

External article
Articles:
1年半取り組んだプロジェクトのPMを語る�
Vueを用いた開発プロジェクト用にカスタムジェネレーターを作ってみる
はじめに
こんにちは、モチベーションクラウドの開発にフリーのエンジニアとして参画している@HayatoKamonoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」2日目の記事となります。
先に成果物のイメージ
$ yo mcs
_-----_
| | ╭──────────────────────────╮
|--(o)--| │ Welcome to MCS App │
`---------´ │ Generator! │
( _´U`_ ) ╰──────────────────────────╯
/___A___\ /
| ~ |
__'.___.'__
´ ` |° ´ Y `
? What do you want to generate? (Use arrow keys)
❯ Vue Component
Vuex Store Module
? What's the component name? SampleComponent
create SampleComponent/SampleComponent.index.js
create SampleComponent/SampleComponent.vue
create SampleComponent/SampleComponent.stories.js
create SampleComponent/SampleComponent.specs.js
↑ この記事では、このようなものを作っていきます。
概要
モチベーションクラウドの開発チームでは2018年10月から改善期間と称して、開発に関するガイドラインやルール作りをはじめとする、様々な改善活動に取り組んでいます。
私が所属するフロントエンド開発チームでも、改善活動の一環として複数のガイドラインを作成しているのですが、その作成したガイドラインの1つに、コンポーネントを配置するディレクトリ構成・ファイル構成に関するガイドラインがあります。
.
├── atoms
├── molecules
├── organisms
│ └── SampleComponent
│ ├── index.js
│ ├── SampleComponent.specs.js
│ ├── SampleComponent.stories.js
│ └── SampleComponent.vue
├── templates
├── pages
└── decorators
簡単に説明をすると、componentsディレクトリ配下のディレクトリを、Atomic Designのatoms、molecules、organisms、templates、pagesで切り、そして、開発するコンポーネント毎にそのコンポーネント名でディレクトリを切るというディレクトリ構成で行くという方針で固まりました。
また、コンポーネント単位のディレクトリ配下には、「index.js」、単一ファイルコンポーネントの「ComponentName.vue」、Storybook用の「ComponentName.stories.js」、テスト用の「ComponentName.specs.js」を作成するというファイル構成で行くことに決まりました。
しかしながら、コンポーネント単位のディレクトリ以下に、毎回、4つのファイルを手動で決まった命名規則に合わせて作成するのは何気に面倒ですし、また、コード内に登場するコンポーネント名や、importするファイル名などを毎回、手動で書いたりするのも面倒です。
そこで今回はこれらのファイル一式を雛形ファイルをもとに自動生成するジェネレーターを作ってみたいと思います。
Yeoman事始め

今回、ジェネレーターを作成するに当たっては、Yeomanを利用します。
What's Yeoman?
Yeoman helps you to kickstart new projects, prescribing best practices and tools to help you stay productive.
To do so, we provide a generator ecosystem. A generator is basically a plugin that can be run with theyocommand to scaffold complete projects or useful parts.
$ npm install -g yo
まずは、Yeomanをインストール。
$ mkdir generator-mcs
早速、ジェネレーター用のフォルダをYeomanの命名規則に従って作成します。
ジェネレーター用のフォルダ名は「generator-name」のように、「generator」をフォルダ名のprefixとし、ハイフンで次に続くジェネレーター名を区切る必要があります。
$ cd generator-mcs
$ npm init -y
$ npm install --save yeoman-generator yosay
次に、package.jsonを作成し、今回の記事で作成するジェネレーターで使う依存モジュールを先にインストールしておきます。
※ 今回は、npm init -yでpackage.jsonの細かな設定はスキップしましたが、作成したジェネレーターをYeomanのGeneratorsページにインデックスさせたい場合は、package.jsonのkeywordに["yeoman-generator"]を指定、また、descriptionに任意の説明文を入れる必要があります。
$ mkdir -p generators/app generators/component
$ touch generators/app/index.js generators/component/index.js
今度は作業ディレクトリにgeneratorsフォルダーを作成し、その中にappフォルダーとcomponentフォルダーを作成します。
.
├── generators
│ ├── app
│ │ └── index.js
│ └── component
│ └── index.js
└── package.json
Yeomanにはapp generatorというメインのジェレネーターと、sub generatorというサブのジェネレーターの2種類のジェネレーターが作成可能です。
両者の使い分けは、app generatorは主にアプリケーション全体の雛形を作る為に利用し、sub generatorはより限定的な用途に利用するといったイメージです。
デフォルトの設定では、appディレクトリ以下のindex.jsがapp generatorに対応します。
そして、その他の任意の名前をつけるディレクトリ以下のindex.jsがそれぞれsub generatorに対応し、今回の例でいうと、componentディレクトリ下のindex.jsがsub generatorに該当します。
$ yo mcs
例えば、この記事で作成しているジェネレーターの名前はgenertor-mcsなので、appディレクトリ以下のapp generatorは上記のコマンドで後ほど実行出来ることになります。
$ yo mcs:component
また、先ほどgeneratorディレクトリ以下に作成したcomponentディレクトリの名前は、そのまま、サブジェネレーターの名前となるので、上記のコマンドでこちらのサブジェネレーターを後ほど実行出来るようになります。
app/index.js
const Generator = require('yeoman-generator');
const yosay = require('yosay');
module.exports = class extends Generator {
constructor(args, opts) {
super(args, opts);
this.log(yosay('Welcome to MCS App Generator!'));
}
};
とりあえず、app generatorに対応するapp/index.jsを上記のように編集して、Hello World的なものを作り動作確認をしてみます。
$ npm link
動作確認をする為にも、上記のコマンドを実行して、現在作成しているジェネレーターをグローバールインストールしておきます。
$ yo mcs
_-----_
| | ╭──────────────────────────╮
|--(o)--| │ Welcome to MCS App │
`---------´ │ Generator! │
( _´U`_ ) ╰──────────────────────────╯
/___A___\ /
| ~ |
__'.___.'__
´ ` |° ´ Y `
yo generator-nameを実行すると、無事にapp generatorの実行が確認出来るはずです。
This Generator is empty. Add at least one method for it to run.というエラーが出るかもしれませんが、後で他にメソッドを追加すれば解消されるエラーなので、今は特に気にせず、次に進みます。
ちなみに、最初にインストールしたyosayライブラリは、上記の実行結果を見て分かる通り、Yeomanのイメージキャラクターのアスキーアートを出力する為のライブラリです。(見た目大事、楽しさ大事!)
今回は特にアプリケーション全体の雛形ファイルを作ることはしないので、一旦、app generatorはここまでとします。
雛形ファイルをもとにファイルを自動生成する
.
├── atoms
├── molecules
├── organisms
│ └── SampleComponent
│ ├── index.js
│ ├── SampleComponent.specs.js
│ ├── SampleComponent.stories.js
│ └── SampleComponent.vue
├── templates
├── pages
└── decorators
ここからは、この記事の概要で説明した通り、上記のようにcomponent単位のディレクトリ以下にindex.js、componentName.vue, componentName.stories.js、componentName.specs.jsの4ファイルを雛形ファイルをもとに生成するsub generatorを作って行きます。
.
├── generators
│ ├── app
│ │ └── index.js
│ └── component
│ └── index.js
└── package.json
それでは、既に作成しておいたcomponentディレクトリ以下のindex.jsを編集して、yo mcs:componentで実行出来るジェネレーターを作成して行きます。
$ mkdir generators/component/templates
先に、componentディレクトリ以下にtemplatesという名前で雛形ファイルを配置する為のディレクトリを作成しておきます。
Yeomanのデフォルトの設定では、templatesと名前の付いたディレクトリのパスが、後述するthis.templatePath()で取得可能なパスになります。
$ cd generators/component/templates/
$ touch _index.js _ComponentName.vue _ComponentName.specs.js _ComponentName.stories.js
$ tree .
.
├── _ComponentName.specs.js
├── _ComponentName.stories.js
├── _ComponentName.vue
└── _index.js
続けて、templatesディレクトリ以下に雛形となる4つのファイルを任意の名前で作成します。
現時点では単に空ファイルを作成しているだけですが、後ほど、これらの雛形ファイルにそれらしいベースとなるコードを追記したいと思います。
※ ファイル名は任意の名前で大丈夫です。_をファイル名の先頭に付けることは必須ではありません。
component/index.js
const Generator = require('yeoman-generator');
module.exports = class extends Generator {
constructor(args, opts) {
super(args, opts);
}
writing () {
this.fs.copyTpl(
this.templatePath('_index.js'),
this.destinationPath('ComponentName/ComponentName.index.js')
);
this.fs.copyTpl(
this.templatePath('_ComponentName.vue'),
this.destinationPath('ComponentName/ComponentName.vue')
);
this.fs.copyTpl(
this.templatePath('_ComponentName.stories.js'),
this.destinationPath('ComponentName/ComponentName.stories.js')
);
this.fs.copyTpl(
this.templatePath('_ComponentName.specs.js'),
this.destinationPath('ComponentName/ComponentName.specs.js')
);
}
};
早速、component/index.jsを上記のように編集し、雛形ファイルをもとに新規ファイルを生成してみます。
ファイルの書き込み処理は、Generatorクラスに定義されているwritingメソッドの中に記述するようにします。
現段階では、コンポーネント名を直書きしていますが、後ほど、ユーザーからコンポーネント名の入力を受け付けるようにして、動的にコンポーネント名をファイル名に適用して行きます。
component/index.js
this.fs.copyTpl(
this.templatePath('_index.js'),
this.destinationPath('ComponentName/ComponentName.index.js')
);
ここでやっていることは、templatesディレクトリ以下の雛形ファイルをコピー元として指定し、yoコマンドが実際に実行されるカレントディレクトリ以下のComponentName/ComponentName.index.jsにファイルをコピーするという処理です。
$ mkdir ~/demo-project
$ cd ~/demo-project
$ yo mcs:component
ジェネレーター開発用の作業ディレクトリで、yoコマンドでジェネレーターを実行してしまうと、作業ディレクト内にファイルが生成されてしまうので、ここからは、yoコマンドを実行する時には、別に作成したプロジェクトディレクトリ内で実行して行きます。
.
└── ComponentName
├── ComponentName.index.js
├── ComponentName.specs.js
├── ComponentName.stories.js
└── ComponentName.vue
yoコマンドを実行すると、コマンドを実行したカレントディレクトリ上に、ComponentNameというディクレトリが作られ、その中に4つのファイルが生成されていることが確認出来ました。
今度は動的にコンポーネント名を生成されるファイルに反映出来るようにして行きます。
component/index.js
const Generator = require('yeoman-generator');
module.exports = class extends Generator {
constructor(args, opts) {
super(args, opts);
}
async prompting() {
// ユーザーの入力に関する情報をインスタンス変数に入れておく
this.answers = await this.prompt([
{
type: 'input',
name: 'componentName',
message: `What's the component name?`,
validate (input) {
if (input.length > 0) {
return true;
} else {
// 文字列を返すと検証エラー時にそのメッセージが出力表示される
return "You need to provide the component name.";
}
}
}
]);
}
writing () {
// ユーザーが入力したコンポーネント名をインスタンス変数を参照して渡す
this.fs.copyTpl(
this.templatePath('_index.js'),
this.destinationPath(`${this.answers.componentName}/${this.answers.componentName}.index.js`)
);
this.fs.copyTpl(
this.templatePath('_ComponentName.vue'),
this.destinationPath(`${this.answers.componentName}/${this.answers.componentName}.vue`)
);
this.fs.copyTpl(
this.templatePath('_ComponentName.stories.js'),
this.destinationPath(`${this.answers.componentName}/${this.answers.componentName}.stories.js`)
);
this.fs.copyTpl(
this.templatePath('_ComponentName.specs.js'),
this.destinationPath(`${this.answers.componentName}/${this.answers.componentName}.specs.js`)
);
}
};
ユーザーからの入力を受け付ける処理は、Generatorクラスに定義されているprompting()の中に記述するようにします。
promptingメソッドの中で実行しているpromptメソッドは非同期実行され、promiseを返します。
そのため、async, awaitをpromptingメソッドのところでは使っています。
$ yo mcs:component
? What's the component name? SampleComponent
create SampleComponent/SampleComponent.index.js
create SampleComponent/SampleComponent.vue
create SampleComponent/SampleComponent.stories.js
create SampleComponent/SampleComponent.specs.js
yoコマンドを実行すると、コンポーネント名を入力するプロンプトが表示され、入力したコンポーネント名が反映されたディレクトリとファイルが生成されることが確認出来ました。
/templates/_ComponentName.vue
<template>
</template>
<script>
export default {
name: "<%= componentName %>"
}
</script>
<style lang="scss" scoped>
</style>
ここまでは、空の雛形ファイルをもとに動作確認を進めていたので、templates/_ComponentName.vueに簡易的なコードを加えて保存しておきます。
既に雛形ファイルをコピーする際に使用してきたfs.copyTplメソッドはejs template syntaxを使用しているので、雛形ファイルの方では、<%= componentName %>のようなejsの記法を使用することが可能です。
component/index.js
this.fs.copyTpl(
this.templatePath('_ComponentName.vue'),
this.destinationPath(`${this.answers.componentName}/${this.answers.componentName}.vue`),
{ componentName: this.answers.componentName }
);
_ComponentName.vue内の<%= componentName %>の部分に、ユーザーから入力されたコンポーネント名を反映出来るようにしてみます。
その為には、上記のコードのように、fs.copyTplメソッドの第3引数に対象の雛形ファイルに渡したい変数をkey, valueペアのオブジェクトで渡してあげます。
$ yo mcs:component
? What's the component name? SampleComponent
identical SampleComponent/SampleComponent.index.js
conflict SampleComponent/SampleComponent.vue
? Overwrite SampleComponent/SampleComponent.vue? (ynaxdH)
y) overwrite
n) do not overwrite
a) overwrite this and all others
x) abort
d) show the differences between the old and the new
h) Help, list all options
これで、再度、yoコマンドを実行し、コンポーネント名を入力してあげれば、入力したコンポーネント名が生成される.vueファイルの該当箇所に反映されます。
尚、ファイル生成時に既に同じファイルが存在していて、既存のファイルと新規に生成されるファイルの内容が異なる場合は、上記のようにconflictが発生します。
その際は、Hを押せば選択可能なオプションが表示されるので、その中から任意のオプションを選択すると良いです。
ちなみに、yを押せば上書き保存してくれます。
app generatorからsub generatorに処理を委譲する
最後に、ジェネレーターから別のジェネレーターに処理を委譲する方法を紹介して、今回の記事を終わりにしたいと思います。
ここでは例として、app generatorからsub generatorに処理を委譲してみたいと思います。
app/index.js
const Generator = require('yeoman-generator');
const yosay = require('yosay');
module.exports = class extends Generator {
constructor(args, opts) {
super(args, opts);
this.log(yosay('Welcome to MCS App Generator!'));
}
// ユーザーにサブジェネレーターを選択してもらう
async prompting() {
const answers = await this.prompt([
{
type: 'list',
name: 'generatorName',
message: 'What do you want to generate?',
choices: [
{
name: 'Vue Component',
value: 'component'
},
{
name: 'Vuex Store Module',
value: 'module'
}
]
}
]);
// ユーザーが選択したサブジェネレーターに処理を委譲する
this.composeWith(
require.resolve(`../${answers.generatorName}`)
);
}
};
app generatorに対応するapp/index.jsを上記のように編集します。
これで、yo mcsとコマンド実行した時に、先ほど作成したcomponentサブジェネレーターを実行するのか、moduleサブジェネレーターを実行するのかを、ユーザーに選択してもらえるようになり、選択されたサブジェネレーターに処理が委譲され実行されることになります。
※ 尚、2つ目の選択肢に対応するサブジェネレーターは未作成の為、選択するとファイルが見つからずエラーになります。上記の例はmoduleサブジェネレーターが仮に既に作成済みであったという想定の例になります。
$ yo mcs
_-----_
| | ╭──────────────────────────╮
|--(o)--| │ Welcome to MCS App │
`---------´ │ Generator! │
( _´U`_ ) ╰──────────────────────────╯
/___A___\ /
| ~ |
__'.___.'__
´ ` |° ´ Y `
? What do you want to generate? (Use arrow keys)
❯ Vue Component
Vuex Store Module
? What's the component name? SampleComponent
create SampleComponent/SampleComponent.index.js
create SampleComponent/SampleComponent.vue
create SampleComponent/SampleComponent.stories.js
create SampleComponent/SampleComponent.specs.js
今後やりたいこと
- yosayライブラリで出力されるYeomanのイメージキャラクターの代わりに、モチベーションクラウドの広告に起用されている役所広司さんのアスキーアートをウェルカムメッセージに表示出来るようにしたい
- 実際のプロジェクトで使われているコードを雛形ファイルにし、今回作成したジェネレーターを実用的なものにしたい
- 単一ファイルコンポーネントの
<script>部分をASTにparseしてprops情報を抽出し、そのprops情報をもとにStorybook addonのknobsに対応したStorybookファイルを自動生成出来るようにしたい
参考
関連記事
こちらの記事はモチベーションクラウド Advent Calendar 2018に投稿した記事です。
他にも、以下の記事をモチベーションクラウド Advent Calendar 2018に投稿しています。
- Vueを用いた開発プロジェクト用にカスタムジェネレーターを作ってみる
- Vueを用いた開発プロジェクト用に「コンポーネント設計・実装ガイドライン」を作った話
- Vuexを用いた開発プロジェクト用にガイドラインを作成した話
身の丈にあったWebAPI設計ガイドラインを作った話
こんにちは。フリーランスエンジニアの@dayoshixです。
現在、リンクアンドモチベーションのモチベーションクラウドの開発に、主にフロントエンドエンジニアとしてお手伝いさせて頂いております。
そのようなご縁もありモチベーションクラウドのアドベントカレンダー(3日目)に参加させて頂くことになりましたので宜しくお願いします!!
トップバッターの@ishigeさん、2日目の@HayatoKamonoさんお疲れ様でした!!
お二人の記事はこちら。どちらも力作なので宜しくお願いします。
ということで始めたいと思います。
概要
最近モチベーションクラウドのWebAPI設計ガイドラインが作成されたのですが、それはどのような方針で作成されたのか、その結果どのようなガイドラインが出来上がったのかを紹介します。
背景
これまでの状況
これまで、開発チームではWebAPIの設計に関する明文化されたルールがありませんでした。
WebAPI設計に関して専任の担当者がいるわけではなく、最近では状況にもよりますがフロントエンドエンジニアが設計を行う場面も増えてきました。
また、新たな開発メンバーも徐々に増えていき、迷いが生ずる場面が多くなり小さなストレスになっていました。
その結果かどうかわかりませんが、APIとしての一貫性が徐々に失われているように感じていた人も少なくなかったと思います。
改善しよう!!
開発チームとして技術的負債返済のための改善活動の一環としてWebAPI設計ガイドラインを作ろうという話になりました。
結果、私がガイドライン作成の音頭取りとベース作成を担当させて頂くことになり、開発メンバー全員にレビューして貰いブラッシュアップするようなフローで進めることになりました。
大切にしたこと
ガイドラインを作成するに当たって下記の点を大切にしました。
身の丈に合わせる
ネット上に公開されているガイドラインをそのまま模倣するのではなく、それらを参考にしつつも自分達が開発を通じて実際に迷ったことをもとに、今の自分達に必要な身の丈にあった最小限のルールだけを定義しようと考えました。
また、システムの文脈に依存する一般化できないようなルールがこぼれ落ちないことに注意しました。
基本を意識する
基本の理解を疎かにした状態で応用から入らないよう、基本を崩す場合の具体的な判断例を示すことを意識しました。
例えば、最初から特段の根拠もなく基本を崩しパフォーマンス最適化した設計にしないことを促したいと考えました。
べき論よりやり易さを優先する
セオリーや思想的にこうあるべき、という事が自分達にとってやりにくければ執着せずに無視することを意識しました。
システム概要
システムの特徴によってルールとして考慮する点が異なってくる事から、ガイドラインを紹介する前にモチベーションクラウドのシステム概要をざっくりと説明します。
- SaaS型のBtoBサービス
- バックエンドに
Ruby on Rails、フロントエンドにVue.jsを使用したいわゆるシングルページアプリケーション - 2018年11月時点でクライアントのプラットフォームはWebのみ
- WebAPIはシステム内で閉じた使われ方をしており、ユーザーに公開するAPIはない
WebAPI設計ガイドライン
それでは実際に作られたWebAPI設計ガイドラインを紹介します。
ガイドライン中に時折なぜこのような選択をしたのかをコメントしています。
概要
本文書はMCSバックエンド〜フロントエンド間のWebAPI設計のガイドラインです。
MCSはモチベーションクラウドの社内での総称になります。
設計指針
RESTful like
基本的にはRESTに従い設計して下さい。
但し、RESTを原則的に従うことでアプリケーションが複雑になる、パフォーマンスに問題が生ずるなどの理由がある場合はRESTの原則に逸れても問題ありません。
RESTful likeな設計を目指して下さい。
RESTの原則に外れる設計パターンについてはこちらを参照して下さい。
画面に最適化されたWebAPIを作るよりもREST APIを作ることを優先する
画面が必要とする情報を取得するための汎用性の無いWebAPIを設計することよりも、その画面に必要なリソースを取得するためのWebAPIを設計することを優先して下さい。
その画面に必要なリソースの種別が多く、API呼び出しのラウンドトリップ過多でパフォーマンスに影響が出た場合に初めて画面向けのAPIを設計することを検討して下さい。
なぜ?
画面向けのWebAPIは画面の表示要素が変更されるたびにバックエンド側にも改修が発生します。
RESTベースでWebAPIを作っている場合、変更対象の表示要素の情報を取得するためのエンドポイントが既に作られている可能性がありますし、新規に作った場合でも将来的に他の用途で再利用できる可能性があります。
画面の文言をバックエンドで管理しない
特別な理由が無い限り、画面に表示する文言リソースをバックエンドで管理しWebAPI経由でフロントエンドに提供するような設計にせず、フロントエンドで持つようにして下さい。
🙅 Bad
GET /menu_items
{
"meta": null,
"data": [{
"id": 1000,
"title": "属性検索",
"description": "登録済みの属性の一覧を検索することができます。"
},{
"meta": null,
"data": [{
"id": 1001,
"title": "ユーザー検索",
"description": "登録済みのユーザーの一覧を検索することができます。"
}]
}
🙆 good
GET /menu_items
{
"meta": null,
"data": [{
"id": 1000,
"type": 1
},{
"meta": null,
"data": [{
"id": 1001,
"type": 2
}]
}
共通ルール
命名
endpoint(URL)
path
snake caseであること
🙅 Bad
/surveySettings/1
/survey-settings/1
🙆 good
/survey_settings/1
railsとの親和性を考慮しました
query paramter
lower camel caseであること
🙅 Bad
/survey_settings?suvey_id=1000
🙆 good
/survey_settings?suveyId=1000
クライアントサイドJSで触るデータに関してはクライアントサイドJSの命名規則と同じlower camel caseに統一しました。
response body
property名
lower camel caseであること
🙅 Bad
{
"meta": null,
"data": {
"id": 1000,
"first_name": "foo"
}
}
🙆 good
{
"meta": null,
"data": {
"id": 1000,
"firstName": "foo"
}
}
ページング
ページング操作に対応したエンドポイントにおいてはページング情報は下記の命名に従って下さい。
request:
| フィールド名 | 意味 | 制約 | 備考 |
|---|---|---|---|
| page | ページ番号。開始番号は1です。 |
必須指定 | |
| limit | 1ページあたりの件数。 | 任意指定 | 1度に全件取得されると問題がある場合は必ずサーバーサイドで制限チェックを行うこと |
| sort | ソート対象のフィール名です。 | 任意指定 | |
| direction | ソート順です。ascの場合は昇順、descの場合は降順。 |
任意指定 |
response:
| フィールド名 | 意味 | 制約 | 備考 |
|---|---|---|---|
| total | 検索結果の総件数です。 | 必須指定 | リソースとしてではなくmeta情報として設定して下さい。 |
既存に暗黙の命名ルールがありましたがたまに外れた命名もあったため明文化しました。
HTTP method
POST、GET、PUT、DELETEのみ使って下さい。
各methodはCRUDのそれぞれに対応します。
responseのsatus code
正常系
一律 200 を設定して下さい。
異常系
エラーの表現を参照のこと。
response bodyのフォーマット
基本
リソースとリソース以外の情報(リストデータのページング情報、セキュリティトークン等)を分けるために、リソースをdataプロパティに、リソース以外の情報をmetaプロパティに分ける下記を基本のフォーマットとする。
{
"meta": { // リソース以外の情報をここに定義
"totalCount": 5000,
"securityToken" "trHqrxxwK8mJhY"
},
"data": [
// リソースはここに定義
{
"id": 100,
"name": "foo"
}
]
}
このルールは意見の別れるところかと思います。
response bodyはあくまでも純粋なリソースとし、meta情報はHTTP Responseの拡張ヘッダーに設定すべきという考え方もあります。
RESTを前提に扱ったツールと相性が悪いなどデメリットもありますが、情報がJSONに集約されていることによる開発・デバッグ時の分かりやすさを優先しました。
HTTP method: GET
フォーマットはendpointごとの任意の形式にして下さい。
HTTP method: POST
フォーマットはリクエストされたデータにID、生成日が設定されているデータにして下さい。
例)ユーザー情報の新規登録が正常に行われた場合のresponse
- 新規登録のrequest情報:
- endpoint:
/users- requst body:
json { "name": "foo", "gender": 1 }
🙅 Bad
status code: 200のみを返却し、response bodyを返却しない。
🙆 good
リソースのIDと生成日が含まれる下記のresponse bodyを返却する。
{
"id": 1001,
"name": "foo",
"gender": 1,
"createdAt": "2018-11-12T06:41:58.898+0900"
}
HTTP method: PUT
フォーマットはリクエストされたデータに更新日が更新されているデータにして下さい。
例)ユーザー情報の更新が正常に行われた場合のresponse
- 更新のrequest情報:
- endpoint:
/users/1001- requst body:
json { "id": 1001, "name": "bar", "gender": 0 }
🙅 Bad
status code: 200のみを返却し、response bodyを返却しない。
🙆 good
リソースのIDと更新日が含まれる下記のresponse bodyを返却する。
{
"id": 1001,
"name": "bar",
"gender": 0,
"updatedAt": "2018-11-12T06:44:34.894+0900"
}
HTTP method: DELETE
bodyを設定せず、status codeのみ返却して下さい。
非同期操作(※)
フォーマットはendpointごとの任意の形式にして下さい。
※ 非同期操作とは、バッチ処理を起動するなどの最終的な結果が即時に出ない操作を意味します。
エラーの表現
種類
エラーはシステム仕様上起こり得る業務エラーと、システム仕様上想定していないシステムエラーでエラーを区別し、適したエラーを定義して下さい。
業務エラー・システムエラーの具体例
業務エラーの例
- ユーザーの入力内容に誤りがあった。
- 所謂バリデーションエラー
- 他のユーザーが削除したデータを参照した。
- 閲覧権限の無いリソースへのアクスセスを検出した。
システムエラーの例
- バグが原因でサーバーサイドで例外が発生した。
- 外部連携システムがダウンした。
responseのstatus code
業務エラー
エラーの種別により下記のstatus codeを設定して下さい。
| status code | 意味 | 発生ケース |
|---|---|---|
| 400 | リクエストの内容に誤りがある | 入力内容のバリデーションに引っかかった。 パラメータ改竄されている、等 |
| 401 | 認証がなされていない | 認証が必要なendpointに認証情報を付加せずにアクセスした。 |
| 403 | リソースに対してアクセス権がない | 閲覧権限のない情報にアクセスした、等 |
上記は一例になります
システムエラー
エラーの種別により下記のstatus codeを設定して下さい。
| status code | 意味 | 発生ケース |
|---|---|---|
| 500 | システム内で想定外のエラーが発生した | システムがダウンしている、 サーバーサイドアプリケーションにバグがある、等 |
status codeの追加について
扱うエラーに対して本ガイドラインで定めているstatus codeに適したものが無い場合、適したstatus codeをガイドラインに追加して下さい。
また、扱わないエラーのstatus codeをあらかじめガイドラインに追加しないようにして下さい。
参考:HTTPステータスコード
response bodyのフォーマット
エラーを表現する場合、基本的にはreponseのstatus codeで表しますが、クライアント側でより詳細なレベルのエラー情報が必要な場合にのみ、reponse bodyで詳細なエラー情報を表現して下さい。
基本
エラーの詳細情報を表す場合、下記の基本フォーマットに従って下さい。
{
"meta": null,
"data": [
{
"code": 400000, // ※ 詳細エラーコード。必須。
"message": "error!!" // 任意
},
// ...
]
}
※ 詳細エラーコードの採番についてはこちらで説明します。
基本フォーマットで表現できない詳細情報を付加したい場合は基本フォーマットを変更しないことを前提に拡張して構いません。
{
"meta": null,
"data": [
{
"code": 400002,
"message": null,
"rowNo": 1, // 拡張部分
"columnNo": 10 // 拡張部分
},
{
"code": 400003,
"message": null,
"rowNo" 1,
"columnNo": 15
}
]
}
詳細エラーコードの採番規則
詳細エラーコードは数値型で、HTTPレスポンスのstatus codeと連番を組み合わせて採番して下さい。
フォーマットは6桁の数値で先頭3桁はstatus code、後続の3桁はエラー種別を表す0から始まる連番になります。
例)status codeが400のBad requestで、エラー種別が 3 の場合
{
"meta": null,
"data": [
{
"code": 400003
}
]
}
詳細エラーコード
詳細エラーコードは下記を使用して下さい。
| エラーコード | status code | 意味 | 備考 |
|---|---|---|---|
| 400000 | 400 | 既に指定されたemailアドレスがデータベースに存在する |
適したエラーコードが無い場合、上記のテーブルに追加して下さい。
Formのバリデーションエラー
Formのバリデーションエラーにおいて、エラー発生元フィールドとエラー情報を関連付ける必要がある場合は下記のルールに従って下さい。
- エラーレスポンスの詳細エラー情報ごとに
fieldNameという名前のフィールドを追加し、リクエストに含まれているバリデーション対象のフィールド名を設定する
例)メールアドレスに重複エラーとクレジットカード番号に与信エラーのバリデーションエラーが発生した場合
- メールアドレスのフィールド名は
email、クレジットカードの番号のフィールド名はcardNoとします。 - メールアドレスの重複エラーの詳細エラーコードは
400001、クレジットカードの番号の与信エラーの詳細エラーコードを400002とします。
request:
{
"meta": null,
"data": {
"email": "osumi_kumamon@ggmail.com",
"cardNo": "378282246310005"
}
}
response:
(status codeは400:bad request)
{
"meta": null,
"data": [
{
"code": 400001,
"fieldName": "email"
},
{
"code": 400002,
"fieldName": "cardNo"
}
]
}
データが無い場合の表現
リソース自体が無い
リソースのデータ形式が配列の場合は空配列([])を設定して下さい。
{
"meta": null,
"data": []
}
リソースのデータ形式がObjectの場合はnullを設定して下さい。
{
"meta": null,
"data": null
}
リソース内の一部のpropertyが無い
リソース自体が無い場合のルールと同じです。
リソースのデータ形式が配列の場合は空配列([])を設定して下さい。
{
"meta": null,
"data": {
"id": 1,
"children": []
}
}
リソースのデータ形式がObjectの場合はnullを設定して下さい。
{
"meta": null,
"data": {
"id": 1,
"firstName": "Thet Win Aung",
"lastName": null
}
}
データのフォーマット
データ型
基本的にデータに適したデータ型で設定して下さい。
🙅 Bad
{
"meta": null,
"data": {
"id": 1,
"score": "60.5" ‼️
}
}
🙆 Good
{
"meta": null,
"data": {
"id": 1,
"score": 60.5 👍
}
}
日時型
ISO8601拡張形式のタイムゾーンJSTで表現して下さい。
🙅 Bad
{
"meta": null,
"data": {
"id": 1,
"createdAt": "2018/10/29 05:38:24"
}
}
🙆 Good
{
"meta": null,
"data": {
"id": 1,
"createdAt": "2018-10-29T05:38:24.486+09:00"
}
}
区分値
区分を表すコード値は数値で指定して下さい。
区分値の例
🙅 Bad
{
"meta": null,
"data": {
"id": 1,
"status": "in_progress"
}
}
🙆 Good
{
"meta": null,
"data": {
"id": 1,
"status": 1
}
}
真偽値
真偽を表すフラグ値はBooleanで指定して下さい。
フラグ値の例
🙅 Bad
{
"meta": null,
"data": {
"id": 1,
"published": 1
}
}
🙆 Good
{
"meta": null,
"data": {
"id": 1,
"published": true
}
}
サニタイズ
responce bodyをXSS対策のためにサニタイズせず、rawデータで指定して下さい。
🙅 Bad
{
"meta": null,
"data": {
"id": 1,
"name": "<script>alert("foo")</script>"
}
}
🙆 Good
{
"meta": null,
"data": {
"id": 1,
"published": "<script>alert(\"foo\")</script>"
}
}
サニタイズはクライアントサイドのテンプレートシステムで行なっているためです。
query parameter
配列
配列データは<フィールド名>[]で表現して下さい。
🙅 Bad
GET /suveys?id=1,2,3,4,5
🙆 Good
GET /suveys?id[]=1&id[]=2&id[]=3&id[]=4&id[]=5
railsとの親和性を考慮しました。
構造を持つデータ表現
複数の異なるリソースを含むリソースはリソース単位でネスト構造を持たせて表現して下さい。
🙅 bad
{
"meta": null,
"data": {
"id": 1,
"name": "foo"
"barId": 1,
"barName": "foo"
}
}
🙆 good
{
"meta": null,
"data": {
"id": 1,
"name": "foo"
"bar": {
"id": 1,
"name": "foo"
}
}
}
エンドポイントのネスト
エンドポイントのネストは基本的にせず、path parameterよりquery parameterで表現することを優先して下さい。
🙅 bad
/companies/:company_id/survys/:survey_id/foos/:foo_id
🙆 good
/foos/:foo_id?companyId=:company_id&surveyId=:survey_id
REST原則に外れる設計パターン
REST原則に従うことによってアプリケーションとして問題が生ずる場合があります。
下記に示すパターンに沿って設計を行って下さい。
WebAPIコールのN+1問題
問題
複数のリソースで構成されたリソースの一覧を取得する場合、単純にRESTらしい設計を行うとN+1問題が発生します。
下記に例を示します。
前提
- 画面表示対象の回答者は100人いる
- 回答者として表示する情報は回答数、ユーザー名、性別、生年月日
- 用意されているリソースは下記の2つ
- 回答者リソース
- Endpoint:
/answers - 回答数とユーザーIDを保持する
- Endpoint:
- ユーザーリソース
- Endpoint:
/users - ユーザー名、性別、生年月日を保持する
- Endpoint:
- 回答者リソース
制御フロー
- 回答者リソースを全件(100件)取得する
-
/answersのAPIコール数:1回
-
- 回答者に紐づくユーザーリソースを取得する
-
/users/:idのAPIコール数:100回
-
😱回答者の数だけAPIコールが発生しクライアント側のパフォーマンスやサーバー負荷の問題が発生しうる!!
設計パターン
本問題に対する設計パターンは2つあり、それぞれの状況によって使い分けて下さい。
パターンA: リソースの検索条件として複数のIDを指定できるようにする
対象のリソースのEndpointのフィルタ条件として複数のIDを指定できるように設計します。
これにより複数のリソースで構成された情報を取得する際のAPIコール回数がリソースの種別数分に抑えることができます。
先の例ではユーザーリソースのフィルタ条件に配列型のIDを定義できるようにします。
- 回答者リソースを全件(100件)取得する
-
/answersのAPIコール数:1回
-
- 回答者に紐づくユーザーリソースを取得する
-
/users?id[]=1&id[]=2&id[]=3....のAPIコール数:1回
-
😀合計2回のAPIコールで済みました。
基本的にはパターンBよりパターンAを優先します。
パターンB: リソースに異なるリソースを含める
REST原則に違反する形にはなりますが、リソースに異なるリソースを含めます。
これにより複数のリソースで構成された情報を1度のAPIコールで取得することができます。
先の例では回答者のリソースにユーザーのリソースを含めるように拡張します。
{
"meta": null
"data": [
{
"id": 1,
"answerCount": 50,
"user": {
"id": 1,
"name": "foo",
"gender": 1,
"birthDate": "1994-07-30T00:00:00.000+0900"
}
},
{
"id": 2,
"answerCount": 45,
"user": {
"id": 2,
"name": "bar",
"gender": 0,
"birthDate": "1974-10-02T00:00:00.000+0900"
}
},
...
]
}
パターンAとの使い分けの観点としては、このリソースが拡張した異なるリソースとともに複数個所でよく使われるのかどうかになります。
よく使われる場合はパターンAよりパターンBを採用した方が良いでしょう。
そうでなければ、拡張したリソースは多くのケースで余計な情報になるためパターンAを採用すべきでしょう。
また、本パターンを採用する場合、拡張するリソースが3種類以上、及び3階層以上にならないようにして下さい。
🙅 Bad
{
"meta": null
"data": [
{
"id": 1,
"answerCount": 50,
"user": {
"id": 1,
"name": "foo",
"gender": 1,
"birthDate": "1994-07-30T00:00:00.000+0900",
"company": { // 🙆 2階層目のリソース
"id": 100,
"name": "bar",
"address": { // 🙅 3階層目のリソース
"id": 30,
"location": "東京都中央区銀座6丁目10-1"
}
}
},
"answerdQuestion": [{ // 🙅 3種類以上のリソース
"no": 1,
"title": "第一問 あなたの性別は?",
"answer": 1
}]
},
...
]
}
🙆 good
パターンAを使用し複数のリソースを複数回のAPIコールで取得する、もしくは画面に最適化した専用のリソースとして新たに定義しましょう。
最後に
紹介したガイドラインを適用した本格運用をまだ始めたばかりで、今後足り無い部分や余計な部分など色々な問題が出て来ると思います。
しかしこの点に関しては心配はしていません。
ガイドラインはシステムの改変、チームの成長、文化の変化などにより成長していく生き物のようなものです。
チームでこのガイドラインを放置せず大切に育て行くことにこそ意義があります。
ということでレビューをしてくれた全ての開発メンバーの皆様ありがとうございました!!
一緒にガイドラインを大切に育てて行きましょう!!😀
最後の最後に
組織改善にご興味のある方は全ての組織がこれで変わるモチベーションクラウドを是非ご検討して頂ければと思います!!
�フロントエンドAPIモック�導入でビルド時間が爆速になった
フロントエンドAPIモック導入したことでビルド時間が爆速になった
おはようございます、モチベーションクラウドの開発に参画している@sinpaoutです。
TL; DR
Docker + Rails + Mysql + webpackerで起動するのが時間かかりすぎるので
全てを捨ててnodeのみ(webpack-dev-server)で生きていくことに。。。
環境
Rails + Mysql + webpacker(vue.jsビルド)がDockerイメージとして管理され、
コマンド一発で開発環境を起動できる。
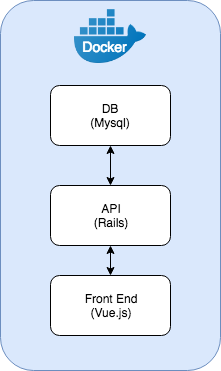
問題
起動にdb:setup や db:migrate などDBの初期化が走り大体3〜5分前後かかる。
更に画面が起動後にWebpackerが走り、フロントのビルドは1分ちょい。
DBの処理化なしでマイグレーションのみでもRailsが立上がるまで2,3分かかってしまう。
普段はJSのビルド時間も入れると5分はかかってしまう。
立上がったあとは毎回ログインして目的の画面に進むが途中で何かしらエラーに直面して進めなくなることはよくある。
また、 Seeds データが全てのパターンきちんと用意さていない事が多く
目的の画面まで到達するのにかなりの時間と労力がかかってしまう。
ときにはDockerが壊れて丸一日をクジラのお世話に費やされてしまうエンジニアもいた。
Seedsデータを用意できても更新系やデータのありなしなどの
パターンはDBを直接触る必要が出てき来たりするので手間がかかるので
APIモックシステムの構築を検討することになった。
APIモックとは
APIをJSONファイルとしてwebpack-dev-serverなど簡易Webサーバで提供する仕組み
Railsなどのバックエンドを起動しないため高速に開発環境を起動可能
バックエンドの関係者たちを退場させる:
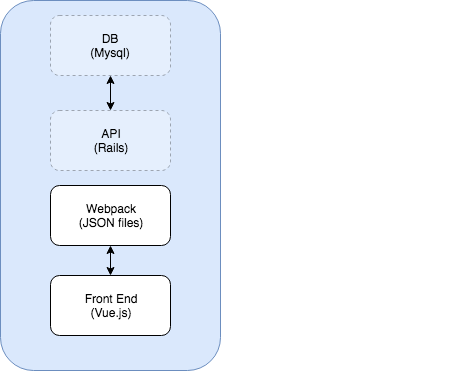
Nodeは今どきnvmなど入れとけばバージョン管理も楽なのでDockerも退場。
(みんな今まで頑張ってくれてありがとう。。。)
アプリのAPIパスとJSONファイルのマッピングはyamlファイルで定義し
axiosのintercepeterでアドレスを変換する
使ってみる
マッピングの設定:
# js/mocks/apiMapper.yml
default:
desc: デフォルトのモック
api:
/users: mocks/users.json
/users/1/: mocks/users/detail.json
users.json の中身
{
"users": [{
"id": "",
"name": "",
}]
}
上記の例は
/users のAPIをmocks/users.json に
/users/1/ のAPIを mocks/users/detail.json
に置き変える。
※ パスのidの部分は全て1として解釈するようにする。
APIをJSONファイルと関連付けてくれる人
API mocker 役割
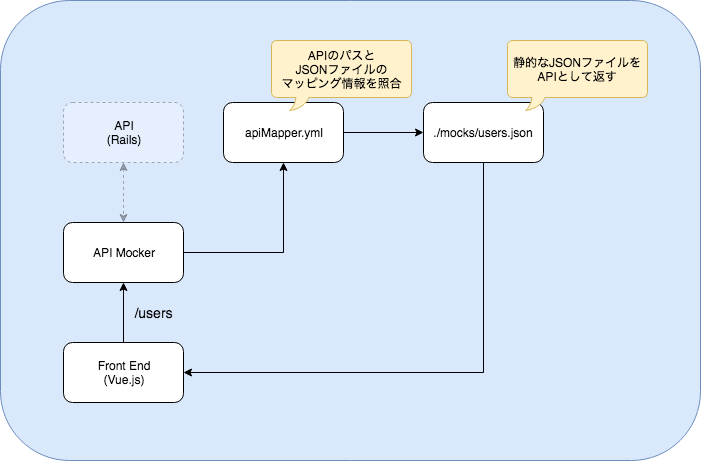
API Mockerの詳細
// js/mocks/apiMocker.js
import urlParse from 'url-parse'
import apiMapper from './apiMapper.yml'
const defaultApi = apiMappers.default.api
global.apiMockIntercepter = (config) => {
const originalUrl = config.url
const parsedUrl = urlParse(config.url)
let apiPath = parsedUrl.pathname.replace(new RegExp(`^${config.baseURL}`), '')
// idをすべて1に置き換える
apiPath = apiPath.replace(/\/([0-9]+)\//ig, '/1/')
const mockApiPath = defaultApi[apiPath]
if (mockApiPath) {
// 強制的にGETに
config.method = 'get'
config.url = config.baseURL + mockApiPath
// 元情報を書き出す
console.info('api mocked', originalUrl, mockApiPath)
}
return config
}
※ 環境に合わせてパスを調整する必要がある。
Webpackの設定
普段は index のみバンドルするが、実行環境がlocalの時のみ apiMockerを挿入する。
apiMocker が index より前に挿入する必要がある。
CopyWebpackPlugin:
モックのJSONファイルをoutputパスにコピーさせる
// webpack.local.js
if (process.env.DEV_ENV === 'local') {
...
// Inject api mocker
webpackConfig.entry.index = [
`${dir.mocks}/apiMocker.js`,
`${dir.js}/index.js`
]
webpackConfig.plugins.push(new CopyWebpackPlugin([{
from: `${dir.mocks}/api/`,
to: `${output.path}/api/`
}]))
...
}
axiosの設定
実行環境がlocalの時かつ apiMockIntercepter が存在したら使うようにする
axios.interceptors.request.use((config) => {
if (process.env.DEV_ENV === 'local' && global.apiMockIntercepter) {
return global.apiMockInterceptor(config)
}
return config
})
モックマッピングの拡張
パターンごとに切り替えられるようにする。
# js/mocks/apiMapper.yml
default: &default
desc:
api: &api
/users: /users.json
/users/1/: /users/detail.json
...
noData:
<<: *default
api:
<<: *api
/users: /users_no_data.json
noData のパターンでは /users をデータなしに置き換える
users_no_data.json
{
"users": []
}
一捻り
Devtoolのネットワークでデバッグ
元のAPIやPOST場合は中身がリクエストの中身がわからなくなるので
console で元の情報を表示するように apiMocker を更新
// js/mocks/apiMocker.js
global.apiMockIntercepter = (config) => {
const originalUrl = config.url
...
if (mockApiPath) {
...
// 元情報を書き出す
console.info('api mocked', originalUrl, mockApiPath)
}
return config
}
UIからの置き換え
開発時に直接モックを切替変えられると、より効率上がるので
画面の右上あたりにパターン一覧を置き換えるポップアップ的なものを実装。
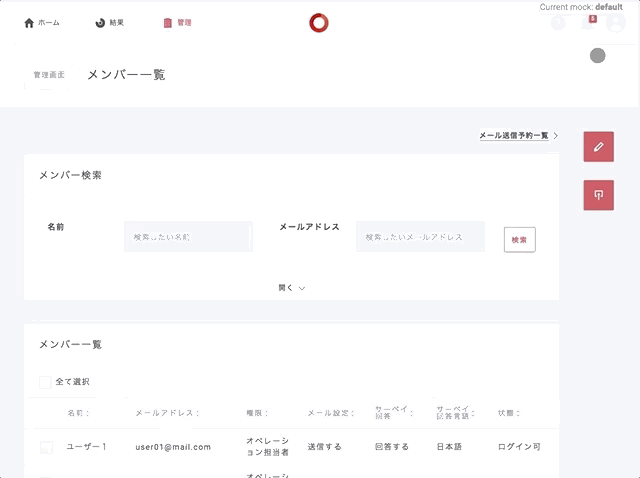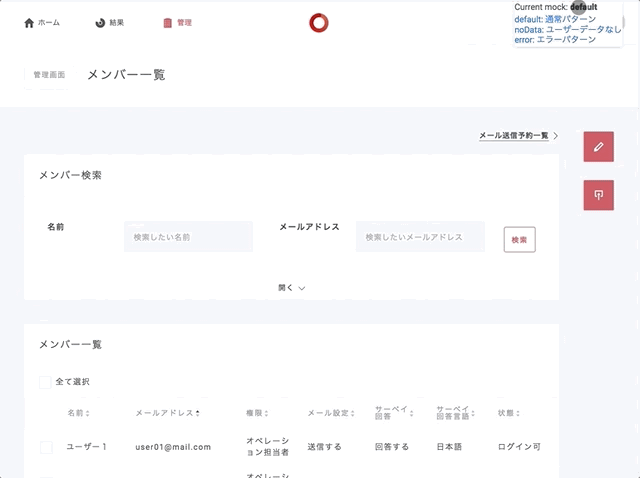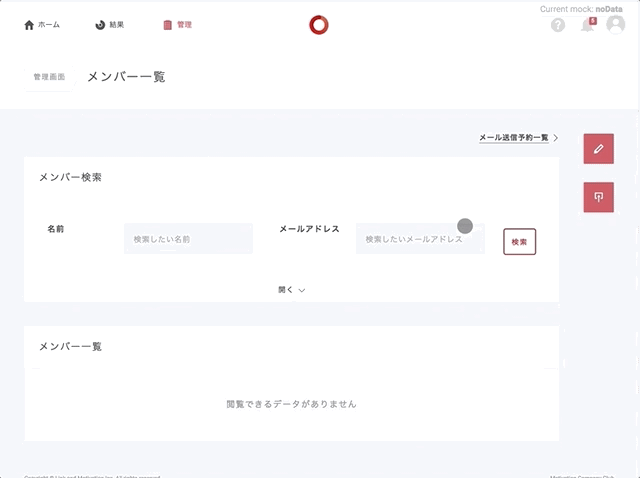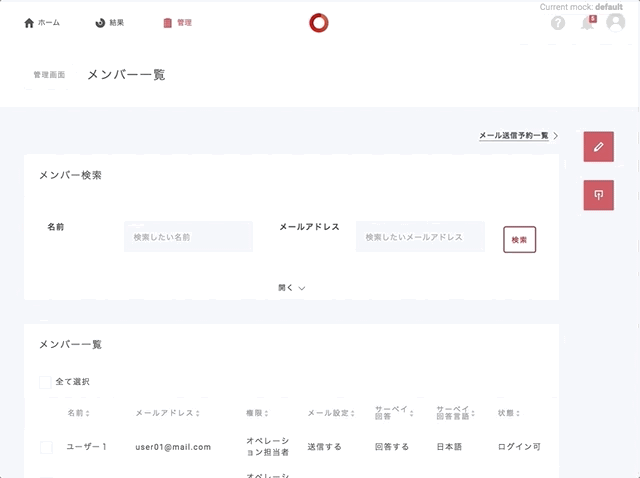
ブラウザーのリロード後もモックの設定を有効にしたいのでsessionStorageに突っ込む。
cookieを使わない理由はhttpOnlyなどを考慮したため。
E2E用
Cypressなどからパターンを変えられるように apiMocker を更新
// js/mocks/apiMocker.js
const apiMocker = {
currentPattern: sessionStorage.getItem('apiMockerPattern') || 'default'
}
// E2Eようの外部モジュールから参照できるようにグローバル変数にしておく
window.apiMocker = apiMocker
...
// モックパターンをセットする関数を用意
apiMocker.setCurrentMock = function (patternName) {
apiMocker.currentPattern = patternName
sessionStorage.setItem('apiMockerPattern', apiMocker.currentPattern)
}
global.apiMockIntercepter = (config) => {
...
const apiMap = apiMappers[apiMocker.currentPattern].api
const mockApiPath = apiMap[apiPath]
...
}
Cypressから使う
cy.window().then((win) => {
win.apiMocker.setCurrentMock('noData')
cy.visit('localhost:8081/company/1/users')
})
結果
- 開発環境の立ち上げ5分 → 1分ちょい
- パターンごとにのデータの用意がjsonファイルのみで完結(ストレス激減)
- Dockerの死亡やSeed不足の悩みから開放
- E2Eからのパターンが切替えられるようになるためUIテストが書きやすい
- DirやPOなどのエンジニア以外への画面共有が楽
今後の追加機能
- Webpackerのビルド廃止(Railsと完全に縁を切る)
- Railsは嫌いではない(むしろ好き)がやりすぎると制御しづらくなるの要注意。
- POSTなどの更新系API対応
- 4xx、5xx系のエラー対応
- webpackのバージョンアップやチューニング
- プルリクエスト単位でのレビュー環境の用意
- 静的なファイルで再現できるためS3にビルド結果を展開が可能
Cypressを使ったインテグレーションテストの導入
Cypressの導入
おはようございます、モチベーションクラウドの開発に参画している@sinpaoutです。
TL; DR
フロントエンドの機能動作を担保するためCypressを導入しインテグレーションテスト機構を構築した。
Cypressの導入、使い方、工夫、運用方法について記述する。

