 DEEPFAKE.XYZ
DEEPFAKE.XYZ 
この記事では2020年2月にリリースされた、DeepFaceLabの最新版、DeepFaceLab 2.0を使ったDeepfake動画の作り方を解説していきます。
DeepFaceLab1.0と2.0の違い
DeepFaceLab 2.0は、以前のバージョンのDeepFaceLab 1.0よりも、より高速かつ高品質に処理できるようなりました。学習モードが「SAEHD」と「Quick96」の2種類のみになり、オプションの項目が増え、 機能も増えましたが基本的な使用方法は、DeepFaceLab1.0と変わりません。
ただし、両バージョンに互換性がありませんから、DeepFaceLab 1.0で作ったモデルを、DeepFaceLab 2.0で使用することはできません。
また、DeepFaceLab 2.0からは、NVIDIAのビデオカード(GPU)しかサポートされません。AMDのビデオカードをお使いの方はDeepFaceLab 1.0をお使いください。
DeepFaceLab 2.0を使うのに必要なモノ
前述したように、DeepFaceLab 2.0からはNVIDIAのビデオカード(GTX 10シリーズ、GTX 16シリーズ、RTXシリーズ)しかサポートされません。
そのなかでも、基本的にはVRAMが6GB以上のものをおすすめします。VRAMが6GB未満だと、処理能力不足です。
後で詳しく述べますが、ローエンドモデル用(VRAM 4GB以上推奨)の学習モード「Quick96」もありますが、解像度が低いため、基本的には最低でもVRAMは6GB以上必要と考えてください。
DeepFaceLab 2.0のダウンロード
DeepFaceLab 2.0は下記のGoogleドライブ、もしくはGithubからダウンロードできます。
「DeepFaceLab_NVIDIA_build_02_28_2020.exe」というような名前のファイルをダウンロードしてください、buildの後はリリースされた日付になります。
DeepFaceLabのbuildは、バグの修正や機能の追加などで、こまめにアップデートされます。ただし、必ずしも最新のbuildを使うことが良いとも限りませんので、ご注意ください。
今回の例では「DeepFaceLab_NVIDIA_build_02_28_2020.exe」を使用しています。
ダウンロードしたファイルの解凍
ダウンロードしたらファイルを解凍します、解凍場所はデスクトップでもCドライブ直下でも、どこでも構いません。
解凍場所を指定し、「Extract」をクリックする。
解凍が終わるのを待ちます、1分程度で終わります。
解凍されたフォルダ名は「DeepFaceLab_NVIDIA」となっています。これは自由に変更したりしても問題ありません。

解凍したフォルダを開いてみましょう。
DeepFaceLab 1.0のときと同様、バッチファイルがたくさん入っています。
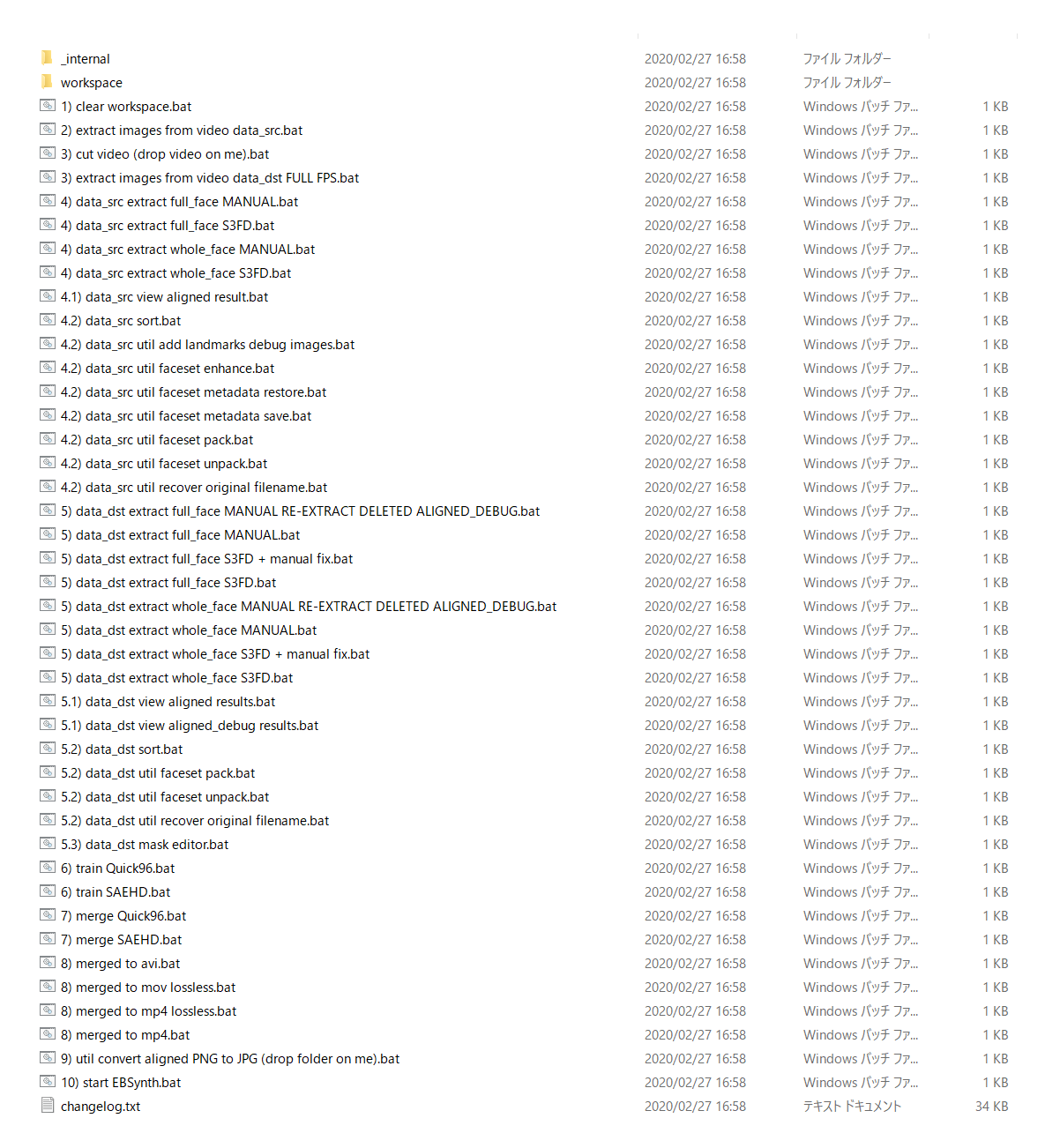
DeepFaceLabはインストールして使うソフトウェアのようなものではなく、必要なバッチファイルを順に実行するようにして使用します。一見「ややこしそう」ですが、素材を準備して、手順通りに必要なバッチファイル実行していくだけですから簡単です。
動画制作の手順
動画制作の手順は下記の通りです。基本的にDeepFaceLab 1.0と同じ流れで処理していきます。
1.素材を準備する
素材となる動画を準備します。素材は何でも構いませんが、まずは1~3分程度の短いもので試してみるのが良いかと思います。動画が長くなればなるほど、すべての処理で時間がかかります。
素材は顔を移植する側とされる側の2種類が必要です。
data_src – 「別の人物の体に移植する顔となる素材」
data_dst – 「別の人物の顔を移植される素材」
例えば「ニコラス・ケイジの顔を、ドナルド・トランプに移植する」場合は、ニコラス・ケイジの動画がdata_src、ドナルド・トランプの動画がdata_dstとなります。
用意した素材は、それぞれ上記の例のようにdata_srcとdata_dstに名前を変更し、workspaceフォルダに入れておきます。
