
我爬了一万篇文章,告诉你AO3是个什么网站
嗯,我回来了。不知道为什么前几天的留言,被举报了。哈哈哈哈哈哈,呼,真棒。
看了各位的留言,其实已经歪楼了。这是一篇技术贴技术贴技术贴。
- 技术贴下面,欢迎针对本章里面各类分析维度做出讨论,全部以开放的态度,接受各位的讨论和验证,我相信,更多的探讨才能更接近真相;
- 代码已经全部开放,感兴趣的朋友,请评论自取即可,技术讨论随时欢迎;
- 关于明星和饭圈的行为,不是我关注的点,不要私信我聊看法,不感兴趣,不感兴趣,不感兴趣,也不是本文的初衷;
- 说到初衷,我无非是看到了很多人将ao3的中文区美化了,但是更多人是看不清真相的跟风者,只想用数据的方式,直白的揭开这个事实而已,至于讨论发文初衷的人,这是最后一次解释;
- 最后,大德奥君说,既然被禁言了,就再多锤一下AO3吧┓( ´∀` )┏,等他忙完论文和工作,咱们周末见。
写在前面:本来这个答案,是要写在问答的答案里面的,看到很多朋友都在蹲。但是真的有点长,还是决定直接写文章吧。整个事件起因是因为全网沸沸扬扬的227事件,路人吃瓜吃了两天,然后自己冲浪了ao3网站,之后227事件对粉圈流行文化里面的这个问题下面回答了不少知友的问题,也就现在的现在情况进行了相对理智的讨论,各位感兴趣的可以去看看。
后来,在讨论的过程里面,发现很多吃瓜路人,很多拥护者,也有很多跟风发言的普通人,或者只是想来辨一辨的朋友也越来越多,其中收获了点赞,私聊,拉黑,对立,情绪宣泄等回复行为。本人原地反思,还是决定摆事实,至于这个道理你服不服还是信不信,我相信真理会越来越清晰。
以下内容,5000以上字预警,各位朋友理智分析优先。看不懂的或者存有问题的,欢迎留言参与讨论。技术层面的问题,接受私聊讨论。杠精就别来了,累死了真的,花了好几天为了弄清楚真相,真的不能接受杠精。不服忍着。
技术方面:针对AO3现有的中文文本库使用selenium进行爬取,依托检索到的中文文字,进行数据分析分类统计;
个人简述:通过边学边练数据分析,收获了不少知识和感慨,最终也希望帮助大家分析一下AO3到底是一个什么样的网站。
关于python 爬虫,数据分析的技术探讨的内容会发布在github上专门讨论,有需要的朋友私聊即可,这两天晚点时候会发布的。
那么让我们一起揭开这个网站的面纱,探讨AO3平台内容本身,以及分享本次数据统计的实际结果。
第一步,针对四种分类标签的文章数进行了数量统计