経緯
新機能を開発していると、ある日「手を止めて負債を解消しようぜ」という天命が下って希望の日差しが見えた。
みんなで負債リストを書き出し、優先順位づけしてリファクタリングを行う準備をした。
そこでリファクタリングの動作確認に自動テストの導入が必須であることに気づきCypressを使ったインテグレーションを導入することに至った。
インテグレーションテストとは
ユニットテストを増やすと勝手に品質が上がるという話をよく聞くが
書くことが多く短時間で品質を担保するためには不向き。
しかし、E2E全機能を全ブラウザーでテストもできないので
Chromeのみで基本動線を担保するレベルのものにすることになった。

環境
Rails、Vue+Vuex、SPA。
一部coffee+erbも残っているが今回はSPAだけを対象にする。
Cypress
先ず動かして感覚をつかめる
https://docs.cypress.io/guides/getting-started/writing-your-first-test.html#Add-a-test-file
実際のテスト
シナリオ1
- データが存在する場合ユーザー一覧が表示されること
- データなしのメッセージが表示されないこと
cy.get('.users tbody tr').should('to.have.length.gt', 0)
cy.get('.empty-msg').should('not.exist')
基本的にDOMの特定はcy.getを使いjqueryのセレクターがサポートされている。
アサーションはshould関数をしよう。
シナリオ2
- 一覧のデータをクリックすることで詳細ページへ遷移できること
- 表示されたページが詳細ページであること
- パンくずの一つ前をクリックで元の一覧画面に戻ること
import url from 'url'
cy.get('.users tbody tr').eq(0).click()
cy.url().should(pageUrl => {
const parsedUrl = url.parse(pageUrl)
// urlが正しいこと
expect(parsedUrl.pathname.match(/\/user\/[0-9]+/)).to.ok
})
※ SPAのURLの検証はパターンのみ検証するため正規表現を使う
Page Object Pattern
各テストでDOMを直接参照しているとDOMの変更があった場合の修正範囲が広がる。
別の画面の機能を呼び出したい時にページのDOM構成を調べる必要がある。
上記の問題を解決するためPage Object Patternを導入する。
先ず共通的なPage Objectを追加。
- ページを意識しない共通的な機能を実装
import url from 'url'
const PAGE_URLS = {
companies: '/companies/?',
users: '/companies/[0-9]+/users/?',
users: '/companies/[0-9]+/users/[0-9]+/?'
}
export default class PageObject {
reload () {
cy.reload()
}
breadcrumb () {
return cy.get('.breadcrumbs')
}
breadcrumbs () {
return cy.get('.breadcrumbs-list > li')
}
// 現在のページのURLをチェック
isPageOf (pageName) {
cy.url().should(pageUrl => {
if (!PAGE_URLS[pageName]) {
throw new Error(`Page url regex not found for pageName: ${pageName}`)
}
const pathReg = new RegExp(PAGE_URLS[pageName])
const parsedUrl = url.parse(pageUrl)
expect(parsedUrl.pathname.match(pathReg)).to.ok
})
}
}
各ページのPage Objectが共通を継承し、該当ページの機能を実装。
import CommonPageObject from '../../common/PageObject'
const URL = '/users'
export default class UsersPageObject extends CommonPageObject {
visit () {
cy.visit(URL)
}
// 検索エリアを開く
expandSearchArea () {
cy.get('.users .fieldset').then($elements => {
if ($elements.length <= 2) {
cy.get('.users .expand-button').click()
}
})
}
// 検索ボタンの押下
search () {
cy.get('.users .actions button').click()
}
getUserRows () {
return cy.get('.user-list tbody tr')
}
emptyMessage () {
return cy.get('.empty-data')
}
}
シナリオ3
- リクエストの中身を検証する
共通PageObjectに関数を追加。
// PageObject.js
spyApiModule () {
cy.window().its('axios').then((module) => {
cy.spy(module, 'get')
cy.spy(module, 'post')
cy.spy(module, 'put')
cy.spy(module, 'delete')
})
}
getSpiedApiModule () {
return cy.window().its('axios')
}
※ windowオブジェクトからaxiosを取得しているので
axiosがグローバル変数としてセットされている必要がある。
if (process.env.NODE_ENV === 'test') {
window.axios = axios
}
使い方
import UsersPageObject from './UsersPageObject'
const userPage = new UsersPageObject()
// 予めスパイさせる
userPage.spyApiModule()
userPage.search()
userPage.getSpiedApiModule().then((module) => {
cy.wrap(module.get).should('be.called')
const firstArgs = module.get.firstCall.args[0]
const parsedQuery = queryString.parse(url.parse(firstArgs).query)
expect(parsedQuery).eqls({
page: '1',
limit: '25',
sort: 'email',
direction: 'asc'
})
})
※ SpyモジュールはSinonが使われている。
運用
テストの記述は2段階に分けて行う。
1. 先ずテストケースだけ(describeとit)のみを記述しレビューを通す
2. それからテストの中身(DOM操作やアサーション)を記述する
テストケースとテストの中身を分けることによってレビューコストを削減ができる。
また、作業分担できるので担当者の得意な部分を依頼ができ、作業効率化が図れる。
Config
cypress.json
{
"baseUrl": "http://localhost:8081/",
"ignoreTestFiles": [
"!/**/*.spec.js"
],
"viewportWidth": 1300,
"viewportHeight": 800,
"video": false
}
integrationフォルダー配下は全てテストファイル扱いになる。
PageObejctのファイルを対象外にしたいので *.spec.js のみが対象となるようにする。
CI連携
モックサーバーが立ち上がってからCypressが走る必要あるのでCI上では工夫が必要。
先ず公式のGuideを参照し、npm scriptを工夫する。
モック
モックサーバーは基本的にDockerなどを使わずローカルでwebpack-dev-serverで起動する。
APIのモックはJSON静的なJSONファイルで提供している。
APIモックの詳細はこちらの記事 を参照。
シェルスクリプトを用意して環境変数のセットとwebpack-dev-serverの起動を行っている。
./bin/local-front-dev
運用コマンド
# モックサーバーを起動
yarn serve:local
# Cypressのtest runnerを起動(モックサーバーを立上げておく)
yarn cy:open
# ヘッドレスでテストを実行(モックサーバーを立上げておく)
yarn cy:run
# ローカルでテストを記述
yarn e2e:local
# CI上でテストを実行
yarn e2e:ci
タスクの詳細
Cypressの起動&テストタスク
"cy:open": "cypress open",
"cy:run": "cypress run",
モックサーバー起動・終了タスク
"serve:local": "./bin/local-front-dev",
"serve:local:kill": "kill $(lsof -i :8081 | grep node | awk '{print $2}')",
モックが立ち上がるのをwaitするタスク
"serve:local:wait": "wait-on http-get://localhost:8081/assets/packs/index.js",
ローカル用タスク
"e2e:local": "run-p serve:local e2e:test",
"e2e:test": "run-s serve:local:wait cy:open",
CIで用タスク(終了後プロセスを殺す)
"e2e:ci": "run-p serve:local e2e:ci:test",
"e2e:ci:test": "run-s serve:local:wait cy:run serve:local:kill",
wait-on モジュールのスターも忘れずに。
問題
ヘッドレスの場合 Electron ブラウザーしか選択肢がない。
テストケースによってヘッドレスで固まってしまうことがあるので
CIの安定した運用はまだ先になりそう。
Chromeのヘッドレスもサポートするそうで期待したい。
https://github.com/cypress-io/cypress/issues/832
感想
E2Eに特化しているサービスだけあってデバッグ機能など豊かで使いやすい。
OSSで始められて将来テストが遅くなったらお金払って並列実行などで運用してもらうことも可能。
Test runner:

Test runner のUI上でselectorやデータ型の相違などの問題が解決するので
になれることをおすすめ。
https://docs.cypress.io/guides/core-concepts/test-runner.html#Overview
おまけ
主に使われるコマンド一覧。
visit:
指定のURLへ遷移
cy.visit('http://localhost:8081/')
url:
現在のURLを取得
cy.url().should('include', '/operations/companies/1/users')
get:
DOMの取得
cy.get('.breadcrumbs-menulist > li').eq(0).click()
contains:
指定の文字列が含まれている要素を取得
cy.contains('メンバー設定').click()
eq:
複数要素取れた場合指定インデックスで取得
cy.get('.users-actions button').eq(1).should('be.visible')
find:
小要素から検索
cy.get('.users-conditions .users-field')
.find('input[type=text]')
.should('have.value', '田中')
children:
小要素一覧を取得
cy.get('.users-conditions .users-field')
.eq(fieldIndex)
.find('select.form-select-target')
.should('be.visible')
.children()
.should('have.length', options.length)
click:
クリックイベントを発火
cy.get('.breadcrumbs .breadcrumbs-menulist').eq(0).find('a').click()
select:
セレクトボックスを指定した値で選択
cy.get('.users-conditions .users-field')
.find('select')
.select('3')
each:
小要素一覧を回す
wrap:
取得した要素をラップしてCypressコマンド使えるようにする
cy.get('.users-conditions .users-field')
.find('select.form-select-target')
.children()
.each(($el, index) => {
cy.wrap($el)
.should('have.value', options[index].value)
.and('have.text', options[index].text)
})
アサーション
should:
基本的なアサーションの作成機能である。
文字列として指定できるものはchainersと予備chaiはsinonの関数が使える。
https://docs.cypress.io/api/commands/should.html#Syntax
// テキストフィールドが表示されていること
cy.get('.users-conditions .users-field')
.should('be.visible')
// クラスが指定されていないこと
cy.get('.list-pager .list-pager-next')
.should('not.have.class', 'is-disabled')
// href属性が存在すること
cy.get('.users-conditions .users-link')
.should('have.attr', 'href')
// 指定数のDOMの数がヒットすること
cy.get('.users-conditions .users-item')
.should('have.length', 5)
// 指定した値が選択されていること
cy.get('.users-conditions .users-item')
.should('have.value', '3')
// 指定した文字列が入力されていること
cy.get('.users-conditions .users-item')
.should('have.text', 'user01@mail.com')
and:
shouldと合わせてAND条件を指定可能にする
cy.get('.users-conditions .users-link')
.should('have.attr', 'href')
.and('contain', '/operations/companies/1/magellan_operation_menu')
expect:
ChaiのBDDアサーション
https://docs.cypress.io/guides/references/assertions.html#Chai
// trim後の文字列の比較
expect($btn.text().trim()).eq('検索')
// checkboxが中間(未選択)状態であること
expect($el[0].indeterminate).eq(true)
リクエストの中身
server:
router関数が使用可能にするためにサーバーを起動
route:
ネットワークリクエストの振る舞いを管理
as:
ルートのリクエスト情報のエリアス、DOMでも使用可能
it('Getting users api status should be 200', () => {
cy.server()
// companies/1/users で始まるリクエストを監視
cy.route('GET', '/companies/1/users*').as('getUsers')
cy.get('.users-conditions .users-form-actions button').click()
cy.url().should('include', '?page=1&sort=email&direction=asc')
// getUsersエリアスのxhrオブジェクトからstatusを取得
cy.wait('@getUsers').its('status').should('eq', 200)
cy.visit('/operations/companies/1/users')
})
ApiモジュールのSpy
it('リクエストパラメーターにpage、sort、directionのみが含まれること', () => {
userPage.spyApiModule()
userPage.search()
userPage.getSpiedApiModule().then((module) => {
cy.wrap(module.get).should('be.called')
const firstArgs = module.get.firstCall.args[0]
const parsedQuery = queryString.parse(url.parse(firstArgs).query)
expect(parsedQuery).eqls({
page: '1',
limit: '25',
sort: 'email',
direction: 'asc'
})
})
})
小技
例:windowオブジェクトからaxiosを取得してaxios.getをスパイする
cy
.window()
.its('axios')
.as('axios')
.then((axios) => {
cy.spy(axios, 'get')
})
...
cy.get('@axios').then((axios) => {
expect(axios.get).to.be.calledOnce
})
デザイナーとStorybookをS3上で共有
デザイナーとStorybookをS3上で共有
おはようございます、モチベーションクラウドの開発に参画している@sinpaoutです。
開発の流れ
UI部品をStorybookで管理しデザイナーが部品の組合せで画面デザインを行う。
Storybook化されている部品で完結するデザインはワイヤーレベルのもので実装する。
デザインの差異などが発生したらStorybookが正解とする。
問題
- デザイナーが簡単にStorybookを閲覧できる環境がない
- 開発現場にいる場合はエンジニアのPCを覗いて閲覧するしかない
- 見ているブランチが古かったりする
- リモートの場合は見れないがどうしているのだろうか!!
解決策
- Storybookを静的にビルドしS3で展開てい共有
- 成果物はブランチ単位でビルドし、誰でも簡単に見れるようにする
S3の展開への流れ
手動で実行するshellを用意し、エンジニアが実行してアップロードする。
将来はCIと連携してPushのたびにビルドされるようにすることも可能。
ブランチ一覧のページを用意し、見ているブランチを認識できるようにする。
展開コマンド
./bin/publish-storybook.sh
詳細
aws s3 sync などのコマンドが使えるようにする。
現場では awsアカウントは開発でログインしているので aws-cli は普通に使用可能
npm-scriptsの用意
"storybook:build": "rm -rf tmp/storybook && build-storybook -c ./js/.storybook -o tmp/storybook",
バケットと同期
# bin/publish-storybook.sh
branch=$(git symbolic-ref --short HEAD)
# "/" は問題ありそうなので一旦 "_" に置き換えておく
folder=$(echo $branch | sed -e "s/[/]/_/g")
yarn storybook:build
# コンテンツはbranchesディレクトリ配下におく
aws s3 sync $STORYBOOK_PATH "s3://$S3_FOLDER/branches/$folder" \
--delete \
--acl public-read
※ acl が public-read だが後述するセキュリティーで制限している
ブランチのデータ
S3上のフォルダー一覧をbranches.txtとして書き出す。
不要な文字列を切り取る。
aws s3 ls "s3://$S3_FOLDER/branches/" | \
sed -e "s/ PRE //g" | \
sed -e 's/[ /]//g' > tmp/branches.txt
ブランチ一覧の表示用ページ
ブランチ一覧を表示するhtmlファイルもアップロード。
htmlファイルはS3にあれば動作するがgitで管理したいので毎回アップロードしておく。
htmlの中身は同じディレクトリのbranches.txt をajaxで読み込んで
一覧のリンクを表示するのみ。
aws s3 sync js/.storybook/s3 \
"s3://$S3_FOLDER" \
--exclude "*" \
--include "index.html" \
--acl public-read
Storybookの一覧
各リンクからStorybookが見れる。

セキュリティー
ACLをpublicにしているがバケットポリシーで社内からしか見れないようにIP制限する。
バケットポリシージェネレーター:
https://awspolicygen.s3.amazonaws.com/policygen.html
後始末
ビルドしたコンテンツの削除処理はS3に任せる。
バケット → 管理 → ライフサイクルルールの追加
名前とスコープ:
ライフサイクル名は分かりやすいのを入力。
prefixはバケットを除いたディレクトリのパス
my-bucket/storybook/branches の場合はstorybook/branches にする。
移行:
何もしない
有効期限:
現行バージョン をチェック
オブジェクトの現行バージョンを失効する をチェック
日数を90にする。
これでコンテンツが作成されてから90日後に消去される。
はまったポイント
S3の静的サイトホスティングのパスが分かりづらい。
htmlファイルなどのコンテンツの詳細にあるリンクは遷移できない。
バケット名 → プロパティ → Static website hosting → エンドポイント を使う必要がる。
先ず始めてみるならこれだけで十分だがSSLやドメインの設定はCloud Frontで行う。
vscodeでVue.jsを書くときに使っているプラグインとか
お疲れ様です。@dayoshixです。
ここ1年ほど仕事でvscodeを使ってVue.jsアプリを書いています。
今、vscodeに入れているプラグインの中からVue.js開発に関連していて便利だと思ったプラグインとかツールをまとめてみました。
ESLint

eslintを使用する場合は入れておきましょう。
後述するVeturを使用し単一ファイルコンポーネント(.vue)内のJSにeslintを効かせたい場合にも必要となります。
Vetur
単一ファイルコンポーネントでVue.jsを書いている場合はほぼ必須のpluginです。
これがないとシンタックスハイライトや、HTMLやJSなど文脈に合わせたコード補間などが効かないので黙って入れることになります。
色々な事ができるのでドキュメントを一通り参照することをお勧めします。
中でもSetupページにある単一コンポーネントファイル内のJSにESLintを効かせるvscodeの設定は先に紹介したESLintプラグインを入れている場合は設定しておくとeslint-plugin-vueのEssentialなルールセットでチェックしてくれるので便利です。
また、ES Moduleのパス指定でWebpackのaliasを使用している場合、通常設定ではコードジャンプが効かなくなってしまうのですが、ここで紹介されているPath mappingをやっておくとコードジャンプが効くようになるので参考にすると良いでしょう。
Bookmarks
単一ファイルコンポーネントを編集する際、コードが長くなればなるほど<template>、<script>、<style>の行ききが煩わしくなる事があります。
そういう場合に行単位でブックマークが出来てショートカットキーで移動できるこのプラグインが便利です。

