
B-treeとは
Wikipediaから引用すると、b-treeとは
多分岐の平衡木(バランス木)である。1 ノードから最大 m 個の枝が出るとき、これをオーダー m のB木という。後述する手順に従って操作すると、根と葉を除く「内部ノード」は最低でも m /2 の枝を持つことを保証できる。
B-treeに関しては詳しい記事がたくさんで書かれているのでこの記事では詳しい説明は割愛して、引用させていただいた記事を紹介させて頂くだけにしておきたいと思います。
文字や図で説明されてもわからないかなと思うので、こちらのvisualizationサイトを利用すると動きが理解しやすいかと思います。
実装
実装内容はgoogle/btreeを大いに参考にしています。
今回実装する内容としては、
1. B-treeの本体
2. 探索
3. 挿入
の順番で実装していきます。
B-treeの本体
B-treeには大きく分けて、比較可能なアイテムと、アイテムが所属するノードに分けられます。ノードは、その子にあたるノード群をもちます。
また、B-treeの起点になるノードを特別なノードとしてルートノードとします。それらを実装していきます。
package tree
// Item - ノードに属するアイテム
type Item struct {
Value int
Object interface{}
}
// Items - アイテムのリスト
type Items []*Item
func (i *Item) Less(item *Item) bool {
return i.Value < item.Value
}
// Node - ノード。属するアイテムのリストと、子になるノード群を持っている
type Node struct {
Items Items
Branch Branch
}
// Branch - あるノードに属するノード群
type Branch []*Node
// Btree - B-treeの本体。ルートになるノードへのポインタを持つ
type Btree struct {
Root *Node
}
// NewBTree - B-treeを作成する。mはB-treeのオーダー
func NewBTree(m int) (*Btree, error) {
if m < 2 {
return nil, fmt.Errorf("m must be greater than 3, can't be %d", m)
}
return &Btree{
m: m,
Root: nil,
}, nil
}
// maxItemNum - アイテムの閾値を返す
func (b *Btree) maxItemNum() int {
return b.m*2 - 1
}
ここでItemは比較対象のアイテムより小さいかどうかを比較するLessメソッドを実装しています。
Itemが持っているObjectはわかりやすさのために、stringにしていますが、interface{}にしておくことで、好きなデータを紐づけることができます。
ItemをLessを持ったinterface化する方が汎用的だと思いますが、今回はこのままでいきます。
新しくB-treeを作成する時には、B-treeのオーダーを指定し、
tree := btree.NewBtree(2)
のようにして作成します。
探索
次にB-treeから特定のアイテムを探索するメソッドを実装していきます。
実際に探索する時には、
1. ルートノードのアイテムリストから対象なアイテムを探索
2. 1で見つからなければ子ノードを探索
3. 子ノードのアイテムリストを探索し、なければその子ノードを(以下略)
の用に探索していきます。
アイテムリストの探索
まずはアイテムリストから対象のアイテムを探索するメソッドを作成します。
// findItem - Itemsの中から検索対象のItemを検索する。なかった場合は、もっとも近く、小さいItemのindexを返す
func (i *Items) findItem(item *Item) (index int, exist bool) {
index = sort.Search(len(*i), func(in int) bool {
return item.Less((*i)[in])
})
// あるItemと等価だった場合は、一つ前のindexで返す
if index > 0 && !((*i)[index-1].Less(item)) {
return index - 1, true
}
return index, false
}
ここでは、アイテムリストの中身をLessとsortパッケージのSearchメソッドを使って順に探索しています。
アイテムリストの中に探しているアイテムが会った時のみ、二番目の戻り値にtrueを返しています(真ん中部分)
アイテムリストの中に探索対象のアイテムがなかった場合、indexとfalseを返しています。
対象アイテムが見つからなかった場合でも、falseのみでなくindexも返しているのは、次の子ノードを探索する時に利用するからです。
下の画像の例でルートのノードから30を探索するケースを考えてみます。
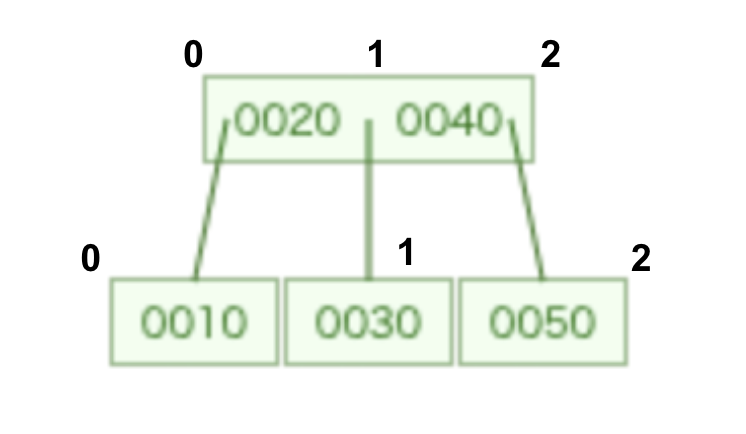
