ドメイン駆動設計 #1 Advent Calendar 2018の 12 日目担当記事です。
11 日目 は @YasuhiroKimesawa さんのドメイン駆動設計における2つの『不変』です。
13 日目は @dskst さんのDDDで学ぶAPI設計の勘所です。
数年前 IDDD のソースを読んでいたときに考えていたことを言語化してみました。
戦術的設計に関する記事になります。よろしければお付き合いください。
はじめに
アプリケーションサービスをご存知でしょうか。
まず大前提としてアプリケーションサービスの知識がないと、この記事は全く意味がないのでアプリケーションサービスについての簡単な解説をします。
既にご存知の方はこの章は読み飛ばして構いません。
アプリケーションサービスはエンティティや値オブジェクトなどのドメインオブジェクトを協調させて処理を行う、スクリプトのような振る舞いを持つオブジェクトです。
エンティティや値オブジェクトはそのまま利用するには粒度が細かすぎる場合があり、それらをまとめあげるための「サービス」です。
より身近な表現をすればアプリケーションの API と表現するとわかりやすいでしょうか。
たとえば MVC フレームワークを利用した Web システムを例にしてみましょう。
まずはアプリケーションサービスを利用しないパターンです。
public class UserController : Controller {
private readonly IUserRepository userRepository;
public UserController(IUserRepository userRepository) {
this.userRepository = userRepository;
}
public IActionResult CreateUser(CreateUserRequestModel request) {
using (var transaction = new TransactionScope()) {
var userName = request.UserName;
var found = userRepository.FindByUserName(userName);
if (found != null) {
throw new Exception("duplicated");
}
var user = new User(userName);
userRepository.Save(user);
transaction.Complete();
}
return View();
}
}
コード自体に問題はありません。
しかし、もしもフレームワークを変更することになった場合にはどうなるでしょうか。
UserController というクラスは MVC フレームワークに依存したクラスです。
移植先のフレームワークが同じプログラミング言語のフレームワークであったとしても、そのまま移植するわけにはいきません。
恐らくそういったコードはいたるところに記述されているでしょう。
このようなコードを現行のフレームワークから引きはがして別のフレームワークに移植するのは並々ならぬ労力が必要です。
さて、今度はアプリケーションサービスを使った場合を見てみましょう。
public class UserController : Controller {
private readonly UserApplicationService userApplicationService;
public UserController(UserApplicationService userApplicationService) {
this.userApplicationService = userApplicationService;
}
public IActionResult CreateUser(CreateUserRequestModel request) {
var userName = request.UserName;
userApplicationService.CreateUser(userName);
return View();
}
}
public class UserApplicationService {
private readonly IUserRepository userRepository;
public UserApplicationService (IUserRepository userRepository) {
this.userRepository = userRepository;
}
public void CreateUser(string userName) {
using (var transaction = new TransactionScope()) {
var user = userRepository.FindByUserName(userName);
if (user != null) {
throw new Exception("duplicated");
}
var newUser = new User(userName);
userRepository.Save(newUser);
transaction.Complete();
}
}
}
UserController はUserApplicationServiceというクラスに処理を移譲するようになりました。
UserApplicationServiceには MVC フレームワーク特有のコードは現れておらず、MVC フレームワークに依存していないといえる状態にあります。
このような形になっていれば、もしもフレームワークを変更することになったとしてもUserApplicationServiceをそのまま流用することができるのでそれほど問題は起きないでしょう。
既にクラス名からしてお気づきでしょうがUserApplicationServiceがアプリケーションサービスです。
いよいよ本題
アプリケーションサービスについてイメージがついたところで本題に入ります。
次のサークル機能(ユーザ同士のグループを作る機能)を実現するアプリケーションサービスをご覧ください。
public class CircleApplicationService {