最初からサンプルの動画が入ってますので、サンプルは消しましょう。
素材動画の注意点
使用する素材にはいくつか注意が必要です。場合によっては事前に動画編集ソフトで、編集する必要があります。
・動画に複数の人物の顔が映っていないこと
この後の工程で人物の顔部分のみを画像で書き出しますが、動画内のすべての顔と認識されるものが書き出されますので、動画には一人の人物の顔しか映らないようにしましょう。(複数人の顔が映る場合は、不要な人物の顔部分を塗りつぶす等の処理が必要です)
・人物の顔が十分なサイズで写っていること
素材となる動画(特にdata_src)は人物の顔がある程度の大きく映っている必要があります。具体的には顔部分の画像の書き出しは256×256ピクセルもしくは512×512ピクセルの正方形なので、動画上の人物の顔のサイズがこの程度のサイズで写っていることが望ましいでしょう。
2.素材動画を全フレーム画像で書き出し
2) extract images from video data_src.bat を実行して、data_srcの動画を画像で書き出します。data_srcは顔を移植する側、つまり画像は学習にしか使用しないないので、必ずしも全フレーム書き出す必要はありません。
FPS選択時に何も打たずにEnterを押すと全フレームが書き出されます。フレームレートを指定する場合は数値を入力します。
素材が短い場合は全フレーム書き出したほうが良いでしょう。
書き出す画像形式は、劣化のないpngをおすすめします。
- [0] Enter FPS ( ?:help ) :何も打たずEnterで全フレーム書き出し
- 0
- [png] Output image format ( png/jpg ?:help ) :何も打たずEnter
- png
3) extract images from video data_dst FULL FPS.bat を実行して、data_dstの動画を全フレーム画像で書き出します。こちらは顔を移植される側なので、最後に顔を移植して動画にする際に全フレーム必要になるので、自動的に全フレーム書き出しとなります。
こちらも劣化のないpng形式で書き出すことをおすすめします。
- [png] Output image format ( png/jpg ?:help ) :何も打たずEnter
- png
書き出された画像はそれぞれ「workspace」フォルダ内のフォルダ「data_src」「data_dst」に保存されます。
3.顔部分のみを抽出
前の工程で書き出した画像から、さらに顔部分のみを抽出し画像で書き出します。
「4) data_src extract full_face S3FD.bat」を実行しdata_srcの画像から顔部分のみを抽出します。
「5) data_dst extract full_face S3FD.bat」を実行しdata_dstの画像から顔部分のみを抽出します。
書き出された画像は、それぞれ「data_src」「data_dst」のフォルダ内の「aligned」というフォルダに書き出されます。
NVIDIAドライバダウンロード https://www.nvidia.co.jp/Download/index.aspx
4.誤検出された画像を削除
前工程での顔部分のみの抽出ですが、完ぺきではないので、何かしらの誤検出があります。これらが学習時に入っていると悪影響を及ぼすので、削除する必要があります。よくあるのは「耳」や「グーにした状態の手」、「家具の模様」など思わぬものが顔として認識されています。
誤検出した画像を膨大な画像の中から目視で探し出すのはとても苦労します。そこで誤検出した画像を発見しやすいように、「4.2) data_src sort.bat」を使って並べ替えてから、目視で削除していきます。
「4.2) data_src sort.bat」を実行すると、どのように並べ替えるかを選択できます。おすすめは[3] histogram similarityです。ヒストグラムの近い画像順に並べ替えてくれるので、実行すると似ている画像が並ぶようになります。これにより誤検出した画像が発見しやすくなります。
並べ替えが終わったら、alignedフォルダを開き誤検出された画像を削除します。
- Running sort tool.
