカウント部分にあらゆる処理を詰め込むことでforの本文を空にすることもできますが、見づらくなるだけなので止めましょう。
do - while
条件のチェックが最後に行われるということ以外はwhileと同じです。
つまり、たとえ条件が偽でも必ず一回だけは実行されるwhileということです。
$i = 100;
do {
echo $i++;
} while ($i < 30);
正直、whileではなくこちらを使わなければならないシーンを思いつきません。
関数型関数
PHPには組み込みでarray_walk、array_reduce、array_productといった、関数型のように書ける関数が多数用意されています。
これらを使うことで反復処理をやめ、関数型プログラミングっぽい記述にすることが可能になります。
$sum = 0;
foreach($array as $val){
$sum += $val;
}
echo $sum;
echo array_sum($array); // ↑と同じ
が、基本的にこれらを使う必要はないです。
上記のようなわかりやすい例はむしろ例外で、PHPでは文法の都合上、大抵の処理は関数型で書くと却ってわかりづらくなります。
以下はPHPで高速オシャレな配列操作を求めてより借用した例です。
// 0~10000のうち、偶数だけを抽出して自乗し、結果が20を超えるものを足しあわせよ
// 関数型
echo array_sum(
array_filter(
array_map(
function ($v) {
return $v ** 2;
},
array_filter(range(0, 10000), function ($v) {
return $v % 2 === 0;
})
),
function ($v) {
return $v > 20;
}
)
);
// 普通に書く
for ($sum = $v = 0; $v <= 10000; ++$v) {
if ($v % 2){ continue; }
$v **= 2;
if ($v <= 20){ continue; }
$sum += $v;
}
echo $sum;
明らかに普通に書いた方がわかりやすいですね。
そもそも関数型の例でよく出てくる『○○を抽出する』みたいな処理は、PHPであればSQL発行する時点で絞っておけって話ですし。
filter_varなど使いこなすと色々楽しいこともできるのですが、実用的かと言われると首が傾いてしまいますね。
もちろん関数型で書いてもわかりやすい場合もありますが、別にforeachで書いたところで可読性も大してかわらないので、なら最初から全部foreachで書いた方が手っ取り早いです。
反復処理の定義
オブジェクトに対するループ処理の挙動を、PHPでは任意に定義可能です。
上のほうでオブジェクトをforeachするとpublicプロパティが順番に出てくると言いましたが、それはデフォルトの動作であって、やろうと思えば変更できるということです。
Iteratorインターフェイス
反復処理実装の基本です。
Iteratorインターフェイスをimplementsして各メソッドを実装します。
class Test implements Iterator
{
public $dummy = '出てこない';
private $data1 = [1, 2, 3];
private $data2 = [4, 5, 6];
private $current = 0;
/**
* @Override
* 現在の値を返す
* @return mixed 現在の値
*/
public function current(){
return $this->data1[$this->current] ?? $this->data2[$this->current - 3] ?? null;
}
/**
* @Override
* 現在のキーを返す
* @return string|int 現在のキー
*/
public function key(){
return $this->current;
}
/**
* @Override
* ポインタを次に移動する
*/
public function next(){
$this->current++;
}
/**
* @Override
* ポインタを初期化する
*/
public function rewind(){
$this->current = 0;
}
/**
* @Override
* 現在のポインタが有効か
* @return boolean 有効ならtrue
*/
public function valid(){
return isset($this->data1[$this->current]) ?: isset($this->data2[$this->current - 3]);
}
}
$test = new Test();
foreach ($test as $key => $val) {
echo $key, '=>', $val; // [0=>1, 1=>2, 2=>3, 3=>4, 4=>5, 5=>6]
}
publicであるはずの$dummyは出てこなくなり、currentで返した結果が表示されるようになります。
このように、Iteratorインターフェイスを使うことでループで返す値を好き勝手に変更することができるようになります。
ただ、変なことをやってもわかりにくくなるだけなので、基本的にあまり使わないほうがいいと思います。
IteratorAggregateインターフェイス
Iteratorインターフェイスは必ず5個のメソッドを実装する必要があって面倒です。
PHPには最初からイテレータが幾つも用意されており、それらで賄える範囲であれば簡単に実装できるIteratorAggregateがあります。
class Test implements IteratorAggregate
{
public $dummy = '出てこない';
private $data1 = [1, 2, 3];
private $data2 = [4, 5, 6];
/**
* @Override
* イテレータを返す
* @return Iterator
*/
public function getIterator(){
$iter = new AppendIterator();
$iter->append(new ArrayIterator($this->data1));
$iter->append(new ArrayIterator($this->data2));
return $iter;
}
}
$test = new Test();
foreach ($test as $key => $val) {
echo $key, '=>', $val; // [0=>1, 1=>2, 2=>3, 0=>4, 1=>5, 2=>6]
}
IteratorAggregate::getIteratorに適当なイテレータを投げれば、foreachループでそれが出てくるようになります。
今回は配列をイテレータにするArrayIterator、複数のイテレータを順にまとめるAppendIteratorを使って、$data1と$data2が順に出てくるようにしました。
もちろん、書くのが楽になったからといって使いまくると何が出てくるかわからないブラックボックスになってしまいます。
