

はじめに
このアイコンをご存知でしょうか。

そう、かの有名なMelvilleさんのアイコンです。
Melvilleさんに好きなキャラなどを描いてもらい、それをtwitterのサムネにしている人が大勢いることで知られ大きな支持を得ています。
この方の描くアイコンはその特有の作風から、「メルアイコン」などとよく呼ばれています。
代表的なメルアイコンの例


(それぞれゆかたゆさんとしゅんさんのものです (2020/2/12現在))
自分もこんな感じのアイコンが欲しい!!!!!!ということで機械学習でメルアイコン生成器を作りました。
本記事ではそれに用いた手法をおおざっぱに紹介していきたいと思います。
GANとは
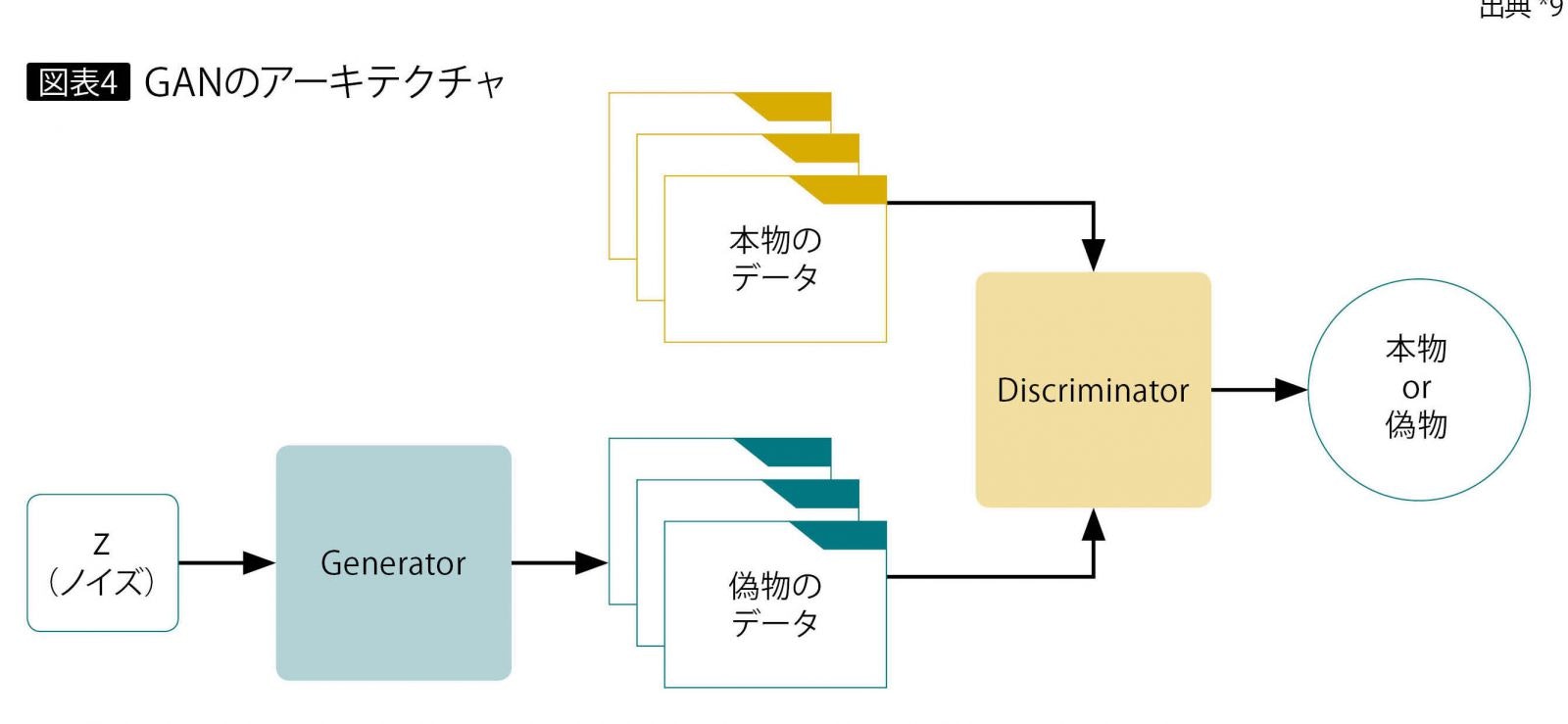
生成にあたってはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法を用いています。
この手法では画像を生成するニューラルネットワーク(Generator)と、入力されたデータがメルアイコンなのかそうでないのかを識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。GeneratorはDiscriminatorを欺くためにできるだけメルアイコンに似せた画像を生成しようとし、Discriminatorはより正確に画像を識別しようと学習します。二つのニューラルネットワークがお互いに鍛え合うことでGeneratorはメルアイコンに近い画像を生成できるようになっていきます。