Vue Peek
vscodeの標準機能である参照先のコードをその場でのぞき見できるpeekを単一ファイルコンポーネントで行えるようになります。
peekをよく使う人は入れておくと便利かもしれません。
その他
vscodeとは関係ありませんがVue.js開発に便利な物も紹介します。
Vue.js devtools
Vue.js開発を便利にするWebブラウザエクステンションで、Vue.js開発をする場合に最初に入れるべき物と言えます。
Vueコンポーネントのinspectionや状態、Vuexストアのmutationごとの状態などを参照する事が出来ます。
Vue CLI 3

Vue.jsアプリのベストプラクティスを適用したっぽいプロジェクト雛形を作成出来たり、Vue.jsのpluginやライブラリなどをアプリに組み込んで来れたり、色々できる開発補助ツールです。
これで作ったプロジェクト雛形と同等のレベルのものを一人で作るには膨大な時間と労力が必要なので特別な理由がない限り利用したいところ。
総括
まとめてみるとVue CLI 3でいい感じのプロジェクトの雛形が出来て、vscodeにVeturを入れて、ChromeにVue.js devtoolsを入れるだけで快適な開発環境を手に入れる事が出来て今Vue.jsでWebフロントエンドを始める人は恵まれているなぁと思った。😌
Vueを用いた開発プロジェクト用に「コンポーネント設計・実装ガイドライン」を作った話
はじめに
こんにちは、モチベーションクラウドの開発にフリーのエンジニアとして参画している@HayatoKamonoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」8日目の記事となります。
概要
モチベーションクラウドの開発チームでは2018年10月から改善期間と称して、開発に関するガイドラインやルール作りをはじめとする、様々な改善活動に取り組んでいます。
その改善活動の一環として作成した「コンポーネント設計・実装ガイドライン」を今回は説明を交えながらご紹介して行きたいと思います。
目次
- Componentの粒度に関して
- Container ComponentとPresentational Component
- コンポーネントの共通化に関して
- コンポーネント実装時の細かな決め事
- CSSに関して
- まとめ
Componentの粒度に関して
これまではフロントエンド開発チームの中で「どの粒度でコンポーネントを切るか?」に関して共通の方針が存在していなかったため、人によって実装するコンポーネントの粒度がバラバラでした。
ただでさえ、Vueの場合、単一ファイルコンポーネントでコンポーネント実装を行うと、どうしても1ファイル内のコードが長くなりがちなので、色々な責務を一つのコンポーネントに押し込んでしまうと、何スクロールもしないと1ファイル内のコード全体を読み通すことが出来ないようなコンポーネントが簡単に出来上がってしまいます。
実際に、そのような産物もチラホラ・・・
そこで、フロントエンド開発チームでは、「コンポーネントの粒度」に関しての方針を決め、ガイドラインに入れることにしました。
Atomic Design
コンポーネントはAtomic Designを参考にし、以下の粒度を意識して実装するという方針に決めました。
- atoms
- molecules
- organisms
- templates
- pages
とはいえ、方針だけ決めても実際に運用に乗らなければ意味がありません。
Atomic Designは「実際に運用してみると難しい」というような話は度々、ネット上の記事で見かけたり、実際に聴いたりもします。
私自身、Atomic Designを参考にしてコンポーネント実装を行なった経験が以前ありましたが、自分の経験としても、「このコンポーネントはatomsなのか、moleculesなのか?」等と判断に迷うことが度々ありました。
また、チームの中にはAtomic Designでのコンポーネント実装を経験している人もいれば、そうでない人もいたので、チームのみんなで「何がどの粒度に該当するのか?」について、サンプルコードや既存のコンポーネントをベースに認識合わせを行なうことにしました。
大事にしたこと
Atomic Designの解釈について大事にしたことは「このチームにおいて、どう解釈するか?」です。なので、チーム内のみんなが納得感を持てれば、それが他のAtomic Designを取り入れている現場の解釈と異なっていてもOKということです。
atoms
- これ以上分割出来ない最小単位の機能を持つ
- (例)formのlabel、button、inputなど
- atomは他のatomを自身の範囲内に含むこともある
molecules
- 意味のある単位でatomを組み合わせて作られた集合体
- (例) フォームのラベル、テキストボックス、ボタンを組み合わせた検索ボックス
- moleculeは他のmoleculeを自身の範囲内に含むこともある
organisms
- 意味のある単位でatom、moleculeを組み合わせて作られた集合体
- (例) ロゴ、検索ボックス、ナビゲーションリンクを組み合わせたヘッダー
- organismsは他のorganismsを自身の範囲内に含むこともある
- 必要に応じてContainer Componentを通じて、VuexのstoreやVue Routerのrouteにアクセスする
templates
- レイアウトに責務を持つ
- 特定のレイアウトを適用したいコンポーネントの中で使われる(pagesレベルのコンポーネントに限定しない)
- 多くの場合、slotsを含む
pages
- atom、molecules, organisms, templatesの集合体
- 単一のURLに対応する
- 必要に応じてContainer Componentを通じて、VuexのstoreやVue Routerのrouteにアクセスする
共通方針
また、全てのレベルのコンポーネントに共通する方針として、コンポーネント自身にCSSのpositionやコンポーネントの外側へのmarginを持たさず、コンポーネントを使う側でそれらは指定するということも共通の認識として持つようにしました。
Container ComponentとPresentational Component
Reactコミュニティーでは、Dan Abramovの「Presentational and Container Components」で有名になった「Container Component」と「Presentational Component」を分けて実装するパターンがお馴染みです。
モチベーションクラウドのフロントエンド開発チームには、私自身も含め、React経験者がチラホラおり、2018年の8月、9月頃から、Container ComponentとPresentational Componentを分けようという動きが生まれました。
しかし、React未経験の開発メンバーにしっかりとコードをもとに、Container ComponentとPresentational Componentの違いを説明・共有出来ていなかったこともあり、Container Componentの認識が人によって異なるという状況が生まれていました。
結果、Container Componentの中にPresentationに関するコードが含まれてしまったりと、結局、ContainerとPresentationalで分離されていないコンポーネントが出来上がってしまうことにもなりました。
そこで、改めて、今回の改善期間の中で作成した「コンポーネント設計・実装ガイドライン」の中に、Container ComponentとPresentational Componentの説明をサンプルコードを交えて組み入れ、再度、認識の擦り合わせを行うようにしました。
目的の共有
そもそも、Container ComponentとPresentational Componentに分けることによって、どんなメリットがあるのかすら共有出来ていなかった為、その辺も含め、ガイドラインに組み込むようにしました。
可読性・保守性の向上
データや振る舞いに関心を持つContainer Componentと、見た目に関心を持つPresentational Componentに分離することで、どこに何が書かれているかが分かりやすくなり、アプリケーションのコードの理解がしやすくなるし、既存コードに機能追加や修正を行なう際には、どこに何を追加・変更すれば良いかが分かりやすくなる。また、1ファイル内のコード量も減るため、コードの見通しも良くなる。
再利用性の向上
Container ComponentとPresentational Componentに分けることで、Presentional Componentが特定のVuex側で持っている状態に依存しなくなり、他の異なるデータソースに差し替えても使い回しが出来るようになる。また、同様にContainer Component自体も同じデータや振る舞いに関心を持つPresentational Componentに対して、使い回しが効くようになる。
テスト容易性の向上
Container ComponentとPresentational Componentを分けることで、Presentational Componentのみを簡単に単体テスト出来るようになったり、リグレッションテストが出来るようになる。
並行作業の容易性向上
Container ComponentとPresentational Componentに分けることで、一人はAPIの繋ぎこみや振る舞いに関するロジックの実装、もう一人はコンポーネントのマークアップやスタイリングを行なうというように、ファイルのコンフリクトを気にせず、並行作業がしやすくなる。
Storybookの追加容易性の向上
Container ComponentとPresentational Componentを分けることで、Vuexのモックを用意するなどせずに、簡単にStorybookにコンポーネントを追加することが出来るようになる。
Presentational Component
特徴
- 見た目に責務を持つ
- VuexのstoreやVue Routerのrouteなどのアプリケーションの状態に依存せず、他のVueアプリケーションにも流用できる。
- 必要なデータがどのように読み込まれるか、また、どのように変更されるかを指定しない
- コンポーネント自身の状態は滅多に持たない。(仮に状態を持つとしても、それはUIに関する状態のみ)
状態を持たせない
Presentational Componentは親からpropsを通して、必要なデータを受け取り、自身を描画するだけのものです。本来のPresentational Componentの特徴としては、UIに関する状態であれば、その状態を持っても良いとあります。
しかし、私たちのチームで別途、作成したVuexのガイドラインでは「パフォーマンスに影響があるなどの特別な理由がない限り、全ての状態をVuexに寄せる」という方針があるため、Presentational Componentが状態を持つことはありません。
仮にVuex側で状態を持たせない方が良い場合は、後述するContainer Component側に持たせます。
サンプルコード
<template>
<div>
<h1 v-if="isOpen">Hello World</h1>
<p>{{ message }}</p>
<button @click="handleClick">toggle</button>
</div>
</template>
<script>
export default {
name: "HelloWorld",
props: {
message: {
type: String,
default: "I am not controlled"
},
isOpen: {
type: Boolean,
default: false
}
},
methods: {
handleClick() {
this.$emit("click");
}
}
};
</script>
Functional Component
いわゆる、Leaf Componentと呼ばれるコンポーネントのように、ループ処理の中で同じコンポーネントが描画されるような場合には、Functional ComponentとしてPresentational Componentを実装することも検討します。
Functional Componentは単なる関数でインスタンスを持たないため、描画コストを少なく抑えることが可能です。
Container Component
特徴
- データや振る舞いに責務を持つ
- データや振る舞いをPresentational Componentや他のContainer Componentに提供する
- VuexのstoreやVue Routerのrouteを参照しても良い(しなくても良い)
- 通常、DOMのマークアップやCSSスタイルを持たない。(仮にDOMを持つとしても、それはラッパー用のdivタグなど)
サンプルコード
// Presentational Component
import SamplePage from "./SamplePage.vue";
/*
以下の`connect`は、Presentational Componentを引数に取り、そのコンポーネントが関心を持つ、
VuexのmoduleのデータとVue Routerのメソッドへのアクセスを与えたContainer Componentを返す高階関数
*/
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
computed: {
count() {
return this.$store.state.count;
}
},
methods: {
handlePageChange({ to }) {
this.$router.push(to);
}
},
render(createElement) {
return createElement(WrappedComponent, {
props: {
count: this.count
},
on: {
pageChange: this.onChangePage
}
});
}
};
};
/*
次の2行は以下のコードをContainerの説明の為に、より明示的にしたもの
export default connect(SamplePage);
*/
const SamplePageContainer = connect(SamplePage);
export default SamplePageContainer;
export { SamplePage };
コンポーネントの共通化に関して
現状、フロントエンド開発チームが抱える1つの課題として、似たようなコンポーネントが複数存在していたり、同じような処理が複数のコンポーネントに散らばっていたりする状況が多々あるというものです。
この状態に至った背景としては、開発の進め方や開発者同士の連携不足に原因があったり、コンポーネント分割やコンポーネント共通化に関する考え方・方法に対する理解不足に原因があるようでしたが、今回作成した「コンポーネント実装・設計ガイドライン」では、共通化の方法論について実際にサンプルコードをもとに共有・認識の擦り合わせを行なうようにしました。
共通化の手法
共通化を実現する方法としては、「継承」であったり、Vueの「Mixin」がありますが、継承は親と子が密結合な関係になってしまいますし、「Mixin」もまた暗黙の依存関係が生まれてしまいます。(※Reactも以前はMixinをサポートしていましたが、Mixinは暗黙の依存関係を生むため廃止しています。)
そのため、Reactコミュニティーではお馴染みのHigher Order Componentを用いたり、Reactコミュニティーで用いられるRender PropsやRender Childrenパターンと同様のことを実現するVueのScoped Slotsを用いて、データや振る舞いの共通化を行います。
ここでは、Higher Order ComponentとScoped Slotsを用いてContainer Componentを実装する簡易的な例を掲載します。
Higher Order Componentを用いた例
以下は、仮にクライアント側で認証を行うSPAであると仮定した場合に必要になりそうな、クライアント認証用のロジックやデータを提供するHigher Order Componentの例です。
Higher Order Componentは引数にComponentを取り、別のComponentを返す高階関数です。
Higher Order Component側
const requireAuth = WrappedComponent => {
return {
name: `${WrappedComponent.name}-protected`,
computed: {
isAuthenticated() {
return this.$store.state.isAuthenticated;
}
},
created() {
// JWTトークンが存在、または、失効しているかどうかをチェック
// トークンが無い、または、失効していたらログインページへリダイレクト
},
render(createElement) {
return createElement(WrappedComponent, {
props: {
isAuthenticated: this.isAuthenticated
}
});
}
};
};
export default requireAuth;
使う側の例
// router.js
export default new Router({
mode: "history",
base: process.env.BASE_URL,
routes: [
{
path: "/",
name: "home",
component: requireAuth(HomePage)
},
{
path: "/about",
name: "about",
component: requireAuth(AboutPage)
}
]
});
Scoped Slotsを用いた例
以下は、マウスの位置情報を提供するContainer Componentの例です。
Container Component側
export default {
name: "MouseMoveTracker",
data() {
return {
mousePosition: {
x: 0,
y: 0
}
};
},
methods: {
handleMouseMove({ clientX, clientY }) {
this.mousePosition.x = clientX;
this.mousePosition.y = clientY;
}
},
mounted() {
this.$refs.wrapper.addEventListener("mousemove", this.onMouseMove);
},
beforeDestroy() {
this.$refs.wrapper.removeEventListener("mousemove", this.onMouseMove);
},
render(createElement) {
return createElement(
"div",
{
ref: "wrapper"
},
[
this.$scopedSlots.default({
mousePosition: this.mousePosition
})
]
);
}
};
使う側
<template>
<div id="app">
<MouseMoveTrakcer>
<template slot-scope="{ mousePosition }">
<SampleComponent :position="mousePosition" />
</template>
</MouseMoveTrakcer>
</div>
</template>
<script>
import SampleComponent from "./components/SampleComponent";
import MouseMoveTrakcer from "./components/trackMouseMove";
export default {
name: "App",
components: {
SampleComponent,
MouseMoveTrakcer
}
};
</script>
Container Componentにラップされる側
※ マウスの位置情報に関心があるコンポーネントであると仮定。
<template>
<div>
<p>X: {{ position.x }}</p>
<p>Y: {{ position.y }}</p>
</div>
</template>
<script>
export default {
name: "SampleComponent",
props: {
position: {
type: Object,
required: true
}
}
};
</script>
コンポーネント実装時の細かな決め事
他にも命名規則やデータ型毎の初期値など、コンポーネント実装時のルールとして定めました。
また、これまでは「JavaScript Standard Style」を適用するESLintプラグインは導入していましたが、Vue用のESLintプラグインは導入していなかったため、まずは、ルールが緩め目の「vue/essensial」を導入し、自分たちでガイドラインを決めなくても良いものに関しては、VueのESLintプラグインが提供してくれるルールに乗っかることにしました。
イベントハンドラーとイベント名の命名規則
これまで特にイベントハンドラーやイベント名にルールがなかったため、例えば、人によってはイベントハンドラー名をhandleXXXのようにhandleで始めたり、onXXXのようにonで始めたりと、名前の付け方がバラバラでした。
そのため、一貫性を持たせコードの見通しを良くするためにも、以下のように命名規則の基本方針を固めました。
イベントハンドラー名
イベントハンドラー名はhandleCancelのようにhandleで始めます。 また、イベントが発生した対象をイベントハンドラ名に含める必要がある場合は、handleModalCloseのように、「on + 名詞 + 動詞」のように命名します。
methods: {
// Good
handleCancel () {
}
// Good
handleModalClose () {
}
// Good
handleKeyPress () {
}
// Good
handleMouseMove () {
}
// Bad
onCancel () {
}
// Bad
onCloseModal () {
}
// Bad
onPressKey () {
}
// Bad
onMoveMouse () {
}
}
イベント名
emitするイベント名は、命名規則に沿ったメソッド名からhandleを取り除いた文字列とします。
methods: {
handleCancel () {
this.$emit('cancel')
}
handleModalClose () {
this.$emit('modalClose')
}
handleKeyPress () {
this.$emit('keyPress')
}
handleMouseMove () {
this.$emit('mouseMove')
}
}
各データ型の初期値
コンポーネントのdataやpropsで持つデータ型の初期値に関して、個々の開発者によって認識がバラバラだったため、初期値としてより適切な値がある場合はそちらを優先することとしながら、基本的な方針として各データ型の初期値についてまとめることにしました。
| データ型 | 初期値 |
|---|---|
| Boolean | false |
| Number | null |
| String | null |
| Object | {} |
| Array | [] |
| Function | null |
| Date | null |
※ Object型の初期値を{}としている理由は、後でobjectに追加したkeyの値がリアクティブになるため
propsのガイドライン
これまで、propsの定義に関しては最低限、propの型の指定はされていましたが、人によって、必須のpropにrequired: trueの指定がされていなかったり、default値の指定がされていなかったりと緩い状態になっていたため、VueのESLint Pluginでチェックが走るものもありますが、以下のように方針を固めました。
必須のpropsにはrequiredをtrueにする
props: {
name: {
type: String,
required: true
}
}
任意のpropsにはdefaultを設定する
props: {
isOpen: {
type: Boolean,
default: false
}
}
データ型を指定する
props: {
name: {
type: String
},
count: {
type: Number
},
isOpen: {
type: Boolean
},
item: {
type: Object
},
mode: {
type: String
},
selectedIds: {
type: Array
},
date: {
type: Date
},
customFunction: {
type: Function
}
}
propsの検証
propsで受け取る値が特定の条件に当てはまる場合は、propsの値にバリデーションを適用します。
以下はバリデーションの一例です。
props: {
name: {
type: String,
validator (value) {
return value.length > 0
}
},
count: {
type: Number,
validator (value) {
return value >= 0
}
},
item: {
type: Object,
validator (obj) {
const EXPECTED_KEY = 0
const EXPECTED_VALUE_TYPE = 1
const expectedPairs = [
['name', 'string'],
['count', 'number']
]
const pairs = Object.entries(obj);
return pairs.every(([KEY, VALUE], index) => {
return KEY === expectedPairs[index][EXPECTED_KEY] && typeof VALUE === expectedPairs[index][EXPECTED_VALUE_TYPE]
})
}
},
mode: {
type: String,
validator (value) {
const modes = ['easy', 'difficult']
return modes.includes(value)
}
},
selectedIds: {
type: Array,
validate (values) {
return values.every(value => typeof value === 'string')
}
},
date: {
type: Date,
validate (value) {
return value >= new Date(2000, 01, 01)
}
}
}
CSSに関して
前提として、モチベーションクラウドのフロントエンド開発においては、styled-componentsのようなCSS-in-JSは使っておらず、Scoped CSSの環境下でSassを利用し、CSSを書いています。
Scopeが切られた環境ということもあり、フロントエンド開発チームにはBEM記法は行わず、また、他に細かなルールを決めるということもしておらず、個々の開発者にCSSの書き方は委ねるといったスタンスでおりました。
一応、クラス名はclass-nameのようにハイフンで区切ったケバブケースにするという簡単な決まり事はありましたが、やはり、これだけでは、次第に辛いところが出てきました。
そのため、追加で「最低限、これだけは守ろう!」といった方針をガイドラインに組み込むことにしました。
要素型セレクターは使わない
pやulなど、要素セレクターは使用しません。代わりにclassセレクターを使用します。
BAD
<template>
<div class="sample-component">
<div>
<p>Hello World</p>
</div>
</div>
</template>
<style lang="scss" scoped>
div {
...プロパティを定義
& > p {
...プロパティを定義
}
}
</style>
GOOD
<template>
<div class="sample-component">
<div class="box">
<p class="message">Hello World</p>
</div>
</div>
</template>
<style lang="scss" scoped>
.box {
...プロパティを定義
& > .message {
...プロパティを定義
}
}
</style>
ケバブケースのクラス名を&や変数展開で繋がない
ケバブケースのクラス名を&や#{}を用いた変数展開で繋ぐと検索性や可読性を損ねるため、これらをクラス名の連結を目的として使用しません。
BAD
<template>
<div class="sample-component">
<div class="box">
<p class="box-description is-large">
<span class="box-warning>"Alert Message</span>
</p>
</div>
<ul class="product-list">
<li class="product-list-item">A</li>
<li class="product-list-item">B</li>
<li class="product-list-item">C</li>
</ul>
</div>
</template>
<style lang="scss" scoped>
.box {
$box: #{&};
...プロパティを定義
&-description {
...プロパティを定義
&.is-large {
...プロパティを定義
#{$box}-warning {
...プロパティを定義
}
}
}
}
.product-list {
...プロパティを定義
&-item {
...プロパティを定義
}
}
</style>
GOOD
<template>
<div class="sample-component">
<div class="box">
<p class="description is-large">
<span class="warning>"Alert Message</span>
</p>
</div>
<ul class="product-list">
<li class="item">A</li>
<li class="item">B</li>
<li class="item">C</li>
</ul>
</div>
</template>
<style lang="scss" scoped>
.box {
...プロパティを定義
.description {
...プロパティを定義
&.is-large {
...プロパティを定義
.box-warning {
...プロパティを定義
}
}
}
}
.product-list {
...プロパティを定義
.item {
...プロパティを定義
}
}
</style>
まとめ
今回作成した「コンポーネント設計・実装ガイドライン」には、この記事の中では触れていないものもありますが、主要な部分に関しては共有出来たと思います。
ガイドラインは実際に運用出来ないと意味がないので、今後、新たにコードを書く際、既存のコードをリファクタリングする際、コードレビューを行なう際に、こちらのガイドラインで決めたことを適用して行きたいと思います。
また、ガイドラインは育てていくものでもあるので、実際に運用に乗せながら、試行錯誤をしつつ、必要に応じて追加・修正を行なって行きたいと思います。
関連記事
こちらの記事はモチベーションクラウド Advent Calendar 2018に投稿した記事です。
他にも、以下の記事をモチベーションクラウド Advent Calendar 2018に投稿しています。
- Vueを用いた開発プロジェクト用にカスタムジェネレーターを作ってみる
- Vueを用いた開発プロジェクト用に「コンポーネント設計・実装ガイドライン」を作った話
- Vuexを用いた開発プロジェクト用にガイドラインを作成した話
Vuexを用いた開発プロジェクト用にガイドラインを作成した話
はじめに
こんにちは、モチベーションクラウドの開発にフリーのエンジニアとして参画している@HayatoKamonoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」9日目の記事となります。
概要
モチベーションクラウドの開発チームでは2018年10月から改善期間と称して、開発に関するガイドラインやルール作りをはじめとする、様々な改善活動に取り組んでいます。
私が所属しているフロントエンド開発チームでは、すでに別記事でご紹介している「WebAPI設計ガイドライン」であったり、「コンポーネント設計・実装ガイドライン」を作成しました。
他にも作成したガイドラインはありますが、今回はモチベーションクラウドのフロントエンド開発で「状態管理パターン + ライブラリ」として導入しているVuexの利用に関するチーム内のガイドラインをサンプルコードや説明を交えながらご紹介出来ればと思います。
目次
- Storeの構造について
- 原則としてVuexで全ての状態を管理する
- Vuexのヘルパー関数を利用する
- ComponentからStoreのcommitを実行しない
- module間の依存関係を作らない
- moduleのactionをグローバルに登録しない
Storeの構造について
全モジュールにおいてnamespaceを切る
const modules = {
namespaced: true,
modules: {
moduleA: {
namespaced: true,
// 略
},
moduleB: {
namespaced: true,
// 略
}
}
}
元々、モチベーションクラウドのフロントエンドアプリケーションではVuexのnamespaceは切っておりませんでした。
そのため、コンポーネント側からVuexのStore側にdispatchするイベント名の重複、衝突を防ぐために、1つのファイルでイベント名を定数管理し、それらの定数化されたイベント名をコンポーネント側やStoreのmodule側で読み込んで利用する方法を採用しておりました。
しかし、開発が進むに連れて、今後、アプリケーションの規模が更に大きくなった場合を考えると、名前空間をこのような泥臭いやり方で管理し続けるのは「辛い」、「不安」と言った声がチーム内で挙がってくるようになりました。
そこで、今回、Vuexのガイドラインを作成するにあたって、「namespaceを全モジュールで切るべきか、部分的に切るべきか?」をチーム内で議論し、意見が割れるところもありましたが、最終的には全モジュールでnamespaceを切るという方針に固まりました。
それに伴い、今後はイベント名を定数で管理し、毎回、利用する箇所で定数を読み込むといったことは辞め、イベント名を直接文字列で扱って行くことにもなりました。
実際、毎回、新たにdispatchするイベント名が登場する度に、定数管理するファイルにそのイベント用の定数を追加し、そして、その定数を利用する箇所で読み込まなければいけないという作業は冗長でストレスを伴うものであったため、この苦行から解放されるのはとても良いことだと思います。
ドメインとUIで状態を分けて管理する
Store内のmoduleをまず、ドメインに関する状態を管理するmoduleと、UIに関する状態を管理するmoduleで大きく2つに分けることにしました。
そして、それら2つのmodule下に更に付随するmoduleを展開していくといったmoduleの管理方法です。
サンプルコード
const modules = {
namespaced: true,
modules: {
domain: {
namespaced: true,
modules: {
users: {
// 略
},
organizations: {
// 略
},
}
},
ui: {
namespaced: true,
modules: {
common: {
// 略
},
operations: {
// 略
}
}
}
}
}
APIを通してサーバーサイドから取得するデータは必要に応じて、加工や正規化をして、domain以下のモジュールでそれぞれ管理します。
また、breadcrumbやmodalの状態のようなページ共通で持っておくことが好ましい状態は、ui以下のcommonモジュール内で管理し、、その他のページ固有のUIに関する状態はui以下にそのページ用のモジュールを置いて、そちらで管理します。
原則としてVuexで全ての状態を管理する
これまでフロントエンド開発チームにおいて、Vuex側で管理する状態と管理しない状態についての共通の方針が存在していなかったため、各開発者によって状態を管理する場所がバラバラでした。
そこで、今回、Vuex利用に関するガイドラインを作成するにあたり、これについても、チーム内で議論しました。
普通に考えると、「ドメインに関する状態はVuexのStoreで持ち、また、ページ遷移後も保持しておきたいようなUIに関する状態をVuexのStoreで持つ」、そして、「それ以外のUIに関する状態をコンポーネント側で持つ」、というのが自然かなと思いますが、最終的にチーム内で合意に至ったのは「パフォーマンスが懸念されるなどの特別な理由がない限り、原則として全ての状態をVuexのStoreで管理する」という方針です。
この決定に至った理由としては以下が挙げられます。
- Time Travel Debuggingが可能になるため、デバッグがしやすくなる
- テストがしやすくなる
- 複数人による開発の中で状態管理に一貫性が生まれる
個人的には、このようにVuexやReduxなどの状態管理ライブラリに全ての状態を寄せるという開発は初めてなので、やってみないと分からないところもありますが、実際に運用していくうちに「パフォーマンスの懸念」以外の理由で他にも、コンポーネント側で状態を持たせた方が良いケースが出てくるかもしれません。
その際は随時、チーム内で議論して、柔軟にガイドラインに調整をかけて行ければ良いと思っています。
dispatchするaction payloadの型
Storeのdispatchメソッドの第2引数に渡す値の型に関しても、今回のガイドライン作成を機に以下のように方針を固めました。
interface ActionPayload = {
payload?: any,
meta?: object,
error?: boolean
}
元々、私自身がReact、Reduxを用いた開発の際には、Flux Standard Actionを取り入れているので、そのまま、Flux Standard Actionを参考にガイドラインに組み込みました。
サンプルコード
this.$store.dispatch('fetchUsers')
this.$store.dispatch('postUser', {
payload: { id: 1, name: 'foo' },
meta: { delay: 3000 }
})
this.$store.dispatch(validationFailed, {
payload: { message: 'hello' },
error: true
})
Vuexのヘルパー関数を利用する
Storeのmoduleのstateやactionを参照する方法は複数ありますが、それらを参照する際にはVuexのヘルパー関数を必ず利用するという制限を設けることにしました。
また、Vuexの各ヘルパー関数にも複数の使い方が存在しますが、それらの使い方に関しても、ガイドラインで決めた方法のみを利用するといった制限を設けることにしました。
狙いとしては、コードの一貫性を高めること、また、それによって、Vue未経験のフロントエンドエンジニアや、普段はサーバーサイドを担当している既存のメンバーがフロントエンド開発に加わるようになった時の学習コストを下げるところにあります。
createNamespacedHelpersの使用
Container ComponentでVuexのnamespaceが切られたmoduleを参照する場合は、必ず、ヘルパー関数のcreateNamespaceHelpersを使用するものとします。
import { createNamespacedHelpers } from 'vuex';
const {
mapState: mapStateOfUsers,
mapActions: mapActionsOfUsers
mapGetters: mapGettersOfUsers
} = createNamespacedHelpers('domain/users');
createNamespaceHelpersは引数に与えたmoduleのネームスペースがバインドされたVuexのヘルパー関数を返します。
命名規則
import { createNamespacedHelpers } from 'vuex';
const {
mapState: mapStateOfUsers,
mapActions: mapActionsOfUsers
mapGetters: mapGettersOfUsers
} = createNamespacedHelpers('domain/users');
const {
mapState: mapStateOfOrganizations,
mapActions: mapActionsOfOrganizations
mapGetters: mapGettersOfOrganizations
} = createNamespacedHelpers('domain/organizations');
Container Componentの中で複数のVuexのmoduleを参照することは良くあることです。
そのため、createNamespacedHelpersが返すmapState、mapActions、mapGettersには別名をつけて、名前の衝突を防ぎます。
その際の命名規則として、mapStateOfUsersのように、「ヘルバー関数名 + モジュール名」をlowerCamelCaseで名前を付けるものとします。
mapState関数の使用
import { createNamespacedHelpers } from 'vuex';
import UsersPage from './UsersPage.vue';
const {
mapState: mapStateOfUsers
} = createNamespacedHelpers('domain/users');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
computed: {
...mapStateOfUsers(['users, isLoading'])
},
render(createElement) {
return createElement(WrappedComponent);
}
};
};
export default connect(UsersPage);
export { UsersPage };
createNamespacedHelpersで返すnamespaceがバインドされたmapState関数を使用します。
参考までに、上記のコードのcomputed部分は以下と同じです。
computed: {
users: this.$store.state.domain.users.users,
isLoading: this.$store.state.domain.users.isLoading
},
mapActions関数の使用
import { createNamespacedHelpers } from 'vuex';
import UsersPage from './UsersPage.vue';
const {
mapActions: mapActionsOfUsers
} = createNamespacedHelpers('domain/users');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
created () {
this.fetchUsers()
},
methods: {
...mapActionsOfUsers(['fetchUsers', 'postUser']),
handleUserSave(payload) {
this.postUser(payload)
}
},
render(createElement) {
return createElement(WrappedComponent, {
on: {
save: handleUserSave
}
});
}
};
};
export default connect(UsersPage);
export { UsersPage };
createNamespacedHelpersで返すnamespaceがバインドされたmapActions関数を使用します。
参考までに、上記のコードのcreatedとmethods部分は以下と同じです。
created () {
this.$store.dispatch('domain/users/fetchUsers')
},
methods: {
handleUserSave(payload) {
this.$store.dispatch('domain/users/postUsers', payload)
}
}
mapGetters関数の使用
import { createNamespacedHelpers } from 'vuex';
import UsersPage from './UsersPage.vue';
const {
mapGetters: mapGettersOfUsers
} = createNamespacedHelpers('domain/users');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
computed: {
...mapGettersOfUsers(['highlyEngagedUsers', 'dormantUsers'])
},
render(createElement) {
return createElement(WrappedComponent);
}
};
};
export default connect(UsersPage);
export { UsersPage };
createNamespacedHelpersで返すnamespaceがバインドされたmapGetters関数を使用します。
参考までに、上記のコードのcomputed部分は以下と同じです。
computed: {
highlyEngagedUsers: this.$store.getters['domain/users/highlyEngagedUsers'],
dormantUsers: this.$store.getters['domain/users/dormantUsers']
}
mapMutations関数の使用禁止
Vuexのヘルパー関数にはmapMutationsというものもありますが、こちらのヘルパー関数には後述する「ComponentからStoreのcommitを実行しない」というチーム内の方針により、使用禁止としました。
Vuexへの参照はContainer Componentで行なう
別記事でご紹介した「コンポーネント設計・実装ガイドライン」の中でも触れていますが、
Vuexへの参照はPresentational Componentでは行わず、Container Componentで行ないます。
Bad
Presentational Component内でVuexのStoreを参照している例
<template>
<div class='users-page'>
<ul>
<li v-for='user in users' :key='user.id'>{{ user.name }}</li>
</ul>
</div>
</template>
<script>
import { createNamespacedHelpers } from 'vuex';
const {
mapState: mapStateOfUsers,
mapActions: mapActionsOfUsers
} = createNamespacedHelpers('domain/users');
export default {
name: 'UsersPage',
created () {
this.fetchUsers()
},
computed: {
...mapStateOfUsers(['users'])
},
methods: {
...mapActionsOfUsers(['fetchUsers'])
}
};
</script>
Good
Container Component内でVuexのStoreを参照している例
import { createNamespacedHelpers } from 'vuex';
import UsersPage from './UsersPage.vue';
const {
mapState: mapStateOfUsers,
mapActions: mapActionsOfUsers
} = createNamespacedHelpers('domain/users');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
created () {
this.fetchUsers()
},
computed: {
...mapStateOfUsers(['users'])
},
methods: {
...mapActionsOfUsers(['fetchUsers'])
},
render(createElement) {
return createElement(WrappedComponent, {
props: {
users: this.users
}
});
}
};
};
export default connect(UsersPage);
export { UsersPage };
<template>
<div class='users-page'>
<ul>
<li v-for='user in users' :key='user.id'>{{ user.name }}</li>
</ul>
</div>
</template>
<script>
export default {
name: 'UsersPage',
props: {
users: {
type: Array,
default: []
}
}
};
</script>
ComponentからStoreのcommitを実行しない
ComponentからStoreのcommitメソッドを実行しないというルールは、モチベーションクラウドの初期のフロンドエント開発メンバーによって以前決められた方針として既に存在していました。
このルールはどういったものかと言うと、ComponentからStoreのstateに変更を加える際に、例え、同期的な変更処理であったとしても、Storeのcommitメソッドは使わず、Storeのdispatchメソッドを必ず通して、Storeのstateに変更を加えるというものです。
正直、同期的に走る変更処理を行なう際に、わざわざ、dispatchメソッドを経由してから、commitメソッドを実行するというのは面倒に感じるところはあります。
しかし、以下の理由により、引き続き、今回作成したガイドラインに組み入れた方が良いということになりました。
理由