RecursiveRegexIteratorあたりまで来ると正直何言ってるかわからないので、変なイテレータには手を出さない方がいいと思います。
ジェネレータ
ジェネレータはクロージャとセットにされがちですが、単に何度もreturn(yield)できる関数という認識でいいと思います。
function getPrimeNumber(){
yield 2;
yield 3;
yield 5;
yield 7;
yield 11;
yield 13;
yield 17;
return 19; // returnは出ない
}
$primes = getPrimeNumber();
foreach($primes as $prime){
echo $prime; // 2, 3, 5, 7, 11, 13, 17
}
returnのかわりにyieldというキーワードを使います。
yieldキーワードが入った関数は、関数呼び出しの返り値が自動的にGeneratorインスタンスになります。
たとえ絶対にyieldを通らない実装だったとしてもそうなるので、少し注意が必要です。
返ってくるのはオブジェクトなので、その返り値をforeachでループすることができるわけですが、その際は関数の最初からではなくyieldで止まったところの次の文から処理が再開されます。
関数内の変数値などは維持されるので、何も考えずにメモ化ができたりします。
上で出した例では全く意味がありませんが、無限数列などを作ったりする際にはジェネレータがとても役立ちます。
// フィボナッチ数を求めるジェネレータ
function getFibonacci(){
$fa = 0;
yield $fa;
$fb = 1;
yield $fb;
while (true) {
$fib = $fa + $fb;
$fa = $fb;
$fb = $fib;
yield $fib;
}
}
$count = 0;
foreach (getFibonacci() as $fibonacci) {
echo $fibonacci . "\n";
// 適当に切らないと無限ループする
if ($count++ > 30) {
break;
}
}
再帰もメモ化もgotoもなんもなしに、普通に定義通りのフィボナッチ数を求める関数が書けてしまいました。
ジェネレータは頻繁に出番があるかというと無いですが、覚えておくといざというとき便利な機能です。
まとめ
自発的に使うのはforeachとwhile/forだけでいいよ。
それ以外はあまり出てくるものでもないので、出てきたときに調べるくらいで大丈夫でしょう。
使う必要のないもの
foreachのリファレンス
foreachでリファレンスが取れますが、使用してはいけません。
$array = range(0, 5);
foreach ($array as &$val) {
$val *= 2;
}
var_dump($array); // [2, 4, 6, 8, 10]
$val = 42;
var_dump($array); // [2, 4, 6, 8, 42] ←
そもそもリファレンスはあらゆる場面で一切使用禁止です。
リファレンスで高速化が云々とか言ってる人は全員間違い1なので、生暖かい目でスルーしましょう。
do - whileの早期return
do-while記法は、簡易的な早期returnに使用できます。
以下はマニュアルに載っている例です。
do {
if ($i < 5) {
echo "i は十分大きくはありません。";
break;
}
$i *= $factor;
if ($i < $minimum_limit) {
break;
}
echo "iはOKです。";
/* 実際の処理 */
} while (0);
breakはループを抜ける文なので、$i<5だったり$i < $minimum_limitの場合は、このwhileループを抜けます。
条件に当てはまらずループの最後まで来た場合、条件が常に偽であるため、そのままループを終了して先に進みます。
はい、早期returnできました。
もちろんこのような書き方はせず、メソッドなどに出してください。
current / reset / next / prev / end
配列ポインタを手動で操作することが可能です。
$array = range(0, 5);
while(true){
echo key($array), current($array);
if(next($array) === false){
break;
}
}
配列ポインタ操作関数はreset、next、prev、endなどひととおり揃っています。
が、あえてこれらの関数を使わなければならない場面はありません。
さらにマニュアルには書かれていないのですが、実はこいつらの引数はZ_PARAM_ARRAY_OR_OBJECT_HTであり、つまりオブジェクトを受け付けます。
class Test{
public $a = 1;
protected $b = 2;
private $c = 3;
}
$array = new Test();
while(true){
var_dump(key($array), current($array) );
if(next($array) === false){
break;
}
}

マジかよ。
each
PHP7.2でDeprecatedになったため、使ってはいけません。
いにしえのPHPではメモリ節約のためにeachを使おうなどとされていた時代もありましたが、PHP7時代においては間違った記述です。
上のほうでforeachしたら配列のコピーが作成され云々とか言いましたが実は嘘で、現在ではforeachループするだけならコピーは作成されません。
ループ中で元の配列を変更しようとしたときに初めてコピーが作成されます。
これはコピーオンライトと呼ばれる技術で、最近のPHPの最適化技術のひとつです。
現在のPHPは非常に最適化が進んでいるので、下手なことを考えるより標準機能を使った方がよっぽど使用メモリも少なく速度も速いです。
ジェネレータの変な使い方
素のジェネレータはforeachしかできず、whileやforで書くことができないのですが、実はGeneratorクラスはIteratorインターフェイスをimplementsしているので、手動でループさせることもできます。
$fibonacci = getFibonacci();
while ($fibonacci->key() < 28) {
$fibonacci->next();
echo $fibonacci->current(); // 1, 1, 2, 3, 5, 8, …
}
こんな処理が必要になるのであれば、ジェネレータではなく他の機能を使った方がよいでしょう。
yield fromキーワードを使って、別のジェネレータの返り値を取り込むことができます。
function gen()
{
yield 1;
yield from [2, 3];
yield from gen2();
}
function gen2()
{
yield 4;
yield 5;
}
$gen = gen();
foreach ($gen as $v) {
echo $v; // 1, 2, 3, 4, 5
}
こんな処理を作り込むよりも、データ構造を見直した方がよいでしょう。
ソート
usortなんかは関数型っぽい書き方なのでループと言えないこともない可能性がなきにしもあらずな気がしないでもないんだけどループの範疇に含めるべきものだろうか?