分类标签的含义如下:
- · General Audiences 大众,即所有人都可以观看
- · Teen And Up Audiences 青年及以上
- · Mature 成人
- · Explicit 露骨
- · Not Rated 未分级
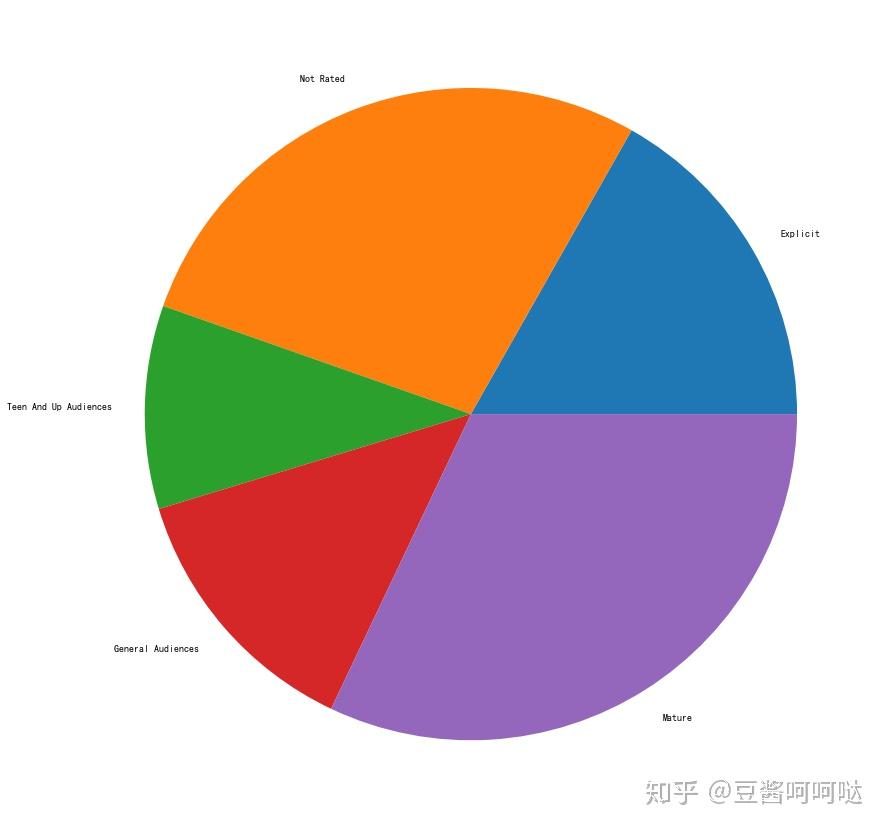
AO3总体中文文章比例:
- 大众向:2万8千篇11.5%;
- 青年及以上:2万4千篇9.8%
- 成人:8万1千篇33.2%;
- 露骨:4万8千篇19.7%;
- 未分级:6万3千篇25.8%
如下图所示,对比抽取样本的比例和总体比例,样本分布基本满足均匀分布的,符合抽样调查的合理性。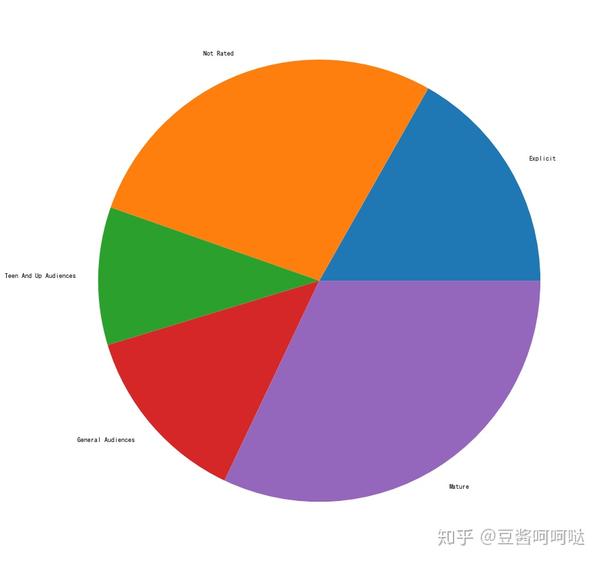
第二步,统计网站中文区,发文日期分布
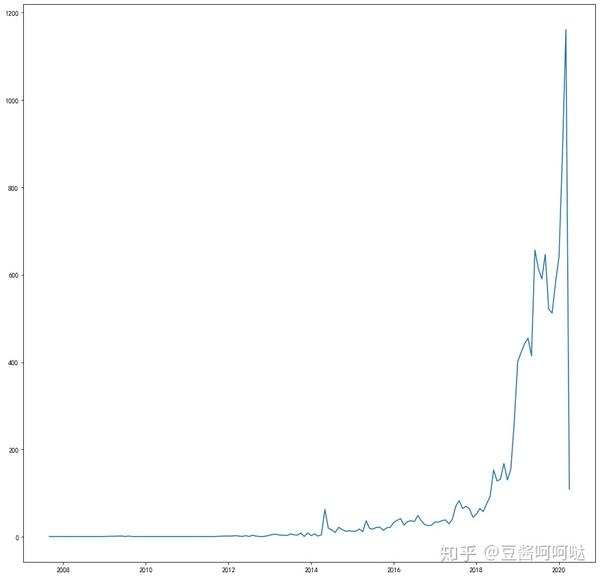
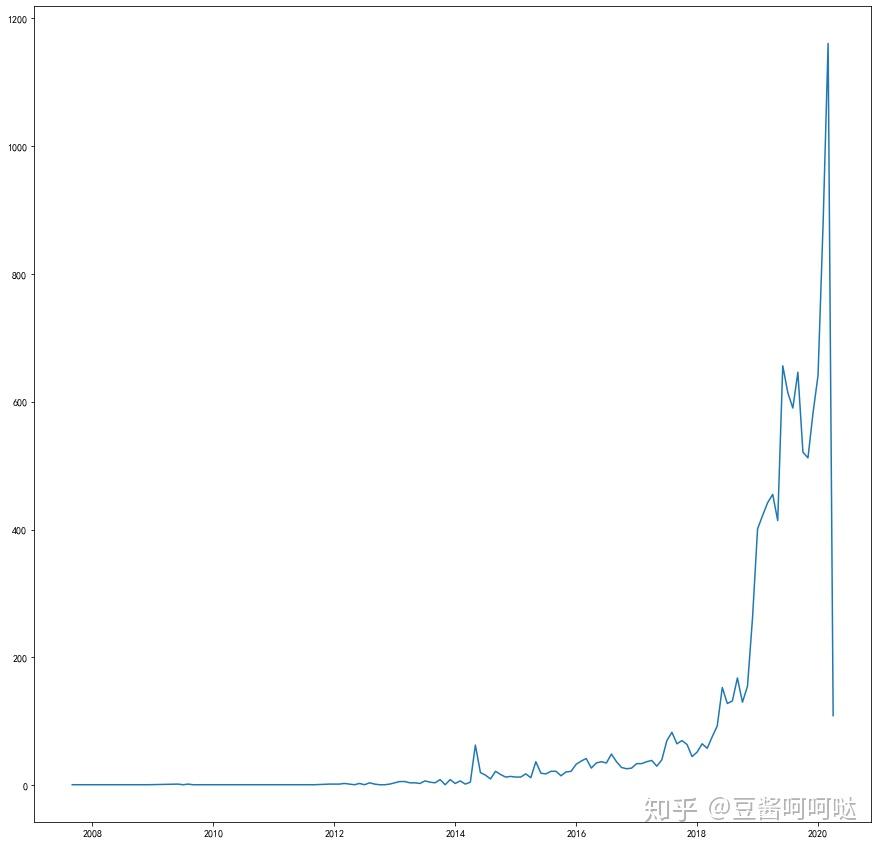
将中文文章写作时间按月统计,注意这个曲线是当月发布的数量,而不是累加值,可见平台中文文章逐年发布增长量非常可观。特别值得注意的是,2020年最后的发布数量突然在最近剧烈下降,因此是被墙对于中文区内容的文章发布数量影响还是很大的。从另一个角度去解释,2020年1月的中文文章发表数量是以往最高月份的一倍以上,这样激增的发文数量是否也是导致被针对的原因,也非常值得我们思考。
第三步,针对平台的标签分级制度的分析
AO3拥护者们和目前最核心的争论焦点是,平台所提供标签制度,因此在阅读前就可以有读者决定是否阅读。那么下一步就对各个标签下是否有敏感词进行一下统计。
首先我们定义一下敏感词,本文使用的敏感词库来自
https://github.com/chason777777/mgck(感谢作者),只使用了涉及敏感向的H类词库。
此次的提取方法是:敏感词直接进行计数,这个做起来简单方便。问题是有些正常的词连接在一起可能会被误识别(例如,左爱左的事儿,这句话本身没有问题,但是左爱是定义的敏感词,所以会计入统计)。一方面我不是NLP专家且时间有限,另一方面有些正常的词汇组合在一起也会产生奇妙的意思。这样此消彼长,加上样本量也比较大。这一点上面,欢迎各位探讨。
敏感词的计数方法是:
- 单一文章中包含相关敏感词,则计数+1;
- 同一篇文章中,一模一样的敏感词进行数量累计,即每出现一次+1;