- 上記の図にあるVuexの単方向データフローに合わせるため
- Component側で通知したイベントをStore側が同期的に処理するのか、非同期的に処理するのかを知らなくても良くなるため
- Component側で常にstoreのdispatchメソッドのみを使うことで、コードに一貫性が生まれ可読性が向上するため
- 同期的処理、非同期的処理に関わらず、Component側でdispatchメソッドを通せば、storeのactionから複数のcommitメソッドをまとめて実行することも出来るため
Bad
import { createNamespacedHelpers } from 'vuex';
import UserPage from './UserPage.vue';
const {
mapMutations: mapMutationsOfUserPage,
} = createNamespacedHelpers('ui/userPage');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
methods: {
...mapMutationsOfUserPage(['clearForm']),
handleFormClear() {
this.clearForm();
}
},
render(createElement) {
return createElement(WrappedComponent, {
on: {
reset: this.handleFormClear
}
});
}
};
};
export default connect(UserPage);
export { UserPage };
Good
import { createNamespacedHelpers } from 'vuex';
import UserPage from './UserPage.vue';
const {
mapActions: mapActionsOfUserPage,
} = createNamespacedHelpers('ui/userPage');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
methods: {
...mapActionsOfUserPage(['clearForm']),
handleFormClear() {
this.clearForm();
}
},
render(createElement) {
return createElement(WrappedComponent, {
on: {
reset: this.handleFormClear
}
});
}
};
};
export default connect(UserPage);
export { UserPage };
module間の依存関係を作らない
あるmoduleから別のmoduleに対して、Storeのcommitメソッドを呼んだりしていると、コードを追いづらくなったりしますし、テスト容易性にも影響をしてきます。
そのため、module間では依存関係を作らないという制約を設けることにしました。
moduleの中でrootState、rootGettersを参照しない
Bad
modules: {
moduleA: {
namespaced: true,
getters: {
someGetterA (state, getters, rootState, rootGetters) {
return rootState.moduleB.foo
},
someGetterB (state, getters, rootState, rootGetters) {
rootGetters['moduleB/someGetterC']
}
},
actions: {
someAction ({ dispatch, commit, getters, rootGetters }) {
dispatch('someOtherAction', rootGetters.moduleB.someGetter)
},
someOtherAction (ctx, payload) { ... }
}
},
moduleB: {
namespaced: true,
state: { foo: null },
getters: {
someGetterC (state) {
return state.foo
}
}
}
}
moduleから他のmoduleに対して、dispatch、commitを実行しない
Bad
modules: {
moduleA: {
namespaced: true,
actions: {
someAction ({ dispatch, commit }) {
dispatch('moduleB/someOtherAction', null, { root: true }) // -> 'moduleB/someOtherAction'
commit('moduleB/someMutation', null, { root: true }) // -> 'moduleB/doSomethingElse'
}
}
},
moduleB: {
namespaced: true,
actions: {
someOtherAction (context, payload) { ... }
},
mutations: {
someMutation (state, payload) {...}
}
}
}
モジュール内から他のモジュールに対して、storeのdispatchやcommitを実行するのはNG。
Good
modules: {
moduleA: {
namespaced: true,
actions: {
someAction ({ dispatch, commit }) {
dispatch('someOtherAction') // -> 'moduleA/someOtherAction'
commit('someMutation') // -> 'moduleA/doSomethingElse'
},
someOtherAction({ dispatch, commit }) {...}
},
mutations: {
someMutation (state, payload) {...}
}
}
}
モジュール内から同じモジュールに対して、storeのdispatchやcommitを実行するのはOK。
モジュール内から他のモジュールにdispatchしたい場合
モジュール内から他のモジュールにdispatchしたい場合は、以下のサンプルコードのように、storeのmodule側でpromiseを返し、Container Component側でpromiseをchainします。
Store側
modules: {
moduleA: {
namespaced: true,
actions: {
someAction ({ dispatch, commit }) {
return api.fetchSomeData()
.then(response => {
return Promise.resolve(response)
})
.catch(error => {
return Promise.reject(error)
})
.finally(() => {
commit('someMutation')
})
},
},
mutations: {
someMutation (state, payload) { ... }
}
},
moduleB: {
namespaced: true,
actions: {
someOtherAction (context, payload) { ... }
}
}
}
Container Component側
import { createNamespacedHelpers } from 'vuex';
import SamplePage from './SamplePage.vue';
const {
mapActions: mapActionsOfModuleA
} = createNamespacedHelpers('moduleA');
const {
mapActions: mapActionsOfModuleB
} = createNamespacedHelpers('moduleB');
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
created () {
this.someAction()
.then((response) => this.someOtherAction())
.catch(console.error)
},
methods: {
...mapActionsOfModuleA(['someAction']),
...mapActionsOfModuleB(['someOtherAction']),
},
render(createElement) {
return createElement(WrappedComponent);
}
};
};
export default connect(UsersPage);
export { UsersPage };
moduleのactionをグローバルに登録しない
namespaceを切ったmoduleであったとしても、actionを以下のように、グローバルに登録することは可能ですが、actionをグローバルに登録することも禁止としました。
BAD
modules: {
moduleA: {
namespaced: true,
actions: {
someAction: {
root: true,
handler (namespacedContext, payload) { ... }
}
}
}
}
最後に
今回ご紹介した「Vuexの利用に関するガイドライン」には、この記事の中では触れていないものもありますが、主要な部分に関しては共有出来たと思います。
今後、こちらのガイドラインで決めたmodule構造に、既存のコードのmodule構造を変えて行く必要があります。
そのリファクタリングを安全に行えるように現在、フロントエンド開発チームでは、別記事「Cypressを使ったインテグレーションテストの導入」でも共有されている通り、Cypressによるインテグレーションテストを充実させているところです。
また、いろんなルールを決めたとしても、そらら全てをコードレビュー時にチェックするのは大変なので、独自のルールは独自のLintルールを作成して、コードレビューのコストを軽減することを検討中です。
関連記事
こちらの記事はモチベーションクラウド Advent Calendar 2018に投稿した記事です。
他にも、以下の記事をモチベーションクラウド Advent Calendar 2018に投稿しています。
- Vueを用いた開発プロジェクト用にカスタムジェネレーターを作ってみる
- Vueを用いた開発プロジェクト用に「コンポーネント設計・実装ガイドライン」を作った話
- Vuexを用いた開発プロジェクト用にガイドラインを作成した話
採用が恋愛なら、オンボーディングをしないのは釣った魚に餌をやらないということになっちゃうので整理してみた
おはようございます。@oturu333と申します。
この記事はモチベーションクラウド Advent Calendar 2018の10日目として書いています。
タイトルちょっとおふざけしましたが、本気です。
入社を決めていただいた方と会社を恋愛のステップで例えるならお付き合いの始まり。「この人となら幸せになれるかもしれない!わくわく!でもちょっと不安もあるな」という状態なのかなと思います。
そしてオンボーディングがないというのは、お付き合いの直後に恋人を放置する、残念な彼、彼女ということになってしまいます。
入社をしていただいて、恋から愛に発展していくためのファーストステップ。大事にしたいですね。
モチベーションクラウドではもともとオンボーディングをまとめた資料がなく、改善活動の一環として最近まとめはじめているところです。
今回はその内容について書いていきます。
事前準備
- PCやアカウントなど事前に準備できるものを準備
- オンボーディングができるよう時間、人の確保
組織やプロダクトについてより深く知っていただく
プロダクトのエンジニアとしてジョインしていただく場合、携わるプロダクトはもちろん、それに関連する様々な情報を提供することで理解度がより深まり、業務へのモチベーションが高まると考えています。
そのために具体的に提供すべきと考えている情報
- 会社やプロダクトの歴史について
- 会社がどのようなものを目指していて、このプロダクトはどのような意義を持って生まれ、現状どのようになっていて、どんな未来を目指すのか
- 配属先の組織について
- 目指す未来に向け、どのような体制で何をしているのか
- 今後どのようなことをしていこうと思っているのか
- プロダクトについての詳細
- ロールや機能について
- 関連組織について
- 他部署の人たちはどんな仕事をしていて、どのように協力しあって業務をしているのか
お互いを知る
- 人の紹介
- 入社いただいた方の自己紹介、一緒に働くメンバーの紹介
- 関連部署で特に関わりのある人への紹介
- 座席表
- ウェルカムランチへのいざない
働く環境を知っていただく
- 業務で利用するツールの説明やアカウントの発行
- Slackだったら必要なチャンネルへの招待など
- オフィスの案内
- 備品の使い方
- 勤怠連絡について
業務について知っていただく
- 存在するリポジトリについて
- 開発環境について
- ドキュメントの在り処
- 開発〜リリースまでのプロセスについて
- 各種環境について
- 必要な権限発行なども含め
- Slack開発系チャンネルへの招待
- スキーマの説明
- ディレクトリ構成などコードについての説明
最後に
最初の不安を払拭したり、モチベーションを高めるためにも必要なオンボーディング。
PDCAを回しつつ、改善を続けていこうと思います。
心理的安全性ガイドライン(あるいは権威勾配に関する一考察)
はじめに
「心理的安全性」とは、「対人リスクを取っても問題ないという信念がチームで共有されている状態」であるとか、「自分のキャリアやステータス、セルフイメージにネガティブな影響を与える恐れのなく、自分を表現し働くことができること」というような定義がなされています。
心理的安全性という言葉はともすれば、ただ快適で居心地のよい職場という意味にも聞こえます。そのため、ぬるま湯で緊張感のない関係性のことを「心理的安全性が高い」と言うのではないかと考えても不思議はありません。
そのため、友人関係のようにプライベートの時間を長く共有する関係になることが、心理的安全性が高いのだろうと考え、飲み会やバーベキュー、慰安旅行などを企画してみたりとプライベートでも遊ぶ機会を増やそうと考える人もいるでしょう。
いわゆる「アットホームな会社です」とアルバイトの求人記事に書かれているような状態です。こういった求人内容を見た時に、私のようにちょっとひねくれた人は、なんだか不穏な気配がして、そこに申し込むのはやめておこうかなと考えたりします。
プライベートで仲がいいような状態でも、「対人リスク」を感じることや「自分の地位」を脅かされるような怖さはないかもしれません。ある意味で、間違いなく「心理的安全性」が高いのだと言えます。
しかし、その状態が「高い生産性」と本当に関係するのでしょうか。高い生産性につながるような「心理的安全性」と、緊張感のないぬるま湯的な「心理的安全性」にはどのような違いがあるのでしょうか。
私は、そのキーワードの意味をできる限り正確に捉えるために、観測可能な事実を重要視します。「心理的安全性」の意味するところ、それは、チーム中にある個人の関係において、「様々な形で課題や問題についての提起がされる」ということに他なりません。これらを観測することによって初めて、内的な感情というヴェールの向こう側にある事態を知ることができます。
つまるところ、心理的安全性が高いとは、「些細な問題であっても提起される」「多く問題に対して自己主張がなされる」という観測可能なチームの状態を意味しています。もし、「心理的」に「安全」だとあなたが思っていたとしても、自己主張を誰もしない状態であれば、それは「心理的安全」の意味するところとは違うと考えられるべきなのでしょう。
この状態はどちらかといえば、「気後れしない」「生意気な」メンバー同士の闊達な議論の様子が目に浮かびます。これは、いわゆる「仲の良い」という関係よりもお互いに対するリスペクトがありながらも喧々諤々の議論の多いチーム像が浮かびます。
様々な概念がバズワードとして消費されがちな昨今、生産性の肝となる「心理的安全性」はどのように理解すれば良いのでしょうか。
下から上への情報の透明性
心理的安全性が低いチームにおいては、現場で発生した問題や課題はしばしば隠蔽され、意思決定者の耳目に入らなくなります。何が起きているかがどんどんと見えなくなります。
明確に嘘とは言えなくても、小さな嘘のようなものが組織中に蔓延するようになります。
そうすると、経営者はまるで五感を遮断して歩くような危険な状態になります。知っている道をただ走るならそれでも構いませんが、不確実性の時代において、これは自殺行為です。言い換えるなら、「心理的安全性」は、下から上への情報の透明性とも言えます。
ソフトウェアエンジニアリングのチームにおいて、このように「些細な問題」でも報告し合い、「本質的な課題に向き合う」という性質が強く要求されることから、生産性と心理的安全性の関係が導かれるのです。
これらの心理的安全性とソフトウェアエンジニアリングの関係性については、Google のRe:workプロジェクトあるいは、拙著である「エンジニアリング組織論への招待」を参照していただければと思います。
今回は、これらの知見を踏まえた上で、別の角度から「心理的安全性」を構成する要素を洗い出してみるという試みです。
権威勾配(authority gradient)について
さて、些細な問題であっても、報告し、それについて真剣に取り扱うということの重要さを身にしみてわかっている業界は、ソフトウェアエンジニアリングの業界だけではありません。
むしろ、1つのミスが重大な事故に繋がりかねない医療・製薬やパイロットの業界においてこれらの「心理的安全性」に類することへの知見は議論されてきました。
このような業界では、ある二者関係において、この「問題を報告しやすい」という関係性を「権威勾配」としてモデル化してきました。
権威勾配:もともと、飛行機のコックピットの中での機長と副操縦士の関係を表したもので、航空業界で用いられてきた。
マネジメントの評価指針として活用され、二者の関係の勾配が急になれば、大事故につながると考えられている。勾配が急すぎると、ワンマンな運営になって、目下の人からの危険に関する情報伝達が遅れる傾向から判断が遅れ、逆に相対的に上長の権威が弱いと決定が遅れて事故になる確率が高まるという。
http://d.hatena.ne.jp/keyword/%B8%A2%B0%D2%B8%FB%C7%DB
権威の格差が大きいほどに、目下の者から仰ぎ見る仰角は高くなります。この角度の大きさが「物申す」ことが難しいことを意味しています。これらは、単純に職位の違いといったファクターだけではなく、極めて多くの構成要素から生まれます。
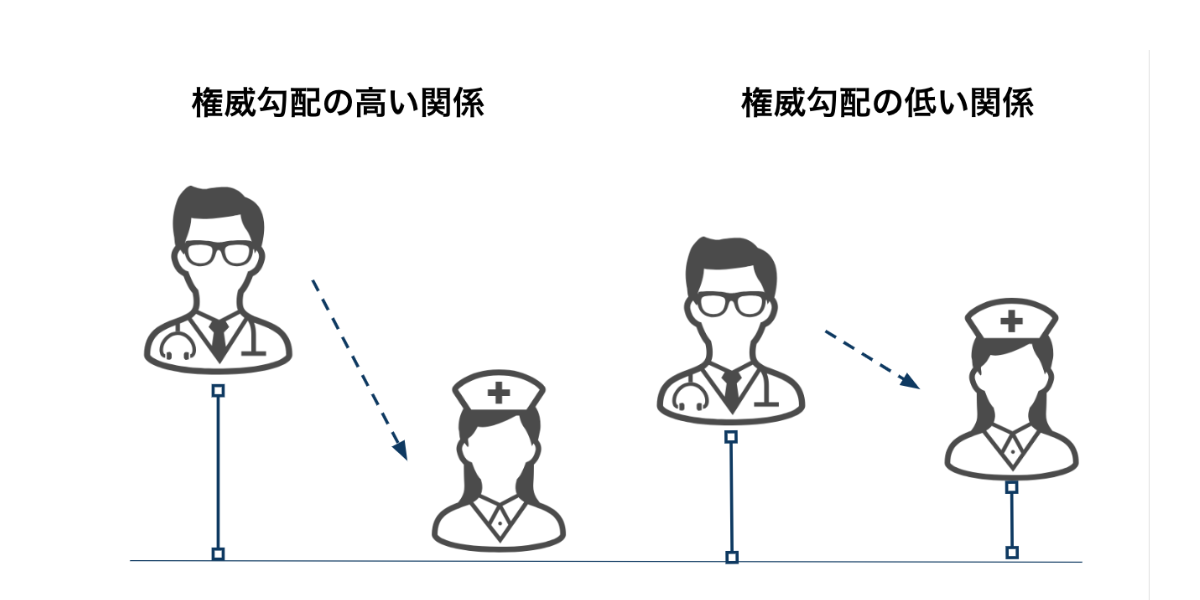
このとき、権威勾配は
- 組織構造による関係性
- 組織文化
- 個人の性質的な差異
などに多種多様な要素を掛け合わせることで生まれます。
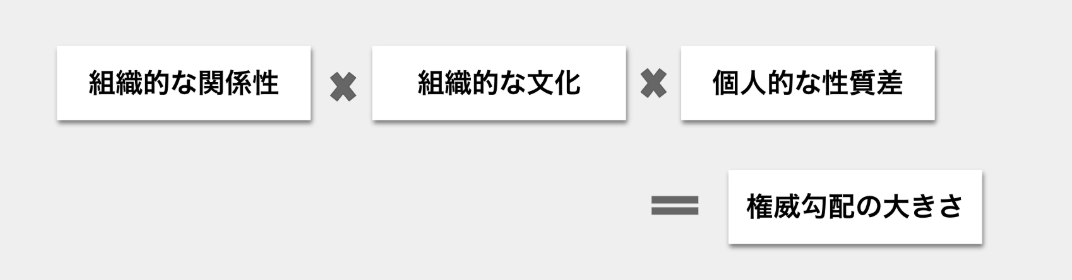
そのため、権威勾配を小さくし、「心理的安全性」を向上させるためには、どのようにしてそれらが生まれるのかを把握する必要があります。そして、その1つ1つの構成要素に対して改善のアクションを取っていけば、少なくとも明日、今よりは良い状況を作ることができます。
そして、チームがもしn人いれば、O(n^2)の関係性が生まれます。その相互の権威勾配の総計が「心理的安全性の低さ」を示唆しているのだと考えると、「心理的安全性」自体のより明晰な定義や理解に近づくのではないかと考えられます。
権威勾配を構成する変数
心理的安全性について、理解するために「些細なことでも自分の意見を発する」ことの障壁となる権威勾配についての考察を進めて見ましょう。航空会社や医療業界のいくつかのテキストと、筆者の観察してきた様々なソフトウェア開発の現場での知見から権威勾配に寄与しているであろう変数には、次のようなものがあると考えられます。
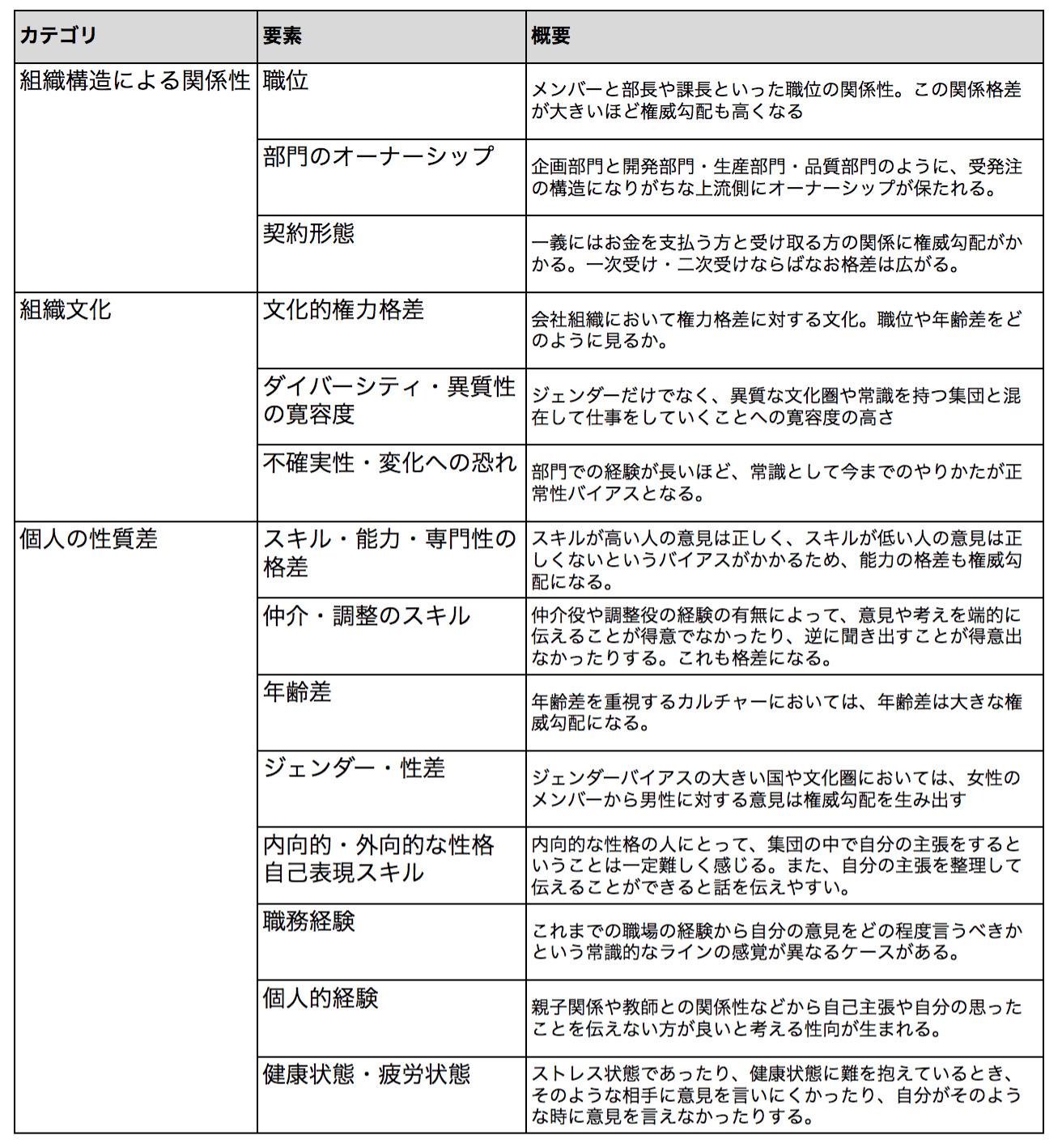
これらは決してすべてリストアップできているわけではありません。
しかし、多くのチームや職場で目にする最大公約数的なものだと言えるでしょう。
これらは、常に「私」と「誰か」のバイネームの問題です。ある任意の二人が会話をする時に思ったことを言えるのかどうかを決める要因がどこにあるのかを知り、改善していくために使えるように、それぞれについての解説を述べたいと思います。
組織構造による関係性
権威勾配を発生させるもっとも単純な原因は、どのような組織的に与えられたロールとの関係性を持っているかによって決まります。組織の役割には、メンバーの差配を行うことで職責を果たすという目的から、一定の権限が割り当てられます。
この権限があることと、個人的な「偉さ」や「正しさ」とは関わり合いのないことなのですが、コントール権を持つものに対して、警戒感を抱いてしまうのは当然のこととも言えます。
職位の格差
Q.あなたとAさんの職位の差は何段階か?(メンバー < マネージャー < 部長 など)
部長やマネージャーといった職位を持つものと、それを持たないメンバーであるというのは、当然のことながら権威勾配を発生させます。
この権威勾配を減らすための手法としては、率先した自己開示、とりわけ個人の弱さをどのように見せていくのかということが挙げられます。これを「飲みの場」でうまく行える人もいます。しかし、飲みニケーションは案外難しいもので、冷静な判断の効かない自分に対して信頼ができると言う人には向いているかもしれませんが、うまくいかないことも多いでしょう。
どちらかというと、自己開示のためのセッションを設計して、誰かにファシリテーションをお願いするか、ランチミーティングや1on1などを通じて定期的な自己開示を行う必要があります。
自己開示にあたって、自分を取り繕うように「自慢げ」にしてしまうのは問題です。自分がどのように悩み、何を考え、どう生きていきたいのかを着飾ることなく伝えましょう。職位が上になると責任感から、完璧に振舞おうとしてしまいます。正しくあろうとすることが、”権限”を”権威”のように見せてしまうことがあります。
一方、職位の低い方が自らを人質に不必要に高圧的に上司に対してコミュニケーションを取るというケースがあります。これは、転職しやすく求人倍率の高い職ほど起こりやすくなります。転職し、職場を選べる人にとっては職場の権威というのはもののかずではありません。不愉快なことがあれば、転職することチラつかせることもできます。
それゆえ、職位が上の人間は難しい立場に置かれます。権力構造が逆転してしまうのです。これは、従来の職位が上の方が権威を振りかざしてきた環境においては、環境を好転させるための素晴らしい変化なのですが、一方、立場の弱い中間管理職を精神的に追い詰め悪い事態を招くことがあります。
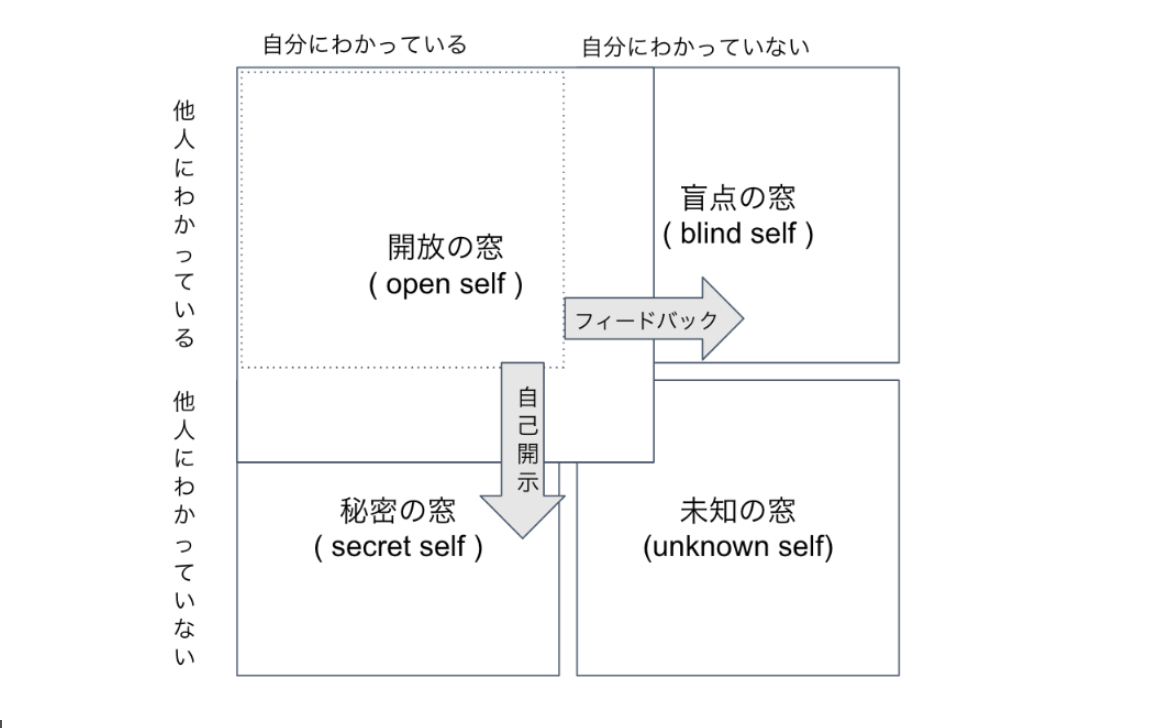
これはジョハリの窓です。自己開示とフィードバックを受けることによって、双方の理解が深まります。このような、サイクルが立場の違いを乗り越えるコミュニケーションの第一歩となります。
部門のオーナーシップ
Q. あなたは相手に依頼する側か?依頼は何部門を経由して行われるか?
業務プロセスの中における上流工程、たとえば「企画部門」に対して「生産部門」「開発部門」といった下流工程側に位置すると思われる部門の間には、業務のオーナーシップがどこにあるのかといった問題から、権威勾配が発生します。
これは職位と同様に強い格差を生み出す可能性があります。職位に比べて問題が大きいのは、職責と一致しないことが多いからです。もし、この権威勾配の発生を防いで生産性を向上させるのであれば、オーナーシップを持つ部門の成果につながる話なので率先して取り組む価値があるように思えます。
しかし、企画部門の1メンバーが、開発チームに対して率先した自己開示やコミュニケーションを通じて、心理的安全性を作るための行動を起こせるかというとなかなか難しいことが多いです。
必要であるからマネージメントしようとする人より、マネージメントする役割だからマネージメントを行う人の方が多いからです。
組織に、部門オーナーシップにかかる問題が頻発するのであれば、設計を見直した方がいいでしょう。一方、個人として対処できることは、お互いを理解する時間を設けて、「〜〜部門の人」ではなく、「個人名」と「その人の性質」から判断するという関係構築を行うことです。
契約形態
Q. あなたは彼/彼女と対等などのような契約か?(同僚 < 直契約 < 間接契約)
上流工程の部門である以上に、対処がしづらいのは、発注側と受注側という関係性になっているケースです。相互により明確な金銭的な契約があり、この契約の決定権がある・あるようにうつっている場合に権威勾配の高さは顕著になります。
また、契約の形態によっては「個々の面談・フィードバック」を禁じられている場合があり、さらに契約が二次受け・三次受けというように多段構造になっている場合があります。このような関係では、対策の幅が狭く、コミュニケーションのパスも間接的になるため、心理的安全性を構築することが極端に難しくなります。
- 一つはこのような状況を抜け出せるようにすること。
- 一つはこのような関係性での信頼関係の構築を意識的に行うこと
が必要です。後者については、
- 一人一人の名前を覚えること
- 名前で呼ぶこと
- 挨拶をすること
- 感謝を伝えること
などをかなり意識的にやる必要があります。これらは、すごく当たり前のことですが、「(会社名)さん」「派遣さん」と呼ぶなど線引きをするような言動や他社の人間として会話をしないといったことをしがちです。
組織文化
組織構造や個人的な性質から生まれる関係は、現実的に改善しきれないことは多々あります。如何に職位の高さがメンバーに対する権威勾配を構成するからといって、すべての人の職責をフラットにしてしまうようなことは現実的でなかったりします。それは責任の所在が不明瞭になりがちだからです。
一方で、ある関係で見たときに同じ関係性であったとしても、たとえば二階級上の上長とのコミュニケーションであったとしても、非常にフラットな雰囲気で行える場合とそうでない場合というのが存在します。
これらは、国家・年代・地域・会社・部門というように多重に社会構造に組み込まれているものがあります。経営層は、このような組織文化の構築・改善を行うことで強い事業組織を育てることができます。逆に、脆弱になりがちな組織はこの文化資本に関しての投資が弱い傾向があります。
ホフステード指数
国家ごとの文化を6つの観点から比較するホフステード指数(https://www.hofstede-insights.com/ )は、国際的な文化傾向の比較をするのに用いられます。職場の文化においてもどのような傾向があるか、類似する基準で見ることができるでしょう。
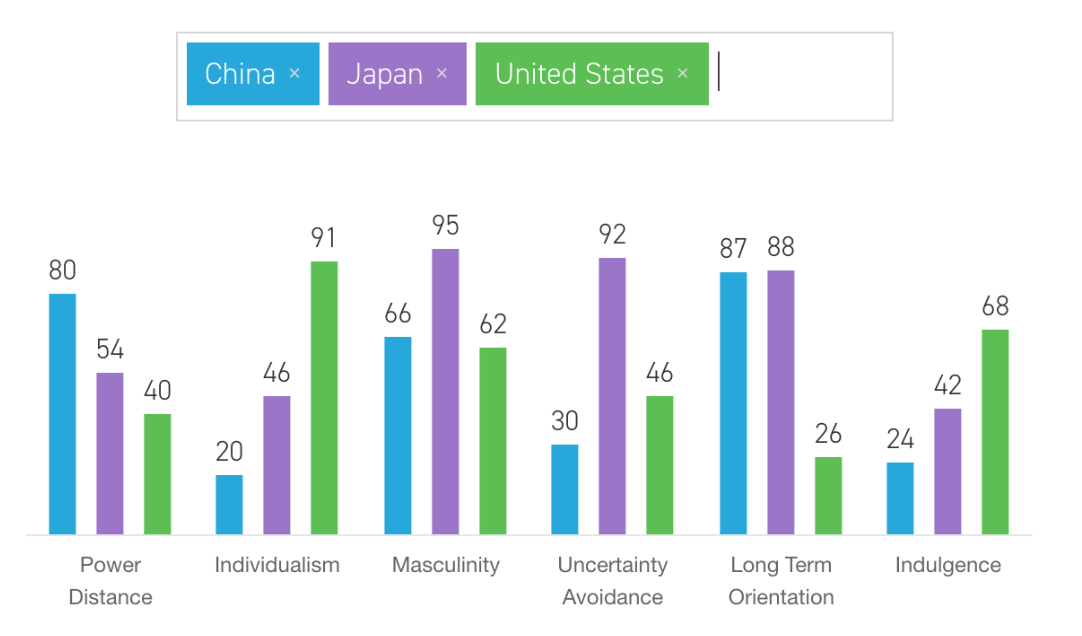
| スコア項目 | 詳細 | アメリカ | 日 本 | 中 国 |
|---|---|---|---|---|
| 権力格差(Power Distance) | 上下関係の強さ。 | 40 | 54 | 80 |
| 個人主義(Individualism) | 個人主義傾向の強さ。 | 91 | 46 | 20 |
| 男性主義(Masculinity) | 男性優位の強さ。 | 62 | 95 | 66 |
| 不確実性忌避(Uncertainty Avoidance) | リスクテイクしない傾向。新しいものをやらない傾向の強さ | 46 | 92 | 30 |
| 長期志向(Long Term Orientation) | 短期の利益より長期的な価値を重視するか。 | 26 | 88 | 87 |
| 快楽志向(Indulgence) | 快楽を求めることを是とするか。禁欲を尊ぶか。 | 68 | 42 | 24 |
権力格差が大きい国の文化圏では、権威勾配が大きくなります。また、個人主義であるほど自己主張がしやすくなるため、意見が生まれやすくなります。男性主義的であると、女性から男性への意見をしづらいと感じる社会であることを意味しています。また、不確実性忌避の傾向が高い国では新しいことや常識の外にあることを受容する力が弱くなり権威勾配が大きくなる傾向があります。
文化的権力格差
Q. あなたの職場では職位を尊称として使うか?たとえば、「〜〜部長」「〜〜課長」など。年少の同僚を「〜〜くん」や呼び捨てするなどの傾向はあるか?
Q. あなたの職場では上長の発言に疑義があっても明確な理由がなければ、反論すべきでないという風土があるか?
Q. あなたの職場では年齢が若い人は年齢が上の人の意見に反論すべきでないという風土があるか?
年齢や権威に対してものが言えなくなる文化が強い場合、実際の職位の乖離を大きな権威勾配へと引き上げてしまいます。上記の質問にあるような上下関係を意識したコミュニケーションが強い文化圏での組織の場合、ちょっとした言葉尻からも権威勾配を生じさせてしまうことがあります。
これらに対する対処としては、年齢や職位を理由にしたコミュニケーションを捉え、減らしていくことです。そして、職位や年齢が下であったとしても「思ったことを意見することは重要」だと伝えていきましょう。
ダイバーシティ・異質性の寛容度
Q. あなたのチームには女性の比率はどの程度いるのか?
Q. あなたのチームには異なる文化圏のメンバーがどの程度いるのか?
Q. あなたのチームは異質な価値観についてどれほど寛容か?
ダイバーシティというと、「女性の活躍」や「外国人」といった文脈を想像しますが、それだけではなく、異なる価値観で生きてきた人たちとどのようにコミュニケーションをしていくべきか知っているということが、様々な意見を取り入れるという土壌を育むことになります。
機能横断型チームの中で育まれた文化圏は、職能型組織に育まれた文化圏よりも多様性に対する受容・包摂が強くなります。たとえば、デザイナーの文化とエンジニアの文化が混ざり合う場所というように。
また、多様性を前提としたチーミングが行われているとき、前提となる文化的背景の違いや、考え方の違いが生まれやすいため、合意点や説明をできる限り明晰に行うという習慣が身につきやすくなります。
こういったことから、「常識と違う考えだから」という理由で、自分自身の考え方が排除されたり、退けられたりしないであろうという関係性が気付きやすくなります。
また、男性優位な社会においては、女性の意見をことさらに特別視したり、軽く見る傾向があります。そのような社会ないし会社で、女性は権威勾配を強く感じます。
このようなことが発生しづらくするためには、
- 自分は女性だからといって意見を軽く見たりするつもりはないこと
- それでもそのように感じたら、自分に伝えてもらうか、別の人に伝えてほしいこと
- 伝えたことで不利になるようなことがないこと
- 自分がもしそのように思わせたら、改善できるように努力すること
などをあらかじめ宣言していくことが重要です。
様々なマイノリティ・多様性に対して、「害意がなくても相手に権威を感じさせる」ことがありうることを自覚し、改善する意思があることを伝えていくことが重要です。
人間ですから、伝え方のミスや無自覚な差別意識が存在することはありえますし、それ自体は仕方なのないことです。問題は、自覚し改善できるようにすることと、フェアネスという価値に対してコミットするつもりがあることを繰り返し伝えることです。
不確実性・変化への恐れ
Q. あなたのチームには直近1年で入社した人がどの程度いるか?
Q. あなたのチームには直近ジョインした人はどの程度いるか?
Q. 何かを決めるときに「今までのやり方」をどの程度重視するか?
多様性とどうように「変化」に対する感受性もまた、権威勾配を生み出しやすい文化的背景になり得ます。たとえば、10年も20年も特定のやり方をしてきた人に対して、別のやり方を提案するのは少し気が引けます。また、相手もなかなか受容しづらいでしょう。やったことがないことをやらなければならないというのは思いの外恐怖を煽ってしまいます。新しいことに対応できるのだろうか、対応できない自分には価値がないと思われるのではないかという意識があると様々な変化に対して、快く思わないという文化が生まれてしまいます。
一方、流動性が高く変化が激しい業界において、去年やっていた仕事と今年やる仕事が変わることは当たり前で、そういった動きがあるからといって、自分の身に危険が及ぶとは考えません。
このような「今までのやり方」を踏襲ようとするマインドがあると、あるゆる場面で意見を求めるということをしづらくなってしまいます。
個人の性質差
個々人がそれまでに過ごしてきた背景や、そこから生まれる性格・言葉づかい、経験の有無などによって高圧的に見えたり、意見を閉じ込めるように聞こえたりすることはあります。
仲介・調整のスキル
Q. あなた/相手は、プライベートでトラブルの仲裁をしたことがあるか?
Q. あなた/相手は傾聴やアサーティブコミュニケーションのトレーニングを受けたことがあるか?
Q. あなた/相手は人と話すことに慣れていて、表情や感情を読み取るのが得意だと思うか?
何か意見を思いついた時に、相手に聞いてもらえるように説明したり、伝えたりする能力の高い人と低い人という個人差は絶対的に生まれます。そのため、何か意見を伝えようとしても伝えられないというもどかしさを感じると、徐々に意見を言わなくなってしまいます。
逆に、相手がうまく聞き出してくれるのであれば、本心や悩みのようなものも拾い上げやすくなります。これは、ソーシャルスキルとして訓練可能なものではありますが、一方で個人的な体験からくる得手不得手はあります。
年齢差
Q. あなたと相手の年齢差はいくつか?
学生時代の悪癖なのか、わずかな年齢差を権力の格差だと錯覚している文化圏の人からすれば、年齢差というのは、大きな権威勾配を生み出します。また、10年も20年も年が離れると世代間の感性のギャップなどから自然と会話する量が減ってしまうといった現象も考えられます。
しばしば、誤解されがちなのですが、「敬意を持って接する」ことと「インナーサークルから排除する」ことは異なります。気を遣って、年齢差のあるメンバーを何かの同僚間のイベントに誘わなかったり、コミュニケーションに壁を設けたりするのは、それは単なる排除であって気を遣っているのとは違います。
ジェンダー・性差
Q. あなたと相手は異性同士か?
Q. あなた/相手はLGBTなどのセクシャルマイノリティか?
女性の社会進出が先進国の中で遅れている日本において、ジェンダーや性差による権威勾配は、思ったよりも深刻なものです。それはLGBTなどのセクシャルマイノリティから見ればなおさらです。
内向的・外向的な性格
Q. あなた/相手は内向的な性格か、外交的な性格か?
内向的な性格の場合、自分の感じた違和感を探り当て、それがなんであるかはっきりと理解できるまで、そのことを誰にも伝えないという傾向があります。慎重であるという美徳ではあるものの、一方で、ストレスや違和感を感じてもなかなか伝えられないということがあります。
職務経験
Q. あなた/相手は権威勾配を強く感じる職場での経験をしてきたか?
Q. あなた/相手は異なる業界慣習で職務経験を重ねてきたか?
これまでの職務経験において、自己主張することや思ったことを伝えることを抑圧されている場合、新たに自己主張をしても良い会社にきたとしてもなかなか発言できないということがあります。
客先常駐型で、マネージメントをあまり受けていない場合、自己主張するよりも黙々と作業していた方がトラブルに巻き込まれないという知恵を身につけてしまい、どこから伝えて良いもので、どこから伝えてはいけないものなのかという判断が鈍ってしまいます。
また、異なる業界から転職してくると、業界慣習を理解するために違和感を感じても一定期間は別の世界の常識を取り入れようとするため、意見を言うよりもむしろ業界慣習の理解に徹すると言うことも考えられます。これ自体は悪いことではないのですが、様々な業界で考えれてきた知見を現在の職場に当てはめる時にどのような問題解決ができるのかという視点まで失ってしまうと発言する機会がどんどんと失われてしまいます。
対策として、どんな仕事をしてきたか、どんな立場だったのか、今はどこが違うと思うのかなどを共有していくと徐々に互いに自分の考えを伝えれるようになっていきます。
個人的経験
Q. あなた/相手は家族や学校などから抑圧的に育てられたか?
Q. あなた/相手は権威や権力を笠にきた誰かに理不尽な精神的・肉体的暴力を受けたことがあるか?
性格とも職場経験とも関連していますが、なかなか原因を特定しづらく、また改善が難しいことが多いものが極めてプライベートな経験によるものです。何か問題を発見しても怒られたり、意見を言うと抑圧されたりすると言う幼少時代を過ごしてしまうと、そのことが心理深くに突き刺さっていて、何かを伝えようとすると動悸が強くなったり冷や汗をかいてしまうと言うことがあります。
そこまででなくても、誰かに何かを言うと「嫌われてしまうのではないか」「見放されてしまうのではないか」など不安にかられてしまい、思考が空転すると言うこともあります。
これらは、同じく個人的な経験から書き換えられることも多いのですが、外部から改善することが難しいことでもあります。たとえば、カウンセリングやメンタリングなどを通じて徐々にこういった個人的な体験によるものだと言う自覚をしていくなどの改善方法が考えられます。ここからはプロフェッショナルの領域になるかと思うので、マネージメントはそういったことを勧めてみるくらいまでができることでしょうか。
あまり、それら個人的な体験自体に深入りせずに、自分の意見を付箋に書き出すという時間を作ったり、文章でまとめてみると言うトレーニングを繰り返しながら、自己主張をしやすくするといったことのほうがうまくいくことが多いです。
健康状態・疲労状態
Q. あなた/相手は健康な生活を続けるのに強い不安を感じているか?
Q. あなた/相手は過度なストレス・疲労や環境変化(結婚などの幸福なイベントも含む)が近々にあったか?
権威勾配の実際的な大きさは、二者間において固定的なものであると言うよりもむしろ、健康状態やストレスといったその場その場で大きく異なるものです。
疲れていそうな人に厳しい意見を言うのはやめておこうと考えてしまうのも人情ですし、その逆に疲れている時に意見するのは大変疲れます。ストレスは人を怒りっぽくさせたり、無意識のバイアスを暴露しがちです。
このストレスの中には、不幸なイベントだけでなく、結婚などの一見ポジティブなイベントによっても引き起こされます。
たとえば、「結婚したんだから、しっかりと家庭を守るんだぞ」と上司に言われたあとでは、改善の指摘も遠慮がちになったりするものです。
難易度を知り、対処する
このように心理的安全を脅かす「権威勾配」についての論点を見ていくと、「こんなものすべてに意識をしてコミュニケーションするなんて不可能だ」とか「気にしすぎて何もできない」と感じてしまう方もいるかもしれません。
本稿の目的は、1つ1つの要因について知ることで、ある二者の関係構築がどのような難しさを抱えているのかを理解することです。そして、難しさの程度と個別の対処方法さえ理解してしまえば、いきなりは無理でも少しづつ良い状態を目指すことができます。
注意しなければならないのは、すべての摩擦や権威勾配をゼロにすることはできないと言うことです。
しかし、難しい状況であっても明日の方が昨日より良いと言えるように何ができるかがわかっていれば、問題はありません。そのためのガイドラインです。
同調圧力・社会的排除
これまでの議論で、心理的安全性を構築するための要素に:
- フェアネス
- 透明性
- 多様性
- 社会的包摂
といった自由主義社会を構成する基本要素と重なり合う側面が大きいことがわかるかと思います。調和を大事にする日本社会という言い方をしては、このことはなかなか見えてきづらいのですが、「同調圧力の強さ」というのは、つまりは異なる常識を持つ人々を社会的に排除するということです。
つまり、リスクをリスクであると声を上げる人を排除してしまうことが「同調圧力」を形作ります。これは、権威勾配と同じものだと言えます。
責任と心理的安全性の四象限
本稿では、「心理的安全性」をつくり上げるために、「権威勾配」と言うパースペクティブから、改善のためのガイドラインを導くものです。
「エンジニアリング組織論〜」でも述べていることではありますが、心理的に安全であると言うことは、「物を言いやすい環境である」ということを意味しています。一方で、「何も言うことがない」のであれば、言いやすくても何も改善はしていきません。これをコンフォートゾーンと言います。
ちょっと耳の痛い改善をやっていこうと話し合いができるのは、チーム全体が心理的安全性だけでなく、事業への共感やミッション達成への責任感を持っているからに他なりません。
一方で、責任感はあってもフラットに意見を言い合える関係でなければ、不安に感じてしまい、どんどんと疲れてしまいます。これが不安ゾーンです。
この心理的安全性と責任の四象限において、どのように「ラーニングゾーン」に導いていくかがチームの生産性が向上するための必要条件だということも忘れてはいけないでしょう。
おわりに
本記事は、モチベーションクラウドアドベントカレンダーの11日目です。モチベーションクラウドの開発チームは、現在社員とパートナー企業、フリーランサーという混合チームで開発を行っています。僕自身も組織構築の支援という形で参加しています。
国際色も多様で、女性のエンジニアやデザイナーも一定比率います。アドベントカレンダーに参加し、知見をシェアするという組織文化が生まれつつあります。心理的安全を構築する上での難しさを乗り越えながら、日々けんけんがくがくの議論ができるチームになってきています。
あわせて読みたい
組織で技術的負債に立ち向かうための取り組み
これはモチベーションクラウドAdvent Calendar 12日目の記事です。
エンジニアとして働いていると技術的負債に悩まされたことはあるのではないでしょうか。技術的負債は開発を継続する中で発生した「理想とかけ離れたコードの状態」を指した比喩ですが、どこの開発現場でもサービスを継続する上では少なからず存在するものだと思います。
特にプロジェクトの期間が長くなってきたり、開発メンバーが増えてくると技術的負債の問題が大きくなってきます。組織構造や開発体制によって技術的負債の扱いは変わると思いますが、以下の理由で中々改善が進まない場合があります。
技術的負債のジレンマ
捉えどころの難しい技術的負債という概念
技術的負債と言ってもそれが具体的に何を表していて、どのぐらいのボリュームがあるのかを把握するのは中々難しいのではないでしょうか。代表的な負債であれば、全体のうちどの部分が複雑化していて、どのような改善を行うべきなのかは思いつくかもしれませんが、その改善の効果がどの程度あるのかを定量的に説明するのは将来の要件を予測して見積をするようなものでほぼ不可能でしょう。結果的に工数の見積や実際にコードに手を入れる際にバッファを設けたり、調査工数に時間を設けたりします。
非エンジニアと技術的負債について議論する難しさ
技術的負債というものをエンジニアも漠然と捉えているので、非エンジニアにも中々上手く伝えることができません。そのため、エンジニアと非エンジニアでは問題の大きさや優先順位の認識が揃わず、お互いストレスを抱えてしまいます。
このままでは技術的負債の返済は見送りとなり、「開発速度の低下」という形で徐々に問題が大きくなっていき、最終的には多大な工数をかけてシステムの大改修や再構築するなどの対策を打つ必要が出てきたり、改修コストと予算が見合わなければサービスを停止するなどの恐れもあります。
技術的負債についてさらに詳しく知りたい方はエンジニアリング組織論への招待を読むことを強くお勧めします。
技術的負債に立ち向かうための取り組み
では、私たちはどのようにこれらの問題に立ち向かうべきなのでしょうか。
ここからは、私たちが実際に行なっている施策について一部をご紹介します。
技術的負債を見える化する
まずは技術的負債という得体の知れないものをテーブルの上に上げるために見える化する必要があります。そのため、Code Climateというコードの品質を計測するためのツールを導入しました。
Code Climateでは複数の言語をサポートしており、循環的複雑度など10点の検査項目で特定した技術的負債によってA〜Fのランク付けをしてくれます。以下はサンプルコードで出した結果ですが、Code Climateのサマリー画面になります。
また、それらの問題解決にかかる時間を"修復時間(remediation time)"として予測値を算出してくれます。機能の詳細はここでは割愛しますが、これはコードの品質についてチームで共通認識を持つためだけでなく、開発サイドとビジネスサイドで改善の必要性を議論する上で役立ちます。
メンバー同士の物理的な距離を近くする
私たちの開発チームは社内のエンジニアだけでなく、複数のパートナー企業とフリーランサーも多数参加しています。このような多種多様なメンバーがいる開発組織だと物理的に距離が近いことで話しかけやすくなり、信頼関係の構築に繋がります。後述する様々な施策を打つにあたり、この信頼関係はとても重要な役割を果たします。
メンバー同士で問題意識を共有する
開発チームが増えてチームが分かれた頃にチーム間での連携や思想の統一が難しいことがありました。そのため、週に1回各チームのメンバーが集まり、問題になっている事や改善したい事について共有する場を作りました。私たちはこれを「改善MTG」と読んでいますが、例えば以下のような事を議題として取り上げてきました。
- コンポーネントの設計思想について
- ライブラリの導入可否やアップデートのタイミングについて
- リファクタリングをいつ・どのように進めるかについて
- LinterやCIの設定変更について
議題をもとに問題の優先順位を話し合い、解決に向けたアクションを"宿題"としてタスクに追加します。宿題は次のMTGで進捗確認にして、当初の問題が解決されればクローズします。
時にはモブプログミングを行い、各メンバーの知識共有も行いました。