$arr = [3, 1, 2];
usort($arr, function ($a, $b) {
return $a <=> $b;
});
var_dump($arr); // 1, 2, 3
やはりループっぽくはないですね。
その他
思いついたのを並べたらこんなかんじでした。
見落としや間違いがあったら誰かがプルリクしてくれるはず。
-
0.1%くらい正しいことを言っている可能性もあるが、見分けは付かないので全て間違いと考えてかまわない。 ↩
Bashで文字列の構造体を使いたい
自身の備忘を兼ねて記載を行っています。
「とりあえず動いた」程度のソースなどもございますので参考程度にブラシアップ頂けると幸いです。
また、誤りやもっとよいコーディングやきれいな書き方があるなどご指摘頂けるととてもうれしいです。
今回のお題
任意の件数のデータについて同一の処理を行いたく、構造体で実現しようと思い作成
では、ソースです。
sample01.sh
#! /bin/bash
# 構造体
LOOP_LISTS=(
ABCDEFG
hijklmn
1234567
あいうえお
)
i=1
# 構造体の中身をループで一つづつ表示
for LOOP_LIST in ${LOOP_LISTS[@]}; do
# 同一の処理(今回は表示)
echo "${i}:${LOOP_LIST}"
let i++
done
# 構造体の中身を指定で表示(1番目のデータは「0」になる)
echo "2番目指定:${LOOP_LISTS[1]}"
実行結果
$ sh sample01.sh
1:ABCDEFG
2:hijklmn
3:1234567
4:あいうえお
2番目指定:hijklmn
関数型プログラミング言語で文字列を再帰的に生成するときの高速化
何をしようとしているか
関数型プログラミング言語にて、データ列を持つモジュールを作り、そこにtoString関数を作ろうとしています。
例えば、以下のようなシグネチャーを持つモジュールになります。
自作モジュールの例
signatureMY_MODULE=sigtypetvaltoString:t->stringendよくやる畳み込みを使った解法とその問題点
このとき、自作モジュールのデータ列は、リストを使って実装するとします。
すると、以下のようにリストの畳み込み関数foldrと、文字列結合関数^を使って、toString書くと見通しが良さそうです。
リストの他にも、arrayやvectorなどでも同様です。
toString関数
typeelem=...(*何らかの要素 *)typet=elemlistfuntoStringdatas=foldr(fn(e,acc)=>(elemToStringe)^acc)""datas例えば、[A, B, C, D]のようなデータがあれば、ざっくり言うと、以下のように展開されながら動きます。foldrを使って実装したので、右から処理されていきます。
toString関数の展開例
toString [A, B, C, D]
=> "A" ^ ("B" ^ ("C" ^ ("D" ^ "")))
=> "ABCD"
しかし、このコードはとても遅いです。
具体的には、入力のデータの長さnに対してO(n^2)時間かかります。
なぜ畳み込みと文字列結合を組み合わせると遅いのか
SMLの文字列はイミュータブルであり、文字列の実体はchar vectorです。
そのため、文字列結合関数^は、新たな文字列を生成して返します。
このような前提の上で、"X" ^ "Y"のアルゴリズムは、例えば以下のようになります。1
- "X"の長さと"Y"の長さの合計の幅のバッファを確保する
- バッファの前半に"X"をコピーする
- バッファの後半に"Y"をコピーする
- バッファを結合された文字列として返す
よって、toString関数の実行中に、途中生成される文字列は以下になります。
toString[A,B,C,D]が生成する文字列
""
"D"
"D"
"C"
"CD"
"B"
"BCD"
"A"
"ABCD"
はい。
明らかに無駄な文字列が大量に生成されています。
この関数は、入力のデータの長さnに対して、文字のコピー回数がO(n^2)起こるため、遅いです。
解法
stringの実体はchar vectorのため、
徐々にデータが大きくなるようなループに使うと、
一時変数を作るコストがとても高いです。
よって、同じような場合でも、一時変数を作るコストが低いデータ構造を考えます。
これには、例えばリストがあげられます。
ここではリストを一時変数に使うことのコストの低さの説明のために、1 :: [2, 3]のアルゴリズムを考えてみましょう。
ここで、[2, 3]はSMLでのリストを表します。