- 基于以上计数方式,单一文章中,若包敏感词总体数量小于5个,则标记为无敏感词文章。
下图显示了无敏感文章数量与总文章数量的对比情况。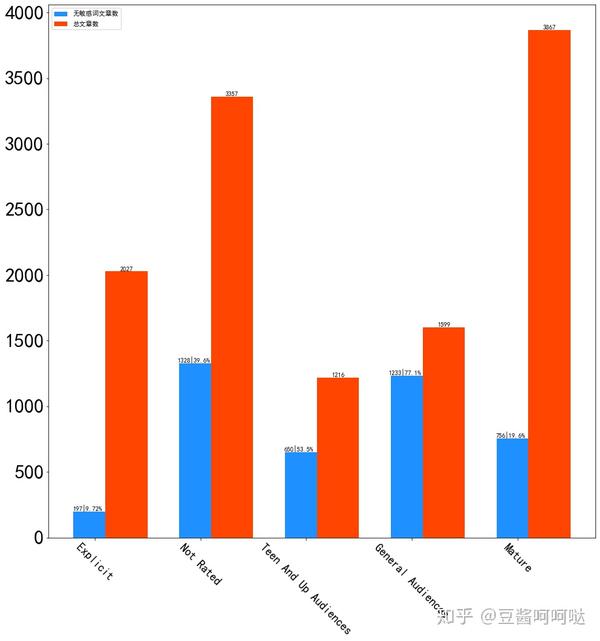
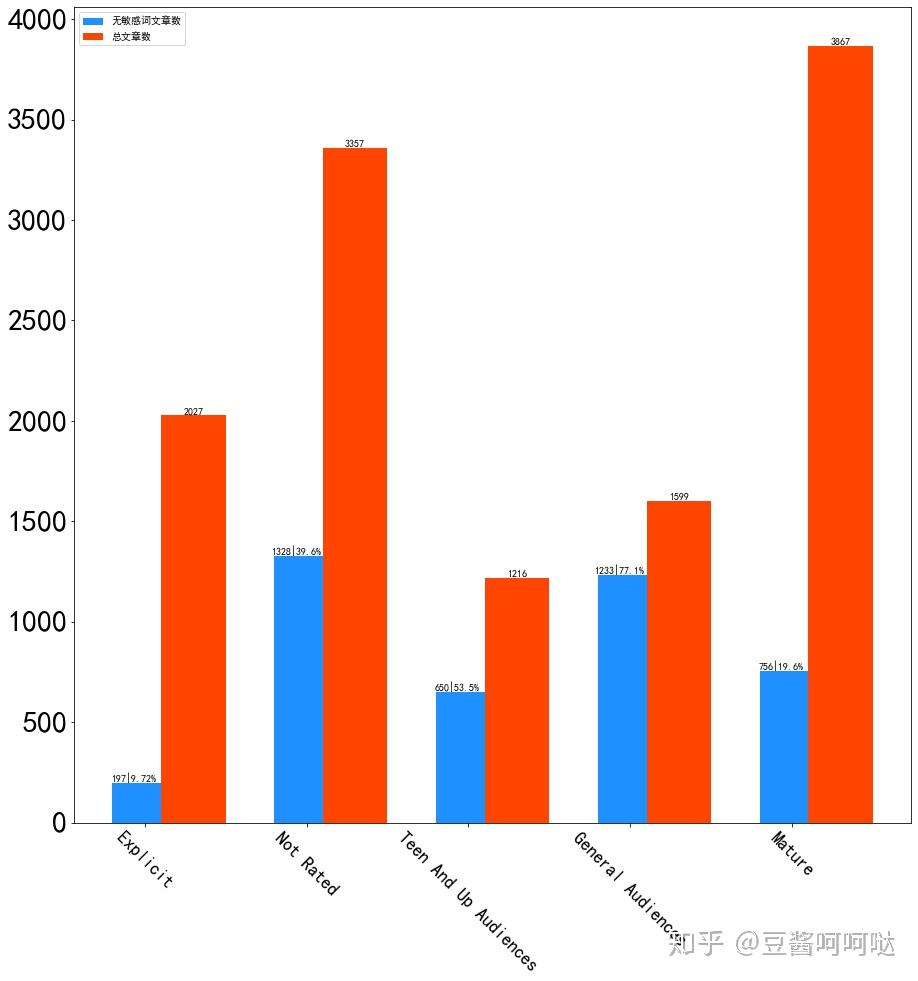
可以看到的是,不同分级标签的敏感词分布确实不同,也基本符合分级标签的含义。但是现有标签的分类及预警作用是有限的,内容并不绝对遵守规则。
接下来,将敏感词的数量与文章内总词量进行一个对比。
即对应标签下,检索文章中敏感词总数量除以该标签下文章包含总词数,计数方式同上。文章敏感词总词数占比,按标签划分统计出来,结果如下图: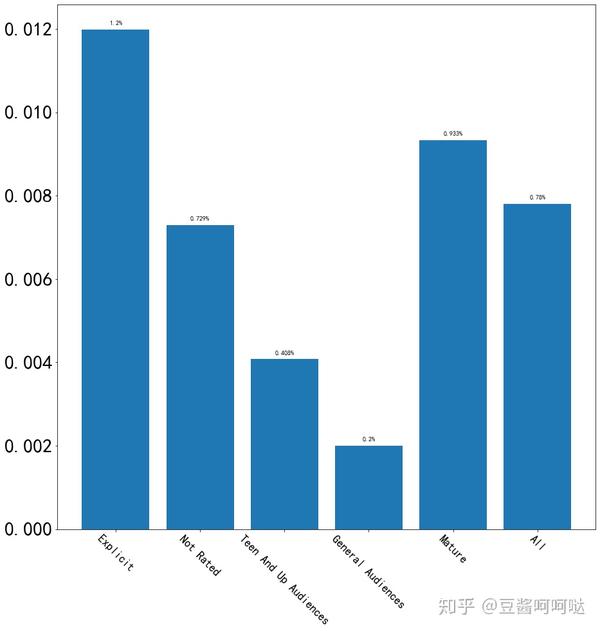
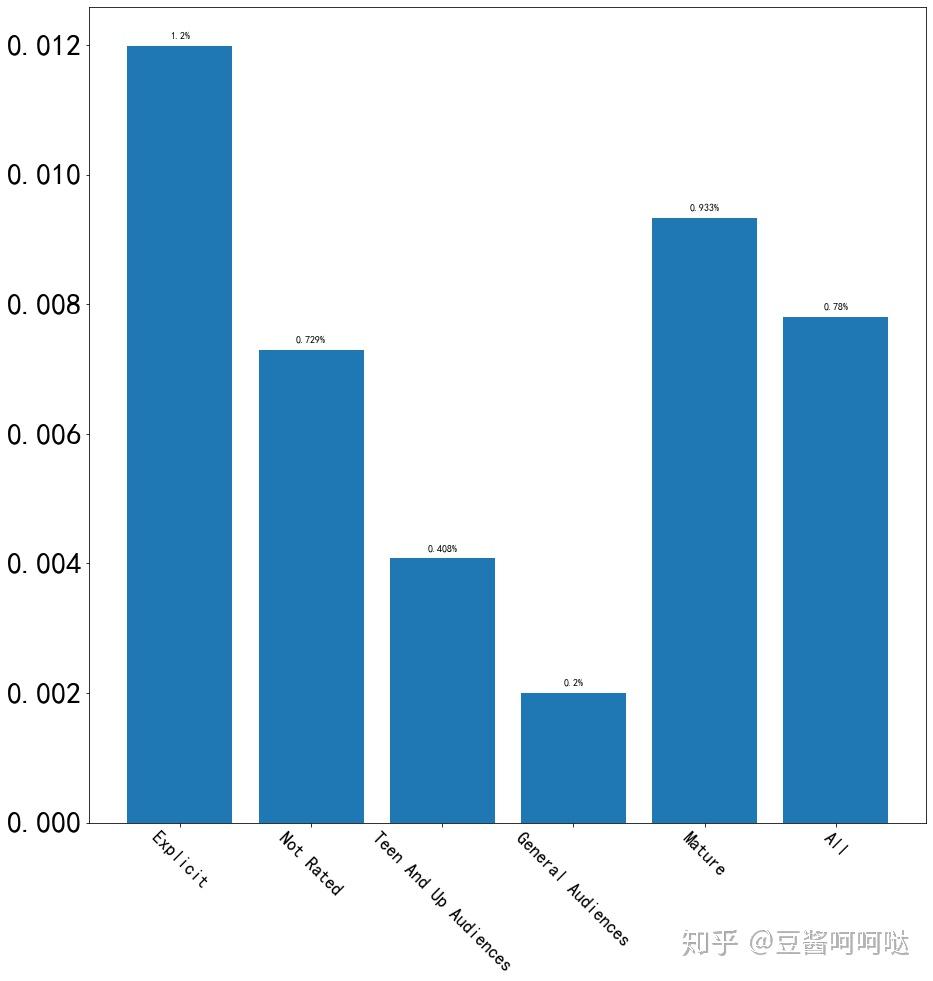
数据显示:
- General Audiences 大众:0.2%(敏感词占比所有词的0.2%)
- Teen And Up Audiences 青年及以上:0.408%
- Mature 成人:0.933%
- Explicit 露骨: 1.2%
- Not Rated 未分级:0.729%
大家可能会感觉 1% 这个比例比较小。但是我在这里分析一下 1%代表每100个词(约200字)就会出现一个敏感词,再加上围绕这些敏感词前前后后的无害词的衬托,这个比例已经非常大了。如果从NLP的方向统计应该会更恐怖,可惜这个方向我并不熟悉,正在努力补课。后期需要持续学习,不断优化分析角度。可能这样的解释,有点绕,还是上图吧。

这就是约200字,前情后续都没有,也没有到重点(可是气氛有了对吧~),但是1%意味着,在接下来的很快就会出现一个敏感词,可见1%的比例不小了。
第四步,词云分析
想了解敏感词统计是否合理还有一个简单的方法就是使用词云,也就是将高频的词展示出来。这里只做了两种词云:
- 所有词云: 对文章总体词语进行词云统计,其中部分常用词被过滤(例如:你我他如果但是因为所以……);
- 敏感词云: 对文章涉及的敏感词进行词云统计,敏感词出自上文提及敏感词库。
在生成词云的时候,我将一些人名,称呼,常用词等等词汇进行了过滤(以下称为过滤词)。经过一段时间的词云生成,当原版未和谐词云显示出来的时候,我只能说闪瞎双眼了,我真的感激郭嘉净网。在这里,为了能够展示给大家,对大部分字进行和谐了替换,如何替换的可以查看代码。