private readonly ICircleRepository circleRepository;
public CircleApplicationService(ICircleRepository circleRepository) {
this.circleRepository = circleRepository;
}
public void CreateCicle(string circleName) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.FindByCircleName(circleName);
if (circle != null) {
throw new Exception($"duplicated (CircleName:{circleName})");
}
var newCircle = new Circle(circleName);
circleRepository.Save(newCircle);
transaction.Complete();
}
}
}
CircleApplicationService はサークル機能に関するアプリケーションサービスです。
現在のCircleApplicationServiceは未完成です。
なぜならCircleApplicationServiceはサークルを作ることができても「サークルにユーザを所属させる」ことができません。
ユーザを所属させるためには次のようなメソッドを追加する必要があるでしょう。
public class CircleApplicationService {
private readonly ICircleRepository circleRepository;
private readonly IUserRepository userRepository;
public CircleApplicationService(ICircleRepository circleRepository, IUserRepository userRepository) {
this.circleRepository = circleRepository;
this.userRepository = userRepository;
}
public void CreateCicle(string circleName) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.FindByCircleName(circleName);
if (circle != null) {
throw new Exception($"duplicated (CircleName:{circleName})");
}
var newCircle = new Circle(circleName);
circleRepository.Save(newCircle);
transaction.Complete();
}
}
public void Join(string circleId, string userId) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.Find(circleId);
if (circle == null) {
throw new Exception($"circle not found(id:{circleId})");
}
var user = userRepository.Find(userId);
if (user == null) {
throw new Exception($"user not found (id:{userId})");
}
circle.Join(user);
circleRepository.Save(circle);
transaction.Complete();
}
}
}
これでユーザをサークルに所属させることができるようになり、サークル機能を無事に完成させることができました。
このクラスはきっとうまくやっていくと思います。
しかし、最初にこのようなコードを見たときに疑問を感じました。
その疑問というのがタイトルに記載されている凝集度についてです。
凝集度
コードが望ましいものであるか、という指標の一つに凝集度というものがあります。
凝集度はクラスの責任範囲がどれだけ集中しているかを測る尺度です。
クラスの責任範囲が狭まるほど、一つの事柄に特化することになるので、凝集度は高い方が望ましいとされています。
さてこの凝集度を測るには LCOM(Lack of Cohesion in Methods)という計算式があります。
これはメンバー変数とそれが利用されているメソッドの数で計算される値なのですが、その計算式の内容は「メンバー変数はすべてのメソッドで利用される方がよい」といったものです。
凝集度がどういうものかは計算式を見るよりも例を見た方がわかりやすいでしょう。
たとえば次のコードは凝集度が低いコードです。
public class Sample {
private int member1;
private int member2;
private int member3;
private int member4;
public int CalculateA() {
return member1 + member2;
}
public int CalculateB() {
return member3 + member4;
}
}
member1 とmember2はCalculateAでしか使われておらず、member3とmember4はCalculateBでしか使われていません。
つまりメンバー変数がすべてのメソッドで利用されていません。
凝集度としては「メンバー変数はすべてのメソッドで利用される方がよい」ので、Sampleは凝集度が低いモジュールになっています。
もしも凝集度を高めたい場合は、次のようにクラスを分割することで高めることができます。
public class SampleA {
private int member1;
private int member2;
public int Calculate() {
return member1 + member2;
}
}
public class SampleB {
