はじめに
この記事はGoアドベントカレンダーの1日目の記事です。
スライスの実態
runtimeのコードをみるとGoのスライスは以下のように定義されています。
type slice struct {
array unsafe.Pointer
len int
cap int
}
reflectパッケージのSliceHeaderを見ても次のような定義になっています。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
つまり、Goのスライスは次の図のように、配列へのポインタと長さと容量を持った値として表現されています。
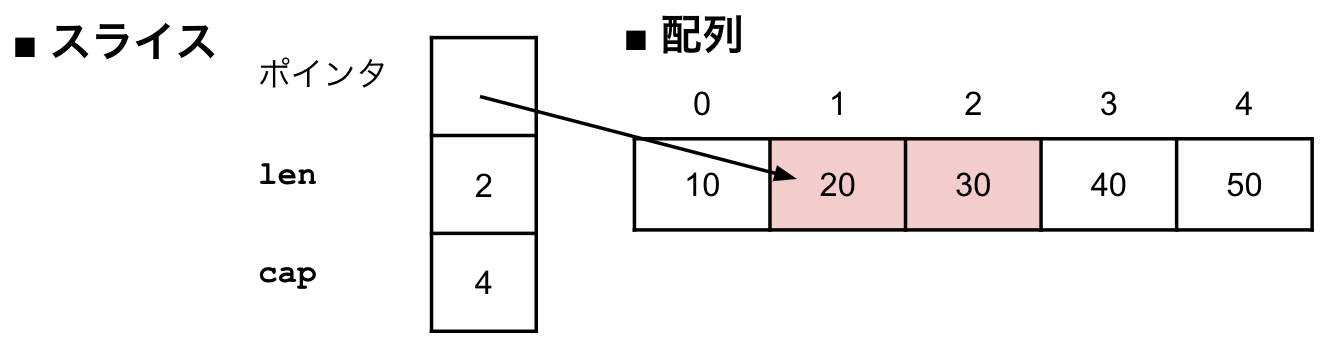
runtimeとreflectパッケージでポインタがunsafe.Pointerとuintptrで表現方法は違いますが、どちらもポインタを表す値です。
unsafe.Pointerは任意型のポインタと相互変換可能な型です。一方で、uintptrは整数型でunsafe.Pointerに変換が可能な型です。uintptrは整数型の1つなので、int型などと同様に四則演算が可能です。

次のように、[]int型をreflect.SliceHeader型として解釈してみます。
まず、[]int型の変数であるnsのポインタを取り、unsafe.Pointer型に変換します。
変換した値はptrという変数に入れています。
次に、ptrを*reflect.Slice型にキャストし、そのポインタが指す先の値をreflect.SliceHeader型の変数sに代入しています。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
ns := []int{10, 20, 30}
// nsをunsafe.Pointerに変換する
ptr := unsafe.Pointer(&ns)
// ptrを*reflect.SliceHeaderにキャストして、それが指す値をsにいれる
s := *(*reflect.SliceHeader)(ptr)
fmt.Printf("%#v\n", s)
}
要素へのアクセス
reflect.SliceHeaderを用いてi番目のスライスの要素にアクセス方法を考えて見ましょう。reflect.SliceHeaderはスライスが参照している配列へのポインタを持っています。そのポインタは、スライスの0番目の要素を指すポインタです。
そのため、次のat関数のように、先頭へポインタから要素i個分のポインタを進めた場所がi番目の要素のポインタとなります。要素の型によって、1要素あたりどのくらいポインタを進めれば良いのかは違うため、次の例ではint型の場合に限定しています。任意の型のサイズを取得するには、unsafe.Sizeofを用います。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func at(s reflect.SliceHeader, i int) unsafe.Pointer {
// 先頭ポインタ + インデックス * int型のサイズ
return unsafe.Pointer(s.Data + uintptr(i)*unsafe.Sizeof(int(0)))
}
func main() {
a := [...]int{10, 20, 30}
s := reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&a[0])), Len: 2, Cap: len(a)}
*(*int)(at(s, 0)) = 100 // unsafe.Pointerを*intに変換して代入している
fmt.Println(a)
}
要素の追加
ここでappend関数のような機能を実装してみたいと思います。
appendは追加する際に、スライスが参照している配列の容量が足りている場合と足りたない場合で挙動が異なるため、それぞれ考えてみます。
容量が足りる場合
容量が足りる場合は、単純に次の手順で要素の追加を行います。
- 新しい要素をコピーする
- 長さを更新する
package main
import (
"fmt"
"reflect"
"unsafe"
)
func at(s reflect.SliceHeader, i int) unsafe.Pointer {
// 先頭ポインタ + インデックス * int型のサイズ
return unsafe.Pointer(s.Data + uintptr(i)*unsafe.Sizeof(int(0)))
}
func myAppend(s reflect.SliceHeader, vs ...int) reflect.SliceHeader {
// 新しい要素の追加
for i := 0; i < len(vs); i++ {
*((*int)(at(s, s.Len+i))) = vs[i]
}
return reflect.SliceHeader{Data: s.Data, Len: s.Len + len(vs), Cap: s.Cap}
}
func main() {
a := [...]int{10, 20, 30}
// s := a[0:2] -> [10 20]
s := reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&a[0])), Len: 2, Cap: len(a)}