1を値に持つコンスセルを作る1のコンスセルのポインタを、リスト[2, 3]の参照にする1のコンスセルの参照を、新たなリストとして返す
このように、リストのcons(::)は、
新たなリストの生成時に元のリストを使いまわします。
それでは、一時変数にリストを使って先のtoString関数を書き直してみます。
幸いにも、Standard ML Basis Libraryには、CharVector.fromList : char list -> stringという関数があります。
これを使い、char list型で構築して、最後に文字列に変換すれば良いです。
新たなtoString関数
funtoStringdatas=letvalcharList=foldr(fn(e,acc)=>(elemToChare)::acc)nildatasinCharVector.fromListcharListendこのtoString関数は、ざっくり言うと、以下のように展開されながら動きます。
なお、#"A"はSMLでのchar型のAを表します。
新たなtoString関数の展開例
toString [A, B, C, D]
=> CharVector.fromList (#"A" :: #"B" :: #"C" :: "D" :: nil)
=> "ABCD"
このとき、生成されるデータは以下です。
新たなtoString[A,B,C,D]が生成するデータ
#"D"
#"C"
#"B"
#"A"
[#"A", #"B", #"C", #"D"]
今度は無駄なデータの生成がなくなりました。2
実行時間の差の計測
実際のコンパイラで差が出るのかを確認します。
今回は、AtCoderなどでも利用されているMLtonコンパイラと、自分が好きなSML#コンパイラを使って、速度差が出るかを検証しました。
使ったテストコードを以下に示します。
このテストコードでは、長さ10,000のテストデータを作り、文字列へ変換してプリントします。
時間の計測にはtimeコマンドを使います。
問題のあるテストコード
test1.sml
structureS:sigdatatypeelem=A|BtypetvaltoString:t->stringend=structdatatypeelem=A|Btypet=elemlistfunelemToStringA="A"|elemToStringB="B"funtoStringdatas=foldl(fn(e,acc)=>(elemToStringe)^acc)""datasendfunmain()=let(* n個のAを持つデータをプリントする *)valn=10000valinput:S.t=List.tabulate(n,fn_=>S.A)valformat=S.toStringinputinprintformatendval()=main()改善したテストコード
test2.sml
structureS:sigdatatypeelem=A|BtypetvaltoString:t->stringend=structdatatypeelem=A|Btypet=elemlist(* char listにしてからCharVector.fromListでstringにする *)funelemToCharA=#"A"|elemToCharB=#"B"funtoStringdatas=letvalcharList=foldr(fn(e,acc)=>elemToChare::acc)nildatasinCharVector.fromListcharListendendfunmain()=let(* n個のAを持つデータをプリントする *)valn=10000valinput:S.t=List.tabulate(n,fn_=>S.A)valformat=S.toStringinputinprintformatendval_=main()計測結果
MLtonコンパイラでもSML#コンパイラでも如実に時間差が見られます。
特にMLtonコンパイラでは時間差が顕著となりました。
MLtonコンパイラによる実行時間の差
$mlton
MLton 20130715 (built Fri Apr 28 06:06:34 UTC 2017 on lcy01-11)
$make &&time ./test1 > /dev/null &&time ./test2 > /dev/null
mlton test1.sml
mlton test2.sml
real 0m0.123s
user 0m0.118s
sys 0m0.000s
real 0m0.002s
user 0m0.000s
sys 0m0.000s
SML#コンパイラによる実行時間の差