很多词只能靠大家脑补,想看原词大家可以自己去运行代码。这里强调一下,词云会揭开很多有意思的事情。

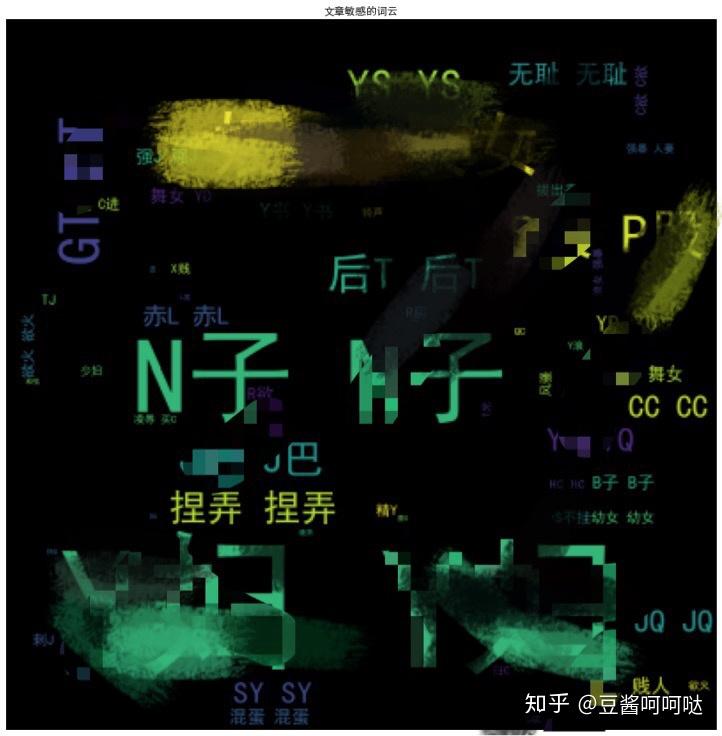
AO3词云里面敏感词都不是很和谐,这里只放出 General Audiences 大众标签下的敏感词云让大家品一下:
这是大众标签中文章出现的高频敏感词云
根据这样的展示,不难发现,这就是个H网。
第五步,各标签文章平均点击量分析
分析完平台中文文章,我们现在来看看文章平均点击情况。
数据计算方式:该标签内的单篇文章的平均点击量=标签内文章点击量加总 / 标签内文章总数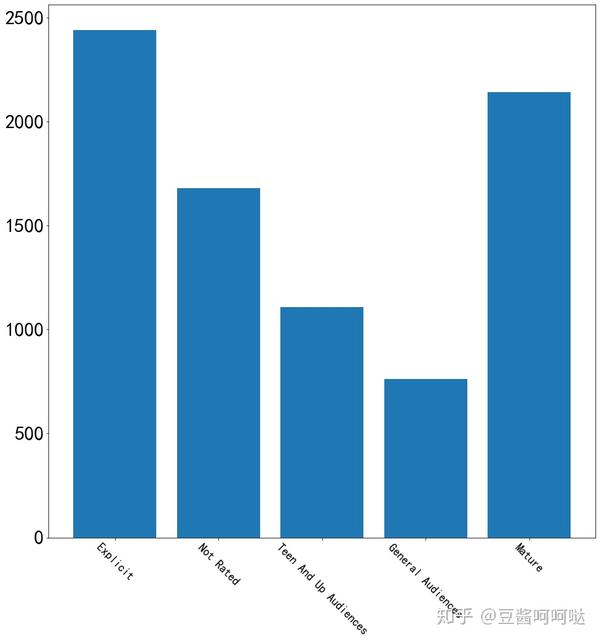
数据结论:
- 标签限制级别越高的文章(Top2: Explicit 露骨,Mature 成人),获得了普遍更高的点击率;
- “General Audiences大众” “Teen And Up Audiences 青年及以上”标签内文章点击对比约在上述Top2的一半左右;
第六步,过滤词分析
在上述第四步中,已经基本定义了过滤词的含义,即人名,称呼,常用词等等词汇。因为你我她他它、常见的语气词形容词副词、人名等。
这里我们把这些过滤掉的词拿出来分析一次,避免偏差。
由于过滤词是由程序多次运行词云分析,并从中手动挑选的高频词。即一直去除这些最高频词直到一些‘有趣’的词率先浮现。在过滤词云的过程中,词云逐步出现了一些有趣的规律。因此,对这些过滤词进行了如下分类&进一步分析:
- · 身体部位(不涉及性别)
- · 颜色
- · 动作
- · 地点
- · 方向
- · 主角
- · 人称/称呼
- · 物品
- · 其他(量词,语气词,形容词,副词等)
Ps 通过两个方法确保过滤词并不会影响本次数据分析的结论:
公开所有代码和过滤词(不包括:本次抽取的AO3的中文文库、接下来用于对比使用的其他文学作品以及敏感词库)。这样如果大家对某个词有质疑不公平可以及时指出并讨论,也可以自己运行程序修改、复验、解读;
对过滤词进行分析以及横向对比,阐述过滤词的正当性,这里时间有限,横向对比只做了一小部分,后文阐述。
这里需要注意的是计数方式的改变,即同一篇文章出现的重复过滤词只算一次,不累加计数。
这里的过滤词,如果条目太多,图表最多显示Top30.