private int member3;
private int member4;
public int Calculate() {
return member3 + member4;
}
}
どちらのクラスもすべてのメンバ変数がすべてのメソッドで利用されています。
凝集度の観点からすると、本来はこのように分かれてしかるべきクラスであったのです。
これらのクラスは凝集度が高いモジュールといえるでしょう。
もちろん必ずしも凝集度が高いということが正解ではありません。
高い方が好ましいというだけであって、そのコードを取り巻く環境によっては敢えて凝集度を下げることが正解となることも有り得ます。
あくまでも凝集度は望ましいコードかどうかを判断する一つの尺度に過ぎません。
アプリケーションサービスの凝集度
凝集度について理解したところでサークル機能のアプリケーションサービスを見てみましょう。
public class CircleApplicationService {
private readonly ICircleRepository circleRepository;
private readonly IUserRepository userRepository;
public CircleApplicationService(ICircleRepository circleRepository, IUserRepository userReporitory) {
this.circleRepository = circleRepository;
this.userRepository = userRepository;
}
public void CreateCicle(string circleName) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.FindByCircleName(circleName);
if (circle != null) {
throw new Exception($"duplicated (CircleName:{circleName})");
}
var newCircle = new Circle(circleName);
circleRepository.Save(newCircle);
transaction.Complete();
}
}
public void Join(string circleId, string userId) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.Find(circleId);
if (circle == null) {
throw new Exception($"circle not found(id:{circleId})");
}
var user = userRepository.Find(userId);
if (user == null) {
throw new Exception($"user not found (id:{userId})");
}
circle.Join(user);
circleRepository.Save(circle);
transaction.Complete();
}
}
}
このクラスではcircleRepository変数は全てのメソッドで利用されていますが、userRepository変数はJoinメソッドでは利用されているもののCreateCircleメソッドでは利用されていません。
凝集度という観点では、最高とはいえる状況ではなさそうです。
では、これは悪いコードなのでしょうか。
そうではないでしょう。
このモジュールは凝集度が最も高い値ではないというだけのことです。
サークルの機能が一つのクラスにまとまっているのはわかりやすいでしょう。
とはいえ、何かを問われたら「0か1か」で答えたくなってしまうのがプログラマの性分です。
もしもサークルアプリケーションサービスにおいて、最高の凝集度を追い求めると、どのような変化がコードに表れるのでしょうか。
凝集度を高めてみる
現在のところサークルに関する処理をまとめたアプリケーションサービスには「サークルを作る処理」と「サークルに所属する処理」という二つの処理が存在します。
これら処理はサークルというデータを扱うということで同じクラスに同居していますが、それぞれを独立して動作させても問題ありません。
凝集度を高めるためにそれぞれの処理をクラスに分割してみましょう。
処理を分割
public class CircleCreateService {
private readonly ICircleRepository circleRepository;
public CircleCreateService(ICircleRepository circleRepository) {
this.circleRepository = circleRepository;
}
public void Handle(string circleName) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.FindByCircleName(circleName);
if (circle != null) {
throw new Exception($"duplicated (CircleName:{circleName})");
}
var newCircle = new Circle(circleName);
circleRepository.Save(newCircle);
transaction.Complete();
}
}
}
public class CircleJoinService {
private readonly ICircleRepository circleRepository;
private readonly IUserRepository userRepository;
public CircleJoinService (ICircleRepository circleRepository, IUserRepository userRepository) {
this.circleRepository = circleRepository;