最初はフロントエンドメンバーのみで始めましたが、最近ではプロジェクトマネージャーやバックエンドエンジニアも一緒に参加するようになっています。
改善する時間をつくる
最近では開発チーム全体での改善活動も始まりました。これは「改善Day」と呼ばれ、隔週に1日の改善の期間を設けます。この時間は各々が普段感じている問題の対処に時間を使って良い日です。この時間を使って、宿題として登録されたタスクをこなしたり、後回しにしていた負債コードの改修にあたります。
また、この改善Dayは能動的に参加してもらうために強制にはしておらず、スケジュールの都合などで普段の開発タスクを優先する事も可能としています。
バグをドラゴンと呼ぶ
技術的負債が溜まってくるとバグの発生率も上がりますが、エンジニアにとってバグ対応は心理的な負荷が高いものです。"バグ"という言葉はエンジニアに精神的ダメージを与え、結果的に生産性の低下に繋がる恐れがあります。※もちろん、バグを出してしまったエンジニアにも責任があることは重々承知しています...。
そんな中、とあるメンバーの発案で"バグ"を"ドラゴン"と呼ぶことにしました。また、バグのインパクトに応じて"しんりゅう"、"リザードマン"、"ドラゴンキッズ"というドラクエ譲りのラベルを付け、バグ対応にあたるエンジニアを"ドラゴンスレイヤー"と名付けるようにしました。彼らをサービスを守る勇者であると開発チームで讃えることにしたのです。これによって、開発現場で"バグ"という言葉がほとんど使われなくなりました。
モチベーションクラウドのエンジニアリングチームでは、バグや障害を「ドラゴン」と呼ぶことに決め、奴らを倒すものに伝説の剣を与えるという文化が生まれたそうです。 pic.twitter.com/MV7wu4Al6t
— 広木 大地/ エンジニアリング組織論への招待 (@hiroki_daichi) November 16, 2018
終わりに
技術的負債への取り組み方は各々の開発現場で様々な工夫をされているのではないかと思います。
上記の取り組みは私たちが現在行なっているものであり、今後も状況に応じて変化させていく可能性は十分にありますが、モチベーションクラウドの開発チームはサービスだけでなく、組織を大事にする文化があります。引き続き、より良いサービスの改善に向けて組織で一丸となっていきたいと思います。
合わせて読みたい
スクラムマスターを経験して味わった成功体験と失敗体験
※この記事はモチベーションクラウド Advent Calendar 2018の13日目の記事となります。
おはようございます。
モチベーションクラウドの開発に参画している@kiiiiitaです。
はじめに

マネージメント未経験でスクラム開発経験も4ヶ月だった私が、スクラムマスターを経験して味わった成功体験と失敗体験を振り返ります。
スクラムマスターになった経緯
時系列で書くと
- スクラム導入
- 開発チームの一員になる
- 所属していたチームのスクラムマスターがエンジニアに転向するため離任
- 後任として私に白羽の矢が立つ
- 偉い人たちに呼ばれお願いされる
- 最初は断るが押しに負ける
- 開発メンバー兼スクラムマスターの誕生
のような流れです。
イベントや体制など
スクラムイベント
- モーニングスクラム(朝会)毎日
- スナックスクラム(夕会)毎日
- スクラムマスターMTG 毎日
- 振り返り(KPT)週1
- スプリントプランニング 週1
- スプリントレビュー 週1
- 振り返りFB 週1
イベントは多分他と比べて多かったです。
他と明らかに違うだろう点は振り返りFBがあることですかね。
内容は週1振り返りでやっている内容の振り返りです。
コンサルとしてJOINしているRector社の松岡さんと広木さんにチームで振り返った内容を共有して、アドバイスを頂き振り返りの質を上げようという場です。
チーム体制
- PO×1
- スクラムマスター×1
- 開発メンバー×4~6くらい
チームには含まれませんが、デザイナーやテストチームも存在して必要であれば連携していくスタイルです。
スプリント期間
初期は1週間、途中から2週間で回していました。
スクラムでの成功体験

ストーリーのタスク分けを細かくした
タスクやストーリー自体が大きすぎると抽象度が上がり、見積もった以上の実績がかかることはよくあると思います。
その乖離をなくすために
- タスクは細くする
- 予実の乖離を起きづらくする
- ストーリーに対してプランニング時にガッチリ仕様を詰める
- ストーリーを進める上での影響を洗い出し不確実性をなくす
をしました。
予実管理はバーンダウンチャートを使用していたのですが、予定通り落ちていくと安心感が違います。
終わらなかったストーリーの問題を深堀りした
約束したストーリーを全部終わらせられないことはよくありました。
その時は振り返りで
- 終わらなかったストーリーのポイントを見返す
- 適正だったかを議論する
- 問題を深掘りする
- 具体的にどういうところに時間をかけたか分析
- ハマりポイントを明確にする
を行い次回のプランニング時に同じことを繰り返さない対策を打っていました。
メンバー間の心理的安全性を保つ
これはスクラムマスターになって特に重要度を感じました。
スクラムはチームで仕事をするのでチーム力やコミュニケーション力が非常に大事です。
チームメンバーの一人ひとりが気兼ねなく発言できることは、チームの状態や仕事をしていく上でのパフォーマンスにかなり影響があります。そしてコミュニケーション量を増やし、チームの雰囲気向上にも繋がります。
また、振り返り、プランニング、コードレビューでも、それぞれの考えをぶつけ合うことで質が上がる要因になっていたと思います。
スクラムでの失敗体験