データセット収集
Generatorがメルアイコンっぽい画像を生成できるようになったり、Discriminatorが入力された画像をメルアイコンなのかどうかを識別できるようになったりするためには実在するメルアイコンをできるだけ大量に持ってきて教師データとなるデータセットを作り、これを学習に用いる必要があります。
ということでtwitterを巡ってメルアイコンのサムネを見つけては保存といったことを繰り返し100枚以上手に入れました。これを学習に使います。
Generatorの作成
Generatorには先ほど用意したメルアイコンをみて、それっぽい画像を生成できるよう学習してもらいます。
生成する画像は64×64pixel、色はrgbの3チャネルとします。
仮にGeneratorが同じようなデータを毎回生成してしまうと学習がうまく進まないため、できるだけ多くの種類の画像を生成できる必要があります。そのためGeneratorには画像生成に乱数でできた数列を入力します。
この数列に対し、後述する「転置畳み込み」という処理を各畳み込み層で施し段階的に64×64pixel、rgbの3チャネルを持つ画像に近づけます。
転置畳み込みとは
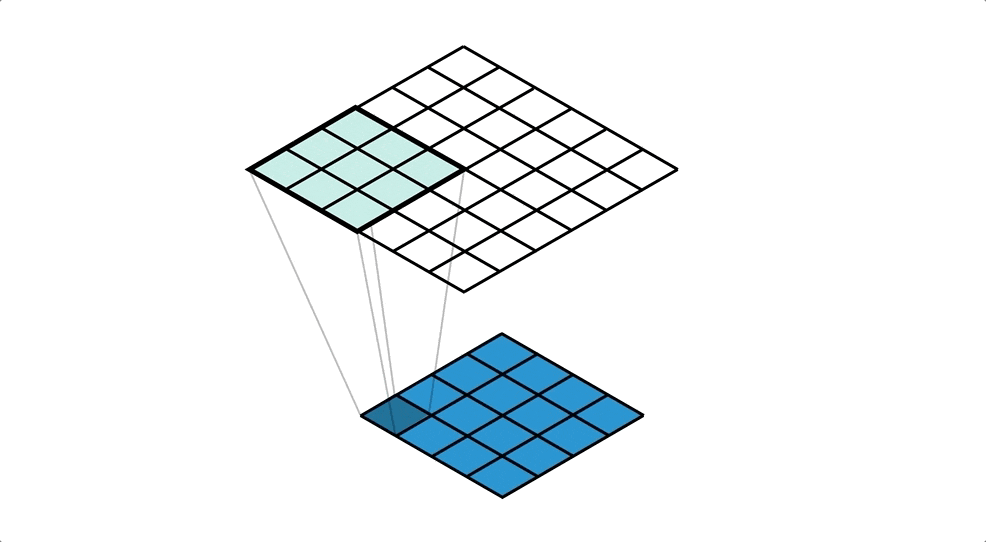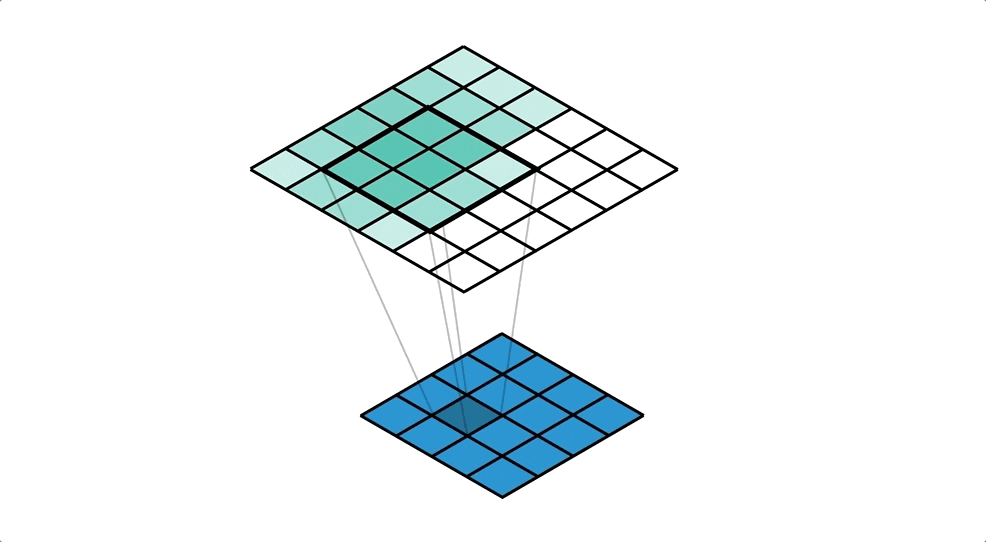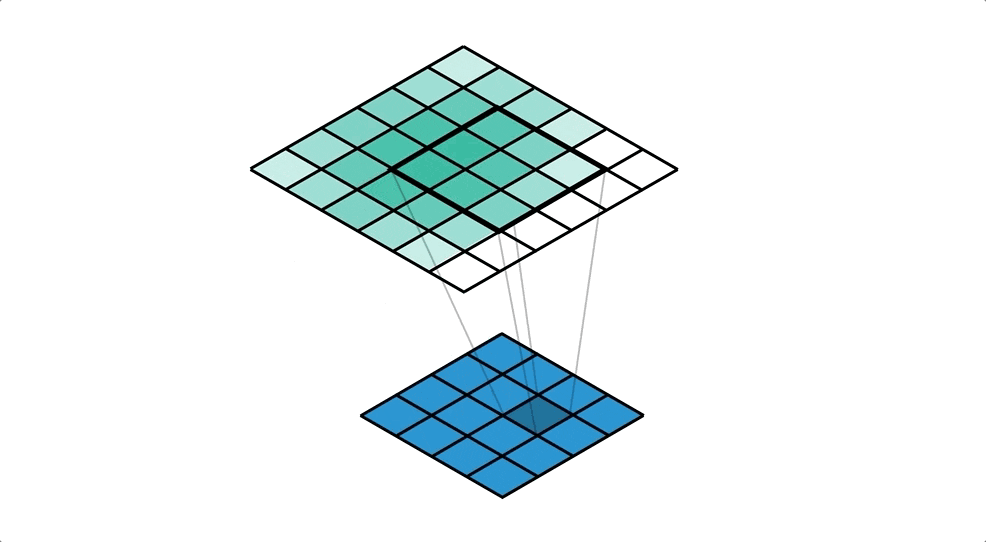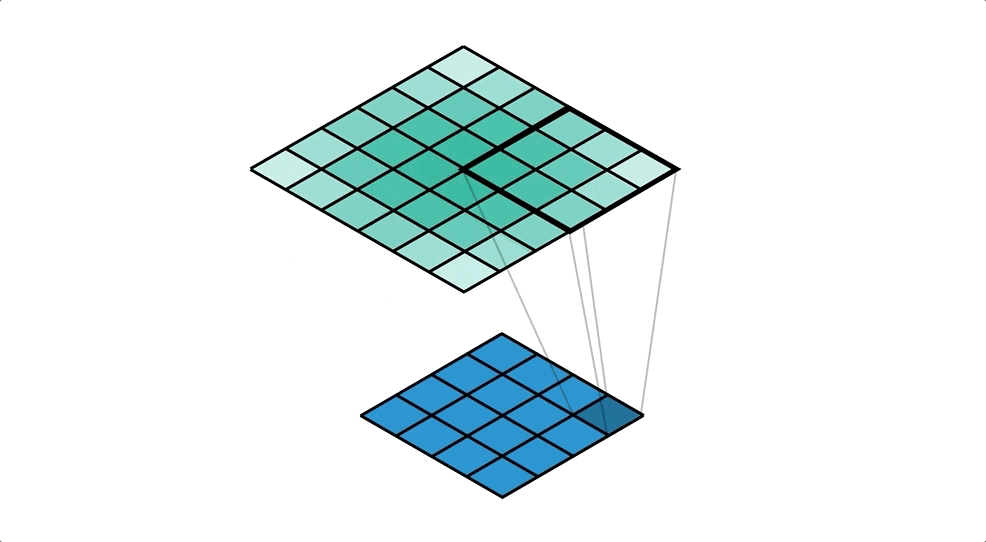
