A better zip bomb
David Fifield
david@bamsoftware.com
Summary
This article shows how to construct a non-recursive zip bomb that achieves a high compression ratio by overlapping files inside the zip container. "Non-recursive" means that it does not rely on a decompressor's recursively unpacking zip files nested within zip files: it expands fully after a single round of decompression. The output size increases quadratically in the input size, reaching a compression ratio of over 28 million (10 MB → 281 TB) at the limits of the zip format. Even greater expansion is possible using 64-bit extensions. The construction uses only the most common compression algorithm, DEFLATE, and is compatible with most zip parsers.
- Source code:
-
git clone https://www.bamsoftware.com/git/zipbomb.git
zipbomb-20190822.zip - Data and source for figures:
-
git clone https://www.bamsoftware.com/git/zipbomb-paper.git
中文翻译: 北岸冷若冰霜.
| non-recursive | recursive | ||||
|---|---|---|---|---|---|
| zipped size | unzipped size | ratio | unzipped size | ratio | |
| Cox quine | 440 | 440 | 1.0 | ∞ | ∞ |
| Ellingsen quine | 28 809 | 42 569 | 1.5 | ∞ | ∞ |
| 42.zip | *42 374 | 558 432 | 13.2 | 4 507 981 343 026 016 | 106 billion |
| this technique | 42 374 | 5 461 307 620 | 129 thousand | 5 461 307 620 | 129 thousand |
| this technique | 9 893 525 | 281 395 456 244 934 | 28 million | 281 395 456 244 934 | 28 million |
| this technique (Zip64) | 45 876 952 | 4 507 981 427 706 459 | 98 million | 4 507 981 427 706 459 | 98 million |
Compression bombs that use the zip format must cope with the fact that DEFLATE, the compression algorithm most commonly supported by zip parsers, cannot achieve a compression ratio greater than 1032. For this reason, zip bombs typically rely on recursive decompression, nesting zip files within zip files to get an extra factor of 1032 with each layer. But the trick only works on implementations that unzip recursively, and most do not. The best-known zip bomb, 42.zip, expands to a formidable 4.5 PB if all six of its layers are recursively unzipped, but a trifling 0.6 MB at the top layer. Zip quines, like those of Ellingsen and Cox, which contain a copy of themselves and thus expand infinitely if recursively unzipped, are likewise perfectly safe to unzip once.
This article shows how to construct a non-recursive zip bomb whose compression ratio surpasses the DEFLATE limit of 1032. It works by overlapping files inside the zip container, in order to reference a "kernel" of highly compressed data in multiple files, without making multiple copies of it. The zip bomb's output size grows quadratically in the input size; i.e., the compression ratio gets better as the bomb gets bigger. The construction depends on features of both zip and DEFLATE—it is not directly portable to other file formats or compression algorithms. It is compatible with most zip parsers, the exceptions being "streaming" parsers that parse in one pass without first consulting the zip file's central directory. We try to balance two conflicting goals:
- Maximize the compression ratio. We define the compression ratio as the the sum of the sizes of all the files contained the in the zip file, divided by the size of the zip file itself. It does not count filenames or other filesystem metadata, only contents.
- Be compatible. Zip is a tricky format and parsers differ, especially around edge cases and optional features. Avoid taking advantage of tricks that only work with certain parsers. We will remark on certain ways to increase the efficiency of the zip bomb that come with some loss of compatibility.
Structure of a zip file
A zip file consists of a central directory which references files.
![A block diagram of the structure of a zip file. The central directory header consists of three central directory headers labeled CDH[1] (README), CDH[1] (Makefile), and CDH[3] (demo.c). The central directory headers point backwards to three local file headers LFH[1] (README), LFH[2] (Makefile), and LFH[3] (demo.c). Each local file header is joined with file data. The three joined blocks of (local file header, file data) are labeled file 1, file 2, and file 3.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4KPHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHhtbG5zOnhsaW5rPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rIiB3aWR0aD0iNTA0cHQiIGhlaWdodD0iNjUuMzNwdCIgdmlld0JveD0iMCAwIDUwNCA2NS4zMyIgdmVyc2lvbj0iMS4xIj4KPGRlZnM+CjxnPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS42NzE4NzUgLTIuODEyNSBMIDMuODI4MTI1IC0yLjgxMjUgQyA0LjU2MjUgLTIuODEyNSA0Ljg5MDYyNSAtMi40NTMxMjUgNC44OTA2MjUgLTEuNjU2MjUgTCA0Ljg5MDYyNSAtMS4wNjI1IEMgNC44OTA2MjUgLTAuNjU2MjUgNC45NTMxMjUgLTAuMjY1NjI1IDUuMDc4MTI1IDAgTCA2LjA5Mzc1IDAgTCA2LjA5Mzc1IC0wLjIwMzEyNSBDIDUuNzgxMjUgLTAuNDIxODc1IDUuNzE4NzUgLTAuNjU2MjUgNS42ODc1IC0xLjUzMTI1IEMgNS42ODc1IC0yLjU5Mzc1IDUuNTE1NjI1IC0yLjkyMTg3NSA0LjgxMjUgLTMuMjM0Mzc1IEMgNS41NDY4NzUgLTMuNTkzNzUgNS44NDM3NSAtNC4wNDY4NzUgNS44NDM3NSAtNC43OTY4NzUgQyA1Ljg0Mzc1IC01LjkyMTg3NSA1LjEyNSAtNi41MzEyNSAzLjg0Mzc1IC02LjUzMTI1IEwgMC44MjgxMjUgLTYuNTMxMjUgTCAwLjgyODEyNSAwIEwgMS42NzE4NzUgMCBaIE0gMS42NzE4NzUgLTMuNTQ2ODc1IEwgMS42NzE4NzUgLTUuNzk2ODc1IEwgMy42ODc1IC01Ljc5Njg3NSBDIDQuMTU2MjUgLTUuNzk2ODc1IDQuNDIxODc1IC01LjczNDM3NSA0LjYyNSAtNS41NDY4NzUgQyA0Ljg1OTM3NSAtNS4zNTkzNzUgNC45Njg3NSAtNS4wNjI1IDQuOTY4NzUgLTQuNjcxODc1IEMgNC45Njg3NSAtMy45MDYyNSA0LjU3ODEyNSAtMy41NDY4NzUgMy42ODc1IC0zLjU0Njg3NSBaIE0gMS42NzE4NzUgLTMuNTQ2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0yIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjY0MDYyNSAtMi45ODQzNzUgTCA1LjIwMzEyNSAtMi45ODQzNzUgTCA1LjIwMzEyNSAtMy43MTg3NSBMIDEuNjQwNjI1IC0zLjcxODc1IEwgMS42NDA2MjUgLTUuNzk2ODc1IEwgNS4zNDM3NSAtNS43OTY4NzUgTCA1LjM0Mzc1IC02LjUzMTI1IEwgMC44MTI1IC02LjUzMTI1IEwgMC44MTI1IDAgTCA1LjUgMCBMIDUuNSAtMC43MzQzNzUgTCAxLjY0MDYyNSAtMC43MzQzNzUgWiBNIDEuNjQwNjI1IC0yLjk4NDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtMyI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNC4yNSAtMS45Njg3NSBMIDQuOTIxODc1IDAgTCA1Ljg1OTM3NSAwIEwgMy41NjI1IC02LjUzMTI1IEwgMi40ODQzNzUgLTYuNTMxMjUgTCAwLjE1NjI1IDAgTCAxLjA0Njg3NSAwIEwgMS43MzQzNzUgLTEuOTY4NzUgWiBNIDQuMDE1NjI1IC0yLjY1NjI1IEwgMS45Mzc1IC0yLjY1NjI1IEwgMy4wMTU2MjUgLTUuNjQwNjI1IFogTSA0LjAxNTYyNSAtMi42NTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtNCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC43OTY4NzUgMCBMIDMuMzEyNSAwIEMgNC45Njg3NSAwIDUuOTg0Mzc1IC0xLjIzNDM3NSA1Ljk4NDM3NSAtMy4yODEyNSBDIDUuOTg0Mzc1IC01LjI5Njg3NSA0Ljk4NDM3NSAtNi41MzEyNSAzLjMxMjUgLTYuNTMxMjUgTCAwLjc5Njg3NSAtNi41MzEyNSBaIE0gMS42MjUgLTAuNzM0Mzc1IEwgMS42MjUgLTUuNzk2ODc1IEwgMy4xNzE4NzUgLTUuNzk2ODc1IEMgNC40Njg3NSAtNS43OTY4NzUgNS4xNDA2MjUgLTQuOTM3NSA1LjE0MDYyNSAtMy4yNjU2MjUgQyA1LjE0MDYyNSAtMS42MDkzNzUgNC40Njg3NSAtMC43MzQzNzUgMy4xNzE4NzUgLTAuNzM0Mzc1IFogTSAxLjYyNSAtMC43MzQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuMjAzMTI1IDAgTCA2LjAzMTI1IC01LjQ4NDM3NSBMIDYuMDMxMjUgMCBMIDYuODI4MTI1IDAgTCA2LjgyODEyNSAtNi41MzEyNSBMIDUuNjcxODc1IC02LjUzMTI1IEwgMy43NjU2MjUgLTAuODQzNzUgTCAxLjgyODEyNSAtNi41MzEyNSBMIDAuNjcxODc1IC02LjUzMTI1IEwgMC42NzE4NzUgMCBMIDEuNDY4NzUgMCBMIDEuNDY4NzUgLTUuNDg0Mzc1IEwgMy4zMTI1IDAgWiBNIDQuMjAzMTI1IDAgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTYiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzk2ODc1IC0wLjQzNzUgQyA0LjcxODc1IC0wLjQyMTg3NSA0LjY4NzUgLTAuNDIxODc1IDQuNjQwNjI1IC0wLjQyMTg3NSBDIDQuMzc1IC0wLjQyMTg3NSA0LjIzNDM3NSAtMC41NjI1IDQuMjM0Mzc1IC0wLjc5Njg3NSBMIDQuMjM0Mzc1IC0zLjU0Njg3NSBDIDQuMjM0Mzc1IC00LjM5MDYyNSAzLjYyNSAtNC44MjgxMjUgMi40Njg3NSAtNC44MjgxMjUgQyAxLjc4MTI1IC00LjgyODEyNSAxLjIxODc1IC00LjY0MDYyNSAwLjkwNjI1IC00LjI4MTI1IEMgMC42ODc1IC00LjA0Njg3NSAwLjU5Mzc1IC0zLjc4MTI1IDAuNTc4MTI1IC0zLjMxMjUgTCAxLjM0Mzc1IC0zLjMxMjUgQyAxLjQwNjI1IC0zLjg5MDYyNSAxLjczNDM3NSAtNC4xNDA2MjUgMi40Mzc1IC00LjE0MDYyNSBDIDMuMTA5Mzc1IC00LjE0MDYyNSAzLjQ4NDM3NSAtMy44OTA2MjUgMy40ODQzNzUgLTMuNDM3NSBMIDMuNDg0Mzc1IC0zLjI1IEMgMy40ODQzNzUgLTIuOTM3NSAzLjI5Njg3NSAtMi43OTY4NzUgMi43MDMxMjUgLTIuNzE4NzUgQyAxLjY1NjI1IC0yLjU5Mzc1IDEuNDg0Mzc1IC0yLjU2MjUgMS4yMDMxMjUgLTIuNDM3NSBDIDAuNjU2MjUgLTIuMjE4NzUgMC4zNzUgLTEuNzk2ODc1IDAuMzc1IC0xLjE4NzUgQyAwLjM3NSAtMC4zMjgxMjUgMC45Njg3NSAwLjIwMzEyNSAxLjkyMTg3NSAwLjIwMzEyNSBDIDIuNTE1NjI1IDAuMjAzMTI1IDIuOTg0Mzc1IDAgMy41MTU2MjUgLTAuNDg0Mzc1IEMgMy41NjI1IC0wLjAxNTYyNSAzLjc5Njg3NSAwLjIwMzEyNSA0LjI4MTI1IDAuMjAzMTI1IEMgNC40Mzc1IDAuMjAzMTI1IDQuNTYyNSAwLjE4NzUgNC43OTY4NzUgMC4xMjUgWiBNIDMuNDg0Mzc1IC0xLjQ4NDM3NSBDIDMuNDg0Mzc1IC0xLjIzNDM3NSAzLjQyMTg3NSAtMS4wNzgxMjUgMy4xODc1IC0wLjg3NSBDIDIuODkwNjI1IC0wLjU5Mzc1IDIuNTE1NjI1IC0wLjQ1MzEyNSAyLjA3ODEyNSAtMC40NTMxMjUgQyAxLjUgLTAuNDUzMTI1IDEuMTU2MjUgLTAuNzE4NzUgMS4xNTYyNSAtMS4yMDMxMjUgQyAxLjE1NjI1IC0xLjY4NzUgMS40ODQzNzUgLTEuOTUzMTI1IDIuMjgxMjUgLTIuMDYyNSBDIDMuMDc4MTI1IC0yLjE3MTg3NSAzLjIzNDM3NSAtMi4yMDMxMjUgMy40ODQzNzUgLTIuMzI4MTI1IFogTSAzLjQ4NDM3NSAtMS40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTciPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDEuMjY1NjI1IC02LjUzMTI1IEwgMC41MTU2MjUgLTYuNTMxMjUgTCAwLjUxNTYyNSAwIEwgMS4yNjU2MjUgMCBMIDEuMjY1NjI1IC0xLjgyODEyNSBMIDEuOTg0Mzc1IC0yLjU0Njg3NSBMIDMuNTc4MTI1IDAgTCA0LjUgMCBMIDIuNTc4MTI1IC0zLjA3ODEyNSBMIDQuMjE4NzUgLTQuNzAzMTI1IEwgMy4yNSAtNC43MDMxMjUgTCAxLjI2NTYyNSAtMi43MDMxMjUgWiBNIDEuMjY1NjI1IC02LjUzMTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC04Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0LjU5Mzc1IC0yLjA5Mzc1IEMgNC41OTM3NSAtMi44MTI1IDQuNTQ2ODc1IC0zLjI1IDQuNDA2MjUgLTMuNTkzNzUgQyA0LjEwOTM3NSAtNC4zNzUgMy4zOTA2MjUgLTQuODI4MTI1IDIuNTE1NjI1IC00LjgyODEyNSBDIDEuMjAzMTI1IC00LjgyODEyNSAwLjM1OTM3NSAtMy44MjgxMjUgMC4zNTkzNzUgLTIuMjgxMjUgQyAwLjM1OTM3NSAtMC43NSAxLjE3MTg3NSAwLjIwMzEyNSAyLjUgMC4yMDMxMjUgQyAzLjU2MjUgMC4yMDMxMjUgNC4zMTI1IC0wLjQwNjI1IDQuNSAtMS40MjE4NzUgTCAzLjc1IC0xLjQyMTg3NSBDIDMuNTQ2ODc1IC0wLjgxMjUgMy4xMjUgLTAuNDg0Mzc1IDIuNTE1NjI1IC0wLjQ4NDM3NSBDIDIuMDQ2ODc1IC0wLjQ4NDM3NSAxLjY0MDYyNSAtMC43MDMxMjUgMS4zOTA2MjUgLTEuMDkzNzUgQyAxLjIwMzEyNSAtMS4zNTkzNzUgMS4xNDA2MjUgLTEuNjI1IDEuMTQwNjI1IC0yLjA5Mzc1IFogTSAxLjE1NjI1IC0yLjcwMzEyNSBDIDEuMjE4NzUgLTMuNTc4MTI1IDEuNzUgLTQuMTQwNjI1IDIuNSAtNC4xNDA2MjUgQyAzLjIzNDM3NSAtNC4xNDA2MjUgMy43OTY4NzUgLTMuNTMxMjUgMy43OTY4NzUgLTIuNzY1NjI1IEMgMy43OTY4NzUgLTIuNzUgMy43OTY4NzUgLTIuNzE4NzUgMy43OTY4NzUgLTIuNzAzMTI1IFogTSAxLjE1NjI1IC0yLjcwMzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtOSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMi4yNjU2MjUgLTQuNzAzMTI1IEwgMS40ODQzNzUgLTQuNzAzMTI1IEwgMS40ODQzNzUgLTUuNDM3NSBDIDEuNDg0Mzc1IC01Ljc1IDEuNjU2MjUgLTUuOTA2MjUgMiAtNS45MDYyNSBDIDIuMDYyNSAtNS45MDYyNSAyLjA5Mzc1IC01LjkwNjI1IDIuMjY1NjI1IC01LjkwNjI1IEwgMi4yNjU2MjUgLTYuNTE1NjI1IEMgMi4wOTM3NSAtNi41NjI1IDEuOTg0Mzc1IC02LjU2MjUgMS44NDM3NSAtNi41NjI1IEMgMS4xNDA2MjUgLTYuNTYyNSAwLjczNDM3NSAtNi4xNzE4NzUgMC43MzQzNzUgLTUuNSBMIDAuNzM0Mzc1IC00LjcwMzEyNSBMIDAuMTA5Mzc1IC00LjcwMzEyNSBMIDAuMTA5Mzc1IC00LjA5Mzc1IEwgMC43MzQzNzUgLTQuMDkzNzUgTCAwLjczNDM3NSAwIEwgMS40ODQzNzUgMCBMIDEuNDg0Mzc1IC00LjA5Mzc1IEwgMi4yNjU2MjUgLTQuMDkzNzUgWiBNIDMuOTA2MjUgLTQuNzAzMTI1IEwgMy4xNzE4NzUgLTQuNzAzMTI1IEwgMy4xNzE4NzUgMCBMIDMuOTA2MjUgMCBaIE0gMy45MDYyNSAtNi41MzEyNSBMIDMuMTcxODc1IC02LjUzMTI1IEwgMy4xNzE4NzUgLTUuNTkzNzUgTCAzLjkwNjI1IC01LjU5Mzc1IFogTSAzLjkwNjI1IC02LjUzMTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0xMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS4zNTkzNzUgLTYuNTMxMjUgTCAwLjYwOTM3NSAtNi41MzEyNSBMIDAuNjA5Mzc1IDAgTCAxLjM1OTM3NSAwIFogTSAxLjM1OTM3NSAtNi41MzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtMTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNDM3NSAtNi41MzEyNSBMIDMuNjg3NSAtNi41MzEyNSBMIDMuNjg3NSAtNC4xMDkzNzUgQyAzLjM3NSAtNC41NzgxMjUgMi44NzUgLTQuODI4MTI1IDIuMjUgLTQuODI4MTI1IEMgMS4wMzEyNSAtNC44MjgxMjUgMC4yMzQzNzUgLTMuODU5Mzc1IDAuMjM0Mzc1IC0yLjM1OTM3NSBDIDAuMjM0Mzc1IC0wLjc2NTYyNSAxLjAxNTYyNSAwLjIwMzEyNSAyLjI4MTI1IDAuMjAzMTI1IEMgMi45MjE4NzUgMC4yMDMxMjUgMy4zNzUgLTAuMDMxMjUgMy43ODEyNSAtMC42MjUgTCAzLjc4MTI1IDAgTCA0LjQzNzUgMCBaIE0gMi4zNzUgLTQuMTQwNjI1IEMgMy4xODc1IC00LjE0MDYyNSAzLjY4NzUgLTMuNDIxODc1IDMuNjg3NSAtMi4yOTY4NzUgQyAzLjY4NzUgLTEuMjAzMTI1IDMuMTcxODc1IC0wLjUgMi4zOTA2MjUgLTAuNSBDIDEuNTYyNSAtMC41IDEuMDE1NjI1IC0xLjIxODc1IDEuMDE1NjI1IC0yLjMxMjUgQyAxLjAxNTYyNSAtMy40MDYyNSAxLjU2MjUgLTQuMTQwNjI1IDIuMzc1IC00LjE0MDYyNSBaIE0gMi4zNzUgLTQuMTQwNjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0xMiI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC42MjUgLTQuNzAzMTI1IEwgMC42MjUgMCBMIDEuMzc1IDAgTCAxLjM3NSAtMi45NTMxMjUgQyAxLjM3NSAtMy42MjUgMS44NzUgLTQuMTcxODc1IDIuNDg0Mzc1IC00LjE3MTg3NSBDIDMuMDQ2ODc1IC00LjE3MTg3NSAzLjM1OTM3NSAtMy44NDM3NSAzLjM1OTM3NSAtMy4yMzQzNzUgTCAzLjM1OTM3NSAwIEwgNC4xMDkzNzUgMCBMIDQuMTA5Mzc1IC0yLjk1MzEyNSBDIDQuMTA5Mzc1IC0zLjYyNSA0LjU5Mzc1IC00LjE3MTg3NSA1LjIwMzEyNSAtNC4xNzE4NzUgQyA1Ljc2NTYyNSAtNC4xNzE4NzUgNi4wNzgxMjUgLTMuODI4MTI1IDYuMDc4MTI1IC0zLjIzNDM3NSBMIDYuMDc4MTI1IDAgTCA2LjgyODEyNSAwIEwgNi44MjgxMjUgLTMuNTMxMjUgQyA2LjgyODEyNSAtNC4zNzUgNi4zNDM3NSAtNC44MjgxMjUgNS40Njg3NSAtNC44MjgxMjUgQyA0Ljg0Mzc1IC00LjgyODEyNSA0LjQ2ODc1IC00LjY0MDYyNSA0LjAzMTI1IC00LjEwOTM3NSBDIDMuNzUgLTQuNjI1IDMuMzc1IC00LjgyODEyNSAyLjc2NTYyNSAtNC44MjgxMjUgQyAyLjE0MDYyNSAtNC44MjgxMjUgMS43MTg3NSAtNC41OTM3NSAxLjMxMjUgLTQuMDMxMjUgTCAxLjMxMjUgLTQuNzAzMTI1IFogTSAwLjYyNSAtNC43MDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTEzIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAyLjQzNzUgLTQuODI4MTI1IEMgMS4xMjUgLTQuODI4MTI1IDAuMzI4MTI1IC0zLjg5MDYyNSAwLjMyODEyNSAtMi4zMTI1IEMgMC4zMjgxMjUgLTAuNzM0Mzc1IDEuMTA5Mzc1IDAuMjAzMTI1IDIuNDUzMTI1IDAuMjAzMTI1IEMgMy43NjU2MjUgMC4yMDMxMjUgNC41NzgxMjUgLTAuNzM0Mzc1IDQuNTc4MTI1IC0yLjI4MTI1IEMgNC41NzgxMjUgLTMuOTA2MjUgMy43OTY4NzUgLTQuODI4MTI1IDIuNDM3NSAtNC44MjgxMjUgWiBNIDIuNDUzMTI1IC00LjE0MDYyNSBDIDMuMjk2ODc1IC00LjE0MDYyNSAzLjc5Njg3NSAtMy40NTMxMjUgMy43OTY4NzUgLTIuMjgxMjUgQyAzLjc5Njg3NSAtMS4xODc1IDMuMjgxMjUgLTAuNDg0Mzc1IDIuNDUzMTI1IC0wLjQ4NDM3NSBDIDEuNjA5Mzc1IC0wLjQ4NDM3NSAxLjEwOTM3NSAtMS4xNzE4NzUgMS4xMDkzNzUgLTIuMzEyNSBDIDEuMTA5Mzc1IC0zLjQzNzUgMS42MDkzNzUgLTQuMTQwNjI1IDIuNDUzMTI1IC00LjE0MDYyNSBaIE0gMi40NTMxMjUgLTQuMTQwNjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0xNCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS43MTg3NSAtMC45Mzc1IEwgMC43ODEyNSAtMC45Mzc1IEwgMC43ODEyNSAwIEwgMS43MTg3NSAwIFogTSAxLjcxODc1IC0wLjkzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgwLTE1Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0LjIxODc1IC0zLjEyNSBDIDQuMTg3NSAtMy41NzgxMjUgNC4wOTM3NSAtMy44NzUgMy45MDYyNSAtNC4xNDA2MjUgQyAzLjU5Mzc1IC00LjU3ODEyNSAzLjAxNTYyNSAtNC44MjgxMjUgMi4zNzUgLTQuODI4MTI1IEMgMS4xMDkzNzUgLTQuODI4MTI1IDAuMjgxMjUgLTMuODI4MTI1IDAuMjgxMjUgLTIuMjY1NjI1IEMgMC4yODEyNSAtMC43NSAxLjA3ODEyNSAwLjIwMzEyNSAyLjM1OTM3NSAwLjIwMzEyNSBDIDMuNDg0Mzc1IDAuMjAzMTI1IDQuMTg3NSAtMC40Njg3NSA0LjI4MTI1IC0xLjYwOTM3NSBMIDMuNTMxMjUgLTEuNjA5Mzc1IEMgMy40MDYyNSAtMC44NTkzNzUgMy4wMTU2MjUgLTAuNDg0Mzc1IDIuMzc1IC0wLjQ4NDM3NSBDIDEuNTQ2ODc1IC0wLjQ4NDM3NSAxLjA2MjUgLTEuMTU2MjUgMS4wNjI1IC0yLjI2NTYyNSBDIDEuMDYyNSAtMy40Mzc1IDEuNTQ2ODc1IC00LjE0MDYyNSAyLjM1OTM3NSAtNC4xNDA2MjUgQyAyLjk4NDM3NSAtNC4xNDA2MjUgMy4zNzUgLTMuNzgxMjUgMy40Njg3NSAtMy4xMjUgWiBNIDQuMjE4NzUgLTMuMTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDUuNzE4NzUgLTEuNzM0Mzc1IEMgNS41NDY4NzUgLTEuMzU5Mzc1IDUuNDA2MjUgLTEuMTI1IDUuMjUgLTAuOTUzMTI1IEMgNC45MDYyNSAtMC41NjI1IDQuMzU5Mzc1IC0wLjM5MDYyNSAzLjUzMTI1IC0wLjM5MDYyNSBMIDIuODU5Mzc1IC0wLjM5MDYyNSBDIDIuMTQwNjI1IC0wLjM5MDYyNSAyIC0wLjQ1MzEyNSAyIC0wLjc5Njg3NSBMIDIgLTUuNTE1NjI1IEMgMiAtNi4yMTg3NSAyLjE0MDYyNSAtNi4zNTkzNzUgMi45Mzc1IC02LjQwNjI1IEwgMi45Mzc1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4wOTM3NSBDIDAuOTg0Mzc1IC0wLjM5MDYyNSAwLjg0Mzc1IC0wLjIzNDM3NSAwLjEyNSAtMC4xODc1IEwgMC4xMjUgMCBMIDUuNDg0Mzc1IDAgTCA1Ljk2ODc1IC0xLjczNDM3NSBaIE0gNS43MTg3NSAtMS43MzQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzgxMjUgLTIuMjk2ODc1IEwgNC43ODEyNSAtNC42MDkzNzUgTCA0LjU0Njg3NSAtNC42MDkzNzUgQyA0LjQyMTg3NSAtMy44MTI1IDQuMjUgLTMuNjcxODc1IDMuNDUzMTI1IC0zLjY3MTg3NSBMIDIgLTMuNjcxODc1IEwgMiAtNS44NzUgQyAyIC02LjE1NjI1IDIuMDQ2ODc1IC02LjIxODc1IDIuMzI4MTI1IC02LjIxODc1IEwgMy42NzE4NzUgLTYuMjE4NzUgQyA0LjgxMjUgLTYuMjE4NzUgNS4wMzEyNSAtNi4wNzgxMjUgNS4xODc1IC01LjE3MTg3NSBMIDUuNDM3NSAtNS4xNzE4NzUgTCA1LjQwNjI1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4yMDMxMjUgQyAwLjk4NDM3NSAtMC4zNzUgMC44NzUgLTAuMjM0Mzc1IDAuMTI1IC0wLjE4NzUgTCAwLjEyNSAwIEwgMi45MDYyNSAwIEwgMi45MDYyNSAtMC4xODc1IEMgMi4xNDA2MjUgLTAuMjM0Mzc1IDIgLTAuMzc1IDIgLTEuMDkzNzUgTCAyIC0zLjI2NTYyNSBMIDMuNDUzMTI1IC0zLjI2NTYyNSBDIDQuMjUgLTMuMjY1NjI1IDQuNDIxODc1IC0zLjEwOTM3NSA0LjU0Njg3NSAtMi4yOTY4NzUgWiBNIDQuNzgxMjUgLTIuMjk2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0zIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAyLjA3ODEyNSAtMy41NzgxMjUgTCAyLjA3ODEyNSAtNS41MTU2MjUgQyAyLjA3ODEyNSAtNi4yMzQzNzUgMi4xODc1IC02LjM0Mzc1IDIuOTUzMTI1IC02LjQwNjI1IEwgMi45NTMxMjUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjA2MjUgLTYuMjM0Mzc1IDEuMDYyNSAtNS41MTU2MjUgTCAxLjA2MjUgLTEuMjAzMTI1IEMgMS4wNjI1IC0wLjM1OTM3NSAwLjk2ODc1IC0wLjIzNDM3NSAwLjE4NzUgLTAuMTg3NSBMIDAuMTg3NSAwIEwgMi45NTMxMjUgMCBMIDIuOTUzMTI1IC0wLjE4NzUgQyAyLjIxODc1IC0wLjI1IDIuMDc4MTI1IC0wLjM3NSAyLjA3ODEyNSAtMS4wOTM3NSBMIDIuMDc4MTI1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0xLjIwMzEyNSBDIDUuMTA5Mzc1IC0wLjM1OTM3NSA1IC0wLjIzNDM3NSA0LjIzNDM3NSAtMC4xODc1IEwgNC4yMzQzNzUgMCBMIDcgMCBMIDcgLTAuMTg3NSBDIDYuMjUgLTAuMjUgNi4xMjUgLTAuMzc1IDYuMTI1IC0xLjA5Mzc1IEwgNi4xMjUgLTUuNTE1NjI1IEMgNi4xMjUgLTYuMjM0Mzc1IDYuMjM0Mzc1IC02LjM0Mzc1IDcgLTYuNDA2MjUgTCA3IC02LjU5Mzc1IEwgNC4yMzQzNzUgLTYuNTkzNzUgTCA0LjIzNDM3NSAtNi40MDYyNSBDIDUgLTYuMzQzNzUgNS4xMDkzNzUgLTYuMjM0Mzc1IDUuMTA5Mzc1IC01LjUxNTYyNSBMIDUuMTA5Mzc1IC0zLjU3ODEyNSBaIE0gMi4wNzgxMjUgLTMuNTc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS00Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjMxMjUgLTQuMTU2MjUgTCAwLjk4NDM3NSAtNC4xNTYyNSBMIDAuOTg0Mzc1IC0wLjkzNzUgQyAwLjk4NDM3NSAtMC4yOTY4NzUgMC44NzUgLTAuMTcxODc1IDAuMzEyNSAtMC4xNTYyNSBMIDAuMzEyNSAwIEwgMi41MTU2MjUgMCBMIDIuNTE1NjI1IC0wLjE1NjI1IEMgMS45NTMxMjUgLTAuMTg3NSAxLjgyODEyNSAtMC4zMjgxMjUgMS44MjgxMjUgLTAuODc1IEwgMS44MjgxMjUgLTQuMTU2MjUgTCAyLjY4NzUgLTQuMTU2MjUgQyAzLjY0MDYyNSAtNC4xNTYyNSAzLjY4NzUgLTQuMTI1IDMuNjg3NSAtMy41OTM3NSBMIDMuNjg3NSAtMC45Njg3NSBDIDMuNjg3NSAtMC4yOTY4NzUgMy42MjUgLTAuMjAzMTI1IDMgLTAuMTU2MjUgTCAzIDAgTCA1LjE4NzUgMCBMIDUuMTg3NSAtMC4xNTYyNSBDIDQuNjQwNjI1IC0wLjIwMzEyNSA0LjUzMTI1IC0wLjMyODEyNSA0LjUzMTI1IC0wLjk2ODc1IEwgNC41MzEyNSAtMy41NzgxMjUgQyA0LjUzMTI1IC0zLjc5Njg3NSA0LjUzMTI1IC00LjAzMTI1IDQuNTQ2ODc1IC00LjU2MjUgTCA0LjUgLTQuNTc4MTI1IEMgNC4wNjI1IC00LjUxNTYyNSAzLjc4MTI1IC00LjQ4NDM3NSAzLjM3NSAtNC40ODQzNzUgTCAxLjgxMjUgLTQuNDg0Mzc1IEwgMS44MTI1IC00LjkyMTg3NSBDIDEuODEyNSAtNS4zNTkzNzUgMS44NDM3NSAtNS42NTYyNSAxLjg5MDYyNSAtNS44MjgxMjUgQyAyLjAzMTI1IC02LjI2NTYyNSAyLjQyMTg3NSAtNi41NjI1IDIuODc1IC02LjU2MjUgQyAzLjE1NjI1IC02LjU2MjUgMy4zNDM3NSAtNi40Mzc1IDMuNTc4MTI1IC02LjA5Mzc1IEMgMy43NjU2MjUgLTUuODI4MTI1IDMuODkwNjI1IC01LjcxODc1IDQuMDYyNSAtNS43MTg3NSBDIDQuMjgxMjUgLTUuNzE4NzUgNC40MjE4NzUgLTUuODkwNjI1IDQuNDIxODc1IC02LjEwOTM3NSBDIDQuNDIxODc1IC02LjUzMTI1IDMuOTIxODc1IC02LjgxMjUgMy4xNTYyNSAtNi44MTI1IEMgMi40MDYyNSAtNi44MTI1IDEuODI4MTI1IC02LjU0Njg3NSAxLjQ2ODc1IC02LjA2MjUgQyAxLjE3MTg3NSAtNS42NTYyNSAxLjA2MjUgLTUuMjgxMjUgMSAtNC40ODQzNzUgTCAwLjMxMjUgLTQuNDg0Mzc1IFogTSAwLjMxMjUgLTQuMTU2MjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDAuMTg3NSAtNi4yMDMxMjUgTCAwLjI1IC02LjIwMzEyNSBDIDAuMzU5Mzc1IC02LjIxODc1IDAuNDg0Mzc1IC02LjIzNDM3NSAwLjU2MjUgLTYuMjM0Mzc1IEMgMC44NzUgLTYuMjM0Mzc1IDAuOTg0Mzc1IC02LjA5Mzc1IDAuOTg0Mzc1IC01LjYyNSBMIDAuOTg0Mzc1IC0wLjg3NSBDIDAuOTg0Mzc1IC0wLjMyODEyNSAwLjg0Mzc1IC0wLjIwMzEyNSAwLjIwMzEyNSAtMC4xNTYyNSBMIDAuMjAzMTI1IDAgTCAyLjU2MjUgMCBMIDIuNTYyNSAtMC4xNTYyNSBDIDEuOTM3NSAtMC4xODc1IDEuODEyNSAtMC4yOTY4NzUgMS44MTI1IC0wLjg0Mzc1IEwgMS44MTI1IC02Ljc4MTI1IEwgMS43ODEyNSAtNi44MTI1IEMgMS4yNSAtNi42NDA2MjUgMC44NzUgLTYuNTQ2ODc1IDAuMTg3NSAtNi4zNzUgWiBNIDAuMTg3NSAtNi4yMDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTYiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuMDYyNSAtMS42NDA2MjUgQyAzLjU5Mzc1IC0wLjg3NSAzLjE1NjI1IC0wLjU5Mzc1IDIuNTE1NjI1IC0wLjU5Mzc1IEMgMS45NTMxMjUgLTAuNTkzNzUgMS41MzEyNSAtMC44NzUgMS4yMzQzNzUgLTEuNDUzMTI1IEMgMS4wNjI1IC0xLjgyODEyNSAwLjk4NDM3NSAtMi4xNTYyNSAwLjk2ODc1IC0yLjc2NTYyNSBMIDQuMDMxMjUgLTIuNzY1NjI1IEMgMy45NTMxMjUgLTMuNDA2MjUgMy44NTkzNzUgLTMuNzAzMTI1IDMuNjA5Mzc1IC00LjAxNTYyNSBDIDMuMzEyNSAtNC4zNzUgMi44NDM3NSAtNC41NzgxMjUgMi4zMjgxMjUgLTQuNTc4MTI1IEMgMS44MjgxMjUgLTQuNTc4MTI1IDEuMzU5Mzc1IC00LjQwNjI1IDAuOTg0Mzc1IC00LjA2MjUgQyAwLjUxNTYyNSAtMy42NTYyNSAwLjI1IC0yLjk1MzEyNSAwLjI1IC0yLjE0MDYyNSBDIDAuMjUgLTAuNzUgMC45Njg3NSAwLjA5Mzc1IDIuMTA5Mzc1IDAuMDkzNzUgQyAzLjA2MjUgMC4wOTM3NSAzLjgxMjUgLTAuNDg0Mzc1IDQuMjM0Mzc1IC0xLjU2MjUgWiBNIDAuOTg0Mzc1IC0zLjA3ODEyNSBDIDEuMDkzNzUgLTMuODU5Mzc1IDEuNDM3NSAtNC4yMzQzNzUgMi4wNDY4NzUgLTQuMjM0Mzc1IEMgMi42NTYyNSAtNC4yMzQzNzUgMi44OTA2MjUgLTMuOTUzMTI1IDMuMDE1NjI1IC0zLjA3ODEyNSBaIE0gMC45ODQzNzUgLTMuMDc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS03Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjQyMTg3NSAwLjA5Mzc1IEwgNC44OTA2MjUgLTAuNDIxODc1IEwgNC44OTA2MjUgLTAuNTc4MTI1IEMgNC43MTg3NSAtMC41NjI1IDQuNjg3NSAtMC41NjI1IDQuNjcxODc1IC0wLjU2MjUgQyA0LjMxMjUgLTAuNTYyNSA0LjIzNDM3NSAtMC42NzE4NzUgNC4yMzQzNzUgLTEuMTQwNjI1IEwgNC4yMzQzNzUgLTYuNzgxMjUgTCA0LjE3MTg3NSAtNi44MTI1IEMgMy43MDMxMjUgLTYuNjQwNjI1IDMuMzQzNzUgLTYuNTQ2ODc1IDIuNzE4NzUgLTYuMzc1IEwgMi43MTg3NSAtNi4yMDMxMjUgQyAyLjc5Njg3NSAtNi4yMTg3NSAyLjg0Mzc1IC02LjIxODc1IDIuOTM3NSAtNi4yMTg3NSBDIDMuMjk2ODc1IC02LjIxODc1IDMuMzkwNjI1IC02LjEyNSAzLjM5MDYyNSAtNS43MTg3NSBMIDMuMzkwNjI1IC00LjE1NjI1IEMgMy4wMTU2MjUgLTQuNDY4NzUgMi43MzQzNzUgLTQuNTc4MTI1IDIuMzQzNzUgLTQuNTc4MTI1IEMgMS4yMDMxMjUgLTQuNTc4MTI1IDAuMjY1NjI1IC0zLjQ1MzEyNSAwLjI2NTYyNSAtMi4wNDY4NzUgQyAwLjI2NTYyNSAtMC43NjU2MjUgMS4wMTU2MjUgMC4wOTM3NSAyLjEwOTM3NSAwLjA5Mzc1IEMgMi42NzE4NzUgMC4wOTM3NSAzLjA0Njg3NSAtMC4wOTM3NSAzLjM5MDYyNSAtMC41NjI1IEwgMy4zOTA2MjUgMC4wNjI1IFogTSAzLjM5MDYyNSAtMS4wMTU2MjUgQyAzLjM5MDYyNSAtMC45NTMxMjUgMy4zMTI1IC0wLjgyODEyNSAzLjIxODc1IC0wLjcxODc1IEMgMy4wNDY4NzUgLTAuNTE1NjI1IDIuNzk2ODc1IC0wLjQyMTg3NSAyLjUgLTAuNDIxODc1IEMgMS42NzE4NzUgLTAuNDIxODc1IDEuMTI1IC0xLjIxODc1IDEuMTI1IC0yLjQzNzUgQyAxLjEyNSAtMy41NjI1IDEuNjA5Mzc1IC00LjMxMjUgMi4zNzUgLTQuMzEyNSBDIDIuOTA2MjUgLTQuMzEyNSAzLjM5MDYyNSAtMy44NDM3NSAzLjM5MDYyNSAtMy4zMTI1IFogTSAzLjM5MDYyNSAtMS4wMTU2MjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTgiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNDA2MjUgLTAuNjU2MjUgQyA0LjIzNDM3NSAtMC41MTU2MjUgNC4xMDkzNzUgLTAuNDY4NzUgMy45Njg3NSAtMC40Njg3NSBDIDMuNzM0Mzc1IC0wLjQ2ODc1IDMuNjcxODc1IC0wLjYwOTM3NSAzLjY3MTg3NSAtMS4wNDY4NzUgTCAzLjY3MTg3NSAtMi45ODQzNzUgQyAzLjY3MTg3NSAtMy41MTU2MjUgMy42MjUgLTMuNzk2ODc1IDMuNDY4NzUgLTQuMDMxMjUgQyAzLjI1IC00LjM5MDYyNSAyLjgyODEyNSAtNC41NzgxMjUgMi4yMzQzNzUgLTQuNTc4MTI1IEMgMS4yOTY4NzUgLTQuNTc4MTI1IDAuNTYyNSAtNC4wOTM3NSAwLjU2MjUgLTMuNDY4NzUgQyAwLjU2MjUgLTMuMjM0Mzc1IDAuNzUgLTMuMDQ2ODc1IDAuOTg0Mzc1IC0zLjA0Njg3NSBDIDEuMjE4NzUgLTMuMDQ2ODc1IDEuNDM3NSAtMy4yMzQzNzUgMS40Mzc1IC0zLjQ1MzEyNSBDIDEuNDM3NSAtMy41IDEuNDIxODc1IC0zLjU0Njg3NSAxLjQyMTg3NSAtMy42MjUgQyAxLjM5MDYyNSAtMy43MDMxMjUgMS4zOTA2MjUgLTMuNzgxMjUgMS4zOTA2MjUgLTMuODU5Mzc1IEMgMS4zOTA2MjUgLTQuMTI1IDEuNzAzMTI1IC00LjM0Mzc1IDIuMTA5Mzc1IC00LjM0Mzc1IEMgMi41OTM3NSAtNC4zNDM3NSAyLjg1OTM3NSAtNC4wNjI1IDIuODU5Mzc1IC0zLjUxNTYyNSBMIDIuODU5Mzc1IC0yLjkwNjI1IEMgMS4zMjgxMjUgLTIuMjk2ODc1IDEuMTU2MjUgLTIuMjE4NzUgMC43MzQzNzUgLTEuODI4MTI1IEMgMC41MTU2MjUgLTEuNjQwNjI1IDAuMzc1IC0xLjI5Njg3NSAwLjM3NSAtMC45Njg3NSBDIDAuMzc1IC0wLjM0Mzc1IDAuODEyNSAwLjA5Mzc1IDEuNDIxODc1IDAuMDkzNzUgQyAxLjg1OTM3NSAwLjA5Mzc1IDIuMjY1NjI1IC0wLjEwOTM3NSAyLjg3NSAtMC42MjUgQyAyLjkyMTg3NSAtMC4xMDkzNzUgMy4wOTM3NSAwLjA5Mzc1IDMuNTE1NjI1IDAuMDkzNzUgQyAzLjg0Mzc1IDAuMDkzNzUgNC4wNjI1IC0wLjAxNTYyNSA0LjQwNjI1IC0wLjQwNjI1IFogTSAyLjg1OTM3NSAtMS4yMTg3NSBDIDIuODU5Mzc1IC0wLjkyMTg3NSAyLjgxMjUgLTAuODI4MTI1IDIuNjA5Mzc1IC0wLjcwMzEyNSBDIDIuMzU5Mzc1IC0wLjU2MjUgMi4wNzgxMjUgLTAuNDg0Mzc1IDEuODc1IC0wLjQ4NDM3NSBDIDEuNTMxMjUgLTAuNDg0Mzc1IDEuMjUgLTAuODEyNSAxLjI1IC0xLjI1IEwgMS4yNSAtMS4yODEyNSBDIDEuMjUgLTEuODc1IDEuNjU2MjUgLTIuMjM0Mzc1IDIuODU5Mzc1IC0yLjY3MTg3NSBaIE0gMi44NTkzNzUgLTEuMjE4NzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTkiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuNTQ2ODc1IC00LjQ4NDM3NSBMIDEuNTMxMjUgLTQuNDg0Mzc1IEwgMS41MzEyNSAtNS42NDA2MjUgQyAxLjUzMTI1IC01LjczNDM3NSAxLjUzMTI1IC01Ljc2NTYyNSAxLjQ2ODc1IC01Ljc2NTYyNSBDIDEuMzkwNjI1IC01LjY4NzUgMS4zMjgxMjUgLTUuNTkzNzUgMS4yNjU2MjUgLTUuNSBDIDAuODkwNjI1IC00LjkzNzUgMC40NTMxMjUgLTQuNDY4NzUgMC4yOTY4NzUgLTQuNDIxODc1IEMgMC4xODc1IC00LjM1OTM3NSAwLjEyNSAtNC4yODEyNSAwLjEyNSAtNC4yMzQzNzUgQyAwLjEyNSAtNC4yMDMxMjUgMC4xNDA2MjUgLTQuMTg3NSAwLjE3MTg3NSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtMS4xNzE4NzUgQyAwLjcwMzEyNSAtMC4zMjgxMjUgMSAwLjA5Mzc1IDEuNTc4MTI1IDAuMDkzNzUgQyAyLjA3ODEyNSAwLjA5Mzc1IDIuNDUzMTI1IC0wLjE0MDYyNSAyLjc4MTI1IC0wLjY1NjI1IEwgMi42NTYyNSAtMC43NjU2MjUgQyAyLjQzNzUgLTAuNTE1NjI1IDIuMjY1NjI1IC0wLjQyMTg3NSAyLjA0Njg3NSAtMC40MjE4NzUgQyAxLjY4NzUgLTAuNDIxODc1IDEuNTMxMjUgLTAuNjg3NSAxLjUzMTI1IC0xLjMxMjUgTCAxLjUzMTI1IC00LjE3MTg3NSBMIDIuNTQ2ODc1IC00LjE3MTg3NSBaIE0gMi41NDY4NzUgLTQuNDg0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0xMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNi4xODc1IC00LjQ4NDM3NSBMIDYuMDkzNzUgLTYuNzM0Mzc1IEwgNS44NzUgLTYuNzM0Mzc1IEMgNS44MjgxMjUgLTYuNTMxMjUgNS42NTYyNSAtNi40MDYyNSA1LjQ2ODc1IC02LjQwNjI1IEMgNS4zNzUgLTYuNDA2MjUgNS4yMTg3NSAtNi40Mzc1IDUuMDc4MTI1IC02LjUgQyA0LjU3ODEyNSAtNi42NTYyNSA0LjA5Mzc1IC02LjczNDM3NSAzLjYyNSAtNi43MzQzNzUgQyAyLjc5Njg3NSAtNi43MzQzNzUgMS45Njg3NSAtNi40Mzc1IDEuMzU5Mzc1IC01Ljg3NSBDIDAuNjU2MjUgLTUuMjY1NjI1IDAuMjgxMjUgLTQuMzQzNzUgMC4yODEyNSAtMy4yMzQzNzUgQyAwLjI4MTI1IC0yLjMxMjUgMC41NzgxMjUgLTEuNDUzMTI1IDEuMDkzNzUgLTAuODkwNjI1IEMgMS42ODc1IC0wLjIzNDM3NSAyLjYwOTM3NSAwLjE0MDYyNSAzLjU5Mzc1IDAuMTQwNjI1IEMgNC43MTg3NSAwLjE0MDYyNSA1LjcwMzEyNSAtMC4zMTI1IDYuMzEyNSAtMS4xMjUgTCA2LjEyNSAtMS4zMTI1IEMgNS4zOTA2MjUgLTAuNTkzNzUgNC43MzQzNzUgLTAuMjk2ODc1IDMuOTA2MjUgLTAuMjk2ODc1IEMgMy4yODEyNSAtMC4yOTY4NzUgMi43MTg3NSAtMC41IDIuMjk2ODc1IC0wLjg3NSBDIDEuNzUgLTEuMzU5Mzc1IDEuNDM3NSAtMi4yNjU2MjUgMS40Mzc1IC0zLjM3NSBDIDEuNDM3NSAtNS4xNzE4NzUgMi4zNTkzNzUgLTYuMzQzNzUgMy44MTI1IC02LjM0Mzc1IEMgNC4zNzUgLTYuMzQzNzUgNC44OTA2MjUgLTYuMTI1IDUuMjk2ODc1IC01LjczNDM3NSBDIDUuNjA5Mzc1IC01LjQwNjI1IDUuNzY1NjI1IC01LjE0MDYyNSA1Ljk1MzEyNSAtNC40ODQzNzUgWiBNIDYuMTg3NSAtNC40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTExIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjAzMTI1IC0xLjA5Mzc1IEMgMS4wMzEyNSAtMC4zNzUgMC45MjE4NzUgLTAuMjM0Mzc1IDAuMTU2MjUgLTAuMTg3NSBMIDAuMTU2MjUgMCBMIDIuOTg0Mzc1IDAgQyA0LjE0MDYyNSAwIDUuMTg3NSAtMC4zMjgxMjUgNS44MTI1IC0wLjg5MDYyNSBDIDYuNDUzMTI1IC0xLjQ2ODc1IDYuODI4MTI1IC0yLjM1OTM3NSA2LjgyODEyNSAtMy4zMjgxMjUgQyA2LjgyODEyNSAtNC4yMzQzNzUgNi41MzEyNSAtNSA1Ljk4NDM3NSAtNS41NDY4NzUgQyA1LjI5Njg3NSAtNi4yMzQzNzUgNC4yMTg3NSAtNi41OTM3NSAyLjg0Mzc1IC02LjU5Mzc1IEwgMC4xNTYyNSAtNi41OTM3NSBMIDAuMTU2MjUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjAzMTI1IC02LjI1IDEuMDMxMjUgLTUuNTE1NjI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSBDIDIuMDQ2ODc1IC02LjE1NjI1IDIuMTU2MjUgLTYuMjM0Mzc1IDIuNTc4MTI1IC02LjIzNDM3NSBDIDMuNDIxODc1IC02LjIzNDM3NSA0LjA3ODEyNSAtNi4wNzgxMjUgNC41NjI1IC01LjczNDM3NSBDIDUuMzI4MTI1IC01LjE4NzUgNS43MzQzNzUgLTQuMzQzNzUgNS43MzQzNzUgLTMuMjY1NjI1IEMgNS43MzQzNzUgLTIuMDc4MTI1IDUuMzI4MTI1IC0xLjI1IDQuNTMxMjUgLTAuNzgxMjUgQyA0LjAxNTYyNSAtMC40ODQzNzUgMy40Mzc1IC0wLjM3NSAyLjU3ODEyNSAtMC4zNzUgQyAyLjE3MTg3NSAtMC4zNzUgMi4wNDY4NzUgLTAuNDUzMTI1IDIuMDQ2ODc1IC0wLjc4MTI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuOTA2MjUgLTYuNzM0Mzc1IEwgMS4xMDkzNzUgLTUuODI4MTI1IEwgMS4xMDkzNzUgLTUuNjg3NSBDIDEuMjE4NzUgLTUuNzM0Mzc1IDEuMzI4MTI1IC01Ljc4MTI1IDEuMzc1IC01Ljc5Njg3NSBDIDEuNTYyNSAtNS44NzUgMS43MTg3NSAtNS45MDYyNSAxLjgyODEyNSAtNS45MDYyNSBDIDIuMDMxMjUgLTUuOTA2MjUgMi4xMjUgLTUuNzY1NjI1IDIuMTI1IC01LjQzNzUgTCAyLjEyNSAtMC45MjE4NzUgQyAyLjEyNSAtMC41OTM3NSAyLjA0Njg3NSAtMC4zNzUgMS44OTA2MjUgLTAuMjgxMjUgQyAxLjczNDM3NSAtMC4xODc1IDEuNTkzNzUgLTAuMTU2MjUgMS4xNzE4NzUgLTAuMTU2MjUgTCAxLjE3MTg3NSAwIEwgMy45MjE4NzUgMCBMIDMuOTIxODc1IC0wLjE1NjI1IEMgMy4xNDA2MjUgLTAuMTU2MjUgMi45ODQzNzUgLTAuMjY1NjI1IDIuOTg0Mzc1IC0wLjczNDM3NSBMIDIuOTg0Mzc1IC02LjcxODc1IFogTSAyLjkwNjI1IC02LjczNDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTMiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzM0Mzc1IC0xLjM1OTM3NSBMIDQuNjA5Mzc1IC0xLjQyMTg3NSBDIDQuMjM0Mzc1IC0wLjg0Mzc1IDQuMTA5Mzc1IC0wLjc1IDMuNjU2MjUgLTAuNzUgTCAxLjI4MTI1IC0wLjc1IEwgMi45NTMxMjUgLTIuNTE1NjI1IEMgMy44NDM3NSAtMy40Mzc1IDQuMjM0Mzc1IC00LjIwMzEyNSA0LjIzNDM3NSAtNC45Njg3NSBDIDQuMjM0Mzc1IC01Ljk2ODc1IDMuNDIxODc1IC02LjczNDM3NSAyLjM3NSAtNi43MzQzNzUgQyAxLjgyODEyNSAtNi43MzQzNzUgMS4zMTI1IC02LjUxNTYyNSAwLjk1MzEyNSAtNi4xMjUgQyAwLjYyNSAtNS43ODEyNSAwLjQ4NDM3NSAtNS40Njg3NSAwLjMxMjUgLTQuNzUgTCAwLjUxNTYyNSAtNC43MDMxMjUgQyAwLjkyMTg3NSAtNS42ODc1IDEuMjgxMjUgLTYgMS45Njg3NSAtNiBDIDIuNzk2ODc1IC02IDMuMzc1IC01LjQzNzUgMy4zNzUgLTQuNTkzNzUgQyAzLjM3NSAtMy44MTI1IDIuOTA2MjUgLTIuODkwNjI1IDIuMDc4MTI1IC0yIEwgMC4yOTY4NzUgLTAuMTI1IEwgMC4yOTY4NzUgMCBMIDQuMTg3NSAwIFogTSA0LjczNDM3NSAtMS4zNTkzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE0Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjUzMTI1IC0zLjI5Njg3NSBDIDIuMTA5Mzc1IC0zLjI5Njg3NSAyLjM0Mzc1IC0zLjI2NTYyNSAyLjU3ODEyNSAtMy4xODc1IEMgMy4yMDMxMjUgLTIuOTUzMTI1IDMuNTkzNzUgLTIuMzkwNjI1IDMuNTkzNzUgLTEuNzAzMTI1IEMgMy41OTM3NSAtMC44NzUgMy4wMTU2MjUgLTAuMjE4NzUgMi4yODEyNSAtMC4yMTg3NSBDIDIuMDE1NjI1IC0wLjIxODc1IDEuODEyNSAtMC4yOTY4NzUgMS40NTMxMjUgLTAuNTMxMjUgQyAxLjE0MDYyNSAtMC43MDMxMjUgMC45ODQzNzUgLTAuNzgxMjUgMC44MTI1IC0wLjc4MTI1IEMgMC41NzgxMjUgLTAuNzgxMjUgMC40MjE4NzUgLTAuNjQwNjI1IDAuNDIxODc1IC0wLjQyMTg3NSBDIDAuNDIxODc1IC0wLjA3ODEyNSAwLjg1OTM3NSAwLjE0MDYyNSAxLjU2MjUgMC4xNDA2MjUgQyAyLjMyODEyNSAwLjE0MDYyNSAzLjEwOTM3NSAtMC4xMjUgMy41NzgxMjUgLTAuNTMxMjUgQyA0LjA0Njg3NSAtMC45Mzc1IDQuMzEyNSAtMS41MTU2MjUgNC4zMTI1IC0yLjE4NzUgQyA0LjMxMjUgLTIuNjg3NSA0LjE0MDYyNSAtMy4xNTYyNSAzLjg1OTM3NSAtMy40Njg3NSBDIDMuNjU2MjUgLTMuNjg3NSAzLjQ2ODc1IC0zLjgxMjUgMy4wMzEyNSAtNCBDIDMuNzE4NzUgLTQuNDY4NzUgMy45Njg3NSAtNC44MjgxMjUgMy45Njg3NSAtNS4zNzUgQyAzLjk2ODc1IC02LjE4NzUgMy4zMjgxMjUgLTYuNzM0Mzc1IDIuNDA2MjUgLTYuNzM0Mzc1IEMgMS45MDYyNSAtNi43MzQzNzUgMS40Njg3NSAtNi41NjI1IDEuMTA5Mzc1IC02LjI1IEMgMC44MTI1IC01Ljk4NDM3NSAwLjY3MTg3NSAtNS43MTg3NSAwLjQ1MzEyNSAtNS4xMjUgTCAwLjU5Mzc1IC01LjA3ODEyNSBDIDEgLTUuODEyNSAxLjQ1MzEyNSAtNi4xNDA2MjUgMi4wNzgxMjUgLTYuMTQwNjI1IEMgMi43MzQzNzUgLTYuMTQwNjI1IDMuMTg3NSAtNS43MDMxMjUgMy4xODc1IC01LjA3ODEyNSBDIDMuMTg3NSAtNC43MTg3NSAzLjAzMTI1IC00LjM1OTM3NSAyLjc4MTI1IC00LjEwOTM3NSBDIDIuNDg0Mzc1IC0zLjgxMjUgMi4yMDMxMjUgLTMuNjU2MjUgMS41MzEyNSAtMy40MjE4NzUgWiBNIDEuNTMxMjUgLTMuMjk2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0xNSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMy45Njg3NSAtMS41NjI1IEMgMy40ODQzNzUgLTAuODU5Mzc1IDMuMTI1IC0wLjYyNSAyLjU2MjUgLTAuNjI1IEMgMS42NTYyNSAtMC42MjUgMS4wMTU2MjUgLTEuNDIxODc1IDEuMDE1NjI1IC0yLjU2MjUgQyAxLjAxNTYyNSAtMy41OTM3NSAxLjU2MjUgLTQuMjk2ODc1IDIuMzc1IC00LjI5Njg3NSBDIDIuNzM0Mzc1IC00LjI5Njg3NSAyLjg1OTM3NSAtNC4xODc1IDIuOTUzMTI1IC0zLjgxMjUgTCAzLjAxNTYyNSAtMy41OTM3NSBDIDMuMDkzNzUgLTMuMzEyNSAzLjI4MTI1IC0zLjE0MDYyNSAzLjQ4NDM3NSAtMy4xNDA2MjUgQyAzLjc1IC0zLjE0MDYyNSAzLjk2ODc1IC0zLjMyODEyNSAzLjk2ODc1IC0zLjU2MjUgQyAzLjk2ODc1IC00LjEwOTM3NSAzLjI2NTYyNSAtNC41NzgxMjUgMi40Mzc1IC00LjU3ODEyNSBDIDEuOTM3NSAtNC41NzgxMjUgMS40Mzc1IC00LjM5MDYyNSAxLjAzMTI1IC00LjAzMTI1IEMgMC41MzEyNSAtMy41OTM3NSAwLjI1IC0yLjkwNjI1IDAuMjUgLTIuMTI1IEMgMC4yNSAtMC44MjgxMjUgMS4wMzEyNSAwLjA5Mzc1IDIuMTQwNjI1IDAuMDkzNzUgQyAyLjU5Mzc1IDAuMDkzNzUgMi45ODQzNzUgLTAuMDYyNSAzLjM0Mzc1IC0wLjM3NSBDIDMuNjI1IC0wLjYwOTM3NSAzLjgxMjUgLTAuODc1IDQuMTA5Mzc1IC0xLjQ2ODc1IFogTSAzLjk2ODc1IC0xLjU2MjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE2Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjE1NjI1IC0zLjk2ODc1IEMgMC4yMTg3NSAtNCAwLjMxMjUgLTQgMC40MjE4NzUgLTQgQyAwLjcwMzEyNSAtNCAwLjc5Njg3NSAtMy44NTkzNzUgMC43OTY4NzUgLTMuMzc1IEwgMC43OTY4NzUgLTAuODkwNjI1IEMgMC43OTY4NzUgLTAuMzI4MTI1IDAuNjg3NSAtMC4xODc1IDAuMTcxODc1IC0wLjE1NjI1IEwgMC4xNzE4NzUgMCBMIDIuMjk2ODc1IDAgTCAyLjI5Njg3NSAtMC4xNTYyNSBDIDEuNzgxMjUgLTAuMTg3NSAxLjY0MDYyNSAtMC4zMTI1IDEuNjQwNjI1IC0wLjY3MTg3NSBMIDEuNjQwNjI1IC0zLjQ2ODc1IEMgMi4xMDkzNzUgLTMuOTIxODc1IDIuMzI4MTI1IC00LjAzMTI1IDIuNjU2MjUgLTQuMDMxMjUgQyAzLjE1NjI1IC00LjAzMTI1IDMuMzkwNjI1IC0zLjczNDM3NSAzLjM5MDYyNSAtMy4wNzgxMjUgTCAzLjM5MDYyNSAtMC45ODQzNzUgQyAzLjM5MDYyNSAtMC4zNTkzNzUgMy4yNjU2MjUgLTAuMTg3NSAyLjc2NTYyNSAtMC4xNTYyNSBMIDIuNzY1NjI1IDAgTCA0LjgyODEyNSAwIEwgNC44MjgxMjUgLTAuMTU2MjUgQyA0LjM0Mzc1IC0wLjIwMzEyNSA0LjIzNDM3NSAtMC4zMTI1IDQuMjM0Mzc1IC0wLjgxMjUgTCA0LjIzNDM3NSAtMy4wOTM3NSBDIDQuMjM0Mzc1IC00LjAzMTI1IDMuNzgxMjUgLTQuNTc4MTI1IDMuMDQ2ODc1IC00LjU3ODEyNSBDIDIuNTkzNzUgLTQuNTc4MTI1IDIuMjgxMjUgLTQuNDIxODc1IDEuNjA5Mzc1IC0zLjc4MTI1IEwgMS42MDkzNzUgLTQuNTYyNSBMIDEuNTMxMjUgLTQuNTc4MTI1IEMgMS4wNDY4NzUgLTQuNDA2MjUgMC43MDMxMjUgLTQuMjk2ODc1IDAuMTU2MjUgLTQuMTQwNjI1IFogTSAwLjE1NjI1IC0zLjk2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0xNyI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC4wNjI1IC0zLjg5MDYyNSBDIDAuMjAzMTI1IC0zLjkyMTg3NSAwLjI5Njg3NSAtMy45MjE4NzUgMC40MjE4NzUgLTMuOTIxODc1IEMgMC42NzE4NzUgLTMuOTIxODc1IDAuNzUgLTMuNzY1NjI1IDAuNzUgLTMuMzI4MTI1IEwgMC43NSAtMC44NDM3NSBDIDAuNzUgLTAuMzQzNzUgMC42ODc1IC0wLjI2NTYyNSAwLjA0Njg3NSAtMC4xNTYyNSBMIDAuMDQ2ODc1IDAgTCAyLjQzNzUgMCBMIDIuNDM3NSAtMC4xNTYyNSBDIDEuNzY1NjI1IC0wLjE3MTg3NSAxLjU5Mzc1IC0wLjMyODEyNSAxLjU5Mzc1IC0wLjg5MDYyNSBMIDEuNTkzNzUgLTMuMTQwNjI1IEMgMS41OTM3NSAtMy40NTMxMjUgMi4wMzEyNSAtMy45NTMxMjUgMi4yOTY4NzUgLTMuOTUzMTI1IEMgMi4zNTkzNzUgLTMuOTUzMTI1IDIuNDM3NSAtMy45MDYyNSAyLjU0Njg3NSAtMy44MTI1IEMgMi43MTg3NSAtMy42NzE4NzUgMi44MjgxMjUgLTMuNjA5Mzc1IDIuOTUzMTI1IC0zLjYwOTM3NSBDIDMuMTg3NSAtMy42MDkzNzUgMy4zNDM3NSAtMy43ODEyNSAzLjM0Mzc1IC00LjA2MjUgQyAzLjM0Mzc1IC00LjM5MDYyNSAzLjEyNSAtNC41NzgxMjUgMi43OTY4NzUgLTQuNTc4MTI1IEMgMi4zNzUgLTQuNTc4MTI1IDIuMDc4MTI1IC00LjM1OTM3NSAxLjU5Mzc1IC0zLjY1NjI1IEwgMS41OTM3NSAtNC41NjI1IEwgMS41NDY4NzUgLTQuNTc4MTI1IEMgMS4wMTU2MjUgLTQuMzU5Mzc1IDAuNjU2MjUgLTQuMjM0Mzc1IDAuMDYyNSAtNC4wNDY4NzUgWiBNIDAuMDYyNSAtMy44OTA2MjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE4Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjc1IC00LjU3ODEyNSBMIDAuMjAzMTI1IC00LjAzMTI1IEwgMC4yMDMxMjUgLTMuODkwNjI1IEwgMC4yODEyNSAtMy44OTA2MjUgQyAwLjQwNjI1IC0zLjkyMTg3NSAwLjUzMTI1IC0zLjkyMTg3NSAwLjYyNSAtMy45MjE4NzUgQyAwLjg1OTM3NSAtMy45MjE4NzUgMC45NTMxMjUgLTMuNzY1NjI1IDAuOTUzMTI1IC0zLjMyODEyNSBMIDAuOTUzMTI1IC0xLjAxNTYyNSBDIDAuOTUzMTI1IC0wLjI5Njg3NSAwLjg0Mzc1IC0wLjE4NzUgMC4xNTYyNSAtMC4xNTYyNSBMIDAuMTU2MjUgMCBMIDIuNTE1NjI1IDAgTCAyLjUxNTYyNSAtMC4xNTYyNSBDIDEuODU5Mzc1IC0wLjIwMzEyNSAxLjc4MTI1IC0wLjI5Njg3NSAxLjc4MTI1IC0xLjAxNTYyNSBMIDEuNzgxMjUgLTQuNTYyNSBaIE0gMS4yODEyNSAtNi44MTI1IEMgMSAtNi44MTI1IDAuNzgxMjUgLTYuNTc4MTI1IDAuNzgxMjUgLTYuMjk2ODc1IEMgMC43ODEyNSAtNi4wMTU2MjUgMSAtNS43OTY4NzUgMS4yODEyNSAtNS43OTY4NzUgQyAxLjU2MjUgLTUuNzk2ODc1IDEuNzk2ODc1IC02LjAxNTYyNSAxLjc5Njg3NSAtNi4yOTY4NzUgQyAxLjc5Njg3NSAtNi41NzgxMjUgMS41NjI1IC02LjgxMjUgMS4yODEyNSAtNi44MTI1IFogTSAxLjI4MTI1IC02LjgxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE5Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAyLjUgLTQuNTc4MTI1IEMgMS4yMDMxMjUgLTQuNTc4MTI1IDAuMjk2ODc1IC0zLjYyNSAwLjI5Njg3NSAtMi4yNSBDIDAuMjk2ODc1IC0wLjkwNjI1IDEuMjE4NzUgMC4wOTM3NSAyLjQ2ODc1IDAuMDkzNzUgQyAzLjczNDM3NSAwLjA5Mzc1IDQuNjg3NSAtMC45NTMxMjUgNC42ODc1IC0yLjMyODEyNSBDIDQuNjg3NSAtMy42NDA2MjUgMy43NjU2MjUgLTQuNTc4MTI1IDIuNSAtNC41NzgxMjUgWiBNIDIuMzU5Mzc1IC00LjMxMjUgQyAzLjIwMzEyNSAtNC4zMTI1IDMuNzgxMjUgLTMuMzQzNzUgMy43ODEyNSAtMS45ODQzNzUgQyAzLjc4MTI1IC0wLjg1OTM3NSAzLjM0Mzc1IC0wLjE3MTg3NSAyLjU5Mzc1IC0wLjE3MTg3NSBDIDIuMjAzMTI1IC0wLjE3MTg3NSAxLjgyODEyNSAtMC40MjE4NzUgMS42MjUgLTAuODEyNSBDIDEuMzQzNzUgLTEuMzI4MTI1IDEuMTg3NSAtMi4wMzEyNSAxLjE4NzUgLTIuNzM0Mzc1IEMgMS4xODc1IC0zLjY4NzUgMS42NTYyNSAtNC4zMTI1IDIuMzU5Mzc1IC00LjMxMjUgWiBNIDIuMzU5Mzc1IC00LjMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTIwIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0LjczNDM3NSAtNC40ODQzNzUgTCAzLjM5MDYyNSAtNC40ODQzNzUgTCAzLjM5MDYyNSAtNC4zNDM3NSBDIDMuNzAzMTI1IC00LjM0Mzc1IDMuODc1IC00LjI1IDMuODc1IC00LjA5Mzc1IEMgMy44NzUgLTQuMDQ2ODc1IDMuODU5Mzc1IC0zLjk4NDM3NSAzLjgyODEyNSAtMy45MjE4NzUgTCAyLjg1OTM3NSAtMS4xNzE4NzUgTCAxLjcxODc1IC0zLjY4NzUgQyAxLjY1NjI1IC0zLjgyODEyNSAxLjYwOTM3NSAtMy45NTMxMjUgMS42MDkzNzUgLTQuMDYyNSBDIDEuNjA5Mzc1IC00LjI1IDEuNzY1NjI1IC00LjMxMjUgMi4xODc1IC00LjM0Mzc1IEwgMi4xODc1IC00LjQ4NDM3NSBMIDAuMTQwNjI1IC00LjQ4NDM3NSBMIDAuMTQwNjI1IC00LjM0Mzc1IEMgMC40MDYyNSAtNC4zMTI1IDAuNTYyNSAtNC4yMDMxMjUgMC42NDA2MjUgLTQuMDMxMjUgTCAxLjc4MTI1IC0xLjU3ODEyNSBMIDEuODEyNSAtMS41IEwgMS45Njg3NSAtMS4yMDMxMjUgQyAyLjI1IC0wLjcwMzEyNSAyLjQwNjI1IC0wLjM0Mzc1IDIuNDA2MjUgLTAuMTg3NSBDIDIuNDA2MjUgLTAuMDQ2ODc1IDIuMTcxODc1IDAuNTkzNzUgMiAwLjg5MDYyNSBDIDEuODU5Mzc1IDEuMTQwNjI1IDEuNjQwNjI1IDEuMzI4MTI1IDEuNSAxLjMyODEyNSBDIDEuNDUzMTI1IDEuMzI4MTI1IDEuMzU5Mzc1IDEuMzEyNSAxLjI1IDEuMjY1NjI1IEMgMS4wNjI1IDEuMjAzMTI1IDAuODkwNjI1IDEuMTU2MjUgMC43MzQzNzUgMS4xNTYyNSBDIDAuNSAxLjE1NjI1IDAuMjk2ODc1IDEuMzU5Mzc1IDAuMjk2ODc1IDEuNTkzNzUgQyAwLjI5Njg3NSAxLjkyMTg3NSAwLjYyNSAyLjE3MTg3NSAxLjAzMTI1IDIuMTcxODc1IEMgMS43MDMxMjUgMi4xNzE4NzUgMi4xODc1IDEuNjA5Mzc1IDIuNzE4NzUgMC4xNzE4NzUgTCA0LjI1IC0zLjg5MDYyNSBDIDQuMzkwNjI1IC00LjIwMzEyNSA0LjUgLTQuMzEyNSA0LjczNDM3NSAtNC4zNDM3NSBaIE0gNC43MzQzNzUgLTQuNDg0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMi0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgyLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuMTQwNjI1IC00Ljk4NDM3NSBMIDAuODEyNSAtNC4zMTI1IEwgMC44MTI1IC00LjIxODc1IEMgMC45MDYyNSAtNC4yNSAwLjk4NDM3NSAtNC4yODEyNSAxLjAxNTYyNSAtNC4yOTY4NzUgQyAxLjE1NjI1IC00LjM0Mzc1IDEuMjgxMjUgLTQuMzc1IDEuMzQzNzUgLTQuMzc1IEMgMS41IC00LjM3NSAxLjU3ODEyNSAtNC4yNjU2MjUgMS41NzgxMjUgLTQuMDMxMjUgTCAxLjU3ODEyNSAtMC42ODc1IEMgMS41NzgxMjUgLTAuNDM3NSAxLjUxNTYyNSAtMC4yNjU2MjUgMS4zOTA2MjUgLTAuMjAzMTI1IEMgMS4yODEyNSAtMC4xNDA2MjUgMS4xODc1IC0wLjEyNSAwLjg3NSAtMC4xMDkzNzUgTCAwLjg3NSAwIEwgMi45MDYyNSAwIEwgMi45MDYyNSAtMC4xMDkzNzUgQyAyLjMyODEyNSAtMC4xMjUgMi4yMDMxMjUgLTAuMTg3NSAyLjIwMzEyNSAtMC41NDY4NzUgTCAyLjIwMzEyNSAtNC45Njg3NSBaIE0gMi4xNDA2MjUgLTQuOTg0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMi0yIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjUgLTEuMDE1NjI1IEwgMy40MDYyNSAtMS4wNDY4NzUgQyAzLjE0MDYyNSAtMC42MjUgMy4wMzEyNSAtMC41NjI1IDIuNzAzMTI1IC0wLjU2MjUgTCAwLjkzNzUgLTAuNTYyNSBMIDIuMTg3NSAtMS44NTkzNzUgQyAyLjg0Mzc1IC0yLjU0Njg3NSAzLjEyNSAtMy4xMDkzNzUgMy4xMjUgLTMuNjg3NSBDIDMuMTI1IC00LjQyMTg3NSAyLjUzMTI1IC00Ljk4NDM3NSAxLjc2NTYyNSAtNC45ODQzNzUgQyAxLjM1OTM3NSAtNC45ODQzNzUgMC45Njg3NSAtNC44MjgxMjUgMC43MDMxMjUgLTQuNTMxMjUgQyAwLjQ2ODc1IC00LjI4MTI1IDAuMzU5Mzc1IC00LjA0Njg3NSAwLjIzNDM3NSAtMy41MTU2MjUgTCAwLjM5MDYyNSAtMy40ODQzNzUgQyAwLjY3MTg3NSAtNC4yMDMxMjUgMC45Mzc1IC00LjQzNzUgMS40NTMxMjUgLTQuNDM3NSBDIDIuMDc4MTI1IC00LjQzNzUgMi41IC00LjAxNTYyNSAyLjUgLTMuNDA2MjUgQyAyLjUgLTIuODI4MTI1IDIuMTU2MjUgLTIuMTQwNjI1IDEuNTMxMjUgLTEuNDg0Mzc1IEwgMC4yMTg3NSAtMC4wOTM3NSBMIDAuMjE4NzUgMCBMIDMuMDkzNzUgMCBaIE0gMy41IC0xLjAxNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDItMyI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS4xMjUgLTIuNDM3NSBDIDEuNTYyNSAtMi40Mzc1IDEuNzM0Mzc1IC0yLjQyMTg3NSAxLjkwNjI1IC0yLjM1OTM3NSBDIDIuMzc1IC0yLjE4NzUgMi42NTYyNSAtMS43NjU2MjUgMi42NTYyNSAtMS4yNjU2MjUgQyAyLjY1NjI1IC0wLjY0MDYyNSAyLjIzNDM3NSAtMC4xNTYyNSAxLjY4NzUgLTAuMTU2MjUgQyAxLjQ4NDM3NSAtMC4xNTYyNSAxLjM0Mzc1IC0wLjIxODc1IDEuMDYyNSAtMC4zOTA2MjUgQyAwLjg0Mzc1IC0wLjUzMTI1IDAuNzE4NzUgLTAuNTc4MTI1IDAuNTkzNzUgLTAuNTc4MTI1IEMgMC40MjE4NzUgLTAuNTc4MTI1IDAuMzEyNSAtMC40Njg3NSAwLjMxMjUgLTAuMzEyNSBDIDAuMzEyNSAtMC4wNjI1IDAuNjQwNjI1IDAuMTA5Mzc1IDEuMTU2MjUgMC4xMDkzNzUgQyAxLjcxODc1IDAuMTA5Mzc1IDIuMjk2ODc1IC0wLjA5Mzc1IDIuNjQwNjI1IC0wLjM5MDYyNSBDIDMgLTAuNjg3NSAzLjE4NzUgLTEuMTI1IDMuMTg3NSAtMS42MDkzNzUgQyAzLjE4NzUgLTEuOTg0Mzc1IDMuMDYyNSAtMi4zNDM3NSAyLjg1OTM3NSAtMi41NjI1IEMgMi43MDMxMjUgLTIuNzM0Mzc1IDIuNTYyNSAtMi44MTI1IDIuMjM0Mzc1IC0yLjk1MzEyNSBDIDIuNzUgLTMuMjk2ODc1IDIuOTM3NSAtMy41NzgxMjUgMi45Mzc1IC0zLjk2ODc1IEMgMi45Mzc1IC00LjU3ODEyNSAyLjQ2ODc1IC00Ljk4NDM3NSAxLjc4MTI1IC00Ljk4NDM3NSBDIDEuNDIxODc1IC00Ljk4NDM3NSAxLjA5Mzc1IC00Ljg1OTM3NSAwLjgyODEyNSAtNC42MjUgQyAwLjYwOTM3NSAtNC40MjE4NzUgMC41IC00LjIzNDM3NSAwLjMyODEyNSAtMy43OTY4NzUgTCAwLjQzNzUgLTMuNzY1NjI1IEMgMC43NSAtNC4yOTY4NzUgMS4wNzgxMjUgLTQuNTQ2ODc1IDEuNTQ2ODc1IC00LjU0Njg3NSBDIDIuMDE1NjI1IC00LjU0Njg3NSAyLjM1OTM3NSAtNC4yMTg3NSAyLjM1OTM3NSAtMy43NSBDIDIuMzU5Mzc1IC0zLjQ4NDM3NSAyLjIzNDM3NSAtMy4yMTg3NSAyLjA2MjUgLTMuMDMxMjUgQyAxLjg0Mzc1IC0yLjgxMjUgMS42MjUgLTIuNzAzMTI1IDEuMTI1IC0yLjUzMTI1IFogTSAxLjEyNSAtMi40Mzc1ICIvPgo8L3N5bWJvbD4KPC9nPgo8Y2xpcFBhdGggaWQ9ImNsaXAxIj4KICA8cGF0aCBkPSJNIDMgMTUgTCA0OSAxNSBMIDQ5IDQzIEwgMyA0MyBaIE0gMyAxNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMiI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzIj4KICA8cGF0aCBkPSJNIDQ3IDE1IEwgOTYgMTUgTCA5NiA0MyBMIDQ3IDQzIFogTSA0NyAxNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNCI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1Ij4KICA8cGF0aCBkPSJNIDk2IDE1IEwgMTQ1IDE1IEwgMTQ1IDQzIEwgOTYgNDMgWiBNIDk2IDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3Ij4KICA8cGF0aCBkPSJNIDE0MyAxNSBMIDE5MyAxNSBMIDE5MyA0MyBMIDE0MyA0MyBaIE0gMTQzIDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5Ij4KICA8cGF0aCBkPSJNIDE5MyAxNSBMIDIzOCAxNSBMIDIzOCA0MyBMIDE5MyA0MyBaIE0gMTkzIDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMCI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExIj4KICA8cGF0aCBkPSJNIDIzNiAxNSBMIDMwOCAxNSBMIDMwOCA0MyBMIDIzNiA0MyBaIE0gMjM2IDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMiI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzIj4KICA8cGF0aCBkPSJNIDMwOCAxNSBMIDM3MyAxNSBMIDM3MyA0MyBMIDMwOCA0MyBaIE0gMzA4IDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNCI+CiAgPHBhdGggZD0iTSAzMTEuMzgyODEyIDQyLjY3MTg3NSBMIDM2OS41NjI1IDQyLjY3MTg3NSBDIDM3Mi4wMjczNDQgNDIuNjcxODc1IDM3Mi4wMjczNDQgMzQuODY3MTg4IDM3Mi4wMjczNDQgMjguOTc2NTYyIEMgMzcyLjAyNzM0NCAyMy4wODU5MzggMzcyLjAyNzM0NCAxNS4yODEyNSAzNjkuNTYyNSAxNS4yODEyNSBMIDMxMS4zODI4MTIgMTUuMjgxMjUgQyAzMDguOTE3OTY5IDE1LjI4MTI1IDMwOC45MTc5NjkgMjMuMDg1OTM4IDMwOC45MTc5NjkgMjguOTc2NTYyIEMgMzA4LjkxNzk2OSAzNC44NjcxODggMzA4LjkxNzk2OSA0Mi42NzE4NzUgMzExLjM4MjgxMiA0Mi