

External article
Articles:
App Engine Standard Go 1.9 migration to Go 1.11
Objectifyのv6でmemcacheを使う方法(SDK混在による混乱を防ぎながら)
External article
Cloud Datastoreのクエリでがんばるハナシ
昨今Cloud SpannerやCloud Firestoreなど上位の製品も出てきて徐々に存在感を失いつつありますが、「オレはまだDatastoreを愛してるんだ」「Spanner使う金ねえし」という人もいると思ってCloud Datastore(以降Datastoreと記述します)のクエリのハナシを書きます。
はじめに
普段使用されている方はご存知の通りDatastoreのクエリにはRDBのSQLと比較して制限があります。
- Inequality Filter(>,>=,<,<=)は単一プロパティにのみ使用可能
- 複数プロパティソート(ORDER BY)を併用する場合、Inequality Filterは最初にソートするプロパティに対してしか使えない
- LIKEが使えない
- NOT(!=)が使えない(後述するがライブラリレベルでは可能なものもある)
- OR、INが使えない(後述するがライブラリレベルでは可能なものもある)
Datastoreを使用したアプリを作っていてUI(特に検索画面など)を設計する際は上記制限をよく把握しておかないと、実装フェーズに入ってからお客様に「この要件は実現出来ませんでした」と謝る羽目になります。
制限を緩和する為にはSearch APIを併用するのが(自分の中では)定石でしたが、Search APIはインデックスサイズに上限があり、Datastore最大の長所スケーラビリティを失うというトレードオフもあります。
またGAE/Go 1.11 runtimeでは "Instead of using the App Engine Search API, host any full-text search database such as ElasticSearch on Compute Engine and access it from your service." と述べられており、Search APIは将来利用されなくなっていく可能性があります。(参考)
Datastoreクエリの制限は、要件や仕様を調整したり実装を工夫することである程度緩和させることができます。
本記事では、できるだけDatastoreの標準機能だけを用いてクエリの制限を回避(緩和)する方法を提示します。
※全ての制限を回避できるわけではありませんし、トレードオフもあります。悪しからず
サンプルコード
GAE/Go 1.11 runtime上で、appengine標準API(google.golang.org/appengine/datastore) を用いて記述しています。
https://github.com/knightso/sandbox/blob/master/extra-ds-query/gae_books.go
Cloud Datastore Client Library(cloud.google.com/go/datastore)用のサンプルコードも用意しました。
https://github.com/knightso/sandbox/blob/master/extra-ds-query/gcd_books.go
動作確認は旧Datastore及びCloud Firestore in Datastore modeで行なっています。
NOT EQUAL
NOT EQUALフィルタ(!=)は、JavaやPythonのライブラリには用意されていますがGoには用意されていません。不便に思った人もいるかと思いますが、そもそもNOT EQUALはDatastore APIの機能として用意されているものではなく、JavaもPythonもSDKライブラリレベルで実現されている機能です。
Hoge != 999 は、 内部的に Hoge > 999 と Hoge < 999 の複数クエリに分割実行され結果がマージされます。
Goでも自前で同様の実装を行えば(かなり面倒ですが)実現は可能ですが、本記事では割愛します。
上記の様にInequality Filterを用いてNOT EQUAL検索することは可能ですが、同時にInequality Filterの制限もくっついてきます。つまり、他プロパティに対するInequality Filterの適用が出来なくなり、また他プロパティをソートの第一条件にすることが出来なくなります。
さらに、複数クエリを組み合わせている都合上、カーソルが利用できなくなる、という制限も発生します。
そこで、もう一つ別の方法を紹介します。
NOT EQUALの比較対象が固定の場合、boolの派生プロパティを持つことによってEquality Filterで処理できる様になります。
サンプルとして、下記の様なBookモデルを考えます。
// BookStatus describles status of Book
type BookStatus int
// BookStatus contants
const (
BookStatusUnpublished BookStatus = 1 << iota
BookStatusPublished
BookStatusDiscontinued
)
// Book is sample model.
type Book struct {
Title string
Price int
Category string
Status BookStatus
}
例えば Status != BookStatusUnpublished で検索する、という要件があった場合、その条件をboolで表すIsPublishedの様なプロパティを別途保存しておくことで、IsPublised = false のEquality Filterが使用できる様になります。
// Book is sample model.
type Book struct {
Title string
Price int
Category string
Status BookStatus
IsPublished bool // 追加
}
// Book保存時に派生プロパティを補完
book.IsPublished = book.Status == BookStatusPublished
// 派生プロパティに対してフィルタして検索
var books []Book
_, err := datastore.NewQuery("Book").Filter("IsPublished =", false).GetAll(ctx, &books)
この様にすることで、他プロパティの比較やソート用にInequality Filter用インデックスを節約しておくことができます。
IN(OR)
INもNOT EQUAL同様JavaやPythonがサポートしていてGoではサポートされていない機能となります。これもJavaやPythonは複数の条件でクエリを実行して結果をマージしています。(こちらもカーソルは使えません)
Goでも自前で同様の実装を行えば(やはり面倒ですが)実現可能です。本記事では割愛します。
INも条件が固定されているのであれば、派生プロパティを用意してEquality Filterに置き換える手法が使えます。
あまりよい例ではないですが例えばCategoryプロパティが"sports"または"cooking"のものを抽出したいという仕様があった場合、その条件をboolで保存する派生プロパティを用意します。
// Book is sample model.
type Book struct {
Title string
Price int
Category string
Status BookStatus
IsPublished bool
IsHobby bool // 追加
}
// Book保存時に派生プロパティを補完
book.IsHobby = book.Category == "sports" || book.Category == "cooking"
// 派生プロパティに対してフィルタして検索
var books []Book
_, err := datastore.NewQuery("Book").Filter("IsHobby =", true).GetAll(ctx, &books)
これでInequality Filterを消費せずに検索できます。
さらに別の力技を紹介します。IN条件の全組み合わせをListプロパティに保持しておくことで、比較値が不定でも検索できる様になります。
// Book is sample model.
type Book struct {
Title string
Price int
Category string
Status BookStatus
StatusORIndex []int // 追加
IsPublished bool
IsHobby bool
}
// book.Statusを含むOR条件組み合わせを全て保存しておく
for j := 1; j < 1<<uint(len(BookStatuses))+1; j++ {
if j&int(book.Status) != 0 {
book.StatusORIndex = append(book.StatusORIndex, j)
}
}
// Status IN (BookStatusUnpublished, BookStatusPublished)で検索
var books []Book
_, err := datastore.NewQuery("Book").Filter("StatusORIndex =", BookStatusUnpublished|BookStatusPublished).GetAll(ctx, &books)
選択肢が多いと指数関数的にListプロパティのサイズが増えていくので注意してください。選択肢8個(128通り)くらいまでなら余裕で保存可能です。
OR条件も基本的にINと同じ考えで実装することができます。
大小比較
数値などの大小比較についてテクニックを紹介します。
1プロパティまでであれば普通にInequality Filter(> >= < <=)が使えますが、前述の通り、他のプロパティに対してInequality Filterが使えなくなったりソートに制限がかかるので、可能ならばInequality Fitlerを使わずにおきたいところです。
例えば検索画面UIなどで下のイメージの様な金額を入力して絞り込むフィールドがあるとします。
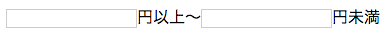
これだとInequality Filterが必須になります、これを下記の選択肢を持つプルダウンに仕様変更できればEquality Filterで検索できる様になります。

実際の数値プロパティとは別に派生プロパティを用意し、そこにプルダウンのオプションに対応する値を保存しておきます。
// Book is sample model.
type Book struct {
Title string
Price int
PriceRange string // 追加
Category string
Status BookStatus
StatusORIndex []int
IsPublished bool
IsHobby bool
}
switch {
case book.Price < 3000:
book.PriceRange = "p<3000"
case book.Price < 5000:
book.PriceRange = "3000<=p<5000"
case book.Price < 10000:
book.PriceRange = "5000<=p<10000"
default:
book.PriceRange = "10000<=p"
}
検索する際はその派生プロパティに対してフィルタをかけます。
// 5000円以上〜10000円未満で検索
var books []Book
_, err := datastore.NewQuery("Book").Filter("PriceRange =", "5000<=p<10000").GetAll(ctx, &books)
後ろの条件が「未満」になっていることに注意してください。これが「以下」という仕様になると複数選択肢にまたがってhitする金額が発生する為、インデックスをListプロパティにする必要が生じます。
部分一致検索
Datastoreではプロパティに対する部分一致検索(LIKE)が出来ません。これはJava、Pythonも同様です。
しかし、検索用インデックスを自前で作成しListプロパティに保存することで、(完全なLIKE互換ではないですが)部分一致検索を行うことができます。
インデックスの作成にはN-Gramを利用します。
私は二文字ずつ分割するbigramと、一文字に分けるunigramを併用して利用しています。
AppEngine → ap, pp, pe, en, ng, gi, in, ne, a, p, e, n, g, i
// Book is sample model.
type Book struct {
Title string
TitleIndex []string // 追加
Price int
PriceRange string
Category string
Status BookStatus
StatusORIndex []int
IsPublished bool
IsHobby bool
}
// Book保存時に派生プロパティを補完
book.TitleIndex = biunigrams(book.Title)
検索パラメータも分割する必要があります。
q := datastore.NewQuery("Book")
if runeLen := utf8.RuneCountInString(title); runeLen == 1 {
// パラメータが1文字の場合はunigramで検索
q = q.Filter("TitleIndex =", title)
} else if runeLen > 1 {
// パラメータが2文字以上の場合はbigramで検索
for _, gram := range bigrams(title) {
q = q.Filter("TitleIndex =", gram)
}
}
var books []Book
_, err := q.GetAll(ctx, &books)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
bigrams, biunigrams関数の詳細は割愛します。興味ある方はこちら。
注意
検索にノイズが発生することがあります。たとえば「東京都」で検索した場合に、「東京」「京都」を含んでいれば「東京都」を含まないデータもhitします。
また、インデックスが巨大になりノイズも増えることからあまり長い文章には適しません。Cloud Datastoreはエンティティあたりのサイズ制限(1Mbyte)があるので、超過するとエラーになります。
本テクニックを使用した場合、検索実行時に内部でマージ・ジョインが行われます。エンティティの件数と検索条件によっては検索にかなり時間がかかる可能性があります。
全文検索
部分一致と同様にListプロパティにインデックスを保存すれば、形態素解析の使用も理論的には可能です。
本記事では割愛しますが、GAEで形態素解析動かした方もいらっしゃるので興味ある方はチャレンジしてみてください。
参考: 形態素解析器 kagome を Google App Engine の最も安いインスタンスで動かす
注意
エンティティあたりのサイズに制限(1Mbytes)があるので、あまり長文になるとエラーになります。
前方一致検索
Inequality Filterを利用して前方一致検索することができます。
例えば'abc'から前方一致で検索したい場合は、
Hoge >= "abc"
と
Hoge < "abc" + "\ufffd"
の条件を組み合わせれば検索できます。
datastore.NewQuery(kind).Filter("Hoge>=", hoge).Filter("Hoge<", hoge+"\ufffd").GetAll(ctx, &fuga)
Inequality Filterを節約したい場合はEquality Filterでも実現可能です。
Listプロパティに、データの先頭から一文字ずつ増やしたプレフィクスをインデックスとして保存しておきます。
AppEngine → a, ap, app, appe, appen, appeng, appengi, appengin, appengine
// Book is sample model.
type Book struct {
Title string
TitleIndex []string
TitlePrefix []string // 追加
Price int
PriceRange string
Category string
Status BookStatus
StatusORIndex []int
IsPublished bool
IsHobby bool
}
// Book保存時に派生プロパティを補完
book.TitleIndex = biunigrams(book.Title)
book.TitlePrefix = prefixes(book.Title)
検索パラメータはそのまま渡します。大文字小文字区別しない様にする為に小文字にだけ変換しています(インデックスも小文字で統一しています)。
var books []Book
_, err := datastore.NewQuery("Book").Filter("TitlePrefix =", strings.ToLower(title)).GetAll(ctx, &books)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
N-Gramよりもインデックス量は増えるので、対象データが大きい場合は解析先頭文字数を制限するとよいでしょう。
後方一致検索
前方一致検索と同様の手法で実現可能です。
Inequality Filterを利用する場合は、あらかじめ内容を逆順に並び替えた派生プロパティを用意しておき、それに対して前方一致検索を行います。
Equality Filterを利用する場合は前方一致同様のインデックスを後方から作成すればOKです。
AppEngine → e, ne, ine, gine, ngine, engine, pengine, ppengine, appengine
実際に後方一致検索が必要となるケースはそれほど多くなさそうです(自分は今まで経験ありません)。
例えば拡張子検索などが挙げられるかもしれませんが、その場合はあらかじめ拡張子だけを抜き出して派生プロパティに保存しておいた方がインデックスを節約できます。
注意点
インデックス爆発
本記事で紹介してきた手法のうちListプロパティを用いたものは、他のListプロパティと組み合わせてカスタムインデックス作成すると組み合わせの数だけインデックスが作成されてしまう(インデックス爆発)ので注意してください。
後述するライブラリではマージジョインを利用することでインデックス爆発を避ける仕組みを組み込んでいます。
マイグレーション
派生プロパティを用いて解決する手法をいくつか紹介しましたが、派生プロパティに影響する仕様変更があった場合は保存済Entityを全て保存しなおす必要が生じます。
Cloud Firestore in Datastore mode
現在Datastoreのバックエンドに従来のCloud DatastoreとCloud Firestore in Datastore modeが選択可能となっており、近い将来全てのDatastoreがCloud Firestore in Datastore modeに置き換わっていくらしいです。
Cloud Firestore in Datastore modeはクエリが全て強整合参照で実行できるという超強力なメリットがありますが、その分インデックスサイズが大きいと保存時のパフォーマンスに対して悪影響が予測されます。
本記事で紹介しているテクニックで使用インデックスが増えた場合にどの程度パフォーマンスに影響あるかは、追って検証したいと考えています。
さいごに
本記事で提示したように、Datastore標準クエリ機能だけでも工夫次第でもう少し複雑な検索を行うことができます。決して万能ではないですが、単純に「IN出来ない」「LIKE使えない」の理解だけで終わってしまうと実現できる要件の幅が狭くなってしまいます。それはとても勿体ないと思います。
クエリとインデックスの性質をよく把握して、要件定義の時点からそれを意識して行うことで、できることの範囲が広がります。
コツは、常に「この要件、Equality Filterだけで実現できないかな?」と考えるクセをつけることです(^^)
おまけ
本記事で行なっている様な検索をサポートするライブラリをつくってます。
2年くらいまえから作る作る言ってましたが、忙しさにかまけて放置してました(´・ω・`)
来週のGCP Advent Calendarその2にも記事を予定してるので、それまでに動くものをつくってアップします(宣言!)
→つくりました!\(^o^)/
https://qiita.com/hogedigo/items/02dcce80f6197faae1fb
Cloud DNSのプライベートDNSゾーンがリリースされたので試してみた
External article
GKEの快適なオペレーション
はじめに
最近、業務でGKEを使いはじめたので、gcloudコマンドやkubectlコマンドを使ったオペレーションが増えてきました。
gcloudコマンドやkubectlコマンドはそのまま使っても便利ですが、より快適なオペレーションを実現するために自分が工夫していることを書いておきます。
GCPのプロジェクト、アカウント切り替えを快適に
業務では複数のGCPプロジェクトを切り替えて作業します。
gcloudを使う場合、以下のコマンドを実行します。
# プロジェクトのリストを表示
$ gcloud projects list
# プロジェクトの切り替え
$ gcloud config set project PROJECT_ID
頻繁に切り替えることが多いので、この手順は結構手間になります。
そこでfzfでプロジェクトをインタラクティブに選択できる関数を作成し、alias登録してあります。
function _gcloud_change_project() {
local proj=$(gcloud projects list | fzf --header-lines=1 | awk '{print $1}')
if [ -n $proj ]; then
gcloud config set project $proj
return $?
fi
}
alias gcp=_gcloud_change_project
現在のプロジェクトは以下のコマンドで確認できます。
$ gcloud config get-value project
こちらもプロジェクトと同じように、アカウント切り替えもalias登録してあります。
function _gcloud_change_account() {
local account=$(gcloud auth list --format="value(account)" | fzf | awk '{print $1}')
if [[ -n $account ]]; then
gcloud config set account $account
return $?
fi
}
alias gca=_gcloud_change_account
kubectlのcontextとnamespaceの切り替え快適に
通常、kubectlを使ってcontextを切り替える場合は、このコマンドを実行します。
# contextのリストを表示
$ kubectl config get-contexts
# contextを切り替え
$ kubectl config use-context CONTEXT
また、namespaceはコマンド実行時に--namespaceオプションで指定することが多いと思います。
こういった手順が面倒なときは、こちらのkubectx/kubensというコマンドを使うとcontextやnamespaceを補完してくれるので、切り替えが楽になります。
また、fzfがインストールされている際はインタラクティブにcontextやnamespaceを切り替えることができます。
プロンプトに現在のプロジェクトを表示して快適に
複数のプロジェクトやcontextを切り替えているとどのコンテキストで作業しているか分かりづらいので、
常にプロンプトに表示するようにしています。
自分は以下のプラグインを参考にフォーマットを変えて表示しています。
- https://github.com/jonmosco/kube-ps1
- https://github.com/katsew/zsh-gkeadm-prompt
kubctlの補完を有効にして快適に
標準でbashとzsh用の補完機能が提供されているので、ぜひ有効にしましょう。
# bash
source <(kubectl completion bash)
# zsh
source <(kubectl completion zsh)
自分は.zshrcに以下を追加してあります。
if [ $commands[kubectl] ]; then
source <(kubectl completion zsh)
fi
Kubernetesのリソースの指定を快適に
kubectl getやkubectl describeなどで指定するリソース名は省略することができます。
$ kubectl get pod
$ kubectl get po
$ kubectl get deployment
$ kubectl get deploy
$ kubectl get service
$ kubectl get svc
以下が、リソース名と省略形の対応関係の一覧です。
kubectl api-resources で確認することができます。
| リソース名 | 省略形 |
|---|---|
| certificatesigningrequests | csr |
| clusterrolebindings | |
| clusterroles | |
| componentstatuses | cs |
| configmaps | cm |
| controllerrevisions | |
| cronjobs | |
| customresourcedefinition | crd |
| daemonsets | ds |
| deployments | deploy |
| endpoints | ep |
| events | ev |
| horizontalpodautoscalers | hpa |
| ingresses | ing |
| jobs | |
| limitranges | limits |
| namespaces | ns |
| networkpolicies | netpol |
| nodes | no |
| persistentvolumeclaims | pvc |
| persistentvolumes | pv |
| poddisruptionbudgets | pdb |
| podpreset | |
| pods | po |
| podsecuritypolicies | psp |
| podtemplates | |
| replicasets | rs |
| replicationcontrollers | rc |
| resourcequotas | quota |
| rolebindings | |
| roles | |
| secrets | |
| serviceaccounts | sa |
| services | svc |
| statefulsets | sts |
| storageclasses | sc |
kubectlを省略して快適に
kubectl自体も毎回入力するのは手間なので省略しちゃいましょう。
こちらは好みも別れますが、以下のようなaliasを登録してます。
kubectxとkubensも合わせて登録してます。
alias k=kubectl
alias kx=kubectx
alias kn=kubens
ロギングを快適に
複数のログをまとめて見る場合は、Stackdriver loggingが便利ですが、CLIで手軽に見たい場合があります。
また、kubectlには標準でkubectl -f logs POD_IDでログを出力することができますが、PodのIDを個別に指定してしなければいけないので面倒です。
sternを使うとPodのラベルを指定して手軽にログを出力することができます。
こちらも補完を有効にしておくとさらに便利です。
if [ $commands[stern] ]; then
source <(stern --completion=zsh)
fi
まとめ
他にも良いTipsがあればぜひ教えていただきたいです!
快適なGKEライフを!
Cloud Spanner をつかったテストのやり方
この記事は Google Cloud Platform その1 Advent Calendar 2018 の6日目の記事です。
GCP には Cloud Spanner というデータベースがあります。分散技術をふんだんに使ったとにかくすごいデータベースなのですが、最低料金がお高いこともあってか、情報がまだ少ない印象です。
実際に Cloud Spanner をつかってアプリを開発する場合、テストはどのように書くとよいのでしょうか。
この記事で解説すること
- Cloud Spanner 開発用環境の構築方法
- Cloud Spanner データベースの初期化のやり方
- 初期データの挿入のやり方
- Cloud Spanner 特有の引っかかりやすい点と解決策
Cloud Spanner 開発環境の構築
Cloud Spanner は完全なマネージドサービスで、現在は残念ながら Cloud Spanner 自体をローカルで動かすことはできません 
よって、Cloud Spanner を使ったテストを行いたい場合、実際に Cloud Spanner のインスタンスを作っておいて、そこにテストのたびに接続する形となります。
ロジックのテストを行うだけであれば、ノード数 1 で十分です。(1 nodeでもお高いですが・・・  )
)
認証情報の作成
Cloud Spanner は GCP のサービスなので、ADC と呼ばれる仕組みで認証を行います。
テスト用の環境では、データベースを作ったり壊したりできたほうがいいので、データベースの削除などを含めた強めの権限 を持っておくとテストしやすいです。(実運用の環境とは別のインスタンスでやりましょう!)
自分は Cloud Spanner の databaseAdmin の権限を持ったサービスアカウントを作成し、その鍵ファイルを環境変数 GOOGLE_APPLICATION_CREDENTIALS に入れることで認証しています。
export GOOGLE_APPLICATION_CREDENTIALS=/path/to/key.json
ADC の仕組みにより、この環境変数をセットするだけでソースコード側で何も認証を指定せずに Cloud Spanner に接続できます!
データベース テストのやり方
Cloud Spanner はデータベースです。まず最初は一般的なデータベースにおけるテストのやり方を見てみましょう。
テストの初期状態では、常にデータベースの状態が一定になっていることが望ましいです。
- データベースをまっさらな状態にする
- テストのための初期データ(フィクスチャ) を入れる
- テストを実行する
- データベースをまっさらな状態にする
データベースをまっさらな状態にする
最も簡単な方法は、データベースごと作り直す方法です。
-
DROP DATABASE ...データベースを削除する(あれば) -
CREATE DATABASE ...データベース自体をつくる -
CREATE TABLE ...テーブルやインデックスを作る
Cloud Spanner でこれをやってみましょう。サンプルコードは Go で書いていますが、ベースは gRPC なので他の言語でもやり方は基本同じです。
package main
import (
"context"
"log"
"cloud.google.com/go/spanner/admin/database/apiv1"
adminpb "google.golang.org/genproto/googleapis/spanner/admin/database/v1"
"fmt"
"time"
"google.golang.org/grpc/status"
"google.golang.org/grpc/codes"
)
func main() {
ctx := context.Background()
client, err := database.NewDatabaseAdminClient(ctx)
if err != nil {
log.Fatal(err)
}
projectID := "xxx"
instanceID := "xxx"
databaseID := "xxx"
dsn := fmt.Sprintf("projects/%s/instances/%s/databases/%s", projectID, instanceID, databaseID)
dsnParent := fmt.Sprintf("projects/%s/instances/%s", projectID, instanceID)
{
exists := true
if _, err := client.GetDatabase(ctx, &adminpb.GetDatabaseRequest{Name: dsn}); err != nil {
st, ok := status.FromError(err)
if ok && st.Code() == codes.NotFound {
exists = false
} else {
log.Fatal(err)
}
}
if exists {
fmt.Printf("begin (DROP DATABASE)\n")
start := time.Now()
if err := client.DropDatabase(ctx, &adminpb.DropDatabaseRequest{
Database: dsn,
}); err != nil {
log.Fatal(err)
}
fmt.Printf("end (DROP DATABASE) (%s)\n", time.Since(start))
}
}
{
fmt.Printf("begin (CREATE DATABASE)\n")
start := time.Now()
op, err := client.CreateDatabase(ctx, &adminpb.CreateDatabaseRequest{
Parent: dsnParent,
CreateStatement: fmt.Sprintf("CREATE DATABASE `%s`", databaseID),
})
if err != nil {
log.Fatal(err)
}
if _, err := op.Wait(ctx); err != nil {
log.Fatal(err)
}
fmt.Printf("end (CREATE DATABASE) (%s)\n", time.Since(start))
}
{
fmt.Printf("begin (CREATE TABLE & INDEX)\n")
start := time.Now()
op, err := client.UpdateDatabaseDdl(ctx, &adminpb.UpdateDatabaseDdlRequest{
Database: dsn,
Statements: []string{
`CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX)
) PRIMARY KEY (SingerId)`,
`CREATE INDEX SingersByFirstName ON Singers(FirstName)`},
})
if err != nil {
log.Fatal(err)
}
if err := op.Wait(ctx); err != nil {
log.Fatal(err)
}
fmt.Printf("end (CREATE TABLE & INDEX) (%s)\n", time.Since(start))
}
}
これを実行してみたところ、次の結果となりました。
begin (DROP DATABASE)
end (DROP DATABASE) (2.471652346s)
begin (CREATE DATABASE)
end (CREATE DATABASE) (7.146112054s)
begin (CREATE TABLE & INDEX)
end (CREATE TABLE & INDEX) (8m1.547491812s)
- DROP DATABASE 約3秒
- CREATE DATABASE 約7秒
- CREATE TABLE & INDEX 約8分
・・・・8分!??