- Choose sorting method:
- [0] blur
- [1] face yaw direction
- [2] face pitch direction
- [3] histogram similarity
- [4] histogram dissimilarity
- [5] brightness
- [6] hue
- [7] amount of black pixels
- [8] original filename
- [9] one face in image
- [10] absolute pixel difference
- [11] best faces
- [3] : 3
- 3
data_dstも同様に「5.2) data_dst sort.bat」を実行し、並べ替えた後、誤検出された顔画像を削除します、
5.学習させる(train)
いよいよ学習をさせていきます。ここはDeepFaceLab 1.0から大きく変わった点のひとつです。DeepFaceLab 2.0では現在2種類の学習方法があります。どちらか一方のみを使用します。
6) train SAEHD.bat
VRAM 6GB以上のハイエンドGPU用。「build_02_23_2020」以前は最大256×256ピクセル、 「build_02_28_2020」 以降は最大512×512ピクセルの解像度で学習させることができます。フルHD(1080×1920ピクセル)やHD(1280×720ピクセル)の動画を素材に使う場合は、このモードをおすすめします。
6) train Quick96.bat
VRAM 4GB以上のローエンドGPU用。軽量版の学習モード。一応、それなりに学習させることはできますが、解像度が96×96ピクセルのため、いくら学習させても解像度不足は補うことはできません。SD画質・480p(480×720ピクセル)程度の動画であれば、このモードでも良いかもしれません。
今回は「6) train SAEHD.bat」を使用します。実行するとオプションを尋ねられるので、入力していきます。
(「6) train Quick96.bat」でも手順は同じです、オプションがほとんどないだけです。)
train時のオプション
モデル名の入力
DeepFaceLab 2.0から、学習するモデルに名前をつけることが可能になりました。これにより同じDeepFaceLabのフォルダ内に複数のモデルを作成・学習することができるようになりました。
- Running trainer.
- [new] No saved models found. Enter a name of a new model : モデル名の入力してEnter
一度、保存したモデルの学習を再開する場合も同様にモデル名をここで入力します。
GPUの選択
使用するGPUを選択します。
- Choose one or several GPU idxs (separated by comma).
- [CPU] : CPU
- [0] : GeForce GTX 1080 Ti
- [0] Which GPU indexes to choose? : 0
- 0
Write preview history ( y/n ?:help ) :
「y」にすると、10回の反復(学習)おきにプレビュー画面を保存してくれます。保存場所は「workspace > model > [モデル名]_SAEHD_history」です。
基本的には不要なので「n」にします。
[0] Target iteration :
何回まで反復(学習)するかを入力できます。基本的に無制限に学習させるので「0」(無効)にします。手動で学習を終了させるまで、無制限に学習を続けます。
Flip faces randomly ( y/n ?:help ) :
「y」(有効)にすると、元の画像に加えて、左右反転させて学習させることができます。
例えばdata_dstに、右を向いているシーンがあったとします。しかし、data_srcには右を向いているシーンがない、もしくは少ない場合に、左を向いている画像を左右反転させることによって、これを補って学習することができます。
ただし、ランダムで左右反転し学習させるため、顔のほくろやキズなども顔の両側に表れることになります。また、人の顔は必ずしもピッタリ左右対称という訳ではないため、data_srcに顔が似ない可能性もあります。
必要に応じて選択してください。デフォルトは「n」(無効)です。
[8] Batch_size ( ?:help ) :
バッチサイズを指定します。バッチサイズがある程度大きいと学習の進度が早くなります(LOSS値が早く低下し、ブレも少なくなる)。ただし、バッチサイズが大きいほどVRAMの容量を圧迫するため、バッチサイズが大き過ぎるとエラーでtrain(学習)が始まらないこともあります。
バッチサイズは学習時の解像度や他の設定との兼ね合いもあるので、参考例を後で示します。
[128] Resolution ( 64-512 ?:help ) :