2週間スプリントの難しさ
1週間スプリントに慣れてきた時に2週間スプリントに移行したのですが、難易度の高さを感じました。何故なら、MTGの時間はそのままだがプランニングの量は倍になりタスクの抽象度が上がる不確実性が増していったからです。
また、スプリントが長いため遅れていても取り返せるんだと考えがちでしたが、実態はリカバリー案がなく終わらないことが多かったです。
このことから2週間先の見込みを十分に立てることの重要性と、こまめな進捗管理が2週間スプリントでは学びました。
一つ勘違いしてはいけないのは、タスクの抽象度を上げるということは悪ではありません。成熟したチームなら抽象度が高くても仕様決めから開発までをやり遂げるでしょう。
チームの大幅な入れ替え
元々スクラムはメンバーの入れ替えに弱いです。
チームが成熟している時に追加や入れ替えが発生すると、チームビルディングをやり直す必要があるからです。ましてや大幅な入れ替えとなるとそれは必然となるでしょう。
今までのやり方が合わない新メンバーもいるため、チームビルディングをし直すこと自体はすごく意味があると思います。
しかし、既存のメンバー(私も含む)からすると大きくやり方を変えるのは難しいです。何故なら成功体験があるからです。
メンバーそれぞれの目指す方向を共通認識として持つことがスクラムでは重要だと学びました。
MTGのタイムマネージメントをできなかった
スクラムはイベント(MTG)が多いですがそのほとんどが長くなりがちでした。
その原因の一つにMTGに参加する人数が多いということが挙げられます。もちろんいて欲しい場合がありますがその殆どがその限りではありません。人が多いと議論が活発化され着地しづらくなります。必要である場合以外はMTGを最少人数でやるようにすべきでした。
また、MTG中の時間管理もしっかりできていませんでした。そのため長くなると集中力が切れ良い意見も出ません。中には自分の作業をしだして議論に参加しないメンバーもいました。
そうならないためにMTGをアジェンダ通りに進めることや、状況次第では第二回を開催するなどの対策を取るべきだと学びました。
何でもかんでも自分でやりすぎた
スクラムマスターはチームへの妨害を排除することが目的です。なので私はメンバーが開発の邪魔になりそうことはやりました
具体的に何をやったかというと
- 本番ブランチと開発ブランチのコンフリクト対応
- 開発環境に問題があった場合の調整
- 仕様の最終決定をPOと調整
- 他チームとの連携・調整
- リリースの段取り
- 実際のリリース作業
- ストーリーをバックログに追加する
などです。
これ以外に自分のタスク(開発のストーリー、スクラムイベントへの参加、振り返り資料作成)も抱えていましたが、最後はパンクしました。
ここまでやった理由としてストーリーが終わらなかったときの理由を他責にして欲しくなかったことが強かったです。
しかしメンバーを信頼して作業分配すべきだったと学びました。
まとめ
スクラムマスターを経験して多くの学びがありました。
チームとして、組織として成果を出すことの難しさを痛感してます。
また、スクラムとは単なるフレームワークなのでチーム状況に応じた柔軟な対応がいかに大事かを学びました。
最後にスクラムにとって特に重要なこと
それは心理的安全性が保たれてることだと思いました。
改めて振り返ってみると良い状態のときはあって悪い状態にはなかった要素かなと思ってます。多分この要素を満たしているだけでチームが良い状態になる可能性が高まるのではないでしょうか。
割と問題はヒトとヒトの間にあることが多いです。
チームや関わる人たちに言いたいことを言い合える環境こそが、スクラムをやる上での重要なことだと感じました。
ただし心理的安全性が保たれている=いじりや悪口など何でも言っていいということではありません。
相手を思いやる気持ちとリスペクトの精神を忘れないようにして、質の高いコミュニケーションを心がけましょう。
私はそれで何度も失敗しました
Macを触ったことのなかった新人エンジニアが再帰プログラムを説明してみた
はじめまして。リンクアンドモチベーションでモチベーションクラウドの開発をしている@ohtatakatoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」の記事となります。
新卒2年目から未経験で急遽エンジニアとなり、現場に入ってまだ1ヶ月の私ですが、研修を通して学んだことをまとめていきます。
この記事では、再帰プログラムとは何なのかが分かっていない方の為に具体例を示しながらなるべく分かりやすく説明しようと思います。
再帰プログラムとは
再帰とはwikipediaに下記のように記載があります。
再帰(さいき)は、あるものについて記述する際に、記述しているものそれ自身への参照が、その記述中にあらわれることをいう
つまり、再帰プログラムとはプログラム中で自身への参照をしているプログラムのことを言うわけですが、私はこれだけではいまいち何を言っているのか分かりませんでした。
具体例 : クリスマスツリーに星を飾る
クリスマスツリーに星を一つずつ飾ってn個の星が飾られた状態をつくります。
仮に10個の星が箱の中に入っていたとして、ツリーに星を飾る回数を数えるときに、
下記のように考えることができます。
「10個の星を飾り付けるためには9個の星を飾り付けた状態のツリーにさらに1個星を飾れば良い」
これを数式で表すと下記のように書けます。
kazatteru_hoshi(n)でn個の星が飾られた状態を示すとすると
kazatteru_hoshi(10) = kazatteru_hoshi(9) + 1
このように10個の星を飾るためには9個の星が飾られている必要があり、
同様に9個の星を飾るためには8個の星が飾られている必要があります。
まさにこれが再帰的な試行なのです。
n個の星を飾る行為は下記のように記述することができます。
def kazatteru_hoshi(n)
if n < 1
return 0
else
return kazatteru_hoshi(n - 1) + 1
end
end
※nはintとする
再帰プログラムは漸化式だった!
ここまで学習してみて、再帰プログラムを作成する際には高校数学の漸化式の作成と同様のことをしていることに気がつきました。
今回のクリスマスツリーを飾る試行の漸化式は下記のようになります。
f(1) = 1
f(n) = f(n-1) + 1
この漸化式を解くとf(n) = n
wikipediaで「漸化式」を調べてみると
漸化式(ぜんかしき、英: recurrence relation; 再帰関係式)は、各項がそれ以前の項の函数として定まるという意味で数列を再帰的に定める等式である。
つまり、高校生の頃に学んだ漸化式を作成することができれば、再帰プログラムを組むことは容易にできるということです。
↓フィボナッチ数列の漸化式も再帰で書けますね
f(0) = 0
f(1) = 1
f(n) = f(n-2) + f(n-1)
def fibo(num)
if num < 0
return "numは0以上の整数"
else
case num
when 0
return 0
when 1
return 1
else
return fibo(num-2) + fibo(num-1)
end
end
end
注意点
再帰プログラムにおいて自身を呼び出す回数が多くなると計算量が膨大になってしまう可能性があるので注意が必要です。
これに関してはお正月休みに詳しくまとめようと思います。
最後に
モチベーションクラウドは社員と複数のパートナー企業様、フリーランスの方の混合チームで開発しています。
エンジニアになる以前はスクラムマスターとして携わっていたのですが、その時からプロダクトだけでなく、その根底にあるチーム創りを大切にしています。
興味がある方はモチベーションクラウド Advent Calendar 2018の下記記事をご覧ください。
Vue使いなら知っておきたいVueのパターン・小技集
はじめに
こんにちは、モチベーションクラウドの開発にフリーのエンジニアとして参画している@HayatoKamonoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」15日目の記事となります。
概要
モチベーションクラウドのフロントエンド開発では、JavaScriptのフレームワークとしてVueを採用しています。
私がモチベーションクラウドの開発にジョインしたのは2018年7月です。
それまで私はReactを使ったフロントエンド開発を2、3年ほど行なってはいたものの、Vue自体は未経験の状態でした。
今回は、そんなVue未経験だった私が、この5ヶ月弱の間に、実務や日々の学習を通して蓄積してきたVueのパターンや小技、また、Reactコミュニティーから拝借したパターンなどを簡易的なサンプルコードとともに、共有させて頂きたいと思います。
v-modelのカスタマイズ
<some-component v-model="isExpanded" />
v-modelはデフォルトでは以下のように書き換え可能です。
<some-component @input="someFunction" :value="isExpanded" />
しかし、このデフォルトの挙動を以下のようにカスタマイズすることも可能です。
model: {
prop: "isExpanded",
event: "toggle"
},
props: {
isExpanded: {
type: Boolean,
default: false
}
},
フォーム系のコンポーネントであれば、v-modelに紐づくprop名とevent名をそのまま、valueとinputにしても良いですが、フォーム系"以外"のコンポーネントの場合、そのコンポーネントの振る舞いにより適したprop名とevent名を、上記の例のように割り当ててあげるのが良いと思います。
$once('hook:beforeDestroy')
<script>
export default {
name: "SampleComponent",
created () {
this.someEventHandler = () => {
console.log("実際の開発ではイベントは間引こう!");
};
document.addEventListener("mousemove", this.someEventHandler);
},
beforeDestroy () {
document.removeEventListener("mousemove", this.someEventHandler);
}
};
</script>
時折、このようにcreatedのタイミングで何らかのイベントに特定の処理を紐付け、beforeDestoryのタイミングで同じイベントに紐づけておいた処理を除去したいこともあるかと思います。
こういった場合は以下のように書くと、よりシンプルにコードを書くことが可能です。
<script>
export default {
name: "SampleComponent",
created() {
const eventHandler = () => {
console.log("実際の開発ではイベントは間引こう!");
};
document.addEventListener("mousemove", eventHandler);
this.$once("hook:beforeDestroy", () => {
document.removeEventListener("mousemove", eventHandler);
});
}
};
</script>
ポイントはcreatedメソッドの中で、一度だけ実行される$onceメソッドを呼び出し、Vueのhook:beforeDestroyイベントに対して、beforeDestoryメソッドの中で行いたい処理を記述するということです。
watchプロパティーのimmediate: true
Vueでは特定のpropの値が変化した時に、何らかの処理を実行したい場合、watchプロパティーを使用します。
しかし、watchプロパティーは普通に使うと、監視対象のpropの値が変化した時にのみ、監視対象のpropに紐づけたメソッドが実行されます。
watch: {
isOpen () {
this.count = this.count + 1
}
}
例えば、この場合は親コンポーネントから受け取るpropであるisOpenの値が変化する時にのみ、このコンポーネント自身が持つcountがインクリメントされます。
watch: {
isOpen: {
immediate: true,
handler() {
this.count = this.count + 1;
}
}
}
しかし、このように書き換えることで、このコンポーネント自身が最初にマウントされたタイミングにも、countがインクリメントされるようになります。
Render Function
多くの場合、Vueでは<template>タグを使用していれば事が足りますが、render functionというVNodeをプログマティックに生成するAPIを使う事で、描画部分のコードをより簡潔に書けたり、柔軟に処理を行えたりします。
<template>
<p :style="{ color: 'red' }">Hello World</p>
</template>
<script>
export default {
name: "HelloWorld"
};
</script>
上記は単純に'Hello World'と赤文字で表示するだけの簡単な例です。
<script>
export default {
name: "HelloWorld",
render(createElement) {
return createElement("p",
{ style: { color: 'red' } },
"Hello World"
);
}
};
</script>
先ほどのコードをrender functionを使って書くとこのようになります。
render(createElement) {
return createElement("p",
{ style: { color: 'red' } },
"Hello World"
);
}
render functionの引数にはcreateElementという関数が渡ってきます。このcreateElementを使って、VNodeを生成します。
createElementの第一引数には要素名やコンポーネント名を渡し、第2引数にはpropsやclassなどの設定オブジェクトを任意で渡します。そして、第3引数には、子要素になるVNodeや文字列を渡します。
<script>
export default {
name: "HelloWorld",
props: {
level: {
type: Number,
default: 1,
validator(value) {
return value > 1 && value <= 6;
}
}
},
render(createElement) {
return createElement(
`h${this.level}`,
{ style: { color: "red" } },
"Hello World"
);
}
};
</script>
render functionを使えば、上記の例のように、親からlevelというpropを通して、1〜6の見出しレベルを受け取り、その受け取った見出しレベルに対応するHタグを動的にcreateElementの第一引数に渡してあげることも可能になります。
これを<template>タグを用いて行おうとすると、<template>タグの中で対応させたい見出しレベルの数だけ条件分岐を行わなければなりませんが、render functionを使えば、簡潔にコードを書く事が出来るようになります。
Functional Wrapper Component
条件毎に異なるコンポーネントを描画したいような場合は、Functional Componentでラップして条件に対応したコンポーネントを描画してあげると、コードがクリーンになります。
以下は配列の中にデータがある場合は、データがある場合のコンポーネントを描画し、データがない場合はデータが無い場合のフォールバック用コンポーネントを描画するという簡易的な例です。
App.vue
<template>
<div id="app">
<smart-item-list :items="items" />
</div>
</template>
<script>
import SmartItemList from "./components/SmartItemList";
export default {
name: "App",
components: {
SmartItemList
},
data() {
return {
items: [{ id: 1, name: "apple" }, { id: 2, name: "banana" }]
};
}
};
</script>
ここでは単に、SmartItemListコンポーネントのitems propに2つのオブジェクトを持つ配列を渡しているだけです。
SmartItemList.vue
<script>
import ItemList from "./ItemList";
import EmptyData from "./EmptyData";
export default {
functional: true,
props: {
items: {
type: Array,
default() {
return [];
}
}
},
render(createElement, { props }) {
const Component = props.items.length > 0 ? ItemList : EmptyData;
return createElement(Component, {
props: {
items: props.items
}
});
}
};
</script>
ここでは、親から受け取ったitems配列の中のオブジェクトの数をチェックして、配列の中身が無い場合は、EmptyDataコンポーネントを描画し、配列の中身がある場合は、ItemListコンポーネントを描画しています。
ItemList.vue
<template>
<ul>
<li v-for="item in items" :key="item.id">{{ item.name }}</li>
</ul>
</template>
<script>
export default {
name: "ItemList",
props: {
items: {
type: Array,
default() {
return [];
}
}
}
};
</script>
データがある場合は上記のコンポーネントが描画されます。
EmptyData.vue
<template>
<div>No Data...</div>
</template>
<script>
export default {
name: "EmptyData"
};
</script>
データが無い場合は、'No Data...'と表示されるだけのコンポーネントが描画されます。
Error Boundary
ReactではError Boundaryという、子孫コンポーネントでエラーが発生した際にクラッシュしたUIを表示させる代わりに、フォールバックのUIを表示させる手法が存在します。
それをVueで実現する為には、VueのerrorCapturedフックを使用します。
以下はその簡易的な例です。まずは、Error Boundaryの使い方から見ていきます。
App.vue
<template>
<div id="app">
<ul>
<template v-for="item in items">
<error-boundary :fallback="fallbackItem" :key="item.id">
<dummy-item :item="item" />
</error-boundary>
</template>
</ul>
</div>
</template>
<script>
import ErrorBoundary from "./components/ErrorBoundary";
import DummyItem from "./components/DummyItem";
import FallbackItem from "./components/FallbackItem";
export default {
name: "App",
components: {
ErrorBoundary,
DummyItem,
FallbackItem
},
data() {
return {
items: [
{ id: 1, name: "apple" },
{ id: 2, name: "banana" },
{ id: 3, name: null }
]
};
},
computed: {
fallbackItem() {
return FallbackItem;
}
}
};
</script>
ここでは、エラーが発生しうるコンポーネントをErrorBoundaryと名付けたコンポーネントでラップしています。ErrorBoundaryコンポーネントのpropsであるfallbackには、エラーが発生した際に代わりに表示させたいフォールバック用のコンポーネントを渡しています。
propsを通して、フォールバック用のコンポーネントを設定出来るようにすることで、ErrorBoundaryコンポーネントの利用者がエラー発生時に表示させたいコンポーネントを自由に選べるようになります。
ErrorBoundary.vue
<script>
export default {
name: "ErrorBoundary",
props: {
fallback: {
type: Object
}
},
data() {
return {
hasError: false
};
},
errorCaptured() {
this.hasError = true;
},
render(createElement) {
return this.hasError
? createElement(this.fallback)
: this.$slots.default[0];
}
};
</script>
次に、ErrorBoundaryコンポーネントを見ていきます。ここでやっていることは単に、子孫コンポーネントで発生したエラーを、errorCapturedメソッドで捕獲してあげて、エラーであった場合はフォールバック用のコンポーネントを描画し、そうでない場合は、自身のslotsコンテンツを描画してあげています。
DummyItem.vue
<template>
<li>{{ item.name.toUpperCase() }}</li>
</template>
<script>
export default {
name: "DummyItem",
props: {
item: {
type: Object
}
}
};
</script>
このコンポーネントがエラーが発生しうるコンポーネントです。親コンポーネントからpropsを通して受け取るitemオブジェクトのnameプロパティーは文字列であるため、<template>の中では例として、item.name.toUpperCase()を実行して文字列を大文字に変換しています。
しかし、APIから取得したデータに異常値が含まれている場合などを想定した場合、itemオブジェクトのnameプロパティーが欠損していたり、nullであるかもしれません。
そういった場合に、文字列ではないデータ型に今回のようにtoUppserCaseメソッドを実行すると、レンダリングエラーが発生してしまいます。
FallbackItem.vue
<template functional>
<li>nah...</li>
</template>
<script>
export default {
name: "FallbackItem"
};
</script>
エラーが発生した場合は、ErrorBoundaryコンポーネントのpropsのfallbackに渡していた、FallbackItemコンポーネントが代わりに表示されます。
Higher Order Component
Higher Order Componentはデータや振る舞いを共通化したい時に利用する、Reactではお馴染みのパターンですが、Vueでもrender functionを使えば可能です。
Higher Order Componentは、引数にComponentを取り、別のComponentを返す高階関数です。
以下は、仮にクライアント側で認証を行うSPAであると仮定した場合に必要になりそうな、クライアント認証用のロジックやデータを提供するHigher Order Componentの例です。
Higher Order Component側
requireAuth.js
const requireAuth = WrappedComponent => {
return {
name: `${WrappedComponent.name}-protected`,
computed: {
isAuthenticated() {
return this.$store.state.isAuthenticated;
}
},
created() {
// JWTトークンが存在、または、失効しているかどうかをチェック
// トークンが無い、または、失効していたらログインページへリダイレクト
},
render(createElement) {
return createElement(WrappedComponent, {
props: {
isAuthenticated: this.isAuthenticated
}
});
}
};
};
export default requireAuth;
使う側の例
router.js
export default new Router({
mode: "history",
base: process.env.BASE_URL,
routes: [
{
path: "/",
name: "home",
component: requireAuth(HomePage)
},
{
path: "/about",
name: "about",
component: requireAuth(AboutPage)
}
]
});
クライアント認証のロジックを適用したいコンポーネントをrequireAuth関数の引数に渡してあげれば、引数に渡されたコンポーネントはクライアント認証のロジックを持つようになります。
Container Component、Presentational Component
Reactコミュニティーではお馴染みのパターンの1つに、データと振る舞いに関心を持つContainer Componentと、描画に関心を持つPresentational Componentを分けて実装するというものがあります。
render functionとHigher Order Componentのパターンを使えば、Vueでも同じことが実現可能です。
// Presentational Componentをimport
import SamplePage from "./SamplePage.vue";
/*
以下の`connect`は、Presentational Componentを引数に取り、そのコンポーネントが関心を持つ、
VuexのmoduleのデータとVue Routerのメソッドへのアクセスを与えたContainer Componentを返す高階関数
*/
const connect = WrappedComponent => {
return {
name: `${WrappedComponent.name}Container`,
computed: {
count() {
return this.$store.state.count;
}
},
methods: {
handlePageChange({ to }) {
this.$router.push(to);
}
},
render(createElement) {
return createElement(WrappedComponent, {
props: {
count: this.count
},
on: {
pageChange: this.onChangePage
}
});
}
};
};
/*
次の2行は以下のコードをContainerの説明の為に、より明示的にしたもの
export default connect(SamplePage);
*/
const SamplePageContainer = connect(SamplePage);
export default SamplePageContainer;
export { SamplePage };
Renderless Component(Scoped Slots)
VueにはHigher Order Componentの他にも、データやロジックを共通化する方法として、Scoped Slotsを利用したものがあります。
Scoped SlotsはReactコミュニティーでお馴染みのRender ChildrenやRender Propsパターンのようなものです。
以下はScoped Slotsを用いたContainer Componentの例です。
DataProvider.vue
<script>
export default {
name: "DataProvider",
props: {
url: {
type: String
}
},
created() {
fetch(this.url)
.then(response => response.json())
.then(json => (this.data = json))
.catch(console.error);
},
data() {
return {
data: []
};
},
render(createElement) {
return this.$scopedSlots.default({
data: this.data
})[0];
}
};
</script>
上記のコードでは例として、propsで渡ってきたURLにGETリクエストを行い、成功時に返って来たデータを呼び出し元にscoped slotsを通して渡しています。
this.$scopedSlots.default()自体はVNodesを含んだ配列を返す為、このメソッドの結果をそのまま、render functionの中でreturnしてあげれば、return createElement('div', [this.$scopedSlots.default()]のように、何らかのDOM要素でラップしてあげる必要もありません。
App.vue
<template>
<div id="app">
<data-provider url="https://jsonplaceholder.typicode.com/todos">
<template slot-scope="{ data: todos }">
<ul>
<li v-for="todo in todos" :key="todo.id">{{ todo.title }}</li>
</ul>
</template>
</data-provider>
</div>
</template>
<script>
import DataProvider from "./components/DataProvider";
export default {
name: "App",
components: {
DataProvider
}
};
</script>
呼び出し元では、DataProviderコンポーネントの中でfetchしたデータをslot-scopeを通して受け取り、受け取ったデータをslotコンテンツに渡して描画してあげています。
このようなアプローチを取ると、DataProviderコンポーネントが持っているロジックを使い回すことができますし、DataProviderコンポーネントに内包されるコンテンツは差し替え可能になります。
Provide / Inject
VueにはPlugin開発向け、コンポーネントライブラリ開発向けのAPIとしてprovide & inject APIが用意されています。
通常、コンポーネントから他のコンポーネントへデータを受け渡す際は、「親コンポーネントからその子コンポーネントへ」、「その子コンポーネントからその子コンポーネントへ」といった具合に、バケツリレーのようにデータの受け渡しを行なわなければなりません。
しかし、provide & injectAPIを使えば、親コンポーネントから孫コンポーネントへデータを直接受け渡すことも可能です。
ReactではContext APIがこれに当たります。
Parent.vue
<template>
<div>
<h1>Parent</h1>
<child />
</div>
</template>
<script>
import Child from "./Child.vue";
export default {
name: "Parent",
components: { Child },
data() {
return {
// provide対象のデータをreactiveにする為には、このように別オブジェクトで内包する必要がある
sharedState: {
message: "Hello World"
}
};
},
mounted() {
// ここでは、provide対象のデータが更新された時にリアクティブになっていることを単に確認しているだけ
setTimeout(() => {
this.sharedState.message = "Hello Everyone";
}, 1000);
},
provide() {
return {
providedState: this.sharedState
};
}
};
</script>
providedStateという名前でthis.sharedStateを、この後、孫コンポーネントで受け取る事が可能になる。
Child.vue
<template>
<div>
<h1>Child</h1>
<grand-child />
</div>
</template>
<script>
import GrandChild from "./GrandChild.vue";
export default {
name: "Child",
components: { GrandChild }
};
</script>
ご覧にのように、GrandChildコンポーネントにはpropsでバケツリレーでデータを受け渡してはいない。しかし、この後、孫コンポーネントでは、先ほど親コンポーネントでprovideの対象としたデータを受け取る事が出来る。
GrandChild.vue
<template>
<div>
<h1>Grand Child</h1>
<p>{{ message }}</p>
</div>
</template>
<script>
export default {
name: "GrandChild",
inject: ["providedState"],
computed: {
message() {
return this.providedState.message;
}
}
};
</script>
上記のように上位階層のコンポーネントにおいて、provideで公開されたデータを、injectで受け取る事が可能になる。
provide & injectはバケツリレーの回数が多い場合に便利。
ただし、注意点としては、おそらく、ReactのContext APIが辿ったように、VueでもこのAPIは仕様が変更になることが予想されるのと、また、Presentational Componentの中で直接、VuexのStoreを参照している時と同じように、provide側とinject側で強い依存関係が生まれてしまうので、Higher Order Componentなどを用いて、抽象化してあげた方がAPI仕様の変更にも強く、また、疎結合にもなるので、そういった対応が必要になります。
Vue.js のコンポーネント用 Storybook を Single File Component (SFC) で書く
はじめに
はじめまして。Motivation Cloud 開発メンバーの新参者 @navy-field です。
この開発現場では、フロントエンジニアとデザイナー間、あるいはフロントエンジニア同士の円滑なコミュニケーションのために Storybook を活用しています(参考:デザイナーとStorybookをS3上で共有)。
本記事では、そんな中で発見した、VueコンポーネントのStorybookを書く上でちょっと便利な小技を紹介いたします。
よくあるVueコンポーネントのStoryの書き方
Vue.jsコンポーネントのStoryの書き方として、以下のようなパターンをよく見かけます。
test.story.js
import { storiesOf } from "@storybook/vue";
import Test from "./Test.vue";
storiesOf('Test', module)
.add('story as a component', () => ({
components: { Test },
data () {
return {
message: "Hello!"
};
},
template: `<test :msg="message"></test>`
}));
オフィシャルのドキュメントにもこのような形で書かれていますが、この書き方には次のような不便な点があります。
- templateが文字列としてJS内に書かれるのでエディタのハイライトや補完が効かない
- StoryにCSSを当てたいときに別ファイルに定義したりテンプレート内にインラインで書く必要があり、たちまち複雑化する
Vue.jsのオフィシャルガイドに書かれているSFCのメリットの裏返しですね。
これら問題は、Story を Single File Component (以下 SFC) で書くことで解消できます。
Storybook の設定ファイル
SFCでStoryを書く前に、Storybookの設定ファイルを変更して.vueファイルで書かれたStoryを読み込むようにましょう。
config.js
import { configure } from '@storybook/vue';
const req = require.context('../../src/components', true, /.story.(vue|js)$/)
function loadStories () {
req.keys().forEach(req)
}
configure(loadStories, module);
このようにrequire.contextをつかうことで、componentsディレクトリ以下にあるファイルのうち、名前が.story.vueまたは .story.js で終わるファイルを全てStorybookで読み込むことができます。
SFCで書き直したStory
上記 test.story.js をSFCで書き直したサンプルは以下の通りです。
test.story.vue
<template>
<test :msg="message"></test>
</template>
<script>
import Vue from "vue";
import { storiesOf } from "@storybook/vue";
import Test from "./Test.vue";
const testStory = {
components: {
Test
},
data () {
return {
message: "Hello!"
}
}
};
export default testStory;
storiesOf("Test", module)
.add("story as a single file component", () => testStory);
</script>
<template> 内の export default testStory; によって、 vue-loaderがtestStoryにtemplateを組み込んでくれます。
またその下の add() の第2引数の関数の戻り値にtestStoryを指定することで、このStoryをtemplateを含むコンポーネントとしてStorybookに渡すことができます。
これでめでたくStoryをSFCで書くことができました。
おわりに
Storybookで自前のコンポーネントカタログを作ってそのクオリティを徐々に上げていくと能率がアップするし、とても楽しいです。
他にもTypeScriptでStory書いたり、Storyの整理術とかもあるので追々書いていこうと思います。
今後もStorybookを使っていきたいと思っていますが、最近Storybookのコミッター界隈で色々な動きがあったようですね。
(これ とか これ)
今後、宗派が別れて揉めたり、営利企業の介入によって廃れたりしなければ良いなと思うこの頃です。
We are hiring!
モチベーションクラウドは
「すべての組織を変える」
「世界の経営指標を変える」
事を本気で考え、心からそれを実現したいチームが開発しています。
組織に課題を感じたことのあるエンジニアのかたは少なくないと思います。
もし、少しでもこれらミッションやビジョンに共感したり興味があるというかたは
こちら から是非ご連絡ください!
おまけ
Storybook はフレームワークやアドオンのバージョン違いで動かなくなることがよくあるので、
今回のサンプルを動かした環境の package.json を記しておきます。
package.json
{
"name": "sfc-story-sample",
"version": "0.1.0",
"private": true,
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
"storybook": "start-storybook -p 9001 -c config/storybook"
},
"dependencies": {
"@vue/cli": "^3.2.1",
"vue": "^2.5.17",
"vue-class-component": "^6.0.0",
"vue-property-decorator": "^7.0.0"
},
"devDependencies": {
"@babel/core": "^7.2.2",
"@storybook/vue": "^4.1.1",
"@vue/cli-plugin-babel": "^3.2.0",
"@vue/cli-plugin-typescript": "^3.2.0",
"@vue/cli-service": "^3.2.0",
"awesome-typescript-loader": "^5.2.1",
"babel-loader": "^8.0.4",
"babel-preset-vue": "^2.0.2",
"node-sass": "^4.9.0",
"sass-loader": "^7.0.1",
"typescript": "^3.0.0",
"vue-loader": "^15.4.2",
"vue-template-compiler": "^2.5.21"
}
}
採用未経験の私が、なぜエンジニアを採用できたのか?
はじめに
こんにちは、リンクアンドモチベーションでテクノロジー職種の採用責任者をしています@entrylmi(尾上)です。
この記事は、モチベーションクラウド Advent Calendar 2018の17日目の記事となります。
現在リンクアンドモチベーションは、テクノロジー企業化に向けて第二創業期を迎えています。
弊社プロダクトであるモチベーションクラウド及び新規プロダクトの更なる開発体制の強化に向けて、約半年前にエンジニアをはじめとするテクノロジー職種の採用を本格的に推進することにしました。
その責任者として白羽の矢が立ったのが私ですが、エンジニア採用どころか、採用自体もやったことも無い全くの素人でした。
本記事では、そんな私が何を実施しどんな失敗を経験したのか、採用活動当初に戻れるなら、何を実施すべきかについて共有できればと思います。
想定する読者
- エンジニア採用担当者(特にこれからエンジニア採用を行う担当者)
- エンジニア採用に関わるエンジニア・エンジニアリングマネジャー
まず実施したこと(立上げフェーズ:~3ヶ月)
とりあえずエンジニアの方々にお会いする
当初の私は「ダイレクトリクルーティングってなに?」くらいの知識量で、何から手を付けてよいのか全く分からなかったため、とりあえず「餅は餅屋に聞け!」と思い、様々なエンジニアの方々と積極的にお会いしました。とにかく多くの人と面談し自分の感覚を磨くことに注力した結果、工数は想定以上にかかりましたが、エンジニアの方々が転職先に求めることや弊社にマッチする人物像を描くことが出来ました。
小心者の私は「こんなこと聞いたら失礼かな?」「うざいと思われないかな?」と挙動不審な態度で質問していましたが、予想に反し、応募者の方は嫌な顔ひとつせずに、丁寧にフィードバックくださる方ばかりでした。話が盛り上がりすぎて後日飲みに行ったケースもあります(笑)
本フェーズでは、採用担当者が積極的に教えを乞う姿勢が重要だと思いますので、是非実践してみてください。
また、弊社にご入社頂くまでの工程が他社と比べた時に多いと感じる方もいらっしゃいます。
私たちは、弊社と応募者が相思相愛の状態で入社頂きたいという想いから、選考途中でも入社後に一緒に働くメンバーとの会食や面談を複数回設定し、相互理解を図る場を設けている為です。
このような場を設定することにより、弊社と応募者のエンゲージメントが高まり、ご入社頂く確立も各段とUPします。
本フェーズで実施した内容を次に記載します。
ダイレクト・リクルーティング
最初に実施したことは、Wantedly,BizReachにてスカウトメールを月200通程度送付し、1日2~3人の方と面談させて頂きました。面談の場では、弊社のことをお話しさせて頂いただけではなく「スカウトメール文は魅力的でしたか?修正するならどこを修正した方が良いですか?」などとフィードバックをもらえるように質問を準備していました。応募者の方々も親身になって相談に乗ってくださり、「スマホのポップアップはこのように見えるためタイトルをもう少し短くした方が良い」、「そもそも本文が長くて読む気がしないので、プロダクトの説明などはリンクで飛ばした方が良い」などと具体的なフィードバックを頂け、結果としてスカウト返信率も約20%まで向上しました。
転職エージェント
当初、10社以上の転職エージェントの方々にお声掛けしましたが、その時点ではどのような人物像が弊社にマッチするのか、求めるスキルレベルはどのくらいかを明文化出来ていませんでした。
(感覚的には分かるが言語化が出来ていない状況)
そこで、エージェントの方とも基準を一致させるためにも、求める人物像やスキルレベルを明文化しましたが、基準に曖昧な箇所も多かったため、とにかく紹介頂いた方のほとんどとお会いし、応募者の具体的なご発言やご経験を基にエージェント会社へフィードバックするように心掛けました。
それでも、まだお伝えしきれない箇所があったため、次の施策を実行しました。
- エージェントの方が応募者へ説明するための資料/トークスクリプト作成
- エージェントの方々への説明会開催
- エージェントの方とのディナー/ランチを開催し、弊社のビジョンや実現したい世界感の共有
- エージェントの方との定例MTGを実施
上記施策を実行することにより弊社が求める人物像やスキルレベルの基準が擦り合うようになり、結果として開発責任者やテックリードを採用することが出来ました。
様々なエンジニアにお会いしたが採用に繋げられなかった理由
一方、応募者の方々と面談させて頂きましたが採用に繋げられなかった理由も振り返りたいと思います。
魅力的に事業・プロダクトのことを語れない
ありがちなのが人事担当者が面談で募集内容や条件面のみを説明し、応募者へ全く動機づけ出来ていないケースです。まさに私たちもその落とし穴にはまっていました。面談者が弊社の将来像やビジョン、今後の事業の方向性を魅力的に語れなかったため、面談で終了してしまうケースがありました。将来像やビジョンを魅力的に語れるか否かが面接に進んで頂けるかの鍵になるため、トークスクリプトを作成し、毎日のように語る練習をしました。
結果として、面談に来て頂いた方の90%以上が次に進みたいと言ってもらえるまでに改善することが出来ました。お互いカルチャーマッチしない
弊社のカルチャーで重視している例として、STYLEという行動指針がありますが、その指針にあまり共感頂けない方もいます。私たちは、この行動指針に従って日々の業務を行っており、且つこの行動指針はエンジニア文化と非常に密接な関係があるため、今後のエンジニア文化形成の礎として大切にしていきたい指針です。詳細については、技術アドバイザーとして参画頂いているレクター社の広木氏へのインタビューをご参照頂ければと思います。


次に実施したこと(拡大フェーズ:~半年)
リンクアンドモチベーションをテクノロジー企業として認知してもらう
一般的なリンクアンドモチベーションのイメージは「コンサル・営業会社」であり、それを「テクノロジー企業」に認知を変えるために採用広報活動を本格的に行うことにしました。
採用広報活動を開始した当初は、3ヶ月程度広報施策を打ち続ければ、自然と応募も増えるため、応募から採用出来れば良い程度に考えていましたが、応募数は採用広報活動を行う前とほぼ変わらず、目に見える効果は現れませんでした。今となれば当然ですが、採用広報活動は、中長期的に実施することにより効果が現れます(はずです)
採用広報活動において、実施した内容を次に記載します。
採用広報戦略策定
まず、誰に対してどのようなメッセージを届けるかを3Cを用いて整理しました。特に競合と比較し、自社の強み・弱みを整理し、自社のポジショニングを明確にした上で、ターゲットへのメッセージを抽出したことがポイントになります。
リンクアンドモチベーションの世間からの印象を細分化し、それを払拭するようにメッセージを詳細化しました。

最後に、メッセージをどのチャネルでどの順番で届けるかを整理し、アクションに反映しました。

Twitterの活用
私自身リンクアンドモチベーションに転職する際に、入社前に接点を持った人事の方から会社の雰囲気やカルチャーを感じたのを思い出し、その会社で最初に出会い最も深くかかわる人事担当者のパーソナリティーが採用において、とても重要な役割を果たすと考えています。
そこで、弊社で最初にエンジニアの方々にお会いする可能性の高い私のパーソナリティーを、より多くの方々に知って頂くために、Twitterを利用することにしました。
リンクアンドモチベーションの雰囲気やカルチャー及び私自身のキャラに親近感を感じて頂き、一回くらい会ってやっても良いかなと思って頂けるように日々ツイートを発信しています。
ブログの配信
ブログは、Wantedlyを用いて配信しています。
まだまだ、上手く記事化出来ていないため、改善の余地が沢山ありますが、今後はイベントレポートからインタビュー記事まで幅広く掲載していく予定です。
イベント開催・協賛
銀座Rails
リンクアンドモチベーションは、技術交流の場の提供を目的に、GINZA SIXのイベントスペースを提供しています。現在、銀座Railsに毎月利用頂いており、
少しずつではありますが、リンクアンドモチベーションというブランドが技術界隈にも浸透し始めてきました。
元々はイベントオーナーの河野氏にご協力頂き、弊社GINZA SIXのイベント会場を利用してもらうことから始めたことをきっかけに、現在ではRuby on Railsに関わる様々なイベントへの繋がりを広げております。
Ruby on Rails界隈でリンクアンドモチベーションの名をより広く認知させていく為に、
2019年も様々なイベントへの協賛を予定しています。銀座寿司会
銀座寿司会は、エンジニアの方々が技術の悩みを有識者に相談出来る場があったら良いと考え、弊社オフィスが銀座にあることから(銀座と言えば寿司!ということで)、銀座寿司会というイベントを開催しました。
有識者にはエンジニアリング組織論への招待の著者である広木氏だけではなく、他の著名の方々にもお越し頂ける何とも豪華な場にすることが出来ました。

Ruby関連のイベント協賛
Rubyを活用している企業として、Rubyの発展と貢献を目的にRuby Association、Rails Girls、に協賛させて頂きました。これからも積極的にRuby関連のコミュニティやイベントに協賛し、技術の発展に貢献します。

この半年を振り返り、当初から実施すべきだったこと
採用チーム以外の協力を積極的に仰ぐ
立上げフェーズでは、短期施策であるダイレクト・リクルーティングや紹介エージェント経由をメインに活用しており、拡大フェーズでは、中長期施策である採用ブランディングをメインで実施してきましたが、当初からブランディングを実施すべきだったこと、拡大フェーズでも短期施策に注力し続けるべきだったと内省しています。
以前は、採用担当の工数不足を理由に、施策を絞らざるを得ないと考えていましたが、採用活動は採用チームだけが実施するのではなく、全社的に実施するものだと再認識しました。今では、開発チーム全員がスカウトメール送付に協力してくれ、返信率も向上しています。
短期施策と中長期施策の両立を実現するためにも、他チームのメンバーも採用活動に協力してもらえるよう意識を醸成することが重要だと感じています。
当初からあらゆる採用手法を試行しPDCAを回すべきだった
当初からTwitterでの採用活動は知っていたのですが、Twitter経由でのブランディングや採用に懐疑的だったため利用していませんでした。もし、当初からTwitterを利用しておけば、ブランディングも加速していたかもしれないと内省しています。
おわりに
弊社では、採用を最重要業務として位置づけられているのですが、入社当初は正直ピンと来ていませんでした。
しかし、実際に採用責任者として採用させて頂く上で、その人がいなかったら会社の未来が変わっていたかもしれないと感じることが多々ありました。
裏を返せば、採用出来ていないということは、採用出来ていればプラスに変わったかもしれない会社の未来を摘んでいることになります。
また、採用した人が入社後に活躍する姿を見ることが、採用責任者としての一番のご褒美だと感じています。
これからも、採用活動を通じてリンクアンドモチベーションの未来を創っていきます。
SendGridのEventWebhookでBounceイベントがPostされたのにメールは送信できていた話
はじめに
これはモチベーションクラウドAdvent Calendar 18日目の記事です。
モチベーションクラウドではメール配信にSendGridを利用させていただいています。