データベースの作成・削除はともかく、テーブルとインデックスの作成がめちゃ遅いです 😥
その上、作るテーブルやインデックスの数が増えるとさらに遅くなってきて地獄です。
テストのたびにこんなに待たされてるのではさすがに辛いですね。
ExtraStatements を使ってテーブルとインデックスの作成を爆速にする
テーブルやインデックスの作成が遅いのは Cloud Spanner の仕様かと思って諦めかけていたのですが、解決策がひとつ見つかりました。 ExtraStatements というパラメータです。
CREATE TABLE や CREATE INDEX といったものを、データベース作成時に一緒に送ることができるパラメータです。
使い方は簡単で、 CREATE DATABASE するときに追加で与えるだけでOKです。
op, err := client.CreateDatabase(ctx, &adminpb.CreateDatabaseRequest{
Parent: dsnParent,
CreateStatement: fmt.Sprintf("CREATE DATABASE `%s`", databaseID),
+ ExtraStatements: []string{
+ `CREATE TABLE Singers (
+ SingerId INT64 NOT NULL,
+ FirstName STRING(1024),
+ LastName STRING(1024),
+ SingerInfo BYTES(MAX)
+ ) PRIMARY KEY (SingerId)`,
+ `CREATE INDEX SingersByFirstName ON Singers(FirstName)`},
})
これでもう一度同じ初期化を実行してみます
begin (DROP DATABASE)
end (DROP DATABASE) (2.507284052s)
begin (CREATE DATABASE + ExtraStatements)
end (CREATE DATABASE + ExtraStatements) (8.352879087s)
- DROP DATABASE 約3秒
- CREATE DATABASE + ExtraStatements 約8秒
・・・・・8秒!!!

この速度なら繰り返しテストを実行しても大丈夫そうですね!
初期データを挿入する
初期データを入れておきたい場合は、特別なことをしなくても普通に INSERT を使って入れると良いでしょう!
初期の Cloud Spanner は INSERT UPDATE DELETE などの文が使えなかったのですが、最近のアップデートで使えるようになりました 🎉
client.ReadWriteTransaction(ctx, func(ctx context.Context, tx *spanner.ReadWriteTransaction) error {
sql := "INSERT INTO User (...) VALUES (...)"
if _, err := tx.Update(ctx, spanner.NewStatement(sql)); err != nil {
return err
}
return nil
})
しかし、大量のデータを入れたい場合は注意が必要です! Cloud Spanner で INSERT などの更新系の命令に制限があります。
- 1回のトランザクションにつき、20,000 mutations 以下に収める
- クエリパラメータの数は 950 個 まで
mutations??? とは何でしょうか? 
ミューテーションとは挿入、更新、削除といった操作の一つの単位です。変更を加える行数と列数、そして対象の列を含むインデックスの数で決まります。
ミューテーションの数え方については、次の動画の解説がわかりやすいです。
https://www.youtube.com/watch?v=12yXz2eS-T0
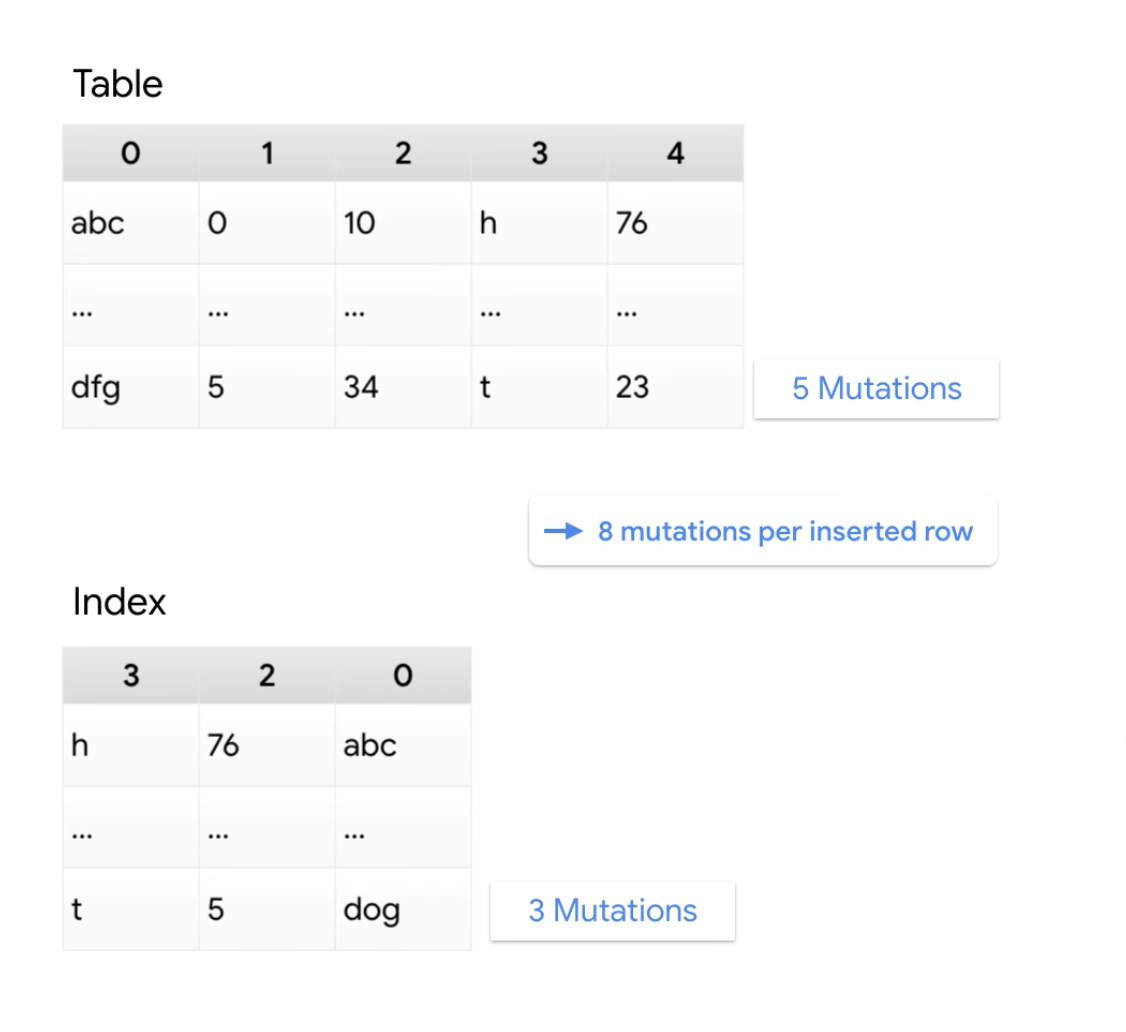
1つのトランザクションで 20,000 ミューテーションを超えるようなデータを入れる場合は、トランザクションを複数回に分割するなどして工夫する必要があります。
ミューテーション数の制限を受けない Partitioned DML
ミューテーション数の制限を受けない特殊な文 Partitioned DML というものもあります。これは、ひとつの UPDATE DELETE 文を分散して実行することで大規模な更新が可能になるものです。
ただし、INSERT 文では使用できないので、テスト用データの大量挿入には使えなさそうです。。
クエリパラメータの制約
クエリパラメータとは、クエリの一部分をパラメータ化して再利用可能にするものです。 MySQL でいうとプリペアドステートメントという機能に近いです。
SELECT * FROM Singers WHERE ID = @param1
クエリパラメータを使うことで、次のような効果が期待できます。
- SQLインジェクションの防止
- 類似クエリを連続して実行する際のパフォーマンス向上
ただし、これにも制約がいくつかあるので注意です。
- 1つの文にクエリパラメータは 950 個まで
-
LIKE '%test%'のようなワイルドカードを含むクエリは最適化が効かず、インデックスが使用されない場合がある(参考ページ)
この制約を解除する方法は現在ではないので、ミューテーション数の制約を Partitioned DML で解決したとしても、こっちのクエリパラメータ数の制約にかかってしまう場合があります。
回避策としては、次のような感じでしょうか。
- 複数のトランザクションに分割する
- クエリパラメータを使わない
まとめ
- Cloud Spanner はローカル環境上に立てることはできないので、テスト用の環境を作ってがんばる
- データベースの初期化は、毎回データベースごと作り直すと簡単。その際、
ExtraStatementsの指定を忘れずに。 - ミューテーション数やクエリパラメータ数といった Cloud Spanner 特有の制限があるので知っておくとよい
Go + Cloud Spanner によるテストの実例
Cloud Spanner 含む複数データベース間で差分を取るツール tamate というものの開発のお手伝いをしたことがありまして、そこで Cloud Spanner をつかったテストを書いています。
こんな感じになるのか〜って実例として参考になれば幸いです!
https://github.com/Mitu217/tamate-spanner/blob/master/datasource_test.go
以上、Google Cloud Platform その1 Advent Calendar 2018 の6日目の記事でした。次回の担当は @cvusk さんです!
Google Cloud Spanner Transaction Abort 探検記
External article
GASを使った認可パターン
External article
BigQuery GISとFlaskとMapbox GL JSを組み合わせて可視化してみた
External article
BigQueryMLとScheduled Queryで機械学習モデル運用を自動化しよう
こんにちは、この記事はGCPアドベントカレンダー10日目です。
はじめに
今年はBigQueryGIS、BigQueryMLという大きいリリースがあり、どんどんBigQueryが便利になっていきますね。
中でもBigQueryMLは、SQLのように一連の機械学習プロセスを実行できるということで、かなり注目が集まっていると思います。
今回はBigQueryMLで構築した機械学習モデルについて、同じく今年リリースされたScheduled QueryというBigQueryの新しい機能を用いて、その後のモデル運用プロセスの一部を自動化できるのでは?というお話です。
公式Docs:
・ すべての BigQuery ML ドキュメント
・ クエリのスケジューリング
機械学習モデルを構築し終わった後、することって何?
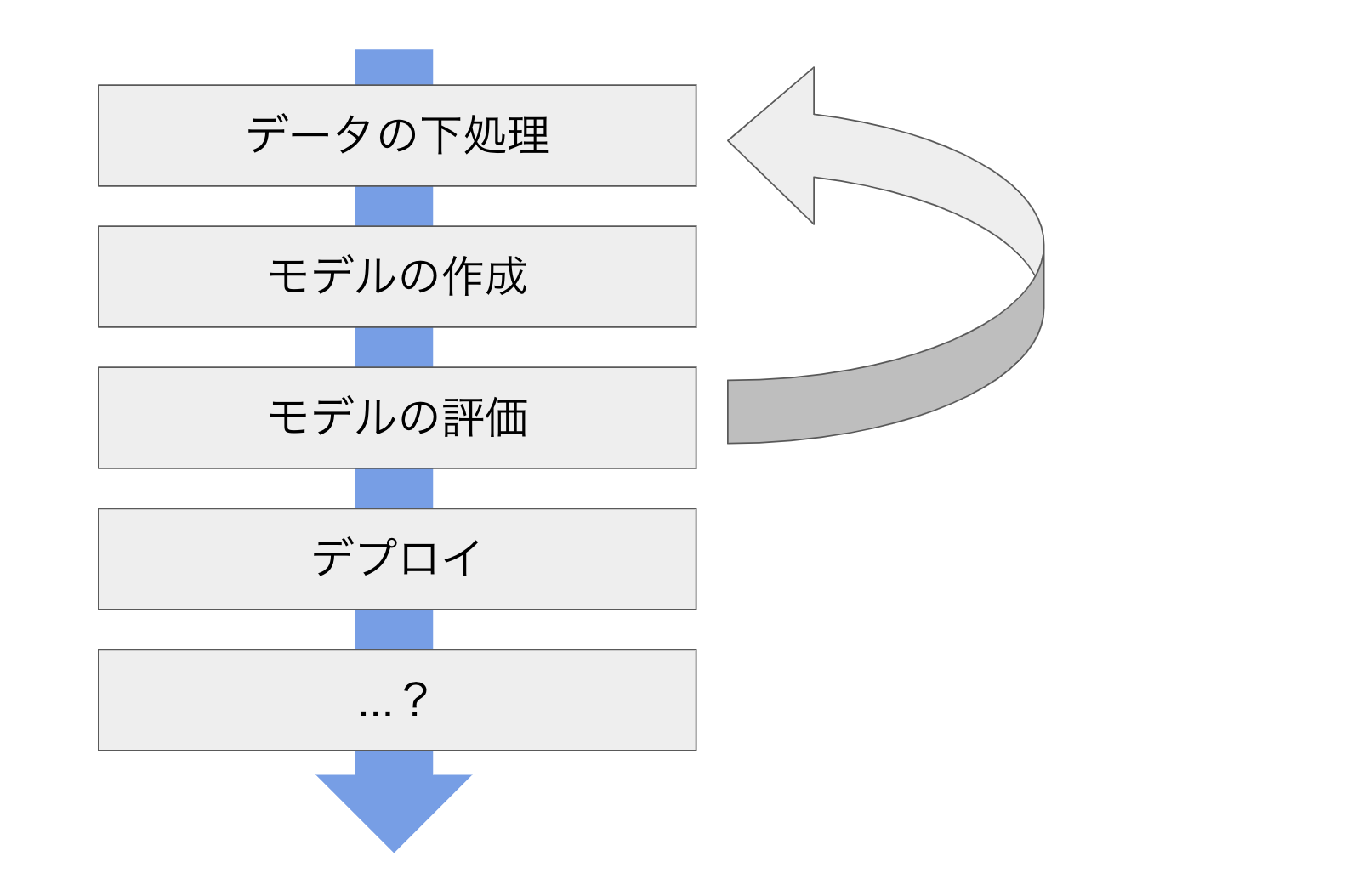
一般的な機械学習プロセスは、以下の図のようになります。
データの下処理、モデルの構築、そしてそれが未知のデータについても適合することの検証という流れを数回繰り返し、実際に予測モデルをデプロイし予測をしていくというプロセスになります。
しかし、デプロイして終わりではありません。
その後モデルを運用していくためには、性能をモニタリングし続けることが必要です。
それは、デプロイした時には性能が十分だったモデルでも、時間の経過と共にデータの特性が変化し、新しいデータに対しての性能が不十分になってしまう可能性があるからです。
これって毎回そんなに時間は取られないけれども定期的にやってくるルーティンワークで、手動でやろうとするとすごく面倒くさそうですよね。
そこで、そんなところに時間をかけず、Scheduled Queryを使って自動化してしまいましょう!
Scheduled Queryによる自動化
今回は、BigQueryMLでモデルを構築済みの状況を想定します。
モデルの作成方法など、気になる方は公式ドキュメントを読んでみて下さい。(最初の方にリンクあります)
Scheduled Queryは、その名の通り、特定のクエリを定期的に実行し、その結果をテーブルに保存したりできるものです。
詳しい仕様などここでは述べませんので気になる方はドキュメントを読んでみて下さい。書き込み先のテーブル名の指定や、実行間隔など、設定は簡単です。
また、テーブルへの書き込み形式も設定でき、全て置き換える場合と既存のテーブルに追加する場合を選択できます。(今回は後者)
それでは、具体的に仕込むクエリを描いてみます。
例えば、こんな風にBigQueryMLのML.EVALUEATE関数を使ったコードをScheduled Queryで設定します。(下の例は3ヶ月毎の実行を想定してます。)
SELECT
CURRENT_DATE() AS run_date,
mean_squared_error,
r2_score,
...
FROM
ML.EVALUATE(MODEL `モデル名`,
(
SELECT
...
FROM
`テーブル名`
WHERE timestamp BETWEEN CURRENT_DATE() AND DATE_ADD(CURRENT_DATE(), INTERVAL 3 MONTH)))
すると、このようなイメージで新しい検証結果がどんどん追加されていきます。