s = myAppend(s, 400)
var ns []int
*(*reflect.SliceHeader)(unsafe.Pointer(&ns)) = s
fmt.Println(ns)
}
容量が足りない場合
一方で、容量が足りない場合は、次のように配列の再確保を行う必要があります。
- 元のおよそ2倍の容量を確保しなおす
- 配列へのポインタを貼り直す
- 元の配列から要素をコピーする
- 新しい要素をコピーする
- 長さと容量を更新する
この手順でスライスのサイズを拡張するための関数growsliceを実装すると次のようになります。そして、myAppend内で容量が足りない場合にgrowsliceを呼んでやることでスライスを拡張してやることができます。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func at(s reflect.SliceHeader, i int) unsafe.Pointer {
// 先頭ポインタ + インデックス * int型のサイズ
return unsafe.Pointer(s.Data + uintptr(i)*unsafe.Sizeof(int(0)))
}
func myAppend(s reflect.SliceHeader, vs ...int) reflect.SliceHeader {
// 容量が足りない場合
if s.Len+len(vs) > s.Cap {
s = growslice(s, s.Len+len(vs))
}
// 新しい要素の追加
for i := 0; i < len(vs); i++ {
*((*int)(at(s, s.Len+i))) = vs[i]
}
return reflect.SliceHeader{Data: s.Data, Len: s.Len + len(vs), Cap: s.Cap}
}
func growslice(old reflect.SliceHeader, cap int) reflect.SliceHeader {
newcap := cap
doublecap := old.Cap + old.Cap
if cap < doublecap {
newcap = doublecap
}
s := make([]int, old.Len, newcap)
newslice := *(*reflect.SliceHeader)(unsafe.Pointer(&s))
// 古いスライスから要素のコピー
for i := 0; i < old.Len; i++ {
*((*int)(at(newslice, i))) = *((*int)(at(old, i)))
}
return newslice
}
func main() {
a := [...]int{10, 20, 30}
// s := a[0:2] -> [10 20]
s := reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&a[0])), Len: 2, Cap: len(a)}
s = myAppend(s, 400, 500) // 溢れる
var ns []int
*(*reflect.SliceHeader)(unsafe.Pointer(&ns)) = s
fmt.Println(ns)
}
ここで注意したいのは、myAppendの戻り値がreflect.SliceHeaderという点です。要素の追加が行われた場合、少なくとも長さは更新されるため、戻り値として返す必要があります。
これはreflect.SliceHeader型は構造体のため、引数で受け取った値のフィールドをいくら変更しても呼び出し元に影響がないからです。例えば、次の例を見てみるとs2.Lenを変更してもs1.Lenに影響がないことが分かります。
func main() {
a := [...]int{10, 20, 30}
s1 := reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&a[0])), Len: 2, Cap: len(a)}
s2 := s1
s2.Len = 3 // s1には影響ない
fmt.Println(s1) // {4310908 2 3}
fmt.Println(s2) // {4310908 3 3}
}
おわりに
この記事では、スライスがどのように表現されているかを調べ、スライスに関数する処理を実際に実装するとことで、スライスを理解することを試みました。
なお、ここで扱ったunsafe.Pointerは次の例のように扱い方を間違えると大変危険なので、ご注意ください。
func main() {
v := struct {
a [5]int
b [2]int
}{
a: [...]int{10, 20, 30, 40, 50},
b: [...]int{100, 200},
}
// capがlen(a)より大きい
s := reflect.SliceHeader{Data: uintptr(unsafe.Pointer(&v.a[1])), Len: 2, Cap: 6}
var ns []int
*(*reflect.SliceHeader)(unsafe.Pointer(&ns)) = s
// aを超えてappend
ns = append(ns, 60, 70, 80)
fmt.Println(ns, v.a, v.b)
}