先将没有具体指代的过滤词都贴在这里,这些词大多没有明确的意义;

下面将有有一些含义的过滤词进行了分类并做成了统计图表:
6.1 身部位过滤词分析
平台文章喜欢描写的一般身体部位Top30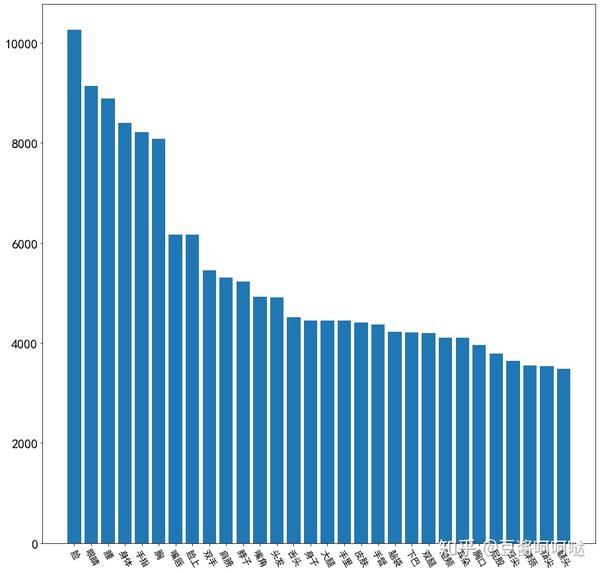
6.2颜色描述类过滤词分析
内容中出现频率最高的颜色分别:白色,黑色,红色(包含白、黑、红)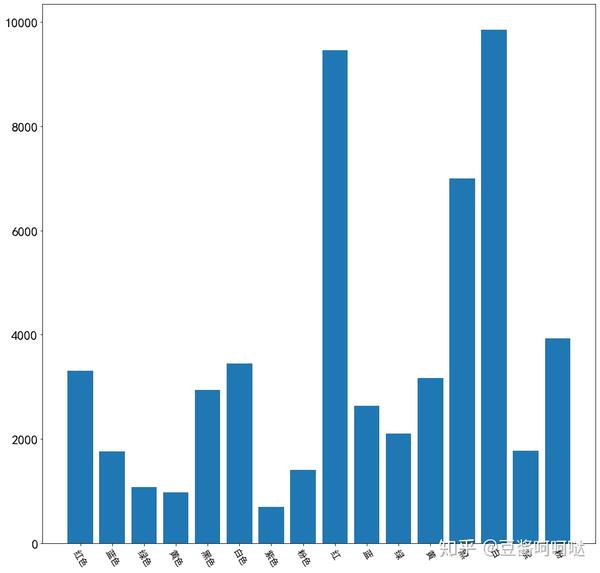
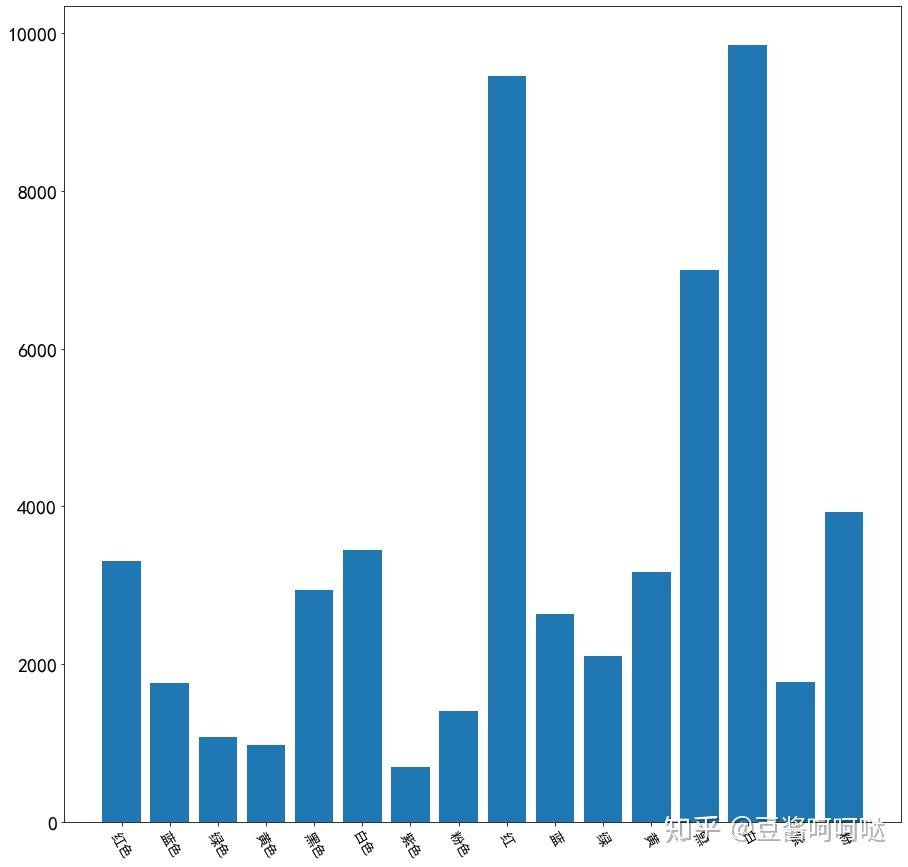
6.3动作描述类过滤词分析
动作描述类过滤词Top10:看着,想要,动作,轻轻,抬起,心里,眼神,听到,微微,表情。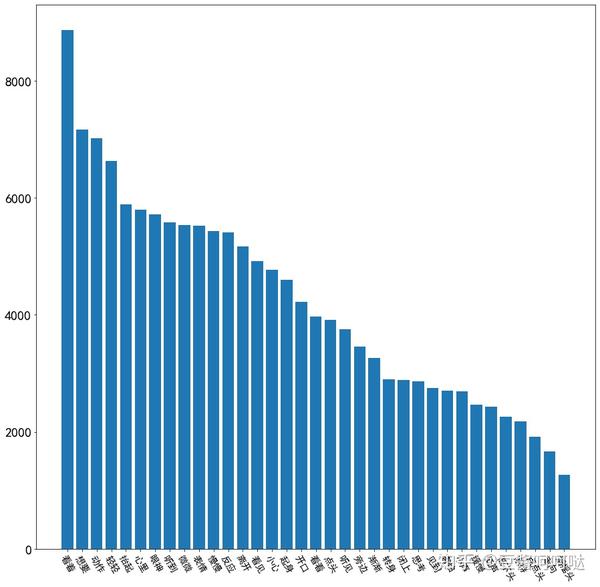
6.4地点描述类过滤词分析
地点描述类过滤词Top10:床上、怀里、地上、房间、世界、门口、回家、家里、出口、桌上。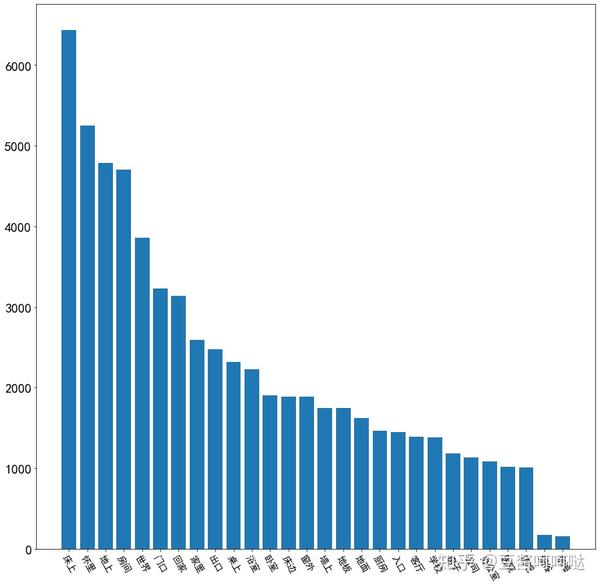
6.5方向与相对位置描述过滤词分析
Top10:出来,身上,下来,眼前,里面,身后,进来,身边,耳边,上来,后面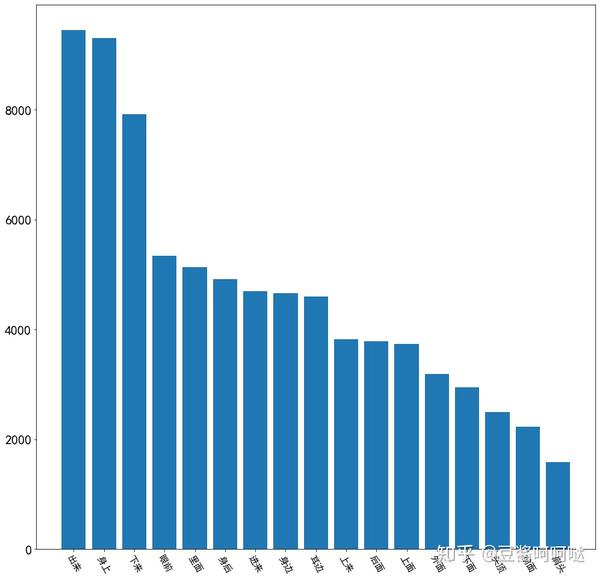
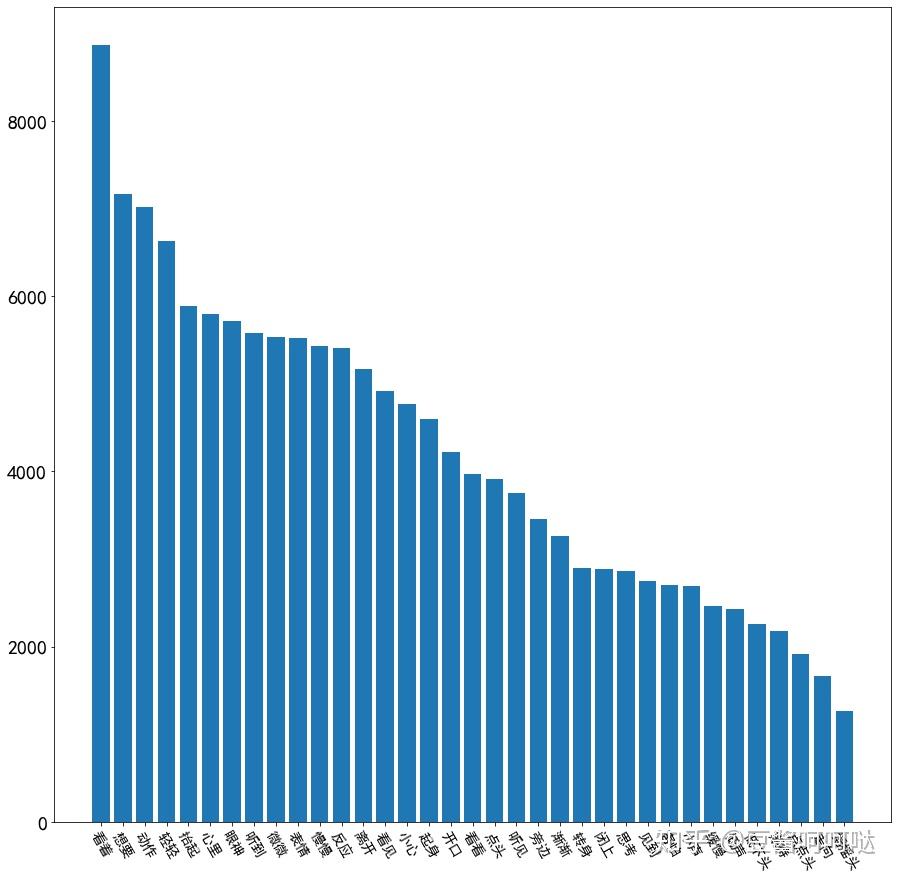
6.6主角统计
目前过滤词中采集到的人名数量约140个(词云里还有),这里只取了排名Top30进行展示。
这里都是真名居多,狗头保命,观众有图自鉴。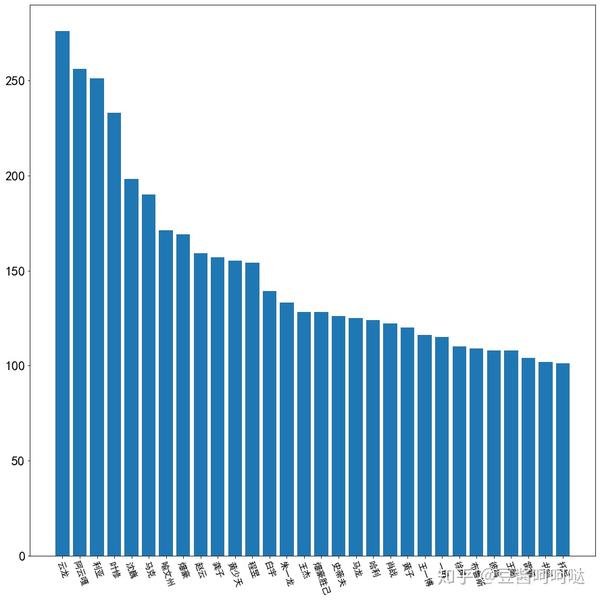
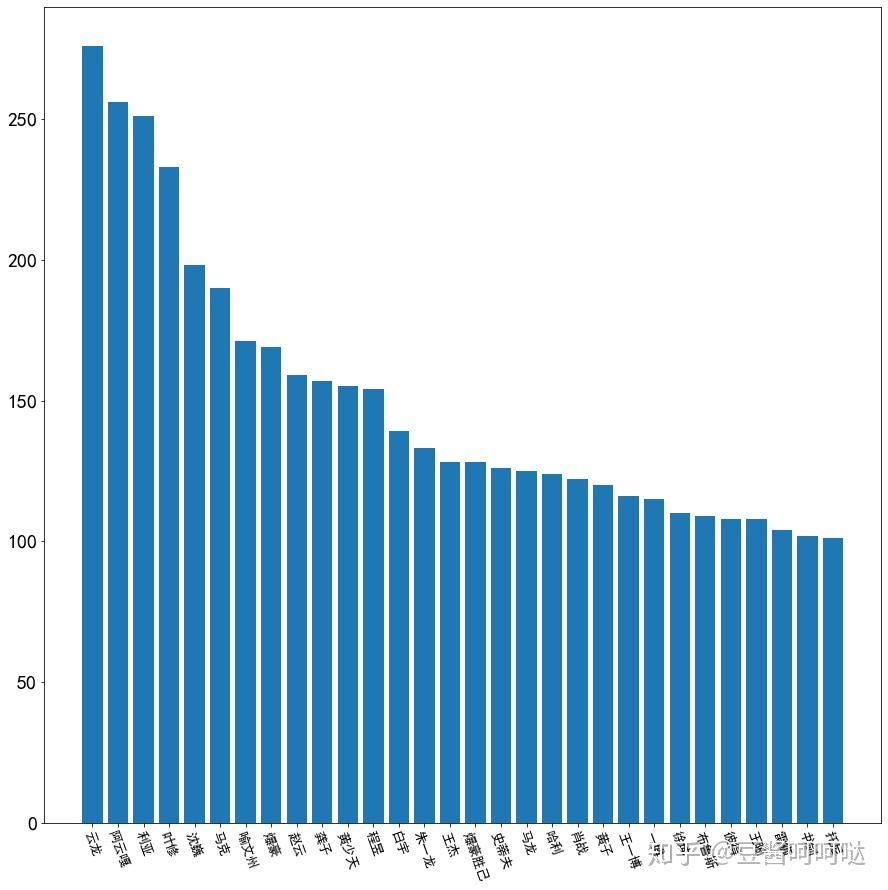
6.7称呼类过滤词分析
称呼或人群类指代词过滤分析Top30(不含:你我他它自己)展示如图。
其中top10:对方,男人,孩子,朋友,别人,年轻,小孩,大家,少年,哥哥。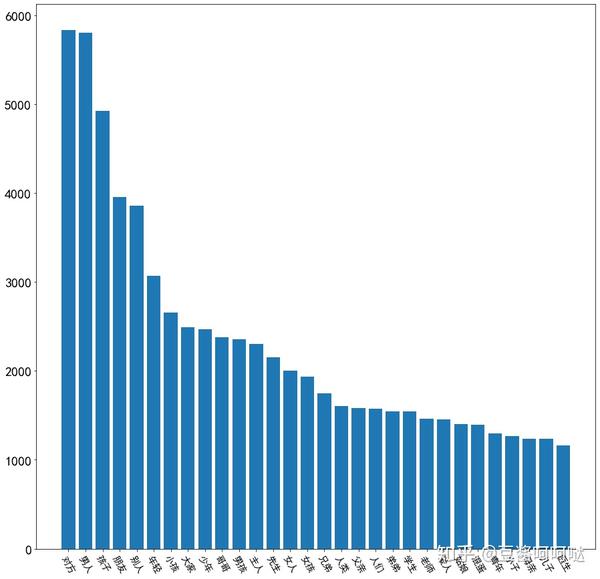
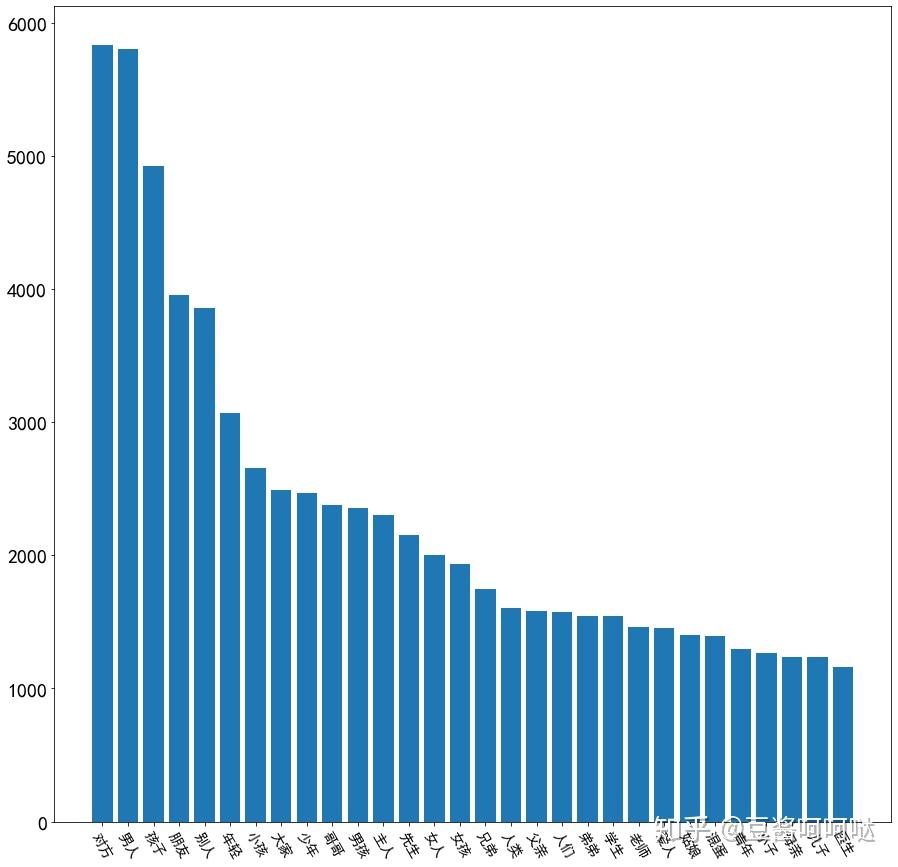
6.8物品类过滤词分析
只取了词云里面浮现出来的,所以并不多。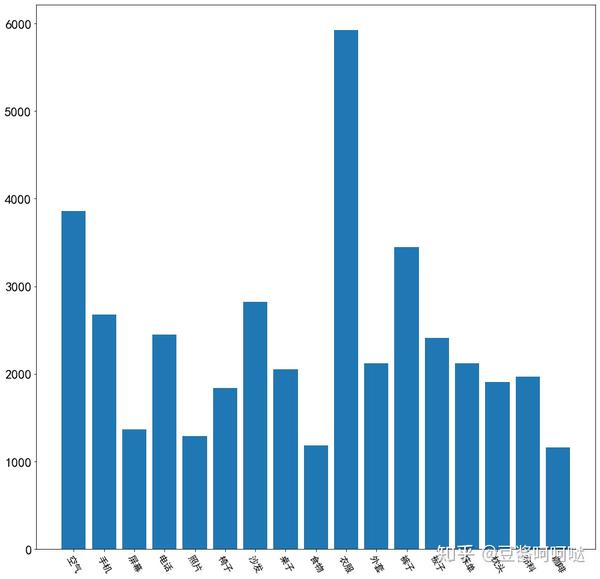