$smlsharp
SML#3.5.0 (2019-12-24 17:29:31 JST)for x86_64-pc-linux-gnu with LLVM 7.0.0
$make &&time ./test1 > /dev/null &&time ./test2 > /dev/null
smlsharp -c -O2 test1.sml
smlsharp test1.smi -o test1
smlsharp -c -O2 test2.sml
smlsharp test2.smi -o test2
real 0m0.030s
user 0m0.013s
sys 0m0.026s
real 0m0.011s
user 0m0.014s
sys 0m0.000s
今回しなかった話
今回は例が簡単なデータ構造のため、一方向からの挿入さえ早ければよく、一時変数はリストで十分でした。
より複雑なデータ構造になり、複数の結合や削除を行う場合には、ツリー構造など適したものを選定する必要があります。
使う言語がBufferやSeqやArrayのようなものを持っており、そこから文字列を構築する方法があれば、より簡単に
まとめ
- 文字列は素朴なデータではないので、再帰などのループで扱うときには注意が必要
^をfoldなどのループ内で使ってはいけない- コストの低い一時変数を選び、最後に結合する方法を使う
追記
MLtonとかSML#の標準ライブラリを眺めた感じだと、stringを作りたいときはリストに詰めておいてString.concatするのが速いっぽい(MLtonだとcocatは最初に必要なだけ領域を確保してunsafeCopyで埋めてくれる https://t.co/4b8QJPWclh
— でこれき (@dico_leque) February 19, 2020
CharVector.fromListや同じ動作をするString.implode以外にも便利な関数が。
SML#の実装も眺めて見ましたが、やはりMLtonと同じく先にバッファを確保するため効率がよいです。String.concat : string list -> stringも活用していきましょう。
正確には、リスト
[#"A", ... , #"D"]の各要素も共有されており、新たな#"A"生成はされません。新たに生成されるデータは、このリストを表現するためのコンスセルになります。 ↩
C言語におけるループ処理の簡単なまとめ
Cには全部で3つのループ文が用意されている
- for文 : 回数指定
- while文 : 条件指定(先判定)
- do~while文 : 条件指定(後判定)
回数指定ループ(for文)
for文 : 回数指定
inti;for(i=1;i<=繰り返し回数;i++){繰り返す文;}ループを強制終了させる
これは全てのループ処理で使える。
break;
条件指定ループ(while文とdo~while文)
while文 : 条件指定(先判定)
- 実行前に条件式を判定する
while(条件式){繰り返す文;}forのように使いたいときは下記のように書く
初期化;while(条件式){ 繰り返す文; 更新;}do~while文 : 条件指定(後判定)
実行後に条件を判定する
- 必ず一度実行したい場合はこちらを使用する
入力チェックのときに威力を発揮する。間違っていたら再入力させるときに
do{繰り返す文;}while(条件式);民間企業の情シスが本当に欲しいZabbix
民間企業の情シス
フリーランスのSE(インフラSE)を生業にして約15年。
ベンダー系企業に常駐することが多かったが,2年前より初の民間の情シスへ常駐している。
民間企業の情シスは守備範囲が広い。サーバ構築など手を動かす仕事はベンダーに任せるが,クライアントPCの不具合,サーバの不具合,ネットワーク機器の不具合,しいてはOffice製品の問い合わせまで対応をする。
そんな守備範囲の広い民間企業の情シスで一番負荷が高く,緊急かつ重要な仕事が障害対応である。
ユーザからすればサーバは動いて当たり前,ネットワークはつながって当たり前の感覚でいるので,障害が起こった時は電話と非難の嵐である。
その上,ダウンタイムが影響人数と時間当たりのコストから損害金額として算出され,ただでさえお金を生まない部署なのに損害を出したことでどんどん立場が弱くなっていく。
民間企業の情シスはこんな立場の所が多いのではないだろうか,と思う。
常駐開始後まもなく
常駐した翌日に社内ネットワーク全停止という大規模障害が発生した。