そんな頻繁にデータの特性が変わることは考えづらいので、実行は1ヶ月置き、3ヶ月置きなどで大丈夫だと思います。
この時点で、定期的にモデルの精度を検証するクエリが走るように設定できましたが、ついでにDataStudioでモニタリング用のダッシュボードも作成してみましょう!
DataStudioでのモニタリング
Google DataStudio (Data Portal)
生データでも良いと思いますが、
- データが増えてきた場合に比較しづらい
- 指標の変化を一覧化できない
など課題があるため、個人的にはDataStudioなどの可視化ツールで折れ線プロットを作成してモニタリングするのが良いと思います。
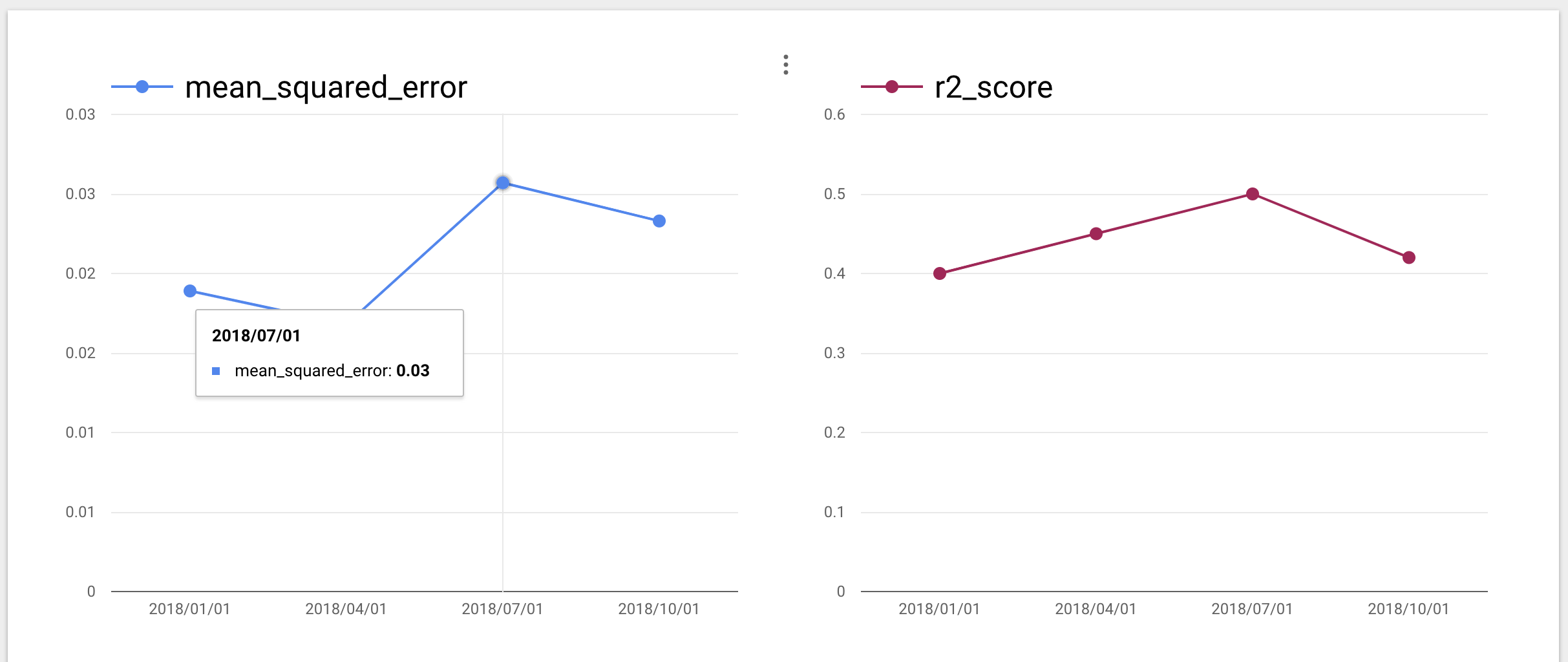
DataStudioを使えばこのように指標の変化を一覧化し一目で把握できます。
また、ページネーションも効くので、複数のモデルも1つのURLにアクセスするだけで性能のモニタリングができます。
終わりに
ここまでご覧いただきありがとうございました。
BigQueryML, Scheduled Query共にとても便利な機能なので、今後のアップデートが楽しみです。
BigQueryMLについて、前に弊社で勉強会をやった際の資料もあるのでもしご興味あればご参照下さい
また、先日行われたbq_sushiでのwantedlyの方の発表では実例が豊富に紹介されており、とても参考になるのでぜひ合わせてご覧ください!
Professional Cloud Architectへのロードマップ

この記事は Google Cloud Platform その1 Advent Calendar 2018 の11日目の記事です。
ちゃんとしたGCPの紹介が続く中で若干の気後れをしていますが、今回はGCPの資格試験である Professional Cloud Architect を受けてきたので、その準備内容をまとめます。
既にネットを探せばある情報ですが、2018/11に試験内容がアップデートした可能性があるためきっと誰かの役に立つ(かもしれない)と思うことにします。
なお私は平均的なサーバーサイドエンジニアでインフラを主とした仕事はしていません。
その前提でお読みいただければと思います。
Professional Cloud Architect って何?
Professional Cloud Architect とは、Google Cloud の技術を組織が活用するために必要なクラウド アーキテクチャと Google Cloud Platform に関する専門的な知識を有することを認められ、ビジネス目標を実現するために、スケーラブルで高可用性を備え、堅牢でかつ安全な動的ソリューションを設計、開発、管理できる者をいいます。 Google Cloud Certified - Professional Cloud Architect 試験では、以下のことを行う能力が評価されます。 他には などの資格が存在します。
Googleが用意している GOOGLE CLOUD CERTIFIED の一つです。
[✓] クラウド ソリューション アーキテクチャの設計と計画
[✓] クラウド ソリューション インフラストラクチャの管理とプロビジョニング
[✓] セキュリティとコンプライアンスに対応した設計
[✓] 技術プロセスやビジネス プロセスの分析と最適化
[✓] クラウド アーキテクチャの実装の管理
[✓] ソリューションとオペレーションの信頼性の確保
結論
(公式)ドキュメントを読み通す が正解です。が、それが難しいためいくつか他の材料を併用することをおすすめします(後述)
特に Computing / Storage / Network / Bigdata / Stackdriver は詳細に把握しておく必要があります。
加えて、 IAMの具体的な運用は複数題でていました。どれも場の設定理解が重要になります。
そして意外とDataTransfer系やData Loss Prevention APIが問われました。
またインフラレイヤーの一般的な知識と、kubernetesの知識が前提となった問題が多く出ますので、kubeはシンプルなクラスタを組める程度の理解が必要になります。(これは業務でカバーしていたのでラッキーでした)
問題を通じてGCPは
- オンプレからの移行・連携
- ビッグデータ処理(とML、そこからのサービスへのリアルタイム反映)
に力を入れているのだというメッセージを感じるようなお題でありました。
話をもどしますが、公式ドキュメントは中々のボリュームがあることと、表現が独特な箇所があり、それだけを読むということが難しい内容になっています。
というわけで以下の副教材的なものを併用して準備しました。
公式ではCourseraのコースを推奨していましたがお値段がそこそこしたので、そちらは見送っています。
なお公開模試がありますが、それの難易度が本番のそれだと思うと大怪我するので、そこだけ注意が必要です。(問題の雰囲気はつかめる)
教材
- (公式)ドキュメント
-
公開模試 1本
-
書籍 1冊
-
Udemyの動画 1本と、模試セット1本
-
他知識の学習
- kubernetes
- 一般的なdevops系知識(blue/green, カナリア etc)
- ネットワーク周り(BGPとは、など)
特に中心となるのが太字にした、公式ドキュメント/Udemyの動画/書籍/Udemyの模試 でした。
独断と偏見でサービス群別に、試験範囲とそのカバー範囲を適当に図示します
- 黄色 -> 書籍
- 青色 -> udemyの動画
- ピンクの線 -> 実際に体感した難易度です (問題を公開してはいけない規約なので雰囲気で語っています)
公式ドキュメントは全てをカバーしています。

黄色と青色でカバーできない範囲を模試で確認しつつ、公式ドキュメントを読む...を繰り返して穴を埋めていく後半戦といったイメージです。
進め方
※ あくまで私個人が振り返ってこうすれば最適だったと思う進め方です
- まず公開模試を受ける
- 黄色本を読む
- Udemyの動画をみすすめながら、適宜ドキュメントを読む
- みおわったら二度目の公開模試と動画最後にある模試を受ける
- そこそこできるようになっているはず
- (必要あれば)ここまでで出てきたGCP以外の知識を習得する
- kubernetes
- k8sはシンプルなクラスタ(Deployment/StatefuleSet/Service/Ingress/Job/Configmap/Secretなど)が組める程度に習熟する必要があります
- spanner ... 概要だけ
- CIツール
- deployment各種手法
- 災害対策
- BGP
- kubernetes
- Udemyの模試セットを受ける
- 激ムズ. これと公開模試の中間が本番の難易度のイメージ
- あとはここで浮き彫りになった不明点を模試の解説とドキュメントで補強していく
以下使用した副教材の紹介です。
書籍
Google Cloud Platform エンタープライズ設計ガイド
- point
- これで 30%はわかる。わかりやすい
- でもこれだけじゃ足りない。
- 2時間くらいで読める。
公開模試
本番の難易度ではないが、雰囲気を掴むのに最適
公式の公開模試
- point
- 雰囲気を掴むのには最適
- ただレベルは本番のそれよりもだいぶ低い
- 2周くらいすると回答を暗記して最初の3文字くらいで選択肢を選べるようになる。
動画
レクチャー
ドキュメントの機能詳細を丁寧に解説してくれる。本当に丁寧。やりすぎなところもたまにある。
ただ聞くだけでも知識が入ってくるのでドキュメントを読み進めるのと比べるとかなり進みがいい。
動画: google-cloud-architect-certifications
- point
- かなり詳細に説明してくれる。小テストで間違えたところは何度かトライ
- 機能説明に特化しているのであくまでベースとなる知識を固めるためのもの。実際のテストではこれをもとに判断するケースしかでない(機能単体を問われることはない)
- thとrの癖が強い
模試
インド人の動画だけではちょっと試験慣れに不安が残ったので模試だけのコースを購入。
結論買ってよかった。
模試セット: google-cloud-certified-professional-cloud-architect-practice-test
- point
- ゲキムズ。
- でも方向性はこちらのほうがリアル。
- 心が折れそうになる。
- これを80%とれたらまずうかる(最後まで70%超えなかった)
公式ドキュメント
全てはここにある。ありすぎる。
公式ドキュメント
- point
- 全て読めるわけがない
- 全てのサービスの役目と概要は確実に抑えておく必要がある
- ML系やDataLossPrevension APIなど、普段使わないものも理解だけはしておく
- 抑えるポイント
- その役目、特徴
- 他のサービスとの使い分け
- 他サービスとの連携
- 基本サービスカテゴリはスペックも確実に抑える(Computing, Storage, Network, Stackdriver, Bigdata)
- 概念を通し見したあとに利用シーンなどを把握する
- ベストプラクティスや入門がそれに当たる
あとは基本サービスカテゴリはちゃんと自分で手を動かして操作できるようにしておくと安心です。ここはこの1-2ヶ月GCPで開発をしていたのでよかった。(でも普段使っているからと言ってこの試験はパスできないのが辛い)
終わりに
そんなこんなで大体20-30時間くらいの勉強時間で無事合格できました 
GCPの Professional Cloud Architect 合格した。 pic.twitter.com/ck8qtJAI0C
— 🦍 (@vsanna2) December 6, 2018
なお教材の選定については先輩エンジニア複数名からアドバイスをもらいました。
その一人が今年10月に資格を取得した際の記事がありますのでこちらもぜひ!
https://www.wantedly.com/companies/anypay/post_articles/138266
資格とっても~という声もありますが、これをきっかけによりインフラやネットワークについて学ぶこともできたので個人的にはとてもいい機会でした。
この冬皆様ももしよければぜひチャレンジしてみてはいかがでしょうか!
それでは以上です。
余談
PCAの証明書が届いたので噂のグッズを貰おうと思ったら Item is currently on backorder. Merchandise options are subject to change. Please check back in 3-4 weeks. とのことでした 
TypeScript で Google Cloud Functions やりたい人向けのテンプレートをつくった
TypeScriptでCloud Functionsをやるときに毎回同じようなことを書いていたので、テンプレートを作りました。※Firebaseコマンドで Firebase Functions をやるときは JavaScriptかTypeScriptか選択することができます。
リポジトリ
https://github.com/flatfisher/cloud-functions-typescript-template
オススメの設定や何か問題などあればIssueやプルリクエストをいただけると嬉しいです
下準備
configを変更します。 runtimeの違いによって動作しない機能もございますので 、詳しくはドキュメントをご参照ください。
package.json
"config": {
"function_name": "helloWorld",
"region": "リージョンをいれる 例:asia-northeast1",
"gcp_project": "GCPのプロジェクトIDをいれる",
"runtime": "ランタイムを指定 例:nodejs8"
},
Lint
$ npm run lint
Build
functions/src/ に Node.js のプロジェクトがビルドされます
$ npm run build
Test
$ npm install -g mocha // mochaがインストールされていればスキップ
$ npm run test
Hello function
✓ Get 200 response
1 passing (31ms)
Deploy
Cloud Functionsにデプロイします
$ npm run deploy --prefix functions/src/
リクエスト
デプロイ後に表示されるhttpsTriggerURLにリクエストしHello Worldが表示されればデプロイに成功しています。
$ curl https://asia-northeast1-foo.cloudfunctions.net/helloWorld
$ Hello World
Cloud DatastoreのCLIツールを作った
GoogleCloudPlatform シェアフル Advent Calendar 2018 13 日目の記事です。
みんな大好きCloudDatastore。もちろん私も大好きなのですが、コマンドラインで操作(データの抽出とか削除とか)が出来ないのが個人的な不満点でした。
そこで、CloudDatastoreをCLIで操作するGo製のツール datastore-tools を作成しました。何番煎じかわからないくらい他にもありそうなツールですが、せっかく作ったし、おまけに年末でもありますからツール供養がてらご紹介させて頂きたいと思います。
何が出来るの?
- エンティティを出力(Json形式、テーブル形式)
- エンティティを更新
- エンティティをtruncate
インストール方法
Goが入っている環境であれば、
$ go get github.com/keitaro1020/datastore-tools
でインストール出来ます。また、Windows/Mac/Linuxのバイナリも用意しています。
使い方
事前準備
CloudDatastoreにアクセスするために gcloud auth をするか、datastore.user のロールを持ったサービスアカウントを作成しキーファイルをダウンロードしておく必要があります。
エンティティを出力
datastore-tools select でエンティティを検索し、出力することが出来ます
$ datastore-tools select -p [project-name] -k [kind-name]
[
{
"__key__": {
"Kind": "Fruits",
"ID": 5634612826996736,
"Name": "",
"Namespace": ""
},
"description": "オレンジ",
"name": "orange"
},
{
"__key__": {
"Kind": "Fruits",
"ID": 5643096528257024,
"Name": "",
"Namespace": ""
},
"description": "りんご",
"name": "apple"
}
]
json形式で出力されるので、jqコマンドと組み合わせれば加工も容易です。
-tオプションをつけると、テーブル形式で出力することも出来ます
~ $ datastore-tools select -p [project-name] -k [kind-name] -t
+------------------+--------+-------------+
| KEY | NAME | DESCRIPTION |
+------------------+--------+-------------+
| 5634612826996736 | orange | オレンジ |
+------------------+--------+-------------+
| 5643096528257024 | apple | りんご |
+------------------+--------+-------------+
エンティティを更新
datastore-tools update でエンティティを更新することが出来ます。
-sオプションに Property=value の形式で値を指定します。
-wオプションで条件を指定し、指定した条件の値のみを変更することも出来ます。
~ $ datastore-tools update -p [project-name] -k [kind-name] -w name=apple -s description="りんご とても美味しい"
~ $ datastore-tools select -p [project-name] -k [kind-name]
[
{
"__key__": {
"Kind": "Fruits",
"ID": 5634612826996736,
"Name": "",
"Namespace": ""
},
"description": "オレンジ",
"name": "orange"
},
{
"__key__": {
"Kind": "Fruits",
"ID": 5643096528257024,
"Name": "",
"Namespace": ""
},
"description": "りんご とても美味しい",
"name": "apple"
}
]
エンティティをtruncate
datastore-tools truncate でエンティティを全件削除することが出来ます。
~ $ datastore-tools truncate -p [project-name] -k [kind-name]
truncate finish, count = 2
~ $ datastore-tools select -p [project-name] -k [kind-name]
[
]
まとめ
以上が現在の datastore-tools で出来ることになります。まだまだ至らない点もたくさんあるかと思いますが、多くの方に使っていただけたら嬉しいです。
もし不具合や改善提案等ありましたら、Githubのissueとかに書いてもらえれば順次対応していきます。
GCPのgcloudコマンドのインストールと最初の認証までを初心者向けに細かく解説
最近AWSだけではなく、マルチクラウドも当たり前につかえておかないと生きていけなそうなのでそろそろGCPを使い始めました。今回はGCPのリソースをCLIで操作できるgcloudコマンドのインストールと初期設定について初心者向けに細かく説明していきます。
gcloudコマンドをインストール
基本的には以下のコマンド一発で gcloud コマンドをインストールすることができます。
Google Cloud SDKをインストールするとついでに gcloudコマンドも使えるといった感じのようですね。
$ curl https://sdk.cloud.google.com | bash
それにしてもcurlでシェルスクリプト取得してインストールさせるなんておしゃれなことするな。Googleさん
$ curl https://sdk.cloud.google.com
#!/bin/bash
URL=https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash
function download {
scratch="$(mktemp -d -t tmp.XXXXXXXXXX)" || exit
script_file="$scratch/install_google_cloud_sdk.bash"
echo "Downloading Google Cloud SDK install script: $URL"
curl -# "$URL" > "$script_file" || exit
chmod 775 "$script_file"
echo "Running install script from: $script_file"
"$script_file" "$@"
}
download "$@"
macOS の場合は Google Cloud SDK は Homebrew Cask からインストールできるようです。
$ brew cask install google-cloud-sdk
さっそくインストールしていきましょう。
途中で色々聞かれますが基本的にはYesを答えていけばよいです。Enterキー押しまくったらOKです。
$ curl https://sdk.cloud.google.com | bash
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 443 0 443 0 0 1381 0 --:--:-- --:--:-- --:--:-- 1909
Downloading Google Cloud SDK install script: https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash
######################################################################## 100.0%
Running install script from: /var/folders/0w/fhc_kcts3rz9r36c9qlx2vkr0000gn/T/tmp.XXXXXXXXXX.VPSuXP9n/install_google_cloud_sdk.bash
which curl
curl -# -f https://dl.google.com/dl/cloudsdk/channels/rapid/google-cloud-sdk.tar.gz
######################################################################## 100.0%
Installation directory (this will create a google-cloud-sdk subdirectory) (/Users/daisuke):
mkdir -p /Users/daisuke
tar -C /Users/daisuke -zxvf /var/folders/0w/fhc_kcts3rz9r36c9qlx2vkr0000gn/T/tmp.XXXXXXXXXX.nExxemcm/google-cloud-sdk.tar.gz
x google-cloud-sdk/
x google-cloud-sdk/lib/
x google-cloud-sdk/lib/third_party/
==========================================================
~ 略 ~
==========================================================
x google-cloud-sdk/.install/core.manifest
x google-cloud-sdk/.install/.download/
/Users/daisuke/google-cloud-sdk/install.sh
Welcome to the Google Cloud SDK!
To help improve the quality of this product, we collect anonymized usage data
and anonymized stacktraces when crashes are encountered; additional information
is available at <https://cloud.google.com/sdk/usage-statistics>. You may choose
to opt out of this collection now (by choosing 'N' at the below prompt), or at
any time in the future by running the following command:
gcloud config set disable_usage_reporting true
Do you want to help improve the Google Cloud SDK (Y/n)? # <--------------------ここで "Enter"
This will install all the core command line tools necessary for working with
the Google Cloud Platform.
Your current Cloud SDK version is: 228.0.0
Installing components from version: 228.0.0
┌────────────────────────────────────────────────────────────────────────────┐
│ These components will be installed. │
├─────────────────────────────────────────────────────┬────────────┬─────────┤
│ Name │ Version │ Size │
├─────────────────────────────────────────────────────┼────────────┼─────────┤
│ BigQuery Command Line Tool │ 2.0.39 │ < 1 MiB │
│ BigQuery Command Line Tool (Platform Specific) │ 2.0.34 │ < 1 MiB │
│ Cloud SDK Core Libraries (Platform Specific) │ 2018.09.24 │ < 1 MiB │
│ Cloud Storage Command Line Tool │ 4.34 │ 3.5 MiB │
│ Cloud Storage Command Line Tool (Platform Specific) │ 4.34 │ < 1 MiB │
│ Default set of gcloud commands │ │ │
│ gcloud cli dependencies │ 2018.08.03 │ 1.5 MiB │
└─────────────────────────────────────────────────────┴────────────┴─────────┘
For the latest full release notes, please visit:
https://cloud.google.com/sdk/release_notes
╔════════════════════════════════════════════════════════════╗
╠═ Creating update staging area ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: BigQuery Command Line Tool ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: BigQuery Command Line Tool (Platform Spec... ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: Cloud SDK Core Libraries (Platform Specific) ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: Cloud Storage Command Line Tool ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: Cloud Storage Command Line Tool (Platform... ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: Default set of gcloud commands ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Installing: gcloud cli dependencies ═╣
╠════════════════════════════════════════════════════════════╣
╠═ Creating backup and activating new installation ═╣
╚════════════════════════════════════════════════════════════╝
Performing post processing steps...done.
Update done!
Modify profile to update your $PATH and enable shell command
completion?
Do you want to continue (Y/n)? # <--------------------ここで "Enter"
The Google Cloud SDK installer will now prompt you to update an rc
file to bring the Google Cloud CLIs into your environment.
Enter a path to an rc file to update, or leave blank to use
[/Users/daisuke/.bash_profile]: # <--------------------ここで "Enter"
Backing up [/Users/daisuke/.bash_profile] to [/Users/daisuke/.bash_profile.backup].
[/Users/daisuke/.bash_profile] has been updated.
==> Start a new shell for the changes to take effect.
For more information on how to get started, please visit:
https://cloud.google.com/sdk/docs/quickstarts
.bash_profile内に以下が追記されていることを確認します。
ちなみにこのファイルたちは
.bash_profile
# The next line updates PATH for the Google Cloud SDK.
if [ -f '/Users/daisuke/google-cloud-sdk/path.bash.inc' ]; then . '/Users/daisuke/google-cloud-sdk/path.bash.inc'; fi
# The next line enables shell command completion for gcloud.
if [ -f '/Users/daisuke/google-cloud-sdk/completion.bash.inc' ]; then . '/Users/daisuke/google-cloud-sdk/completion.bash.inc'; fi
あとはこの.bash_profileの設定を再読み込みして、gcloudコマンドが実行できることを確認すればOKです🎉
# 再読み込みして
$ source .bash_profile
# gcloudコマンドが叩ければ完了です
$ gcloud version
Google Cloud SDK 228.0.0
bq 2.0.39
core 2018.12.07
gsutil 4.34
初期設定
インストールが終わったら、認証情報などを設定するために gcloud init コマンドを実行しましょう。
$ gcloud init
Welcome! This command will take you through the configuration of gcloud.
Your current configuration has been set to: [default]
You can skip diagnostics next time by using the following flag:
gcloud init --skip-diagnostics
Network diagnostic detects and fixes local network connection issues.
Checking network connection...done.
Reachability Check passed.
Network diagnostic passed (1/1 checks passed).
You must log in to continue. Would you like to log in (Y/n)? # <------------- ここで "Enter"
ログインするように求めらるのでEnter(Y)を押すとログイン画面がブラウザで立ち上がります。