第七步,其他作品横向对比
做横向对比的原因,是看到很多言论,对于文学作品性质的探讨。
由于实在没有时间和精力去爬其它的文章网站,所以这里主要是一个抛砖引玉的作用,有兴趣的小伙伴可以自己做一做。同时也想提问一下做NLP的同学们,难道没有用于训练的中文散文库么?找了两天根本没找到。
根据AO3拥护者的呼声,挑选四部中外名著(最后一篇是我自己加的 LOL):《羊脂球》、《百年孤独》、《红楼梦》、《金瓶梅》,从数据角度进行文字内容分析,上述数据的横向参考意义,这里要提前说明,无关作品价值和已取得成就本身。
通过无敏感词统计发现,四篇文章确实都含有敏感词(这也是ao3拥护者用这些文章说事儿的原因),那么让我们看看四篇文章的敏感词占比,继续做横向对比。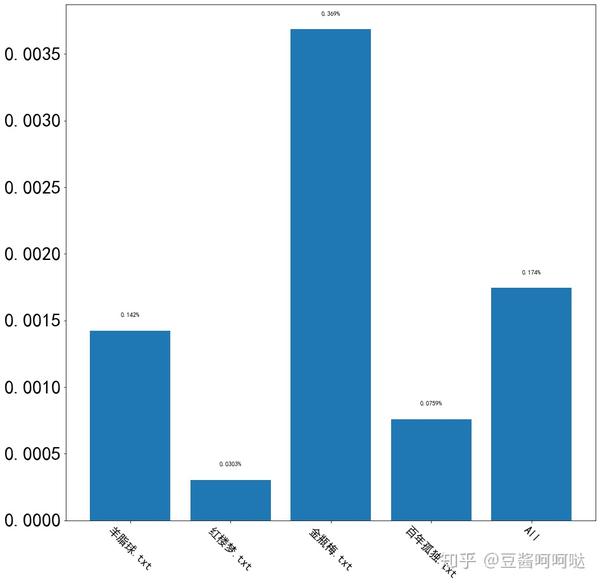

文章开头我们已经得到了AO3的敏感词占比数据,我们来回忆以下:
- · General Audiences 大众:0.2%(敏感词占比所有词的0.2%)
- · Teen And Up Audiences 青年及以上:0.408%
- · Mature 成人:0.933%
- · Explicit 露骨: 1.2%
- · Not Rated 未分级:0.729%
四篇文章的情况如下:
- 《羊脂球》:0.142%
- 《红楼梦》:0.0303%
- 《金瓶梅》:0.369%
- 《百年孤独》:0.0759%
所以重点来了:
通过数据可以看到《金瓶梅》不负众望以绝对优势夺得第一。但就算这古今公认的文章,敏感词占比也在AO3 分级制度的大众与青年的平均比例中间。
由此可见AO3中文内容尺度如何。
这里已经以内容加上分级角度,建立了数据基线,结论:AO3中文区大部分内容敏感程度,高于《金瓶梅》,基本断定H无疑。
同样的,为了公允,我也对这四篇文章进行了词云分析,大家可以看看区别。

敏感词云在这里: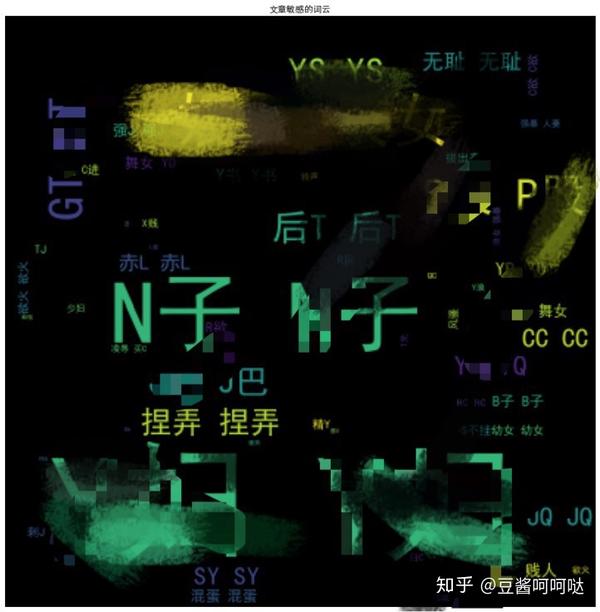
写在最后:
探索真相的过程是有趣的,一步步的揭开网站的内容板块的面纱,基于数据去做拆分和分析,最后发表个人观点:
1. 写作自由真的不代表传播自由,从网站目前的状况和流量增长趋势来看,这样内容的网站被封是早晚的事情;