ルートノードには[20, 40]があり、30はありません。20 < 30 < 40 なのでindexは1になります。
B-treeの特性としてあるアイテムの右にはそのアイテムより大きく、左にはそのより小さいアイテムしかないという特性があるので、30は0の子ノード以下には存在しなく、同時に2の子ノードにも存在しないことになります。
つまり探索する子ノードは1の子ノードだけで良いのです。このindexはノードの探索用関数で使うことになります。
ノードの探索
// findItem - ノードの要素、Branchの中に指定されたItemがあるかをチェック
func (n *Node) findItem(item *Item) (*Item, bool) {
index, ok := n.Items.findItem(item)
if ok {
return n.Items[index], true
}
if len((*n).Branch) > 0 {
return n.Branch[index].findItem(item)
}
return nil, false
}
ノードの探索関数は上のようになります。
ノードにあるアイテムリストから探索し、もし見つかればそこで終了。もし見つからなければ、先ほどのindexにあたる子ノードを再帰的に探索していきます。
ここでイメージがわきやすいようにテストを書いておきます。必要がない方は飛ばしてください。
findItemのテストコードfunc TestNode_findItem(t *testing.T) {
type fields struct {
Items Items
Branch Branch
}
type args struct {
item *Item
}
tests := []struct {
name string
fields fields
args args
want *Item
want1 bool
}{
{
name: "ノードのアイテムリストに探索対象が存在",
fields: fields{
Items: Items{
{Value: 10},
{Value: 20},
},
Branch: Branch{
{Items: Items{{Value: 5}}},
{Items: Items{{Value: 15}}},
{Items: Items{{Value: 25}}}},
},
args: args{
item: &Item{
Value: 10,
},
},
want: &Item{
Value: 10,
},
want1: true,
},
{
name: "子ノードに探索対象が存在",
fields: fields{
Items: Items{
{Value: 10},
{Value: 20},
},
Branch: Branch{
{Items: Items{{Value: 5}}},
{Items: Items{{Value: 15}}},
{Items: Items{{Value: 25}}}},
},
args: args{
item: &Item{
Value: 15,
},
},
want: &Item{
Value: 15,
},
want1: true,
},
{
name: "アイテムリストにも子ノードにも存在しない",
fields: fields{
Items: Items{
{Value: 10},
{Value: 20},
},
Branch: Branch{
{Items: Items{{Value: 5}}},
{Items: Items{{Value: 15}}},
{Items: Items{{Value: 25}}}},
},
args: args{
item: &Item{
Value: 40,
},
},
want: nil,
want1: false,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
n := &Node{
Items: tt.fields.Items,
Branch: tt.fields.Branch,
}
got, got1 := n.findItem(tt.args.item)
if !reflect.DeepEqual(got, tt.want) {
t.Errorf("findItem() got = %v, want %v", got, tt.want)
}
if got1 != tt.want1 {
t.Errorf("findItem() got1 = %v, want %v", got1, tt.want1)
}
})
}
}
ノードの探索関数ができたので、ルートからそれを呼び出す関数を追加します。
func (b *Btree) Find(item *Item) (*Item, bool) {
return b.Root.findItem(item)
}
動作確認
手書きでB-treeにアイテム・ノードを入れて試してみます。
func main() {
btree := tree.Btree{
Root: &tree.Node{
Items: tree.Items{
{Value: 10, Object: "田中"},
},
Branch: tree.Branch{
{Items: tree.Items{
{Value: 4, Object: "佐藤"},