最後にこの画面までくれば認証は完了です。

次にプロジェクトを選べと言われますのでここはご自由に。
GCPをコンソール画面から使用したことがある人ならプロジェクトは当然作っているはずですね。
もしプロジェクトを作ったことがなければこのままCLIで作ってしまうこともできます。
You are logged in as: [gee.awa@gmail.com].
Pick cloud project to use:
[1] global-phalanx-xxxxxxx
[2] Create a new project
Please enter numeric choice or text value (must exactly match list
item): # <---------- 1 or 2を入力
あとはリージョンを選べと言われるのでここもご自由にどうぞ
Do you want to configure a default Compute Region and Zone? (Y/n)? <----------- ここで "Enter"
Which Google Compute Engine zone would you like to use as project
default?
If you do not specify a zone via a command line flag while working
with Compute Engine resources, the default is assumed.
[1] us-east1-b
[2] us-east1-c
[3] us-east1-d
[4] us-east4-c
[5] us-east4-b
[6] us-east4-a
[7] us-central1-c
[8] us-central1-a
[9] us-central1-f
[10] us-central1-b
[11] us-west1-b
[12] us-west1-c
[13] us-west1-a
[14] europe-west4-a
[15] europe-west4-b
[16] europe-west4-c
[17] europe-west1-b
[18] europe-west1-d
[19] europe-west1-c
[20] europe-west3-b
[21] europe-west3-c
[22] europe-west3-a
[23] europe-west2-c
[24] europe-west2-b
[25] europe-west2-a
[26] asia-east1-b
[27] asia-east1-a
[28] asia-east1-c
[29] asia-southeast1-b
[30] asia-southeast1-a
[31] asia-southeast1-c
[32] asia-northeast1-b
[33] asia-northeast1-c
[34] asia-northeast1-a
[35] asia-south1-c
[36] asia-south1-b
[37] asia-south1-a
[38] australia-southeast1-b
[39] australia-southeast1-c
[40] australia-southeast1-a
[41] southamerica-east1-b
[42] southamerica-east1-c
[43] southamerica-east1-a
[44] asia-east2-a
[45] asia-east2-b
[46] asia-east2-c
[47] europe-north1-a
[48] europe-north1-b
[49] europe-north1-c
[50] northamerica-northeast1-a
Did not print [6] options.
Too many options [56]. Enter "list" at prompt to print choices fully.
Please enter numeric choice or text value (must exactly match list
item): # <--------------------------------------------------- 1 ~ 50で選ぶ
Your project default Compute Engine zone has been set to [us-east1-b].
You can change it by running [gcloud config set compute/zone NAME].
Your project default Compute Engine region has been set to [us-east1].
You can change it by running [gcloud config set compute/region NAME].
Created a default .boto configuration file at [/Users/daisuke/.boto]. See this file and
[https://cloud.google.com/storage/docs/gsutil/commands/config] for more
information about configuring Google Cloud Storage.
Your Google Cloud SDK is configured and ready to use!
* Commands that require authentication will use gee.awa@gmail.com by default
* Commands will reference project `global-phalanx-225913` by default
* Compute Engine commands will use region `us-east1` by default
* Compute Engine commands will use zone `us-east1-b` by default
Run `gcloud help config` to learn how to change individual settings
This gcloud configuration is called [default]. You can create additional configurations if you work with multiple accounts and/or projects.
Run `gcloud topic configurations` to learn more.
Some things to try next:
* Run `gcloud --help` to see the Cloud Platform services you can interact with. And run `gcloud help COMMAND` to get help on any gcloud command.
* Run `gcloud topic --help` to learn about advanced features of the SDK like arg files and output formatting
完了です。
これで快適なgcloudライフを送る準備が整いましたね。
クラウド生活をエンジョイしましょう!
Cloud Shell環境を使ってCloud Shellのベースイメージを変更する
この記事は Google Cloud Platform その1 Advent Calendar 2018 の15日目の記事です。
なんだかんだでQiita初投稿となります(アドベントカレンダーが初って人も珍しい気が…)。
弊社内にてGCP上でAnsibleとTerraformを用いたハンズオンを実施している際、「AnsibleとTerraformをはじめからインストールしている環境が欲しい」という意見をいただきました。(内容については弊社内ブログにて公開しております。)
ハンズオンはCloud Shellを利用していましたので、いつの間にかアルファ版として実装されていたCloud Shell環境を利用してコンテナイメージを作成してみます。
Cloud Shell環境の確認
Cloud Shellを開き、右上にあるアイコン一覧の一番左にあるモニターアイコンをクリックします。

クリックするとCloud Shell環境の画面が新規タブでCloud Shell環境が開きます。
Cloud Shellコンテナの作成
早速コンテナを作成します。
手順は以下の通りです。
- カスタムイメージの作成よりイメージを作成する
- Dockerfileを編集する
- イメージが作成されるので確認する
カスタムイメージの作成よりイメージを作成する
「カスタムイメージの作成」から、「新しいカスタムイメージを作成」をクリックします。
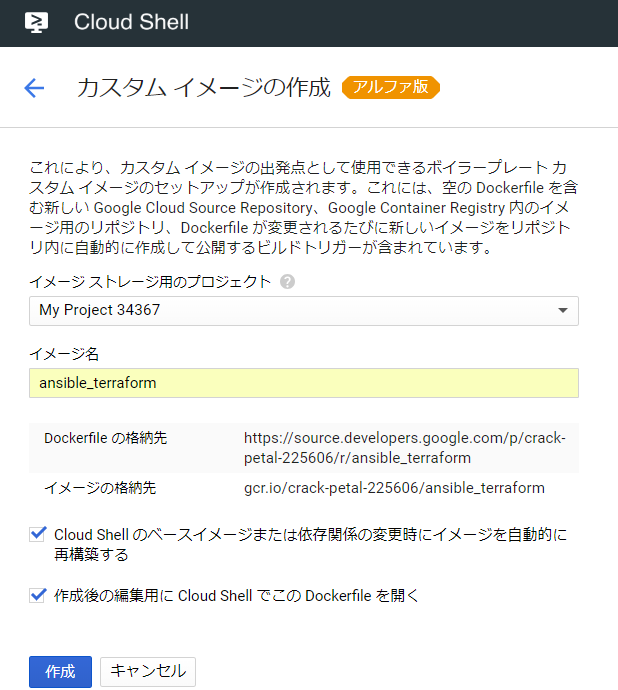
今回は以下のように作成します。
| 項目名 | 設定値 |
|---|---|
| イメージストレージ用のプロジェクト | 作成するプロジェクト名 |
| イメージ名 | ansible_terraform |
またチェックについては両方にチェックをつけ、「作成」ボタンをクリックします。
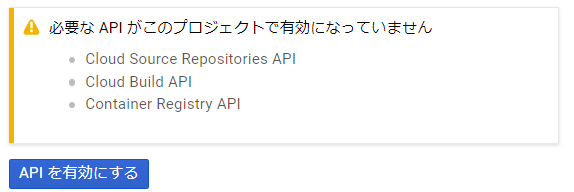
※必要なAPIが許可されていない場合、「APIを有効にしてください」と表示されるため、APIを有効化します。
Dockerfileを編集する
作成が終わると、gitリポジトリのクローンを確認されるため、続行をクリックしてリポジトリを作成します。
リポジトリ作成後、Dockerfileが表示されます。
Dockerfile内に以下ソースを追加します。
RUN wget https://releases.hashicorp.com/terraform/0.11.8/terraform_0.11.8_linux_amd64.zip
RUN unzip terraform_0.11.8_linux_amd64.zip -d /usr/local/bin
RUN pip install ansible
作成後、gitリポジトリにaddします。
git add Dockerfile
git commit -m "edit Dockerfile"
git push origin master
pushすると、自動でCloud Buildが走ってDockerイメージを作成してくれます。すごいですね…。

作成は10分程度で終わります。作成終了後、Cloud Shell環境より[編集]をクリックします。
環境の編集にて、「プロジェクトからイメージを選択する」を選択します。
イメージを選択から、先ほど作成したイメージを選択します。
先程作成したイメージを選択して、「保存」をクリックするとベースイメージが変更されます。
Cloud Shellコンソールを開いている場合はセッションを再起動してください表示されるため、再起動します。
再起動するとコンテナに接続しますが、結構長く接続中とでるためのんびり待っていると起動します。
起動後、イメージ内にAnsibleとTerraformがインストールされているか確認します。
これでCloud Shell上にAnsibleとTerraformがインストールされたイメージの作成ができました。
Dockerfileを作成するだけでイメージが簡単に作成できるため、Cloud Shellを利用した研修を行うならかなりいいかもしれないです。
CloudBuildか、GKE
External article
GCR(Google Container Registry)を高速で安価なDockerのプライベートリポジトリとして利用する(?)
モチベーション
dockerイメージをgcrからpullするだけなら gcloud docker pull/push を利用するのが一番手軽で良いと思いますが、稀にgcloudコマンドをインストールせずにdockerコマンドのみある環境で GCR の認証を行いたい場合もあると思います。
そんな人のための記事になります。
追記 : GCRを高速なプライベートリポジトリとして利用できるので、嬉しい人は多いかもしれない。ということでタイトルも変更。
事前準備
- gcloudコマンドインストールした端末を用意する
- gcpのプロジェクトは作成しておく
そのぐらい、gcloudインストールしたくないとはいっても、認証のトークンを取得するためにどこかの端末にインストールし、 gcloud auth login は済ませて置く必要があります
認証のトークンを取得する
以下のコマンドを実行し、出力されるトークン(割と長めな文字列)をメモしておく。
gcloud auth print-access-token
GCRにdocker loginする
以下のようなコマンドで docker login する
docker login -u oauth2accesstoken -p {先程のトークン} https://asia.gcr.io
Login Succeeded と表示されればOK
試しに docker push/pull してみる
Dockerfileを配置し、コンテナをbuildする
Dockerfileは以下のように
FROM alpine
CMD echo "hello! ore-dayo!"
Dockerfileを配置したディレクトリで以下のコマンドでdocker buildを行う
docker build -t asia.gcr.io/{project id}/oreore .
コンテナをdockerコマンドでpushしてみる
以下のコマンドを実行
docker push asia.gcr.io/{project id}/oreore
問題なし。
GCPのコンソールからGCRないにpushしたイメージが見えているはず。
コンテナをdockerコマンドでpullしてみる(runする)
事前にbuildしたイメージは消しておく。
docker rmi {containerのid}
コンテナを実行する
docker run --rm asia.gcr.io/{project id}/oreore
コンテナイメージのpullが完了した後に、 hello! ore-dayo! と出れば成功。
これで gcloud をインストールしていない環境でも GCR からイメージをpush/pullできそう。
enjoy!
BQやDataStudioについて書く予定 → 書きました『BigQueryのコスト可視化ダッシュボードを10分で作る』
External article
GCP MarketPlaceからWordPress環境を5分で構築する
Wordpressを使ってみる必要があったので、
ローカルに構築しようと思ったけど、MySQL入れたり割と面倒だったので
いっそのことGCPの無料枠で使ってみようかと思い構築してみました。
MarketPlace使えば一瞬という話ですが、真相は如何に
(ちなみに最近GCP触り始めたのでMarketPlace使うのも初めてです)
プロジェクトを作成
対象のプロジェクト名を入力して作成ボタンをクリック
WordPressをデプロイ
MarketPlaceから「WorkPress(Google Click to Deploy タイプ 仮想サーバー)」を選択
「COMPUTE ENGIN上で起動」をクリック

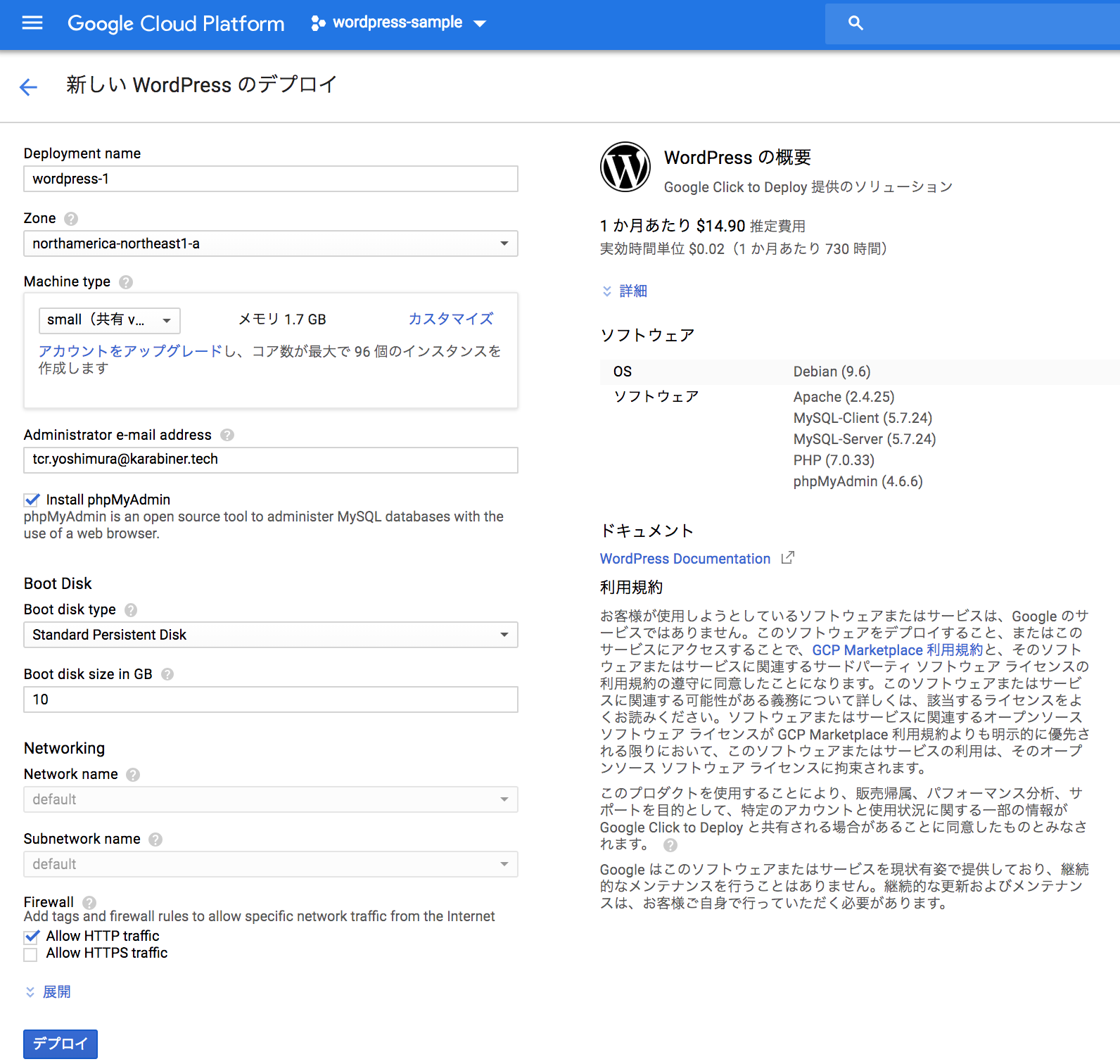
「デプロイ」ボタンをクリックすると数分で環境が構築される。

WordPressにログインする
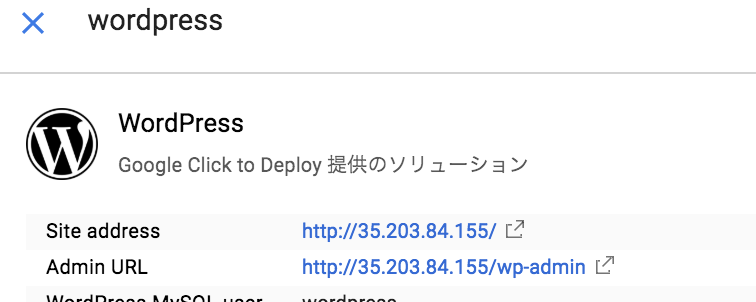
環境構築完了後表示されるWordPressの構成情報にサイトおよび管理画面のURLを記載されている。
(したの方にユーザーとパスワードも)
あとは、Wordpressの管理画面から記事を書いたりPlugin入れたり色々できる。