2. 有人可能想说我现在依旧可以看到AO3也是采取了某些措施,我想说的是,我靠自己的知识和学习获得了我的自由。
3. 需要任何东西都是有成本的。这个成本不一定指的是金钱,也有可能是你付出的时间、学习、劳动和知识。网站就在那里,只是浏览成本提高了,光喊“降价”,可能性大吗?
4. 谁也不是圣人,总会有些小圈子小癖好,个人尊重所有的隐私和爱好。但是有些东西,如果扛着所谓的自由肆意宣泄,强行指鹿为马并不太合适。对于那些熟悉AO3且依旧闹的人,我只能想到“戒断反应”这个词了;
5. 对于那些压根没有看过AO3的人,我想说即使AO3是那个获过‘雨果奖’的圣地,那么中文社区恐怕已经沦为“艾辛格”(来自《魔戒》),至于谁是萨鲁曼,大家自行分析。这里的‘雨果奖’已经解释了无数次了,并不是那个雨果,是2回事,自己学习百度吧。
6. 这是一篇分析向出发的数据贴,如果认为分析方式存在偏颇或者不合理的地方,欢迎讨论。我相信大家最终的目的不过是走向真相,实现的技术细节如果有需求,可以私聊我技术贴的地址。
如果读者你是家长,发现自己的孩子是AO3的拥护者,不论Ta是否真看过,请正确引导。
anyway 三观笔直,感谢郭嘉净网。



3,485 条评论
补充一个细节:截止发文时间2020-3-7,AO3有共有中文文章:244595篇,抽取中文文章数量:12066篇,比例分别为:大众13.3%;青少10.1%;成人32%;露骨16.8%;未分级27.8% 。可见抽样样本分布还是基本满足均匀分布的。
其实我们这么做并不是为了洗地,我们是为了亚文化更好更健康的发展,我们都愿意看到一个多元的,精彩的,健康的,可持续发展的文学创作环境,只不过现在相关制度还不完善,任何的新尝试不免总会误入歧途,真心希望以后亚文化圈推陈出新,活跃发展,为文学创作注入新活力
佩服佩服 讨厌的是很多营销号和部分媒体跟风把这个网站说得无比美好
太多没有研究过ao3也没有看过下坠的
今天还看过一篇文章 夸下坠题材的 说关注发廊妹这个群头 弥补了文学领域的不足
我好想问候作者全家[衰][衰][衰][衰]
不过我自己把骂人的和恶意挑事的禁了不少 这个世界终于清净了[大笑]
理解被波及的理智读者。但这件事发展到现在已经妖魔化了,大面积的拿xz“祭天”以换取亚文化发展的言论实在无法苟同,面目全非。