42NzE4NzUgWiBNIDMxMS4zODI4MTIgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNSI+CiAgPHBhdGggZD0iTSAzNzMgMTUgTCA0MzkgMTUgTCA0MzkgNDMgTCAzNzMgNDMgWiBNIDM3MyAxNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTYiPgogIDxwYXRoIGQ9Ik0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgTCA0MzYuMTI1IDQyLjY3MTg3NSBDIDQzOC41ODk4NDQgNDIuNjcxODc1IDQzOC41ODk4NDQgMzQuODY3MTg4IDQzOC41ODk4NDQgMjguOTc2NTYyIEMgNDM4LjU4OTg0NCAyMy4wODU5MzggNDM4LjU4OTg0NCAxNS4yODEyNSA0MzYuMTI1IDE1LjI4MTI1IEwgMzc1LjQ4MDQ2OSAxNS4yODEyNSBDIDM3My4wMTU2MjUgMTUuMjgxMjUgMzczLjAxNTYyNSAyMy4wODU5MzggMzczLjAxNTYyNSAyOC45NzY1NjIgQyAzNzMuMDE1NjI1IDM0Ljg2NzE4OCAzNzMuMDE1NjI1IDQyLjY3MTg3NSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBaIE0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE3Ij4KICA8cGF0aCBkPSJNIDQzOSAxNSBMIDUwMyAxNSBMIDUwMyA0MyBMIDQzOSA0MyBaIE0gNDM5IDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOCI+CiAgPHBhdGggZD0iTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBMIDUwMC4yMTg3NSA0Mi42NzE4NzUgQyA1MDIuNjgzNTk0IDQyLjY3MTg3NSA1MDIuNjgzNTk0IDM0Ljg2NzE4OCA1MDIuNjgzNTk0IDI4Ljk3NjU2MiBDIDUwMi42ODM1OTQgMjMuMDg1OTM4IDUwMi42ODM1OTQgMTUuMjgxMjUgNTAwLjIxODc1IDE1LjI4MTI1IEwgNDQyLjAzOTA2MiAxNS4yODEyNSBDIDQzOS41NzQyMTkgMTUuMjgxMjUgNDM5LjU3NDIxOSAyMy4wODU5MzggNDM5LjU3NDIxOSAyOC45NzY1NjIgQyA0MzkuNTc0MjE5IDM0Ljg2NzE4OCA0MzkuNTc0MjE5IDQyLjY3MTg3NSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBaIE0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE5Ij4KICA8cGF0aCBkPSJNIDE5MiA0MiBMIDQ5MiA0MiBMIDQ5MiA2NS4zMjgxMjUgTCAxOTIgNjUuMzI4MTI1IFogTSAxOTIgNDIgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIwIj4KICA8cGF0aCBkPSJNIDEwIDcgTCAzOC4wODIwMzEgNyBMIDM4LjA4MjAzMSA4IEwgMTAgOCBaIE0gNjEuMDc0MjE5IDcgTCA4OSA3IEwgODkgOCBMIDYxLjA3NDIxOSA4IFogTSA2MS4wNzQyMTkgNyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjEiPgogIDxwYXRoIGQ9Ik0gODggNSBMIDk2LjQxNzk2OSA1IEwgOTYuNDE3OTY5IDEwIEwgODggMTAgWiBNIDg4IDUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIyIj4KICA8cGF0aCBkPSJNIDIuNzM4MjgxIDUgTCAxMSA1IEwgMTEgMTAgTCAyLjczODI4MSAxMCBaIE0gMi43MzgyODEgNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjMiPgogIDxwYXRoIGQ9Ik0gMi43MzgyODEgMyBMIDQgMyBMIDQgMTIgTCAyLjczODI4MSAxMiBaIE0gMi43MzgyODEgMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjQiPgogIDxwYXRoIGQ9Ik0gOTUgMyBMIDk2LjQxNzk2OSAzIEwgOTYuNDE3OTY5IDEyIEwgOTUgMTIgWiBNIDk1IDMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDI1Ij4KICA8cGF0aCBkPSJNIDEwNCA3IEwgMTMyLjk5MjE4OCA3IEwgMTMyLjk5MjE4OCA4IEwgMTA0IDggWiBNIDE1NS45ODQzNzUgNyBMIDE4NSA3IEwgMTg1IDggTCAxNTUuOTg0Mzc1IDggWiBNIDE1NS45ODQzNzUgNyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjYiPgogIDxwYXRoIGQ9Ik0gMTg0IDUgTCAxOTIuNTYyNSA1IEwgMTkyLjU2MjUgMTAgTCAxODQgMTAgWiBNIDE4NCA1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyNyI+CiAgPHBhdGggZD0iTSA5Ni40MTc5NjkgNSBMIDEwNSA1IEwgMTA1IDEwIEwgOTYuNDE3OTY5IDEwIFogTSA5Ni40MTc5NjkgNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjgiPgogIDxwYXRoIGQ9Ik0gOTYuNDE3OTY5IDMgTCA5OCAzIEwgOTggMTIgTCA5Ni40MTc5NjkgMTIgWiBNIDk2LjQxNzk2OSAzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyOSI+CiAgPHBhdGggZD0iTSAxOTEgMyBMIDE5Mi41NjI1IDMgTCAxOTIuNTYyNSAxMiBMIDE5MSAxMiBaIE0gMTkxIDMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMwIj4KICA8cGF0aCBkPSJNIDIwMCA3IEwgMjM4Ljk5NjA5NCA3IEwgMjM4Ljk5NjA5NCA4IEwgMjAwIDggWiBNIDI2MS45OTIxODggNyBMIDMwMSA3IEwgMzAxIDggTCAyNjEuOTkyMTg4IDggWiBNIDI2MS45OTIxODggNyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzEiPgogIDxwYXRoIGQ9Ik0gMzAwIDUgTCAzMDguNDI1NzgxIDUgTCAzMDguNDI1NzgxIDEwIEwgMzAwIDEwIFogTSAzMDAgNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzIiPgogIDxwYXRoIGQ9Ik0gMTkyLjU2MjUgNSBMIDIwMSA1IEwgMjAxIDEwIEwgMTkyLjU2MjUgMTAgWiBNIDE5Mi41NjI1IDUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMzIj4KICA8cGF0aCBkPSJNIDE5Mi41NjI1IDMgTCAxOTQgMyBMIDE5NCAxMiBMIDE5Mi41NjI1IDEyIFogTSAxOTIuNTYyNSAzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzNCI+CiAgPHBhdGggZD0iTSAzMDcgMyBMIDMwOC40MjU3ODEgMyBMIDMwOC40MjU3ODEgMTIgTCAzMDcgMTIgWiBNIDMwNyAzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzNSI+CiAgPHBhdGggZD0iTSAzMTYgNyBMIDM3Mi4zOTA2MjUgNyBMIDM3Mi4zOTA2MjUgOCBMIDMxNiA4IFogTSA0MzkuMjE0ODQ0IDcgTCA0OTYgNyBMIDQ5NiA4IEwgNDM5LjIxNDg0NCA4IFogTSA0MzkuMjE0ODQ0IDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM2Ij4KICA8cGF0aCBkPSJNIDMwOC40MjU3ODEgNSBMIDMxNyA1IEwgMzE3IDEwIEwgMzA4LjQyNTc4MSAxMCBaIE0gMzA4LjQyNTc4MSA1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzNyI+CiAgPHBhdGggZD0iTSAzMDguNDI1NzgxIDMgTCAzMTAgMyBMIDMxMCAxMiBMIDMwOC40MjU3ODEgMTIgWiBNIDMwOC40MjU3ODEgMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzgiPgogIDxwYXRoIGQ9Ik0gNyAzMSBMIDE0IDMxIEwgMTQgMzggTCA3IDM4IFogTSA3IDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzOSI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0MCI+CiAgPHBhdGggZD0iTSAxNCAzMSBMIDE5IDMxIEwgMTkgMzggTCAxNCAzOCBaIE0gMTQgMzEgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQxIj4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQyIj4KICA8cGF0aCBkPSJNIDE5IDMxIEwgMjYgMzEgTCAyNiAzOCBMIDE5IDM4IFogTSAxOSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDMiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgNDIuNjcxODc1IEwgOTMuNDYwOTM4IDQyLjY3MTg3NSBDIDk1LjkyNTc4MSA0Mi42NzE4NzUgOTUuOTI1NzgxIDM0Ljg2NzE4OCA5NS45MjU3ODEgMjguOTc2NTYyIEMgOTUuOTI1NzgxIDIzLjA4NTkzOCA5NS45MjU3ODEgMTUuMjgxMjUgOTMuNDYwOTM4IDE1LjI4MTI1IEwgNS42OTkyMTkgMTUuMjgxMjUgQyAzLjIzMDQ2OSAxNS4yODEyNSAzLjIzMDQ2OSAyMy4wODU5MzggMy4yMzA0NjkgMjguOTc2NTYyIEMgMy4yMzA0NjkgMzQuODY3MTg4IDMuMjMwNDY5IDQyLjY3MTg3NSA1LjY5OTIxOSA0Mi42NzE4NzUgWiBNIDUuNjk5MjE5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDQiPgogIDxwYXRoIGQ9Ik0gMjYgMzEgTCAzMiAzMSBMIDMyIDM4IEwgMjYgMzggWiBNIDI2IDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NSI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NiI+CiAgPHBhdGggZD0iTSAzMiAzMSBMIDM5IDMxIEwgMzkgMzggTCAzMiAzOCBaIE0gMzIgMzEgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ3Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ4Ij4KICA8cGF0aCBkPSJNIDQwIDMxIEwgNDUgMzEgTCA0NSAzOCBMIDQwIDM4IFogTSA0MCAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDkiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgNDIuNjcxODc1IEwgOTMuNDYwOTM4IDQyLjY3MTg3NSBDIDk1LjkyNTc4MSA0Mi42NzE4NzUgOTUuOTI1NzgxIDM0Ljg2NzE4OCA5NS45MjU3ODEgMjguOTc2NTYyIEMgOTUuOTI1NzgxIDIzLjA4NTkzOCA5NS45MjU3ODEgMTUuMjgxMjUgOTMuNDYwOTM4IDE1LjI4MTI1IEwgNS42OTkyMTkgMTUuMjgxMjUgQyAzLjIzMDQ2OSAxNS4yODEyNSAzLjIzMDQ2OSAyMy4wODU5MzggMy4yMzA0NjkgMjguOTc2NTYyIEMgMy4yMzA0NjkgMzQuODY3MTg4IDMuMjMwNDY5IDQyLjY3MTg3NSA1LjY5OTIxOSA0Mi42NzE4NzUgWiBNIDUuNjk5MjE5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTAiPgogIDxwYXRoIGQ9Ik0gMTQgMjAgTCAyMSAyMCBMIDIxIDI3IEwgMTQgMjcgWiBNIDE0IDIwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1MSI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1MiI+CiAgPHBhdGggZD0iTSAyMCAyMCBMIDI3IDIwIEwgMjcgMjcgTCAyMCAyNyBaIE0gMjAgMjAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDUzIj4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU0Ij4KICA8cGF0aCBkPSJNIDI2IDIwIEwgMzQgMjAgTCAzNCAyNyBMIDI2IDI3IFogTSAyNiAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTUiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgNDIuNjcxODc1IEwgOTMuNDYwOTM4IDQyLjY3MTg3NSBDIDk1LjkyNTc4MSA0Mi42NzE4NzUgOTUuOTI1NzgxIDM0Ljg2NzE4OCA5NS45MjU3ODEgMjguOTc2NTYyIEMgOTUuOTI1NzgxIDIzLjA4NTkzOCA5NS45MjU3ODEgMTUuMjgxMjUgOTMuNDYwOTM4IDE1LjI4MTI1IEwgNS42OTkyMTkgMTUuMjgxMjUgQyAzLjIzMDQ2OSAxNS4yODEyNSAzLjIzMDQ2OSAyMy4wODU5MzggMy4yMzA0NjkgMjguOTc2NTYyIEMgMy4yMzA0NjkgMzQuODY3MTg4IDMuMjMwNDY5IDQyLjY3MTg3NSA1LjY5OTIxOSA0Mi42NzE4NzUgWiBNIDUuNjk5MjE5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTYiPgogIDxwYXRoIGQ9Ik0gMzQgMjMgTCAzNyAyMyBMIDM3IDI5IEwgMzQgMjkgWiBNIDM0IDIzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1NyI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1OCI+CiAgPHBhdGggZD0iTSA1NCAyNCBMIDYwIDI0IEwgNjAgMzIgTCA1NCAzMiBaIE0gNTQgMjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU5Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDYwIj4KICA8cGF0aCBkPSJNIDYwIDI0IEwgNjMgMjQgTCA2MyAzMiBMIDYwIDMyIFogTSA2MCAyNCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjEiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgNDIuNjcxODc1IEwgOTMuNDYwOTM4IDQyLjY3MTg3NSBDIDk1LjkyNTc4MSA0Mi42NzE4NzUgOTUuOTI1NzgxIDM0Ljg2NzE4OCA5NS45MjU3ODEgMjguOTc2NTYyIEMgOTUuOTI1NzgxIDIzLjA4NTkzOCA5NS45MjU3ODEgMTUuMjgxMjUgOTMuNDYwOTM4IDE1LjI4MTI1IEwgNS42OTkyMTkgMTUuMjgxMjUgQyAzLjIzMDQ2OSAxNS4yODEyNSAzLjIzMDQ2OSAyMy4wODU5MzggMy4yMzA0NjkgMjguOTc2NTYyIEMgMy4yMzA0NjkgMzQuODY3MTg4IDMuMjMwNDY5IDQyLjY3MTg3NSA1LjY5OTIxOSA0Mi42NzE4NzUgWiBNIDUuNjk5MjE5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjIiPgogIDxwYXRoIGQ9Ik0gNjMgMjYgTCA2OCAyNiBMIDY4IDMyIEwgNjMgMzIgWiBNIDYzIDI2ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2MyI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2NCI+CiAgPHBhdGggZD0iTSA3MCAyNCBMIDc1IDI0IEwgNzUgMzIgTCA3MCAzMiBaIE0gNzAgMjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY1Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY2Ij4KICA8cGF0aCBkPSJNIDc1IDI2IEwgODAgMjYgTCA4MCAzMiBMIDc1IDMyIFogTSA3NSAyNiAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjciPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgNDIuNjcxODc1IEwgOTMuNDYwOTM4IDQyLjY3MTg3NSBDIDk1LjkyNTc4MSA0Mi42NzE4NzUgOTUuOTI1NzgxIDM0Ljg2NzE4OCA5NS45MjU3ODEgMjguOTc2NTYyIEMgOTUuOTI1NzgxIDIzLjA4NTkzOCA5NS45MjU3ODEgMTUuMjgxMjUgOTMuNDYwOTM4IDE1LjI4MTI1IEwgNS42OTkyMTkgMTUuMjgxMjUgQyAzLjIzMDQ2OSAxNS4yODEyNSAzLjIzMDQ2OSAyMy4wODU5MzggMy4yMzA0NjkgMjguOTc2NTYyIEMgMy4yMzA0NjkgMzQuODY3MTg4IDMuMjMwNDY5IDQyLjY3MTg3NSA1LjY5OTIxOSA0Mi42NzE4NzUgWiBNIDUuNjk5MjE5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjgiPgogIDxwYXRoIGQ9Ik0gNzkgMjUgTCA4MyAyNSBMIDgzIDMyIEwgNzkgMzIgWiBNIDc5IDI1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2OSI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA0Mi42NzE4NzUgTCA5My40NjA5MzggNDIuNjcxODc1IEMgOTUuOTI1NzgxIDQyLjY3MTg3NSA5NS45MjU3ODEgMzQuODY3MTg4IDk1LjkyNTc4MSAyOC45NzY1NjIgQyA5NS45MjU3ODEgMjMuMDg1OTM4IDk1LjkyNTc4MSAxNS4yODEyNSA5My40NjA5MzggMTUuMjgxMjUgTCA1LjY5OTIxOSAxNS4yODEyNSBDIDMuMjMwNDY5IDE1LjI4MTI1IDMuMjMwNDY5IDIzLjA4NTkzOCAzLjIzMDQ2OSAyOC45NzY1NjIgQyAzLjIzMDQ2OSAzNC44NjcxODggMy4yMzA0NjkgNDIuNjcxODc1IDUuNjk5MjE5IDQyLjY3MTg3NSBaIE0gNS42OTkyMTkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3MCI+CiAgPHBhdGggZD0iTSA4MiAyNiBMIDg3IDI2IEwgODcgMzIgTCA4MiAzMiBaIE0gODIgMjYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDcxIj4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDQyLjY3MTg3NSBMIDkzLjQ2MDkzOCA0Mi42NzE4NzUgQyA5NS45MjU3ODEgNDIuNjcxODc1IDk1LjkyNTc4MSAzNC44NjcxODggOTUuOTI1NzgxIDI4Ljk3NjU2MiBDIDk1LjkyNTc4MSAyMy4wODU5MzggOTUuOTI1NzgxIDE1LjI4MTI1IDkzLjQ2MDkzOCAxNS4yODEyNSBMIDUuNjk5MjE5IDE1LjI4MTI1IEMgMy4yMzA0NjkgMTUuMjgxMjUgMy4yMzA0NjkgMjMuMDg1OTM4IDMuMjMwNDY5IDI4Ljk3NjU2MiBDIDMuMjMwNDY5IDM0Ljg2NzE4OCAzLjIzMDQ2OSA0Mi42NzE4NzUgNS42OTkyMTkgNDIuNjcxODc1IFogTSA1LjY5OTIxOSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDcyIj4KICA8cGF0aCBkPSJNIDEwNSAzMSBMIDExMiAzMSBMIDExMiAzOCBMIDEwNSAzOCBaIE0gMTA1IDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3MyI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzQiPgogIDxwYXRoIGQ9Ik0gMTEyIDMzIEwgMTE3IDMzIEwgMTE3IDM5IEwgMTEyIDM5IFogTSAxMTIgMzMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDc1Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3NiI+CiAgPHBhdGggZD0iTSAxMTcgMzEgTCAxMjIgMzEgTCAxMjIgMzggTCAxMTcgMzggWiBNIDExNyAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzciPgogIDxwYXRoIGQ9Ik0gOTkuMzc1IDQyLjY3MTg3NSBMIDE4OS42MDE1NjIgNDIuNjcxODc1IEMgMTkyLjA2NjQwNiA0Mi42NzE4NzUgMTkyLjA2NjQwNiAzNC44NjcxODggMTkyLjA2NjQwNiAyOC45NzY1NjIgQyAxOTIuMDY2NDA2IDIzLjA4NTkzOCAxOTIuMDY2NDA2IDE1LjI4MTI1IDE4OS42MDE1NjIgMTUuMjgxMjUgTCA5OS4zNzUgMTUuMjgxMjUgQyA5Ni45MTAxNTYgMTUuMjgxMjUgOTYuOTEwMTU2IDIzLjA4NTkzOCA5Ni45MTAxNTYgMjguOTc2NTYyIEMgOTYuOTEwMTU2IDM0Ljg2NzE4OCA5Ni45MTAxNTYgNDIuNjcxODc1IDk5LjM3NSA0Mi42NzE4NzUgWiBNIDk5LjM3NSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDc4Ij4KICA8cGF0aCBkPSJNIDEyMSAzMyBMIDEyNiAzMyBMIDEyNiAzOSBMIDEyMSAzOSBaIE0gMTIxIDMzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3OSI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODAiPgogIDxwYXRoIGQ9Ik0gMTI2IDMxIEwgMTMxIDMxIEwgMTMxIDM4IEwgMTI2IDM4IFogTSAxMjYgMzEgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDgxIj4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4MiI+CiAgPHBhdGggZD0iTSAxMzEgMzEgTCAxMzMgMzEgTCAxMzMgMzggTCAxMzEgMzggWiBNIDEzMSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODMiPgogIDxwYXRoIGQ9Ik0gOTkuMzc1IDQyLjY3MTg3NSBMIDE4OS42MDE1NjIgNDIuNjcxODc1IEMgMTkyLjA2NjQwNiA0Mi42NzE4NzUgMTkyLjA2NjQwNiAzNC44NjcxODggMTkyLjA2NjQwNiAyOC45NzY1NjIgQyAxOTIuMDY2NDA2IDIzLjA4NTkzOCAxOTIuMDY2NDA2IDE1LjI4MTI1IDE4OS42MDE1NjIgMTUuMjgxMjUgTCA5OS4zNzUgMTUuMjgxMjUgQyA5Ni45MTAxNTYgMTUuMjgxMjUgOTYuOTEwMTU2IDIzLjA4NTkzOCA5Ni45MTAxNTYgMjguOTc2NTYyIEMgOTYuOTEwMTU2IDM0Ljg2NzE4OCA5Ni45MTAxNTYgNDIuNjcxODc1IDk5LjM3NSA0Mi42NzE4NzUgWiBNIDk5LjM3NSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDg0Ij4KICA8cGF0aCBkPSJNIDEzMyAzMyBMIDEzOCAzMyBMIDEzOCAzOSBMIDEzMyAzOSBaIE0gMTMzIDMzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4NSI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODYiPgogIDxwYXRoIGQ9Ik0gMTA5IDIwIEwgMTE2IDIwIEwgMTE2IDI3IEwgMTA5IDI3IFogTSAxMDkgMjAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDg3Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4OCI+CiAgPHBhdGggZD0iTSAxMTUgMjAgTCAxMjIgMjAgTCAxMjIgMjcgTCAxMTUgMjcgWiBNIDExNSAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODkiPgogIDxwYXRoIGQ9Ik0gOTkuMzc1IDQyLjY3MTg3NSBMIDE4OS42MDE1NjIgNDIuNjcxODc1IEMgMTkyLjA2NjQwNiA0Mi42NzE4NzUgMTkyLjA2NjQwNiAzNC44NjcxODggMTkyLjA2NjQwNiAyOC45NzY1NjIgQyAxOTIuMDY2NDA2IDIzLjA4NTkzOCAxOTIuMDY2NDA2IDE1LjI4MTI1IDE4OS42MDE1NjIgMTUuMjgxMjUgTCA5OS4zNzUgMTUuMjgxMjUgQyA5Ni45MTAxNTYgMTUuMjgxMjUgOTYuOTEwMTU2IDIzLjA4NTkzOCA5Ni45MTAxNTYgMjguOTc2NTYyIEMgOTYuOTEwMTU2IDM0Ljg2NzE4OCA5Ni45MTAxNTYgNDIuNjcxODc1IDk5LjM3NSA0Mi42NzE4NzUgWiBNIDk5LjM3NSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDkwIj4KICA8cGF0aCBkPSJNIDEyMSAyMCBMIDEyOSAyMCBMIDEyOSAyNyBMIDEyMSAyNyBaIE0gMTIxIDIwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5MSI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTIiPgogIDxwYXRoIGQ9Ik0gMTI4IDIzIEwgMTMyIDIzIEwgMTMyIDI5IEwgMTI4IDI5IFogTSAxMjggMjMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDkzIj4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5NCI+CiAgPHBhdGggZD0iTSAxNTEgMjQgTCAxNTYgMjQgTCAxNTYgMzIgTCAxNTEgMzIgWiBNIDE1MSAyNCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTUiPgogIDxwYXRoIGQ9Ik0gOTkuMzc1IDQyLjY3MTg3NSBMIDE4OS42MDE1NjIgNDIuNjcxODc1IEMgMTkyLjA2NjQwNiA0Mi42NzE4NzUgMTkyLjA2NjQwNiAzNC44NjcxODggMTkyLjA2NjQwNiAyOC45NzY1NjIgQyAxOTIuMDY2NDA2IDIzLjA4NTkzOCAxOTIuMDY2NDA2IDE1LjI4MTI1IDE4OS42MDE1NjIgMTUuMjgxMjUgTCA5OS4zNzUgMTUuMjgxMjUgQyA5Ni45MTAxNTYgMTUuMjgxMjUgOTYuOTEwMTU2IDIzLjA4NTkzOCA5Ni45MTAxNTYgMjguOTc2NTYyIEMgOTYuOTEwMTU2IDM0Ljg2NzE4OCA5Ni45MTAxNTYgNDIuNjcxODc1IDk5LjM3NSA0Mi42NzE4NzUgWiBNIDk5LjM3NSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDk2Ij4KICA8cGF0aCBkPSJNIDE1NiAyNCBMIDE1OSAyNCBMIDE1OSAzMiBMIDE1NiAzMiBaIE0gMTU2IDI0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5NyI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTgiPgogIDxwYXRoIGQ9Ik0gMTU5IDI2IEwgMTY0IDI2IEwgMTY0IDMyIEwgMTU5IDMyIFogTSAxNTkgMjYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDk5Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDAiPgogIDxwYXRoIGQ9Ik0gMTY2IDI0IEwgMTcxIDI0IEwgMTcxIDMyIEwgMTY2IDMyIFogTSAxNjYgMjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwMSI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTAyIj4KICA8cGF0aCBkPSJNIDE3MSAyNiBMIDE3NiAyNiBMIDE3NiAzMiBMIDE3MSAzMiBaIE0gMTcxIDI2ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDMiPgogIDxwYXRoIGQ9Ik0gOTkuMzc1IDQyLjY3MTg3NSBMIDE4OS42MDE1NjIgNDIuNjcxODc1IEMgMTkyLjA2NjQwNiA0Mi42NzE4NzUgMTkyLjA2NjQwNiAzNC44NjcxODggMTkyLjA2NjQwNiAyOC45NzY1NjIgQyAxOTIuMDY2NDA2IDIzLjA4NTkzOCAxOTIuMDY2NDA2IDE1LjI4MTI1IDE4OS42MDE1NjIgMTUuMjgxMjUgTCA5OS4zNzUgMTUuMjgxMjUgQyA5Ni45MTAxNTYgMTUuMjgxMjUgOTYuOTEwMTU2IDIzLjA4NTkzOCA5Ni45MTAxNTYgMjguOTc2NTYyIEMgOTYuOTEwMTU2IDM0Ljg2NzE4OCA5Ni45MTAxNTYgNDIuNjcxODc1IDk5LjM3NSA0Mi42NzE4NzUgWiBNIDk5LjM3NSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwNCI+CiAgPHBhdGggZD0iTSAxNzUgMjUgTCAxNzkgMjUgTCAxNzkgMzIgTCAxNzUgMzIgWiBNIDE3NSAyNSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTA1Ij4KICA8cGF0aCBkPSJNIDk5LjM3NSA0Mi42NzE4NzUgTCAxODkuNjAxNTYyIDQyLjY3MTg3NSBDIDE5Mi4wNjY0MDYgNDIuNjcxODc1IDE5Mi4wNjY0MDYgMzQuODY3MTg4IDE5Mi4wNjY0MDYgMjguOTc2NTYyIEMgMTkyLjA2NjQwNiAyMy4wODU5MzggMTkyLjA2NjQwNiAxNS4yODEyNSAxODkuNjAxNTYyIDE1LjI4MTI1IEwgOTkuMzc1IDE1LjI4MTI1IEMgOTYuOTEwMTU2IDE1LjI4MTI1IDk2LjkxMDE1NiAyMy4wODU5MzggOTYuOTEwMTU2IDI4Ljk3NjU2MiBDIDk2LjkxMDE1NiAzNC44NjcxODggOTYuOTEwMTU2IDQyLjY3MTg3NSA5OS4zNzUgNDIuNjcxODc1IFogTSA5OS4zNzUgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDYiPgogIDxwYXRoIGQ9Ik0gMTc4IDI2IEwgMTgzIDI2IEwgMTgzIDMyIEwgMTc4IDMyIFogTSAxNzggMjYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwNyI+CiAgPHBhdGggZD0iTSA5OS4zNzUgNDIuNjcxODc1IEwgMTg5LjYwMTU2MiA0Mi42NzE4NzUgQyAxOTIuMDY2NDA2IDQyLjY3MTg3NSAxOTIuMDY2NDA2IDM0Ljg2NzE4OCAxOTIuMDY2NDA2IDI4Ljk3NjU2MiBDIDE5Mi4wNjY0MDYgMjMuMDg1OTM4IDE5Mi4wNjY0MDYgMTUuMjgxMjUgMTg5LjYwMTU2MiAxNS4yODEyNSBMIDk5LjM3NSAxNS4yODEyNSBDIDk2LjkxMDE1NiAxNS4yODEyNSA5Ni45MTAxNTYgMjMuMDg1OTM4IDk2LjkxMDE1NiAyOC45NzY1NjIgQyA5Ni45MTAxNTYgMzQuODY3MTg4IDk2LjkxMDE1NiA0Mi42NzE4NzUgOTkuMzc1IDQyLjY3MTg3NSBaIE0gOTkuMzc1IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTA4Ij4KICA8cGF0aCBkPSJNIDIwMSAzMSBMIDIwNiAzMSBMIDIwNiAzOSBMIDIwMSAzOSBaIE0gMjAxIDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDkiPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMTAiPgogIDxwYXRoIGQ9Ik0gMjA2IDMzIEwgMjEyIDMzIEwgMjEyIDM5IEwgMjA2IDM5IFogTSAyMDYgMzMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExMSI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExMiI+CiAgPHBhdGggZD0iTSAyMTIgMzMgTCAyMTkgMzMgTCAyMTkgMzggTCAyMTIgMzggWiBNIDIxMiAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTEzIj4KICA8cGF0aCBkPSJNIDE5NS41MTk1MzEgNDIuNjcxODc1IEwgMzA1LjQ2ODc1IDQyLjY3MTg3NSBDIDMwNy45MzM1OTQgNDIuNjcxODc1IDMwNy45MzM1OTQgMzQuODY3MTg4IDMwNy45MzM1OTQgMjguOTc2NTYyIEMgMzA3LjkzMzU5NCAyMy4wODU5MzggMzA3LjkzMzU5NCAxNS4yODEyNSAzMDUuNDY4NzUgMTUuMjgxMjUgTCAxOTUuNTE5NTMxIDE1LjI4MTI1IEMgMTkzLjA1NDY4OCAxNS4yODEyNSAxOTMuMDU0Njg4IDIzLjA4NTkzOCAxOTMuMDU0Njg4IDI4Ljk3NjU2MiBDIDE5My4wNTQ2ODggMzQuODY3MTg4IDE5My4wNTQ2ODggNDIuNjcxODc1IDE5NS41MTk1MzEgNDIuNjcxODc1IFogTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTE0Ij4KICA8cGF0aCBkPSJNIDIxOSAzMyBMIDIyNCAzMyBMIDIyNCAzOSBMIDIxOSAzOSBaIE0gMjE5IDMzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMTUiPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMTYiPgogIDxwYXRoIGQ9Ik0gMjI0IDM3IEwgMjI2IDM3IEwgMjI2IDM4IEwgMjI0IDM4IFogTSAyMjQgMzcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExNyI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExOCI+CiAgPHBhdGggZD0iTSAyMjYgMzMgTCAyMzEgMzMgTCAyMzEgMzkgTCAyMjYgMzkgWiBNIDIyNiAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTE5Ij4KICA8cGF0aCBkPSJNIDE5NS41MTk1MzEgNDIuNjcxODc1IEwgMzA1LjQ2ODc1IDQyLjY3MTg3NSBDIDMwNy45MzM1OTQgNDIuNjcxODc1IDMwNy45MzM1OTQgMzQuODY3MTg4IDMwNy45MzM1OTQgMjguOTc2NTYyIEMgMzA3LjkzMzU5NCAyMy4wODU5MzggMzA3LjkzMzU5NCAxNS4yODEyNSAzMDUuNDY4NzUgMTUuMjgxMjUgTCAxOTUuNTE5NTMxIDE1LjI4MTI1IEMgMTkzLjA1NDY4OCAxNS4yODEyNSAxOTMuMDU0Njg4IDIzLjA4NTkzOCAxOTMuMDU0Njg4IDI4Ljk3NjU2MiBDIDE5My4wNTQ2ODggMzQuODY3MTg4IDE5My4wNTQ2ODggNDIuNjcxODc1IDE5NS41MTk1MzEgNDIuNjcxODc1IFogTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTIwIj4KICA8cGF0aCBkPSJNIDIwNCAyMCBMIDIxMSAyMCBMIDIxMSAyNyBMIDIwNCAyNyBaIE0gMjA0IDIwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjEiPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjIiPgogIDxwYXRoIGQ9Ik0gMjEwIDIwIEwgMjE3IDIwIEwgMjE3IDI3IEwgMjEwIDI3IFogTSAyMTAgMjAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyMyI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyNCI+CiAgPHBhdGggZD0iTSAyMTYgMjAgTCAyMjQgMjAgTCAyMjQgMjcgTCAyMTYgMjcgWiBNIDIxNiAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTI1Ij4KICA8cGF0aCBkPSJNIDE5NS41MTk1MzEgNDIuNjcxODc1IEwgMzA1LjQ2ODc1IDQyLjY3MTg3NSBDIDMwNy45MzM1OTQgNDIuNjcxODc1IDMwNy45MzM1OTQgMzQuODY3MTg4IDMwNy45MzM1OTQgMjguOTc2NTYyIEMgMzA3LjkzMzU5NCAyMy4wODU5MzggMzA3LjkzMzU5NCAxNS4yODEyNSAzMDUuNDY4NzUgMTUuMjgxMjUgTCAxOTUuNTE5NTMxIDE1LjI4MTI1IEMgMTkzLjA1NDY4OCAxNS4yODEyNSAxOTMuMDU0Njg4IDIzLjA4NTkzOCAxOTMuMDU0Njg4IDI4Ljk3NjU2MiBDIDE5My4wNTQ2ODggMzQuODY3MTg4IDE5My4wNTQ2ODggNDIuNjcxODc1IDE5NS41MTk1MzEgNDIuNjcxODc1IFogTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTI2Ij4KICA8cGF0aCBkPSJNIDIyMyAyMyBMIDIyNyAyMyBMIDIyNyAyOSBMIDIyMyAyOSBaIE0gMjIzIDIzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjciPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjgiPgogIDxwYXRoIGQ9Ik0gMjU1IDI0IEwgMjYxIDI0IEwgMjYxIDMyIEwgMjU1IDMyIFogTSAyNTUgMjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyOSI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzMCI+CiAgPHBhdGggZD0iTSAyNjEgMjQgTCAyNjQgMjQgTCAyNjQgMzIgTCAyNjEgMzIgWiBNIDI2MSAyNCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTMxIj4KICA8cGF0aCBkPSJNIDE5NS41MTk1MzEgNDIuNjcxODc1IEwgMzA1LjQ2ODc1IDQyLjY3MTg3NSBDIDMwNy45MzM1OTQgNDIuNjcxODc1IDMwNy45MzM1OTQgMzQuODY3MTg4IDMwNy45MzM1OTQgMjguOTc2NTYyIEMgMzA3LjkzMzU5NCAyMy4wODU5MzggMzA3LjkzMzU5NCAxNS4yODEyNSAzMDUuNDY4NzUgMTUuMjgxMjUgTCAxOTUuNTE5NTMxIDE1LjI4MTI1IEMgMTkzLjA1NDY4OCAxNS4yODEyNSAxOTMuMDU0Njg4IDIzLjA4NTkzOCAxOTMuMDU0Njg4IDI4Ljk3NjU2MiBDIDE5My4wNTQ2ODggMzQuODY3MTg4IDE5My4wNTQ2ODggNDIuNjcxODc1IDE5NS41MTk1MzEgNDIuNjcxODc1IFogTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTMyIj4KICA8cGF0aCBkPSJNIDI2NCAyNiBMIDI2OSAyNiBMIDI2OSAzMiBMIDI2NCAzMiBaIE0gMjY0IDI2ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzMiPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzQiPgogIDxwYXRoIGQ9Ik0gMjcwIDI0IEwgMjc2IDI0IEwgMjc2IDMyIEwgMjcwIDMyIFogTSAyNzAgMjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzNSI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzNiI+CiAgPHBhdGggZD0iTSAyNzYgMjYgTCAyODEgMjYgTCAyODEgMzIgTCAyNzYgMzIgWiBNIDI3NiAyNiAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTM3Ij4KICA8cGF0aCBkPSJNIDE5NS41MTk1MzEgNDIuNjcxODc1IEwgMzA1LjQ2ODc1IDQyLjY3MTg3NSBDIDMwNy45MzM1OTQgNDIuNjcxODc1IDMwNy45MzM1OTQgMzQuODY3MTg4IDMwNy45MzM1OTQgMjguOTc2NTYyIEMgMzA3LjkzMzU5NCAyMy4wODU5MzggMzA3LjkzMzU5NCAxNS4yODEyNSAzMDUuNDY4NzUgMTUuMjgxMjUgTCAxOTUuNTE5NTMxIDE1LjI4MTI1IEMgMTkzLjA1NDY4OCAxNS4yODEyNSAxOTMuMDU0Njg4IDIzLjA4NTkzOCAxOTMuMDU0Njg4IDI4Ljk3NjU2MiBDIDE5My4wNTQ2ODggMzQuODY3MTg4IDE5My4wNTQ2ODggNDIuNjcxODc1IDE5NS41MTk1MzEgNDIuNjcxODc1IFogTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTM4Ij4KICA8cGF0aCBkPSJNIDI4MCAyNSBMIDI4MyAyNSBMIDI4MyAzMiBMIDI4MCAzMiBaIE0gMjgwIDI1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzkiPgogIDxwYXRoIGQ9Ik0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgTCAzMDUuNDY4NzUgNDIuNjcxODc1IEMgMzA3LjkzMzU5NCA0Mi42NzE4NzUgMzA3LjkzMzU5NCAzNC44NjcxODggMzA3LjkzMzU5NCAyOC45NzY1NjIgQyAzMDcuOTMzNTk0IDIzLjA4NTkzOCAzMDcuOTMzNTk0IDE1LjI4MTI1IDMwNS40Njg3NSAxNS4yODEyNSBMIDE5NS41MTk1MzEgMTUuMjgxMjUgQyAxOTMuMDU0Njg4IDE1LjI4MTI1IDE5My4wNTQ2ODggMjMuMDg1OTM4IDE5My4wNTQ2ODggMjguOTc2NTYyIEMgMTkzLjA1NDY4OCAzNC44NjcxODggMTkzLjA1NDY4OCA0Mi42NzE4NzUgMTk1LjUxOTUzMSA0Mi42NzE4NzUgWiBNIDE5NS41MTk1MzEgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNDAiPgogIDxwYXRoIGQ9Ik0gMjgzIDI2IEwgMjg4IDI2IEwgMjg4IDMyIEwgMjgzIDMyIFogTSAyODMgMjYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0MSI+CiAgPHBhdGggZD0iTSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBMIDMwNS40Njg3NSA0Mi42NzE4NzUgQyAzMDcuOTMzNTk0IDQyLjY3MTg3NSAzMDcuOTMzNTk0IDM0Ljg2NzE4OCAzMDcuOTMzNTk0IDI4Ljk3NjU2MiBDIDMwNy45MzM1OTQgMjMuMDg1OTM4IDMwNy45MzM1OTQgMTUuMjgxMjUgMzA1LjQ2ODc1IDE1LjI4MTI1IEwgMTk1LjUxOTUzMSAxNS4yODEyNSBDIDE5My4wNTQ2ODggMTUuMjgxMjUgMTkzLjA1NDY4OCAyMy4wODU5MzggMTkzLjA1NDY4OCAyOC45NzY1NjIgQyAxOTMuMDU0Njg4IDM0Ljg2NzE4OCAxOTMuMDU0Njg4IDQyLjY3MTg3NSAxOTUuNTE5NTMxIDQyLjY3MTg3NSBaIE0gMTk1LjUxOTUzMSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0MiI+CiAgPHBhdGggZD0iTSAzMjMgMzEgTCAzMjkgMzEgTCAzMjkgMzggTCAzMjMgMzggWiBNIDMyMyAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQzIj4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0NCI+CiAgPHBhdGggZD0iTSAzMjkgMzEgTCAzMzUgMzEgTCAzMzUgMzggTCAzMjkgMzggWiBNIDMyOSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ1Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0NiI+CiAgPHBhdGggZD0iTSAzMzUgMzEgTCAzNDEgMzEgTCAzNDEgMzggTCAzMzUgMzggWiBNIDMzNSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ3Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0OCI+CiAgPHBhdGggZD0iTSAzNDEgMzEgTCAzNDggMzEgTCAzNDggMzggTCAzNDEgMzggWiBNIDM0MSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ5Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1MCI+CiAgPHBhdGggZD0iTSAzNDggMzEgTCAzNTUgMzEgTCAzNTUgMzggTCAzNDggMzggWiBNIDM0OCAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTUxIj4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1MiI+CiAgPHBhdGggZD0iTSAzNTUgMzEgTCAzNjEgMzEgTCAzNjEgMzggTCAzNTUgMzggWiBNIDM1NSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTUzIj4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1NCI+CiAgPHBhdGggZD0iTSAzMjkgMjAgTCAzMzYgMjAgTCAzMzYgMjcgTCAzMjkgMjcgWiBNIDMyOSAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTU1Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1NiI+CiAgPHBhdGggZD0iTSAzMzUgMjAgTCAzNDMgMjAgTCAzNDMgMjcgTCAzMzUgMjcgWiBNIDMzNSAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTU3Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1OCI+CiAgPHBhdGggZD0iTSAzNDMgMjAgTCAzNTAgMjAgTCAzNTAgMjcgTCAzNDMgMjcgWiBNIDM0MyAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTU5Ij4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE2MCI+CiAgPHBhdGggZD0iTSAzNTAgMjMgTCAzNTQgMjMgTCAzNTQgMjkgTCAzNTAgMjkgWiBNIDM1MCAyMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTYxIj4KICA8cGF0aCBkPSJNIDMxMS4zODI4MTIgNDIuNjcxODc1IEwgMzY5LjU2MjUgNDIuNjcxODc1IEMgMzcyLjAyNzM0NCA0Mi42NzE4NzUgMzcyLjAyNzM0NCAzNC44NjcxODggMzcyLjAyNzM0NCAyOC45NzY1NjIgQyAzNzIuMDI3MzQ0IDIzLjA4NTkzOCAzNzIuMDI3MzQ0IDE1LjI4MTI1IDM2OS41NjI1IDE1LjI4MTI1IEwgMzExLjM4MjgxMiAxNS4yODEyNSBDIDMwOC45MTc5NjkgMTUuMjgxMjUgMzA4LjkxNzk2OSAyMy4wODU5MzggMzA4LjkxNzk2OSAyOC45NzY1NjIgQyAzMDguOTE3OTY5IDM0Ljg2NzE4OCAzMDguOTE3OTY5IDQyLjY3MTg3NSAzMTEuMzgyODEyIDQyLjY3MTg3NSBaIE0gMzExLjM4MjgxMiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE2MiI+CiAgPHBhdGggZD0iTSAzOTEgMzEgTCAzOTggMzEgTCAzOTggMzggTCAzOTEgMzggWiBNIDM5MSAzMSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTYzIj4KICA8cGF0aCBkPSJNIDM3NS40ODA0NjkgNDIuNjcxODc1IEwgNDM2LjEyNSA0Mi42NzE4NzUgQyA0MzguNTg5ODQ0IDQyLjY3MTg3NSA0MzguNTg5ODQ0IDM0Ljg2NzE4OCA0MzguNTg5ODQ0IDI4Ljk3NjU2MiBDIDQzOC41ODk4NDQgMjMuMDg1OTM4IDQzOC41ODk4NDQgMTUuMjgxMjUgNDM2LjEyNSAxNS4yODEyNSBMIDM3NS40ODA0NjkgMTUuMjgxMjUgQyAzNzMuMDE1NjI1IDE1LjI4MTI1IDM3My4wMTU2MjUgMjMuMDg1OTM4IDM3My4wMTU2MjUgMjguOTc2NTYyIEMgMzczLjAxNTYyNSAzNC44NjcxODggMzczLjAxNTYyNSA0Mi42NzE4NzUgMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgWiBNIDM3NS40ODA0NjkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNjQiPgogIDxwYXRoIGQ9Ik0gMzk4IDMzIEwgNDAzIDMzIEwgNDAzIDM5IEwgMzk4IDM5IFogTSAzOTggMzMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE2NSI+CiAgPHBhdGggZD0iTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBMIDQzNi4xMjUgNDIuNjcxODc1IEMgNDM4LjU4OTg0NCA0Mi42NzE4NzUgNDM4LjU4OTg0NCAzNC44NjcxODggNDM4LjU4OTg0NCAyOC45NzY1NjIgQyA0MzguNTg5ODQ0IDIzLjA4NTkzOCA0MzguNTg5ODQ0IDE1LjI4MTI1IDQzNi4xMjUgMTUuMjgxMjUgTCAzNzUuNDgwNDY5IDE1LjI4MTI1IEMgMzczLjAxNTYyNSAxNS4yODEyNSAzNzMuMDE1NjI1IDIzLjA4NTkzOCAzNzMuMDE1NjI1IDI4Ljk3NjU2MiBDIDM3My4wMTU2MjUgMzQuODY3MTg4IDM3My4wMTU2MjUgNDIuNjcxODc1IDM3NS40ODA0NjkgNDIuNjcxODc1IFogTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTY2Ij4KICA8cGF0aCBkPSJNIDQwMyAzMSBMIDQwOCAzMSBMIDQwOCAzOCBMIDQwMyAzOCBaIE0gNDAzIDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNjciPgogIDxwYXRoIGQ9Ik0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgTCA0MzYuMTI1IDQyLjY3MTg3NSBDIDQzOC41ODk4NDQgNDIuNjcxODc1IDQzOC41ODk4NDQgMzQuODY3MTg4IDQzOC41ODk4NDQgMjguOTc2NTYyIEMgNDM4LjU4OTg0NCAyMy4wODU5MzggNDM4LjU4OTg0NCAxNS4yODEyNSA0MzYuMTI1IDE1LjI4MTI1IEwgMzc1LjQ4MDQ2OSAxNS4yODEyNSBDIDM3My4wMTU2MjUgMTUuMjgxMjUgMzczLjAxNTYyNSAyMy4wODU5MzggMzczLjAxNTYyNSAyOC45NzY1NjIgQyAzNzMuMDE1NjI1IDM0Ljg2NzE4OCAzNzMuMDE1NjI1IDQyLjY3MTg3NSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBaIE0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE2OCI+CiAgPHBhdGggZD0iTSA0MDcgMzMgTCA0MTIgMzMgTCA0MTIgMzkgTCA0MDcgMzkgWiBNIDQwNyAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTY5Ij4KICA8cGF0aCBkPSJNIDM3NS40ODA0NjkgNDIuNjcxODc1IEwgNDM2LjEyNSA0Mi42NzE4NzUgQyA0MzguNTg5ODQ0IDQyLjY3MTg3NSA0MzguNTg5ODQ0IDM0Ljg2NzE4OCA0MzguNTg5ODQ0IDI4Ljk3NjU2MiBDIDQzOC41ODk4NDQgMjMuMDg1OTM4IDQzOC41ODk4NDQgMTUuMjgxMjUgNDM2LjEyNSAxNS4yODEyNSBMIDM3NS40ODA0NjkgMTUuMjgxMjUgQyAzNzMuMDE1NjI1IDE1LjI4MTI1IDM3My4wMTU2MjUgMjMuMDg1OTM4IDM3My4wMTU2MjUgMjguOTc2NTYyIEMgMzczLjAxNTYyNSAzNC44NjcxODggMzczLjAxNTYyNSA0Mi42NzE4NzUgMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgWiBNIDM3NS40ODA0NjkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNzAiPgogIDxwYXRoIGQ9Ik0gNDEyIDMxIEwgNDE3IDMxIEwgNDE3IDM4IEwgNDEyIDM4IFogTSA0MTIgMzEgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE3MSI+CiAgPHBhdGggZD0iTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBMIDQzNi4xMjUgNDIuNjcxODc1IEMgNDM4LjU4OTg0NCA0Mi42NzE4NzUgNDM4LjU4OTg0NCAzNC44NjcxODggNDM4LjU4OTg0NCAyOC45NzY1NjIgQyA0MzguNTg5ODQ0IDIzLjA4NTkzOCA0MzguNTg5ODQ0IDE1LjI4MTI1IDQzNi4xMjUgMTUuMjgxMjUgTCAzNzUuNDgwNDY5IDE1LjI4MTI1IEMgMzczLjAxNTYyNSAxNS4yODEyNSAzNzMuMDE1NjI1IDIzLjA4NTkzOCAzNzMuMDE1NjI1IDI4Ljk3NjU2MiBDIDM3My4wMTU2MjUgMzQuODY3MTg4IDM3My4wMTU2MjUgNDIuNjcxODc1IDM3NS40ODA0NjkgNDIuNjcxODc1IFogTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTcyIj4KICA8cGF0aCBkPSJNIDQxNyAzMSBMIDQxOSAzMSBMIDQxOSAzOCBMIDQxNyAzOCBaIE0gNDE3IDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNzMiPgogIDxwYXRoIGQ9Ik0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgTCA0MzYuMTI1IDQyLjY3MTg3NSBDIDQzOC41ODk4NDQgNDIuNjcxODc1IDQzOC41ODk4NDQgMzQuODY3MTg4IDQzOC41ODk4NDQgMjguOTc2NTYyIEMgNDM4LjU4OTg0NCAyMy4wODU5MzggNDM4LjU4OTg0NCAxNS4yODEyNSA0MzYuMTI1IDE1LjI4MTI1IEwgMzc1LjQ4MDQ2OSAxNS4yODEyNSBDIDM3My4wMTU2MjUgMTUuMjgxMjUgMzczLjAxNTYyNSAyMy4wODU5MzggMzczLjAxNTYyNSAyOC45NzY1NjIgQyAzNzMuMDE1NjI1IDM0Ljg2NzE4OCAzNzMuMDE1NjI1IDQyLjY3MTg3NSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBaIE0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE3NCI+CiAgPHBhdGggZD0iTSA0MTkgMzMgTCA0MjQgMzMgTCA0MjQgMzkgTCA0MTkgMzkgWiBNIDQxOSAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTc1Ij4KICA8cGF0aCBkPSJNIDM3NS40ODA0NjkgNDIuNjcxODc1IEwgNDM2LjEyNSA0Mi42NzE4NzUgQyA0MzguNTg5ODQ0IDQyLjY3MTg3NSA0MzguNTg5ODQ0IDM0Ljg2NzE4OCA0MzguNTg5ODQ0IDI4Ljk3NjU2MiBDIDQzOC41ODk4NDQgMjMuMDg1OTM4IDQzOC41ODk4NDQgMTUuMjgxMjUgNDM2LjEyNSAxNS4yODEyNSBMIDM3NS40ODA0NjkgMTUuMjgxMjUgQyAzNzMuMDE1NjI1IDE1LjI4MTI1IDM3My4wMTU2MjUgMjMuMDg1OTM4IDM3My4wMTU2MjUgMjguOTc2NTYyIEMgMzczLjAxNTYyNSAzNC44NjcxODggMzczLjAxNTYyNSA0Mi42NzE4NzUgMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgWiBNIDM3NS40ODA0NjkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNzYiPgogIDxwYXRoIGQ9Ik0gMzk0IDIwIEwgNDAxIDIwIEwgNDAxIDI3IEwgMzk0IDI3IFogTSAzOTQgMjAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE3NyI+CiAgPHBhdGggZD0iTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBMIDQzNi4xMjUgNDIuNjcxODc1IEMgNDM4LjU4OTg0NCA0Mi42NzE4NzUgNDM4LjU4OTg0NCAzNC44NjcxODggNDM4LjU4OTg0NCAyOC45NzY1NjIgQyA0MzguNTg5ODQ0IDIzLjA4NTkzOCA0MzguNTg5ODQ0IDE1LjI4MTI1IDQzNi4xMjUgMTUuMjgxMjUgTCAzNzUuNDgwNDY5IDE1LjI4MTI1IEMgMzczLjAxNTYyNSAxNS4yODEyNSAzNzMuMDE1NjI1IDIzLjA4NTkzOCAzNzMuMDE1NjI1IDI4Ljk3NjU2MiBDIDM3My4wMTU2MjUgMzQuODY3MTg4IDM3My4wMTU2MjUgNDIuNjcxODc1IDM3NS40ODA0NjkgNDIuNjcxODc1IFogTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTc4Ij4KICA8cGF0aCBkPSJNIDQwMSAyMCBMIDQwOCAyMCBMIDQwOCAyNyBMIDQwMSAyNyBaIE0gNDAxIDIwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNzkiPgogIDxwYXRoIGQ9Ik0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgTCA0MzYuMTI1IDQyLjY3MTg3NSBDIDQzOC41ODk4NDQgNDIuNjcxODc1IDQzOC41ODk4NDQgMzQuODY3MTg4IDQzOC41ODk4NDQgMjguOTc2NTYyIEMgNDM4LjU4OTg0NCAyMy4wODU5MzggNDM4LjU4OTg0NCAxNS4yODEyNSA0MzYuMTI1IDE1LjI4MTI1IEwgMzc1LjQ4MDQ2OSAxNS4yODEyNSBDIDM3My4wMTU2MjUgMTUuMjgxMjUgMzczLjAxNTYyNSAyMy4wODU5MzggMzczLjAxNTYyNSAyOC45NzY1NjIgQyAzNzMuMDE1NjI1IDM0Ljg2NzE4OCAzNzMuMDE1NjI1IDQyLjY3MTg3NSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBaIE0gMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE4MCI+CiAgPHBhdGggZD0iTSA0MDggMjAgTCA0MTYgMjAgTCA0MTYgMjcgTCA0MDggMjcgWiBNIDQwOCAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTgxIj4KICA8cGF0aCBkPSJNIDM3NS40ODA0NjkgNDIuNjcxODc1IEwgNDM2LjEyNSA0Mi42NzE4NzUgQyA0MzguNTg5ODQ0IDQyLjY3MTg3NSA0MzguNTg5ODQ0IDM0Ljg2NzE4OCA0MzguNTg5ODQ0IDI4Ljk3NjU2MiBDIDQzOC41ODk4NDQgMjMuMDg1OTM4IDQzOC41ODk4NDQgMTUuMjgxMjUgNDM2LjEyNSAxNS4yODEyNSBMIDM3NS40ODA0NjkgMTUuMjgxMjUgQyAzNzMuMDE1NjI1IDE1LjI4MTI1IDM3My4wMTU2MjUgMjMuMDg1OTM4IDM3My4wMTU2MjUgMjguOTc2NTYyIEMgMzczLjAxNTYyNSAzNC44NjcxODggMzczLjAxNTYyNSA0Mi42NzE4NzUgMzc1LjQ4MDQ2OSA0Mi42NzE4NzUgWiBNIDM3NS40ODA0NjkgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxODIiPgogIDxwYXRoIGQ9Ik0gNDE1IDIzIEwgNDE5IDIzIEwgNDE5IDI5IEwgNDE1IDI5IFogTSA0MTUgMjMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE4MyI+CiAgPHBhdGggZD0iTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSBMIDQzNi4xMjUgNDIuNjcxODc1IEMgNDM4LjU4OTg0NCA0Mi42NzE4NzUgNDM4LjU4OTg0NCAzNC44NjcxODggNDM4LjU4OTg0NCAyOC45NzY1NjIgQyA0MzguNTg5ODQ0IDIzLjA4NTkzOCA0MzguNTg5ODQ0IDE1LjI4MTI1IDQzNi4xMjUgMTUuMjgxMjUgTCAzNzUuNDgwNDY5IDE1LjI4MTI1IEMgMzczLjAxNTYyNSAxNS4yODEyNSAzNzMuMDE1NjI1IDIzLjA4NTkzOCAzNzMuMDE1NjI1IDI4Ljk3NjU2MiBDIDM3My4wMTU2MjUgMzQuODY3MTg4IDM3My4wMTU2MjUgNDIuNjcxODc1IDM3NS40ODA0NjkgNDIuNjcxODc1IFogTSAzNzUuNDgwNDY5IDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTg0Ij4KICA8cGF0aCBkPSJNIDQ1OCAzMSBMIDQ2MyAzMSBMIDQ2MyAzOSBMIDQ1OCAzOSBaIE0gNDU4IDMxICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxODUiPgogIDxwYXRoIGQ9Ik0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgTCA1MDAuMjE4NzUgNDIuNjcxODc1IEMgNTAyLjY4MzU5NCA0Mi42NzE4NzUgNTAyLjY4MzU5NCAzNC44NjcxODggNTAyLjY4MzU5NCAyOC45NzY1NjIgQyA1MDIuNjgzNTk0IDIzLjA4NTkzOCA1MDIuNjgzNTk0IDE1LjI4MTI1IDUwMC4yMTg3NSAxNS4yODEyNSBMIDQ0Mi4wMzkwNjIgMTUuMjgxMjUgQyA0MzkuNTc0MjE5IDE1LjI4MTI1IDQzOS41NzQyMTkgMjMuMDg1OTM4IDQzOS41NzQyMTkgMjguOTc2NTYyIEMgNDM5LjU3NDIxOSAzNC44NjcxODggNDM5LjU3NDIxOSA0Mi42NzE4NzUgNDQyLjAzOTA2MiA0Mi42NzE4NzUgWiBNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxODYiPgogIDxwYXRoIGQ9Ik0gNDYzIDMzIEwgNDY4IDMzIEwgNDY4IDM5IEwgNDYzIDM5IFogTSA0NjMgMzMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE4NyI+CiAgPHBhdGggZD0iTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBMIDUwMC4yMTg3NSA0Mi42NzE4NzUgQyA1MDIuNjgzNTk0IDQyLjY3MTg3NSA1MDIuNjgzNTk0IDM0Ljg2NzE4OCA1MDIuNjgzNTk0IDI4Ljk3NjU2MiBDIDUwMi42ODM1OTQgMjMuMDg1OTM4IDUwMi42ODM1OTQgMTUuMjgxMjUgNTAwLjIxODc1IDE1LjI4MTI1IEwgNDQyLjAzOTA2MiAxNS4yODEyNSBDIDQzOS41NzQyMTkgMTUuMjgxMjUgNDM5LjU3NDIxOSAyMy4wODU5MzggNDM5LjU3NDIxOSAyOC45NzY1NjIgQyA0MzkuNTc0MjE5IDM0Ljg2NzE4OCA0MzkuNTc0MjE5IDQyLjY3MTg3NSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBaIE0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE4OCI+CiAgPHBhdGggZD0iTSA0NjggMzMgTCA0NzUgMzMgTCA0NzUgMzggTCA0NjggMzggWiBNIDQ2OCAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTg5Ij4KICA8cGF0aCBkPSJNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1IEwgNTAwLjIxODc1IDQyLjY3MTg3NSBDIDUwMi42ODM1OTQgNDIuNjcxODc1IDUwMi42ODM1OTQgMzQuODY3MTg4IDUwMi42ODM1OTQgMjguOTc2NTYyIEMgNTAyLjY4MzU5NCAyMy4wODU5MzggNTAyLjY4MzU5NCAxNS4yODEyNSA1MDAuMjE4NzUgMTUuMjgxMjUgTCA0NDIuMDM5MDYyIDE1LjI4MTI1IEMgNDM5LjU3NDIxOSAxNS4yODEyNSA0MzkuNTc0MjE5IDIzLjA4NTkzOCA0MzkuNTc0MjE5IDI4Ljk3NjU2MiBDIDQzOS41NzQyMTkgMzQuODY3MTg4IDQzOS41NzQyMTkgNDIuNjcxODc1IDQ0Mi4wMzkwNjIgNDIuNjcxODc1IFogTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTkwIj4KICA8cGF0aCBkPSJNIDQ3NSAzMyBMIDQ4MCAzMyBMIDQ4MCAzOSBMIDQ3NSAzOSBaIE0gNDc1IDMzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOTEiPgogIDxwYXRoIGQ9Ik0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgTCA1MDAuMjE4NzUgNDIuNjcxODc1IEMgNTAyLjY4MzU5NCA0Mi42NzE4NzUgNTAyLjY4MzU5NCAzNC44NjcxODggNTAyLjY4MzU5NCAyOC45NzY1NjIgQyA1MDIuNjgzNTk0IDIzLjA4NTkzOCA1MDIuNjgzNTk0IDE1LjI4MTI1IDUwMC4yMTg3NSAxNS4yODEyNSBMIDQ0Mi4wMzkwNjIgMTUuMjgxMjUgQyA0MzkuNTc0MjE5IDE1LjI4MTI1IDQzOS41NzQyMTkgMjMuMDg1OTM4IDQzOS41NzQyMTkgMjguOTc2NTYyIEMgNDM5LjU3NDIxOSAzNC44NjcxODggNDM5LjU3NDIxOSA0Mi42NzE4NzUgNDQyLjAzOTA2MiA0Mi42NzE4NzUgWiBNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOTIiPgogIDxwYXRoIGQ9Ik0gNDgwIDM3IEwgNDgyIDM3IEwgNDgyIDM4IEwgNDgwIDM4IFogTSA0ODAgMzcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE5MyI+CiAgPHBhdGggZD0iTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBMIDUwMC4yMTg3NSA0Mi42NzE4NzUgQyA1MDIuNjgzNTk0IDQyLjY3MTg3NSA1MDIuNjgzNTk0IDM0Ljg2NzE4OCA1MDIuNjgzNTk0IDI4Ljk3NjU2MiBDIDUwMi42ODM1OTQgMjMuMDg1OTM4IDUwMi42ODM1OTQgMTUuMjgxMjUgNTAwLjIxODc1IDE1LjI4MTI1IEwgNDQyLjAzOTA2MiAxNS4yODEyNSBDIDQzOS41NzQyMTkgMTUuMjgxMjUgNDM5LjU3NDIxOSAyMy4wODU5MzggNDM5LjU3NDIxOSAyOC45NzY1NjIgQyA0MzkuNTc0MjE5IDM0Ljg2NzE4OCA0MzkuNTc0MjE5IDQyLjY3MTg3NSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBaIE0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE5NCI+CiAgPHBhdGggZD0iTSA0ODIgMzMgTCA0ODcgMzMgTCA0ODcgMzkgTCA0ODIgMzkgWiBNIDQ4MiAzMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTk1Ij4KICA8cGF0aCBkPSJNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1IEwgNTAwLjIxODc1IDQyLjY3MTg3NSBDIDUwMi42ODM1OTQgNDIuNjcxODc1IDUwMi42ODM1OTQgMzQuODY3MTg4IDUwMi42ODM1OTQgMjguOTc2NTYyIEMgNTAyLjY4MzU5NCAyMy4wODU5MzggNTAyLjY4MzU5NCAxNS4yODEyNSA1MDAuMjE4NzUgMTUuMjgxMjUgTCA0NDIuMDM5MDYyIDE1LjI4MTI1IEMgNDM5LjU3NDIxOSAxNS4yODEyNSA0MzkuNTc0MjE5IDIzLjA4NTkzOCA0MzkuNTc0MjE5IDI4Ljk3NjU2MiBDIDQzOS41NzQyMTkgMzQuODY3MTg4IDQzOS41NzQyMTkgNDIuNjcxODc1IDQ0Mi4wMzkwNjIgNDIuNjcxODc1IFogTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTk2Ij4KICA8cGF0aCBkPSJNIDQ2MCAyMCBMIDQ2NyAyMCBMIDQ2NyAyNyBMIDQ2MCAyNyBaIE0gNDYwIDIwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOTciPgogIDxwYXRoIGQ9Ik0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgTCA1MDAuMjE4NzUgNDIuNjcxODc1IEMgNTAyLjY4MzU5NCA0Mi42NzE4NzUgNTAyLjY4MzU5NCAzNC44NjcxODggNTAyLjY4MzU5NCAyOC45NzY1NjIgQyA1MDIuNjgzNTk0IDIzLjA4NTkzOCA1MDIuNjgzNTk0IDE1LjI4MTI1IDUwMC4yMTg3NSAxNS4yODEyNSBMIDQ0Mi4wMzkwNjIgMTUuMjgxMjUgQyA0MzkuNTc0MjE5IDE1LjI4MTI1IDQzOS41NzQyMTkgMjMuMDg1OTM4IDQzOS41NzQyMTkgMjguOTc2NTYyIEMgNDM5LjU3NDIxOSAzNC44NjcxODggNDM5LjU3NDIxOSA0Mi42NzE4NzUgNDQyLjAzOTA2MiA0Mi42NzE4NzUgWiBNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOTgiPgogIDxwYXRoIGQ9Ik0gNDY2IDIwIEwgNDc0IDIwIEwgNDc0IDI3IEwgNDY2IDI3IFogTSA0NjYgMjAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE5OSI+CiAgPHBhdGggZD0iTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBMIDUwMC4yMTg3NSA0Mi42NzE4NzUgQyA1MDIuNjgzNTk0IDQyLjY3MTg3NSA1MDIuNjgzNTk0IDM0Ljg2NzE4OCA1MDIuNjgzNTk0IDI4Ljk3NjU2MiBDIDUwMi42ODM1OTQgMjMuMDg1OTM4IDUwMi42ODM1OTQgMTUuMjgxMjUgNTAwLjIxODc1IDE1LjI4MTI1IEwgNDQyLjAzOTA2MiAxNS4yODEyNSBDIDQzOS41NzQyMTkgMTUuMjgxMjUgNDM5LjU3NDIxOSAyMy4wODU5MzggNDM5LjU3NDIxOSAyOC45NzY1NjIgQyA0MzkuNTc0MjE5IDM0Ljg2NzE4OCA0MzkuNTc0MjE5IDQyLjY3MTg3NSA0NDIuMDM5MDYyIDQyLjY3MTg3NSBaIE0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIwMCI+CiAgPHBhdGggZD0iTSA0NzMgMjAgTCA0ODEgMjAgTCA0ODEgMjcgTCA0NzMgMjcgWiBNIDQ3MyAyMCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjAxIj4KICA8cGF0aCBkPSJNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1IEwgNTAwLjIxODc1IDQyLjY3MTg3NSBDIDUwMi42ODM1OTQgNDIuNjcxODc1IDUwMi42ODM1OTQgMzQuODY3MTg4IDUwMi42ODM1OTQgMjguOTc2NTYyIEMgNTAyLjY4MzU5NCAyMy4wODU5MzggNTAyLjY4MzU5NCAxNS4yODEyNSA1MDAuMjE4NzUgMTUuMjgxMjUgTCA0NDIuMDM5MDYyIDE1LjI4MTI1IEMgNDM5LjU3NDIxOSAxNS4yODEyNSA0MzkuNTc0MjE5IDIzLjA4NTkzOCA0MzkuNTc0MjE5IDI4Ljk3NjU2MiBDIDQzOS41NzQyMTkgMzQuODY3MTg4IDQzOS41NzQyMTkgNDIuNjcxODc1IDQ0Mi4wMzkwNjIgNDIuNjcxODc1IFogTSA0NDIuMDM5MDYyIDQyLjY3MTg3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjAyIj4KICA8cGF0aCBkPSJNIDQ4MSAyMyBMIDQ4NSAyMyBMIDQ4NSAyOSBMIDQ4MSAyOSBaIE0gNDgxIDIzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyMDMiPgogIDxwYXRoIGQ9Ik0gNDQyLjAzOTA2MiA0Mi42NzE4NzUgTCA1MDAuMjE4NzUgNDIuNjcxODc1IEMgNTAyLjY4MzU5NCA0Mi42NzE4NzUgNTAyLjY4MzU5NCAzNC44NjcxODggNTAyLjY4MzU5NCAyOC45NzY1NjIgQyA1MDIuNjgzNTk0IDIzLjA4NTkzOCA1MDIuNjgzNTk0IDE1LjI4MTI1IDUwMC4yMTg3NSAxNS4yODEyNSBMIDQ0Mi4wMzkwNjIgMTUuMjgxMjUgQyA0MzkuNTc0MjE5IDE1LjI4MTI1IDQzOS41NzQyMTkgMjMuMDg1OTM4IDQzOS41NzQyMTkgMjguOTc2NTYyIEMgNDM5LjU3NDIxOSAzNC44NjcxODggNDM5LjU3NDIxOSA0Mi42NzE4NzUgNDQyLjAzOTA2MiA0Mi42NzE4NzUgWiBNIDQ0Mi4wMzkwNjIgNDIuNjcxODc1ICIvPgo8L2NsaXBQYXRoPgo8L2RlZnM+CjxnIGlkPSJzdXJmYWNlMSI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoNTAlLDUwJSwxMDAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMS43NzM0MzggNDMuNjQwNjI1IEwgNDguMDc4MTI1IDQzLjY0MDYyNSBMIDQ4LjA3ODEyNSAxNC4zMTY0MDYgTCAxLjc3MzQzOCAxNC4zMTY0MDYgTCAxLjc3MzQzOCA0My42NDA2MjUgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDc1JSw3NSUsMTAwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDQ3LjExMzI4MSA0My42NDA2MjUgTCA5Ny4zODI4MTIgNDMuNjQwNjI1IEwgOTcuMzgyODEyIDE0LjMxNjQwNiBMIDQ3LjExMzI4MSAxNC4zMTY0MDYgTCA0Ny4xMTMyODEgNDMuNjQwNjI1ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig1MCUsNTAlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSA5NS40NTMxMjUgNDMuNjQwNjI1IEwgMTQ0LjIyMjY1NiA0My42NDA2MjUgTCAxNDQuMjIyNjU2IDE0LjMxNjQwNiBMIDk1LjQ1MzEyNSAxNC4zMTY0MDYgTCA5NS40NTMxMjUgNDMuNjQwNjI1ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig3NSUsNzUlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAxNDMuMjU3ODEyIDQzLjY0MDYyNSBMIDE5My41MjczNDQgNDMuNjQwNjI1IEwgMTkzLjUyNzM0NCAxNC4zMTY0MDYgTCAxNDMuMjU3ODEyIDE0LjMxNjQwNiBMIDE0My4yNTc4MTIgNDMuNjQwNjI1ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoNTAlLDUwJSwxMDAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMTkxLjU5Mzc1IDQzLjY0MDYyNSBMIDIzNy45MDIzNDQgNDMuNjQwNjI1IEwgMjM3LjkwMjM0NCAxNC4zMTY0MDYgTCAxOTEuNTkzNzUgMTQuMzE2NDA2IEwgMTkxLjU5Mzc1IDQzLjY0MDYyNSAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig3NSUsNzUlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyMzYuOTMzNTk0IDQzLjY0MDYyNSBMIDMwOS4zOTA2MjUgNDMuNjQwNjI1IEwgMzA5LjM5MDYyNSAxNC4zMTY0MDYgTCAyMzYuOTMzNTk0IDE0LjMxNjQwNiBMIDIzNi45MzM1OTQgNDMuNjQwNjI1ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDEwMCUsNTAlLDUwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDMwNy40NjA5MzggNDMuNjQwNjI1IEwgMzczLjQ4ODI4MSA0My42NDA2MjUgTCAzNzMuNDg4MjgxIDE0LjMxNjQwNiBMIDMwNy40NjA5MzggMTQuMzE2NDA2IEwgMzA3LjQ2MDkzOCA0My42NDA2MjUgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMTAwJSw1MCUsNTAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMzcxLjU1NDY4OCA0My42NDA2MjUgTCA0NDAuMDUwNzgxIDQzLjY0MDYyNSBMIDQ0MC4wNTA3ODEgMTQuMzE2NDA2IEwgMzcxLjU1NDY4OCAxNC4zMTY0MDYgTCAzNzEuNTU0Njg4IDQzLjY0MDYyNSAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigxMDAlLDUwJSw1MCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSA0MzguMTE3MTg4IDQzLjY0MDYyNSBMIDUwNC4xNDQ1MzEgNDMuNjQwNjI1IEwgNTA0LjE0NDUzMSAxNC4zMTY0MDYgTCA0MzguMTE3MTg4IDE0LjMxNjQwNiBMIDQzOC4xMTcxODggNDMuNjQwNjI1ICIvPgo8L2c+CjwvZz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjcuMzgyODEyIDE0Ni42MjAzMTIgTCAyNy4zODI4MTIgMTQ2LjMwNzgxMiBDIDI3LjM4MjgxMiAxMjcuNDAxNTYyIDQyLjczNDM3NSAxMTIuMDUgNjEuNjQwNjI1IDExMi4wNSBMIDM1NjcuNzM0Mzc1IDExMi4wNSBDIDM1ODYuNjQwNjI1IDExMi4wNSAzNjAxLjk1MzEyNSAxMjcuNDAxNTYyIDM2MDEuOTUzMTI1IDE0Ni4zMDc4MTIgTCAzNjAxLjk1MzEyNSAyMjEuNjIwMzEyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyLjczODI4MSA0My4xNjc5NjkgTCAwLjgwNDY4OCA1MC40NDUzMTIgQyAwLjc4NTE1NiA1MC41MTk1MzEgMC43Njk1MzEgNTAuNTkzNzUgMC43NTM5MDYgNTAuNjY3OTY5IEwgNC43MzgyODEgNTAuNjY3OTY5IEMgNC43MTQ4NDQgNTAuNTkzNzUgNC42OTUzMTIgNTAuNTE5NTMxIDQuNjcxODc1IDUwLjQ0NTMxMiBMIDIuNzM4MjgxIDQzLjE2Nzk2OSAiLz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjcuMzgyODEyIDIyMS42MjAzMTIgTCA4LjA0Njg3NSAxNDguODQ2ODc1IEMgNy44NTE1NjIgMTQ4LjEwNDY4NyA3LjY5NTMxMiAxNDcuMzYyNSA3LjUzOTA2MiAxNDYuNjIwMzEyIEwgNDcuMzgyODEyIDE0Ni42MjAzMTIgQyA0Ny4xNDg0MzggMTQ3LjM2MjUgNDYuOTUzMTI1IDE0OC4xMDQ2ODcgNDYuNzE4NzUgMTQ4Ljg0Njg3NSBaIE0gMjcuMzgyODEyIDIyMS42MjAzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gOTY0LjE3OTY4OCAxNDYuNjIwMzEyIEwgOTY0LjE3OTY4OCA5MS41NDIxODcgQyA5NjQuMTc5Njg4IDcyLjU5Njg3NSA5NzkuNDkyMTg4IDU3LjI4NDM3NSA5OTguMzk4NDM4IDU3LjI4NDM3NSBMIDQyMDguNjcxODc1IDU3LjI4NDM3NSBDIDQyMjcuNTc4MTI1IDU3LjI4NDM3NSA0MjQyLjg5MDYyNSA3Mi41OTY4NzUgNDI0Mi44OTA2MjUgOTEuNTQyMTg3IEwgNDI0Mi44OTA2MjUgMjIxLjYyMDMxMiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8cGF0aCBzdHlsZT0iZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSA5NjQuMTc5Njg4IDIyMS42MjAzMTIgTCA5NDQuMDYyNSAxNDYuNjIwMzEyIEwgOTg0LjI1NzgxMiAxNDYuNjIwMzEyIFogTSA5NjQuMTc5Njg4IDIyMS42MjAzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxOSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDE5MjUuNjI1IDE0Ni42MjAzMTIgTCAxOTI1LjYyNSAzNi43Mzc1IEMgMTkyNS42MjUgMTcuODMxMjUgMTk0MC45Mzc1IDIuNTE4NzUgMTk1OS44NDM3NSAyLjUxODc1IEwgNDg3NC4yOTY4NzUgMi41MTg3NSBDIDQ4OTMuMjAzMTI1IDIuNTE4NzUgNDkwOC41MTU2MjUgMTcuODMxMjUgNDkwOC41MTU2MjUgMzYuNzM3NSBMIDQ5MDguNTE1NjI1IDIyMS42MjAzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPC9nPgo8cGF0aCBzdHlsZT0iZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxOTI1LjYyNSAyMjEuNjIwMzEyIEwgMTkwNS41MDc4MTIgMTQ2LjYyMDMxMiBMIDE5NDUuNzAzMTI1IDE0Ni42MjAzMTIgWiBNIDE5MjUuNjI1IDIyMS42MjAzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDg4NC4yNTc4MTIgNTgwLjUyNjU2MiBMIDEwNy4zMDQ2ODggNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSA5NS45MjU3ODEgNy4yNzczNDQgTCA4OC40MjU3ODEgNS4yNjk1MzEgTCA4OC40MjU3ODEgOS4yODkwNjIgWiBNIDk1LjkyNTc4MSA3LjI3NzM0NCAiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDk1OS4yNTc4MTIgNTgwLjUyNjU2MiBMIDg4NC4yNTc4MTIgNjAwLjYwNDY4NyBMIDg4NC4yNTc4MTIgNTYwLjQwOTM3NSBaIE0gOTU5LjI1NzgxMiA1ODAuNTI2NTYyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjwvZz4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDMuMjMwNDY5IDcuMjc3MzQ0IEwgMTAuNzMwNDY5IDkuMjg5MDYyIEwgMTAuNzMwNDY5IDUuMjY5NTMxIFogTSAzLjIzMDQ2OSA3LjI3NzM0NCAiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMyLjMwNDY4OCA1ODAuNTI2NTYyIEwgMTA3LjMwNDY4OCA1NjAuNDA5Mzc1IEwgMTA3LjMwNDY4OCA2MDAuNjA0Njg3IFogTSAzMi4zMDQ2ODggNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMi4zMDQ2ODggNTQzLjAyNjU2MiBMIDMyLjMwNDY4OCA2MTguMDI2NTYyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDk1OS4yNTc4MTIgNTQzLjAyNjU2MiBMIDk1OS4yNTc4MTIgNjE4LjAyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxODQ1LjY2NDA2MiA1ODAuNTI2NTYyIEwgMTA0NC4xMDE1NjIgNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxOTIwLjY2NDA2MiA1ODAuNTI2NTYyIEwgMTg0NS42NjQwNjIgNjAwLjYwNDY4NyBMIDE4NDUuNjY0MDYyIDU2MC40MDkzNzUgWiBNIDE5MjAuNjY0MDYyIDU4MC41MjY1NjIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDI3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gOTY5LjEwMTU2MiA1ODAuNTI2NTYyIEwgMTA0NC4xMDE1NjIgNTYwLjQwOTM3NSBMIDEwNDQuMTAxNTYyIDYwMC42MDQ2ODcgWiBNIDk2OS4xMDE1NjIgNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSA5NjkuMTAxNTYyIDU0My4wMjY1NjIgTCA5NjkuMTAxNTYyIDYxOC4wMjY1NjIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDI5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMTkyMC42NjQwNjIgNTQzLjAyNjU2MiBMIDE5MjAuNjY0MDYyIDYxOC4wMjY1NjIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzAwNC4zMzU5MzggNTgwLjUyNjU2MiBMIDIwMDUuNTQ2ODc1IDU4MC41MjY1NjIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPC9nPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMzA3LjkzMzU5NCA3LjI3NzM0NCBMIDMwMC40MzM1OTQgNS4yNjk1MzEgTCAzMDAuNDMzNTk0IDkuMjg5MDYyIFogTSAzMDcuOTMzNTk0IDcuMjc3MzQ0ICIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzA3OS4zMzU5MzggNTgwLjUyNjU2MiBMIDMwMDQuMzM1OTM4IDYwMC42MDQ2ODcgTCAzMDA0LjMzNTkzOCA1NjAuNDA5Mzc1IFogTSAzMDc5LjMzNTkzOCA1ODAuNTI2NTYyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjwvZz4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDE5My4wNTQ2ODggNy4yNzczNDQgTCAyMDAuNTU0Njg4IDkuMjg5MDYyIEwgMjAwLjU1NDY4OCA1LjI2OTUzMSBaIE0gMTkzLjA1NDY4OCA3LjI3NzM0NCAiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDE5MzAuNTQ2ODc1IDU4MC41MjY1NjIgTCAyMDA1LjU0Njg3NSA1NjAuNDA5Mzc1IEwgMjAwNS41NDY4NzUgNjAwLjYwNDY4NyBaIE0gMTkzMC41NDY4NzUgNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxOTMwLjU0Njg3NSA1NDMuMDI2NTYyIEwgMTkzMC41NDY4NzUgNjE4LjAyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMDc5LjMzNTkzOCA1NDMuMDI2NTYyIEwgMzA3OS4zMzU5MzggNjE4LjAyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSA0OTUxLjgzNTkzOCA1ODAuNTI2NTYyIEwgMzE2NC4xNzk2ODggNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDUwMjYuODM1OTM4IDU4MC41MjY1NjIgTCA0OTUxLjgzNTkzOCA2MDAuNjA0Njg3IEwgNDk1MS44MzU5MzggNTYwLjQwOTM3NSBaIE0gNTAyNi44MzU5MzggNTgwLjUyNjU2MiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDY1LjMzKSIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDM2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzA4OS4xNzk2ODggNTgwLjUyNjU2MiBMIDMxNjQuMTc5Njg4IDU2MC40MDkzNzUgTCAzMTY0LjE3OTY4OCA2MDAuNjA0Njg3IFogTSAzMDg5LjE3OTY4OCA1ODAuNTI2NTYyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMwODkuMTc5Njg4IDU0My4wMjY1NjIgTCAzMDg5LjE3OTY4OCA2MTguMDI2NTYyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsNjUuMzMpIi8+CjwvZz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gNTAyNi44MzU5MzggNTQzLjAyNjU2MiBMIDUwMjYuODM1OTM4IDYxOC4wMjY1NjIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCw2NS4zMykiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTEiIHg9IjYuOTYwMTYiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTIiIHg9IjEzLjQ0MDE2MiIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMyIgeD0iMTkuNDQwMTY1IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQ1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC00IiB4PSIyNS40NDAxNjciIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTUiIHg9IjMxLjkyMDE3IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQ5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0yIiB4PSIzOS4zNjAxNyIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDUwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMSIgeD0iMTQuNjM5ODUiIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDUzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0yIiB4PSIyMC43NTk4NDkiIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIyNi4yNzk4NDgiIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0xIiB4PSIzMy40ODAwNSIgeT0iMjguMjQ5ODQiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTQiIHg9IjU0LjU5OTk1IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iNjAuMTE5OTUyIiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNiIgeD0iNjIuODc5OTQ3IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNyIgeD0iNjkuODM5Nzg3IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iNzQuODc5NzkyIiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iNzkuMzE5Nzg4IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iODIuMDc5NzgzIiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtNSIgeD0iMTA0LjUyIiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC02IiB4PSIxMTEuOTYwMDAzIiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC03IiB4PSIxMTYuOTk5OTk4IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC04IiB4PSIxMjEuMzIwMDA0IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDgxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC05IiB4PSIxMjYuMzYwMDExIiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDgzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xMCIgeD0iMTMwLjgiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTgiIHg9IjEzMi44NCIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMSIgeD0iMTA5LjU2MDIzIiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMiIgeD0iMTE1LjY4MDIyOCIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTMiIHg9IjEyMS4yMDAyMjkiIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDkzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0yIiB4PSIxMjguNDAwMDMiIHk9IjI4LjI0OTg0Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS00IiB4PSIxNTAuNzE5OTMiIHk9IjMxLjM2OTc2Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIxNTYuMjM5OTIiIHk9IjMxLjM2OTc2Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIxNTguOTk5OTI3IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTAxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS03IiB4PSIxNjUuOTU5NzY3IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTAzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSIxNzAuOTk5NzY2IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS05IiB4PSIxNzUuNDM5NzY4IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSIxNzguMTk5NzYzIiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xMSIgeD0iMjAxLjQ4IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTEwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTgiIHg9IjIwNi41MTk5OTUiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTIiIHg9IjIxMS41NjAwMTQiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTMiIHg9IjIxOS4wMDAwMDUiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTQiIHg9IjIyMy42ODAwMTQiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExOSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTUiIHg9IjIyNi4yMDAwMTEiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMjApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMSIgeD0iMjA0LjQ4IiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTIzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0yIiB4PSIyMTAuNTk5OTg1IiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTI1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIyMTYuMTE5OTc1IiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTI3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0zIiB4PSIyMjMuMzE5OCIgeT0iMjguMjQ5ODQiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMjgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyOSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNCIgeD0iMjU1LjU5OTkiIHk9IjMxLjM2OTc2Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTMwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjI2MS4xMTk4OSIgeT0iMzEuMzY5NzYiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNiIgeD0iMjYzLjg3OTkwOSIgeT0iMzEuMzY5NzYiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNyIgeD0iMjcwLjcxOTgyOSIgeT0iMzEuMzY5NzYiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMjc1Ljc1OTgxNiIgeT0iMzEuMzY5NzYiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzOSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iMjgwLjE5OTgzIiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSIyODIuOTU5ODI0IiB5PSIzMS4zNjk3NiIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xIiB4PSIzMjIuNTYiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMiIgeD0iMzI5LjA0MDAwMSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQ3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0zIiB4PSIzMzUuMDQwMDEiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtNCIgeD0iMzQxLjA0MDAxOSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTUxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC01IiB4PSIzNDcuNTE5OTk1IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTUyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNTMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTIiIHg9IjM1NC45NjAwMSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTU1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMCIgeD0iMzI5LjE2IiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTU3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMSIgeD0iMzM1Ljc1OTk4OCIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNTgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iMzQyLjk1OTk5NyIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNjApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE2MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDItMSIgeD0iMzUwLjE2IiB5PSIyOC4yNDk4NCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE2MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTYzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC01IiB4PSIzOTAuNDgiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNjQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE2NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtNiIgeD0iMzk3LjkxOTk5MSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE2NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTY3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC03IiB4PSI0MDIuOTYwMDEiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNjgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE2OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtOCIgeD0iNDA3LjI4MDAxNiIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE3MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTcxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC05IiB4PSI0MTIuMzIwMDExIiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTcyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNzMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTEwIiB4PSI0MTYuNzU5OTg4IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTc0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNzUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTgiIHg9IjQxOC44MDAwMzYiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNzYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE3NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTAiIHg9IjM5NC40Mzk3NyIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNzgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE3OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTEiIHg9IjQwMS4wMzk3NTgiIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTgwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxODEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTMiIHg9IjQwOC4yMzk3NjciIHk9IjI2LjgxIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTgyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxODMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgyLTIiIHg9IjQxNS40Mzk3NyIgeT0iMjguMjQ5ODQiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxODQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE4NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTEiIHg9IjQ1Ny44IiB5PSIzNy45Njk4Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTg2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxODcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTgiIHg9IjQ2Mi44Mzk5OTUiIHk9IjM3Ljk2OTgiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxODgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE4OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMTIiIHg9IjQ2Ny44Nzk5OSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE5MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTkxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xMyIgeD0iNDc1LjMyMDAyOSIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE5MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTkzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xNCIgeD0iNDgwLjAwMDAxNCIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE5NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTk1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0xNSIgeD0iNDgyLjUyMDAxMiIgeT0iMzcuOTY5OCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE5NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTk3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMCIgeD0iNDU5LjcxOTkyIiB5PSIyNi44MSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE5OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTk5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMSIgeD0iNDY2LjMxOTkzMiIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMDApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDIwMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iNDczLjUxOTk0MSIgeT0iMjYuODEiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMDIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDIwMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDItMyIgeD0iNDgwLjgzOTgyIiB5PSIyOC4yNDk4NCIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTQiIHg9IjM5LjQ4MDEiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iNDUuMDAwMDk5IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjQ3Ljc2MDEiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTIiIHg9IjU0LjcxOTk0IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTQiIHg9IjEzNC40MDAwMzkiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iMTM5LjkyMDAyOSIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIxNDIuNjgwMDM2IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEzIiB4PSIxNDkuNjM5ODc2IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTQiIHg9IjI0MC4zNjAxNzQiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iMjQ1Ljg4MDE2NCIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIyNDguNjQwMTgzIiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE0IiB4PSIyNTUuNjAwMDIzIiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE1IiB4PSIzNzMuMDgwNDcxIiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjM3Ny41MjA0NiIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNiIgeD0iMzgxLjk2MDQ3NCIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS05IiB4PSIzODcuMDAwNDYiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTciIHg9IjM4OS43NjA0OCIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSIzOTMuMTIwNDciIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iMzk3LjU2MDQ4NCIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS03IiB4PSI0MDIuNjAwNDE0IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE4IiB4PSI0MDcuNjQwNDAxIiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE3IiB4PSI0MTAuNDAwMzk2IiB5PSI5LjY0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjQxMy43NjAzODciIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTUiIHg9IjQxOC4yMDA0MDEiIHk9IjkuNjQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iNDIyLjY0MDQxNCIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xOSIgeD0iNDI1LjQwMDQwOSIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNyIgeD0iNDMwLjQ0MDQyMSIgeT0iOS42NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0yMCIgeD0iNDMzLjgwMDQxMSIgeT0iOS42NDk5Ii8+CjwvZz4KPC9nPgo8L3N2Zz4K)
The central directory is at the end of the zip file. It is a list of central directory headers. Each central directory header contains metadata for a single file, like its filename and CRC-32 checksum, and a backwards pointer to a local file header. A central directory header is 46 bytes long, plus the length of the filename.