結論
まじで5分でできた!
構成情報から、次の操作へのリンクなどが漏らさずついてるなど
GCPは本当にUIが素晴らしいですね
イメージの展開とVMインスタンスのスケーリング運用
はじめに
今回は、GCPでTerraformとPackerを用いた運用の一例を紹介させていただきます。
Packerで取ったイメージを展開
Ansibleでプロビジョニングしています。定期的にスケーリング
弊社が運用しているサービスは、昼と夜の決まった時間にトラフィックが上がるのでサーバの負荷が上がるタイミングをある程度予測することができるという特徴を持っています。そのため定刻にスケーリングさせたいという要望がありました。
本記事で説明に使用するサンプルです→https://github.com/Takashi-Kawano/scaling_sample
インスタンステンプレート作成
terraform/providers/dev/terraform.tfvars
project_id = "meta-iterator-225901"
region = "us-west1"
project_name = "scaling-sample"
dev_target_size = "1"
zone = "us-west1-a"
network = "default"
machine_dev = {
"name" = "dev"
"machine_type" = "f1-micro"
"env_name" = "dev"
"group_name" = "dev"
"disk_type" = "pd-standard"
"disk_size" = "30"
"update_strategy" = "NONE"
}
"instance_group_zones" = [
"us-west1-a",
]
scaling_sample/terraform/providers/dev/managed_group.tf
resource "google_compute_instance_template" "instance_template" {
name_prefix = "${var.project_name}-${lookup(var.machine_dev, "name")}-"
machine_type = "${lookup(var.machine_dev, "machine_type", "f1-micro")}"
region = "${var.region}"
disk {
source_image = "${coalesce(var.dev_image, data.terraform_remote_state.output.dev_image)}"
disk_type = "${lookup(var.machine_dev, "disk_type", "pd-standard")}"
disk_size_gb = "${lookup(var.machine_dev, "disk_size", "30")}"
device_name = "${lookup(var.machine_dev, "device_name", "persistent-disk-0")}"
}
network_interface {
network = "${var.network}"
access_config {}
}
lifecycle {
create_before_destroy = true
}
}
source_imageの値を変数(dev_image)にすることで、Terraformコマンドを実行する際にイメージを指定することができます。
実行例
$ terraform apply -var "dev_image=scaling-sample-dev-instance-1545206547"
マネージドインスタンスグループ作成
マネージドインスタンスグループに割り当てられているインスタンステンプレートに割り当てられているビルドイメージを元にVMインスタンスが作成されるようになります。
scaling_sample/terraform/providers/dev/managed_group.tf
resource "google_compute_instance_group_manager" "instance_group_manager" {
name = "instance-group-manager"
instance_template = "${google_compute_instance_template.instance_template.self_link}"
base_instance_name = "dev-instance"
zone = "${var.zone}"
target_size = "${var.dev_target_size}"
update_strategy = "ROLLING_UPDATE"
rolling_update_policy {
minimal_action = "REPLACE"
type = "PROACTIVE"
max_unavailable_fixed = 0
}
}
target_sizeの値を変数(dev_target_size)にすることで、Terraformコマンドを実行する際に起動するVMインスタンスの数を指定することができます。
実行例
$ terraform apply -var "dev_target_size=1"
また、update_strategyを使用して、rolling_update_policyにローリングアップデートの条件を設定しています。
既に起動しているVMインスタンスに対しては、再生成をして新しいVMインスタンスに置き換えることでイメージを適用させます。Terraformコマンド実行時にローリングアップデート処理を開始し、再生成中に停止しているVMインスタンスの数を0と設定しています。こうすることで、運用中のサービスでも止めることなくローリングアップデートができます。
こちらはbeta版ということらしいです。https://www.terraform.io/docs/providers/google/r/compute_instance_group_manager.html
今回サンプルでは使用してみたのですが、実際の運用ではまだ導入はしておらず、イメージの割り当て後にGCPコンソールから手動でローリングアップデートを実行しています。
Packerでイメージ作成
Packerを使ってインスタンスイメージをビルドします。プロビジョニングにAnsibleを使用しています。
scaling_sample/ansible/playbook/build_image.yml
- name: Execute Base Setting...
hosts: "{{ packer_build_target }}"
become: yes
gather_facts: yes
tasks:
- name: Create sample file
copy:
content: helloworld
dest: /message
ansible/packer/packer.json
{
"builders": [{
"type": "googlecompute",
"account_file": "{{user `credential_file`}}",
"project_id": "{{user `project_id`}}",
"source_image_family": "centos-7",
"zone": "{{user `zone`}}",
"instance_name": "{{user `project`}}-{{user `app_stage`}}-instance-base",
"machine_type": "{{user `machine_type`}}",
"disk_size": "{{user `disk_size`}}",
"image_family": "{{user `project`}}-{{user `app_stage`}}-instance",
"image_name": "{{user `project`}}-{{user `app_stage`}}-instance-{{timestamp}}",
"network": "default",
"subnetwork": "default",
"omit_external_ip": false,
"use_internal_ip": false,
"tags": [
"packer-build"
],
"ssh_username": "ansible",
"ssh_private_key_file": "../credentials/ansible_key"
}],
"provisioners": [
{
"type": "ansible",
"playbook_file": "{{user `playbook_file`}}",
"extra_arguments": [
"-i", "./inventory",
"-e", "packer_build_target={{user `project`}}-{{user `app_stage`}}-instance-base",
"-e", "packer_build=yes"
]
}
]
}
ansible/packer/vars/scaling-sample-dev.json
{
"credential_file": "../credentials/scaling-sample-427451a6e5ec.json",
"project_id": "meta-iterator-225901",
"zone": "us-west1-a",
"project": "scaling-sample",
"machine_type": "f1-micro",
"disk_size": "30",
"app_stage": "dev",
"group": "dev",
"network": "default",
"playbook_file": "playbook/build_image.yml"
}
以下のコマンドを実行してイメージビルドします。
$ packer build -var-file=packer/vars/scaling-sample-dev.json packer/packer.json
処理が正常に終了すると、以下のようにビルドされたイメージファイルの名前が表示されます。
(略)
Apply complete! Resources: 0 added, 0 changed, 0 destroyed.
Outputs:
dev_image = scaling-sample-dev-instance-1545206547
dev_target_size = 1
イメージ割り当て(ローリングアップデート)+スケーリング
上で説明したイメージの割り当てとスケーリングをひとまとめに実行します。
$ terraform apply -var "dev_target_size=1" -var "dev_image=scaling-sample-dev-instance-1545206547"
GCPコンソール上で確認すると、新しいVMインスタンスが起動し、既存のVMインスタンスが停止→削除される様子が確認できます。
VMインスタンスにsshログインして以下のようになれば、正常にイメージが割り当てられていることを確認できます。
[dev-instance-b2rv ~]$ cat /message
helloworld
Jenkinsでスケーリングを定期実行
上記のTerraformコマンドでスケーリングとイメージの割り当て(とローリングアップデート)ができるので、これをシェルスクリプトで実行し、定期的にジョブを走らせるようにcronを設定しています。
JenkinsでTerraformコマンドを実行させるためのサンプル用の設定は気が向いたらやっておきます
なぜAutoScalingを使っていないのか
GCPのマネージドインスタンスグループにはAutoScalingという機能が提供されています。これは平均CPU使用率や秒間リクエスト数、StackdriverMonitoringの指標に閾値を設定して、設定した閾値に到達した際に自動でVMインスタンスを増やすという機能です。
現在のアーキテクチャーの仕組みだと新規にVMインスタンスを追加したときに、デプロイ処理を行ってロードバランサーのヘルスチェックが通るまでの間に時間が掛かかります。なので、ヘルスチェックが通るまでの時間差と負荷に対する閾値の考慮が必要でそれを検証するための時間がまず割けていません。。尚且つ、最初に説明した通りある程度トラフィックが上がるタイミングを予測できるので、Jenkinsを使って定期的にスケーリングをするという方針をとっています。
プリエンプティブインスタンスを利用
トラフィックが上がってくるタイミングでVMインスタンスを増やす際にはプリエンプティブインスタンスを利用しています。これを利用することでコストを大幅に削減することができています。ですが、東京リージョンを使用している方々が多いせいか、一時プリエンプティブリソースが充足していない時があって必要な数のプリエンプティブインスタンスが起動せずに焦ることがあったりなど、コスト削減と引き換えに運用面で苦労する場面があるので利用する際には注意が必要です。弊社での運用例の詳細はこちらの記事を参照してください。
終わりに
定刻でスケーリングするだけでなく、トラフィックが多くなると予想されるイベントが始まる前に事前にスケールアウトして備えておくといったことも簡単にできるのでとても便利です。
今後の展望としては、今回のサンプルで使用したローリングアップデートの自動化を適用したり、デプロイ処理をもっと早くできるようにして、よりスムーズにイメージの適用とスケーリングを行えるようにしていきたいと考えています。
以上となります。
最後まで読んでいただきありがとうございました!
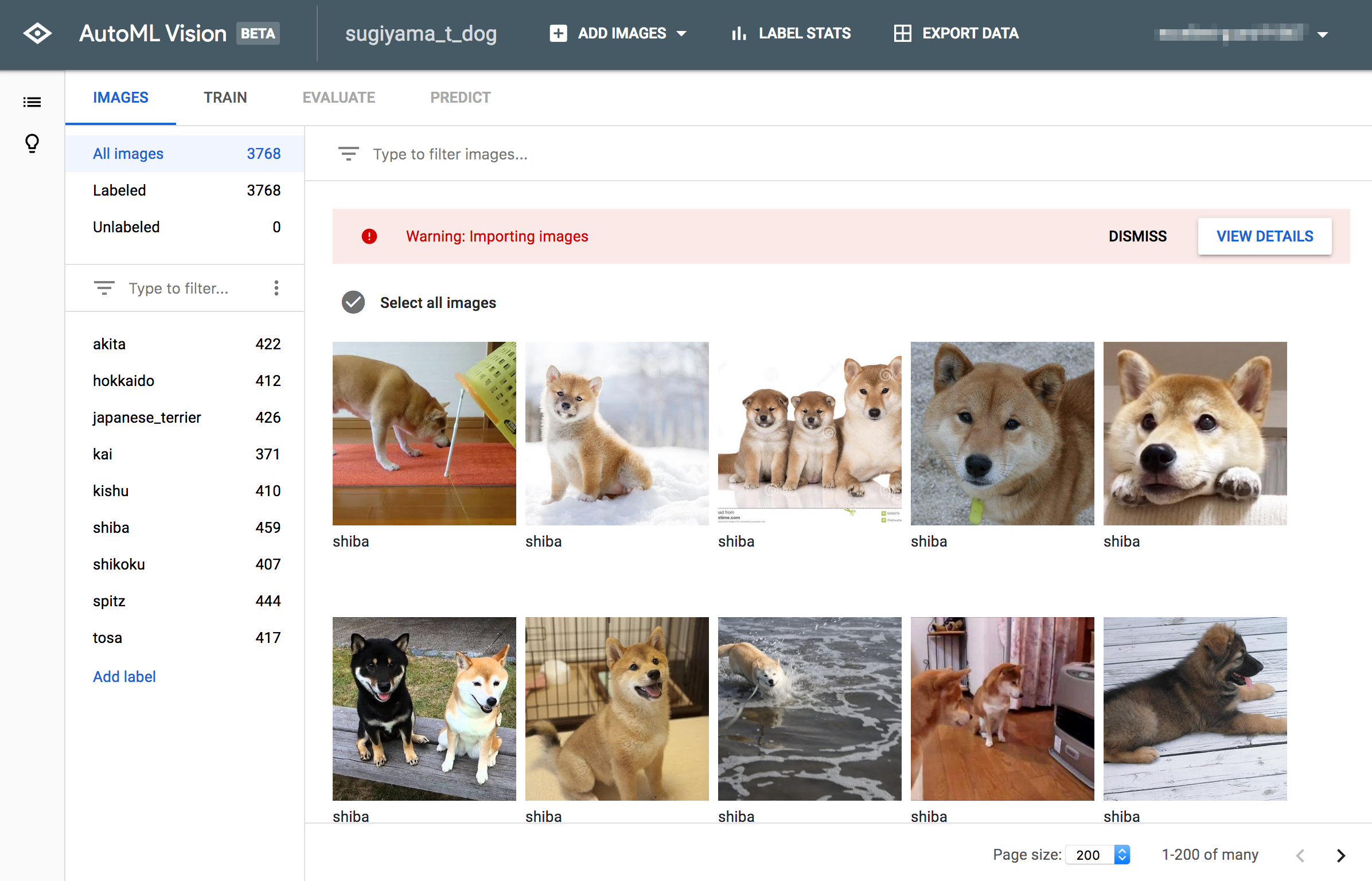
AutoML Vision用の学習用画像収集スクリプト
皆さんこんにちは。@best_not_bestです。
Google Cloud Platform(GCP)のプロダクトの1つに、Cloud AutoML Visionとういうものがあり、ノンプログラミングで画像認識モデルの作成が可能です。
学習用の画像は以下の方法でアップロード可能です。
(cf. https://cloud.google.com/vision/automl/docs/create#upload_your_images )
- Web UI上からアップロード(zipファイルで複数ファイルアップロードも可能)
- Google Cloud Storage(GCS)からの読み込み
今回は後者の方法を用い、画像検索APIで画像を収集 → GCSへファイルをアップロードするスクリプトを作成します。
モデルは犬画像の認識モデルを作成します!
AutoML Visionに加え、GCS、Stackdriver Loggingを使用しますので、必要に応じてGCP上から各種APIをオンにしてください。
環境
マシン/OS
- MacBook Pro (13-inch, 2017, Four Thunderbolt 3 Ports)
- OS 10.12.6
- pyenv: 1.2.8
- pyenv-virtualenv: 1.1.3
Python
pyenv、pyenv-virtualenvで 3.7.1 の環境を構築します。
$ mkdir hogehoge
$ cd hogehoge
$ pyenv local 3.7.1
$ pyenv virtualenv 3.7.1 hogehoge
$ pyenv local hogehoge
$ pip install -U pip
以下のライブラリをインストールします。
requirements.txt
cachetools==3.0.0
certifi==2018.11.29
chardet==3.0.4
dill==0.2.8.2
docopt==0.6.2
flake8==3.6.0
flake8-docstrings==1.1.0
flake8-polyfill==1.0.1
future==0.16.0
gapic-google-cloud-logging-v2==0.91.3
google-api-core==1.7.0
google-api-python-client==1.7.7
google-auth==1.6.2
google-auth-httplib2==0.0.3
google-cloud-core==0.29.1
google-cloud-logging==1.9.1
google-cloud-storage==1.13.2
google-gax==0.15.16
google-resumable-media==0.3.2
googleapis-common-protos==1.5.5
grpcio==1.17.1
httplib2==0.12.0
idna==2.8
mccabe==0.6.1
numpy==1.15.4
oauth2client==3.0.0
pandas==0.23.4
ply==3.8
proto-google-cloud-logging-v2==0.91.3
protobuf==3.6.1
pyasn1==0.4.4
pyasn1-modules==0.2.2
pycodestyle==2.4.0
pydocstyle==3.0.0
pyflakes==2.0.0
python-dateutil==2.7.5
pytz==2018.7
PyYAML==3.13
requests==2.21.0
rsa==4.0
six==1.12.0
snowballstemmer==1.2.1
uritemplate==3.0.0
urllib3==1.24.1
ディレクトリ構成
scripts
└─ scripts.py
model
└─ get_images.py
config
└─ conf.yml
outputs
処理概要
- 画像検索APIで画像を収集
- ローカルに画像を保存
- 画像ファイルをGCSへアップロード
- 画像のURIとラベルを含むCSVファイルの作成
- CSVファイルをGCSへアップロード
画像検索APIはGoogle Custom Search APIを使いたい所ですが、リクエスト制限があるため、Bing Image Search APIを使用します。
Microsoftアカウントの作成等は、以下の記事を参考にさせて頂きました。
ファイル説明
conf.yml
APIキーや、検索ワードを設定します。
検索ワードはみんなの犬図鑑から日本犬をピックアップしています。(全犬種やりたかったけど時間がなかった・・・。)
conf.yml
api_key: 'xxxxx'
gcs_bucket_name: 'yyyyy'
images_per_requests: 50
request_count: 10
dir_name: 'dog'
search_words:
-
label: 'akita'
word: '秋田犬'
-
label: 'kai'
word: '甲斐犬'
-
label: 'kishu'
word: '紀州犬'
-
label: 'shikoku'
word: '四国犬'
-
label: 'shiba'
word: '柴犬'
-
label: 'tosa'
word: '土佐犬'
-
label: 'spitz'
word: '日本スピッツ'
-
label: 'japanese-terrier'
word: '日本テリア'
-
label: 'hokkaido'
word: '北海道犬'
-
api_key: Bingの画像検索APIキー -
gcs_bucket_name: アップロードするGCSのバケット名(バケット名は<GCPのプロジェクトID>-vcmにする必要があります。) -
images_per_requests: 1リクエストあたりの要求画像数 -
request_count: リクエスト数 -
dir_name: ローカル、及びGCSの保存ディレクトリ名 -
search_words.label: 画像に付けるラベル名 -
search_words.word: 画像検索ワード
get_images.py
Bing画像検索APIから画像の取得、GCSへのファイルアップロードを行います。
get_images.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""Get images from Bing Search."""
from google.cloud import storage
import hashlib
import os
import pandas as pd
import requests
import urllib
class CommonError(Exception):
"""common error class."""
pass
class GetImagesFromBingSearch(object):
"""Get images from Bing Search."""
def __init__(
self,
api_key: str,
gcs_bucket_name: str,
gcs_dir_name: str,
):
"""init."""
self.headers = {
'Content-Type': 'multipart/form-data',
'Ocp-Apim-Subscription-Key': api_key,
}
gcs_client = storage.Client()
self.gcs_bucket_name = gcs_bucket_name
self.gcs_bucket = gcs_client.get_bucket(gcs_bucket_name)
self.csv_data = []
self.gcs_dir_name = gcs_dir_name
def get_image_url(
self,
search_word: str,
images_per_requests: int = 50,
request_count: int = 20,
) -> list:
"""get image url."""
image_url_list = []
# offset
for offset in range(0, (images_per_requests * request_count), images_per_requests):
# query parameters
params = urllib.parse.urlencode(
{
'q': search_word,
'mkt': 'ja-JP',
'count': images_per_requests,
'offset': offset,
}
)
try:
# get
response = requests.get(
'https://api.cognitive.microsoft.com/bing/v7.0/images/search',
headers=self.headers,
params=params
)
response.raise_for_status()
search_results = response.json()
except Exception as e:
raise CommonError(e)
# append url
for values in search_results['value']:
image_url_list.append(values['contentUrl'])
return list(set(image_url_list))
def get_image(
self,
image_url: str,
output_dir_path: str,
blob_dir: str,
) -> bool:
"""get image."""
opener = urllib.request.build_opener()
urllib.request.install_opener(opener)
# check extension
parsed_url_path = urllib.parse.urlparse(image_url).path.split(':')[0]
extension = os.path.splitext(parsed_url_path)[-1].lower()
if extension not in ('.jpg', '.jpeg', '.gif', '.png', '.bmp'):
msg = 'extension error. url:"%s".' % (image_url)
raise CommonError(msg)
try:
# get
response = requests.get(image_url, allow_redirects=True, timeout=5)
except Exception as e:
raise CommonError(e)
# check content
if len(response.content) == 0:
msg = 'content error. url:"%s".' % (image_url)
raise CommonError(msg)
# save
hashed_url = hashlib.sha256(image_url.encode('utf-8')).hexdigest()
output_file_path = os.path.join(
output_dir_path,
hashed_url + extension,
)
with open(output_file_path, 'wb') as fp:
fp.write(response.content)
# upload to GCS
blob_name = 'automl_vision/' \
+ self.gcs_dir_name \
+ '/' \
+ blob_dir \
+ '/' \
+ hashed_url \
+ extension
blob = self.gcs_bucket.blob(blob_name)
blob.upload_from_filename(output_file_path)
# add data
self.csv_data.append(
{
'gcs_uri': 'gs://' + self.gcs_bucket_name + '/' + blob_name,
'label': blob_dir,
}
)
return True
def make_csv(
self,
output_file_path: str,
) -> bool:
"""make CSV file."""
df = pd.DataFrame.from_dict(self.csv_data)
df = df.ix[
:,
[
'gcs_uri',
'label',
]
]
df.to_csv(output_file_path, index=False, header=False)
# upload to GCS
blob_name = 'automl_vision/' \
+ self.gcs_dir_name \
+ '/' \
+ os.path.basename(output_file_path)
blob = self.gcs_bucket.blob(blob_name)
blob.upload_from_filename(output_file_path)
return True
-
get_image_url: Bing画像検索APIから画像URLの取得を行います。 -
get_image: 画像URLから画像の取得 → ローカルに保存 → GCSへのファイルアップロードを行います。- 盛り込み過ぎたのでUnitテストしづらい・・・。
- 特定の拡張子を持つファイルのみ保存されます。また、ファイルサイズが0のファイルは保存されません。
-
make_csv: 前述した「画像のURIとラベルを含むCSVファイル」を作成します。
scripts.py
スクリプト部分になります。ログはStackdriver Loggingに送られます。
scripts.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""Get images from Bing Search.
Usage:
scripts.py
--conf_file_path=<conf_file_path>
--output_dir_path=<output_dir_path>
scripts.py -h | --help
Options:
-h --help show this screen and exit.
"""
from docopt import docopt
import google.cloud.logging
import logging
import os
import shutil
import sys
import yaml
try:
import get_images
except ImportError:
sys.path.append(os.path.abspath(os.path.dirname(__file__)) + '/../model')
import get_images
if __name__ == '__main__':
# logging config
logging.basicConfig(format='%(asctime)s %(levelname)s: %(message)s')
# logging
logging_client = google.cloud.logging.Client()
logging_client.setup_logging()
logging.info('%s start.' % (__file__))
# get parameters
args = docopt(__doc__)
conf_file_path = args['--conf_file_path']
output_dir_path = args['--output_dir_path']
# config
with open(conf_file_path) as f:
conf_data = yaml.load(f)
api_key = conf_data['api_key']
search_words = conf_data['search_words']
gcs_bucket_name = conf_data['gcs_bucket_name']
images_per_requests = conf_data['images_per_requests']
request_count = conf_data['request_count']
dir_name = conf_data['dir_name']
# create model
gifbs = get_images.GetImagesFromBingSearch(
api_key,
gcs_bucket_name,
dir_name,
)
for search_word in search_words:
label = search_word['label']
word = search_word['word']
# make dir
output_tmp_dir_path = os.path.join(
os.path.abspath(output_dir_path),
dir_name,
label,
)
if os.path.isdir(output_tmp_dir_path):
# remove dir
shutil.rmtree(output_tmp_dir_path)
os.mkdir(output_tmp_dir_path)
try:
# get image url
image_url_list = gifbs.get_image_url(
word,
images_per_requests=images_per_requests,
request_count=request_count,
)
except get_images.CommonError as e:
logging.warning(e)
for image_url in image_url_list:
# get image, save and upload GCS
try:
gifbs.get_image(
image_url,
output_tmp_dir_path,
label,
)
except get_images.CommonError as e:
logging.warning(e)
continue
# make CSV file
output_file_path = os.path.join(
os.path.abspath(output_dir_path),
dir_name,
'data.csv',
)
gifbs.make_csv(output_file_path)
logging.info('%s end.' % (__file__))
sys.exit(0)
実行方法
conf_file_path、output_dir_pathがコマンド引数となります。それぞれ<設定ファイルのパス>、<画像の保存ディレクトリのパス>を指定ください。
実行例
$ python scripts/scripts.py \
--conf_file_path=./config/conf.yml \
--output_dir_path=./outputs/
実行結果
結構な数のWarningログが出力されますが、プログラム内で意図的に出力しているログであり、必要な画像はGCSへとアップロードされています。
実行結果
2018-12-22 23:47:05,421 INFO: scripts/scripts.py start.
scripts/scripts.py start.
2018-12-22 23:47:21,630 WARNING: extension error. url:"https://item-shopping.c.yimg.jp/i/j/usual_irish3".
extension error. url:"https://item-shopping.c.yimg.jp/i/j/usual_irish3".
(中略)
2018-12-22 23:51:12,407 INFO: scripts/scripts.py end.
scripts/scripts.py end.
Program shutting down, attempting to send 1 queued log entries to Stackdriver Logging...
Waiting up to 5 seconds.
Sent all pending logs.
gs://<gcs_bucket_name>/automl_vision/<dir_name>/<search_words.label>/配下にラベル毎に画像ファイルが、gs://<gcs_bucket_name>/automl_vision/<dir_name>/data.csvに、「画像のURIとラベルを含むCSVファイル」がアップロードされます。
AutoML Vision
では、実際にAutoML Visionを使用してみます。
学習用画像のアップロード
ページ上部の「ADD IMAGES」→「Select CSV file on Cloud Storage」から、上記の「画像のURIとラベルを含むCSVファイル」のGCS上のURIを入力し、「IMPORT」をクリックします。
以下の画面に遷移すればアップロード完了です。
同一画像が別ラベルでアップロードされている、ファイルが読み込めない等のエラーが出ていますが、今回は後述の作業にクリティカルな影響が無いため無視します。