その時の対応を見て,障害が発生した場合,どのように障害を検知し,連絡し,対応しているかを聞いてみたが,システム障害,ネットワーク障害を検知するための監視システムが入っておらず,情シスが障害を検知するタイミングは「ユーザからの連絡のみ」という状況だった。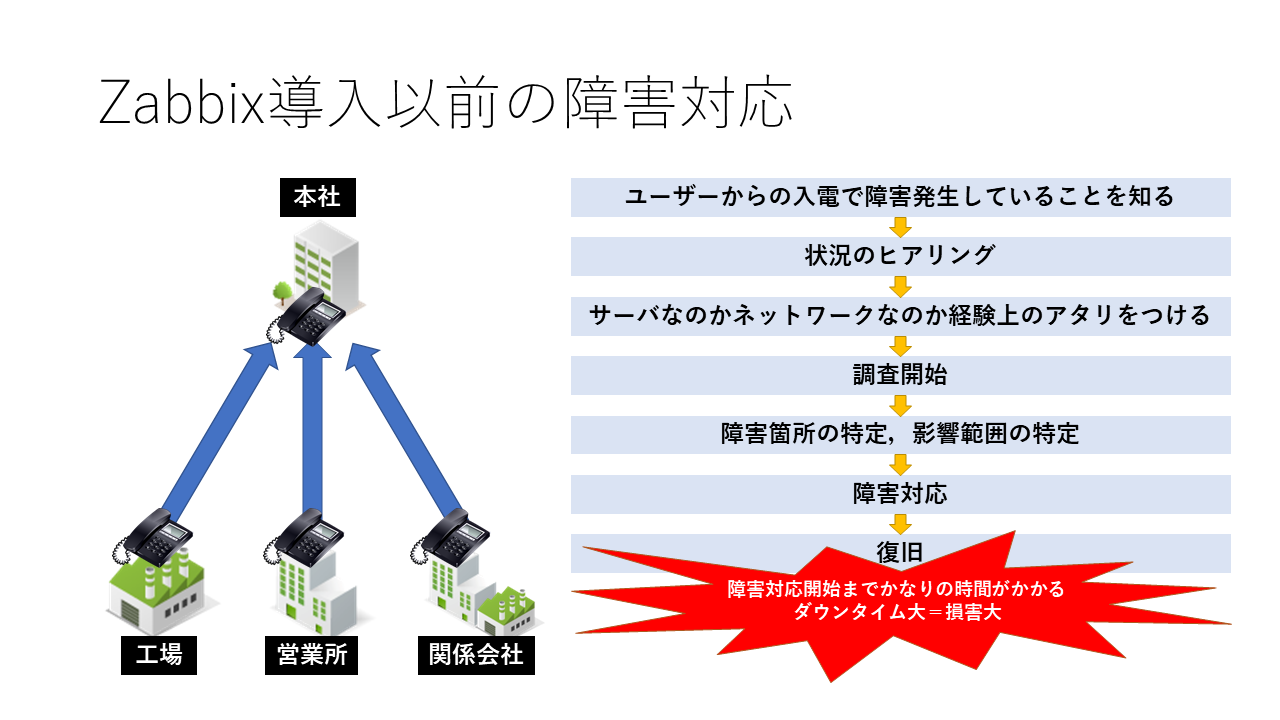
監視システム「Zabbix」の導入
せめてサーバとネットワーク機器を監視しておいて,障害が発生したことを検知できる体制を作ることが必要だと思い,監視システムの導入を手掛けることにした。今までもベンダーから監視システムの提案はあったがそれなりの費用がかかる上,その他の仕事に追われて後回しとなっているのだとも聞いた。
そうなれば導入費用のかかるものはNGとなる。必然的にオープンソースであるZabbixを選定して導入を進めた。
まずはubuntu16.04+Zabbix3.0の組み合わせでVMに構築した。
私にとってZabbixはこの時がデビューだった。
まずは,疎通できなくなることが一番の障害なので,どのサーバ,どのネットワーク機器が通信できなくなったのかを検知するためにping監視と障害メールの送信を設定した。
Zabbixを育てる
Zabbixの導入は障害対応スピードの向上に大きく貢献した。
連絡が入って初めて知ることはほぼなくなり,逆にユーザが気付かないレベルで検知するのでこちらから「障害が起きているようなので調べてください」と拠点の担当者にアウトバンドできるようになった。
また,Zabbixのマップにネットワーク構成図を表示して,障害が発生した機器がすぐ分かるようにしたり,メールでは気づかない時もあったので,障害発生時にはパトランプを連動させるようにした。
しかし,ネットワーク構成図のマップをダッシュボードに表示しておいてもどこにある機器なのかが分からないと不便だな,と思うようになった。
そんな中,Zabbixも触りなれてきたので,最初から構築しなおした。
ついでにZabbixのバージョンアップも行い,ubuntu18.04+Zabbix4.0で構築した。
拠点のネットワーク調査(実際の配線レベル)も同時に行っていたので,拠点の平面図に機器配置と配線を描いた調査図をZabbixに使えたら誰が見ても,どこで障害が発生しているか一目で分かるのではないかと思い,Zabbixへ反映した。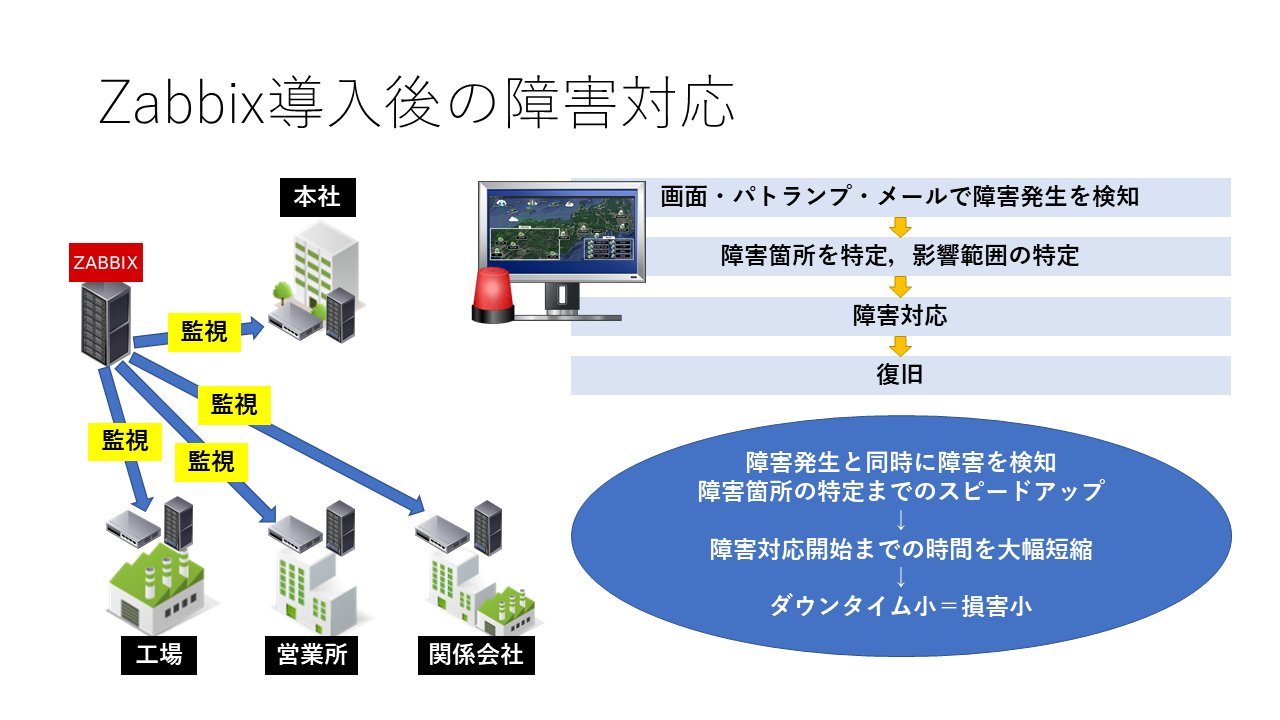
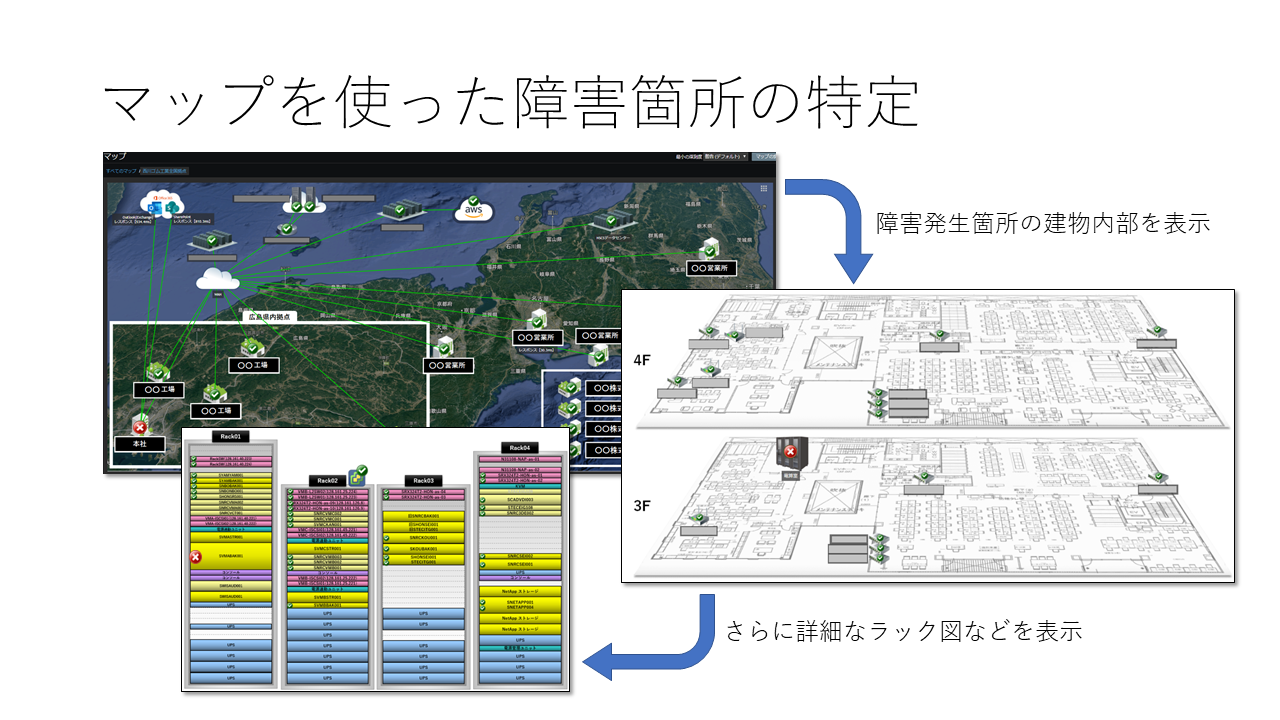
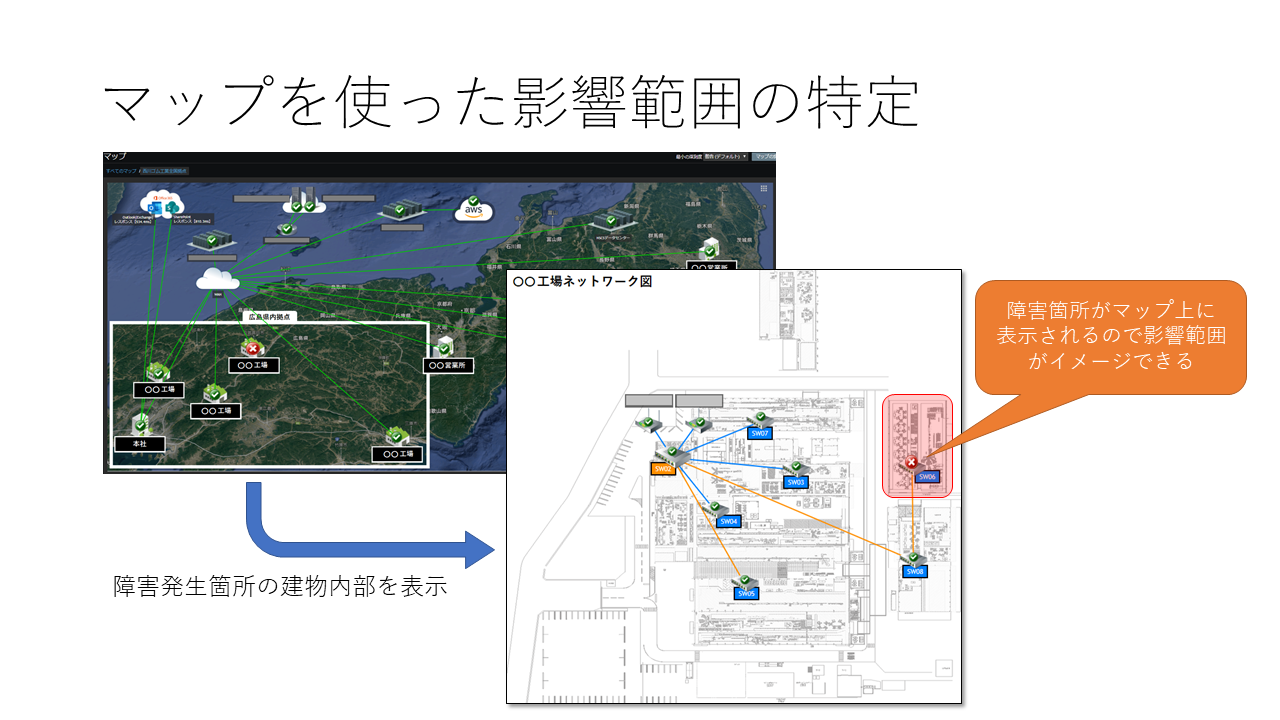
民間企業に必要なZabbix
監視システムの必要性は契約先にも十分理解してもらえた。
本運用開始後半年ぐらいだが,今ではなくてはならないものになり,社員の方にZabbix公式トレーニングプログラムを受けてもらうまでになった。
民間企業の情シスは運用方である。
今回とても勉強になったのは,システム屋が構築するシステムと運用方が欲しているシステムには開きがあり,そこがうまく融合していないシステムは廃れ,融合したシステムはとても役に立つということだった。
言葉にすると当たり前のことかもしれないが,この違いをうまく融合できていないシステムは多いと思う。「運用でカバー」という言葉を聞くことが多いが,この言葉は融合していないから出る逃げの言葉だと良くわかった。
ベンダー系企業の情シスや社外へ情シス部門を出している企業,成熟した情シスを持っている企業であれば,ホスト名やIPアドレスで機器の位置,情報,役割などが頭に浮かぶレベルだったりする。
そういう企業では私が作った運用方のZabbixは必要ないと思う。
情シスが何でも屋になることの多い中小の民間企業では運用方Zabbixの必要性が分かってもらえると思う。
最後に
最後まで読んで頂きありがとうございました。
Zabbixを触ったのはこの導入が初めてで難しいことは何もやっていません。
今はSWのステータスをブラウザで表示したり,Office365の応答時間を表示させたりとZabbixを育成中です。
お困りのことや知りたいことがありましたらお気軽にご連絡ください。
また,
https://www.lancers.jp/skill_pkg/items/727
で簡単なコンサルも受け付けています。
導入相談~導入,フォローも可能です。
ありがとうございました。
http://www.office-hayashi.biz/
Scanner 正常入力になるまで無限ループ
Scanner 正常入力になるまで無限ループ
前回の振り返り
前回はtry-catch構文を使って、例外クラスが使われた時の処理を実装するという内容をやりました。
今回は入力のパターンを全て考えてif文、try-catch構文、while文を使い入力が異なる場合ループさせる方法についてご説明します。
てことで例題いっちゃいましょ〜!