this.userRepository = userRepository;
}
public void Handle(string circleId, string userId) {
using (var transaction = new TransactionScope()) {
var circle = circleRepository.Find(circleId);
if (circle == null) {
throw new Exception($"circle not found(id:{circleId})");
}
var user = userRepository.Find(userId);
if (user == null) {
throw new Exception($"user not found (id:{userId})");
}
circle.Join(user);
circleRepository.Save(circle);
transaction.Complete();
}
}
}
二つのメソッドは二つのクラスになり、それぞれすべてのメンバ変数がすべてのメソッドで利用されている凝集度が高い状態となっています。
使いまわしていたメンバ変数の定義やクラスの定義文を記述する必要があるため、全体としてはわずかにコード量が増えています。
もちろん、変化は単純なコード量の増加だけではありません。
このクラスを利用した場合の違いを比較してみます。
// before
var circleRepository = new InMemoryCircleRepository();
var userRepository = new InMemoryUserRepository(); // IUserRepository は利用されないが CircleApplicationService をインスタンス化するために用意しなくてはいけない
var circleService = new CircleApplicationService(circleRepository, userRepository); // userRepository は触れられないことがわかっているので null を渡してもいいかもしれない
circleService.CreateCircle("TestCicle");
// after
var circleRepository = new InMemoryCircleRepository();
var circleService = new CircleCreateService(circleRepository); // サークルを作るだけの処理なので userRepository は不要
circleService.Handle("TestCircle");
処理内容としてサークルを作るだけであれば、本来ユーザに纏わるアレコレは不要です。
しかし、分割する前のCircleApplicationServiceではコンストラクタがIUserRepositoryを要求しているため、何かしらのインスタンス(もしくは null )を引き渡す必要があります。
対してクラスを分割した場合には、そもそもコンストラクタで不要なオブジェクトを受け取らないように変更されます。
null を取り扱ったり、使いもしないインスタンスを作らずに済むのはメリットではないでしょうか。
これだけであれば何も考えずとも分割すればよいのですが、大抵の場合メリットにはデメリットが付き物です。
分割した場合のデメリットとして最も気になりそうなのは、やはり処理の関連性を示唆できなくなってしまったことです。
クラスに分割する前のCircleApplicationServiceのときは「サークルに関わる処理」が同じクラスの中にまとまっていました。
それに比べて、クラスを分割したCircleCreateServiceとCircleJoinServiceの間には、かろうじて「 Circle という名前が接頭語としてついている」程度の関係性しかありません。
これでは処理を探すときや新しい処理を追加するときに、どこに記述すればよいか迷ってしまいそうです。
名前空間による関係性の示唆
関係した処理をまとめておき、それがまとまっていることを示すのはとても重要です。
そのまとまり方が周知されていれば、プログラマはある程度のアタリをつけて探すことができます。
探すことができるということは仕様の確認なども簡単に行うことができます。
またモジュールの再利用を促すことにも繋がり、結果として重複の排除につながります。
そう考えると関連性を示すことができなくなってしまったというのは許容しがたいデメリットです。
凝集度を高めるために関連した処理を分割し、結果としてモジュールが探せなくなるようでは開発に支障が出るでしょう。
とはいえここで諦めてしまっては話が終わってしまいますので解決策を考えます。
今回のようにクラスを分けた場合は、そのまとまりを示す手段として名前空間を利用するのがよいでしょう。
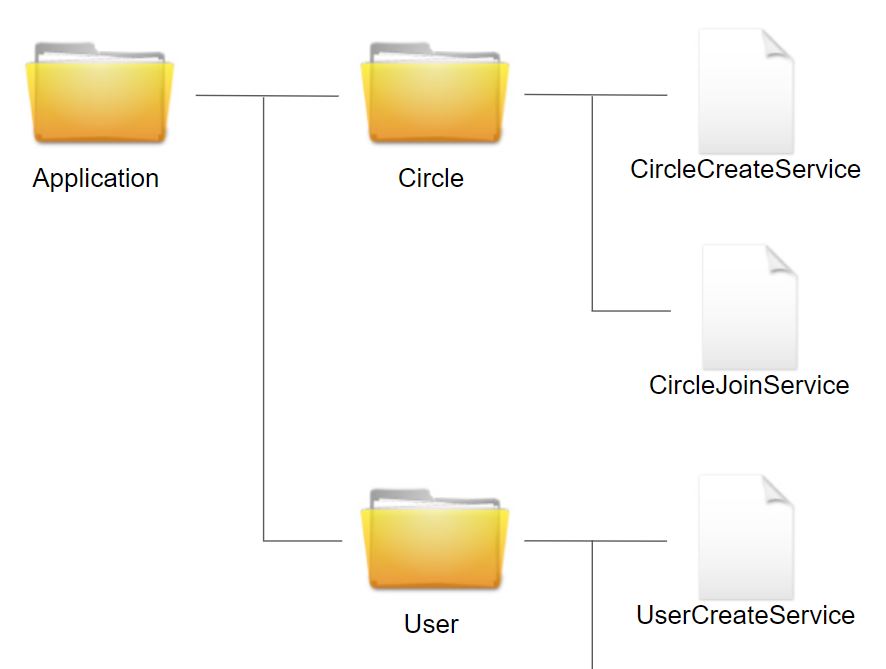
Application.Circle.CicleCreateService
Application.Circle.CicleJoinService
一般的に名前空間はそのままディレクトリ構造に反映されます。
ソースファイルの配置は次のようになります。

これによりサークルに関係する処理は Circle フォルダにまとめることができます。
開発者はサークルに関わる処理は Circle ディレクトリを、ユーザに関わる処理は User ディレクトリを参照するようになるでしょう。
コントローラへの影響
アプリケーションサービスのメソッドがそれぞれクラスになった結果、最も大きな影響を受けるのはそれを利用する箇所、つまりコントローラです。
まずは分割する前のコントローラをご覧ください。
public class CircleController : Controller {
private readonly CircleApplicationService circleApplicationService;
public CircleController(CircleApplicationService circleApplicationService) {
