
PKSHA Technologyから,NLPライブラリCamphrを公開しました.
Camphrを使うと,TransformersやUdifyなどの最先端の手法の他,knpなど伝統的な言語処理手法を簡単に組み合わせて使うことができます.
本記事では,Camphrの特徴や,簡単な使い方を紹介していきます.
spaCy
CamphrはspaCyのプラグインです.日本だとGinzaがspaCyを利用しており有名ですね.
spaCyはNLPフレームワークで,以下のような特長があります(主観).
- 様々な機能を簡単に合成できる (深層学習からパターンマッチまで何でもOK)
- パイプラインを1コマンドで保存&復元できる
1つ目の機能は実用上とても重要です.NLPはここ数年で大幅に進歩しましたが,実際のタスクはend-to-endにデータを食わせればOK,みたいに美味しいものばかりではありません.かといって新しい手法を全く使わないのも,あまり筋が良くなさそうです.
spaCyを使うと,最新の手法からルールベースの手法まで,様々な手法を組み合わせることができます.そしてCamphrを使うと,例えばBERTをfine-tuneした後にKNPと正規表現を組み合わせる,ということが簡単にできます.
また2つめの機能のおかげで,組み合わせた複雑なパイプラインを簡単に保存・復元でき,容易に持ち運ぶことができます.
Quick Tour
Camphrが提供している機能をざっとみていきます.
日本語を使う場合は,MeCabをインストールしておく必要があります.
Udify - BERTベースの多言語 Dependency Parsing
UdifyはBERTベースの多言語dependency parserです.同じモデルで,多言語(例: 日本語,英語,フランス語,,,)の解析をすることができます.
インストールは以下のコマンドだけでOKです.モデルパラメータ等がダウンロードされるので,結構時間がかかるかもしれません.
$ pip install https://github.com/PKSHATechnology-Research/camphr_models/releases/download/0.5/ja_mecab_udify-0.5.tar.gz
そして以下のように使います.
import spacy
nlp = spacy.load("ja_mecab_udify")
doc = nlp("今日はいい天気だ")
spacy.displacy.render(doc)
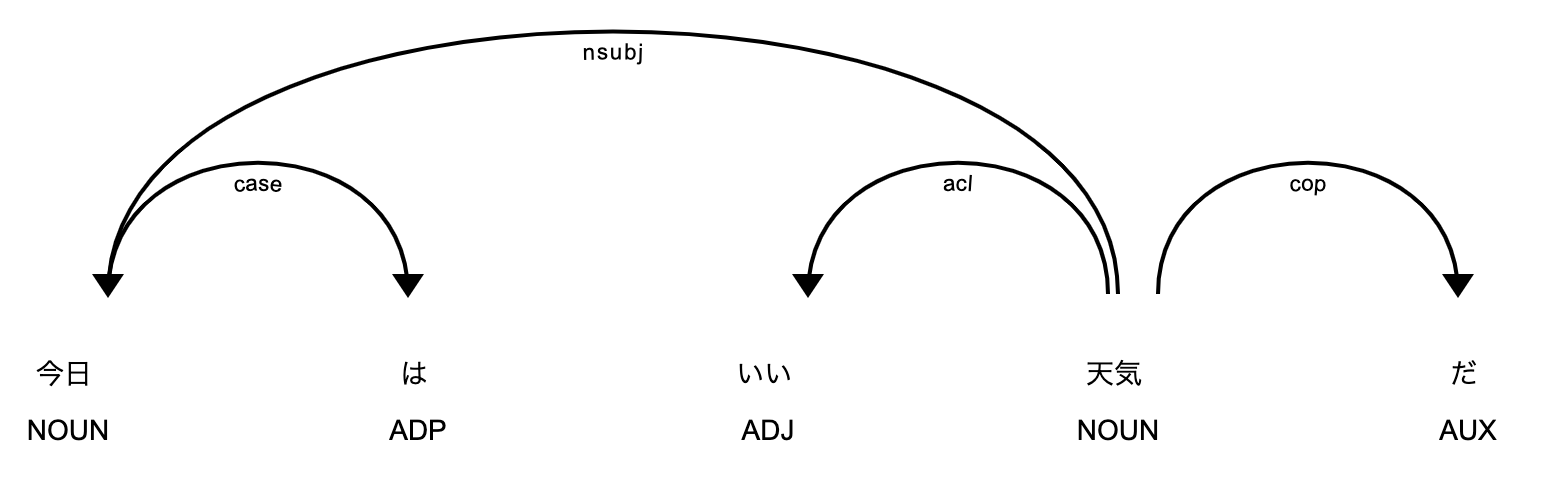
Udifyは多言語モデルなので,そのまま英語の解析ができます.