学習時の解像度を指定できます。解像度が高ければ高いほど、ボヤけの少ない、より高精細なモデルをつくることができます。しかし、これもバッチサイズと同様に大きければ大きいほどVRAMを圧迫するため、大きいとエラーでtrain(学習)が始まらないこともあります。
[f]Face type ( h/mf/f/wf ?:help ) :
学習するモードを選べます。
- FULL FACE (f):顔全体を学習
- HALF FACE (h):口から眉の間(顔の中心部分)のみを学習
- MID HALF FACE (mf) :HALF FACEよりも30%大きい範囲を学習
- WHOLE FACE (wf):FULL FACEよりもさらに広い範囲(頭や顔の形)まで学習
通常はFULL FACE (f)を使用すると良いと思います。
HALF FACE、MID FACEは、同じ解像度でもFULL FACEに比べ顔の中心部分を高い解像度で学習させることができる利点もあります。

AE architecture ( dfhd/liaehd/df/liae ?:help ) :
学習アーキテクチャを選択します。DeepFaceLab 2.0には、DFとLIAEの2種類のアーキテクチャがあります。また、それぞれにおいてパフォーマンスを犠牲にし品質を優先するHDバージョンがあります。
DF
このモードでは、顔の変形は行わないモードです。顔が正面に向いているシーンが多いものに最適なモードです。data_srcに再現するすべての角度の画像が必要なため、横顔などが多いシーンには不向きです。
LIAE
このモードでは、顔の変形を行います。正面の顔はDFに比べ再現性が劣りますが、横顔はLIAEのほうがはるかに上手く処理することができます。

次にオートエンコーダー、エンコーダー、デコーダー、デコーダーマスクの設定ですが、特にデフォルト値から変更する必要もないので、何も打たずにEnterでスキップし、デフォルト値を使用します。開発者も「安定した動作が必要な場合は、デフォルトのままにしてください」としています。
- [256] AutoEncoder dimensions ( 32-1024 ?:help ) :何も打たずにEnter
- 256
- [64] Encoder dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 64
- [64] Decoder dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 64
- [22] Decoder mask dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 22
[n] Learn mask ( y/n ?:help ) :
「y」(有効)にすると、顔の形状の学習を行って、merge(顔を合成する工程)で使用できるマスク(Learn mask)を生成することができます。通常はdata_dstのフレームから顔画像を書き出す工程で生成されるマスク(dst mask)を、mergeで使用しています。dst maskよりもLearn maskのほうが優れていますが、この機能を有効にするとVRAMに大きな負荷がかかる(1回あたりの反復(学習)に時間がかかる)ため、使うとしても学習中のどこかで5000~6000回程度の間だけ有効にすることをオススメします。顔の学習の品質には影響しません。
この機能は何度でも有効・無効にすることができます。
通常は「n」(無効)で良いと思います。dst maskに万が一不満があれば、Leran maskを使ってみると良いかもしれません。
[n] Eyes priority ( y/n ?:help ) :
Deepfakeで合成した顔では、目やその周辺の描写が上手く行かないケースがよくあります。「y」(有効)にすると、これらが改善されます。ただし、目線の方向を正しい方向することを保証する機能ではありません。デフォルトでは「n」(無効)ですが、私自身は「y」(有効)にしています。
[y] Place models and optimizer on GPU ( y/n ?:help ) :
「y」(有効)にすると、GPUのVRAMにほぼすべてのデータを置くため、1回の反復(学習)にかかる時間が大幅に短縮し、train(学習)の速度が速くなります。ただし、バッチサイズが小さくなります。(DeepFaceLab 1.0でも同じ方式)
「n」(無効)にすると、データをメインメモリ(システムRAM)に置くため、VRAMへの負荷が減り、わずかに高いバッチサイズでtrainを実行できたり、より高い解像度(Resolution)でtrainを実行できる可能性があります。ただし1回あたりの反復(学習)にかかる時間が大幅に増大し、train(学習)の速度が遅くなります。
VRAMが6GBで、システムRAMが16GBや32GBある場合(VRAMは少ないけど、システムRAMはたくさんあるよ という場合 )には、「n」(無効)にして、時間を犠牲にし、品質を優先するというのもひとつの方法でしょう。