this.circleApplicationService = circleApplicationService;
}
[HttpPost]
public IActionResult Create(CircleCreateRequestViewModel model) {
var name = model.Name;
circleApplicationService.CreateCicle(name);
return View();
}
[HttpPost]
public IActionResult Join(CircleJoinRequestViewModel model) {
var circleId = model.CircleId;
var joinUserId = model.UserId;
circleApplicationService.Join(circleId, joinUserId);
return View();
}
}
コントローラはCircleApplicationServiceを利用しています。
CircleApplicationServiceのメソッド、CreateCircleとJoinが使われているので、メソッドごとにクラスに分割してみましょう。
public class CircleController : Controller {
private readonly CircleCreateService createService;
private readonly CircleJoinService joinService;
public CircleController(CircleCreateService createService, CircleJoinService joinService) {
this.createService = createService;
this.joinService = joinService;
}
[HttpPost]
public IActionResult Create(CircleCreateRequestViewModel model) {
var name = model.Name;
createService.Handle(name);
return View();
}
[HttpPost]
public IActionResult Join(CircleJoinRequestViewModel model) {
var circleId = model.CircleId;
var joinUserId = model.UserId;
joinService.Handle(circleId, joinUserId);
return View();
}
}
コントローラは分割されたクラスをすべてメンバ変数として保持するようになりました。
今度はコントローラの凝集度が下がってしまっているのにお気づきでしょうか。
また、今段階ではアクションが二つしかないので大した問題には見えませんが、今後新たなアクションが追加されるたびにコントローラのメンバ変数が増えるのが想像に難くありません。
将来的に一体どれだけのクラスを保持するようになるのか見当がつきません。
これは問題に思えますので対処したいところです。
この問題に対する方策としてメッセージバスを採用する方法があります。
メッセージバスを採用した場合のコントローラを見てみましょう。
public class CircleController : Controller {
private readonly MessageBus bus;
public CircleController(MessageBus bus) {
this.bus = bus;
}
[HttpPost]
public IActionResult Create(CircleCreateRequestViewModel model) {
var name = model.Name;
var request = new CircleCreateRequest(name);
bus.Handle(request);
return View();
}
[HttpPost]
public IActionResult Join(CircleJoinRequestViewModel model) {
var circleId = model.CircleId;
var joinUserId = model.UserId;
var request = new CircleJoinRequest(circleId, joinUserId);
bus.Handle(request);
return View();
}
}
コントローラのメソッドではクライアントから受け取ったデータを元にコマンドオブジェクトを生成し、メッセージバスにそれを引き渡します。
メッセージバスにはその背後にある処理の中から、引き渡されたコマンドに適した処理を起動します。
こうして考えると、コマンドを作るということはそれに対応した処理を期待する行為です。
つまりコマンドは実行したいユースケースのシリアライズ化したオブジェクトと捉えることができます。
では、コマンドに対する処理はどのように決まるのかというと、次のように事前に登録しておきます。
var bus = new MessageBus();
bus.Register<CircleCreateRequest, CircleCreateService>();
bus.Register<CircleJoinRequest, CircleJoinService>();
CircleCreateRequest というコマンドのオブジェクトを受け取った場合はCircleCreateServiceに処理を移譲し、CircleJoinRequestの場合はCircleJoinServiceに処理を移譲するという設定を行っています。
コマンドとそれに対応する処理の登録はこういったスクリプトでも構いませんし、ファイルから読み込んで設定するのでも構いません。
※メッセージバスの実際の実装例が気になる方は以下の URL を参照してください(UseCaseBus という名前になっています)
https://github.com/nrslib/ClArc-CSharp
