

こんにちは、エンジニアの建三です。
AIチャットって何?

弊社サービスのノマドではユーザーとのやり取りを主にチャットを使って行います。ユーザーはお部屋に関する質問から契約の手続きに至るまで、様々な用途でチャットを利用されます。中には簡単に答えられる質問があるので、それを人間が毎回答えるのは煩わしいですよね。そこで一部の質問を人口知能(AI)を使って自動で返信しています。
大まかな流れとしては、まずユーザーのメッセージの種類を300近くある種類の中から判別し、それに対してあらかじめ用意してある文を返します。その中で大きく分けて6つのステップがあるので、それぞれのステップについて説明します。
Step1 - 文分割(Sentence Segmentation)

ユーザーのメッセージによっては複数の文が入っている場合があるので、まずはメッセージを文に分割します。これは単純に句読点で区切ってるだけです。ステップ2以降は分割された文毎に行われます。
Step2 - 固有名詞抽出(Named Entity Recognition)

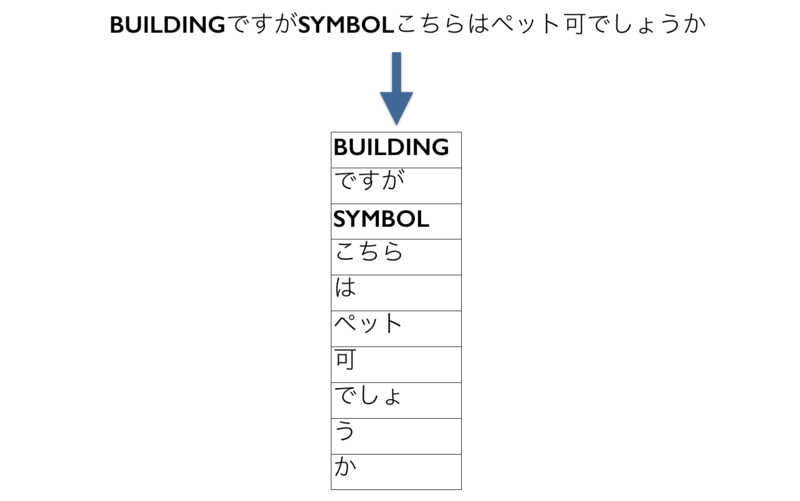
次は建物名、駅、URL、メールアドレス、数字、記号などを辞書と正規表現を使ってキーワードに置き換えます。
例えばこの文が「アトラス板橋ですが、こちらはペット可でしょうか」ではなく「ロアール麻布ですが、こちらはペット可でしょうか」だとしましょう。建物名が違うだけで、どちらもペット可かどうか聞いてることには変わりありません。質問の種類を判別する上で建物名は関係ないので、こういったものは一つのキーワードに置き換えた方が良いです。あとは単語数を減らすという意味でも重要です。
Step3 - わかち書き(Tokenization)
Step4 - 単語のベクトル化(Word Embedding)

次に単語をベクトル化します。これはword2vecが有名ですが、他にも単語をベクトル化する方法は沢山あります。僕はKerasというライブラリを使ってディープラーニングのモデルを作っています。KerasはTorchに影響を受けて出来たもので、レイヤーを重ねていくだけの簡単なAPIになっています。KerasにはEmbeddingのレイヤーがあるので、それを使います。
word2vecと何が違うかと言うと、word2vecは教師無し学習です。なので大量のデータを使って学習させることが出来ます。一方でKerasのEmbeddingのレイヤーはその後のレイヤーと一体となって使われるので、ラベルが付いたデータしか使えません。一方で、一つのモデルでEmbeddingから判別まで出来るので、word2vecのように別々に学習させる必要がありません。
どちらも試してみたところ、KerasのEmbeddingを使った時の方が精度が良いので今はそっちを使っています。なので実際はステップ4と5で1ステップという感じです。もっとデータを入れればword2vecの方が精度が良くなるかもしれません。
Step5 - 判別(Classification)

ここがメインとなる部分です。ベクトル化された単語の列を使ってメッセージの種類を判別します。KerasのLSTMを使っています。LSTMは有名なので説明は省きます。
Step6 - メッセージの作成

最後に、判別された質問の種類を元に適切なメッセージを返します。あらかじめそれぞれの質問に対して定型文を用意されているので、それを返すという流れです。一つのメッセージに複数の文がある場合は「また、」でそれぞれの返答文を繋げて返します。
物件に関する質問はメッセージの種類を正しく判別しただけでは返せません。チャット上でどの物件に関する質問か選べるようになっているので、それを使ってデータベースからその物件のデータを取ってきます。今回はペット可かどうかに関する質問なので、そのカラムを見てペット可だったら「ペット相談の物件でございます。」、何も入ってなければ「ペットに関して確認いたします。」という文を返します。
まとめ
まだまだ課題は沢山あります。例えば、そのメッセージだけでは種類を判断するのに情報不足な場合が多々あります。その前の会話の流れをインプットとして使えれば良いのですが、上手いやり方がまだ見つかっていません。何か良い方法を知ってる方は是非教えて下さい!またイタンジではクレイジーなエンジニアを募集していますので、是非オフィスに遊びにいらして下さい!