とはいえ、VRAMにデータを置いて学習しても、数万~20万回と反復(学習)させるには、とてつもない時間がかかりますから、基本的には「y」(有効)にしましょう。デフォルトでも「y」(有効)です。
[n] Use learning rate dropout ( y/n ?:help ) :
この機能は使用するとしても、トレーニングの最終段階(数十万回学習が終わってから)のみで「y」(有効)にしてください。また、「random warp of samples」や「flip faces randomly」の機能と同時に有効にしないでください。モデルがかなりよく学習されてから、「random warp of samples」「flip faces randomly」の機能を無効にした上で、この機能を有効にしてください。モデルがよりシャープになります。モデルが十分に訓練されていない状態で有効にすると、悪影響を及ぼします。
必ずしも使用する必要のある機能ではありません。
デフォルトでは「n」(無効)です。
[y] Enable random warp of samples ( y/n ?:help ) :
モデルを一般化し、基本的な形状、顔の特徴、構造を適切に学習するために使用します。初期段階はこの機能は有効にして学習を行い、学習が進んでいる間は有効にしておきましょう。学習が停滞してきたら(LOSS値が減少しなくなってきたら)、この機能を無効にし学習させることで、顔のより詳細な部分を学習させることができます。ここまで学習させるには数十万回の反復(学習)が必要です。
デフォルトでは「y」(有効)です。
[0.0] GAN power ( 0.0 .. 10.0 ?:help ) :
こちらの機能も十分に訓練がされてから「 random warp of samples 」を無効にした上で、「y」(有効)にするオプションです。より詳細(シャープ)な顔を生成することができます。ただし、data_srcのデータセット(顔画像)の品質に大きく依存するため、必ずしも良い結果が得られるとは限りません。良い結果が得られるかどうかを試すために、低い値から始めることをオススメします。また、この機能を有効にする前にモデルのバックアップを取るようにしましょう。
デフォルトでは「0」(無効)です。




[0.0] Face style power ( 0.0..100.0 ?:help ) :
[0.0] Background style power ( 0.0..100.0 ?:help ) :
学習済みの顔に、data_dstの画像の顔・背景部分のスタイルを適応することで、merge(顔を合成する工程)での、合成の品質・外観が良くなります。しかし、値が大きいと学習したにもかかわらずdata_dstの顔になってしまいます。最大でも10.0を指定し、トレーニング中に1.0から0.1まで下げていくことをオススメします。

要は設定が強いほど、合成した顔がdata_dstの顔っぽくなります。data_dstの目や唇・肌の色や化粧などを引き継ぎたい場合には、有効な機能だと思います。
ただし、この機能はパフォーマンスに大きな影響を与えるため、バッチサイズを小さくするか、「Place models and optimizer on GPU」を無効にする必要があります。また、1回の反復(学習)にかかる時間も増大するため、学習の速度も低下します。
デフォルトでは「n」(無効)です。
Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :
data_srcの肌の色を、data_dstの肌の色に合わせるための機能です。いくつか種類がありますが、「rct」もしくは「lct」がオススメです。

[n] Enable gradient clipping ( y/n ?:help ) :
DeepFaceLab 2.0の様々な機能を使用することで発生する可能性のある、モデルの崩壊・破損を防ぐための機能です。パフォーマンスへの影響は小さいため、デフォルト値は「n」(無効)ですが、常に「y」(有効)にすることをオススメします。
[n] Enable pretraining mode ( y/n ?:help ) :
ここでは詳しく説明しませんが、トレーニング済みのをモデルを入手し、これを使用する場合に使う機能です。
基本的には「n」(無効)にしておいてください。
これでtrainのオプションの設定は完了です。素材となる画像の読み込みが始まり、無事にtrain(学習)が開始されると、プレビューウィンドウが立ち上がってきます。
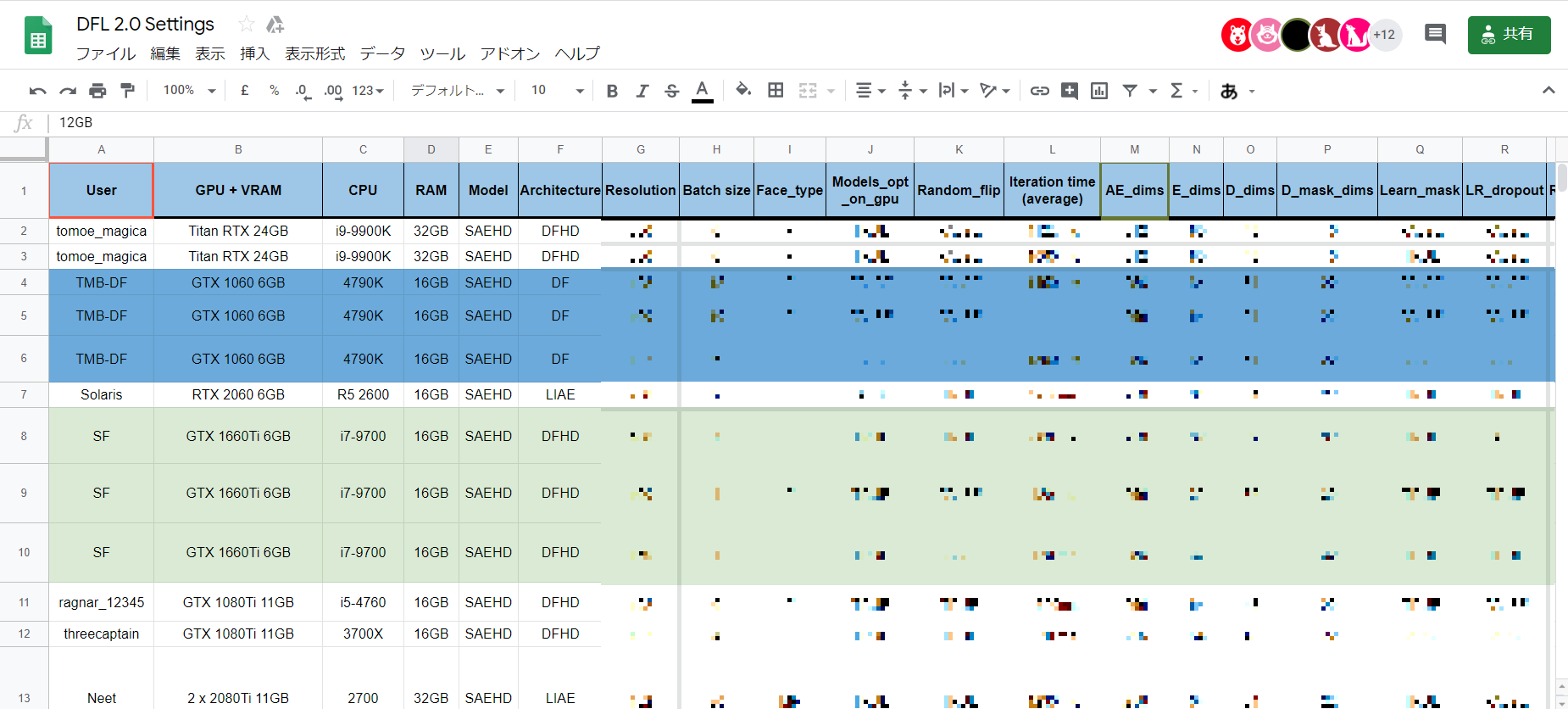
エラーでtrainがはじまらない場合は設定(バッチサイズ・解像度・アーキテクチャー)を見直しましょう。必ず動くという保証はできませんが、設定値の参考例を以下に示します。