doc = nlp("Udify is a BERT based dependency parser")
spacy.displacy.render(doc)

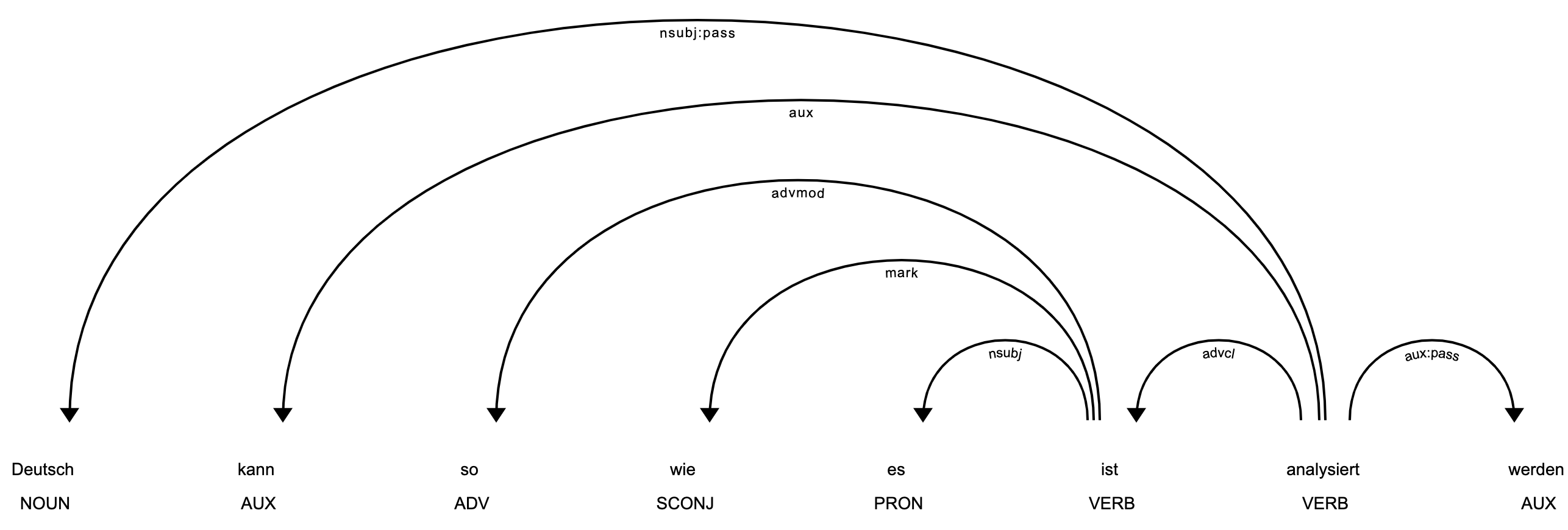
スペース区切りの言語ならば大抵いけます.(中国語とかはトークナイザを付け替える必要あり)
doc = nlp("Deutsch kann so wie es ist analysiert werden")
spacy.displacy.render(doc)
より詳細な使い方は,公式ドキュメントを参照してください.
Transformersの埋め込みベクトルを使う
まずはcamphrをインストールします
$ pip install camphr[mecab]
BERTの埋め込みベクトルを使ってみましょう.Bert as a serviceと同じです.
下のように,パイプラインの設定をcamphr.loadに渡します.例はYamlですが,omegaconfが処理できるものならば何でも良いです. (dict, json等)
import camphr
nlp = camphr.load(
"""
lang:
name: ja_mecab # lang名
pipeline:
transformers_model:
trf_name_or_path: bert-base-japanese # モデル名
"""
)
裏でtransformersが動いており,パラメータ等は勝手にダウンロードされます.(なのでちょっと時間がかかるかもしれません).