A file consists of a local file header followed by compressed file data. The local file header is 30 bytes long, plus the length of the filename. It contains a redundant copy of the metadata from the central directory header, and the compressed and uncompressed sizes of the file data that follows. Zip is a container format, not a compression algorithm. Each file's data is compressed using an algorithm specified in the metadata—usually DEFLATE.
This description of the zip format omits many details that are not needed for understanding the zip bomb. For full information, refer to section 4.3 of APPNOTE.TXT or The structure of a PKZip file by Florian Buchholz, or see the source code.
The first insight: overlapping files
By compressing a long string of repeated bytes, we can produce a kernel of highly compressed data. By itself, the kernel's compression ratio cannot exceed the DEFLATE limit of 1032, so we want a way to reuse the kernel in many files, without making a separate copy of it in each file. We can do it by overlapping files: making many central directory headers point to a single file, whose data is the kernel.
![A block diagram of a zip file with fully overlapping files. The central directory header consists of central directory headers CDH[1], CDH[2], ..., CDH[N−1], CDH[N], with filenames A, B, ..., Y, Z. There is a single local file header LFH[1] with filename A whose file data is a compressed kernel. Every one of the central directory headers points backwards to the same local file header, LFH[1]. The lone file is multiply labeled file 1, file 2, ..., file N−1, file N.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4KPHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHhtbG5zOnhsaW5rPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rIiB3aWR0aD0iNTA0cHQiIGhlaWdodD0iMTIwLjExcHQiIHZpZXdCb3g9IjAgMCA1MDQgMTIwLjExIiB2ZXJzaW9uPSIxLjEiPgo8ZGVmcz4KPGc+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9IiIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0xIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0LjI1IC0xLjk2ODc1IEwgNC45MjE4NzUgMCBMIDUuODU5Mzc1IDAgTCAzLjU2MjUgLTYuNTMxMjUgTCAyLjQ4NDM3NSAtNi41MzEyNSBMIDAuMTU2MjUgMCBMIDEuMDQ2ODc1IDAgTCAxLjczNDM3NSAtMS45Njg3NSBaIE0gNC4wMTU2MjUgLTIuNjU2MjUgTCAxLjkzNzUgLTIuNjU2MjUgTCAzLjAxNTYyNSAtNS42NDA2MjUgWiBNIDQuMDE1NjI1IC0yLjY1NjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0yIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjcwMzEyNSAwIEwgMy42NTYyNSAwIEMgNC4yODEyNSAwIDQuNzM0Mzc1IC0wLjE3MTg3NSA1LjA3ODEyNSAtMC41NDY4NzUgQyA1LjQwNjI1IC0wLjg5MDYyNSA1LjU5Mzc1IC0xLjM1OTM3NSA1LjU5Mzc1IC0xLjg1OTM3NSBDIDUuNTkzNzUgLTIuNjU2MjUgNS4yMzQzNzUgLTMuMTI1IDQuMzkwNjI1IC0zLjQ1MzEyNSBDIDQuOTg0Mzc1IC0zLjczNDM3NSA1LjI5Njg3NSAtNC4yMTg3NSA1LjI5Njg3NSAtNC44NzUgQyA1LjI5Njg3NSAtNS4zNTkzNzUgNS4xMjUgLTUuNzgxMjUgNC43ODEyNSAtNi4wNzgxMjUgQyA0LjQzNzUgLTYuMzkwNjI1IDMuOTg0Mzc1IC02LjUzMTI1IDMuMzU5Mzc1IC02LjUzMTI1IEwgMC43MDMxMjUgLTYuNTMxMjUgWiBNIDEuNTQ2ODc1IC0zLjcxODc1IEwgMS41NDY4NzUgLTUuNzk2ODc1IEwgMy4xNTYyNSAtNS43OTY4NzUgQyAzLjYyNSAtNS43OTY4NzUgMy44OTA2MjUgLTUuNzM0Mzc1IDQuMTA5Mzc1IC01LjU2MjUgQyA0LjM0Mzc1IC01LjM5MDYyNSA0LjQ2ODc1IC01LjEyNSA0LjQ2ODc1IC00Ljc2NTYyNSBDIDQuNDY4NzUgLTQuNDA2MjUgNC4zNDM3NSAtNC4xNDA2MjUgNC4xMDkzNzUgLTMuOTUzMTI1IEMgMy44OTA2MjUgLTMuNzgxMjUgMy42MjUgLTMuNzE4NzUgMy4xNTYyNSAtMy43MTg3NSBaIE0gMS41NDY4NzUgLTAuNzM0Mzc1IEwgMS41NDY4NzUgLTIuOTg0Mzc1IEwgMy41NzgxMjUgLTIuOTg0Mzc1IEMgMy45ODQzNzUgLTIuOTg0Mzc1IDQuMjUgLTIuODkwNjI1IDQuNDUzMTI1IC0yLjY3MTg3NSBDIDQuNjQwNjI1IC0yLjQ2ODc1IDQuNzUgLTIuMTcxODc1IDQuNzUgLTEuODU5Mzc1IEMgNC43NSAtMS41NDY4NzUgNC42NDA2MjUgLTEuMjUgNC40NTMxMjUgLTEuMDQ2ODc1IEMgNC4yNSAtMC44MjgxMjUgMy45ODQzNzUgLTAuNzM0Mzc1IDMuNTc4MTI1IC0wLjczNDM3NSBaIE0gMS41NDY4NzUgLTAuNzM0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0zIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjQ2ODc1IC0yLjU2MjUgTCA1LjkyMTg3NSAtNi41MzEyNSBMIDQuOTM3NSAtNi41MzEyNSBMIDMuMDYyNSAtMy4zNTkzNzUgTCAxLjE0MDYyNSAtNi41MzEyNSBMIDAuMTA5Mzc1IC02LjUzMTI1IEwgMi42NDA2MjUgLTIuNTYyNSBMIDIuNjQwNjI1IDAgTCAzLjQ2ODc1IDAgWiBNIDMuNDY4NzUgLTIuNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtNCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNS4yMDMxMjUgLTYuNTMxMjUgTCAwLjUgLTYuNTMxMjUgTCAwLjUgLTUuNzk2ODc1IEwgNC4xNzE4NzUgLTUuNzk2ODc1IEwgMC4yNSAtMC43MzQzNzUgTCAwLjI1IDAgTCA1LjIzNDM3NSAwIEwgNS4yMzQzNzUgLTAuNzM0Mzc1IEwgMS4yOTY4NzUgLTAuNzM0Mzc1IEwgNS4yMDMxMjUgLTUuNzgxMjUgWiBNIDUuMjAzMTI1IC02LjUzMTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDUuNzE4NzUgLTEuNzM0Mzc1IEMgNS41NDY4NzUgLTEuMzU5Mzc1IDUuNDA2MjUgLTEuMTI1IDUuMjUgLTAuOTUzMTI1IEMgNC45MDYyNSAtMC41NjI1IDQuMzU5Mzc1IC0wLjM5MDYyNSAzLjUzMTI1IC0wLjM5MDYyNSBMIDIuODU5Mzc1IC0wLjM5MDYyNSBDIDIuMTQwNjI1IC0wLjM5MDYyNSAyIC0wLjQ1MzEyNSAyIC0wLjc5Njg3NSBMIDIgLTUuNTE1NjI1IEMgMiAtNi4yMTg3NSAyLjE0MDYyNSAtNi4zNTkzNzUgMi45Mzc1IC02LjQwNjI1IEwgMi45Mzc1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4wOTM3NSBDIDAuOTg0Mzc1IC0wLjM5MDYyNSAwLjg0Mzc1IC0wLjIzNDM3NSAwLjEyNSAtMC4xODc1IEwgMC4xMjUgMCBMIDUuNDg0Mzc1IDAgTCA1Ljk2ODc1IC0xLjczNDM3NSBaIE0gNS43MTg3NSAtMS43MzQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzgxMjUgLTIuMjk2ODc1IEwgNC43ODEyNSAtNC42MDkzNzUgTCA0LjU0Njg3NSAtNC42MDkzNzUgQyA0LjQyMTg3NSAtMy44MTI1IDQuMjUgLTMuNjcxODc1IDMuNDUzMTI1IC0zLjY3MTg3NSBMIDIgLTMuNjcxODc1IEwgMiAtNS44NzUgQyAyIC02LjE1NjI1IDIuMDQ2ODc1IC02LjIxODc1IDIuMzI4MTI1IC02LjIxODc1IEwgMy42NzE4NzUgLTYuMjE4NzUgQyA0LjgxMjUgLTYuMjE4NzUgNS4wMzEyNSAtNi4wNzgxMjUgNS4xODc1IC01LjE3MTg3NSBMIDUuNDM3NSAtNS4xNzE4NzUgTCA1LjQwNjI1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4yMDMxMjUgQyAwLjk4NDM3NSAtMC4zNzUgMC44NzUgLTAuMjM0Mzc1IDAuMTI1IC0wLjE4NzUgTCAwLjEyNSAwIEwgMi45MDYyNSAwIEwgMi45MDYyNSAtMC4xODc1IEMgMi4xNDA2MjUgLTAuMjM0Mzc1IDIgLTAuMzc1IDIgLTEuMDkzNzUgTCAyIC0zLjI2NTYyNSBMIDMuNDUzMTI1IC0zLjI2NTYyNSBDIDQuMjUgLTMuMjY1NjI1IDQuNDIxODc1IC0zLjEwOTM3NSA0LjU0Njg3NSAtMi4yOTY4NzUgWiBNIDQuNzgxMjUgLTIuMjk2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0zIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAyLjA3ODEyNSAtMy41NzgxMjUgTCAyLjA3ODEyNSAtNS41MTU2MjUgQyAyLjA3ODEyNSAtNi4yMzQzNzUgMi4xODc1IC02LjM0Mzc1IDIuOTUzMTI1IC02LjQwNjI1IEwgMi45NTMxMjUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjA2MjUgLTYuMjM0Mzc1IDEuMDYyNSAtNS41MTU2MjUgTCAxLjA2MjUgLTEuMjAzMTI1IEMgMS4wNjI1IC0wLjM1OTM3NSAwLjk2ODc1IC0wLjIzNDM3NSAwLjE4NzUgLTAuMTg3NSBMIDAuMTg3NSAwIEwgMi45NTMxMjUgMCBMIDIuOTUzMTI1IC0wLjE4NzUgQyAyLjIxODc1IC0wLjI1IDIuMDc4MTI1IC0wLjM3NSAyLjA3ODEyNSAtMS4wOTM3NSBMIDIuMDc4MTI1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0xLjIwMzEyNSBDIDUuMTA5Mzc1IC0wLjM1OTM3NSA1IC0wLjIzNDM3NSA0LjIzNDM3NSAtMC4xODc1IEwgNC4yMzQzNzUgMCBMIDcgMCBMIDcgLTAuMTg3NSBDIDYuMjUgLTAuMjUgNi4xMjUgLTAuMzc1IDYuMTI1IC0xLjA5Mzc1IEwgNi4xMjUgLTUuNTE1NjI1IEMgNi4xMjUgLTYuMjM0Mzc1IDYuMjM0Mzc1IC02LjM0Mzc1IDcgLTYuNDA2MjUgTCA3IC02LjU5Mzc1IEwgNC4yMzQzNzUgLTYuNTkzNzUgTCA0LjIzNDM3NSAtNi40MDYyNSBDIDUgLTYuMzQzNzUgNS4xMDkzNzUgLTYuMjM0Mzc1IDUuMTA5Mzc1IC01LjUxNTYyNSBMIDUuMTA5Mzc1IC0zLjU3ODEyNSBaIE0gMi4wNzgxMjUgLTMuNTc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS00Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjA2MjUgLTYuMjAzMTI1IEMgMC4yMDMxMjUgLTYuMjE4NzUgMC4yOTY4NzUgLTYuMjM0Mzc1IDAuMzkwNjI1IC02LjIzNDM3NSBDIDAuNzE4NzUgLTYuMjM0Mzc1IDAuODEyNSAtNi4wOTM3NSAwLjgxMjUgLTUuNjI1IEwgMC44MTI1IC0wLjgxMjUgQyAwLjgxMjUgLTAuMjk2ODc1IDAuNzgxMjUgLTAuMjY1NjI1IDAuMDYyNSAtMC4xNTYyNSBMIDAuMDYyNSAwIEwgMi40MDYyNSAwIEwgMi40MDYyNSAtMC4xNTYyNSBMIDIuMjAzMTI1IC0wLjE1NjI1IEMgMS43OTY4NzUgLTAuMTcxODc1IDEuNjU2MjUgLTAuMzEyNSAxLjY1NjI1IC0wLjY3MTg3NSBMIDEuNjU2MjUgLTIuNSBMIDMuMDQ2ODc1IC0wLjY0MDYyNSBMIDMuMDc4MTI1IC0wLjU5Mzc1IEMgMy4wOTM3NSAtMC41NjI1IDMuMTI1IC0wLjUzMTI1IDMuMTU2MjUgLTAuNTE1NjI1IEMgMy4yMzQzNzUgLTAuNDA2MjUgMy4yNjU2MjUgLTAuMzQzNzUgMy4yNjU2MjUgLTAuMjk2ODc1IEMgMy4yNjU2MjUgLTAuMjAzMTI1IDMuMTcxODc1IC0wLjE1NjI1IDMuMDQ2ODc1IC0wLjE1NjI1IEwgMi44NTkzNzUgLTAuMTU2MjUgTCAyLjg1OTM3NSAwIEwgNS4wMzEyNSAwIEwgNS4wMzEyNSAtMC4xNTYyNSBDIDQuNTkzNzUgLTAuMTcxODc1IDQuMjgxMjUgLTAuMzc1IDMuODc1IC0wLjg3NSBMIDIuMzQzNzUgLTIuODEyNSBMIDIuNjI1IC0zLjA3ODEyNSBDIDMuMzQzNzUgLTMuNzM0Mzc1IDMuOTUzMTI1IC00LjIwMzEyNSA0LjI1IC00LjI4MTI1IEMgNC4zOTA2MjUgLTQuMzEyNSA0LjUzMTI1IC00LjM0Mzc1IDQuNzAzMTI1IC00LjM0Mzc1IEwgNC43ODEyNSAtNC4zNDM3NSBMIDQuNzgxMjUgLTQuNDg0Mzc1IEwgMi43NSAtNC40ODQzNzUgTCAyLjc1IC00LjM0Mzc1IEMgMy4xNDA2MjUgLTQuMzQzNzUgMy4yNSAtNC4yOTY4NzUgMy4yNSAtNC4xNTYyNSBDIDMuMjUgLTQuMDc4MTI1IDMuMTU2MjUgLTMuOTM3NSAzLjAxNTYyNSAtMy44MTI1IEwgMS42NTYyNSAtMi42MDkzNzUgTCAxLjY1NjI1IC02Ljc4MTI1IEwgMS42MDkzNzUgLTYuODEyNSBDIDEuMjM0Mzc1IC02LjY4NzUgMC45NTMxMjUgLTYuNjA5Mzc1IDAuMzc1IC02LjQ1MzEyNSBMIDAuMDYyNSAtNi4zNzUgWiBNIDAuMDYyNSAtNi4yMDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuMDYyNSAtMS42NDA2MjUgQyAzLjU5Mzc1IC0wLjg3NSAzLjE1NjI1IC0wLjU5Mzc1IDIuNTE1NjI1IC0wLjU5Mzc1IEMgMS45NTMxMjUgLTAuNTkzNzUgMS41MzEyNSAtMC44NzUgMS4yMzQzNzUgLTEuNDUzMTI1IEMgMS4wNjI1IC0xLjgyODEyNSAwLjk4NDM3NSAtMi4xNTYyNSAwLjk2ODc1IC0yLjc2NTYyNSBMIDQuMDMxMjUgLTIuNzY1NjI1IEMgMy45NTMxMjUgLTMuNDA2MjUgMy44NTkzNzUgLTMuNzAzMTI1IDMuNjA5Mzc1IC00LjAxNTYyNSBDIDMuMzEyNSAtNC4zNzUgMi44NDM3NSAtNC41NzgxMjUgMi4zMjgxMjUgLTQuNTc4MTI1IEMgMS44MjgxMjUgLTQuNTc4MTI1IDEuMzU5Mzc1IC00LjQwNjI1IDAuOTg0Mzc1IC00LjA2MjUgQyAwLjUxNTYyNSAtMy42NTYyNSAwLjI1IC0yLjk1MzEyNSAwLjI1IC0yLjE0MDYyNSBDIDAuMjUgLTAuNzUgMC45Njg3NSAwLjA5Mzc1IDIuMTA5Mzc1IDAuMDkzNzUgQyAzLjA2MjUgMC4wOTM3NSAzLjgxMjUgLTAuNDg0Mzc1IDQuMjM0Mzc1IC0xLjU2MjUgWiBNIDAuOTg0Mzc1IC0zLjA3ODEyNSBDIDEuMDkzNzUgLTMuODU5Mzc1IDEuNDM3NSAtNC4yMzQzNzUgMi4wNDY4NzUgLTQuMjM0Mzc1IEMgMi42NTYyNSAtNC4yMzQzNzUgMi44OTA2MjUgLTMuOTUzMTI1IDMuMDE1NjI1IC0zLjA3ODEyNSBaIE0gMC45ODQzNzUgLTMuMDc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS02Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjA2MjUgLTMuODkwNjI1IEMgMC4yMDMxMjUgLTMuOTIxODc1IDAuMjk2ODc1IC0zLjkyMTg3NSAwLjQyMTg3NSAtMy45MjE4NzUgQyAwLjY3MTg3NSAtMy45MjE4NzUgMC43NSAtMy43NjU2MjUgMC43NSAtMy4zMjgxMjUgTCAwLjc1IC0wLjg0Mzc1IEMgMC43NSAtMC4zNDM3NSAwLjY4NzUgLTAuMjY1NjI1IDAuMDQ2ODc1IC0wLjE1NjI1IEwgMC4wNDY4NzUgMCBMIDIuNDM3NSAwIEwgMi40Mzc1IC0wLjE1NjI1IEMgMS43NjU2MjUgLTAuMTcxODc1IDEuNTkzNzUgLTAuMzI4MTI1IDEuNTkzNzUgLTAuODkwNjI1IEwgMS41OTM3NSAtMy4xNDA2MjUgQyAxLjU5Mzc1IC0zLjQ1MzEyNSAyLjAzMTI1IC0zLjk1MzEyNSAyLjI5Njg3NSAtMy45NTMxMjUgQyAyLjM1OTM3NSAtMy45NTMxMjUgMi40Mzc1IC0zLjkwNjI1IDIuNTQ2ODc1IC0zLjgxMjUgQyAyLjcxODc1IC0zLjY3MTg3NSAyLjgyODEyNSAtMy42MDkzNzUgMi45NTMxMjUgLTMuNjA5Mzc1IEMgMy4xODc1IC0zLjYwOTM3NSAzLjM0Mzc1IC0zLjc4MTI1IDMuMzQzNzUgLTQuMDYyNSBDIDMuMzQzNzUgLTQuMzkwNjI1IDMuMTI1IC00LjU3ODEyNSAyLjc5Njg3NSAtNC41NzgxMjUgQyAyLjM3NSAtNC41NzgxMjUgMi4wNzgxMjUgLTQuMzU5Mzc1IDEuNTkzNzUgLTMuNjU2MjUgTCAxLjU5Mzc1IC00LjU2MjUgTCAxLjU0Njg3NSAtNC41NzgxMjUgQyAxLjAxNTYyNSAtNC4zNTkzNzUgMC42NTYyNSAtNC4yMzQzNzUgMC4wNjI1IC00LjA0Njg3NSBaIE0gMC4wNjI1IC0zLjg5MDYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtNyI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC4xNTYyNSAtMy45Njg3NSBDIDAuMjE4NzUgLTQgMC4zMTI1IC00IDAuNDIxODc1IC00IEMgMC43MDMxMjUgLTQgMC43OTY4NzUgLTMuODU5Mzc1IDAuNzk2ODc1IC0zLjM3NSBMIDAuNzk2ODc1IC0wLjg5MDYyNSBDIDAuNzk2ODc1IC0wLjMyODEyNSAwLjY4NzUgLTAuMTg3NSAwLjE3MTg3NSAtMC4xNTYyNSBMIDAuMTcxODc1IDAgTCAyLjI5Njg3NSAwIEwgMi4yOTY4NzUgLTAuMTU2MjUgQyAxLjc4MTI1IC0wLjE4NzUgMS42NDA2MjUgLTAuMzEyNSAxLjY0MDYyNSAtMC42NzE4NzUgTCAxLjY0MDYyNSAtMy40Njg3NSBDIDIuMTA5Mzc1IC0zLjkyMTg3NSAyLjMyODEyNSAtNC4wMzEyNSAyLjY1NjI1IC00LjAzMTI1IEMgMy4xNTYyNSAtNC4wMzEyNSAzLjM5MDYyNSAtMy43MzQzNzUgMy4zOTA2MjUgLTMuMDc4MTI1IEwgMy4zOTA2MjUgLTAuOTg0Mzc1IEMgMy4zOTA2MjUgLTAuMzU5Mzc1IDMuMjY1NjI1IC0wLjE4NzUgMi43NjU2MjUgLTAuMTU2MjUgTCAyLjc2NTYyNSAwIEwgNC44MjgxMjUgMCBMIDQuODI4MTI1IC0wLjE1NjI1IEMgNC4zNDM3NSAtMC4yMDMxMjUgNC4yMzQzNzUgLTAuMzEyNSA0LjIzNDM3NSAtMC44MTI1IEwgNC4yMzQzNzUgLTMuMDkzNzUgQyA0LjIzNDM3NSAtNC4wMzEyNSAzLjc4MTI1IC00LjU3ODEyNSAzLjA0Njg3NSAtNC41NzgxMjUgQyAyLjU5Mzc1IC00LjU3ODEyNSAyLjI4MTI1IC00LjQyMTg3NSAxLjYwOTM3NSAtMy43ODEyNSBMIDEuNjA5Mzc1IC00LjU2MjUgTCAxLjUzMTI1IC00LjU3ODEyNSBDIDEuMDQ2ODc1IC00LjQwNjI1IDAuNzAzMTI1IC00LjI5Njg3NSAwLjE1NjI1IC00LjE0MDYyNSBaIE0gMC4xNTYyNSAtMy45Njg3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtOCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC4xODc1IC02LjIwMzEyNSBMIDAuMjUgLTYuMjAzMTI1IEMgMC4zNTkzNzUgLTYuMjE4NzUgMC40ODQzNzUgLTYuMjM0Mzc1IDAuNTYyNSAtNi4yMzQzNzUgQyAwLjg3NSAtNi4yMzQzNzUgMC45ODQzNzUgLTYuMDkzNzUgMC45ODQzNzUgLTUuNjI1IEwgMC45ODQzNzUgLTAuODc1IEMgMC45ODQzNzUgLTAuMzI4MTI1IDAuODQzNzUgLTAuMjAzMTI1IDAuMjAzMTI1IC0wLjE1NjI1IEwgMC4yMDMxMjUgMCBMIDIuNTYyNSAwIEwgMi41NjI1IC0wLjE1NjI1IEMgMS45Mzc1IC0wLjE4NzUgMS44MTI1IC0wLjI5Njg3NSAxLjgxMjUgLTAuODQzNzUgTCAxLjgxMjUgLTYuNzgxMjUgTCAxLjc4MTI1IC02LjgxMjUgQyAxLjI1IC02LjY0MDYyNSAwLjg3NSAtNi41NDY4NzUgMC4xODc1IC02LjM3NSBaIE0gMC4xODc1IC02LjIwMzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtOSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNi4xODc1IC00LjQ4NDM3NSBMIDYuMDkzNzUgLTYuNzM0Mzc1IEwgNS44NzUgLTYuNzM0Mzc1IEMgNS44MjgxMjUgLTYuNTMxMjUgNS42NTYyNSAtNi40MDYyNSA1LjQ2ODc1IC02LjQwNjI1IEMgNS4zNzUgLTYuNDA2MjUgNS4yMTg3NSAtNi40Mzc1IDUuMDc4MTI1IC02LjUgQyA0LjU3ODEyNSAtNi42NTYyNSA0LjA5Mzc1IC02LjczNDM3NSAzLjYyNSAtNi43MzQzNzUgQyAyLjc5Njg3NSAtNi43MzQzNzUgMS45Njg3NSAtNi40Mzc1IDEuMzU5Mzc1IC01Ljg3NSBDIDAuNjU2MjUgLTUuMjY1NjI1IDAuMjgxMjUgLTQuMzQzNzUgMC4yODEyNSAtMy4yMzQzNzUgQyAwLjI4MTI1IC0yLjMxMjUgMC41NzgxMjUgLTEuNDUzMTI1IDEuMDkzNzUgLTAuODkwNjI1IEMgMS42ODc1IC0wLjIzNDM3NSAyLjYwOTM3NSAwLjE0MDYyNSAzLjU5Mzc1IDAuMTQwNjI1IEMgNC43MTg3NSAwLjE0MDYyNSA1LjcwMzEyNSAtMC4zMTI1IDYuMzEyNSAtMS4xMjUgTCA2LjEyNSAtMS4zMTI1IEMgNS4zOTA2MjUgLTAuNTkzNzUgNC43MzQzNzUgLTAuMjk2ODc1IDMuOTA2MjUgLTAuMjk2ODc1IEMgMy4yODEyNSAtMC4yOTY4NzUgMi43MTg3NSAtMC41IDIuMjk2ODc1IC0wLjg3NSBDIDEuNzUgLTEuMzU5Mzc1IDEuNDM3NSAtMi4yNjU2MjUgMS40Mzc1IC0zLjM3NSBDIDEuNDM3NSAtNS4xNzE4NzUgMi4zNTkzNzUgLTYuMzQzNzUgMy44MTI1IC02LjM0Mzc1IEMgNC4zNzUgLTYuMzQzNzUgNC44OTA2MjUgLTYuMTI1IDUuMjk2ODc1IC01LjczNDM3NSBDIDUuNjA5Mzc1IC01LjQwNjI1IDUuNzY1NjI1IC01LjE0MDYyNSA1Ljk1MzEyNSAtNC40ODQzNzUgWiBNIDYuMTg3NSAtNC40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTEwIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjAzMTI1IC0xLjA5Mzc1IEMgMS4wMzEyNSAtMC4zNzUgMC45MjE4NzUgLTAuMjM0Mzc1IDAuMTU2MjUgLTAuMTg3NSBMIDAuMTU2MjUgMCBMIDIuOTg0Mzc1IDAgQyA0LjE0MDYyNSAwIDUuMTg3NSAtMC4zMjgxMjUgNS44MTI1IC0wLjg5MDYyNSBDIDYuNDUzMTI1IC0xLjQ2ODc1IDYuODI4MTI1IC0yLjM1OTM3NSA2LjgyODEyNSAtMy4zMjgxMjUgQyA2LjgyODEyNSAtNC4yMzQzNzUgNi41MzEyNSAtNSA1Ljk4NDM3NSAtNS41NDY4NzUgQyA1LjI5Njg3NSAtNi4yMzQzNzUgNC4yMTg3NSAtNi41OTM3NSAyLjg0Mzc1IC02LjU5Mzc1IEwgMC4xNTYyNSAtNi41OTM3NSBMIDAuMTU2MjUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjAzMTI1IC02LjI1IDEuMDMxMjUgLTUuNTE1NjI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSBDIDIuMDQ2ODc1IC02LjE1NjI1IDIuMTU2MjUgLTYuMjM0Mzc1IDIuNTc4MTI1IC02LjIzNDM3NSBDIDMuNDIxODc1IC02LjIzNDM3NSA0LjA3ODEyNSAtNi4wNzgxMjUgNC41NjI1IC01LjczNDM3NSBDIDUuMzI4MTI1IC01LjE4NzUgNS43MzQzNzUgLTQuMzQzNzUgNS43MzQzNzUgLTMuMjY1NjI1IEMgNS43MzQzNzUgLTIuMDc4MTI1IDUuMzI4MTI1IC0xLjI1IDQuNTMxMjUgLTAuNzgxMjUgQyA0LjAxNTYyNSAtMC40ODQzNzUgMy40Mzc1IC0wLjM3NSAyLjU3ODEyNSAtMC4zNzUgQyAyLjE3MTg3NSAtMC4zNzUgMi4wNDY4NzUgLTAuNDUzMTI1IDIuMDQ2ODc1IC0wLjc4MTI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDAuMzEyNSAtNC4xNTYyNSBMIDAuOTg0Mzc1IC00LjE1NjI1IEwgMC45ODQzNzUgLTAuOTM3NSBDIDAuOTg0Mzc1IC0wLjI5Njg3NSAwLjg3NSAtMC4xNzE4NzUgMC4zMTI1IC0wLjE1NjI1IEwgMC4zMTI1IDAgTCAyLjUxNTYyNSAwIEwgMi41MTU2MjUgLTAuMTU2MjUgQyAxLjk1MzEyNSAtMC4xODc1IDEuODI4MTI1IC0wLjMyODEyNSAxLjgyODEyNSAtMC44NzUgTCAxLjgyODEyNSAtNC4xNTYyNSBMIDIuNjg3NSAtNC4xNTYyNSBDIDMuNjQwNjI1IC00LjE1NjI1IDMuNjg3NSAtNC4xMjUgMy42ODc1IC0zLjU5Mzc1IEwgMy42ODc1IC0wLjk2ODc1IEMgMy42ODc1IC0wLjI5Njg3NSAzLjYyNSAtMC4yMDMxMjUgMyAtMC4xNTYyNSBMIDMgMCBMIDUuMTg3NSAwIEwgNS4xODc1IC0wLjE1NjI1IEMgNC42NDA2MjUgLTAuMjAzMTI1IDQuNTMxMjUgLTAuMzI4MTI1IDQuNTMxMjUgLTAuOTY4NzUgTCA0LjUzMTI1IC0zLjU3ODEyNSBDIDQuNTMxMjUgLTMuNzk2ODc1IDQuNTMxMjUgLTQuMDMxMjUgNC41NDY4NzUgLTQuNTYyNSBMIDQuNSAtNC41NzgxMjUgQyA0LjA2MjUgLTQuNTE1NjI1IDMuNzgxMjUgLTQuNDg0Mzc1IDMuMzc1IC00LjQ4NDM3NSBMIDEuODEyNSAtNC40ODQzNzUgTCAxLjgxMjUgLTQuOTIxODc1IEMgMS44MTI1IC01LjM1OTM3NSAxLjg0Mzc1IC01LjY1NjI1IDEuODkwNjI1IC01LjgyODEyNSBDIDIuMDMxMjUgLTYuMjY1NjI1IDIuNDIxODc1IC02LjU2MjUgMi44NzUgLTYuNTYyNSBDIDMuMTU2MjUgLTYuNTYyNSAzLjM0Mzc1IC02LjQzNzUgMy41NzgxMjUgLTYuMDkzNzUgQyAzLjc2NTYyNSAtNS44MjgxMjUgMy44OTA2MjUgLTUuNzE4NzUgNC4wNjI1IC01LjcxODc1IEMgNC4yODEyNSAtNS43MTg3NSA0LjQyMTg3NSAtNS44OTA2MjUgNC40MjE4NzUgLTYuMTA5Mzc1IEMgNC40MjE4NzUgLTYuNTMxMjUgMy45MjE4NzUgLTYuODEyNSAzLjE1NjI1IC02LjgxMjUgQyAyLjQwNjI1IC02LjgxMjUgMS44MjgxMjUgLTYuNTQ2ODc1IDEuNDY4NzUgLTYuMDYyNSBDIDEuMTcxODc1IC01LjY1NjI1IDEuMDYyNSAtNS4yODEyNSAxIC00LjQ4NDM3NSBMIDAuMzEyNSAtNC40ODQzNzUgWiBNIDAuMzEyNSAtNC4xNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuOTA2MjUgLTYuNzM0Mzc1IEwgMS4xMDkzNzUgLTUuODI4MTI1IEwgMS4xMDkzNzUgLTUuNjg3NSBDIDEuMjE4NzUgLTUuNzM0Mzc1IDEuMzI4MTI1IC01Ljc4MTI1IDEuMzc1IC01Ljc5Njg3NSBDIDEuNTYyNSAtNS44NzUgMS43MTg3NSAtNS45MDYyNSAxLjgyODEyNSAtNS45MDYyNSBDIDIuMDMxMjUgLTUuOTA2MjUgMi4xMjUgLTUuNzY1NjI1IDIuMTI1IC01LjQzNzUgTCAyLjEyNSAtMC45MjE4NzUgQyAyLjEyNSAtMC41OTM3NSAyLjA0Njg3NSAtMC4zNzUgMS44OTA2MjUgLTAuMjgxMjUgQyAxLjczNDM3NSAtMC4xODc1IDEuNTkzNzUgLTAuMTU2MjUgMS4xNzE4NzUgLTAuMTU2MjUgTCAxLjE3MTg3NSAwIEwgMy45MjE4NzUgMCBMIDMuOTIxODc1IC0wLjE1NjI1IEMgMy4xNDA2MjUgLTAuMTU2MjUgMi45ODQzNzUgLTAuMjY1NjI1IDIuOTg0Mzc1IC0wLjczNDM3NSBMIDIuOTg0Mzc1IC02LjcxODc1IFogTSAyLjkwNjI1IC02LjczNDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTMiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzM0Mzc1IC0xLjM1OTM3NSBMIDQuNjA5Mzc1IC0xLjQyMTg3NSBDIDQuMjM0Mzc1IC0wLjg0Mzc1IDQuMTA5Mzc1IC0wLjc1IDMuNjU2MjUgLTAuNzUgTCAxLjI4MTI1IC0wLjc1IEwgMi45NTMxMjUgLTIuNTE1NjI1IEMgMy44NDM3NSAtMy