github已经上传了代码部分链接:https://github.com/czw90130/AO3_DataAnalyze
再次感谢大德奥君的付出和肝,比心
同是28岁男明星,肖战少年气,李现独特帅气,都输给28岁的他
可见并不能说明涉及到儿童色情。答主也许很懂数据,但不一定懂文学创作。
又比如,单纯地把某些器官名词的出现与作品的价值联系在一起。在此我贴几句话:
“露出她精美绝伦的双乳”
“哑巴跪在大姐面前,双手搂着她的屁股”
“那天抚摸了大概一百二十对乳房”
这几句出自莫言的《丰乳肥臀》。
我也建议答主可以用同样的技术爬一爬《白鹿原》《废都》等等以性描写引人注目的中国现代文学。
突然发现知乎上的小伙伴探讨的更有意思。我就不自己折腾了。我放出了数据,说明过程并放出代码。目的就是确保我的思路在各方面是可以被证伪的,这可也是科学探讨问题该有的方法和态度。也有很多小伙伴私信留言想做进一步分析的。这里指出一些硬伤和解决方法,大家在引用或者自己分析的时候可以作为参考:
1、整个第七步,在建立参照的过程中只选取4篇文章是本文最大的硬伤,很多小伙伴都指出,我在写作的时候就发现了这个问题,在文章里也说明了是个抛砖引玉的过程。解决方案也非常简单,取国内合规的网文或者同人文语料,规模大致与1万2千篇规模相当,用我当前的过滤词库和敏感词库再跑一便1~6步就可以了,由于做这些工作的代码和词库我都公开了,且合规的内容也没有被墙,大家可以自己去做。(至于有些同学回复我上AO3就是为了看H的,我只能说我的目的是告诉没看过AO3的路人这个站和舆论描述的高大上不符,你都自首了,那在这回复的话有本事理直气壮的跟你们父母说去)
2、如果看过我采集方法的同学就会发现,我采集文章的方法是根据高级搜索按页码一页一页去取的,这样做的话一旦AO3搜索含有推荐算法就会很容易影响结果,我在发文的时候对比了抽样数据四个标签的比例,发现和总比例差不多就没有继续纠结这个问题,这里最容易手影响的结论是第二步,发文时间的结论。解决办法也很简单,做页码遍历的时候用numpy的shuffle函数打乱页码即可。由于自己实在不想再来一遍,也不影响我要达到的目的,就这样了~
还有其他的问题,我就不全放出来扫兴了,欢迎大家理性找茬,想继续跟进或者反驳的同学也可以自己做做努力对不对。