以下のようにして使います.
doc = nlp("BERTの埋め込みベクトルをspacyで使う")
print(doc.vector)
token = doc[0]
print(token, token.vector) # トークンのベクトル
span = doc[1:4]
print(span, span.vector) # スパンのベクトル
[[ 1.3047, -1.0605, 0.4627, ..., -0.6162, -0.3270, 0.1817],
...,
BERT [ 1.30469453e+00 -1.06053877e+00 4.62672085e-01 -1.38373268e+00
-1.95268679e+00 -3.93442586e-02 -9.07721579e-01 8.44051391e-02
...
の埋め込みベクトル [ 1.78825343e+00 -1.58017492e+00 -1.46538484e+00 -1.54379010e+00
-1.43261361e+00 2.32346106e+00 -2.69508541e-01 -1.76621303e-01
...
コサイン類似度は以下のようにして取得します.
doc2 = nlp("BERTは自然言語処理を大幅に進歩させました")
print("文の類似度 : ", doc.similarity(doc2))
print("トークンの類似度: ", doc[0].similarity(doc2[0]))
文の類似度 : 0.8219287395477295
トークンの類似度: 0.8147419691085815
他のモデルや,自作モデルを使いたい場合は公式ドキュメントを参照してください.
Transformersのfine-tuning
CLIを使って簡単にfine-tuneできます.例えばテキスト分類の場合は:
$ camphr train train.data.path="./train.jsonl" \ # トレーニングデータ
model.textcat_label="./label.json" \ # ラベル
model.pretrained=bert-base-cased \ # 事前学習モデル名
model.lang=ja_mecab # spacyの言語名
CLIはHydraを使って実装しており,トレーニングのログやパラメータは./outputsに保存されます.
上のコマンドを詳しくみていきましょう.
train.jsonlの中身は,以下のようなjsonl形式です.1行ごとにjsonが入っています.
["1行に一つ,json形式でトレーニングデータを書いていきます", {"cats": {"POSITIVE": 0.1, "NEGATIVE": 0.9}}]
["1つめの要素は入力文,2つめの要素はラベルです.", {"cats": {"POSITIVE": 1.0, "NEGATIVE": 0.0}}]
...
ラベルはspacy.GoldParseに変換されます.
ラベル定義ファイルlabel.jsonは以下のような感じです.カテゴリ分類のラベルを全て列挙してください.
["POSITIVE", "NEGATIVE"]
bert-base-casedはtransformersのモデル名です.事前学習モデルリストから適当に選ぶか,自作モデルのPathを指定します.
OptimizerやSchedulerの調整等,トレーニング設定のカスタマイズをしたい場合は,公式ドキュメントを参照してください.
KNP
knpは日本語の構文・格解析器です.Camphrは,knpの解析結果をspaCyで扱うための機能を提供しています.
インストールは以下のようにします.(システムにjumanとknpをインストールしておく必要があります).
$ pip install camphr[juman]
camphr.loadを使ってモデルをロードします.
import camphr
nlp = camphr.load("knp")
あとはspaCyのやり方で解析するだけです.
doc = nlp("太郎はリンゴとみかんを食べながら富士山へ行った。")
形態素,基本句や係り受けは以下のようにして取得します
token = doc[0]
print("形態素:", token._.knp_morph_element)
sent = list(doc.sents)[0]
print("BList:", sent._.knp_bunsetsu_list_)
tag = sent._.knp_tag_spans[3]
print("基本句:", tag.text)
print("係り受け先:", tag._.knp_tag_children)
print("係り受け元:", tag._.knp_tag_parent)
形態素: <pyknp.juman.morpheme.Morpheme object at 0x12e9faa90>
BList: <pyknp.knp.blist.BList object at 0x12e9fa2d0>
基本句: 食べながら
係り受け先: [みかんを]
係り受け元: 行った。
より詳しい説明は,公式ドキュメントを参照してください.(日本語です)
終わりに
下の絵はCamphrのロゴです.ある単語が隠されているのですが,わかりますか?