{Value: 6, Object: "鈴木"},
}},
{Items: tree.Items{
{Value: 15, Object: "山田"},
{Value: 16, Object: "斎藤"},
}},
},
},
}
if item, ok := btree.Find(&tree.Item{Value: 15}); ok {
fmt.Println(item.Object)
}
}
// output: 山田
これで探索部分が完成しました。
挿入
挿入は探索より少し複雑になります。
基本的な流れは、以下のようになっています。詳しくは参考サイトなどをみていただけると理解しやすいかと思います。
1.ルートノードに余裕があればルートノードのアイテムリストに追加
2. 閾値(m)を超える場合は、自分自身を分割し、自身の子ノードに追加する
3. 子ノードが閾値を超える場合は、子ノードを分割し、アイテムリストに真ん中になるアイテムを追加し、子ノードに分割したノードを追加する。
4. その結果2の条件に当てはまれば、さらに自分自身を分割する。
アイテムリストへの挿入
アイテムリストへの挿入は、特に変わったことはありません。アイテムリストの指定した位置にアイテムが挿入できるようにしておきます
func (i *Items) insertAt(item *Item, index int) {
// 枠を一個増やす
*i = append(*i, nil)
// 最後のindex以外だった場合、新しいItemを入れるスペースを作る
if index < len(*i) {
copy((*i)[index+1:], (*i)[index:])
}
(*i)[index] = item
}
insertAtのテストコードfunc TestItems_insertAt(t *testing.T) {
type args struct {
item *Item
index int
}
tests := []struct {
name string
i Items
args args
want Items
}{
{
name: "insert_to_4",
i: Items{
{Value: 1},
{Value: 2},
{Value: 3},
},
args: args{
item: &Item{
Value: 4,
},
index: 3,
},
want: Items{
{Value: 1},
{Value: 2},
{Value: 3},
{Value: 4},
},
},
{
name: "insert_to_1",
i: Items{
{Value: 1},
{Value: 2},
{Value: 3},
},
args: args{
item: &Item{
Value: 0,
},
index: 0,
},
want: Items{
{Value: 0},
{Value: 1},
{Value: 2},
{Value: 3},
},
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
tt.i.insertAt(tt.args.item, tt.args.index)
if !reflect.DeepEqual(tt.i, tt.want) {
t.Errorf("Items should be= %v(len=%d),but %v(lend=%d)", tt.want, len(tt.want), tt.i, len(tt.i))
}
})
}
}
ノードの挿入
ノードの挿入時には、
1. すでにアイテムがあれば置き換える
2. 子ノードがない場合には、アイテムリストに追加する。
3. アイテムリストが閾値を超えた場合は真ん中で分割する。
といった振る舞いが必要になります。
わかりやすさのために、3を実行する関数を実装します。
下記の図のような状態のB-treeに8のアイテムを挿入するとします。
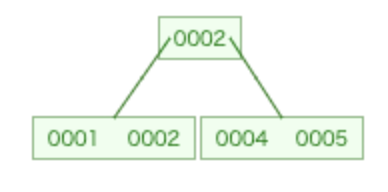
挿入する場所としては右下の[4, 5]のノードになりますが、8を挿入するとアイテムリストが3になるので、事前にこのノードを分割してアイテムを入れるスペースを空ける必要があります。実装としては以下のようになります。
func (n *Node) shouldSplit(i, limit int) bool {
if len(n.Branch[i].Items) <= limit {
return false
}
// limitを超えて分割すべきだった場合、分割してBranchに登録
center, newNode := n.Branch[i].split(limit / 2)
n.Items.insertAt(center, i)
n.Branch.InsertAt(i+1, newNode)
return true
}
func (n *Node) split(index int) (*Item, *Node) {
// ちょうど分割の真ん中にあるItem
item := n.Items[index]
newNode := new(Node)
newNode.Items = append(newNode.Items, n.Items[index+1:]...)