例題
・入力が正の整数値の場合だけ数値を出力、他の場合は入力に戻る。
コンソール
まず、気をつけて欲しいのが0は正の整数ではないということです。(中学生内容)
ループごとの改行は見やすさのために行いました。
処理の通知の文を出力してコードの動きを追いやすくしてみました。
特にbreak;とcontinue;に注目してください。
コメントアウトの詳しい説明は後ろの方に載っているので分からなくてもとりあえず読み進めてください(^^;;
コード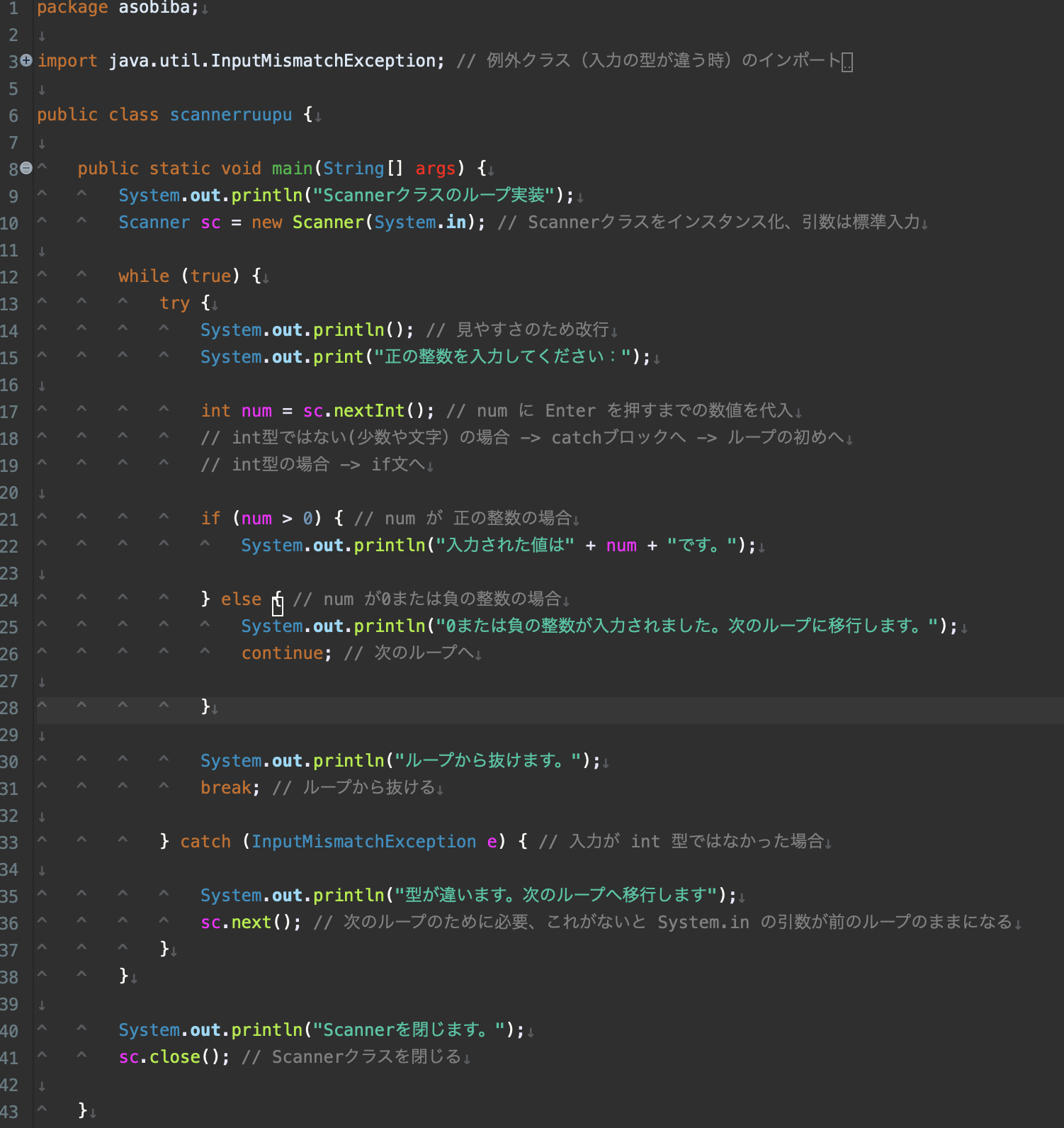
コンソール画面(もう一度)
全体の構造
- try-catch構文をwhile文でループさせています。特にエラーが起きる可能性のない処理をtryブロック内に入れているのは変数のスコープ(有効範囲)を広げないためです。合ってるかはわかりません。
基本は無限ループ、
continue;、breakを使って流れを制御無限ループの書き方は
while(true)やfor(;;)などが簡単だと思います。
プログラムの流れ(基本的には無限ループの中にあることを忘れずに)
- まずint型変数num に標準入力を代入します。
- ここで例外(文字や少数)が発生した場合はcatchブロックの処理を行いwhile文により次のループへ移行します。-> 1へ
- 例外が発生しなかった(正or負の整数、0)場合、if文によってnumを場合分けします。
- numが0または負の整数だった場合、メッセージを出力して
continue;以下のwhileブロックの処理をスキップします。 -> 1へ - numが正の整数だった場合、ifブロック内の処理を行い、tryブロックの次の行に移行します。
- 正常処理を終えた場合は無限ループから脱出しないといけないので
break;を使って無限ループを抜けます。 - Scannerクラスを閉じます。
これで入力に対して全ての場合わけをして、正常処理を行うまで再入力を求めるプログラムができました。
無限ループについて
プログラム中に予期せぬ無限ループが発生したらCtrl + cで止まるので焦らず対処しましょう。
Macユーザーは、環境設定 > 一般 > エディター > キー の画面から終了のキーを設定しましょう。
以下、デフォルトの終了キー設定
【SAS】CSVファイルの各行の文字列を一致検索条件として判定ループさせる
目次
前提
実行環境
- Windows10
- Base SAS 9.4
必要な知識
- SASコードの文法
- DATAステップSETステートメントによるSDS作成
- ATRRIBステートメントによる列定義
- INFILEステートメントによる外部ファイル読み込み
- SETステートメントのnobsオプションによる行数取得
- SELECTステートメントによる条件分岐
- index()による文字列検索
- MACRO,MACRO変数の定義、呼び出し
- %DO %TO %ENDによるループ
- SASコードの文法
目的
次のようなPV(Page View)LogがSDS(SAS Data Set)で存在するとき、
pvlog.sas7bdat
次のような表形式のcsvファイルを用いて、
page_ctgr_list.CSV
| 検索方法 | 検索文字列 | カテゴリ |
|---|---|---|
| 部分一致 | https://abcde.news | ニュース |
| 完全一致 | https://fghij/business/?cid=info | ニュース |
| 部分一致 | https://klmno.weather | 天気 |
| 完全一致 | https://pqrst/pollen?bid=forecast | 天気 |
以下のようにカテゴリを付与する。
pvlog_ctgr.sas7bdat
方法
処理手順概要
- page_ctgr.csvをSDS化して、1行目から順に各列値をマクロ変数に保存
(n行*m列のとき、n*m個のマクロ変数ができる)。 - pvlog.sas7bdatの各urlに対して、page_ctgr.csvの検索文字と検索方法で1行目から順に判定。
- 検索一致した行のカテゴリを付与。1つも一致しなければ欠損にする。
- page_ctgr.csvをSDS化して、1行目から順に各列値をマクロ変数に保存
実装したSASコード