メッセージバスを利用すればコントローラの凝集度も高まり、メンバ変数もユースケースが増えるたびに増えることもなく、とてもよさそうに見えるのですが問題があります。
一番の問題は、コマンドに対して処理をするオブジェクトを登録しておかないと実行時の例外になることでしょう。
コマンドと処理系を作ったはいいけど登録を忘れていた、ということは慣れてくれば慣れてくるほど起きそうな話です。
実際は動作確認を行うでしょうから、ほとんど問題にはならないように思えますが、なるべくなら機械的に解決したい部分であります。
これに対する解決方法には次のようなアプローチが挙げられます。
チェックスクリプトは「定義(及び利用)されているコマンドに対しての処理が登録されていなかった場合はエラーとする」という処理です。
ソフトウェアの実行前イベントにしてエラー時には起動できないようにしたりするとよいでしょう。
スキャフォールディングツールは「簡単な定義を入力するとコマンドやその処理を行うクラス定義を自動で生成するツールを作り、そのとき同時に登録を行う」という方法です。
もちろんスキャフォールディングした後に設定部分を削除してしまえば正常に動作しなくなりますが、通常の開発フローであれば問題なく運用できるでしょう。
モチベーション
フォルダ構成を変更したり、ツールを作ったりと、これだけ大げさなことを行って得られるのは凝集度を高めたという事実だけのみです。なんだか少し物足りなく感じますよね。
もちろん凝集度を高めるということはモジュールの堅牢性や可読性などを高めてくれるので、それがそのまま利点です。
ですので、「凝集度を高めたその事実が素晴らしいことだ」と押し切ることもできなくもないのですが、これだけ大掛かりなことをするのですから、何か後押しが欲しいところです。
凝集度を高める以外に何かモチベーションになりそうなものとして挙げるのであれば、たとえば「迷わなくて済む」というのはどうでしょう。
プログラミングは迷いの連続です。
どう書けばよいのかという迷い。どこに書けばよいのかという迷い。
なるほど迷いというのは大きな障害となりうるでしょう。
逆に迷いを取り除くことができれば、それだけ早く開発を行うことが出来ます。
アプリケーションサービスにおいても迷うことはあります。
たとえば、どこのアプリケーションサービスに所属させるべきか考えたときに、迷う処理が現れることがあります。
次のユーザとサークルのアプリケーションサービスをご覧ください。
public class UserApplicationService {
private readonly IUserRepository userRepository;
public UserApplicationService(IUserRepository userRepository) {
this.userRepository = userRepository;
}
public void CreateUser(string userName) {
var user = new User(userName);
userRepository.Save(user);
}
public User GetUser(string userId) {
return userRepository.Find(userId);
}
}
public class CircleApplicationService {
private readonly ICircleRepository circleRepository;
public CircleApplicationService(ICircleRepositorycircleRepository) {
this.circleRepository= circleRepository;
}
public void CreateCircle(string circleName) {
var circle = new Circle(circleName);
circleRepository.Save(circle);
}
public Circle GetCircle(string circleId) {
return circleRepository.Find(circleId);
}
}
コードをシンプルにするためここではドメインオブジェクトを公開する方針にしています。
いずれも単純な作成処理と取得処理を持つ単純なオブジェクトです。
さて、プレゼンテーションの要求で「サークルに所属しているユーザを取得する処理」という如何にも必要になりそうな要求があったとしましょう。
その処理はどちらに記述されるべきでしょうか。
まずはユーザに関係する処理ということでUserApplicationServiceに記述してみましょう。
public class UserApplicationService {
private readonly IUserRepository userRepository;
private readonly ICircleRepository circleRepository;
public UserApplicationService(IUserRepository userRepository, ICircleRepository circleRepository) {
this.userRepository = userRepository;
this.circleRepository = circleRepository;
}
public void CreateUser(string userName) {
var user = new User(userName);
userRepository.Save(user);
}
public User GetUser(string userId) {
return userRepository.Find(userId);
}
public List<User> GetCircleUsers(string circleId) {
var circle = circleRepository.Find(circleId);
if(circle == null) {
return new List<User>();
}
return userRepository.FindUsers(circle.Users); // Circle.Users は UserId のコレクション