不要画像の削除
その犬種ではない画像、そもそも犬ではない画像はWeb UIから削除します。
これが結構大変です。
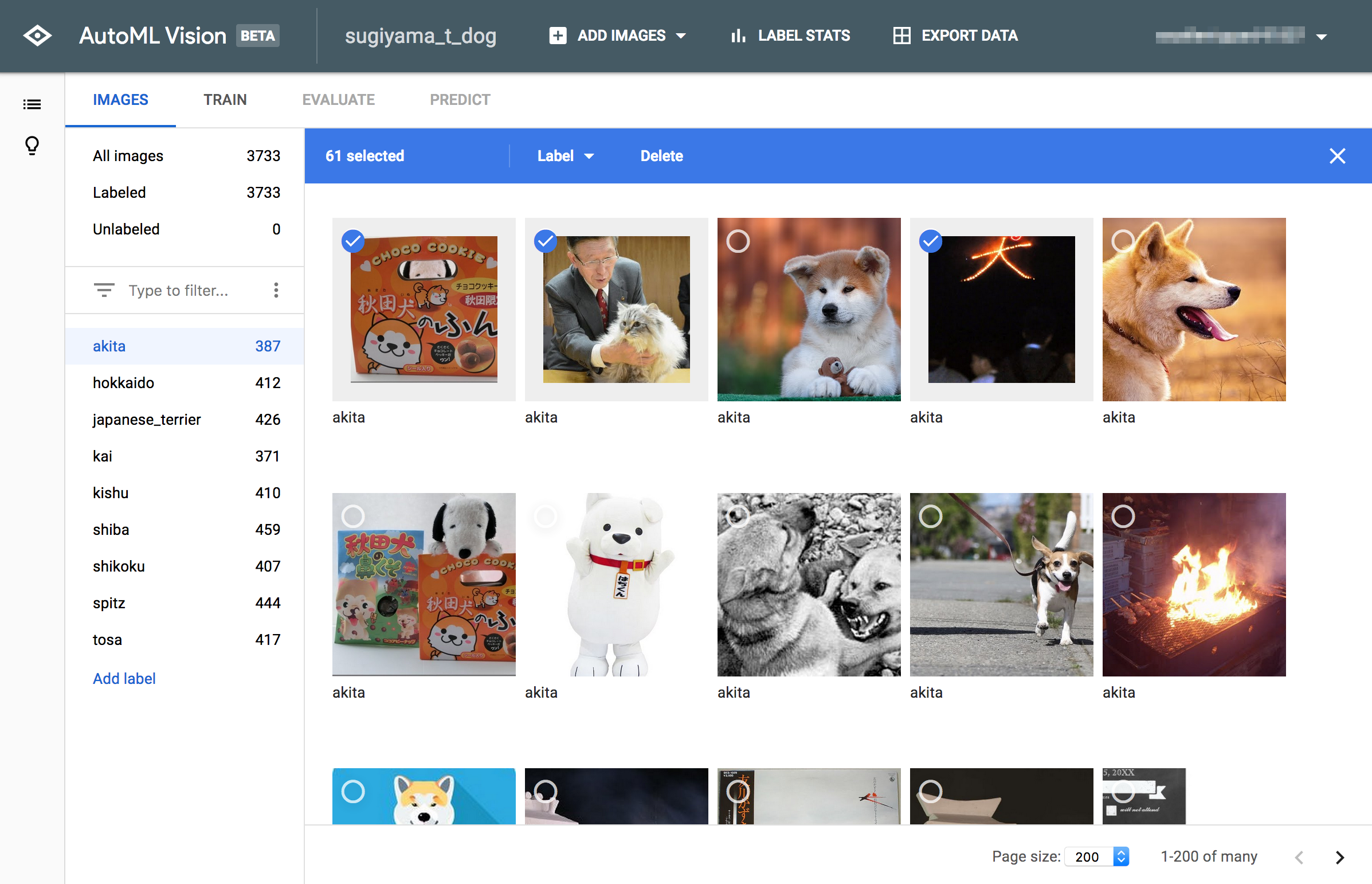
結果、以下のようなデータ数となりました。

学習
画像を学習させます。土佐犬の画像を増やした方が良いと言われてますが、このまま続けてみます。
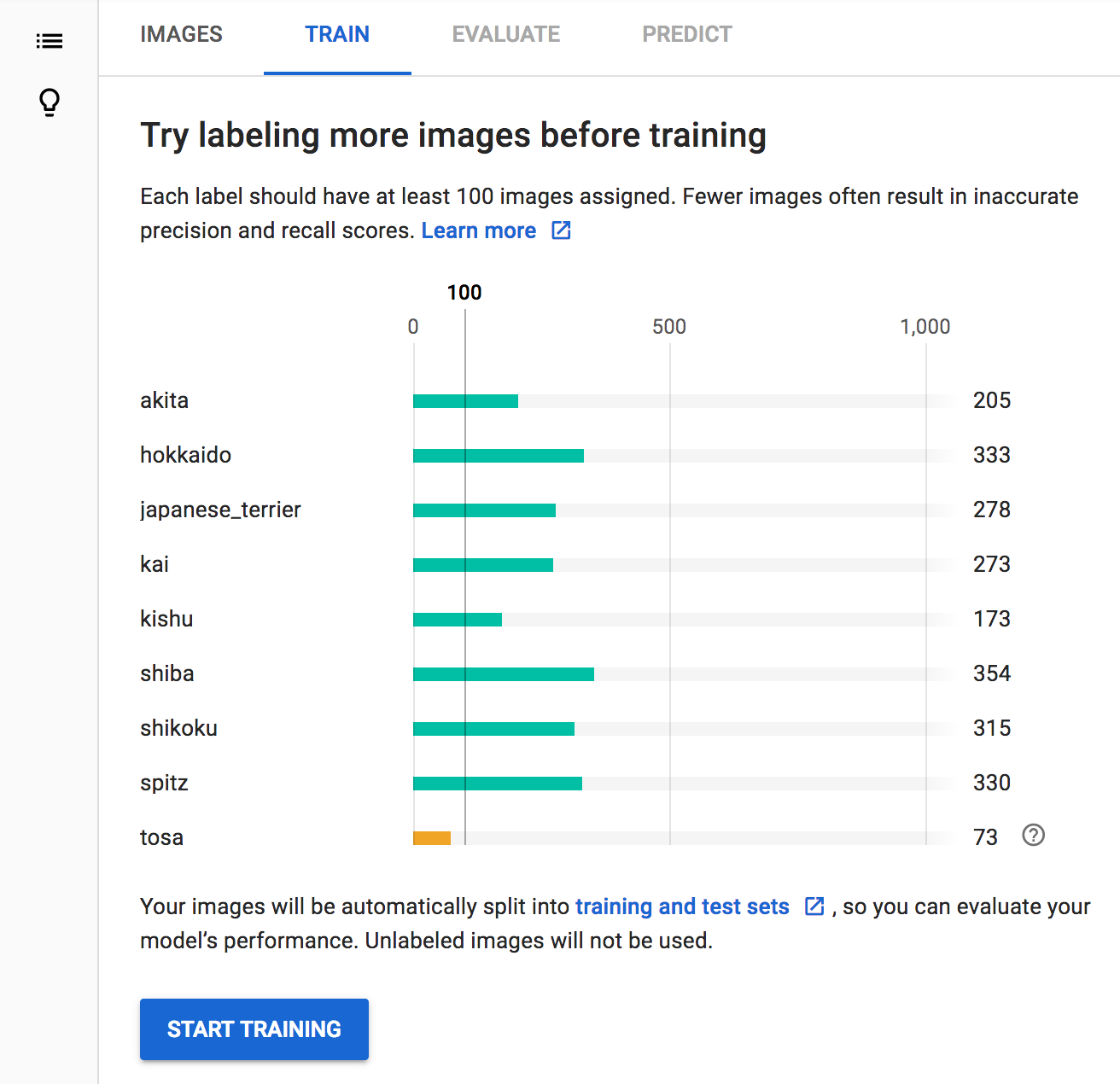
学習方法は無料の「1 compute hour」を選択します。

学習には15分から1時間程度掛かります。完了すると自分のGCPアカウント宛てにメールが届きます。
評価
評価結果は以下のようになりました。


過学習している気もするので新規画像で予測してみます。
予測
Web UIからいくつか画像をアップロードしてみます。
柴犬

土佐犬

北海道犬

紀州犬

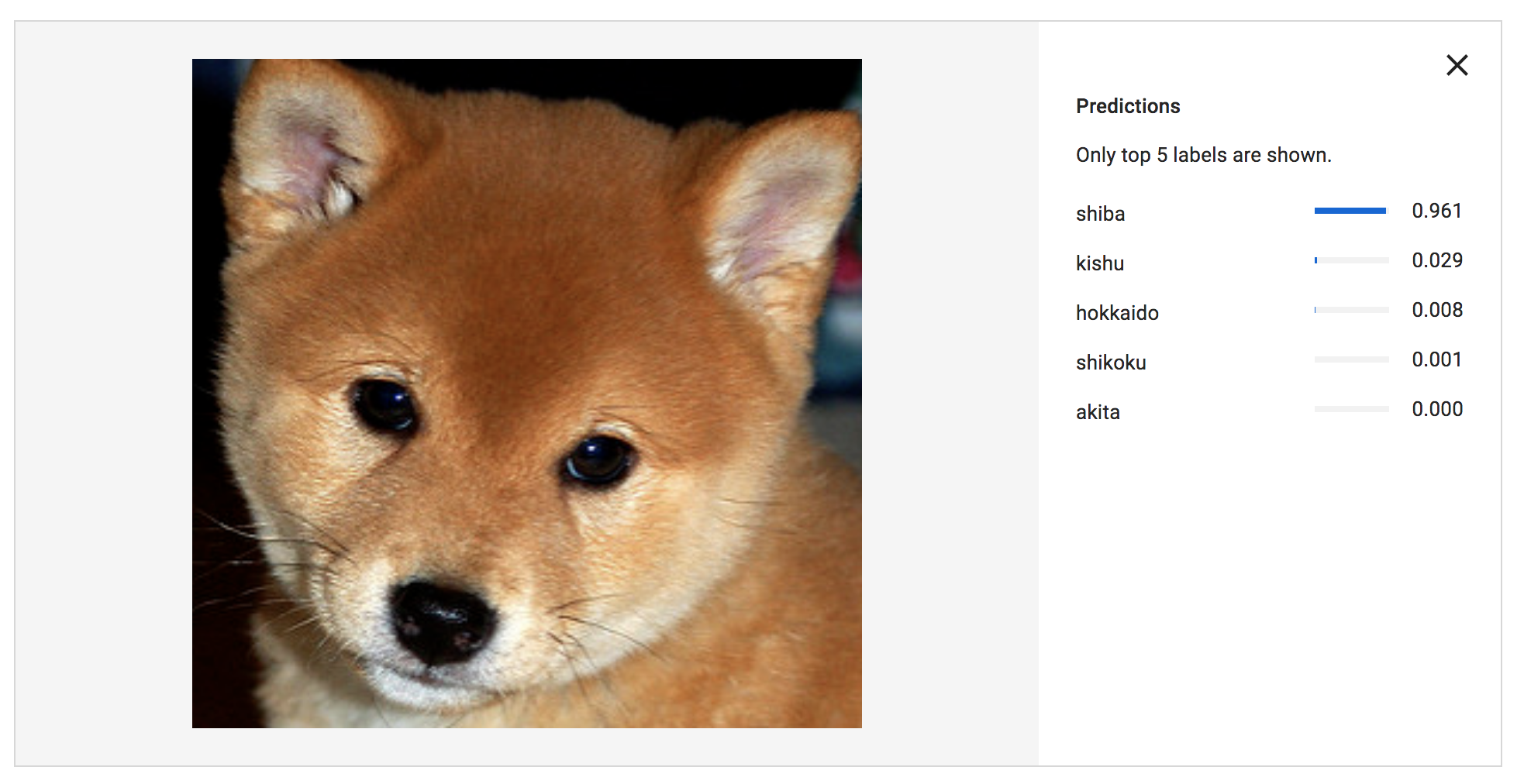
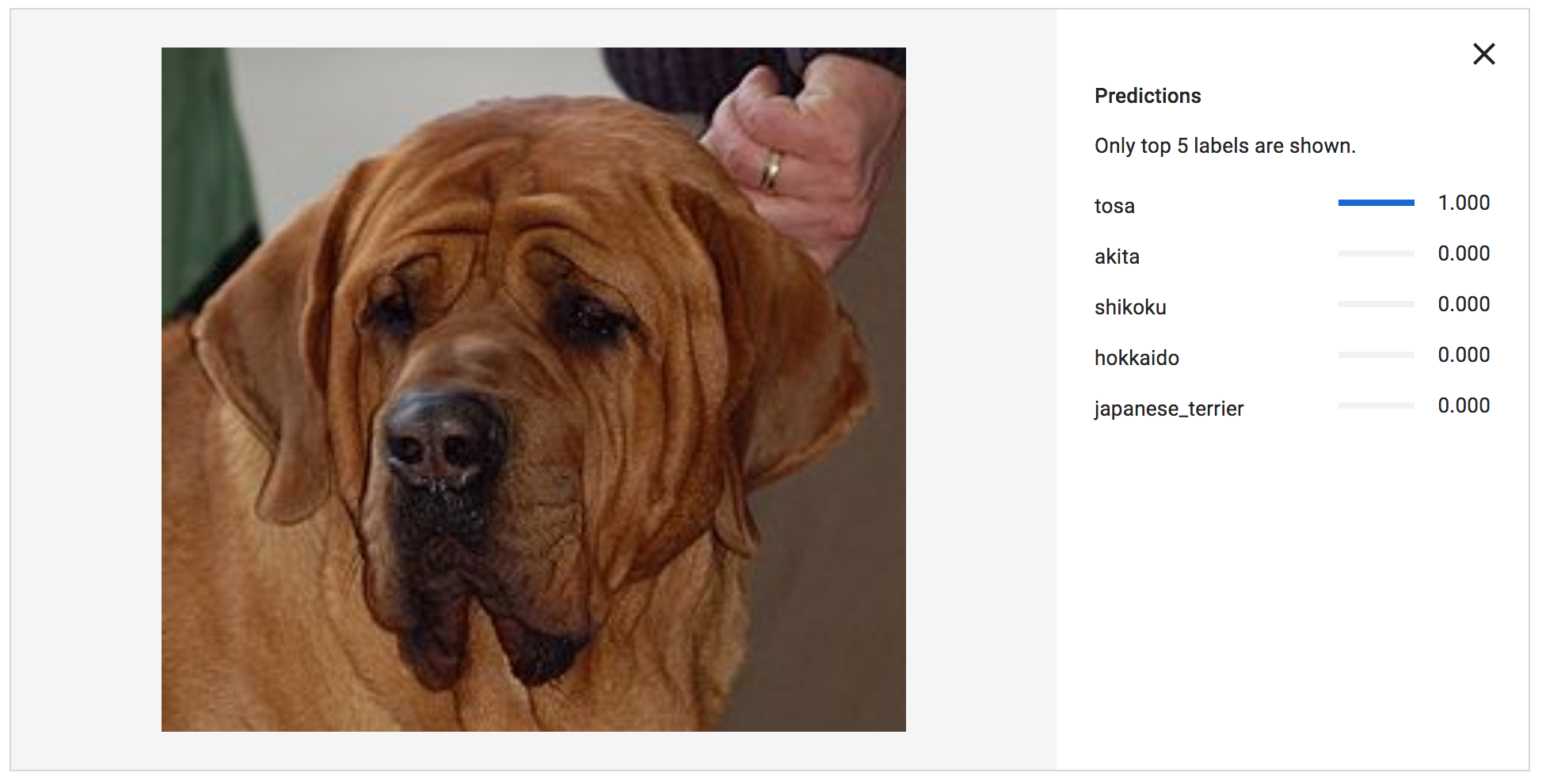
深く検証したわけではないですが、学習データが少なかった土佐犬、パッと見判別し辛い北海道犬と紀州犬も、かなりの精度で判別出来ているようです!
料金
超概算ですが以下になります。
- AutoML Vision: ¥0
- GCS: ¥10未満
- Bing Image Search API: ¥300程度(検証で結構叩いたので実際はもう少し安いかも)
まとめ
- AutoML Vision用の学習データを収集するスクリプトを(ざっくりと)作成しました。
- AutoML Visionで犬画像の認識モデルを作成しました。
- AutoML Vision最高!
Cloud Functions (Python3)入門用に LINE BOTを作ってみる
はじめに
今回の目的はLINE BOTの下地をCloud Functions(GCF)を使って作ること。
言語としては、最近サポートされはじめたPython3を使用する。
LINEで公開しているサンプルコードにあるオウム返しするアプリを、Cloud Functionsでうごかしてみる。
今回つかってみるもの
- LINE Messaging API
- Google Cloud Functions
- Python3
準備
LINE BOT
LINE Developersへ登録
以下のURLからLINE Developersへサインアップ
https://developers.line.biz/ja/
プロバイダーとチャネルの作成
プロバイダーとチャネルという概念があるが、
プロバイダーを作成
チャネル作成を選び、MessageAPIを選択
チャネル作成完了
チャネルの基本設定の確認
以下は後ほどアプリケーション内で使う。
Channel Secretの確認
基本設定 > 基本情報 > Channel Secret
AccessTokenを作成し、確認
基本設定 > メッセージ送受信設定 > AccessToken
Cloud Functions
Google Cloud
以下から登録
https://cloud.google.com/
迷うことはないと思いますが、わからなくてもググればいい記事が出てくるはずなので割愛。
Cloud Functionsの作成
- Cloud Functions API を有効化