* 入出力フォルダ指定(任意);libnameI_DIR="/project/input/"access=readonlylibnameO_DIR="/project/output/"* ページカテゴリ取得マクロ定義;%MACROGetPageCtgr(INPUT_DIR=,I_SDS_NM=,INFILE_NM=,OUTPUT_DIR=,O_SDS_NM=);* csvを読み込みSDSに変換;datawork.page_ctgr_list;attribsearch_typelength=$8.label="検索方法"search_stringlength=$500.label="検索文字列"page_ctgrlength=$8.label="ページカテゴリ";infile"&INPUT_DIR.&INFILE_NM."dlm=","firstobs=2dsdmissover;inputsearch_typesearch_stringpage_ctgr;run;* page_ctgr_listの行数および1行目から順に各列値をマクロ変数に保存;data_null_;setwork.page_ctgr_listend=eof;ifeofthencallsymputx("PAGE_CTGR_LIST_OBS_CNT",_N_);callsymputx(cats("SEARCH_TYPE",_N_),search_type);callsymputx(cats("SEARCH_STRING",_N_),search_string);callsymputx(cats("PAGE_CTGR",_N_),page_ctgr);run;* pvlogのurlに対応するページカテゴリを付与する;data&OUTPUT_DIR.&O_SDS_NM.;set&INPUT_DIR.&I_SDS_NM.;* 検索方法は部分一致と完全一致の2種類のみであるのは既知とし、部分一致を先に判定する;*1つも一致しないときは何もしない=ページカテゴリは欠損になる;
select;%DOI=1%TO&PAGE_CTGR_LIST_OBS_CNT.;%IF&&SEARCH_TYPE&I..=部分一致 %THEN%DO;when(index(url,"&&SEARCH_STRING&I.."))page_ctgr="&&PAGE_CTGR&I..";%END%IF&&SEARCH_TYPE&I..=完全一致 %THEN%DO;when(url="&&SEARCH_STRING&I.."))page_ctgr="&&PAGE_CTGR&I..";%END%END;otherwise;end;run;%MENDGetPageCtgr;* マクロ実行;%GetPageCtgr(INPUT_DIR=I_DIR,I_SDS_NM=pvlog,INFILE_NM=page_ctgr_list.csv,OUTPUT_DIR=O_DIR,O_SDS_NM=pvlog_ctgr);参考
- https://sas-boubi.blogspot.com/2014/09/call-symputx.html
このページを見る前は行数と列値のマクロ変数保存を2ステップに分けて次のように実行していた。
* page_ctgr_listの行数をマクロ変数に保存;data_NULL_;setwork.page_ctgr_listnobs=page_ctgr_list_obs_cnt;callsymputx("PAGE_CTGR_LIST_OBS_CNT",page_ctgr_list_obs_cnt)run;* page_ctgr_listの1行目から順に各列値をマクロ変数に保存;data_NULL_;setwork.page_ctgr_list;%DOI=1%TO&PAGE_CTGR_LIST_OBS_CNT.if_N_=&I.thendo;callsymputx("SEARCH_TYPE&I.",search_type);callsymputx("SEARCH_STRING&I.",search_string);callsymputx("PAGE_CTGR&I.",page_ctgr);end;%END;run;- 検索方法やページカテゴリ別にcsvファイルを分けて管理したいとき、
一連の処理をファイル数だけループさせると再現が可能。
ファイル名(文字列)リストでループを回すとき、以下が参考になる。
https://y-mattu.hatenablog.com/entry/2016/08/05/010801
所感
- この処理を作った理由は、カテゴリリストの変更があるたびに条件式を書き換える作業を避けるためです。
- 現在Pysparkを使うようになったため、同様の処理をPysparkで実装する内容を投稿する予定です。
- QiitaのSASシンタックスハイライトではマクロ変数に色付けてくれないんですね。