n.Items.extract(index)
if len(n.Branch) > 0 {
newNode.Branch = append(newNode.Branch, n.Branch[index+1:]...)
n.Branch.extract(index + 1)
}
return item, newNode
}
// extract - 指定されたindexまでのItemのみを残す
func (i *Items) extract(index int) {
*i = (*i)[:index]
}
// extract - 指定された子ノードのみを残す
func (b *Branch) extract(index int) {
*b = (*b)[:index]
// index以降を初期化
for i := index; i < len(*b); i++ {
(*b)[i] = nil
}
}
処理が終わったあとのB-treeは以下のようになり、8が入るスペースが空けられます。

これを使ってノードへの挿入処理の関数を書きます。
//insert - nodeにItemを挿入する。limitの数を超えていた場合、新しくNodeを作成する
//Itemがもしあれば、Itemを入れ替え、入れ替えるまえのItemを返却する
func (n *Node) insert(item *Item, limit int) *Item {
i, ok := n.Items.findItem(item)
if ok {
res := n.Items[i]
n.Items[i] = item
return res
}
if len(n.Branch) == 0 {
n.Items.insertAt(item, i)
return nil
}
// 子ノードが閾値を超える場合は、分割し、アイテムリストに追加する
if n.shouldSplit(i, limit) {
inTree := n.Items[i]
switch {
case item.Less(inTree):
// no change, we want first split node
case inTree.Less(item):
i++ // we want second split node
default:
out := n.Items[i]
n.Items[i] = item
return out
}
}
return n.Branch[i].insert(item, limit)
}
基本的に自身のアイテムリストに追加し、追加した後に先ほどのノードの分割処理を必要に応じて行なっています。
子ノードができた後は、自身のアイテムリストの直接追加することはせず、適切な子ノードを探索した後に、その子ノードにたいしてinsert関数を呼び出しています。
ルートノードへの挿入
あとはルートノードへの挿入処理です。
ルートノードで必要な処理は、ノードの初期化処理と、ノードと同じようにルートのアイテムリストが閾値を超えた時の分割処理処理のみです。
みてもらえばわかりますが、初期化処理以外は、ノードの挿入処理と同じ動きをしています。
func (b *Btree) InsertOrUpdateItem(item *Item) (*Item, error) {
if item == nil {
return nil, fmt.Errorf("nil item is unacceptable")
}
// RootのNodeがまだなければ作成
if b.Root == nil {
b.Root = &Node{}
b.Root.Items = append(b.Root.Items, item)
return nil, nil
} else {
// Rootに収まらなくなったら分割する
if len(b.Root.Items) >= b.maxItemNum() {
item2, second := b.Root.split(b.maxItemNum() / 2)
old := b.Root
b.Root = new(Node)
b.Root.Items = append(b.Root.Items, item2)
b.Root.Branch = append(b.Root.Branch, old, second)
}
}
res := b.Root.insert(item, b.maxItemNum())
return res, nil
}
これでB-treeの探索処理と、挿入処理が一通り実装できました。
参考サイト
- b-treeを図でわかりやすく説明している。Javaのサンプルコードも掲載
- B-treeとB+ Treeの違いに関して説明させている。B-treeが理解できていれば、B+ Treeの理解もすんなりできる
- こちらは連載。挿入や検索が図を使って時系列でわかりやすくなっている