- 作成ボタンを押す

- 各種項目を設定する
ひとまず以下のようにうめる
| 項目 | 値 |
|---|---|
| 名前 | (任意) |
| 割り当てられるメモリ | 256MB |
| トリガー | HTTP |
| URL | (自動) |
| ソースコード | インラインエディタ |
| ランタイム | Python3.7 |
| 実行する関数 | (任意。main.pyの中にある関数を指定) |
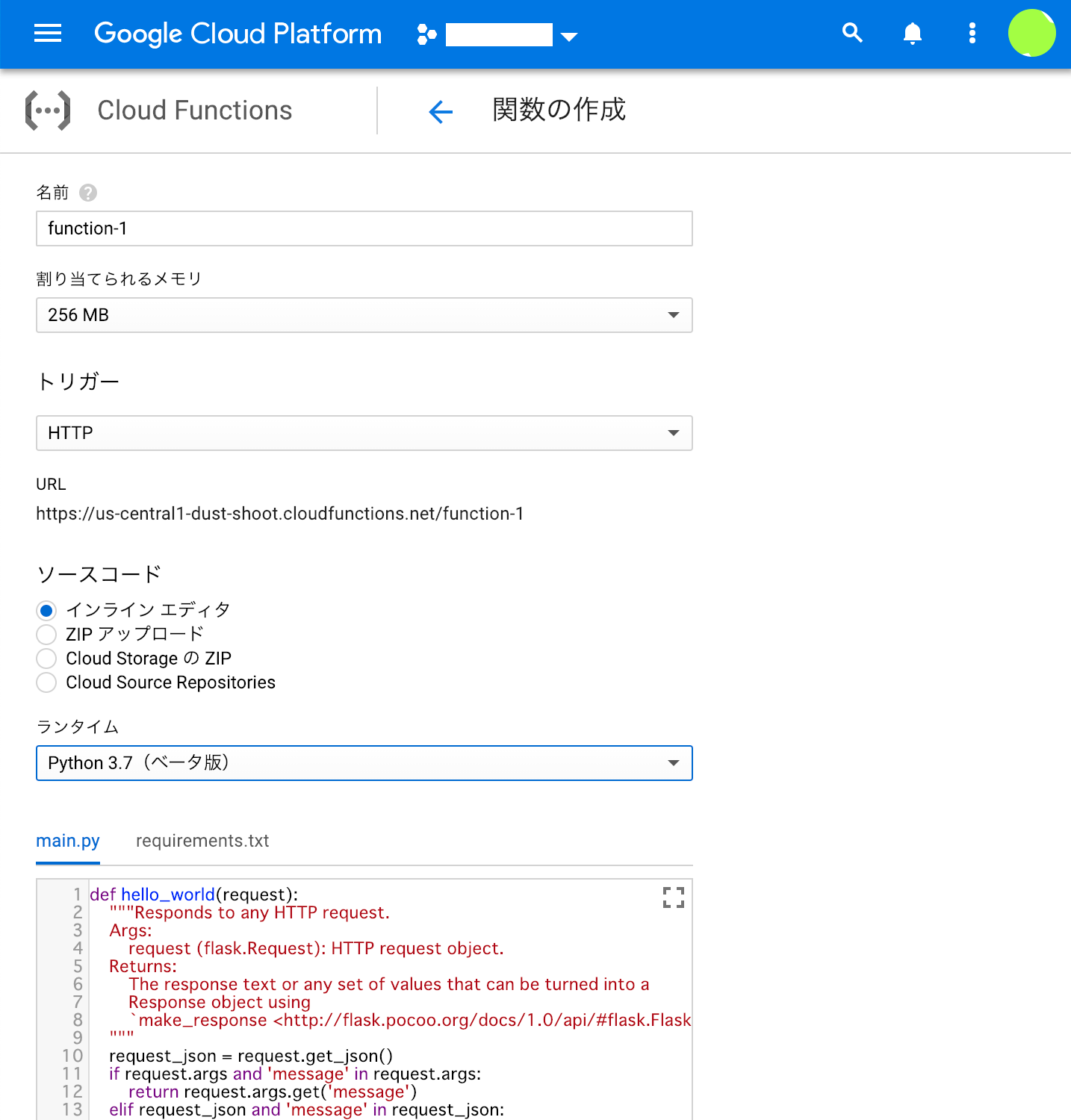
- 項目を埋めたら作成
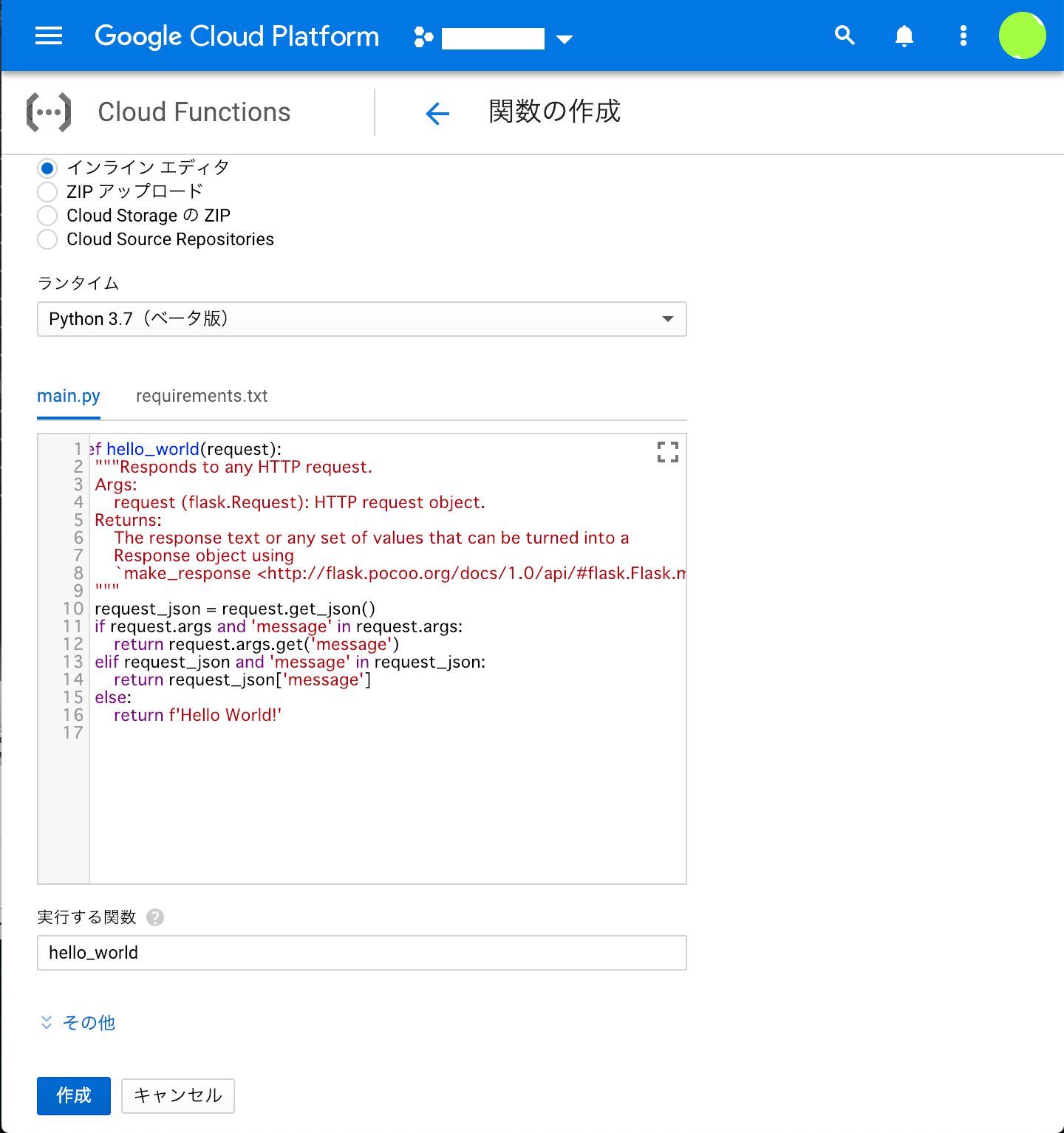
実装
コードはローカルで実装し、git管理して、gcloudコマンドでデプロイしてもいいし、今回くらいの規模なら、直接インラインエディタで書いてもいいかもしれない。
ディレクトリ構造
project/
├ main.py
└ requirements.txt
Python3での実装
実行される関数をかく
main.py
import os
import base64, hashlib, hmac
import logging
from flask import abort, jsonify
from linebot import (
LineBotApi, WebhookParser
)
from linebot.exceptions import (
InvalidSignatureError
)
from linebot.models import (
MessageEvent, TextMessage, TextSendMessage
)
def main(request):
channel_secret = os.environ.get('LINE_CHANNEL_SECRET')
channel_access_token = os.environ.get('LINE_CHANNEL_ACCESS_TOKEN')
line_bot_api = LineBotApi(channel_access_token)
parser = WebhookParser(channel_secret)
body = request.get_data(as_text=True)
hash = hmac.new(channel_secret.encode('utf-8'),
body.encode('utf-8'), hashlib.sha256).digest()
signature = base64.b64encode(hash).decode()
if signature != request.headers['X_LINE_SIGNATURE']:
return abort(405)
try:
events = parser.parse(body, signature)
except InvalidSignatureError:
return abort(405)
for event in events:
if not isinstance(event, MessageEvent):
continue
if not isinstance(event.message, TextMessage):
continue
line_bot_api.reply_message(
event.reply_token,
TextSendMessage(text=event.message.text)
)
return jsonify({ 'message': 'ok'})
pip install しないといけないものをここに記載する
requirements.txt
# Function dependencies, for example:
# package>=version
line-bot-sdk
Cloud Functionsのローカルエミュレータについて
残念ながら、Python3は対応していないので割愛
Cloud Functions へデプロイ
gcloud functions deploy hogehoge --trigger-http
Cloud Functions の環境変数の設定
上述したように、チャネル設定を確認し、
Channel SecretをLINE_CHANNEL_SECRETとして
AccessTokenをLINE_CHANNEL_ACCESS_TOKENとして設定する。
Cloudコンソールから
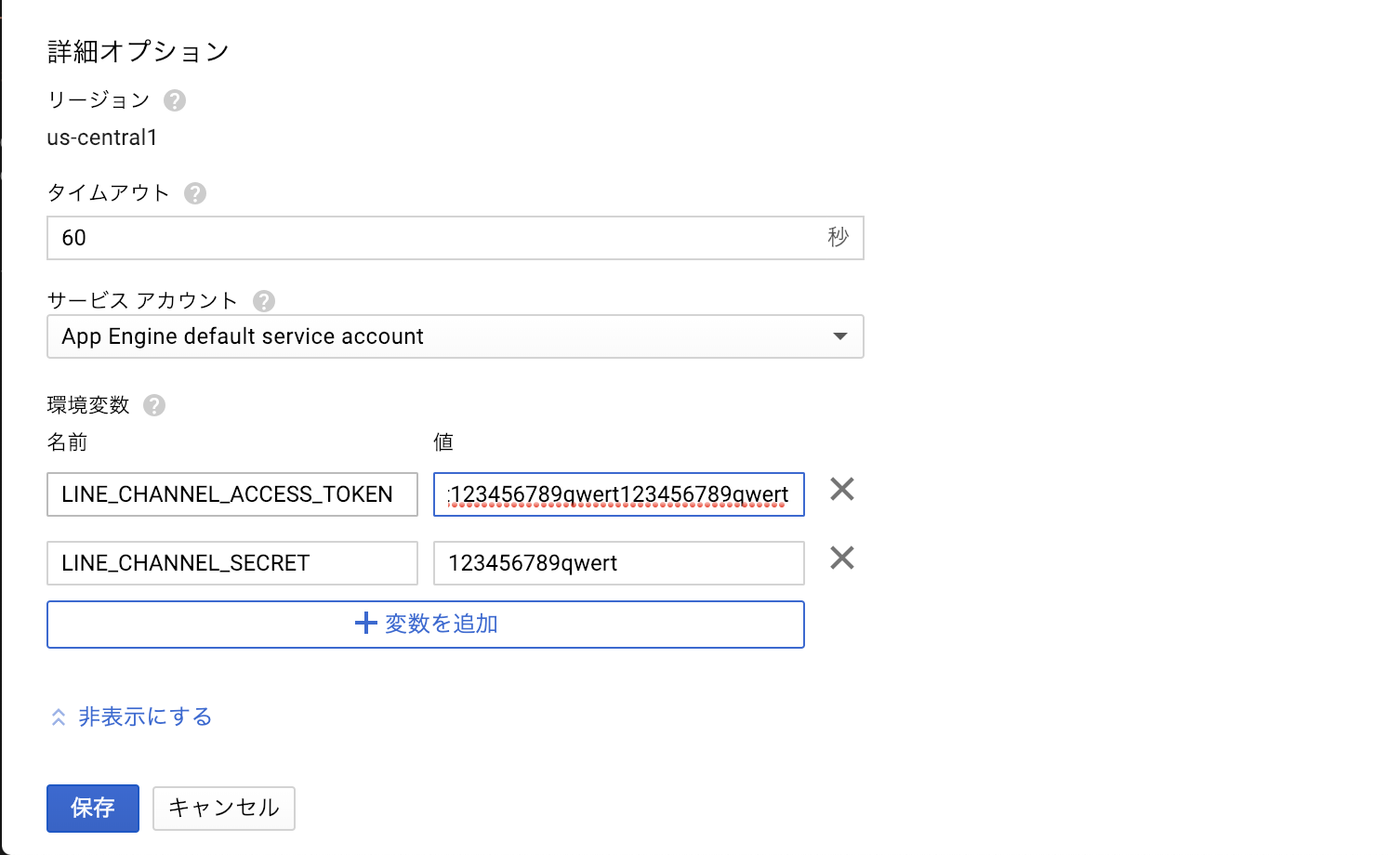
コマンドから
gcloud functions deploy hogehoge --trigger-http --set-env-vars LINE_CHANNEL_SECRET=123456789qwert123456789qwert,LINE_CHANNEL_ACCESS_TOKEN=123456789qwert
挙動
LINE BOT
友だち追加
チャネル基本設定に「LINEアプリへのQRコード」という項目があるので、
それを読み取ると作ったBOTを友だちに追加できる。
チャット
追加すると、チャットをはじめられる。
今回はオウム返しするサンプルコードを使ったのでこんな感じ。
とりあえずこれで最低限の挙動は確認できた。
まとめ
以下の簡単な使い方だけまとめました。
- LINE Messaging API
- Google Cloud Functions
- Python3
やったこととしては、LINEで公開されているサンプルコードにあるオウム返しするアプリを、
Cloud Functions(Python)でうごかしてみた。
基本的にLINEとGoogleの公式ドキュメントが丁寧なので、それを見ていれば問題なさそう。
(特にLINEのドキュメントにはPythonのコードが多いので、Pythonで実装していると楽かもしれない)
参考
- https://developers.line.biz/ja/reference/messaging-api/
- https://cloud.google.com/functions/docs/concepts/python-runtime
展望
今回つくったものを基に、他APIと連携などしてちゃんとしたアプリケーションを作っていく。
Python3は現時点でベータ版なので、今後仕様がいろいろかわるかもしれないが・・・。
(ローカルエミュレータはやく対応してくれ)
Cloud Spannerのindexの簡単な性能試験
Advent Calendar 2018 25日目でしたが、盛大に遅刻しました。ごめんなさい。
Cloud Spannerのindex
Cloud Spannerは昨今注目されるGCPのサービスですが、現在の疑問点としてindexってどうなの?というのがあります。
indexについてのTIPSは公式のCloud Spanner でのクエリ パフォーマンスの向上を読むと大まかに分かりますが、その性能についての詳細な記事は公式/非公式問わず見かけません。
そこで今回、Cloud Spanner(以下Spanner)のindexを張ったときの性能劣化やindex利用による検索速度の向上がどんなものかを調べました。
ストレージがSplitに分かれていてPaxosによる遅延がそこそこあるのでindexを付けることでSplitをまたぐ更新が行われるためindexによる性能劣化が他のRDBMSより大きいのでは?とか、結果について技術的な面からの考察はやりません。
index の limit
基本的なところを確認しておきます
| 項目 | 制限 |
|---|---|
| データベースあたりのindex数 | 4,096 |
| テーブルあたりのindex数 | 32 |
| index名の文字数 | 1~128 文字 |
| indexキーの列数 | 16 |
実は当初このテーブル辺りのindex数の制限はもっと高いと勘違いしていて、100index/テーブルで試そうとしていました。
検証環境
今回試験に当たっては、GCPUG Shared Spanner (スポンサーはメルペイさん)を使用させてもらいました。
自前で借りたら月7万円もするSpannerを、いつでもどこでも自由に使える検証環境です。非常に有難いですね。Spannerを試してみたいと思ったら是非ご利用ください。
テーブル定義
1. 基本テーブル
一般的には推奨されない、いわゆる列持ちテーブルです。
この基本テーブルでは、セカンダリindexはつけていないため、主キーを用いない検索は全てテーブルスキャンになります。
比較に使うindex付きのテーブルも、異なるのはindex定義のみで基本となる部分はすべてこれと同じです
CREATE TABLE fighter_play_count (
player_id INT64,
kirby INT64,
mario INT64,
donkey_kong INT64,
link INT64,
samus INT64,
yoshi INT64,
fox INT64,
pikachu INT64,
luigi INT64,
ness INT64,
captain_falcon INT64,
peach INT64,
koopa INT64,
zelda INT64,
marth INT64,
sonic INT64,
snake INT64,
rockman INT64,
murabito INT64,
inkling INT64,
) PRIMARY KEY(player_id);
2. シンプルなindex
kirby列にのみindexを張ります。
このテーブルでは、kirbyによる検索や並び替えにはindexが利きますが、その場合は主キーのplayer_idとkirby以外の値を取得できません。(取得しようとする場合はindex未使用になります)
CREATE TABLE fighter_play_count_one_simple_index (
-- 省略
) PRIMARY KEY (player_id);
CREATE INDEX simple_kirby
ON fighter_play_count_one_simple_index (
kirby
);
3. 複雑なindex
許可されてる最大数(つまり16)の列にindexを張ります
「15列しかないじゃないか?」ですって?
そうなんですよね。実は主キーもこの制限に含まれるんですよ。これはSpannerのindex使う上でのちょっとした注意点です。
ちなみに、STORING句で保存した列はこの制限に含まれないようです
CREATE TABLE fighter_play_count_one_multi_column_index(
-- 省略
) PRIMARY KEY (player_id);
CREATE INDEX simple_kirby
ON fighter_play_count_one_multi_column_index (
kirby,
mario,
donkey_kong,
link,
samus,
yoshi,
fox,
pikachu,
luigi,
ness,
captain_falcon,
peach,
koopa,
zelda,
marth
);
4. 20個のシンプルなindex
全ての列に対して個別にindexを張ります。
CREATE TABLE fighter_play_count_20_index(
-- 省略
) PRIMARY KEY (player_id);
CREATE INDEX captain_falcon ON fighter_play_count_20_index(captain_falcon);
CREATE INDEX donkey_kong ON fighter_play_count_20_index(donkey_kong);
CREATE INDEX fox ON fighter_play_count_20_index(fox);
CREATE INDEX inkling ON fighter_play_count_20_index(inkling);
CREATE INDEX kirby ON fighter_play_count_20_index(kirby);
CREATE INDEX koopa ON fighter_play_count_20_index(koopa);
CREATE INDEX link ON fighter_play_count_20_index(link);
CREATE INDEX luigi ON fighter_play_count_20_index(luigi);
CREATE INDEX mario ON fighter_play_count_20_index(mario);
CREATE INDEX marth ON fighter_play_count_20_index(marth);
CREATE INDEX murabito ON fighter_play_count_20_index(murabito);
CREATE INDEX ness ON fighter_play_count_20_index(ness);
CREATE INDEX peach ON fighter_play_count_20_index(peach);
CREATE INDEX pikachu ON fighter_play_count_20_index(pikachu);
CREATE INDEX rockman ON fighter_play_count_20_index(rockman);
CREATE INDEX samus ON fighter_play_count_20_index(samus);
CREATE INDEX snake ON fighter_play_count_20_index(snake);
CREATE INDEX sonic ON fighter_play_count_20_index(sonic);
CREATE INDEX yoshi ON fighter_play_count_20_index(yoshi);
CREATE INDEX zelda ON fighter_play_count_20_index(zelda);
5. 32個の複雑なindex
セカンダリindexは32個つけられます(プライマリindexは制限に含まれない)
- 2列に対するindexが1つ
- 3列に対するindexが1つ
- ・・・
- 13列に対するindexが1つ
- 15列に対するinedxが20個
CREATE TABLE fighter_play_count_32_multi_column_index(
-- 省略
) PRIMARY KEY (player_id);
CREATE INDEX kirby_to_mario ON fighter_play_count_32_multi_column_index(kirby, mario);
CREATE INDEX kirby_to_kong ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong);
CREATE INDEX kirby_to_link ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link);
CREATE INDEX kirby_to_samus ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus);
CREATE INDEX kirby_to_yoshi ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi);
CREATE INDEX kirby_to_fox ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox);
CREATE INDEX kirby_to_pikachu ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu);
CREATE INDEX kirby_to_luigi ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi);
CREATE INDEX kirby_to_ness ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness);
CREATE INDEX kirby_to_falcon ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon);
CREATE INDEX kirby_to_peach ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach);
CREATE INDEX kirby_to_koopa ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa);
CREATE INDEX kirby_to_marth ON fighter_play_count_32_multi_column_index(kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth);
CREATE INDEX donkey_to_inkling ON fighter_play_count_32_multi_column_index(donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake);
CREATE INDEX falcon_to_samus ON fighter_play_count_32_multi_column_index(captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus);
CREATE INDEX fox_to_kirby ON fighter_play_count_32_multi_column_index(fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby);