この記事では先日、SendGridのEvent Webhookの挙動に関して、SendGrid日本代理店へ問い合わせして得られたちょっとした知見を書いていきます。
前提
SendGridにはEvent Webhook機能があり、メールを送信する際に発生するイベントを指定のURLにPOSTできます。
モチベーションクラウドではこのEvent Webhookを利用して、受信側メールサーバへ正常に配信できなかったメールの一覧をエラーメール一覧機能として提供しています。
具体的にはEmail Activityの deferred drops bounces blockなどが発生したメールをエラーメールと位置付けています。
起きたこと
とあるお客様からエラーメール一覧に表示されているメールが正常に受信できている旨の問い合わせがありました。
Event WebhookのPOST先サーバログを確認したところ、以下、2件のEventがPOSTされていました。
- 09:05:16に
deliverdイベントがPOSTされる
09_05_16.log(一部抜粋)
{
"email": "sample-1@***.com",
"event": "delivered",
"ip": "******",
"response": "250 Message accepted for delivery"
}
- 09:09:52に
bounceイベント(type:blocked)がPOSTされる
09_09_52.log(一部抜粋)
{
"status": "5.0.0",
"reason": "552 We failed to deliver mail because the volume of recipient's mailbox exceeded the local limit. sample-2@***.com",
"event": "bounce",
"email": "sample-1@***.com",
"type": "blocked"
}
今回のEvent Webhookの挙動に対する疑問
このページのイベントツリーを 見る限り、
deliveredイベントとbounceイベントはどちらかに切り分けられるように見えるが違うのか。
なぜ、deliverdイベントの直後にbounceイベントが発生しているのか。bounceイベントのreasonを見る限り、ソフトバウンスである。
ソフトバウンスの際は、deferredイベントが発生し、72時間自動再送をしてもだめだった場合にblockイベントが発生するとあるが、なぜ、今回はdeferredイベントが発生していないのか。
問い合わせた内容とその回答(一部抜粋)
1回目の問い合わせ
1回目の問い合わせ内容(一部抜粋).log
下記の事象が発生したため、SendGrid側のEventWebhookの仕様を確認させてください。
【発生事象】
1. 09:05:16に`deliverd`イベントがPOSTされる
{
"email": "sample-1@***.com",
"event": "delivered",
"ip": "******",
"response": "250 Message accepted for delivery"
}
2. 09:09:52に`bounce`イベントがPOSTされる
{
"status": "5.0.0",
"reason": "552 We failed to deliver mail because the volume of recipient's mailbox exceeded the local limit. sample-2@***.com",
"event": "bounce",
"email": "sample-1@***.com",
"type": "blocked"
}
3. 該当ユーザーへのメールは正常に送信される
【質問事項】
1.
受信者のメールボックスが一杯等のソフトバウンスはdeferredイベントが発生すると記載されておりますが、
短時間にbounceが発生する原因は何が考えられるでしょうか?
2.
deliverdが発生後、bounceが発生するのは想定される挙動でしょうか?
1回目の回答
1回目の回答(一部抜粋).log
各ご質問へ回答する前に、事象に関してご説明いたします。
ご連絡いただいた事象は、3で該当ユーザが正常に受信されていることから
宛先サーバが「sample-1@***.com」宛てのメールを正常に受信したのち
転送設定などによって他の宛先へ送信しようとして、そこでバウンスが発生したものかと存じます。
エラー内容は宛先サーバによって異なるため、推測となりますが
メッセージにある「sample-2@***.com」への転送でバウンスしたと考えられます。
Deferredイベントによる再送は宛先のメールアドレスに対するものであるため、
今回のような転送先ではイベントが発生いたしません。
バウンスのTypeは応答内容によってbounceかblockedか決まり、
今回はblockedイベントと識別されたものとなります。
以上より、ご連絡の以下状況となったかと存じます。
・宛先の「sample-1@***.com」にはメールが正常に届き、Deliveredイベントが発生した
・転送先の宛先でエラーとなったため、Blockedイベントが発生した
> 1.
> 受信者のメールボックスが一杯等のソフトバウンスはdeferredイベントが発生すると記載されておりますが、
> 短時間にbounceイベントが発生する原因は何が考えられるでしょうか?
前述のとおり、今回の場合は宛先の先でバウンスが発生したため、
deferredは発生せずblockedイベントが発生したものとなります
> 2.
> deliverdが発生後、bounceが発生するのは想定される挙動でしょうか?
今回のケースに限らず、宛先へリレーする中で問題が起きるケースはございます。
遅延バウンスと呼ばれるもので、詳細については以下をご確認いただけますでしょうか。
https://support.sendgrid.kke.co.jp/hc/ja/articles/206128762
2回目の問い合わせ
2回目の問い合わせ(一部抜粋).log
【質問事項】
1. 宛先メールアドレスで起きたバウンスなのか転送設定されたメールアドレス起きたバウンスなのかの切り分けなどはできないでしょうか?
2. 転送設定されたメールアドレスがソフトバウンスの場合はdeferredは発生しないとのことですが、一定時間(72時間)自動的に再送も行われない認識で良いですか?
2回目の回答
2回目の回答(一部抜粋).log
> 1. 宛先メールアドレスで起きたバウンスなのか転送設定されたメールアドレス起きたバウンスなのかの切り分けなどはできないでしょうか?
今回のようにバウンスのREASONによってはある程度の推測が可能なこともあるかと存じますが、
REASONは宛先サーバごとによって異なるため、切り分けはできません。
> 2. 転送設定されたメールアドレスがソフトバウンスの場合はdeferredは発生しないとのことですが、一定時間(72時間)自動的に再送も行われない認識で良いですか?
以前ご回答差し上げたとおり、転送先の送信は
宛先サーバが行う送信であり、SendGridは関与しないため、
応答内容をみたイベントは発生せず、再送も行いません。
まとめ
-
遅延バウンスや今回の転送先メールアドレスで配送不能となった場合は、
deliverdイベントの後にbounceイベントが発生する - 転送先の送信はSendGridが関与せず、宛先サーバーが行う送信のため、
deferredイベントは発生しない。しかし配送不能レポート(Non-Delivery Report/NDR)はSendGridに返るため、bounceイベントが発生する。 - 転送先メールアドレスでのバウンスか宛先メールアドレスでのバウンスかは正確な切り分けはできない。
スクラム未経験者がチームメンバーと共に暗黒の時代を抜けて、エンゲージメント・レーティングをAAまであげた1年を振り返る
はじめに
この記事は、「モチベーションクラウド Advent Calendar 2018」19日目の記事となります。
モチベーションクラウドにフリーのエンジニアとして参画しておりました@ultrasevenstarです。
現在は英語学習のため一時モチベーションクラウドを離れフィリピンのセブ島で暮らしてます。
ここ何ヶ月かは完全に英語漬けで、全くコードを書いてません。
概要
モチベーションクラウドの開発現場ではスプリント毎にチーム状態を把握するため、モチベーションクラウドで
サーベイを取り、チーム状態を可視化しております。
その指標の一つとしてエンゲージメントスコアとエンゲージメントレーティングがあります。
そのエンゲージメントレーティングが上から2番目のAAになったまでの経緯をつらつらと書いていこうと思います。
当時の背景
参画した当時はモチベーションクラウドは2チームに別れ、それぞれのチームがスクラムマスター、POをもち個別に開発をしておりました。
僕はその一方のチームで開発を担当しておりました。
参画当時は特に大きな問題はなく、平穏に過ごしてましたが
開発の難易度が上がりだしした頃から、徐々にチームの雰囲気が怪しくなってきました。
ベロシティーが上がらないどころか、目標が達成できず落としてしまうことがよくあり
KPTでも「疲れた」や「終わりが見えない」などの根が深そうなプロブレムが頻出し、
振返りも十分に出来ていない状態で、トライを発表しても劇ツッコミを喰らうことも多々。
そんな状態なので、他のチームやお客さんから心配やお叱りの言葉を受けることが多々あり、チーム状態は燦々たる有様でした。
エンゲージメントレーティングも確かCぐらいだったかと。
いわゆる暗黒時代でした。
まずはスクラムを理解するとこから
モチベーションクラウドに参画した当初はフリーランスになって間もないってこともあり、イキってたんやろうなと思います。
スクラムよくわからんしとりあえず俺のやることだけやっときゃええやろう。
とりあえず俺の担当分だけ終わらせとけば問題なし!
スクラムマスター?何それ?PLみたいなん?
みたいな感じでした。
でもそれじゃ二進も三進もいかん状況になってきました。
チーム状況は改善される予兆もなく、相変わらずベロシティーも悪いまま。新たな問題も噴出しつつある。
そんな時にある人から
「君達はスクラムの基本が全然出来ていない。スクラムテストでも受けるぐらいのことはしてみなさい」
と手痛いお言葉を頂きました。
結局この言葉が引き金にはなり、自分の不甲斐なさやその他諸々に怒りも覚えたこともあって、
改めて自分自身振り返ってみると、結局僕がスクラムを全く理解出来ていない
理解出来てないのに改善なんてできるわけがない。って結論に達しました。
なのでまずは最低限のことだけでも理解せねばと
スクラムの入門書と名高い「SCRUM BOOT CAMP」を読むことにしました。
役割の線引き
SCRUM BOOT CAMPを読み終わって、チームの現状と照らし合わせた時に一番乖離があったのがスクラムマスターの立ち位置でした。
SCRUM BOOT CAMPを読む前はスクラムマスターってPL/PM的な立ち位置でチームのマネージメントや意思決定権をもつ人なんやろうなと思ってました。
なので、とりあえず色んなことをスクラムマスターに押し付けてました。
極端ですが本来チームメンバーが対応する必要があるものも何から何までスクラムマスターに押し付け、メンバーは開発だけやってた感じがありました。
スクラムは本来チームメンバーが主体となって色々決めていかないといけないはずが、スクラムマスター頼りのところがかなり多かった。
それって正常なスクラムの形ではないですよね。歪にひん曲がっている。
そんな状態やと改善することも難しい。
まずは正常な形にもっていかないと個々の役割があやふやになり、改善の指標も立てにくくなる。
なので正常なスクラムの形に持っていくために、スクラムマスターにはなるべく本来の仕事だけしてもらうよう、本来の業務以外のタスクは剥がし、役割の分担を行いました。
結論をだす
スプリントの振返りが正常に機能していない原因としては、結論が正しく導き出されていないと感じました。
振返りとしてKPTをやっており、プロブレムからトライを出す段で皆で議論をします。
議論をするんですが、皆思うところはあり、様々な意見が出ます。
色々な意見が出ることは良いんですが、収束させずに話が広がるだけ広がり収集が付かず、時間を迎えてしまうことが多々ありました。
一つのプロブレムに対して深掘りするのは良いんですが、深掘りしてるつもりが別の問題に発展しそれがまた別の問題につながっていく。そして気づけば愚痴になってる。みたいなことも良くありました。
だからファシリテートが必要で、ファシリテーターが結論に持って行ってあげないといけない
じゃないと議論が広がるだけ広がって、時間だけ無駄に過ぎていき、結局何も決まらない
もしくは無理やり強引に結論を作り上げる。みたいなことになります
プロブレムって結構出ますが、グルーピングすると3〜5になり
その3〜5のうちほんまにトライをうち解決が必要なものって1か2に絞れるはずです。
大体一週間もしくは二週間で速攻で解決しないといけない問題が山ほどあるとしたら
そのチームって崩壊してますよね。KPTなんかやってる場合やあらへん。
ですので、挙がったプロブレムを整理し、絞り、それを深掘りし結論に持っていくのが
ファシリテータの役目と考えています。
議論が逸れそうになると本来の道筋に戻してあげるのもファシリテータの役目です。
それさえ気を付けていればそれほど時間もかからず結論も出る議論になるはず
当事者意識
チームでは毎朝モーニングスクラムと言う名の進捗共有会をやっています。
やっているんですが、メンバーの数名かは遅れてきたり途中でトイレに行ったり雑談を始めたりすることが時々ありました。
そうなると余計に時間がかかったり、情報格差が生まれたりします。
最初は腹たったりしてたんですが、改めて客観的にモーニングスクラムを見てると無駄な時間が多いことに気づきました。
ファシリテータが一つの問題に対して深掘りしたいがあまり、一対一の会話になり他のメンバーが置いてけぼりをくらう。
進捗共有にしても、メンバーがファシリテータに対しての報告をする姿勢になっているので他のメンバーは聞いていない。
こんな状態なので、個々の問題は個々の問題のまま。
スクラムが提唱する個の課題はチームの課題という状態には程遠い。
なので、モーニングスクラムの時間を短く15分をめどに終わるようにしし、なるべく皆が集中しやすい環境を作りました。
深掘りについては後ほど時間を取って必要なメンバーだけで話をするようにし、課題の共有を図りました。
そうすることにより、ノイズが排除され課題の共有に集中することが出来、メンバーが課題を認識できるようになり
個の課題がチームの課題、チームの課題が個の課題とすることが出来ました。
他責は避ける
KPTをやってると他責を起因としたプロブレムが出ることがあります。
他責って「言うは易く行うは難し」の典型だと思っています。
同一チーム内では凄く共感を持ちやすいし、凄く言うてる感がある。
なので他責のプロブレムが上がると皆食いついて、それの深掘りをするんですよね。
でも他責のプロブレムって一朝一夕で解決するような問題ではないことが多いです。
だって関わる人数が必然と多くなるし、他人を変える必要があったりする。
どこの現場でも良く出る問題が
- ○○部署が全然情報をくれません。情報共有が出来ていません!
- なんだと?!それは由々しき問題だ!解決しないと
- 私、情報共有するスプレッドシートのフォーマットを作りました
- おっ!そいつは素晴らしい!早速〇〇部署に渡して書いてもらうようにしよう
1週間後
- 〇〇部署が全く書いてくれません
- なんだとっ?!だからあいつらはダメなんだ!
言葉は違えど上記のようなことは良くありました。
そもそも言うてやるぐらいなら言われる前からやってるはず。
この手の問題って言う方言われる方どちらもストレスが貯まり、時間も消費無駄に消費する。
そんな無駄な労力使うぐらいなら自分から聞きに行って、自分で共有してる方が建設的で速効で終わります。
他責が起因となるプロブレムを解決するなとは言いませんが、手間も暇もかかるものだと認識し、他人を変えるのではなく自分で何か出来る手立てはないかを考える方が得策です。
特にKPTでのトライのような速効性に重きを置くものとしては他責の解決は向いてないと考えます。
ホワイトボードで見える化
僕もそうなんですが、進捗の遅れがあったりするとどうしても目を背けたくなるのが人情ではないでしょうか。
でも臭いものには蓋をしてても、進捗の遅れは取り戻せたりしません。
なのでホワイトボードに付箋でタスクの管理を始めました。
ホワイトボードなのでそんな難しいことはせず、残課題をホワイトボードに貼り、終われば剥がす。
ただそれだけ。
ただそれだけなんですが、ホワイトボードに付箋なので否が応でも目につきます。
強制的な見える化です。目は背けれません。
これがもしスプレッドシートや他のウェブサービスなら一度そのURLを叩く行為が必要になり
必要が無ければ目にする必要もない。
でもそれじゃ結局スクラムマスターや一部のメンバーしか状況が把握出来ない。
それじゃ当事者意識も生まれにくい。
なので、否が応でも目に入るようにホワイトボードでタスクを管理し皆の目に入るようにし、タスクの共有化を図りました。
情報は足で稼ぐ
メンバーの状況を把握するため、一日最低一回チームメンバーと話をすると勝手に自分の中で決めました。
なので時間が出来ると皆の席まで行きほぼ雑談ですが話をしてました。
日々のモーニングスクラムやslackでも良いんですが、情報は一方通行で生の声は得づらい。
やはり個別に無駄話でも良いので話をしていると色々と情報が得られるし、仲も深まります。
また他のチームメンバーとも話も出来るので他のチームの状況も知れてそれを自チームにも落とし込めます。
お陰で皆には良く「暇なんですか」と言われましたが。
まとめ
そんな感じで細かい改善を繰り返してると、
自チームのモチベーションクラウドのエンゲージメント・レーティングがAAになっており、その状態をキープすることが出来ました。
改めて振り返ってみるとSCRUM BOOT CAMPに載っているような改めて書くようなことでもない基本的なことだらけでした。
でもその基本的なことが一番有用なのだなと感じた一年でした。
QAとしてアジャイル開発で実践すべきこと
はじめに
モチベーションクラウドの開発にQAマネージャー、テストエンジニアとしてジョインしている
masao-shimadaです。
日々プロジェクトの中でQAとしてどのようなことが出来るかを模索する日々です。。。。
概要
アジャイル開発において、QAの目線で失敗した経験談から実践すべきことを投稿させていただきます。
「アジャイルのQAってどうすりゃいいの?何すんの?」って方に読んでほしいです。
アジャイル開発プロセスについて
QAは、開発のスクラムチームと同一チームにする
開発とQAを別のスクラムチームとして実際に運用しましたが、遥かに同一チームでいることの方がメリットが大きいと感じました。
別チームによる運用した時の、体制と役割、起きた事象について説明します。
- 実際に運用したチーム体制と役割
| チーム | メンバー | 役割 |
|---|---|---|
| 機能開発チームA,B | PO、SM、開発メンバ | ストーリーから機能開発、単体テスト実施する |
| QAチーム | SM、QAメンバ | 開発された機能について結合テストし、 リリース可能か判定する |
-
運用して実際に起きた事象
- 機能開発チームは単体テストまで実施することに注力するため、QAチームまで意識がいかない
- 機能開発チームのPO,SMは自チームの開発に注力しているため、QAメンバーが仕様把握したくても時間が無い(チームメンバのフォローでいっぱいいっぱい)
- QAメンバーは、仕様把握不十分のためテスト設計、実行の考慮漏れがスプリント後半で発生し、手戻りが発生
- テストを設計、実行中に仕様変更が発生しても、別チームのためQAメンバが気づけない
プロジェクトがアジャイル開発に慣れてきた頃、KPIであるベロシティの数値向上に全力だった各チームにとって、別チームの状況を把握する余裕がなかったというのが現状でした。
同一チームに変更後、SM、PO、開発、QAが連携し、ベロシティの安定、向上することを目標にすることで
良い品質のプロダクトが生まれていくことを実感しました。
ストーリー内のタスクを開発とQAで分担する
開発するうえで、ストーリーを開発、QAで分割するか、同一にするかの運用も苦慮しました。
例えばストーリーを分割した場合、以下のようにしていました。
- 開発,QA分割ストーリーの完了条件(例)
| ストーリー名 | タスク担当 | 完了条件<機能> | 完了条件<タスク> |
|---|---|---|---|
| サーベイ担当者は、 エンゲージメントサーベイの スコアを表示したい |
開発メンバ | 結果画面にスコアに表示されること スコアの計算結果が正しいこと |
仕様把握 実装 単体テスト |
| サーベイ担当者は、 エンゲージメントサーベイの スコアを表示したい《結合テスト》 |
QAメンバ | 結果画面にスコアに表示されること スコアの計算結果が正しいこと |
テスト設計 テスト実行 |
ここでの失敗は、完了条件としての分割ではなく、担当者単位のタスクでの分割を安易に選択してしまったことでした。
-
運用して実際に起きた事象
- QAストーリーは、開発に依存するため、完了できないことがあった。(テスト設計タスクのみ完了している状態)
- スプリント計画後にバックログ内のQAストーリー入替が都度発生し、管理が煩雑になってしまった。(テスト実施出来ない為、新しいストーリー入れる、など)
- リリース時、ストーリー単位で管理しているため、開発、QAどちらもストーリーが完了しているか把握することに工数がかかってしまった。
正しい選択としては、①ストーリーの完了条件を分割、②スプリント期間内で終わらせる見積で計画を立て、③開発、QAでタスクを分担することでした。
結果、開発、QAが一つのストーリーに向け完了する動きが生まれ、計画やリリース管理もしやすい運用もしやすい状況が生まれました。
テストについて
テスト対象範囲は、ユーザーストーリーの完了条件から洗い出す
テストをする際、必要となる情報は以下のようなものがあります。
- 対象画面(対象機能)
- 実行手順
- テスト観点(画面表示、ページ遷移など)
- テスト結果
- テストパターン(バリデーションチェック、エラーパターンなど)
これらは、ストーリーの完了条件から推測し、洗い出すことが重要です。
逆を言えば、完了条件に無いものについては、対象範囲から外すことを意識しました。
仕様認識合わせは、PO、開発を巻き込んで対面で行う
テスト設計する上で仕様認識合わせは必須です。
テスト対象範囲と判断したものが正しいか判断が必要な為です。
私個人としては、ストーリーに関連するPO、開発、QAが対面で行うこと重要だと考えています。
実施タイミング
スプリント開始直後
事前準備
PO … 事前にストーリーの内容を把握
開発 … ストーリーから実装範囲、不明点を整理
QA … ストーリーからテスト対象範囲、不明点を整理
認識合わせでやること
①ストーリーの対象範囲を詳細まで洗い出し、実装漏れ、テスト対象漏れが無いように確認する
②各担当者の不明点を確認し、不確実性のあるものが無いようにする
スプリント開始直後でストーリーに対して共通認識を持つことで後半に発生する抜けや手戻りを最小限に抑えることが出来ます。
また、2者間(POと開発、開発とテストなど)のみで行った際の他者への共有漏れなども防ぐことが出来ます。
1,2週間のスプリントで、1時間、1日の遅延は致命的のため、無駄な工数は可能な限り発生しないように動いていました。
この考えは、コンサルとしてジョインしているRector社の広木さんに教わり、下記書籍を読んで実践したことにあります。
エンジニアリング組織論への招待
~不確実性に向き合う思考と組織のリファクタリング
テストケースは、境界値分析、バリデーションチェックに関連する事項から優先的に洗い出す
テスト工数は、テストケースの増加に基本比例します。
そのため、ケース増加に関連する境界値分析やバリデーションチェックに関わるテストケースを優先し洗い出すことで、テスト工数の把握が容易になります。
テスト工数から実施完了日、人数をスプリント完了までに一人で完了が厳しい場合は、即座にSMと連携し、テスト実施人員の調整をすることも可能です。
常に意識すること
プロジェクトメンバー全員へのRespectを忘れない
QAは仕様把握やテストデータ作成、環境構築など開発やPOに依存する部分が多く、他のプロジェクトメンバーの作業を止めてでも協力を仰ぐ場面が多々あります。自分の役割の作業が多くある中、手を止めて話を聞いてくれます。
その姿勢や考え方に、感謝、尊敬する気持ちや行動を常に意識することが重要だと思います。
モチベーションクラウドの開発チームには、Respectの文化があり、メンバー個人がメンバーを尊重する文化が根付いています。チーム全体で意識しあえる、この関係性が最高のプロダクトを生む環境であると確信してます。
最後に
このAdvent Calenderの投稿機会を頂いて、自分を見つめなおしアウトプットする良い時間になりました。
今後も、チームメンバーで良いプロダクトになるようQAとして携わっていきます。
新人でもできる信頼関係構築のレシピ
もうすぐクリスマスですね。この記事はモチベーションクラウド2018年アドベントカレンダー21日目になります。昨日は@masao-shimadaさんのQAとしてアジャイル開発で実践すべきことでした。お疲れ様でした。
僕は、この12月からモチベーションクラウドの開発部門に入ったばかりの新人です。前職ではテックリードもやったんですが、まだまだアプリケーションの仕様や使ってる技術を把握はできておらず、チームの皆さんにおんぶにだっこ状態です。
そんな仕事の成果ではなかなか貢献できない中、少なくともみんなと楽しく仕事をするために「信頼関係を築こう」と3週間ほどいろいろと動いてきました。
転職や移動、配属などで、仕事内容以外で信頼を築く必要がある人の助けになれば幸いです。
前提1:組織においてルールよりも信頼が大事
「厳密なルールよりも信頼を想像することが大事」だとリンクアンドモチベーション代表の小笹さんも言ってましたがその通りだと自分も思っています。ルールは増えると結局運用仕切れないし曖昧な部分も絶対に残ってしまう。それをカバーするのが信頼という考えです。
逆に言うと信頼があればルールは少なくて済むので仕事もしやすくてハッピーです。
なんでもいいので信頼を築くことはお互い楽しく過ごすために必須のことだと思っています。
前提2:他の人がやってないことをやるほうが信頼は築きやすい
人の評価は相対評価になりやすいです。部の全員がフロア内に響き渡る大声で挨拶をしている中で、「大きな声で挨拶をしよう」と決めてやっていても、それはなかなか評価されません。
でも、みんな遅刻ギリギリで来る会社で一人だけ朝6時には出社してるとしたらどうでしょう?それは、「あいつはいつも早く来ている」という認識になり、結果信頼が構築されると思います。
他の人と違うことをするというのが信頼を築くポイントです。
やったこと1: 「挨拶をする」(ザイオンス効果)
仕事で成果が出せない以上、やれることは少ないです。なので、誰でもできる「挨拶」を超本気でやることにしました。
殺伐としたチームならいざしらず、モチベーションクラウドの開発チームはみんな普通に挨拶します。それと一線を隔すために「各人と目を合わせながら挨拶する」ようにしてます。
毎日しつこいくらいやるので、やりすぎて「グリーティングハラスメント」(通称: グリハラ)というワードまでできちゃいましたw
最近では他の新人エンジニア達も巻き込んでやってます。
なんでもないことですが、そこで生まれる会話もあるし、お互い気持ちいいのでおすすめです。
行動心理学的にも接触する機会が増えるごとに、抵抗がなくなっていくといわれてるので、接点を増やすのは信頼を築く上で大事な行為かなと思います。
やったこと2: 「寝癖を直す」(リスクヘッジ)
前職だと、寝癖はもはやトレンドマークになってたんですが、リンクアンドモチベーションはコンサルティングがメイン事業の会社であり、開発メンバー以外はビジネスカジュアルやスーツの人が多いです。
きちっとした格好をすることは求められてないですし、今もジーパン&Tシャツですが、寝癖は人によっては嫌悪感を抱かせてしまうリスクがあるため、寝癖は直すことにしました。
前職の人に会うと「成長したね」と褒められますw
格好に制限がないとしても、「見た目は9割」「第一印象は5秒できまる」などといわれるなかで、せめて嫌悪感を抱かれないようにするのは大事かなと思います。
やったこと3: 「毎日半袖でいる」(ブランディング)
これは意図したわけではないのですが、GINZA SIXのオフィスは空調が素晴らしく冬でも過ごしやすい環境です。
もともと体温が高いので、冬でもオフィスの中では半袖でいたら「寒くないですか?」と話しかけられるようになりました。
たまたま半袖がなかったので長袖で出社したら驚かれちゃったので、その日は腕まくりでいることに。。。
そんなこんなで見事「冬でも半袖でいる変なやつ」というブランドが構築され、床に座りながら障害対応していてもよい権利を得ましたw
最後に
信頼関係は約束を守ることを積み重ねることによって築き上げられます。上記は勝手に期待を作り上げることで暗黙の約束を作って、その期待に答えることで約束を守っている感じです。
とはいえ、ビジネスにおいてはやっぱり仕事の成果が一番の信頼要素です。
これからは「すべての組織をこれで変える」ためにモチベーションクラウドも開発チームも最高の作品にできるように、最大限貢献していこうと思います。
みなさま、不束者ですがよろしくおねがいします。
【フロントエンドエンジニア向け】今年お世話になった英語圏の動画学習サービスまとめ
はじめに
こんにちは、モチベーションクラウドの開発にフリーのエンジニアとして参画している@HayatoKamonoです。
この記事は、「モチベーションクラウド Advent Calendar 2018」22日目の記事となります。
概要
Webのフロントエンド分野と言えば、技術の移り変わりが激しいことでも有名で、この目まぐるしく移り変わる技術の変化に対応していかなければ、あっという間に置いてきぼりを喰らってしまいます。
React? Vue? Next? Nuxt? RxJS? Functional Programming? Elm? Ramda.js? GraphQL? Firebase? PWA?
そんな次から次へと新しい技術へのキャッチアップを余儀なくされるフロントエンドエンジニアにオススメなのが、日本ではまだ情報量が充実していない比較的新しい技術に関する情報も一足早く体系化し、まとまった動画コンテンツとして提供してくれている英語圏のエンジニア向け学習サービスです。
英語圏のサービスなので配信される動画コンテンツも英語ではありますが、たいていのサービスでは、英語字幕が付くので、リスニングに自信の無い方であっても、英語がそこそこ読めさえすれば、これらのサービスの価値は得られると思いますし、また、英語の学習にもなって一石二鳥です。
というわけで、この記事では、普段から私が利用している英語圏の学習サービスをご紹介致します。
Frontend Masters
このサイトでは、名だたるTech企業の第一線で活躍している現役エンジニアが定期的にワークショップを行い、それらの映像がオンラインでライブ配信されます。このサイトのサービス利用者はライブ配信されるワークショップにリアルタイムでオンライン参加することも出来ますし、後日、編集された映像の配信を待って視聴することも出来ます。
「Frontend Masters」という名前がサイトについているだけあって、フロントエンド技術に関するコンテンツが主となりますが、フロントエンドエンジニアを対象にしたバックエンドやインフラ関連のコンテンツも提供されています。
講師もカンファレスに登壇しているような人ばかりでレベルも高く、全体的にコンテンツのクオリティーも高くて、オススメのサービスです。
- 月額: $39
- 字幕: 英語
- 再生速度: 0.8 ~ 2.0倍速
- モバイルアプリ対応: 有り
egghead

このサービスもフロントエンドエンジニアをメインターゲットとしている、フロントエンド技術に関する動画コンテンツが主コンテンツの月額サービスですが、フロントエンド以外の技術に関する動画コンテンツも配信しています。
先に紹介した「Frontend Masters」より講師のレベルにバラツキがあったり、講師に納品されたコンテンツの質をサービス運営側がレビューしていなかったり、コンテンツのフォーマットも講師によってバラバラで統一されていないので、その辺が利用していてストレスに感じるところがあります。
ただ、このサイトの特徴としては、1本1本の動画が短めで消化しやすいので、何か気になるコンテンツがあったら気軽に観るといった使い方がしやすいです。
私はこのサイトをメインの学習サービスとして利用する気にはならないですが、他のサービスに比べて更新頻度が高いため、サブの学習サービスとして利用しています。
たまに「解約しようかな」と思うことはありますが、そんな時に限って、気になるコンテンツが配信されるので、解約のタイミングを逃してしまいます。。。
- 月額: $40
- 字幕: 英語
- 再生速度: 1.0倍速
- モバイルアプリ対応: 無し
Pluralsight
「Pluralsight」はフロントエンドエンジニアやエンジニア全般だけをターゲットにしたサービスではなく、ITスキルに関する幅広いコンテンツを提供しているサービスで、デザイナー向けや映像クリエイター向けのコンテンツも配信されています。
プログラミングに関するコンテンツで言えば、言語はJavaScriptだけではなく、PythonやJavaなどの言語もカバーされていますし、また、アジャイル開発に関するコンテンツやプロジェクトマネージメントに関するコンテンツもカバーされています。
サービス運営側が講師から納品されるコンテンツの質をレビューしていると思われ、コンテンツの質も一定以上の期待出来ます。また、コンテンツのフォーマットにも一貫性があり、講師によって動画コンテンツの構成が大きく異なるということもありません。
金額は他のサービスと比べると低めに設定されているものの、コンテンツの量は膨大でお得感があります。また、前述の通り、質も高めです。
- 月額: $29
- 字幕: 英語
- 再生速度: 0.5 ~ 2.0倍速
- モバイルアプリ対応: 有り
Udemy

最後にご紹介するのは日本でも有名な「Udemy」です。
Udemyはこれまでご紹介したサービスと違って、月額サービスではなく、コンテンツを単品購入する形式のサービスですが、Udemyはキャンペーンを度々行なっており、キャンペーン期間中になると普段1万円以上の教材コンテンツも書籍くらいの金額になったりするので、そういう時に気になる教材コンテンツをちょくちょく買ってしまいます。
日本語のコンテンツは滅多に買わないので分からないですが、英語の教材コンテンツに関して言えば、ユーザーの評価が高く、購入者数も多いものであれば、コンテンツの質は高いことが多いので買って後悔することはあまりありません。
- 単品購入: 金額はコンテンツによる
- 字幕: 英語、自動翻訳の日本語字幕
- 再生速度: 0.5 ~ 2.0倍速
- モバイルアプリ対応: 有り
まとめ
比較的新しい技術となると、日本ではそれらに関する記事がポツポツと投稿されているだけで、体系だったコンテンツとして提供されていなことが多いです。そういう時に、英語圏の学習サービスで提供されている体系化されたまとまったコンテンツを利用すると、学習効率も高く、助かります。
英語の学習にもなり、一石二鳥なので、もし今回ご紹介した月額サービスの中で、利用したことがないサービスがあれば、まずはフリートライアルからお試しアレ!
番外編
今年に限らず、私がメインで利用している英語圏の動画学習サービスは以上の通りですが、他にも単発で利用したものがあるので、それらも番外編としてご紹介いたします。
Vue関連
元々、私はReactを使っていましたが、今年の7月からフリーのエンジニアとしてジョインしたモチベーションクラウドの開発プロジェクトではフロントエンドのフレームワークにVueを使っているため、上記で紹介したサービスの他にも、以下の3つのVueに特化したコースやサービスにも登録し、Vueの知見を得られるように努めました。
Advanced Vue Component Design
参考になった!
Vue Mastery
そこそこ得るものはあった。月額制。解約済み!
Vue School

買ったは良いが、あまり観ていない!
テスト関連

Testing Javascript - Pro Testing course
「Frontend Masters」や「egghead」でもコンテンツを提供しているPaypalのKent C DoddsによるJavaScriptとReactのテストに特化したコース。
良い!
GraphQL関連
GraphQLはUdemyのコースや「Frontend Masters」で配信されているコンテンツでも学習したが、それらとは別にボリュームのある以下のコースも購入して学習しました。

Fullstack Advanced React & Graph QL
CSS Grid
今年は先延ばしにしていた「CSS Grid」も以下のコースで学習しました。

元々、以下の「Flexbox Zombies」というFlexboxをゲーム感覚で遊びながらも、しっかりと完全に理解するというコンセプトの無料で提供されているコースを以前利用したことがあって、これが非常に良かったため、「Grid Critters」は有料でしたが課金しました!