通常の畳み込みは下で示すように、カーネルを用意しずらしながら和積を取り出力とします。pytorchにおいては例えばtorch.nn.Conv2dで実装できます。
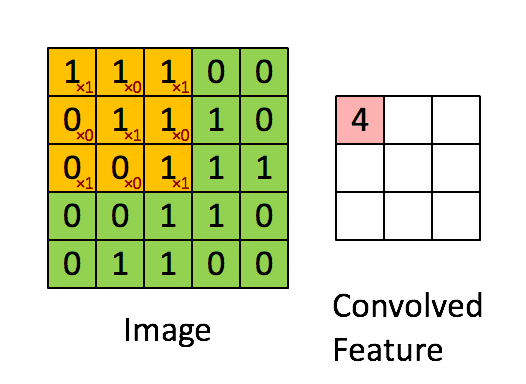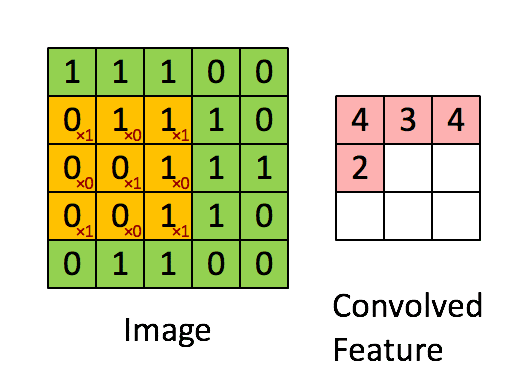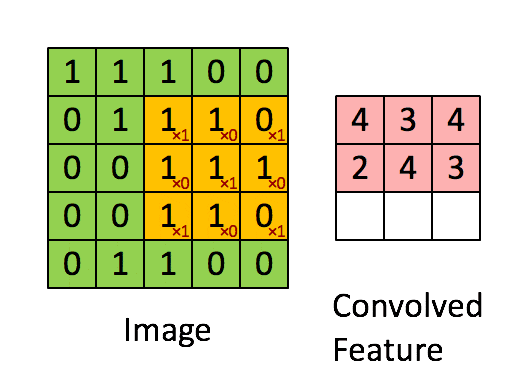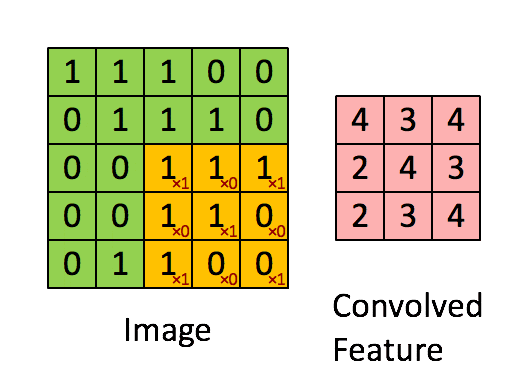
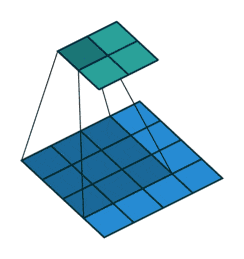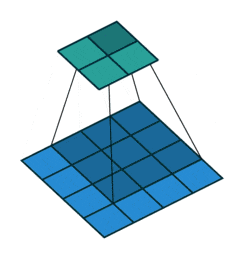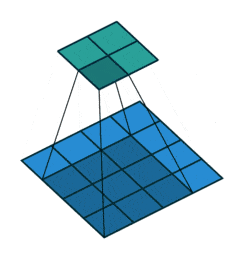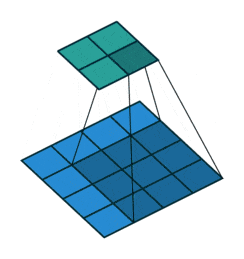
対して今回用いる転置畳み込みでは1要素ごとにカーネルとの積を求め、出てきた結果の和を取ります。イメージとしては対象の要素を拡大するような感じです。pytorchにおいては例えばtorch.nn.ConvTranspose2dで実装できます。
この転置畳み込みの層とself_attentionの層(後述)を重ね、最後の層では出力チャネル数を3としています。(rgbにそれぞれ対応)