| GPU (VRAM容量) | アーキテクチャ | 解像度(Resolution) | バッチサイズ |
| GTX 1650 (4G) | DF | 128 | 6 |
| GTX 1660Ti (6GB) | DFHD | 160 | 7 |
| RTX 2060 (6GB) | DF | 128 | 14 |
| RTX 2060 (6GB) | DFHD | 128 | 8 |
| RTX 2060 S (8GB) | DFHD | 160 | 9 |
| RTX 2070 S (8GB) | DFHD | 128 | 8 |
| GTX 1080Ti (11GB) | DFHD | 192 | 6 |
| Titan RTX (24GB) | DFHD | 256 | 8 |
ちなみにmrdeepfakes.comという海外のフォーラムに、「この設定なら動いたぞ」というのをユーザーが記入しているスプレッドシートへのリンクがあります。
https://mrdeepfakes.com/forums/thread-guide-deepfacelab-2-0-explained-and-tutorials-recommended
ただし、ログインしないとリンクの表示は許されないようなので、ご覧になりたい方は、各自登録して閲覧してみてください。登録しても特にスパムメール等が送られてきたりはしません。
train時のウィンドウの見方
DeepFaceLab 1.0の使い方の記事を書いたときに、質問が多かったtrain時のウィンドウの見方について説明します。trainがはじまると、もともと開かれていた黒いコマンドラインウィンドウに加えて、視覚的に学習状況を把握できるプレビューウィンドウが立ち上がってきます。
コマンドラインウィンドウ
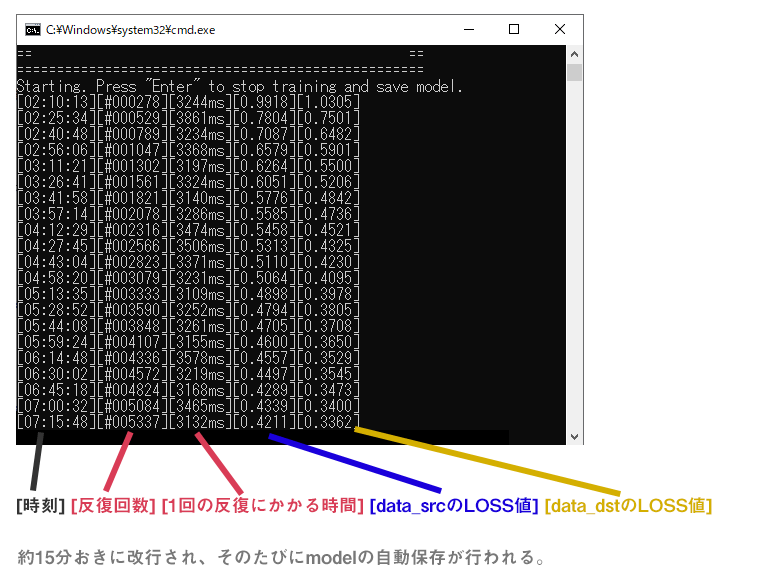
コマンドラインウィンドウには上記の情報が表示されます。
- 反復回数 - 学習回数です。これが5万回ほどいくと、それなりにdata_srcの顔っぽくなってきます。どこが完成というのはありませんが、少なくとも20万回程度は反復させたほうが良いでしょう。(5、6万回に達したところで一旦、動画にしてみるというのも、もちろんOKです。)
- 1回の反復にかかる時間 - そのままですが、これは結構重要です。これで学習の速度が分かります。例えば1回の反復に3000ms(3秒)かかっていたとします。この場合、24時間で28,800回 反復させることができます。これが1000ms(1秒)なら、86,400回 反復させることができます。たかが、2秒の違いですが、何万、何十万回と長時間学習させるため大きな差が出てきます。ですから、反復回数はできるだけ短くしたい訳です。
- LOSS値 - LOSS値は簡単に言うと、この数値が学習の進行度合いを表しています。少なくなればなるほど、学習が進んでいるということになります。時間経過と共にLOSS値が徐々に少なくなっていくのが望ましい(正常)です。LOSS値が安定しない(上昇、低下を繰り返す)場合等は、データセットや学習方法を見直す必要があります。最終段階まで行くと、LOSS値が安定し低下しなくなります。ここまで行けば完成と言って良いでしょう。
プレビューウィンドウ

基本的には画像の通りです。Iterはコマンドラインウィンドウにも表示されている反復回数。青と黄のグラフは、LOSS値をグラフ化したもの。下の画像部分は現在のmodelデータを反映したプレビュー。pキーで更新できます。
モデルデータの保存と学習の再開
このウィンドウを選択した状態でEnterを押すとモデルを保存し、train(学習)を終了します。再開する場合は、再度バッチファイルを実行し、モデル名を入力します。再開時にGPU選択から2秒以内にEnterキーを押すと、設定可能なオプションを再設定することができます。何も押さなければ、前回の設定のままtrain(学習)を再開します。
6.顔を移植した画像を書き出し(merge)
学習したモデルを使って、data_dstの動画の画像に、顔を合成していきます。
trainを終了してから、「7) merge SAEHD.bat」を実行します。
mergeのオプション
[y] Use interactive merger? ( y/n ) :
対話型のコンバーターを使用するか、しないかです。今回は通常のコンバーターを使用するので「n」(通常のコンバーターを使用)にします。
[new] No saved models found. Enter a name of a new model :
どのモデルを使ってmergeするかを、入力します。
[0] Which GPU indexes to choose? :
使用するGPUを選択します。
Choose mode:
(0) original
(1) overlay
(2) hist-match
(3) seamless
(4) seamless-hist-match
(5) raw-rgb
どのモードで合成を行うか選択します。オススメは「(1)overlay」です。