エンジニアリングマネージャーやVPoEの実体験を通じ痛感したことと感謝
こんにちわ! これは「モチベーションクラウド Advent Calendar 2018」 23日目の記事です。
はじめに
リンクアンドモチベーション社の開発に参加してまだ間もないため、過去にエンジニアリングマネージャーやVPoEをやるなかで経験した、多くの悩みや失敗、喜び、感謝を通じて学んだことを中心に書きたいと思います。
ちょうど最近他社のエンジニアリングマネージャーやCTOと以下のような点について会話することがありました。
1. エンジニアリングマネージャーの役割と誤解
2. エンジニアリングマネージャーのコミュニケーションの考え方
3. エンジニアリングマネージャーのオンボーディング
4. エンジニアチームのパフォーマンスに影響を与える要素
5. エンジニアチームの成功
6. エンジニアチームの自己評価(!=査定)
7. エンジニアリングマネージャーを面接する際の質問
など。今回は2、4を書こうと思います。(急遽投稿日が23日になったため笑)
ご支援いただいているRector社の松岡さんと広木さんとも今度話してみたいです! 結果をまたどこかで書きたいと思います。
注意
・スキルよりも考え方多め。
・あくまで体験して感じたことなので、学術的視点やセオリー的にはおかしなところがあるかもしれません。
エンジニアリングマネージャーのコミュニケーションの考え方
ずっと蓄積されていく資産、と捉えています。P/LとB/SでいうとB/S。一方向ではなく、双方向で初めて溜まるもの。
エンジニアリングマネージャー に限った話ではないのでは?
もちろん「エンジニアリング」マネージャーに限ったことではないと思います。エンジニアの場合、仕事の性質上、集中してまとまった時間を取れるかどうかが成果を左右する大きな変数であるため、都度打ち合わせすることよりも、Slackなどの非対面の方がやり取りが多く、手段も増え、ほか職種に比べて大変だと思います。
ですので、コミュニケーションに対して、一定の優先順位の意識がなければ、流れるばかりになってしまいます。「言いました」⇆「見ていません」という議論に発展したこともあります。
体験
お恥ずかしい話ですが、初めてマネジメントした時の自分のコミュニケーションはこんな感じでした。なんでこんなことができないのか?これをこうしろ、相手の話を遮る、など今考えると酷いもので、相手の自己効力感は下がりまくる…私のいない飲み会では悪口ばかりだったと思います笑 *10年ほど前です。

そもそも変化の激しい(VUCA)の時代では事業の前提条件が刻々と移り変わります。制約が大幅に変わる可能性が高く、指示通りに頑張るだけでは必ずしも結果が出るとは限りません。もはや特定の誰かが変化をとらえてアクションを考えるのでは間に合わないほど変化する要素が増えています。だからこそ、各自が考えて行動できる自走型になる必要があるのだと思います。
言葉では自主性や自走を求めながらも、前述のようなコミュニケーションやマネジメントスタイルでは人は去るわ、みんな楽しそうでないわなど、当然の結果だったと思います。
粘り強く指導してくれた当時の社長、後輩のおかげでようやく改めることができ、以下のようなスタイルに変わって行けたと思います。結果、離職率も激減し、目標も達成する組織へと変わっていけたと思います。
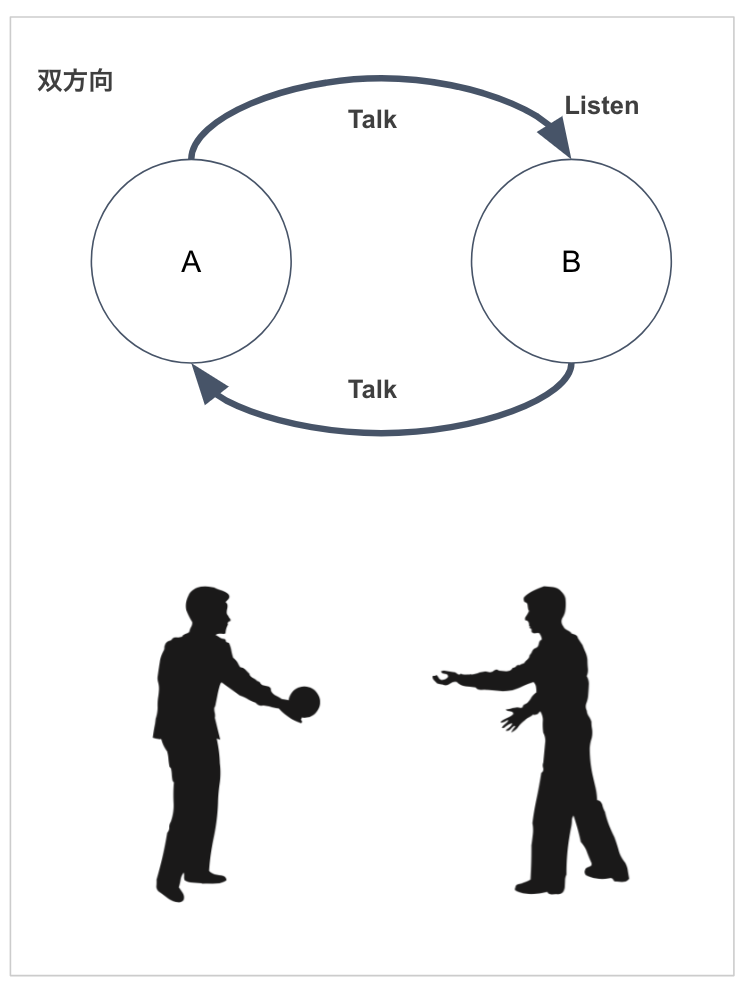
加えてたまたま「大量のコミュニケーションが仕事をより早く円滑に完了させている」という研究結果 (ハーバードビジネススクール Tsedal B.Neeley教授ら)というのも目に留まり、量を増やすことも合わせて、コミュニケーションを改善していきました。
コミュニケーションだけで全てがよくなるわけではないと思いますし、相手のレベルや内容によっては指示や強い命令も必要だとは思いますが、
広木さん の 心理的安全性ガイドライン(あるいは権威勾配に関する一考察)
にもある心理的安全性への影響は大きかったと思います。
具体的にやったこと
効果が高かったと思うことを5つ。どれも地味です。。。
| アクション | 補足 |
|---|---|
| 日報や週報へは必ずリアクション | どんなに忙しくても移動時間など1日に5分、10分は取れるはずです。 |
| 1on1 | 重要性やノウハウはいろんなところで言われていますので割愛します。試行錯誤の中でも特に、上下だけでなく、斜めも/8割は相手に話してもらう。聞くことへのコミットメントが大事/相手のための時間と位置付けて、対象者にテーマを設定してもらうようにすること、などが気づきが多く効果的だったと思います。 |
| 態度(ex.話を聞くときはスマホやパソコンは触らない、ちゃんその人を向く(足を組んだり踏ん反り返ったりしない) | 心ここにあらずの態度として伝わってしまいます。メラビアンの法則(人は非言語の要素で多くを伝えている) |
| Slackなどのチャットとあらかじめの合意 | 極力見ます。どうしても全部は無理な場合があるので、ストックすべき情報、定例でフォローする設計を行い、これをメンバーとも合意しておくことがいいと思います。 |
| 沈黙を堪える | 前述の態度にも関連しますが、当時の自分が最もできていなかったことです。沈黙が訪れると、その間に耐え切れず、自分から話を始めてしまう人がいますが、そのときはぐっとこらえてみることをお勧めします。せかすことなく相手が話し始めるのを待ってみることで、相手が自身の内側からアイデアや思いを言語化する可能性が高くなると思います。 |
など。
リンクアンドモチベーションの開発組織ではパートナーさん含めてコミュニケーションやフィードバックも多く、日々気づきがあります!(飲み会にもよくお誘いいただき幸いです!)
エンジニアチームのパフォーマンスに影響を与える要素
エンジニアのモチベーション、心理的安全は言うまでもありません。
そのほかには、
- 個々のスキルレベル
- アーキテクチャと組織の整合性(アーキテクチャに合わせてパフォーマンスが発揮できる組織や構成をデザイン。マイクロサービス、モノリシック)
も影響度の大きい変数だと思います。
加えて大事なのは、
意思決定の精度(事業、業務理解の促進)・・・どれだけ自分たちで正しい意思決定ができるか?
という意見が多かったです。そう思いましたし、これまで痛感してきました。
ありがちな問題
- ほか組織やプロダクトマネージャーと社内受発注関係になりエンジニアのモチベーションダウン・・・
- スタートアップなど少数の時は開発速度が早かったが、だんだんと遅くなってきた・・・ 開発組織のみが独立したプロセスで考えてしまい、事業組織との足並みがあわずに、結果として差し込み開発が入るなどして開発効率が低下する・・・
など体験したことがある人は多いのではないでしょうか。
スクラムやリーン、仮説・検証などのプロセスで解決することも大事だと思います。しかし、エンジニアやそのチーム自身が高い精度で意志決定できる状態になることが望ましいのではないか?と思います。
そのために必要なことは?
エンジニアがビジネス(お客様、市場、競合、自社)について深く理解することが必要だと思います。会社が置かれている状況と、その状況で成功していくための戦略を、確実に飲み込むこと。全体の目標、戦略、期待、収益、機会、脅威、どのように利益を上げているのか、もっとも大切なことは?など。
自分自身もまだまだなため、自戒9割ですが、とても大事なことだと考えています。
なぜか?
ゲームなどのtoCやエンジニアのコードが直接売上などの数字にヒットするような領域の場合はその限りではないかもしれませんが、エンジニアが技術領域だけに目を向けてしまい、(それが意図を持ってコントロールされたものでない場合、)自分が携わるビジネスに対して受け身にしかなれず、それでは多くの場合、やらされ感が積もるし、営業やコンサルなどのほか組織と受発注関係になり兼ねません。もちろん開発や運用などのスキルは広く、深いに越したことはないですが、技術を使って、ビジネスをどうドライブするか?この意識と経験値の蓄積が重要だと感じています。
そのためにはやはりビジネスの理解が欠かせません。持っている情報が同じで、価値観が揃っていればそこまで大きくずれたりもしないとも思います。ですので、継続的にコンテキストの理解を促す仕組みも必要だと思います。
具体的にやったほうがいいと思うこと
これについては銀の弾丸的なものはないと思いますし、特効薬は見つかっていません。。。営業同行することや勉強会、KPIツリーなどで同じことを見るように、など。継続的なコンテキストの共有としては、会議体の設計もとても重要だと思います。きちんと情報が流れる設計になっているか?などなど。
そのほかに、実績のある他の方から聞いて、他社や市場の理解のために、「個人の取り組み」としてこれはよかった!と教えてもらったものを1つだけ紹介いたします。
expoなどの展示会やイベントに行きまくること
とのことでした。多くの場合無料ですね。とても活きた最新の情報が学べて有意義だったとのことです。
リンクアンドモチベーションでは、このイシューに対し、オンボーディングから継続的に学ぶ仕組みがしっかりしており、学びがとても多いです。今度整理できたらどこかの機会にアウトプットしたいと思います。
最後に
このアドベントカレンダーの取り組みを通じ、パートナー様もみなさんとても積極的に書いていて驚くことばかりでとても素敵だと感じました!今後もこういったことを継続していきたいと感じました。
リンクアンドモチベーションは組織やモチベーションを大事にする強烈な文化があります。これは日々強く感じています。引き続き、より良いサービスの改善に向けて組織で一丸となっていきたいと思います。
今回は全てを書ききれていませんが、ご意見、ご感想や「うちはこうしてるよ!」みたいなコメント大歓迎です!
積極性と強い問題意識を要求する「振り返り」は、もうたくさん
「この人たちのために成長したい」といつも自分を駆り立ててくれる、大好きな職場のみなさんに本稿は捧げます。

はじめに
これからの人生で、チームで「振り返り」をする可能性が1%でもある方々に本稿は贈らせていただきます。
皆さんの「振り返り」が行われる前にもう一度、読んでいただき、参考にしていただければ幸いです。
「振り返り」への違和感
「積極性」と「強い問題意識」を持ったメンバーがいることを前提とした方法論ばかりが叫ばれることに私は強い違和感を感じています。
その目的や背景は置いといて、「過去に起きた出来事をチームメンバーと共に目を向ける過程全般」を本稿では「振り返り」と呼びます。
業務改善、PDCA、KPT、スクラムのレトロスペクティブ、といった過程の一部に含まれており、「振り返り」は広く知られた活動と言えます。
しかし、これらの内容は、
- 「問題があれば主張し、必ず、議題にあげる」という個人主義的な文化圏にメンバー全員がいる前提である
- 「1人の優秀な人間が推進し改革する」というコンサルテイスト(BP改善)
といった内容が見受けられ、そのまま実行すれば、成功が保証されるような代物ではないように思われます。
なぜなら、次のような状況にチームが立ち向かう必要があるからです。
- 本音を話すことができないメンバーがもちろんいるので、すべての問題が机に並ばないことがある
- 無関心なメンバーがいる場合、チームの活動として継続しにくい
- 課題の捉え方やその温度感が揃わず、チーム全体がなかなかうまくまとまらない
こうして考えてみると、現実の「振り返り」の場には、様々なメンバーがいて、「やる気があり問題をどんどん挙げてくれる」メンバーだけではないことがわかります。
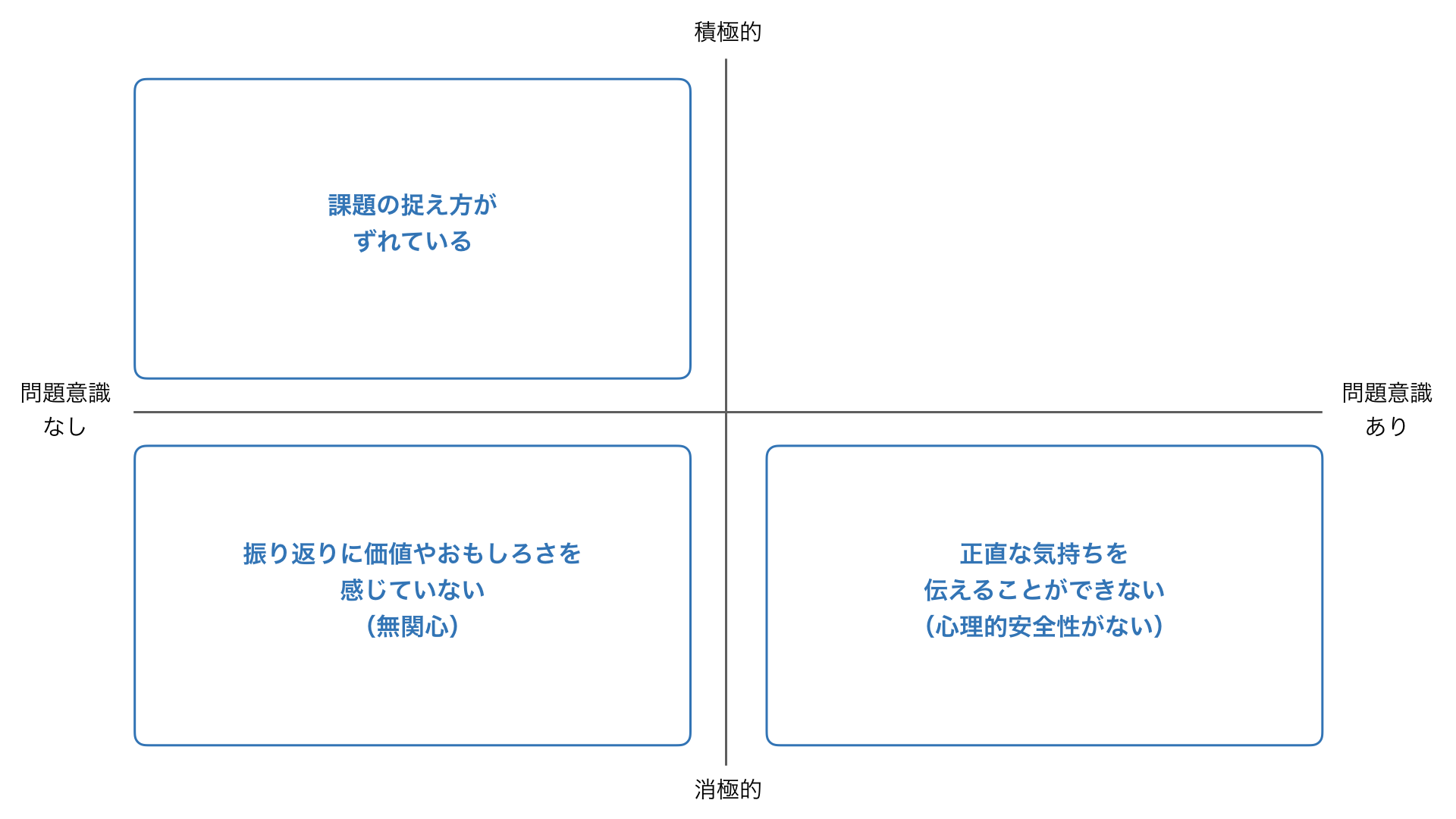
実際に、振り返りを始めたばかりの頃など、「消極的なメンバーが7割で、積極的だけど課題感がずれているメンバー2割」というような状況はよくあるのではないでしょうか。
自分の意見を外に出すのが苦手なメンバーを軽視した方法や全員が最初からやる気がある前提のプロセスをいきなり導入しても、必ずボロが出ていずれ崩壊します。
一般的な「振り返り」の方法論は、メンバーが積極的に参加してくれて問題意識を強く持っている夢のような状態でのみ成立するものばかりで、私自身、現実とのギャップに苦しみました。
では、どのようにしてこの状況を乗り越えればよいのでしょうか?
「振り返り」の共感度が高いチーム
「振り返り」の質をあげるプロセスをつくる前に、「振り返り」の共感度が高いチームをつくる
この1年間、10数個のチームを隣でみてきて出した私なりの答えです。
そして、チームの成否を分けた要素であったとも思っています。
「振り返り」の共感度が高いチームとは、「メンバーが課題に対して自分の仮説を常に持ち(積極性)、問題意識の方向や温度感が揃っている(問題意識あり)」ようなチームです。

このためには、できるだけ多くのメンバーを「積極的」×「問題意識あり」の領域に引き込むことが大切です。
本稿では、このような状況をつくるための方法を、
1.「積極的」の領域に引き込む
2.「問題意識あり」の領域に引き込む
という2つの切り口から紹介します。
自分は「振り返り」の資格をもった専門家でもなければ、「振り返り」を1万時間以上やりこんだプロでもありません。
この1年間私たちが行なってきた事例をもとにした、1つの分析結果として参考にしていただけますと幸いです。
1.「積極的」の領域に引き込む
「振り返り」に対して消極的なメンバーを減らし、積極的なメンバーを増やすために実践したことをまずは紹介します。

この上で、消極的なメンバーの心理を分析します。
A. 心理的安全性がない
問題意識は持っているがそれを正直に伝えられない、本音を妨げている要因がある状態。B. 無関心
問題意識を特に感じておらず、振り返りの価値やおもしろさも知らない状態
それぞれ2つの領域に分かれ、その対応方針も異なります。
A.「心理的安全性がない」を変える
「心理的安全性がない」=「消極的」×「問題意識あり」

心理的安全性について深く知るために、心理的安全性ガイドライン(あるいは権威勾配に関する一考察) をぜひご一読ください。
「心理的安全性がない」メンバーを変えるためには、正直な気持ちを伝えることを阻害する要因を見つけ取り除いでいきましょう。
しかし、消極的なメンバーが阻害要因を自発的に教えてくれるケースは稀です。
そのため、阻害要因を顕在化するための工夫を私たちはチームで施しました。
「机の上に問題があげられたならば、99%は解決できる」という言葉を聞いたことがありますでしょうか?
私たちも、阻害要因が顕在化してしまえば、そのあとの対策は「対話を重ねて認識や期待を合わせていく」という手段を愚直に実行していき内容としてはシンプルなものが多かったです。
そのため、本稿では阻害要因を発見するために実践した方法に絞って紹介します。
状況の緊急性に応じて次の2つを使い分けました。
【劇薬】本音を言う会
ベテランやマネージャーに席を外してもらうことで、一時的に、心理的安全性が高い状態をつくり、まとめて阻害要因を洗い出す方法。精神的にかなりの労力となるので、ここぞという時に使う。
【持薬】人間関係の行間を読む
「振り返り」で出た発言や行動からメンバーの本音を察する方法。洞察の深さと継続的な観察の原動力となる他人への関心が求められる。
【劇薬】:本音を言う会
ベテランやマネージャーに席を外してもらい、一時的に、心理的安全性が高い状態をつくったあとで、メンバーに本音を打ち明けてもらう方法です。
手順
1. メンバーが本音を打ち明けにくいベテランやマネージャーといった方々に、部屋から一度退出してもらう
2. 各メンバーが匿名で本音を付箋に書き出す(もちろん、合意を取った上で)
3. 本音が書き出されたら、再度、ベテランやマネージャーといった方々に入室してもらい、挙げられた付箋を1つ1つ読み込んでもらう
4. その都度、メンバーとベテランやマネージャー陣、両者の本音を聞いていき、期待や認識を合わせていく
私自身、1年間でこの会に2回参加しました。不満や要望がわかるので解決の糸口はもちろん見つかります。
しかし、それ以上に、仕事への想いや過去の経験、将来の夢に話が発展することが多く、仕事の関係を超えて、1人の人間として「何を思っているか?」を知れるような機会に2回ともなりました。
また、誰からのサポートも受けることができずメンバーからの過度な要求をこらえていた「マネージャーの孤独」をメンバーが知る機会にもなり、よりチームが一体になれた瞬間でもありました。
【持薬】:人間関係の行間を読む
消極的なメンバーの発言や行動を観察することで、本音を打ち明けるのを阻害する要因を発見する方法です。
方法自体はとてもシンプルです。
しかし、阻害要因を見極める「深い洞察力」と、普段からメンバーを観察をし続ける「継続力(人への関心)」がなければ、なかなか実現しません。

私たちの現場でも次のようなエピソードがありました。
あるメンバーのパフォーマンスが明らかに悪いものの、その原因が誰にもわからないという状況がありました。
いろんなメンバーが質問を通して深掘りをしたものの、原因が謎のままに終わり停滞感が漂いはじめていました。
しかし、山下というメンバーが、「会社の先輩でもある、チームのリーダーが怖くて、アラートを正しく伝えられなかった」様子をみていて、「無茶なタスク量をこなしていたのでは?」という仮説を持ち出しました。
山下が、「こういう立場だと、よくある」と伝えると、あるメンバーは
「いくら、無理だと言っても、常に工夫することはできないのか?という押し問答を受けて辛かった」
「実は、ずっと、ぎくしゃくした関係だった」
という本音を明らかにしてくれました。(そのあと、定期的に1on1を開き、正直な気持ちを聞く場が設けられました)
このときは山下の経験則や観察力を頼りに、阻害要因を探しました。
しかし、いまなら、先日投稿された心理的安全性ガイドライン(あるいは権威勾配に関する一考察)という記事の権威勾配を構成する変数にまとまっている観点を頼りにより早く・正確に発見ができるでしょう。

「チームメンバーの人間関係」と「上図の各要素」を一問一答形式で照らし合わせていく「阻害要因ドリル」をつくるなど、今後は様々な方法を試していきたいです。
B. 「無関心」を変える
「無関心」=「消極的」×「問題意識なし」
「振り返りの意義がわからないし、問題意識も特にない」という、いわば、「無関心」なメンバーを「積極的」に変える方法には、2つの切り口があります。
【論理で動いてもらう】
「振り返りは価値がある」と理解してもらい、メンバーがひとりでに行動が変えていく方法
【感情で動いてもらう】
「振り返りはおもしろそう」と感じてもらい、周りに巻き込まれながら行動が変わっていく方法
【論理で動いてもらう】
「振り返りは価値がある」と理解してもらうためには、「振り返り」によって起きる変化を観測して、その効果を理解してもらう必要があります。
「定量」・「定性」の観点で、実践した2つの方法を紹介します。
定量:フォーカスサーベイで、改善を数値化
前回までの「振り返り」で決めたアクションプラン(Try)の効果を、モチベーションクラウドを使って数値化しました。
目に見える形で、振り返りの価値を伝えて理解してもらおうとした試みです。
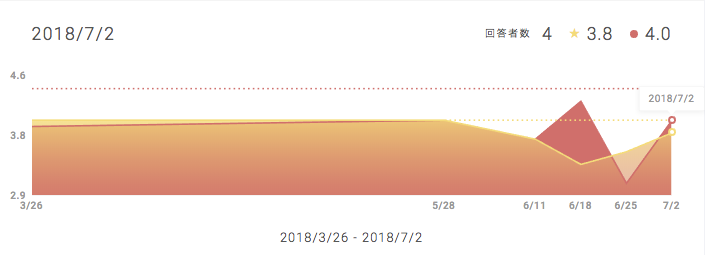
定量観測の対象は、1週間前に決めたアクションプランだけでなく、これまで決めたすべてのアクションプランです。
これによって、1度決めた過去のアクションプランたちがちゃんと継続されているか?といったことが、現場の満足度を通じて把握できます。

振り返りの効果を伝えるために、あらゆるデータを可視化しました。
「1週間で対応するタスクの重さ」をStorypointにて、また、「1週間に使った労力」を作業時間にて測り、さらに、計画時点での予定とスプリント終了時点での実績をそれぞれに出すようにしていました。
しかし、フォーカスサーベイの結果ほど、チームの変化を実感できる指標はなく、「振り返り」の価値を伝える上では1番の方法だと気づきました。
実際に運用していく上で、「期待度が下がり、満足度が上がった」という状態に直面しました。
このときは既存の改善活動には満足していてお腹いっぱい、次のアクションに移ってもよいGOサインが出たチームで出た状態とみんなで結論づけたのですが、おもしろい洞察として記憶に残っています。
定性:「習慣化」した行動を見える化する
KPTのKeepでチーム内で数週間続いていた行動を意識的に取り上げて、「習慣化」というタグをつけました。
振り返りで決めたアクションがチームに根付いていることを見える化して、振り返りの価値を理解してもらおうとした試みです。

「振り返り」のあとに、チームに定着した価値観や行動は無意識に溶け込みます。
1度、これらが当たり前として定着してしまうと、改めて、言語化するのはしつこいと思われるかもしれません。
しかし、振り返りがチームに良い変化をもたらしたことをメンバーに理解してもらうために、泥臭いですがみんなで伝えあることを意識しました。
私たちの現場ではできなかったですが、1週間前のKeepと今週のKeepを見比べていく方法も、「廃れたKeep」や「無意識層に潜り込んだKeep」がわかって面白いかもしれません。
【感情で動いてもらう】
もちろん、論理で人を動かすことができれば良いです。
しかし、チームが劇的に変わった成功体験がない限り、論理で説得はできても納得を生み出すのは難しかったりします。
また、頭よりも心で判断するようなメンバーもいる(特にものづくりをする職場では)ことでしょう。
そのような状況で、メンバーの積極性を促すためには、ムーブメントを興すということを実践しました。
「言語領域」・「非言語領域」の2つの切り口で紹介します。
言語領域:失敗の標語化
チームで起きた成功体験や失敗を共通言語にして、わいわい楽しく使う試みです。端からみて「なんだか楽しそう」という雰囲気をつくるだけでなく、チームが気をつけるべき事柄が一気に広まる効果もありました。以下がその一例です。

言語領域:名言の実況
チームで「振り返り」をしたあとに、その内容を第3者に共有してフィードバックをいただく機会が定例で設けられていたのですが、そこで出たキーワードをslackに投稿する試みです。目的は失敗の標語化に近いです。

定例に参加していないメンバーからすると、作業中に突然、名言風の投稿が流れてくるわけです。ここで「何があった?」と興味を持ち、詳細を聞きにくるメンバーやこのフィードバックの時間にぜひ参加したいと志願するメンバーも出てきました。

非言語領域:聞き手が盛り上げる
盛り上げの責任を、話し手でなく聞き手が持つことです。
「振り返り」だけでなく、チーム活動自体が「なんだか楽しい」と思ってもらえるようにするために行う工夫なのですが、ガヤと呼ばれる行為に近いかもしれません。
チーム全体の熱量が高く、あの渦に巻き込まれてみたいとメンバーに思ってもらうことを目指します。
そのためには、膝に手を当てて静かに話を聞く文化ではなく、聞き手が話し始めても問題ない空気をつくっていきましょう。。

私たちの現場でも次のようなエピソードがありました。
「アイスブレークマン」と後に呼ばれる男がいて、チーム活動を毎回、盛り上げてくれていました。
しかし、冷静に彼の話を思い出してみると、特段おもしろいわけでもなくどちらかというと小話に近いものが多かった気がします。
そんな彼が場を盛り上げることに成功していた理由は、彼の「場をなんとか盛り上げようとする」勇姿にメンバーの心が動かされて、「よっ!」「おおお!」「出た!」というような応援に近い合いの手が生まれていたからでした。
彼のアイスブレークは、ライブ会場のパフォーマーとそれを応援するファンたちのような関係をメンバー間に生み出したのです。
ここから話し手だけでなく、聞き手こそが盛り上げ役としての役割を果たす大切さを学びました。
2.「問題意識あり」の領域に引き込む
「問題意識なし」というメンバーを減らし、「問題意識あり」というメンバーを増やすための方法を紹介します。

このためには、チーム内で意識すべき問題を揃えて、その温度感を徐々に高めていく必要があります。
その上で私たちは次のようなことを実行しました。
・向き合う対象は「過去」でなく「未来」
・進捗の副詞に気をつける
・発言と言動を切り分ける
しかし、こちらはまとめる時間がなかったため、割愛させてください。
内容としては、私の尊敬する偉大なチームリーダー、キタさんとやなさんの記事に書かれていることでもありますので、そちらを参考にしていただければ幸いです。
スクラム未経験者がチームメンバーと共に暗黒の時代を抜けて、エンゲージメント・レーティングをAAまであげた1年を振り返る
おわりに
本記事は、モチベーションクラウドアドベントカレンダーとGoodpatch UI Design Advent Calendarの24日目の記事です。
チームで新しい取り組みを行うとき、そこには必ず、「人」がいます。
「人」の感情を無視して手法やプロセスを組み込むのではなく、その多様性を尊重・感謝する。
私自身、これを忘れずにいたいと思います。
プログラミング経験ゼロから、自社プロダクトの開発に参画することになったのでやったこと
はじめに
この記事は、「モチベーションクラウド Advent Calendar 2018」25日目の記事となります。
モチベーションクラウド開発に新卒2年目からジョインすることになった@shioura_yuuyaです。
モチベーションクラウドアドベントカレンダーの最終日を担当させて頂きます。
モチベーションクラウドの開発現場はハイレベルなベテランエンジニアの方々ばかりなので、配属に先立ち私はまず七ヶ月に渡るプログラミング研修を受けました。
基礎から実践で使える技術までじっくりと学んだ上で、現在は現場でエンジニアとして働いています。
この記事では、私がプログラミングを習得するためにどのような学習をしたのか、細かい内容より学習姿勢的な部分にスポットをあてて、効果的に感じたものを3つご紹介したいと思います。
- ドリルをやらなきゃ九九は覚えない
- それ本当?の精神
- ドキュメント化は未来への投資
プログラミング学習を始めたばかりの新人の方、あるいはそんな新人をレクチャーする立場の方に参考になるものとなれば幸いです。
ドリルをやらなきゃ九九は覚えない
研修では一部分に絞った技術要素を重点的に学ぶことで、継続的・自主的に学習して成長していける状態になることがGOALでした。
とはいえ、学ぶべき技術要素は鬼たくさんありました。
(Ruby、Rails、コマンド操作、Git、SQLなどなど)
最初はとにかく参考書を読みました。が、読むだけでは問題がありました。
読んだだけでは実践できない
具体的には、、、
- プログラミング言語の参考書は読んだが、いざプログラミング問題を解こうとすると書けない
- 参考書のどこに何が書いてあるかも思い出せず索引できない
- コマンド操作の本は読んだがどんな時に使うものなのか分からない
といった事態が発生しました。私は、実は何も習得できていないのに、本を読むことで「勉強したつもり」の状態になっていたのです。
その状況を打破するために行ったことが、手を動かすことでした。
手を動かしながら参考書を読む
参考書を黙読するだけではダメで、とにかく手を動かしました。
- irbを使って参考書に出てくるRubyのプログラムを実際に動かしてみる
- Gitは実際にGitHubのリポジトリとか作ってpushしてみる
- SQLもターミナル上で全て実行する
上記のようなことをめんどくさがらず徹底的に実践していくことで、学習内容の習得度合いは格段に上昇しました。
たとえば小学生の頃に九九を覚えるためにガリガリとドリルを解いたことと同じで、プログラミングにおいて「手を動かす」ことは非常に重要なファクターであると感じました。
それ本当?の精神
詰まったことや分からないことがあった時、ちょっとGoogleで検索すれば公式サイトやQiitaや個人のブログやらさまざまな情報を手に入れることができます。
情報収集をするときには、必ずその情報が「本当に正しいか」の検証を行いました。
これには二つの理由があります。
- 間違った知識を習得してしまう可能性がある
- 情報が正しいか検証する力はエンジニアにとって必須の能力となる
間違った知識を習得してしまう
これは、そのままの意味です。
ネット上で得ることができる情報は有象無象。個人サイトはもちろん、企業のブログであってもちょっと間違ったことが書いてあることは十分ありえます。
当然ですが、一次情報をたどることを大切にしました。
上記のようなことを行うことで「本当に正しいか」確認していました。
逆に、個人のブログなどでも公式の参照が記載されているものは、信用ができそうだな、という指標にもしていました。
情報が正しいか検証する力
最初は正しい情報を収集するために始めたことですが、正しいか検証するという作業はそれ自体エンジニアとしての資質になりうることを感じます。
(例)git resetのオプションによる挙動の違い
研修の中でgit resetの各オプション(--hard HEAD~や--mixied HEAD~、--soft HEAD~)の違いを説明し、それを証明することを求められた時がありました。
この時私は次の3つのことを行いました。
- Pro Gitを読んで、大枠の挙動を理解する
-
git help resetでマニュアルを開きPro Gitの説明が正しいか確認する - 意図した通り動いているか手を動かして(実際に
git resetを行って)確認する
このような「仮説」と「検証」は、現場に出た今でも日常的に行う仕事であり、プログラミング学習初期段階で癖をつけておくことは非常に有意義なものであると感じています。
少なくともテキストを丸暗記するより、ずっと実効性があると思います。
ドキュメント化は未来への投資
研修中に学んだことは、なるべくドキュメント化してGitHubのWikiに溜めるようにしていました。
正直最初はいちいちドキュメントを書くことにめんどくささを覚えていました。まとめている時間はインプットも止まるので、効率悪い気もして。
しかし結論、このドキュメント化する作業が知識の定着という意味で非常に効果的であると感じました。
知識の体系化
学んだことをドキュメント化することは、知識を体系化する作業です。学んだことを関連付けたり、構造的に整理したりしながら、まとめていくことが求められるからです(特にGitHubのWikiはMarkdownで書くため、普通の文書よりドキュメントの構造を意識できる気がする)。
体系化することで、知識の習熟度が上がる実感があります。
記憶には「エピソード記憶」と「意味記憶」がありますが、テキストなどで学ぶような意味記憶は体系化して関連づけることによって思い出しやすくなるという研究もあるそうです。
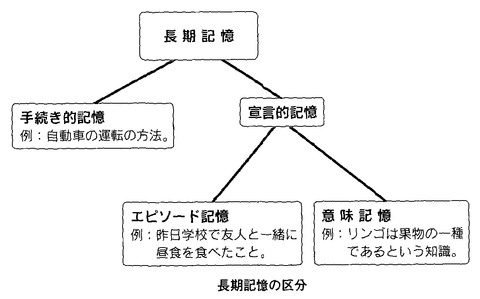
(http://www.ipc.hokusei.ac.jp/~z00105/_kamoku/kiso/2002/itou.htm)
知識の定着が進むことで、結果的に学習効率も向上したように感じます。
ナレッジの蓄積
また、Wikiに溜めていったことはやがてナレッジとして未来の自分や、所属する組織全体にとっても貴重な資産となります。
まとめ
私が初学者として実際にやってみて効果的に感じた学習手法を3つ紹介しました。
- ドリルをやらなきゃ九九は覚えない
- それ本当?の精神
- ドキュメント化は未来への投資
いずれも現場で活躍するエンジニアであれば空気を吸うようにやっていることかもしれません。
しかし、プログラミング初学者にとっては必ずしもそうではありません。
- 「技術書読んだだけで勉強した気になってしまう」という気のせい
- 「ブログに書いてあったら検討せず信じちゃう」という思考の甘さ
- 「ドキュメント書くより勉強進めたい」という短期視点
などなど課題も多く、相応の「訓練」を経て習得できた(今もしている)ものであったと思います。
プログラミング初学の時点で習慣化するくらい体に染み込ませたことで、スムーズに現場の業務に入ることができたと感じています!
おわりに
モチベーションクラウド Advent Calendar 2018は本記事を持ってゴールとなります。
モチベーションクラウドは「One for all, All for one」を実現する企業(組織)を増やしていくという思いが込められたプロダクトです。そのようなプロダクトを作っている開発チームの一員としては、自分たち自身が世界中でもっとも「One for all, All for one」な開発組織でありたいと思っています。
だからこそ、開発メンバーで一丸となって取り組み、無事最後まで走りきれた今回の企画は(私がゴールテープを切るのは恐縮ですが)、「One for all, All for one」の1つの形のように思えて、とても嬉しい気持ちです!
それではみなさん、メリークリスマス!