以上の内容から、作ろうとしているGeneratorの概略は下の図のようになります。

このGeneratorは合計5つの転置畳み込み層を持ちますが、3層目と4層目の間、4層目と5層目の間にはself_attentionという層を挟んでいます。これにより似た値を持つpixel達を一度に見ることで、比較的少ない計算量で画像全体を大局的に評価することが可能です。
こうして構成されたGeneratorは未学習の状態であれば例えばこんな画像を出力します。(入力する乱数の数列によって結果は変化します)

未学習なのでまだノイズのようなものしか出力できていません。ですが次に説明する、入力されたデータがメルアイコンなのかそうでないのかを識別するニューラルネットワーク(Discriminator)とお互いに訓練しあうことでそれらしい画像を出力できるようになっていきます。
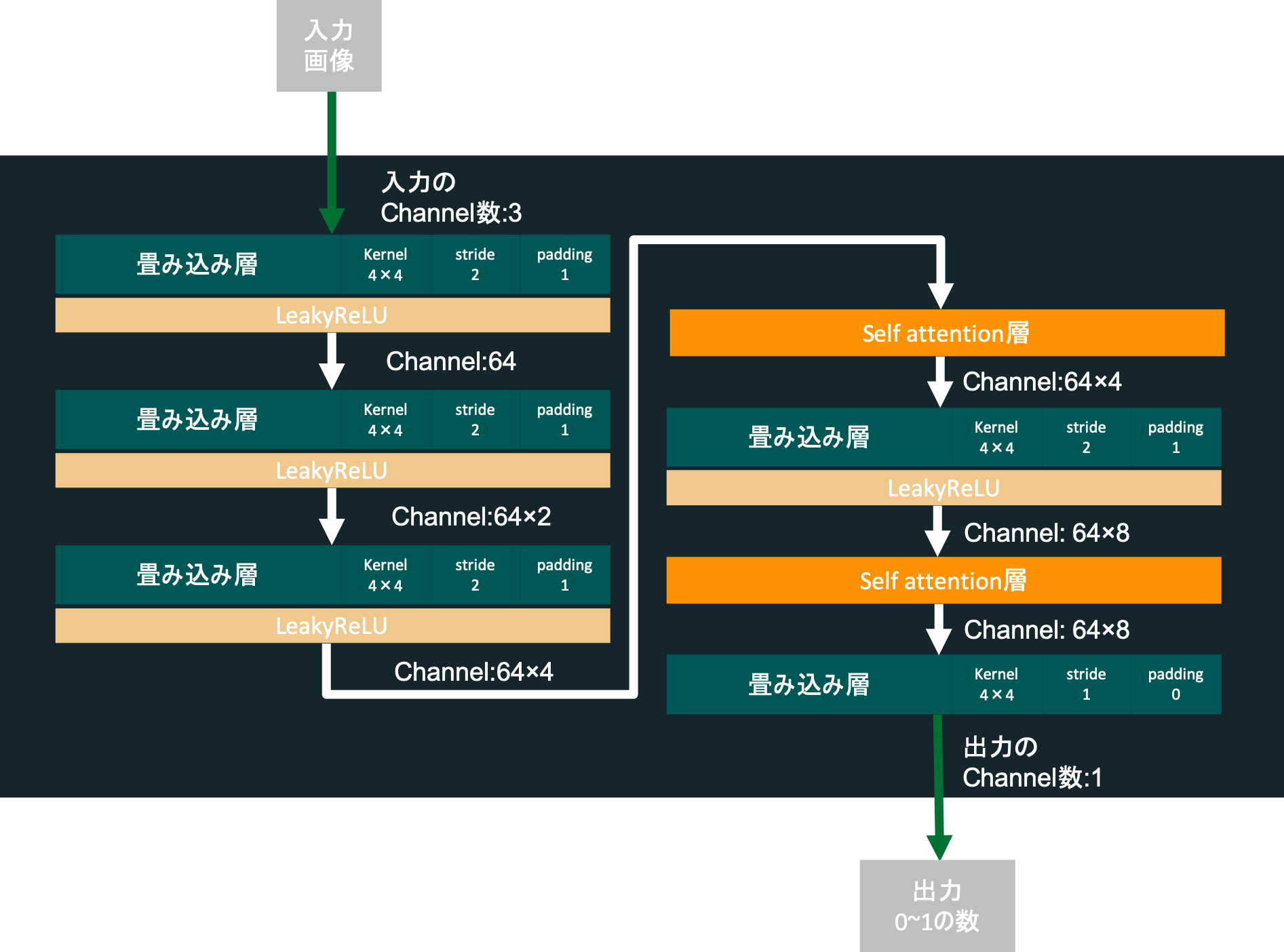
Discriminatorの作成
Discriminatorには上のGeneratorが生成した画像をみて、それがメルアイコンなのかどうかを見分けてもらいます。要は画像認識器を作ります。
入力する画像は64×64pixel、色はrgbの3チャネルとし、出力はどれだけメルアイコンっぽいかを表す値(範囲は0~1)とします。
構成としては、普通の畳み込み層を5つ重ね、3層目と4層目の間、4層目と5層目の間にはself_attentionの層を挟みます。図示すると次のようになります。