Choose mask mode:
(1) learned
(2) dst
(3) FAN-prd
(4) FAN-dst
(5) FAN-prdFAN-dst (6) learnedFAN-prd*FAN-dst
どのマスクを使って合成するか、選択します。通常はdst maskを使用するので「(2)dst」を選択します。
train時にLearn maskのオプションを有効にしており、合成にLearn maskを使用したい場合は「(1) learned」を選択します。
[0] Choose erode mask modifier ( -400..400 ) :
マスクの範囲の大きさを調整できます。基本的に元のままの「0」で良いでしょう。
[0] Choose blur mask modifier ( 0..400 ) :
合成部分の輪郭のぼかしを調整します。デフォルトでは「0」になっていますが、100程度ぼかしをかけたほうが自然に仕上がります。ここは仕上がりを確認しつつ調整してください。
[0] Choose motion blur power ( 0..100 ) :
動体ブレの度合いを調整します。ただし、data_dstの顔画像が同一人物で連続になっている必要があります。例え同じ人物しか映っていなくても、顔画像の画像のファイルの中に 「090890_1.jpg」のような「 _1 」付いている画像が1枚でもできてしまっていると、この機能は使用できません。(同一の人物と認識されていないため)
基本的には「0」(無効)で良いです。
[0] Choose output face scale modifier ( -50..50 ) :
合成する顔の大きさを調整できます。基本は「0」で良いでしょう。

Color transfer to predicted face ( rct/lct/mkl/mkl-m/idt/idt-m/sot-m/mix-m ) :
data_dstとの肌の色を合わせるための機能です。train時と同様「rct」か「lct」がおすすめです。
Choose sharpen mode:
(0) None
(1) box
(2) gaussian
ボックスまたはガウス法のシャープをかけることができます。基本的に「(0)None」で問題ありませんが、必要に応じて使用してください。
[0] Choose super resolution power ( 0..100 ?:help ) :
歯、目などの領域にさらに定義を追加し、学習した顔の詳細/テクスチャを強化できます。通常「0」(無効)で問題ありませんが、必要に応じて適応してください。
[0] Choose image degrade by denoise power ( 0..500 ) :
元のフレーム (data_dst) の外観にノイズ除去をかけることができます。基本的には「0」(無効)で良いですが、data_dstにノイズが多い場合などはこの機能を使用してみてください。
[0] Choose image degrade by bicubic rescale power ( 0..100 ) :
元のフレーム(data_dst)の外観をバイキュービック法を用いてぼかすことができます。例えばdata_dstの画像が高解像過ぎて、合成した顔と違和感がある場合に、顔以外の全体をぼかすことによってこれを軽減できます。通常は「0」(無効)で良いですが、必要に応じて使用してください。
[0] Degrade color power of final image ( 0..100 ) :
通常は「n」(無効)で良いです。数値を上げるほど色の濃淡が弱くなり、ビンテージっぽくなります。色が鮮やかになる訳ではありません。

オプションを選択し終えると、顔を合成したフレームが「workspace > data_dst > merged」に書き出されます。
バッチを途中で中止する場合は「Ctrl + C」で、バッチを中止できます。
7.書き出した画像を動画にする
あとはこれまでの工程で書き出した画像をつなげて動画にするだけです。
8) merged to mp4.bat を実行します。オプションはEnterでスキップして構いません。
動画は「workspace」フォルダ内にresult.mp4という名前で出力されます。
さいごに
これで一通りDeepFaceLab 2.0 を使って動画を制作することができると思います。私もこの手の専門家ではないので、前回の記事と同様に。、うまくいかないところや、間違っているところがありましたら、指摘していただけると幸いです。
今回も質問・コメントなどもありましたら、お気軽にどうぞ。私の答えられる範囲で回答させていただきます。
Twitterのアカウントも作りましたので、そちらで質問していただいても構いません。


ご丁寧な解説ありがとうございます。
ソフトの使い方についてではないのですが、合成される側の動画(data_dst .mp4 )に複数人の顔が表示されている場合は、どうすればよいでしょうか?