CREATE INDEX inkling_to_zelda ON fighter_play_count_32_multi_column_index(inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda);
CREATE INDEX koopa_to_fox ON fighter_play_count_32_multi_column_index(koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox);
CREATE INDEX link_to_rockman ON fighter_play_count_32_multi_column_index(link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman);
CREATE INDEX luigi_to_donkey ON fighter_play_count_32_multi_column_index(luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong);
CREATE INDEX mario_to_sonic ON fighter_play_count_32_multi_column_index(mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic);
CREATE INDEX marth_to_luigi ON fighter_play_count_32_multi_column_index(marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi);
CREATE INDEX murabito_to_koopa ON fighter_play_count_32_multi_column_index(murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa);
CREATE INDEX ness_to_link ON fighter_play_count_32_multi_column_index(ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link);
CREATE INDEX peach_to_yoshi ON fighter_play_count_32_multi_column_index(peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi);
CREATE INDEX pikachu_to_mario ON fighter_play_count_32_multi_column_index(pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario);
CREATE INDEX rockman_to_peach ON fighter_play_count_32_multi_column_index(rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach);
CREATE INDEX samus_to_murabito ON fighter_play_count_32_multi_column_index(samus, yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito);
CREATE INDEX snake_to_falcon ON fighter_play_count_32_multi_column_index(snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness, captain_falcon);
CREATE INDEX sonic_to_ness ON fighter_play_count_32_multi_column_index(sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu, luigi, ness);
CREATE INDEX yoshi_to_inkling ON fighter_play_count_32_multi_column_index(yoshi, fox, pikachu, luigi, ness, captain_falcon, peach, koopa, zelda, marth, sonic, snake, rockman, murabito, inkling);
CREATE INDEX zelda_to_pikachu ON fighter_play_count_32_multi_column_index(zelda, marth, sonic, snake, rockman, murabito, inkling, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu);
性能試験
これら5つのテーブルに対して同じシナリオでinsertのみの試験を行いました
ただ、予想されたことですが4.と5.のテーブルは性能劣化が著しく、CPU負荷も半端なかったので試験を予定の半分で打ち切りました。
シナリオ
かなり雑ですが以下のようにやりました。一応ですが、ローカルマシンのリソースは基本テーブルへの試験時も十分に余裕がありました。
- ローカルのマシンで8スレッドに並列化して複数トランザクションを同時に実行
- 1トランザクションで30レコードをinsert
- insert する内容
- player_id:MIN(INT64)~MAX(INT64)の範囲で無作為な値
- 主キー以外の各列:0~999の範囲で無作為な値
- レコード数が(
目視で)10万を超えたら(手動で)停止して、掛かった時間を計測(4.と5.は半分の5万)
結果まとめ
index数を増やした4.と5.はレコード数増加により明確に性能劣化が見られました。
| 項目 | 試験終了時の行数 | 所要時間 | 大体のCPU負荷 | 1秒当たりのオペレーション回数(概算) |
|---|---|---|---|---|
| 1. 基本テーブル | 101,640 | 13:11 | 50% | 200 |
| 2. シンプルなindex | 100,680 | 26:35 | 70% | 105 |
| 3. 複雑なindex | 100,140 | 27:41 | 75% | 102 |
| 4. 20個のシンプルなindex | 50,190 | 25:34 | 100% | 60~45 |
| 5. 32個の複雑なindex | 50,130 | 57:07 | 100%付近であらぶる | 38~25 |
- 1.と2.の比較
- indexの有る無しでCPU負荷・秒間オペレーション回数ともにまず大きな差が見られます
- 2.と3.の比較
- indexのキー列数が1→15(主キーも入れると2→16)では、微々たる差でした。
- 2.および3. と4.の比較
- index自体の数が増えると、明確に性能が落ちます
- 4.と5.の比較
- そもそもindexの数も20→32に増えてるので同様に性能は落ちますよね。
- 5.をやる意味はあまりなかったかもしれない
性能試験時の負荷
各テーブルごとにSpannerへの負荷がどれくらいだったのかの記録
1. 基本テーブル
2. シンプルなindex
11:56くらいからの山です
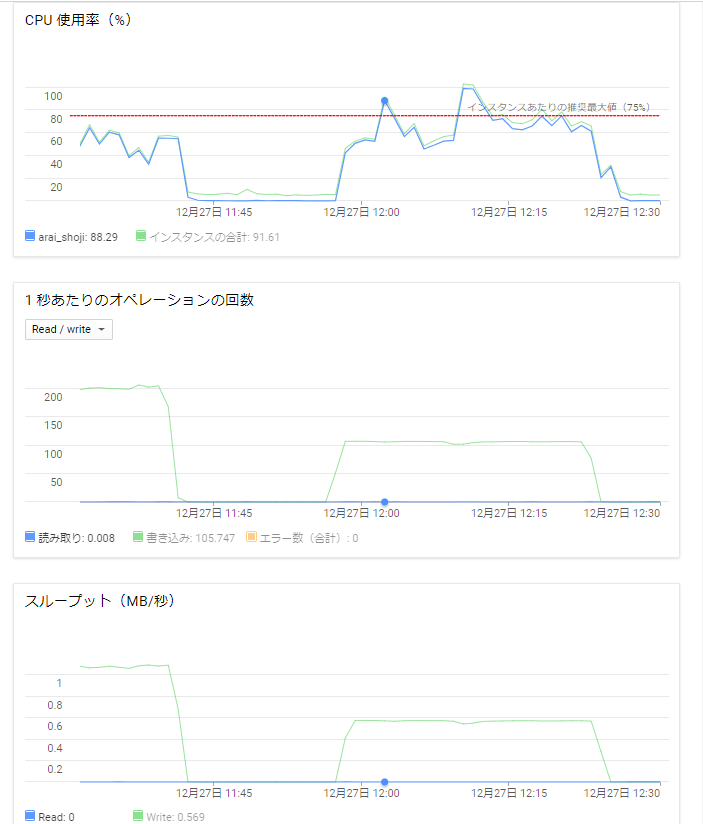
3. 複雑なindex
12:32くらいからの山です
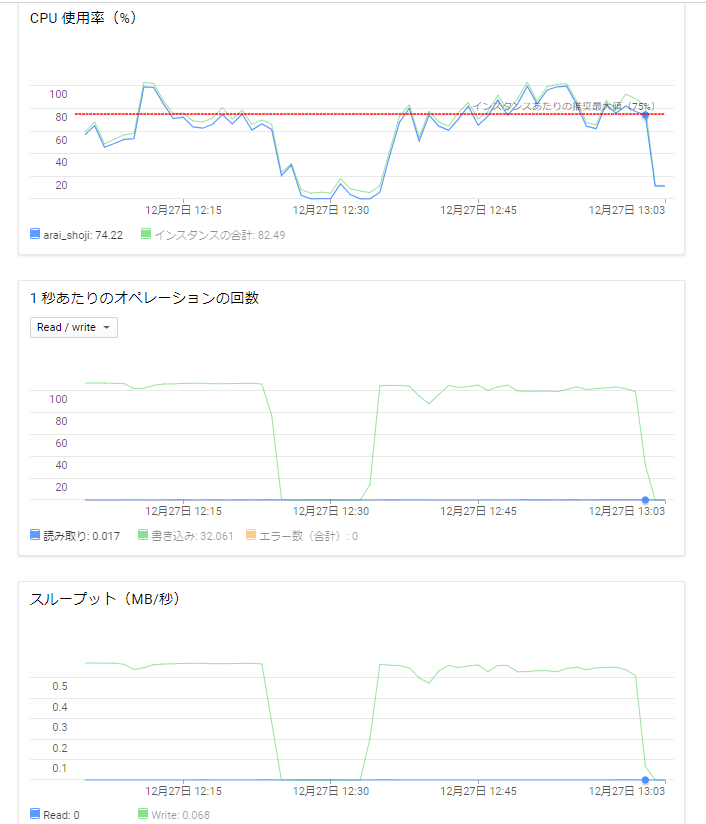
4. 20個のシンプルなindex
13:12くらいからの山です。13:07くらいのはミス
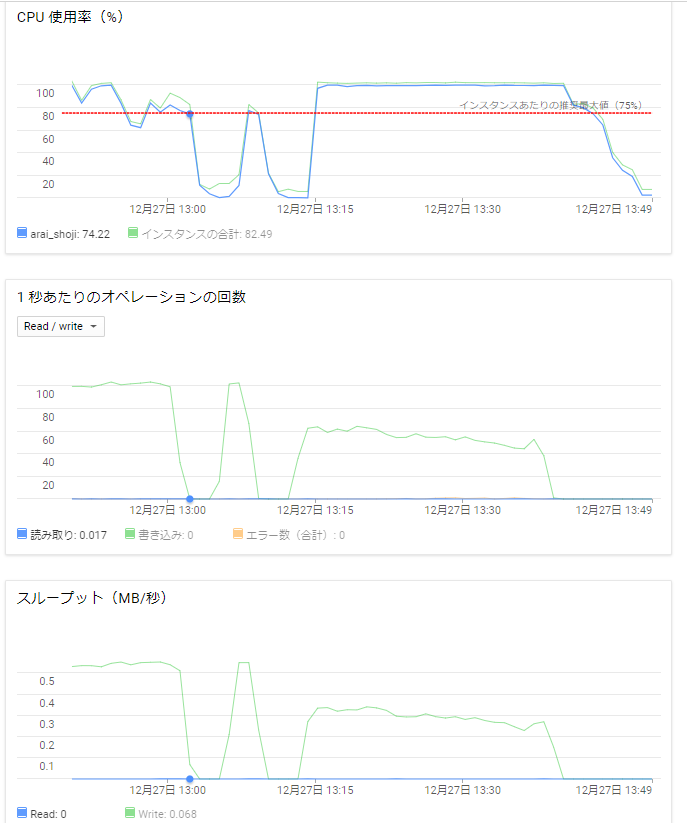
5. 32個の複雑なindex
相当な負荷かけてしまい本当にあせりました。
長かったので開始時のグラフは切れてしまっています。
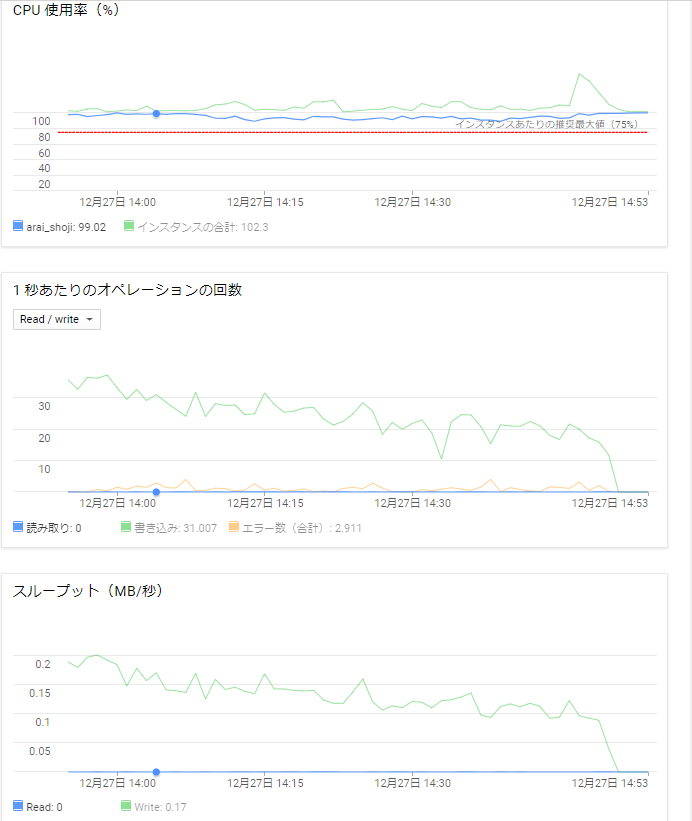
全体
検索性能について
Spanner はGCPコンソール上から検索ができ、しかも詳細な実行計画も取得できます。
いくつか試してみました。もし読者の方で自分でも試してみたいという方が居れば、GCPUG slack に参加して声をかけてください
1. 基本テーブル
1-1
SELECT * FROM fighter_play_count LIMIT 100
1-2
SELECT * FROM fighter_play_count WHERE kirby > 900 LIMIT 100
| SQL | 合計経過時間 | CPU時間 | 検索方法 |
|---|---|---|---|
| 1-1 | 20.62ms | 15.48ms | Table Scan |
| 1-2 | 21.09ms | 16.98ms | Table Scan |
- フルスキャンなので当然変わらないです
2. シンプルなindex
2-1
SELECT * FROM fighter_play_count_one_simple_index LIMIT 100
2-2
SELECT * FROM fighter_play_count_one_simple_index WHERE kirby > 900 LIMIT 100
2-3
SELECT player_id, kirby FROM fighter_play_count_one_simple_index WHERE kirby > 900 LIMIT 100
2-4
SELECT player_id, kirby FROM fighter_play_count_one_simple_index WHERE kirby > 900 ORDER BY mario LIMIT 100
| SQL | 合計経過時間 | CPU時間 | 検索方法 |
|---|---|---|---|
| 2-1 | 20.85ms | 15.97ms | Table Scan |
| 2-2 | 23.97ms | 17.09ms | Table Scan |
| 2-3 | 8.9ms | 5.19ms | Index Scan |
| 2-4 | 337.54ms | 392.3ms | Table Scan |
- 2-2、2-3から分かるように、カバリングindexとしてしかindexの恩恵を受けられません。
- 「合計経過時間<CPU時間」の場合は、実行計画の一部を並列化しています
3. 複雑なindex
3-1
SELECT * FROM fighter_play_count_one_multi_column_index LIMIT 100
3-2
SELECT * FROM fighter_play_count_one_multi_column_index WHERE kirby > 900 LIMIT 100
3-3
SELECT player_id, kirby FROM fighter_play_count_one_multi_column_index WHERE kirby > 900 LIMIT 100
3-4
SELECT player_id, kirby FROM fighter_play_count_one_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
3-5
SELECT * FROM fighter_play_count_one_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
3-6
SELECT player_id, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu FROM fighter_play_count_one_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
| SQL | 合計経過時間 | CPU時間 | 検索方法 |
|---|---|---|---|
| 3-1 | 20.68ms | 15.77ms | Table Scan |
| 3-2 | 23.05ms | 19.82ms | Table Scan |
| 3-3 | 11.49ms | 6.36ms | Index Scan |
| 3-4 | 78.35ms | 68.66ms | Index Scan |
| 3-5 | 955.21ms | 910.91ms | Table Scan |
| 3-6 | 79.61ms | 63.44ms | Index Scan |
- 3-6を見ると、indexに含まれてさえいれば取得列数による性能の変化は特に無いようですね。
- ただし、検索条件やソート条件に含めないのであればこの場合はSTORING句で指定するほうが良いでしょう。
4. 20個のシンプルなindex
4-1
SELECT * FROM fighter_play_count_20_index LIMIT 100
4-2
SELECT * FROM fighter_play_count_20_index WHERE kirby > 900 LIMIT 100
4-3
SELECT player_id, kirby FROM fighter_play_count_20_index WHERE kirby > 900 LIMIT 100
4-4
SELECT player_id, kirby FROM fighter_play_count_20_index WHERE kirby > 900 ORDER BY mario LIMIT 100
4-5
SELECT * FROM fighter_play_count_20_index WHERE kirby > 900 ORDER BY mario LIMIT 100
4-6
SELECT player_id, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu FROM fighter_play_count_20_index WHERE kirby > 900 ORDER BY mario LIMIT 100
| SQL | 合計経過時間 | CPU時間 | 検索方法 |
|---|---|---|---|
| 4-1 | 21.13ms | 16.37ms | Table Scan |
| 4-2 | 25.44ms | 14.62ms | Table Scan |
| 4-3 | 9.61ms | 3.84ms | Index Scan |
| 4-4 | 168.20ms | 148.36ms | Table Scan |
| 4-5 | 522.22ms | 505.88ms | Table Scan |
| 4-6 | 234.72ms | 224.52ms | Table Scan |
- 4-5と4-6 は何回か試してもこの傾向。Table Scanの場合かつソートする場合は、取ってくる列数によって変わるのかもしれません。
- というか4.のテーブルで試験をする意味があったかというと、あまりなかったかも。
5. 32個の複雑なindex
5-1
SELECT * FROM fighter_play_count_32_multi_column_index LIMIT 100
5-2
SELECT * FROM fighter_play_count_32_multi_column_index WHERE kirby > 900 LIMIT 100
5-3
SELECT player_id, kirby FROM fighter_play_count_32_multi_column_index WHERE kirby > 900 LIMIT 100
5-4
SELECT player_id, kirby FROM fighter_play_count_32_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
5-5
SELECT * FROM fighter_play_count_32_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
5-6
SELECT player_id, kirby, mario, donkey_kong, link, samus, yoshi, fox, pikachu FROM fighter_play_count_32_multi_column_index WHERE kirby > 900 ORDER BY mario LIMIT 100
| SQL | 合計経過時間 | CPU時間 | 検索方法 |
|---|---|---|---|
| 5-1 | 20.97ms | 16.32ms | Table Scan |
| 5-2 | 98.07ms | 81.34ms | Table Scan |
| 5-3 | 10.92ms | 4.32ms | Index Scan |
| 5-4 | 52.30ms | 45.16ms | Index Scan |
| 5-5 | 3.89s | 3.4s | Table Scan |
| 5-6 | 132.86ms | 126.17ms | Index Scan |
- 5-2は何度やっても重かったです。indexがあまりに複雑だとTable Scanにも影響出るのでしょうか?
全体のまとめ
- 基本的には一般的に知られるindexとの付き合い方をするってことで良さそう。
- indexあるなしではそれなりに性能差が出る
- 更新系もちゃんと試験するべきでした。
- 相関クエリなど複雑なクエリで試したときに効果でるindexを使用した(つまり実用的な)パターンでも試験するべきでした。