}
}
処理自体に納得感はあります。
しかし、一つのメソッドのためだけにICircleRepositoryを受け取るようになるのは致し方ないとはいえ、若干の気後れを感じるのではないでしょうか。
ではCircleApplicationServiceに実装した場合はどうなるでしょう。
public class CircleApplicationService {
private readonly ICircleRepository circleRepository;
private readonly IUserRepository userRepository;
public CircleApplicationService(ICircleRepositorycircleRepository, IUserRepository userRepository) {
this.circleRepository= circleRepository;
this.userRepository = userRepository;
}
public void CreateCircle(string circleName) {
var circle = new Circle(circleName);
circleRepository.Save(circle);
}
public Circle GetCircle(string circleId) {
return circleRepository.Find(circleId);
}
public List<User> GetUsers(string circleId) {
var circle = circleRepository.Find(circleId);
if(circle == null) {
return new List<User>();
}
return userRepository.FindUsers(circle.Users);
}
}
この場合もUserApplicationServiceと同様の問題を抱えています。
サークルのことなのに、ユーザ集約を返却することにより違和感を感じる方もいるかもしれません。
こうなってくると非常に迷いが生まれる部分であると思います。
UserApplicationService に記述するべきかCircleApplicationServiceに記述するべきか、それとも新しく作るのか。
しかし、もしもすべてのユースケースがそれぞれクラスになっているようなシステムであったのならば、何も考えずにクラス化をするでしょう。
public class CircleGetUsersService {
private readonly ICircleRepository circleRepository;
private readonly IUserRepository userRepository;
public CircleGetUsersService(ICircleRepositorycircleRepository, IUserRepository userRepository) {
this.circleRepository= circleRepository;
this.userRepository = userRepository;
}
public List<User> Handle(CircleGetUsersRequest request) {
var circle = circleRepository.Find(circleId);
if(circle == null) {
return new List<User>();
}
return userRepository.FindUsers(circle.Users);
}
}
このオブジェクト単体では殆ど違和感を感じずに済むのではないでしょうか。
まとめ
凝集度に固執すると今回のように仕掛けが必要になってしまうことがあります。
こういった仕掛けは対象となるシステムの規模が小さい場合には、とても大掛かりに感じることもあるでしょう。
反対にシステムの規模が巨大になっていくと、ユースケース毎にクラスを分割する戦略はその力を発揮してきます。
たとえば本当に小さな変化ですが、処理の検索がしやすくなります。
多くの処理群を内包するシステムでは具体的な処理を見つけ出すのも苦労したりするものです。
そういったシステムにおいて、クラス名で検索できるのは比較的検索しやすい部類になります。
もちろんメソッド名であっても検索することができるのですが、コードに対する検索ではメソッド名よりもクラス名が優先されて表示される IDE が多いように思います(もしもそうでなかったらごめんなさい)。
それ以外にも、今回の例で言えばテストをする際には利用しないリポジトリなどの余計なオブジェクトを作成する必要がなくなりました。
モックを利用してロジックのテストする際に、準備しやすいのはメリットです。
他にも処理毎にクラスが分かれているので、特定の処理だけにスタブを刺し込むというのが容易くなるでしょう。
メインのコードを変更せずともそれが行えると最高です。
また、そもそも凝集度が高まるということ自体がメリットに感じます。
凝集度を高めることは堅牢性、信頼性、再利用性、可読性の向上に繋がります。
オブジェクトの責務の量とその取扱いに必要とされる慎重さは比例するので、高い凝集度のモジュールはその責務が必然的に少なくなり、容易に扱えるようになるのです。
凝集度はあくまで指標です。
その値が最高でなくとも多くは問題が起きません。
場合によっては少し凝集度が低い方が最適であることもあります。
凝集度は今以上に高めた方がよいのか。
高めた場合に弊害は発生するか。
その弊害に対する対抗手段はあるか。
対抗手段を講じた際の影響範囲(開発者への負担も含む)はどのようになるか。
これらを考察し、そのメリットとデメリットを双方をふまえて享受すべきと考えたのであれば、その戦術を採用すべきでしょう。
悪いコードを断罪するための武器としてではなく、よりよいコードを目指すための手がかりとして、凝集度が活用されることを期待します。
おまけ
実はこれを前面に押し出して実装したのが 実践クリーンアーキテクチャ です。
もしこの記事を読んで、ご興味沸いたようでしたらご参照ください。