以前にもコメントいただいていたようで、ご返信できず申し訳ないです。
一度、試したことがあるのですがdata_dstに、人物A、人物Bのふたりの人物が映っていたとします。
「5) data_dst extract full_face S3FD.bat」を実行すると、当然 両方の人物の顔画像が切り出されます。
次に、「4.2) data_src sort.bat」を実行し[3] histogram similarityで並べ替えます。
ここで誤検出した画像に加えて、人物Bの顔画像も一緒にすべて削除していきます。
これでtrainさせると、data_srcの人物とdata_dstの人物Aで学習させることができます。
このモデルを使って、merge(顔画像を合成)すると、どういう仕組みなのか上手く人物Aのみに顔画像が合成されます。
顔画像はすべて、data_dstどのコマのどこから切り出したものなのか記録していて、data_dst > aligned 内で削除されたところについては、
mergeしないように処理しているんだと思います。
ご丁寧な説明ありがとうございました。非常によくわかりました。
DFL 2.0のデフォルト値
res 128
ae_dims 256
e_dims 64
d_dims 48(dfhd以外は64)
res(解像度)を変えなければとりあえずは特に変更しなくていいです
公式ガイドでは
解像度を上げた場合は
全体をバランス良く上げるようにと書かれています
基本はoverlay rctですが
srcの顔色がバラバラの場合、overlay rctで肌色が合わない場合があります
overlay rctで肌色が合わない場合は、overlay idt-mで肌色が合う場合も多いです
それでも合わない場合は、seamless idt-mで肌色が合う場合も多いです
rctで合わない場合のみidt-m。overlayで合わない場合のみseamless
seamlessだとsrcとdstの相性の影響が出やすいです
似るペアもありますが、overlayほど似ないペアもあります
丁寧な解説ありがとうございます!なんとか、自分の満足行くクオリティにしあげられました!1つ作って思ったのですが、モデルの使い回しはできないんでしょうか?同じdstでsrcだけ別の動画と交換(もしくは逆)する場合、1から学習をやりなおさなければならないんでしょうか?
基本的には同じ人物同士であったとしても、別途学習させる必要があります。
すみません、おかげさまで、うまくtrainingを始めることができました!
質問なのですが、10万回ぐらい学習させた時点で
・素材に壊れた画像を発見した(「data_dst」や「data_src」から画像を削除したい)
・足りなかった素材を追加投入したい(「data_src」に画像を追加したい)
場合、こちらは途中から追加/削除できるのでしょうか?
それとも、最初からすべてやり直すしかないのでしょうか?
画像を足したり、増やしたりして学習させても動けば問題ないと思います。
ただし、data_dstについては、削除すると、削除した顔画像のコマは合成が行われません。
質問失礼します。複数の動画から素材を抽出する場合、一つ目の動画から抽出した画像をコピーしたうえで二つ目以降の動画から抽出をし、最後ににコピーしておいた画像をファイルに張り付ければよろしいのでしょうか?
「複数の動画から素材を抽出する場合」この場合の素材というはdata_srcに使用する素材という認識で良いですかね。
その場合、動画ごとに、フレーム書き出し、顔画像書き出しを行って、trainさせるときに同じ、data_src > aligned のフォルダに混ぜてしまえば問題ありません。
ただし、顔画像のファイル名が連番のままだとファイル名が被ってしまうので、混ぜる前に名前を変えておきましょう。
具体的にはWindowsなら、フォルダ内の画像を全選択し、右クリック > 名前の変更で、名前を一括で変更できます。
なお、data_src > aligned 内の顔画像は、連番でなくとも問題なくtrainできます。
質問失礼致します。
顔を書き出した後なのですが、一枚の顔画像に手なども入り込んでる場合は画像を編集して手などを消した方が良いでしょうか?
なるべく顔だけの方が良いですか?
顔画像が入っているalignedフォルダ内に誤検出された画像がある場合は、train前にその顔画像を削除しておけば、trainに影響はありません。
質問失礼いたします。
まだ2.の段階なのですがつまずいていて、素材動画をworkspaceのdata_srcとdstに入れたのですがextract images from video data_src.batをダブルクリックすると「/!¥ input_file not found.
Done.続行するには何かキーを押してください…」と出てしまい、右クリックし管理者として実行(A)を選択しデバイス変更許可を「はい」にすると「指定されたパスが見つかりません。’ ” ” ‘ は、内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません。続行するには何かキーを押してください」と出てしまいます。パソコン初心者なのでご指導お願い致します。
NitroN50-600-N78V/G66TA Corei7 8GB 256G SSD+1T HDD GeForceGTX1660Ti Windows10を使用しています
「素材動画をworkspaceのdata_srcとdstに入れたのですが」とありますが、動画の入れる場所を間違えていませんか。
素材となる動画「data_src.mp4」「data_dst.mp4」は、フォルダ「data_src」「data_dst」には入れません。
素材動画を置く場所は、フォルダ「workspace」内です。
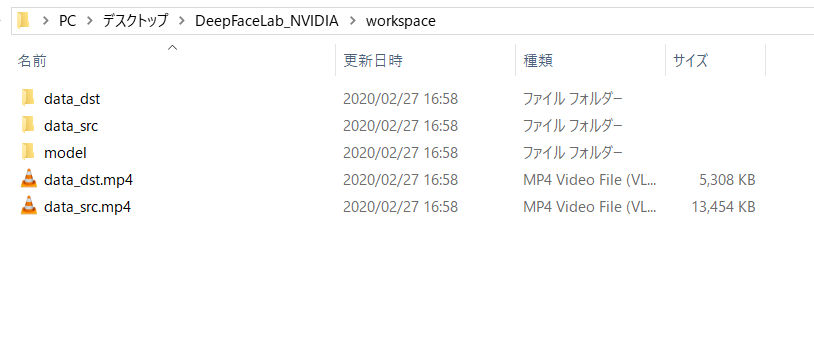
記事内にもworkspaceフォルダ内の画像を掲載していますが、正しく配置していればworkspaceフォルダ内は下記のようになります。
【workspaceフォルダ内】
 data_dst
data_dst
 data_src
data_src
 model
model
 data_dst.mp4
data_dst.mp4
 data_src.mp4
data_src.mp4