学習方法・誤差関数
DiscriminatorとGeneratorそれぞれの学習方法は次に述べる一連の通りにしました。
Discriminatorの学習
Discriminatorは画像が入力されると、どれだけメルアイコンっぽいかを示す数0~1を返します。
まず実在のメルアイコンを入力し、その時の出力(0~1の値)をとします。
次にGeneratorに乱数を入力、画像を生成してもらいます。この画像をDiscriminatorに入力すると同様に0~1の値を返します。これをとおきます。
こうして出てきたとを次に説明する損失関数に入力して誤差伝搬に使う値を得ます。
損失関数
GANの手法の一つ、SAGANの「hinge version of the adversarial loss」では次に説明するような損失関数を用います。簡単に説明するとこの関数はとを正しいラベル、とをDiscriminatorより出力された値、をミニバッチあたりのデータ数とした時
と表されます。1
今回は、、(100%メルアイコンであることを表す)、(絶対メルアイコンじゃないことを表す)とそれぞれ設定し
とします。これが今回用いるDiscriminatorの損失関数となります。誤差伝搬の最適化手法にはAdamを使い、学習率0.0004、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.0と0.9に設定しました。
Generatorの学習
Generatorは乱数でできた数列が入力されると、できるだけメルアイコンっぽくしようと頑張りながら画像を生成します。
まず乱数でできた数列をGeneratorへ入力、画像を得ます。それをDiscriminatorに入力し、どれだけメルアイコンらしいかを示す値を出力させます。これをとします。
損失関数
SAGANの「hinge version of the adversarial loss」ではGeneratorの損失関数は次のように定義されます。
SAGANではこう定義すると経験的にうまくいくことが知られているようです。1
がミニバッチあたりのデータの数なことを考えると、なんと実質Discriminatorの判断結果をそのまま使っています。自分的にはこれに少しびっくりしましたがどうでしょう。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0001、Adamの一次モーメントと二次モーメントはそれぞれ0.0と0.9に設定しました。(学習率以外はDiscriminatorと同じ)
全体像
上でも紹介した画像の再掲ですが、先ほど作成したGeneratorとDiscriminatorをこんな風に組み合わせGANを構成します。
いざ生成
集めた実在のメルアイコンを用いて学習を行い、Generatorにメルアイコンを生成させます。ミニバッチあたりのデータ数は5にしておきます。結果は以下のようになりました。

すげえ!!!!!!!!!!!
感動!!!!!!!!!!!
比較用に上側には入力データの例を表示、下側に実際に生成された画像を表示しています。また生成結果は実行するごとに変化します。
個人的にはそこまで長くないソースコードでここまでできることにかなり驚きました。GANマジ偉大!!!!!!!!
課題
こんなすごいことができるものを作りましたが、まだ解決できていない点もあります。
- モード崩壊
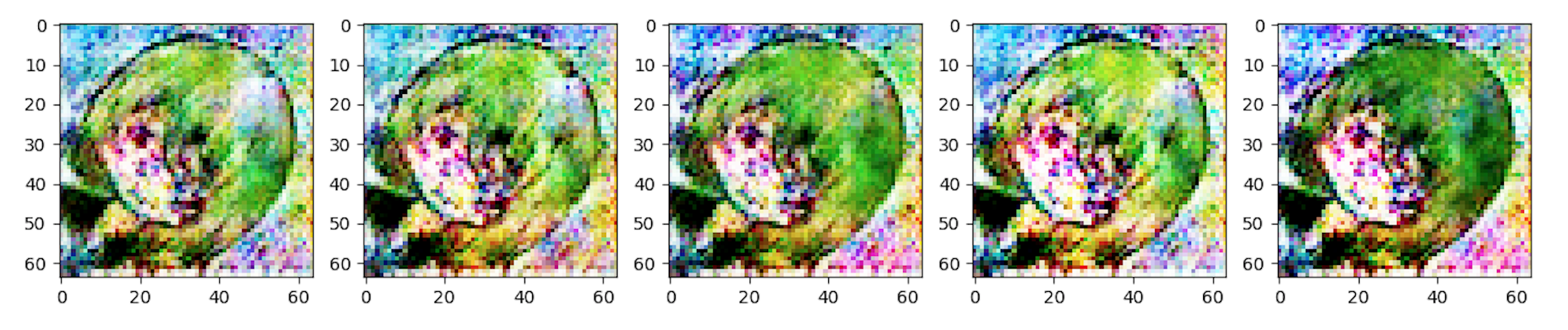
twitterで指摘してくださった方がいらっしゃいましたが、生成結果を見ると乱数を用いて5枚生成しているはずがどれも同じようなキャラの画像になってしまっていることがわかります。このような現象はモード崩壊と呼ばれています。
今回はミニバッチ数5、エポック数3000で学習を回しているためこれによる過学習が原因かとも思いましたが、エポック数を200くらいに減らした状態でも以下のようにやはり同じような画像が生成されてしまいます。 (これはself_attentionをまだ適用していなかった状態での出力ですが、エポック数200くらいではだいたいこんな感じのが出てきます)
(これはself_attentionをまだ適用していなかった状態での出力ですが、エポック数200くらいではだいたいこんな感じのが出てきます)
確かにある程度エポック数3000のときと比べて実行するたびに微妙に違うものが生成されていますが、やはりぱっと見た感じでは同じような画像に見える上にそもそもエポック数が小さいためかクオリティが断然低くなってしまっているのがお分かりだと思います。
MNISTの例の手書き数字の画像が60000枚くらいあることを考えると、データセットをあと59900枚近く増やすことが考えられますがそんな量だとMelvilleさんがやばいので事実上不可能です。
モード崩壊、難しいです。
ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/image_generator
まとめ
GANはめちゃくちゃ素晴らしい手法です。モード崩壊が起きているとはいえ、たった100枚近くのデータセットでかなりメルアイコンに近いものを作ることができました。皆さんもGANでガンガン画像生成しましょう。
おまけ
自分の集めたメルアイコン全てに対して単純に平均を取ったら次のような画像が出てきました。