40Mzc1IDQuMjM0Mzc1IC00LjIwMzEyNSA0LjIzNDM3NSAtNC45Njg3NSBDIDQuMjM0Mzc1IC01Ljk2ODc1IDMuNDIxODc1IC02LjczNDM3NSAyLjM3NSAtNi43MzQzNzUgQyAxLjgyODEyNSAtNi43MzQzNzUgMS4zMTI1IC02LjUxNTYyNSAwLjk1MzEyNSAtNi4xMjUgQyAwLjYyNSAtNS43ODEyNSAwLjQ4NDM3NSAtNS40Njg3NSAwLjMxMjUgLTQuNzUgTCAwLjUxNTYyNSAtNC43MDMxMjUgQyAwLjkyMTg3NSAtNS42ODc1IDEuMjgxMjUgLTYgMS45Njg3NSAtNiBDIDIuNzk2ODc1IC02IDMuMzc1IC01LjQzNzUgMy4zNzUgLTQuNTkzNzUgQyAzLjM3NSAtMy44MTI1IDIuOTA2MjUgLTIuODkwNjI1IDIuMDc4MTI1IC0yIEwgMC4yOTY4NzUgLTAuMTI1IEwgMC4yOTY4NzUgMCBMIDQuMTg3NSAwIFogTSA0LjczNDM3NSAtMS4zNTkzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE0Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjk2ODc1IC0xLjU2MjUgQyAzLjQ4NDM3NSAtMC44NTkzNzUgMy4xMjUgLTAuNjI1IDIuNTYyNSAtMC42MjUgQyAxLjY1NjI1IC0wLjYyNSAxLjAxNTYyNSAtMS40MjE4NzUgMS4wMTU2MjUgLTIuNTYyNSBDIDEuMDE1NjI1IC0zLjU5Mzc1IDEuNTYyNSAtNC4yOTY4NzUgMi4zNzUgLTQuMjk2ODc1IEMgMi43MzQzNzUgLTQuMjk2ODc1IDIuODU5Mzc1IC00LjE4NzUgMi45NTMxMjUgLTMuODEyNSBMIDMuMDE1NjI1IC0zLjU5Mzc1IEMgMy4wOTM3NSAtMy4zMTI1IDMuMjgxMjUgLTMuMTQwNjI1IDMuNDg0Mzc1IC0zLjE0MDYyNSBDIDMuNzUgLTMuMTQwNjI1IDMuOTY4NzUgLTMuMzI4MTI1IDMuOTY4NzUgLTMuNTYyNSBDIDMuOTY4NzUgLTQuMTA5Mzc1IDMuMjY1NjI1IC00LjU3ODEyNSAyLjQzNzUgLTQuNTc4MTI1IEMgMS45Mzc1IC00LjU3ODEyNSAxLjQzNzUgLTQuMzkwNjI1IDEuMDMxMjUgLTQuMDMxMjUgQyAwLjUzMTI1IC0zLjU5Mzc1IDAuMjUgLTIuOTA2MjUgMC4yNSAtMi4xMjUgQyAwLjI1IC0wLjgyODEyNSAxLjAzMTI1IDAuMDkzNzUgMi4xNDA2MjUgMC4wOTM3NSBDIDIuNTkzNzUgMC4wOTM3NSAyLjk4NDM3NSAtMC4wNjI1IDMuMzQzNzUgLTAuMzc1IEMgMy42MjUgLTAuNjA5Mzc1IDMuODEyNSAtMC44NzUgNC4xMDkzNzUgLTEuNDY4NzUgWiBNIDMuOTY4NzUgLTEuNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuNTQ2ODc1IC00LjQ4NDM3NSBMIDEuNTMxMjUgLTQuNDg0Mzc1IEwgMS41MzEyNSAtNS42NDA2MjUgQyAxLjUzMTI1IC01LjczNDM3NSAxLjUzMTI1IC01Ljc2NTYyNSAxLjQ2ODc1IC01Ljc2NTYyNSBDIDEuMzkwNjI1IC01LjY4NzUgMS4zMjgxMjUgLTUuNTkzNzUgMS4yNjU2MjUgLTUuNSBDIDAuODkwNjI1IC00LjkzNzUgMC40NTMxMjUgLTQuNDY4NzUgMC4yOTY4NzUgLTQuNDIxODc1IEMgMC4xODc1IC00LjM1OTM3NSAwLjEyNSAtNC4yODEyNSAwLjEyNSAtNC4yMzQzNzUgQyAwLjEyNSAtNC4yMDMxMjUgMC4xNDA2MjUgLTQuMTg3NSAwLjE3MTg3NSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtMS4xNzE4NzUgQyAwLjcwMzEyNSAtMC4zMjgxMjUgMSAwLjA5Mzc1IDEuNTc4MTI1IDAuMDkzNzUgQyAyLjA3ODEyNSAwLjA5Mzc1IDIuNDUzMTI1IC0wLjE0MDYyNSAyLjc4MTI1IC0wLjY1NjI1IEwgMi42NTYyNSAtMC43NjU2MjUgQyAyLjQzNzUgLTAuNTE1NjI1IDIuMjY1NjI1IC0wLjQyMTg3NSAyLjA0Njg3NSAtMC40MjE4NzUgQyAxLjY4NzUgLTAuNDIxODc1IDEuNTMxMjUgLTAuNjg3NSAxLjUzMTI1IC0xLjMxMjUgTCAxLjUzMTI1IC00LjE3MTg3NSBMIDIuNTQ2ODc1IC00LjE3MTg3NSBaIE0gMi41NDY4NzUgLTQuNDg0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0xNiI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNC40MDYyNSAtMC42NTYyNSBDIDQuMjM0Mzc1IC0wLjUxNTYyNSA0LjEwOTM3NSAtMC40Njg3NSAzLjk2ODc1IC0wLjQ2ODc1IEMgMy43MzQzNzUgLTAuNDY4NzUgMy42NzE4NzUgLTAuNjA5Mzc1IDMuNjcxODc1IC0xLjA0Njg3NSBMIDMuNjcxODc1IC0yLjk4NDM3NSBDIDMuNjcxODc1IC0zLjUxNTYyNSAzLjYyNSAtMy43OTY4NzUgMy40Njg3NSAtNC4wMzEyNSBDIDMuMjUgLTQuMzkwNjI1IDIuODI4MTI1IC00LjU3ODEyNSAyLjIzNDM3NSAtNC41NzgxMjUgQyAxLjI5Njg3NSAtNC41NzgxMjUgMC41NjI1IC00LjA5Mzc1IDAuNTYyNSAtMy40Njg3NSBDIDAuNTYyNSAtMy4yMzQzNzUgMC43NSAtMy4wNDY4NzUgMC45ODQzNzUgLTMuMDQ2ODc1IEMgMS4yMTg3NSAtMy4wNDY4NzUgMS40Mzc1IC0zLjIzNDM3NSAxLjQzNzUgLTMuNDUzMTI1IEMgMS40Mzc1IC0zLjUgMS40MjE4NzUgLTMuNTQ2ODc1IDEuNDIxODc1IC0zLjYyNSBDIDEuMzkwNjI1IC0zLjcwMzEyNSAxLjM5MDYyNSAtMy43ODEyNSAxLjM5MDYyNSAtMy44NTkzNzUgQyAxLjM5MDYyNSAtNC4xMjUgMS43MDMxMjUgLTQuMzQzNzUgMi4xMDkzNzUgLTQuMzQzNzUgQyAyLjU5Mzc1IC00LjM0Mzc1IDIuODU5Mzc1IC00LjA2MjUgMi44NTkzNzUgLTMuNTE1NjI1IEwgMi44NTkzNzUgLTIuOTA2MjUgQyAxLjMyODEyNSAtMi4yOTY4NzUgMS4xNTYyNSAtMi4yMTg3NSAwLjczNDM3NSAtMS44MjgxMjUgQyAwLjUxNTYyNSAtMS42NDA2MjUgMC4zNzUgLTEuMjk2ODc1IDAuMzc1IC0wLjk2ODc1IEMgMC4zNzUgLTAuMzQzNzUgMC44MTI1IDAuMDkzNzUgMS40MjE4NzUgMC4wOTM3NSBDIDEuODU5Mzc1IDAuMDkzNzUgMi4yNjU2MjUgLTAuMTA5Mzc1IDIuODc1IC0wLjYyNSBDIDIuOTIxODc1IC0wLjEwOTM3NSAzLjA5Mzc1IDAuMDkzNzUgMy41MTU2MjUgMC4wOTM3NSBDIDMuODQzNzUgMC4wOTM3NSA0LjA2MjUgLTAuMDE1NjI1IDQuNDA2MjUgLTAuNDA2MjUgWiBNIDIuODU5Mzc1IC0xLjIxODc1IEMgMi44NTkzNzUgLTAuOTIxODc1IDIuODEyNSAtMC44MjgxMjUgMi42MDkzNzUgLTAuNzAzMTI1IEMgMi4zNTkzNzUgLTAuNTYyNSAyLjA3ODEyNSAtMC40ODQzNzUgMS44NzUgLTAuNDg0Mzc1IEMgMS41MzEyNSAtMC40ODQzNzUgMS4yNSAtMC44MTI1IDEuMjUgLTEuMjUgTCAxLjI1IC0xLjI4MTI1IEMgMS4yNSAtMS44NzUgMS42NTYyNSAtMi4yMzQzNzUgMi44NTkzNzUgLTIuNjcxODc1IFogTSAyLjg1OTM3NSAtMS4yMTg3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTciPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDMuNDIxODc1IDAuMDkzNzUgTCA0Ljg5MDYyNSAtMC40MjE4NzUgTCA0Ljg5MDYyNSAtMC41NzgxMjUgQyA0LjcxODc1IC0wLjU2MjUgNC42ODc1IC0wLjU2MjUgNC42NzE4NzUgLTAuNTYyNSBDIDQuMzEyNSAtMC41NjI1IDQuMjM0Mzc1IC0wLjY3MTg3NSA0LjIzNDM3NSAtMS4xNDA2MjUgTCA0LjIzNDM3NSAtNi43ODEyNSBMIDQuMTcxODc1IC02LjgxMjUgQyAzLjcwMzEyNSAtNi42NDA2MjUgMy4zNDM3NSAtNi41NDY4NzUgMi43MTg3NSAtNi4zNzUgTCAyLjcxODc1IC02LjIwMzEyNSBDIDIuNzk2ODc1IC02LjIxODc1IDIuODQzNzUgLTYuMjE4NzUgMi45Mzc1IC02LjIxODc1IEMgMy4yOTY4NzUgLTYuMjE4NzUgMy4zOTA2MjUgLTYuMTI1IDMuMzkwNjI1IC01LjcxODc1IEwgMy4zOTA2MjUgLTQuMTU2MjUgQyAzLjAxNTYyNSAtNC40Njg3NSAyLjczNDM3NSAtNC41NzgxMjUgMi4zNDM3NSAtNC41NzgxMjUgQyAxLjIwMzEyNSAtNC41NzgxMjUgMC4yNjU2MjUgLTMuNDUzMTI1IDAuMjY1NjI1IC0yLjA0Njg3NSBDIDAuMjY1NjI1IC0wLjc2NTYyNSAxLjAxNTYyNSAwLjA5Mzc1IDIuMTA5Mzc1IDAuMDkzNzUgQyAyLjY3MTg3NSAwLjA5Mzc1IDMuMDQ2ODc1IC0wLjA5Mzc1IDMuMzkwNjI1IC0wLjU2MjUgTCAzLjM5MDYyNSAwLjA2MjUgWiBNIDMuMzkwNjI1IC0xLjAxNTYyNSBDIDMuMzkwNjI1IC0wLjk1MzEyNSAzLjMxMjUgLTAuODI4MTI1IDMuMjE4NzUgLTAuNzE4NzUgQyAzLjA0Njg3NSAtMC41MTU2MjUgMi43OTY4NzUgLTAuNDIxODc1IDIuNSAtMC40MjE4NzUgQyAxLjY3MTg3NSAtMC40MjE4NzUgMS4xMjUgLTEuMjE4NzUgMS4xMjUgLTIuNDM3NSBDIDEuMTI1IC0zLjU2MjUgMS42MDkzNzUgLTQuMzEyNSAyLjM3NSAtNC4zMTI1IEMgMi45MDYyNSAtNC4zMTI1IDMuMzkwNjI1IC0zLjg0Mzc1IDMuMzkwNjI1IC0zLjMxMjUgWiBNIDMuMzkwNjI1IC0xLjAxNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTgiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDEuNzUgLTQuNTc4MTI1IEwgMC4yMDMxMjUgLTQuMDMxMjUgTCAwLjIwMzEyNSAtMy44OTA2MjUgTCAwLjI4MTI1IC0zLjg5MDYyNSBDIDAuNDA2MjUgLTMuOTIxODc1IDAuNTMxMjUgLTMuOTIxODc1IDAuNjI1IC0zLjkyMTg3NSBDIDAuODU5Mzc1IC0zLjkyMTg3NSAwLjk1MzEyNSAtMy43NjU2MjUgMC45NTMxMjUgLTMuMzI4MTI1IEwgMC45NTMxMjUgLTEuMDE1NjI1IEMgMC45NTMxMjUgLTAuMjk2ODc1IDAuODQzNzUgLTAuMTg3NSAwLjE1NjI1IC0wLjE1NjI1IEwgMC4xNTYyNSAwIEwgMi41MTU2MjUgMCBMIDIuNTE1NjI1IC0wLjE1NjI1IEMgMS44NTkzNzUgLTAuMjAzMTI1IDEuNzgxMjUgLTAuMjk2ODc1IDEuNzgxMjUgLTEuMDE1NjI1IEwgMS43ODEyNSAtNC41NjI1IFogTSAxLjI4MTI1IC02LjgxMjUgQyAxIC02LjgxMjUgMC43ODEyNSAtNi41NzgxMjUgMC43ODEyNSAtNi4yOTY4NzUgQyAwLjc4MTI1IC02LjAxNTYyNSAxIC01Ljc5Njg3NSAxLjI4MTI1IC01Ljc5Njg3NSBDIDEuNTYyNSAtNS43OTY4NzUgMS43OTY4NzUgLTYuMDE1NjI1IDEuNzk2ODc1IC02LjI5Njg3NSBDIDEuNzk2ODc1IC02LjU3ODEyNSAxLjU2MjUgLTYuODEyNSAxLjI4MTI1IC02LjgxMjUgWiBNIDEuMjgxMjUgLTYuODEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTkiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuNSAtNC41NzgxMjUgQyAxLjIwMzEyNSAtNC41NzgxMjUgMC4yOTY4NzUgLTMuNjI1IDAuMjk2ODc1IC0yLjI1IEMgMC4yOTY4NzUgLTAuOTA2MjUgMS4yMTg3NSAwLjA5Mzc1IDIuNDY4NzUgMC4wOTM3NSBDIDMuNzM0Mzc1IDAuMDkzNzUgNC42ODc1IC0wLjk1MzEyNSA0LjY4NzUgLTIuMzI4MTI1IEMgNC42ODc1IC0zLjY0MDYyNSAzLjc2NTYyNSAtNC41NzgxMjUgMi41IC00LjU3ODEyNSBaIE0gMi4zNTkzNzUgLTQuMzEyNSBDIDMuMjAzMTI1IC00LjMxMjUgMy43ODEyNSAtMy4zNDM3NSAzLjc4MTI1IC0xLjk4NDM3NSBDIDMuNzgxMjUgLTAuODU5Mzc1IDMuMzQzNzUgLTAuMTcxODc1IDIuNTkzNzUgLTAuMTcxODc1IEMgMi4yMDMxMjUgLTAuMTcxODc1IDEuODI4MTI1IC0wLjQyMTg3NSAxLjYyNSAtMC44MTI1IEMgMS4zNDM3NSAtMS4zMjgxMjUgMS4xODc1IC0yLjAzMTI1IDEuMTg3NSAtMi43MzQzNzUgQyAxLjE4NzUgLTMuNjg3NSAxLjY1NjI1IC00LjMxMjUgMi4zNTkzNzUgLTQuMzEyNSBaIE0gMi4zNTkzNzUgLTQuMzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMjAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzM0Mzc1IC00LjQ4NDM3NSBMIDMuMzkwNjI1IC00LjQ4NDM3NSBMIDMuMzkwNjI1IC00LjM0Mzc1IEMgMy43MDMxMjUgLTQuMzQzNzUgMy44NzUgLTQuMjUgMy44NzUgLTQuMDkzNzUgQyAzLjg3NSAtNC4wNDY4NzUgMy44NTkzNzUgLTMuOTg0Mzc1IDMuODI4MTI1IC0zLjkyMTg3NSBMIDIuODU5Mzc1IC0xLjE3MTg3NSBMIDEuNzE4NzUgLTMuNjg3NSBDIDEuNjU2MjUgLTMuODI4MTI1IDEuNjA5Mzc1IC0zLjk1MzEyNSAxLjYwOTM3NSAtNC4wNjI1IEMgMS42MDkzNzUgLTQuMjUgMS43NjU2MjUgLTQuMzEyNSAyLjE4NzUgLTQuMzQzNzUgTCAyLjE4NzUgLTQuNDg0Mzc1IEwgMC4xNDA2MjUgLTQuNDg0Mzc1IEwgMC4xNDA2MjUgLTQuMzQzNzUgQyAwLjQwNjI1IC00LjMxMjUgMC41NjI1IC00LjIwMzEyNSAwLjY0MDYyNSAtNC4wMzEyNSBMIDEuNzgxMjUgLTEuNTc4MTI1IEwgMS44MTI1IC0xLjUgTCAxLjk2ODc1IC0xLjIwMzEyNSBDIDIuMjUgLTAuNzAzMTI1IDIuNDA2MjUgLTAuMzQzNzUgMi40MDYyNSAtMC4xODc1IEMgMi40MDYyNSAtMC4wNDY4NzUgMi4xNzE4NzUgMC41OTM3NSAyIDAuODkwNjI1IEMgMS44NTkzNzUgMS4xNDA2MjUgMS42NDA2MjUgMS4zMjgxMjUgMS41IDEuMzI4MTI1IEMgMS40NTMxMjUgMS4zMjgxMjUgMS4zNTkzNzUgMS4zMTI1IDEuMjUgMS4yNjU2MjUgQyAxLjA2MjUgMS4yMDMxMjUgMC44OTA2MjUgMS4xNTYyNSAwLjczNDM3NSAxLjE1NjI1IEMgMC41IDEuMTU2MjUgMC4yOTY4NzUgMS4zNTkzNzUgMC4yOTY4NzUgMS41OTM3NSBDIDAuMjk2ODc1IDEuOTIxODc1IDAuNjI1IDIuMTcxODc1IDEuMDMxMjUgMi4xNzE4NzUgQyAxLjcwMzEyNSAyLjE3MTg3NSAyLjE4NzUgMS42MDkzNzUgMi43MTg3NSAwLjE3MTg3NSBMIDQuMjUgLTMuODkwNjI1IEMgNC4zOTA2MjUgLTQuMjAzMTI1IDQuNSAtNC4zMTI1IDQuNzM0Mzc1IC00LjM0Mzc1IFogTSA0LjczNDM3NSAtNC40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgyLTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDItMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMi4xNDA2MjUgLTQuOTg0Mzc1IEwgMC44MTI1IC00LjMxMjUgTCAwLjgxMjUgLTQuMjE4NzUgQyAwLjkwNjI1IC00LjI1IDAuOTg0Mzc1IC00LjI4MTI1IDEuMDE1NjI1IC00LjI5Njg3NSBDIDEuMTU2MjUgLTQuMzQzNzUgMS4yODEyNSAtNC4zNzUgMS4zNDM3NSAtNC4zNzUgQyAxLjUgLTQuMzc1IDEuNTc4MTI1IC00LjI2NTYyNSAxLjU3ODEyNSAtNC4wMzEyNSBMIDEuNTc4MTI1IC0wLjY4NzUgQyAxLjU3ODEyNSAtMC40Mzc1IDEuNTE1NjI1IC0wLjI2NTYyNSAxLjM5MDYyNSAtMC4yMDMxMjUgQyAxLjI4MTI1IC0wLjE0MDYyNSAxLjE4NzUgLTAuMTI1IDAuODc1IC0wLjEwOTM3NSBMIDAuODc1IDAgTCAyLjkwNjI1IDAgTCAyLjkwNjI1IC0wLjEwOTM3NSBDIDIuMzI4MTI1IC0wLjEyNSAyLjIwMzEyNSAtMC4xODc1IDIuMjAzMTI1IC0wLjU0Njg3NSBMIDIuMjAzMTI1IC00Ljk2ODc1IFogTSAyLjE0MDYyNSAtNC45ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgyLTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDMuNSAtMS4wMTU2MjUgTCAzLjQwNjI1IC0xLjA0Njg3NSBDIDMuMTQwNjI1IC0wLjYyNSAzLjAzMTI1IC0wLjU2MjUgMi43MDMxMjUgLTAuNTYyNSBMIDAuOTM3NSAtMC41NjI1IEwgMi4xODc1IC0xLjg1OTM3NSBDIDIuODQzNzUgLTIuNTQ2ODc1IDMuMTI1IC0zLjEwOTM3NSAzLjEyNSAtMy42ODc1IEMgMy4xMjUgLTQuNDIxODc1IDIuNTMxMjUgLTQuOTg0Mzc1IDEuNzY1NjI1IC00Ljk4NDM3NSBDIDEuMzU5Mzc1IC00Ljk4NDM3NSAwLjk2ODc1IC00LjgyODEyNSAwLjcwMzEyNSAtNC41MzEyNSBDIDAuNDY4NzUgLTQuMjgxMjUgMC4zNTkzNzUgLTQuMDQ2ODc1IDAuMjM0Mzc1IC0zLjUxNTYyNSBMIDAuMzkwNjI1IC0zLjQ4NDM3NSBDIDAuNjcxODc1IC00LjIwMzEyNSAwLjkzNzUgLTQuNDM3NSAxLjQ1MzEyNSAtNC40Mzc1IEMgMi4wNzgxMjUgLTQuNDM3NSAyLjUgLTQuMDE1NjI1IDIuNSAtMy40MDYyNSBDIDIuNSAtMi44MjgxMjUgMi4xNTYyNSAtMi4xNDA2MjUgMS41MzEyNSAtMS40ODQzNzUgTCAwLjIxODc1IC0wLjA5Mzc1IEwgMC4yMTg3NSAwIEwgMy4wOTM3NSAwIFogTSAzLjUgLTEuMDE1NjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMy0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgzLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuMjk2ODc1IC0yLjk4NDM3NSBDIDIuMjk2ODc1IC0zLjMyODEyNSAyLjAxNTYyNSAtMy42MjUgMS42NTYyNSAtMy42MjUgQyAxLjMxMjUgLTMuNjI1IDEuMDMxMjUgLTMuMzI4MTI1IDEuMDMxMjUgLTIuOTg0Mzc1IEMgMS4wMzEyNSAtMi42NDA2MjUgMS4zMTI1IC0yLjM1OTM3NSAxLjY1NjI1IC0yLjM1OTM3NSBDIDIuMDE1NjI1IC0yLjM1OTM3NSAyLjI5Njg3NSAtMi42NDA2MjUgMi4yOTY4NzUgLTIuOTg0Mzc1IFogTSAyLjI5Njg3NSAtMi45ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg0LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDQtMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNS4zNTkzNzUgLTQuODEyNSBMIDMuODkwNjI1IC00LjgxMjUgTCAzLjg5MDYyNSAtNC43MDMxMjUgQyA0LjMxMjUgLTQuNjU2MjUgNC40MDYyNSAtNC41OTM3NSA0LjQwNjI1IC00LjMyODEyNSBDIDQuNDA2MjUgLTQuMjM0Mzc1IDQuMzkwNjI1IC00LjE0MDYyNSA0LjM0Mzc1IC00IEMgNC4zNDM3NSAtMy45Njg3NSA0LjMyODEyNSAtMy45NTMxMjUgNC4zMjgxMjUgLTMuOTM3NSBMIDMuNTc4MTI1IC0xLjE0MDYyNSBMIDIuMDQ2ODc1IC00LjgxMjUgTCAwLjg1OTM3NSAtNC44MTI1IEwgMC44NTkzNzUgLTQuNzAzMTI1IEMgMS4yMDMxMjUgLTQuNjcxODc1IDEuMzU5Mzc1IC00LjU3ODEyNSAxLjQ4NDM3NSAtNC4yODEyNSBMIDAuNjA5Mzc1IC0xLjIwMzEyNSBDIDAuMzI4MTI1IC0wLjI2NTYyNSAwLjI2NTYyNSAtMC4xNzE4NzUgLTAuMTQwNjI1IC0wLjEyNSBMIC0wLjE0MDYyNSAwIEwgMS4zMTI1IDAgTCAxLjMxMjUgLTAuMTI1IEMgMC45Mzc1IC0wLjE0MDYyNSAwLjc5Njg3NSAtMC4yMzQzNzUgMC43OTY4NzUgLTAuNDM3NSBDIDAuNzk2ODc1IC0wLjUzMTI1IDAuODEyNSAtMC42NzE4NzUgMC44NTkzNzUgLTAuODI4MTI1IEwgMS43MDMxMjUgLTMuOTUzMTI1IEwgMy40MDYyNSAwLjEwOTM3NSBMIDMuNTMxMjUgMC4xMDkzNzUgTCA0LjU5Mzc1IC0zLjU5Mzc1IEMgNC44NzUgLTQuNTQ2ODc1IDQuODkwNjI1IC00LjU5Mzc1IDUuMzU5Mzc1IC00LjcwMzEyNSBaIE0gNS4zNTkzNzUgLTQuODEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDUtMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9IiIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoNS0xIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0Ljg1OTM3NSAtMS43MDMxMjUgQyA0Ljk4NDM3NSAtMS43MDMxMjUgNS4xMjUgLTEuNzAzMTI1IDUuMTI1IC0xLjg0Mzc1IEMgNS4xMjUgLTEuOTg0Mzc1IDQuOTg0Mzc1IC0xLjk4NDM3NSA0Ljg1OTM3NSAtMS45ODQzNzUgTCAwLjg3NSAtMS45ODQzNzUgQyAwLjc1IC0xLjk4NDM3NSAwLjYwOTM3NSAtMS45ODQzNzUgMC42MDkzNzUgLTEuODQzNzUgQyAwLjYwOTM3NSAtMS43MDMxMjUgMC43NSAtMS43MDMxMjUgMC44NzUgLTEuNzAzMTI1IFogTSA0Ljg1OTM3NSAtMS43MDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg2LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDYtMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS45MDYyNSAtMi41IEMgMS45MDYyNSAtMi43ODEyNSAxLjY3MTg3NSAtMy4wMTU2MjUgMS4zOTA2MjUgLTMuMDE1NjI1IEMgMS4wOTM3NSAtMy4wMTU2MjUgMC44NTkzNzUgLTIuNzgxMjUgMC44NTkzNzUgLTIuNSBDIDAuODU5Mzc1IC0yLjIwMzEyNSAxLjA5Mzc1IC0xLjk2ODc1IDEuMzkwNjI1IC0xLjk2ODc1IEMgMS42NzE4NzUgLTEuOTY4NzUgMS45MDYyNSAtMi4yMDMxMjUgMS45MDYyNSAtMi41IFogTSAxLjkwNjI1IC0yLjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg2LTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDYuNTYyNSAtMi4yOTY4NzUgQyA2LjczNDM3NSAtMi4yOTY4NzUgNi45MjE4NzUgLTIuMjk2ODc1IDYuOTIxODc1IC0yLjUgQyA2LjkyMTg3NSAtMi42ODc1IDYuNzM0Mzc1IC0yLjY4NzUgNi41NjI1IC0yLjY4NzUgTCAxLjE3MTg3NSAtMi42ODc1IEMgMSAtMi42ODc1IDAuODI4MTI1IC0yLjY4NzUgMC44MjgxMjUgLTIuNSBDIDAuODI4MTI1IC0yLjI5Njg3NSAxIC0yLjI5Njg3NSAxLjE3MTg3NSAtMi4yOTY4NzUgWiBNIDYuNTYyNSAtMi4yOTY4NzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg3LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDctMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNy4yNSAtNi41MTU2MjUgTCA1LjI2NTYyNSAtNi41MTU2MjUgTCA1LjI2NTYyNSAtNi4zNDM3NSBDIDUuODI4MTI1IC02LjI5Njg3NSA1Ljk2ODc1IC02LjIwMzEyNSA1Ljk2ODc1IC01Ljg0Mzc1IEMgNS45Njg3NSAtNS43MTg3NSA1LjkzNzUgLTUuNjA5Mzc1IDUuODc1IC01LjQwNjI1IEMgNS44NTkzNzUgLTUuMzc1IDUuODU5Mzc1IC01LjMyODEyNSA1Ljg1OTM3NSAtNS4zMjgxMjUgTCA0LjgyODEyNSAtMS41MzEyNSBMIDIuNzY1NjI1IC02LjUxNTYyNSBMIDEuMTU2MjUgLTYuNTE1NjI1IEwgMS4xNTYyNSAtNi4zNDM3NSBDIDEuNjI1IC02LjMxMjUgMS44MjgxMjUgLTYuMTg3NSAyLjAxNTYyNSAtNS43OTY4NzUgTCAwLjgyODEyNSAtMS42NDA2MjUgQyAwLjQ1MzEyNSAtMC4zNTkzNzUgMC4zNzUgLTAuMjM0Mzc1IC0wLjIwMzEyNSAtMC4xNTYyNSBMIC0wLjIwMzEyNSAwIEwgMS43ODEyNSAwIEwgMS43ODEyNSAtMC4xNTYyNSBDIDEuMjY1NjI1IC0wLjIwMzEyNSAxLjA3ODEyNSAtMC4zMTI1IDEuMDc4MTI1IC0wLjU5Mzc1IEMgMS4wNzgxMjUgLTAuNzE4NzUgMS4xMDkzNzUgLTAuOTIxODc1IDEuMTcxODc1IC0xLjEyNSBMIDIuMjk2ODc1IC01LjMyODEyNSBMIDQuNTkzNzUgMC4xNTYyNSBMIDQuNzgxMjUgMC4xNTYyNSBMIDYuMjAzMTI1IC00Ljg1OTM3NSBDIDYuNTc4MTI1IC02LjE1NjI1IDYuNjI1IC02LjIwMzEyNSA3LjI1IC02LjM0Mzc1IFogTSA3LjI1IC02LjUxNTYyNSAiLz4KPC9zeW1ib2w+CjwvZz4KPGNsaXBQYXRoIGlkPSJjbGlwMSI+CiAgPHBhdGggZD0iTSAzIDU5IEwgNDIgNTkgTCA0MiA4NyBMIDMgODcgWiBNIDMgNTkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgMTAyLjA4OTg0NCA4Ni40OTYwOTQgQyAxMDQuNTU0Njg4IDg2LjQ5NjA5NCAxMDQuNTU0Njg4IDc4LjY5MTQwNiAxMDQuNTU0Njg4IDcyLjgwMDc4MSBDIDEwNC41NTQ2ODggNjYuOTEwMTU2IDEwNC41NTQ2ODggNTkuMTA1NDY5IDEwMi4wODk4NDQgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzIj4KICA8cGF0aCBkPSJNIDQwIDU5IEwgMTA1IDU5IEwgMTA1IDg3IEwgNDAgODcgWiBNIDQwIDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDEwMi4wODk4NDQgODYuNDk2MDk0IEMgMTA0LjU1NDY4OCA4Ni40OTYwOTQgMTA0LjU1NDY4OCA3OC42OTE0MDYgMTA0LjU1NDY4OCA3Mi44MDA3ODEgQyAxMDQuNTU0Njg4IDY2LjkxMDE1NiAxMDQuNTU0Njg4IDU5LjEwNTQ2OSAxMDIuMDg5ODQ0IDU5LjEwNTQ2OSBMIDUuNjk5MjE5IDU5LjEwNTQ2OSBDIDMuMjMwNDY5IDU5LjEwNTQ2OSAzLjIzMDQ2OSA2Ni45MTAxNTYgMy4yMzA0NjkgNzIuODAwNzgxIEMgMy4yMzA0NjkgNzguNjkxNDA2IDMuMjMwNDY5IDg2LjQ5NjA5NCA1LjY5OTIxOSA4Ni40OTYwOTQgWiBNIDUuNjk5MjE5IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNSI+CiAgPHBhdGggZD0iTSAxMDUgNTkgTCAxNjMgNTkgTCAxNjMgODcgTCAxMDUgODcgWiBNIDEwNSA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNiI+CiAgPHBhdGggZD0iTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCBMIDE2MC4wMTk1MzEgODYuNDk2MDk0IEMgMTYyLjQ4NDM3NSA4Ni40OTYwOTQgMTYyLjQ4NDM3NSA3OC42OTE0MDYgMTYyLjQ4NDM3NSA3Mi44MDA3ODEgQyAxNjIuNDg0Mzc1IDY2LjkxMDE1NiAxNjIuNDg0Mzc1IDU5LjEwNTQ2OSAxNjAuMDE5NTMxIDU5LjEwNTQ2OSBMIDEwOC4wMDM5MDYgNTkuMTA1NDY5IEMgMTA1LjUzOTA2MiA1OS4xMDU0NjkgMTA1LjUzOTA2MiA2Ni45MTAxNTYgMTA1LjUzOTA2MiA3Mi44MDA3ODEgQyAxMDUuNTM5MDYyIDc4LjY5MTQwNiAxMDUuNTM5MDYyIDg2LjQ5NjA5NCAxMDguMDAzOTA2IDg2LjQ5NjA5NCBaIE0gMTA4LjAwMzkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDciPgogIDxwYXRoIGQ9Ik0gMTYzIDU5IEwgMjIxIDU5IEwgMjIxIDg3IEwgMTYzIDg3IFogTSAxNjMgNTkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDgiPgogIDxwYXRoIGQ9Ik0gMTY1LjkzNzUgODYuNDk2MDk0IEwgMjE3Ljk1MzEyNSA4Ni40OTYwOTQgQyAyMjAuNDE3OTY5IDg2LjQ5NjA5NCAyMjAuNDE3OTY5IDc4LjY5MTQwNiAyMjAuNDE3OTY5IDcyLjgwMDc4MSBDIDIyMC40MTc5NjkgNjYuOTEwMTU2IDIyMC40MTc5NjkgNTkuMTA1NDY5IDIxNy45NTMxMjUgNTkuMTA1NDY5IEwgMTY1LjkzNzUgNTkuMTA1NDY5IEMgMTYzLjQ3MjY1NiA1OS4xMDU0NjkgMTYzLjQ3MjY1NiA2Ni45MTAxNTYgMTYzLjQ3MjY1NiA3Mi44MDA3ODEgQyAxNjMuNDcyNjU2IDc4LjY5MTQwNiAxNjMuNDcyNjU2IDg2LjQ5NjA5NCAxNjUuOTM3NSA4Ni40OTYwOTQgWiBNIDE2NS45Mzc1IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOSI+CiAgPHBhdGggZD0iTSAyNDEgNTkgTCAyOTkgNTkgTCAyOTkgODcgTCAyNDEgODcgWiBNIDI0MSA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTAiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMSI+CiAgPHBhdGggZD0iTSAyOTkgNTkgTCAzNTcgNTkgTCAzNTcgODcgTCAyOTkgODcgWiBNIDI5OSA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTIiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMyI+CiAgPHBhdGggZD0iTSAyIDg2IEwgMzUxIDg2IEwgMzUxIDEyMC4xMDkzNzUgTCAyIDEyMC4xMDkzNzUgWiBNIDIgODYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0Ij4KICA8cGF0aCBkPSJNIDEwIDUwIEwgNDIuMzk0NTMxIDUwIEwgNDIuMzk0NTMxIDUyIEwgMTAgNTIgWiBNIDY1LjM5MDYyNSA1MCBMIDk4IDUwIEwgOTggNTIgTCA2NS4zOTA2MjUgNTIgWiBNIDY1LjM5MDYyNSA1MCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTUiPgogIDxwYXRoIGQ9Ik0gMi43MzgyODEgNDggTCAxMSA0OCBMIDExIDU0IEwgMi43MzgyODEgNTQgWiBNIDIuNzM4MjgxIDQ4ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNiI+CiAgPHBhdGggZD0iTSAyLjczODI4MSA0NyBMIDQgNDcgTCA0IDU2IEwgMi43MzgyODEgNTYgWiBNIDIuNzM4MjgxIDQ3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNyI+CiAgPHBhdGggZD0iTSAxMCAzOSBMIDQyLjM5NDUzMSAzOSBMIDQyLjM5NDUzMSA0MSBMIDEwIDQxIFogTSA2NS4zOTA2MjUgMzkgTCA5OCAzOSBMIDk4IDQxIEwgNjUuMzkwNjI1IDQxIFogTSA2NS4zOTA2MjUgMzkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE4Ij4KICA8cGF0aCBkPSJNIDIuNzM4MjgxIDM3IEwgMTEgMzcgTCAxMSA0MyBMIDIuNzM4MjgxIDQzIFogTSAyLjczODI4MSAzNyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTkiPgogIDxwYXRoIGQ9Ik0gMi43MzgyODEgMzYgTCA0IDM2IEwgNCA0NSBMIDIuNzM4MjgxIDQ1IFogTSAyLjczODI4MSAzNiAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjAiPgogIDxwYXRoIGQ9Ik0gMTAgMTcgTCAzMy44MjAzMTIgMTcgTCAzMy44MjAzMTIgMTkgTCAxMCAxOSBaIE0gNzMuOTY0ODQ0IDE3IEwgOTggMTcgTCA5OCAxOSBMIDczLjk2NDg0NCAxOSBaIE0gNzMuOTY0ODQ0IDE3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyMSI+CiAgPHBhdGggZD0iTSAyLjczODI4MSAxNSBMIDExIDE1IEwgMTEgMjEgTCAyLjczODI4MSAyMSBaIE0gMi43MzgyODEgMTUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIyIj4KICA8cGF0aCBkPSJNIDIuNzM4MjgxIDE0IEwgNCAxNCBMIDQgMjMgTCAyLjczODI4MSAyMyBaIE0gMi43MzgyODEgMTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIzIj4KICA8cGF0aCBkPSJNIDEwIDcgTCA0MS4zMDA3ODEgNyBMIDQxLjMwMDc4MSA4IEwgMTAgOCBaIE0gNjYuNDgwNDY5IDcgTCA5OCA3IEwgOTggOCBMIDY2LjQ4MDQ2OSA4IFogTSA2Ni40ODA0NjkgNyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjQiPgogIDxwYXRoIGQ9Ik0gMi43MzgyODEgNSBMIDExIDUgTCAxMSAxMCBMIDIuNzM4MjgxIDEwIFogTSAyLjczODI4MSA1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyNSI+CiAgPHBhdGggZD0iTSAyLjczODI4MSAzIEwgNCAzIEwgNCAxMiBMIDIuNzM4MjgxIDEyIFogTSAyLjczODI4MSAzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyNiI+CiAgPHBhdGggZD0iTSAxMTIgNTAgTCAxOTcuMzU5Mzc1IDUwIEwgMTk3LjM1OTM3NSA1MiBMIDExMiA1MiBaIE0gMjY0LjE4MzU5NCA1MCBMIDM0OSA1MCBMIDM0OSA1MiBMIDI2NC4xODM1OTQgNTIgWiBNIDI2NC4xODM1OTQgNTAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDI3Ij4KICA8cGF0aCBkPSJNIDM0OCA0OSBMIDM1Ni40OTYwOTQgNDkgTCAzNTYuNDk2MDk0IDU0IEwgMzQ4IDU0IFogTSAzNDggNDkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDI4Ij4KICA8cGF0aCBkPSJNIDM0OCA0OCBMIDM1Ni40OTYwOTQgNDggTCAzNTYuNDk2MDk0IDU0IEwgMzQ4IDU0IFogTSAzNDggNDggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDI5Ij4KICA8cGF0aCBkPSJNIDEwNS4wNDY4NzUgNDkgTCAxMTQgNDkgTCAxMTQgNTQgTCAxMDUuMDQ2ODc1IDU0IFogTSAxMDUuMDQ2ODc1IDQ5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzMCI+CiAgPHBhdGggZD0iTSAxMDUuMDQ2ODc1IDQ4IEwgMTE0IDQ4IEwgMTE0IDU0IEwgMTA1LjA0Njg3NSA1NCBaIE0gMTA1LjA0Njg3NSA0OCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzEiPgogIDxwYXRoIGQ9Ik0gMTA1LjA0Njg3NSA0NyBMIDEwNiA0NyBMIDEwNiA1NiBMIDEwNS4wNDY4NzUgNTYgWiBNIDEwNS4wNDY4NzUgNDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMyIj4KICA8cGF0aCBkPSJNIDM1NSA0NyBMIDM1Ni40OTYwOTQgNDcgTCAzNTYuNDk2MDk0IDU2IEwgMzU1IDU2IFogTSAzNTUgNDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMzIj4KICA8cGF0aCBkPSJNIDIwIDc1IEwgMjYgNzUgTCAyNiA4MiBMIDIwIDgyIFogTSAyMCA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzQiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgMTAyLjA4OTg0NCA4Ni40OTYwOTQgQyAxMDQuNTU0Njg4IDg2LjQ5NjA5NCAxMDQuNTU0Njg4IDc4LjY5MTQwNiAxMDQuNTU0Njg4IDcyLjgwMDc4MSBDIDEwNC41NTQ2ODggNjYuOTEwMTU2IDEwNC41NTQ2ODggNTkuMTA1NDY5IDEwMi4wODk4NDQgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzNSI+CiAgPHBhdGggZD0iTSAxMSA2NCBMIDE4IDY0IEwgMTggNzEgTCAxMSA3MSBaIE0gMTEgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM2Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDEwMi4wODk4NDQgODYuNDk2MDk0IEMgMTA0LjU1NDY4OCA4Ni40OTYwOTQgMTA0LjU1NDY4OCA3OC42OTE0MDYgMTA0LjU1NDY4OCA3Mi44MDA3ODEgQyAxMDQuNTU0Njg4IDY2LjkxMDE1NiAxMDQuNTU0Njg4IDU5LjEwNTQ2OSAxMDIuMDg5ODQ0IDU5LjEwNTQ2OSBMIDUuNjk5MjE5IDU5LjEwNTQ2OSBDIDMuMjMwNDY5IDU5LjEwNTQ2OSAzLjIzMDQ2OSA2Ni45MTAxNTYgMy4yMzA0NjkgNzIuODAwNzgxIEMgMy4yMzA0NjkgNzguNjkxNDA2IDMuMjMwNDY5IDg2LjQ5NjA5NCA1LjY5OTIxOSA4Ni40OTYwOTQgWiBNIDUuNjk5MjE5IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzciPgogIDxwYXRoIGQ9Ik0gMTcgNjQgTCAyNCA2NCBMIDI0IDcxIEwgMTcgNzEgWiBNIDE3IDY0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzOCI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA4Ni40OTYwOTQgTCAxMDIuMDg5ODQ0IDg2LjQ5NjA5NCBDIDEwNC41NTQ2ODggODYuNDk2MDk0IDEwNC41NTQ2ODggNzguNjkxNDA2IDEwNC41NTQ2ODggNzIuODAwNzgxIEMgMTA0LjU1NDY4OCA2Ni45MTAxNTYgMTA0LjU1NDY4OCA1OS4xMDU0NjkgMTAyLjA4OTg0NCA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM5Ij4KICA8cGF0aCBkPSJNIDIzIDY0IEwgMzEgNjQgTCAzMSA3MSBMIDIzIDcxIFogTSAyMyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDAiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgMTAyLjA4OTg0NCA4Ni40OTYwOTQgQyAxMDQuNTU0Njg4IDg2LjQ5NjA5NCAxMDQuNTU0Njg4IDc4LjY5MTQwNiAxMDQuNTU0Njg4IDcyLjgwMDc4MSBDIDEwNC41NTQ2ODggNjYuOTEwMTU2IDEwNC41NTQ2ODggNTkuMTA1NDY5IDEwMi4wODk4NDQgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0MSI+CiAgPHBhdGggZD0iTSAzMSA2NyBMIDM0IDY3IEwgMzQgNzMgTCAzMSA3MyBaIE0gMzEgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQyIj4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDEwMi4wODk4NDQgODYuNDk2MDk0IEMgMTA0LjU1NDY4OCA4Ni40OTYwOTQgMTA0LjU1NDY4OCA3OC42OTE0MDYgMTA0LjU1NDY4OCA3Mi44MDA3ODEgQyAxMDQuNTU0Njg4IDY2LjkxMDE1NiAxMDQuNTU0Njg4IDU5LjEwNTQ2OSAxMDIuMDg5ODQ0IDU5LjEwNTQ2OSBMIDUuNjk5MjE5IDU5LjEwNTQ2OSBDIDMuMjMwNDY5IDU5LjEwNTQ2OSAzLjIzMDQ2OSA2Ni45MTAxNTYgMy4yMzA0NjkgNzIuODAwNzgxIEMgMy4yMzA0NjkgNzguNjkxNDA2IDMuMjMwNDY5IDg2LjQ5NjA5NCA1LjY5OTIxOSA4Ni40OTYwOTQgWiBNIDUuNjk5MjE5IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDMiPgogIDxwYXRoIGQ9Ik0gNTkgNjggTCA2NSA2OCBMIDY1IDc2IEwgNTkgNzYgWiBNIDU5IDY4ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NCI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA4Ni40OTYwOTQgTCAxMDIuMDg5ODQ0IDg2LjQ5NjA5NCBDIDEwNC41NTQ2ODggODYuNDk2MDk0IDEwNC41NTQ2ODggNzguNjkxNDA2IDEwNC41NTQ2ODggNzIuODAwNzgxIEMgMTA0LjU1NDY4OCA2Ni45MTAxNTYgMTA0LjU1NDY4OCA1OS4xMDU0NjkgMTAyLjA4OTg0NCA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ1Ij4KICA8cGF0aCBkPSJNIDY0IDcwIEwgNjkgNzAgTCA2OSA3NiBMIDY0IDc2IFogTSA2NCA3MCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDYiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgMTAyLjA4OTg0NCA4Ni40OTYwOTQgQyAxMDQuNTU0Njg4IDg2LjQ5NjA5NCAxMDQuNTU0Njg4IDc4LjY5MTQwNiAxMDQuNTU0Njg4IDcyLjgwMDc4MSBDIDEwNC41NTQ2ODggNjYuOTEwMTU2IDEwNC41NTQ2ODggNTkuMTA1NDY5IDEwMi4wODk4NDQgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NyI+CiAgPHBhdGggZD0iTSA2OCA3MCBMIDczIDcwIEwgNzMgNzYgTCA2OCA3NiBaIE0gNjggNzAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ4Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDEwMi4wODk4NDQgODYuNDk2MDk0IEMgMTA0LjU1NDY4OCA4Ni40OTYwOTQgMTA0LjU1NDY4OCA3OC42OTE0MDYgMTA0LjU1NDY4OCA3Mi44MDA3ODEgQyAxMDQuNTU0Njg4IDY2LjkxMDE1NiAxMDQuNTU0Njg4IDU5LjEwNTQ2OSAxMDIuMDg5ODQ0IDU5LjEwNTQ2OSBMIDUuNjk5MjE5IDU5LjEwNTQ2OSBDIDMuMjMwNDY5IDU5LjEwNTQ2OSAzLjIzMDQ2OSA2Ni45MTAxNTYgMy4yMzA0NjkgNzIuODAwNzgxIEMgMy4yMzA0NjkgNzguNjkxNDA2IDMuMjMwNDY5IDg2LjQ5NjA5NCA1LjY5OTIxOSA4Ni40OTYwOTQgWiBNIDUuNjk5MjE5IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDkiPgogIDxwYXRoIGQ9Ik0gNzIgNzAgTCA3NyA3MCBMIDc3IDc2IEwgNzIgNzYgWiBNIDcyIDcwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1MCI+CiAgPHBhdGggZD0iTSA1LjY5OTIxOSA4Ni40OTYwOTQgTCAxMDIuMDg5ODQ0IDg2LjQ5NjA5NCBDIDEwNC41NTQ2ODggODYuNDk2MDk0IDEwNC41NTQ2ODggNzguNjkxNDA2IDEwNC41NTQ2ODggNzIuODAwNzgxIEMgMTA0LjU1NDY4OCA2Ni45MTAxNTYgMTA0LjU1NDY4OCA1OS4xMDU0NjkgMTAyLjA4OTg0NCA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDUxIj4KICA8cGF0aCBkPSJNIDc3IDcwIEwgODIgNzAgTCA4MiA3NiBMIDc3IDc2IFogTSA3NyA3MCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTIiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgMTAyLjA4OTg0NCA4Ni40OTYwOTQgQyAxMDQuNTU0Njg4IDg2LjQ5NjA5NCAxMDQuNTU0Njg4IDc4LjY5MTQwNiAxMDQuNTU0Njg4IDcyLjgwMDc4MSBDIDEwNC41NTQ2ODggNjYuOTEwMTU2IDEwNC41NTQ2ODggNTkuMTA1NDY5IDEwMi4wODk4NDQgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1MyI+CiAgPHBhdGggZD0iTSA4MSA2OCBMIDg1IDY4IEwgODUgNzYgTCA4MSA3NiBaIE0gODEgNjggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU0Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDEwMi4wODk4NDQgODYuNDk2MDk0IEMgMTA0LjU1NDY4OCA4Ni40OTYwOTQgMTA0LjU1NDY4OCA3OC42OTE0MDYgMTA0LjU1NDY4OCA3Mi44MDA3ODEgQyAxMDQuNTU0Njg4IDY2LjkxMDE1NiAxMDQuNTU0Njg4IDU5LjEwNTQ2OSAxMDIuMDg5ODQ0IDU5LjEwNTQ2OSBMIDUuNjk5MjE5IDU5LjEwNTQ2OSBDIDMuMjMwNDY5IDU5LjEwNTQ2OSAzLjIzMDQ2OSA2Ni45MTAxNTYgMy4yMzA0NjkgNzIuODAwNzgxIEMgMy4yMzA0NjkgNzguNjkxNDA2IDMuMjMwNDY5IDg2LjQ5NjA5NCA1LjY5OTIxOSA4Ni40OTYwOTQgWiBNIDUuNjk5MjE5IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTUiPgogIDxwYXRoIGQ9Ik0gMTMyIDc1IEwgMTM5IDc1IEwgMTM5IDgyIEwgMTMyIDgyIFogTSAxMzIgNzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU2Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTYwLjAxOTUzMSA4Ni40OTYwOTQgQyAxNjIuNDg0Mzc1IDg2LjQ5NjA5NCAxNjIuNDg0Mzc1IDc4LjY5MTQwNiAxNjIuNDg0Mzc1IDcyLjgwMDc4MSBDIDE2Mi40ODQzNzUgNjYuOTEwMTU2IDE2Mi40ODQzNzUgNTkuMTA1NDY5IDE2MC4wMTk1MzEgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTciPgogIDxwYXRoIGQ9Ik0gMTIyIDYzIEwgMTI5IDYzIEwgMTI5IDcxIEwgMTIyIDcxIFogTSAxMjIgNjMgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU4Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTYwLjAxOTUzMSA4Ni40OTYwOTQgQyAxNjIuNDg0Mzc1IDg2LjQ5NjA5NCAxNjIuNDg0Mzc1IDc4LjY5MTQwNiAxNjIuNDg0Mzc1IDcyLjgwMDc4MSBDIDE2Mi40ODQzNzUgNjYuOTEwMTU2IDE2Mi40ODQzNzUgNTkuMTA1NDY5IDE2MC4wMTk1MzEgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTkiPgogIDxwYXRoIGQ9Ik0gMTI5IDY0IEwgMTM3IDY0IEwgMTM3IDcxIEwgMTI5IDcxIFogTSAxMjkgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDYwIj4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTYwLjAxOTUzMSA4Ni40OTYwOTQgQyAxNjIuNDg0Mzc1IDg2LjQ5NjA5NCAxNjIuNDg0Mzc1IDc4LjY5MTQwNiAxNjIuNDg0Mzc1IDcyLjgwMDc4MSBDIDE2Mi40ODQzNzUgNjYuOTEwMTU2IDE2Mi40ODQzNzUgNTkuMTA1NDY5IDE2MC4wMTk1MzEgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjEiPgogIDxwYXRoIGQ9Ik0gMTM2IDY0IEwgMTQ0IDY0IEwgMTQ0IDcxIEwgMTM2IDcxIFogTSAxMzYgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDYyIj4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTYwLjAxOTUzMSA4Ni40OTYwOTQgQyAxNjIuNDg0Mzc1IDg2LjQ5NjA5NCAxNjIuNDg0Mzc1IDc4LjY5MTQwNiAxNjIuNDg0Mzc1IDcyLjgwMDc4MSBDIDE2Mi40ODQzNzUgNjYuOTEwMTU2IDE2Mi40ODQzNzUgNTkuMTA1NDY5IDE2MC4wMTk1MzEgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjMiPgogIDxwYXRoIGQ9Ik0gMTQ0IDY3IEwgMTQ3IDY3IEwgMTQ3IDczIEwgMTQ0IDczIFogTSAxNDQgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY0Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTYwLjAxOTUzMSA4Ni40OTYwOTQgQyAxNjIuNDg0Mzc1IDg2LjQ5NjA5NCAxNjIuNDg0Mzc1IDc4LjY5MTQwNiAxNjIuNDg0Mzc1IDcyLjgwMDc4MSBDIDE2Mi40ODQzNzUgNjYuOTEwMTU2IDE2Mi40ODQzNzUgNTkuMTA1NDY5IDE2MC4wMTk1MzEgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjUiPgogIDxwYXRoIGQ9Ik0gMTkwIDc1IEwgMTk2IDc1IEwgMTk2IDgyIEwgMTkwIDgyIFogTSAxOTAgNzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY2Ij4KICA8cGF0aCBkPSJNIDE2NS45Mzc1IDg2LjQ5NjA5NCBMIDIxNy45NTMxMjUgODYuNDk2MDk0IEMgMjIwLjQxNzk2OSA4Ni40OTYwOTQgMjIwLjQxNzk2OSA3OC42OTE0MDYgMjIwLjQxNzk2OSA3Mi44MDA3ODEgQyAyMjAuNDE3OTY5IDY2LjkxMDE1NiAyMjAuNDE3OTY5IDU5LjEwNTQ2OSAyMTcuOTUzMTI1IDU5LjEwNTQ2OSBMIDE2NS45Mzc1IDU5LjEwNTQ2OSBDIDE2My40NzI2NTYgNTkuMTA1NDY5IDE2My40NzI2NTYgNjYuOTEwMTU2IDE2My40NzI2NTYgNzIuODAwNzgxIEMgMTYzLjQ3MjY1NiA3OC42OTE0MDYgMTYzLjQ3MjY1NiA4Ni40OTYwOTQgMTY1LjkzNzUgODYuNDk2MDk0IFogTSAxNjUuOTM3NSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY3Ij4KICA8cGF0aCBkPSJNIDE4MCA2MyBMIDE4NyA2MyBMIDE4NyA3MSBMIDE4MCA3MSBaIE0gMTgwIDYzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2OCI+CiAgPHBhdGggZD0iTSAxNjUuOTM3NSA4Ni40OTYwOTQgTCAyMTcuOTUzMTI1IDg2LjQ5NjA5NCBDIDIyMC40MTc5NjkgODYuNDk2MDk0IDIyMC40MTc5NjkgNzguNjkxNDA2IDIyMC40MTc5NjkgNzIuODAwNzgxIEMgMjIwLjQxNzk2OSA2Ni45MTAxNTYgMjIwLjQxNzk2OSA1OS4xMDU0NjkgMjE3Ljk1MzEyNSA1OS4xMDU0NjkgTCAxNjUuOTM3NSA1OS4xMDU0NjkgQyAxNjMuNDcyNjU2IDU5LjEwNTQ2OSAxNjMuNDcyNjU2IDY2LjkxMDE1NiAxNjMuNDcyNjU2IDcyLjgwMDc4MSBDIDE2My40NzI2NTYgNzguNjkxNDA2IDE2My40NzI2NTYgODYuNDk2MDk0IDE2NS45Mzc1IDg2LjQ5NjA5NCBaIE0gMTY1LjkzNzUgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2OSI+CiAgPHBhdGggZD0iTSAxODcgNjQgTCAxOTUgNjQgTCAxOTUgNzEgTCAxODcgNzEgWiBNIDE4NyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzAiPgogIDxwYXRoIGQ9Ik0gMTY1LjkzNzUgODYuNDk2MDk0IEwgMjE3Ljk1MzEyNSA4Ni40OTYwOTQgQyAyMjAuNDE3OTY5IDg2LjQ5NjA5NCAyMjAuNDE3OTY5IDc4LjY5MTQwNiAyMjAuNDE3OTY5IDcyLjgwMDc4MSBDIDIyMC40MTc5NjkgNjYuOTEwMTU2IDIyMC40MTc5NjkgNTkuMTA1NDY5IDIxNy45NTMxMjUgNTkuMTA1NDY5IEwgMTY1LjkzNzUgNTkuMTA1NDY5IEMgMTYzLjQ3MjY1NiA1OS4xMDU0NjkgMTYzLjQ3MjY1NiA2Ni45MTAxNTYgMTYzLjQ3MjY1NiA3Mi44MDA3ODEgQyAxNjMuNDcyNjU2IDc4LjY5MTQwNiAxNjMuNDcyNjU2IDg2LjQ5NjA5NCAxNjUuOTM3NSA4Ni40OTYwOTQgWiBNIDE2NS45Mzc1IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzEiPgogIDxwYXRoIGQ9Ik0gMTk0IDY0IEwgMjAyIDY0IEwgMjAyIDcxIEwgMTk0IDcxIFogTSAxOTQgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDcyIj4KICA8cGF0aCBkPSJNIDE2NS45Mzc1IDg2LjQ5NjA5NCBMIDIxNy45NTMxMjUgODYuNDk2MDk0IEMgMjIwLjQxNzk2OSA4Ni40OTYwOTQgMjIwLjQxNzk2OSA3OC42OTE0MDYgMjIwLjQxNzk2OSA3Mi44MDA3ODEgQyAyMjAuNDE3OTY5IDY2LjkxMDE1NiAyMjAuNDE3OTY5IDU5LjEwNTQ2OSAyMTcuOTUzMTI1IDU5LjEwNTQ2OSBMIDE2NS45Mzc1IDU5LjEwNTQ2OSBDIDE2My40NzI2NTYgNTkuMTA1NDY5IDE2My40NzI2NTYgNjYuOTEwMTU2IDE2My40NzI2NTYgNzIuODAwNzgxIEMgMTYzLjQ3MjY1NiA3OC42OTE0MDYgMTYzLjQ3MjY1NiA4Ni40OTYwOTQgMTY1LjkzNzUgODYuNDk2MDk0IFogTSAxNjUuOTM3NSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDczIj4KICA8cGF0aCBkPSJNIDIwMSA2NyBMIDIwNiA2NyBMIDIwNiA3MyBMIDIwMSA3MyBaIE0gMjAxIDY3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3NCI+CiAgPHBhdGggZD0iTSAxNjUuOTM3NSA4Ni40OTYwOTQgTCAyMTcuOTUzMTI1IDg2LjQ5NjA5NCBDIDIyMC40MTc5NjkgODYuNDk2MDk0IDIyMC40MTc5NjkgNzguNjkxNDA2IDIyMC40MTc5NjkgNzIuODAwNzgxIEMgMjIwLjQxNzk2OSA2Ni45MTAxNTYgMjIwLjQxNzk2OSA1OS4xMDU0NjkgMjE3Ljk1MzEyNSA1OS4xMDU0NjkgTCAxNjUuOTM3NSA1OS4xMDU0NjkgQyAxNjMuNDcyNjU2IDU5LjEwNTQ2OSAxNjMuNDcyNjU2IDY2LjkxMDE1NiAxNjMuNDcyNjU2IDcyLjgwMDc4MSBDIDE2My40NzI2NTYgNzguNjkxNDA2IDE2My40NzI2NTYgODYuNDk2MDk0IDE2NS45Mzc1IDg2LjQ5NjA5NCBaIE0gMTY1LjkzNzUgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3NSI+CiAgPHBhdGggZD0iTSAyNjcgNzUgTCAyNzQgNzUgTCAyNzQgODIgTCAyNjcgODIgWiBNIDI2NyA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzYiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3NyI+CiAgPHBhdGggZD0iTSAyNTMgNjMgTCAyNjAgNjMgTCAyNjAgNzEgTCAyNTMgNzEgWiBNIDI1MyA2MyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzgiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3OSI+CiAgPHBhdGggZD0iTSAyNTkgNjQgTCAyNjcgNjQgTCAyNjcgNzEgTCAyNTkgNzEgWiBNIDI1OSA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODAiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4MSI+CiAgPHBhdGggZD0iTSAyNjYgNjQgTCAyNzQgNjQgTCAyNzQgNzEgTCAyNjYgNzEgWiBNIDI2NiA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODIiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4MyI+CiAgPHBhdGggZD0iTSAyNzMgNjcgTCAyODAgNjcgTCAyODAgNzMgTCAyNzMgNzMgWiBNIDI3MyA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODQiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4NSI+CiAgPHBhdGggZD0iTSAyNzkgNzAgTCAyODUgNzAgTCAyODUgNzEgTCAyNzkgNzEgWiBNIDI3OSA3MCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODYiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4NyI+CiAgPHBhdGggZD0iTSAyODUgNjcgTCAyODggNjcgTCAyODggNzMgTCAyODUgNzMgWiBNIDI4NSA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODgiPgogIDxwYXRoIGQ9Ik0gMjQzLjU4OTg0NCA4Ni40OTYwOTQgTCAyOTUuNjA1NDY5IDg2LjQ5NjA5NCBDIDI5OC4wNzAzMTIgODYuNDk2MDk0IDI5OC4wNzAzMTIgNzguNjkxNDA2IDI5OC4wNzAzMTIgNzIuODAwNzgxIEMgMjk4LjA3MDMxMiA2Ni45MTAxNTYgMjk4LjA3MDMxMiA1OS4xMDU0NjkgMjk1LjYwNTQ2OSA1OS4xMDU0NjkgTCAyNDMuNTg5ODQ0IDU5LjEwNTQ2OSBDIDI0MS4xMjUgNTkuMTA1NDY5IDI0MS4xMjUgNjYuOTEwMTU2IDI0MS4xMjUgNzIuODAwNzgxIEMgMjQxLjEyNSA3OC42OTE0MDYgMjQxLjEyNSA4Ni40OTYwOTQgMjQzLjU4OTg0NCA4Ni40OTYwOTQgWiBNIDI0My41ODk4NDQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA4OSI+CiAgPHBhdGggZD0iTSAzMjYgNzUgTCAzMzIgNzUgTCAzMzIgODIgTCAzMjYgODIgWiBNIDMyNiA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTAiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5MSI+CiAgPHBhdGggZD0iTSAzMTUgNjMgTCAzMjIgNjMgTCAzMjIgNzEgTCAzMTUgNzEgWiBNIDMxNSA2MyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTIiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5MyI+CiAgPHBhdGggZD0iTSAzMjIgNjQgTCAzMjkgNjQgTCAzMjkgNzEgTCAzMjIgNzEgWiBNIDMyMiA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTQiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5NSI+CiAgPHBhdGggZD0iTSAzMjkgNjQgTCAzMzcgNjQgTCAzMzcgNzEgTCAzMjkgNzEgWiBNIDMyOSA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTYiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5NyI+CiAgPHBhdGggZD0iTSAzMzYgNjcgTCAzNDIgNjcgTCAzNDIgNzMgTCAzMzYgNzMgWiBNIDMzNiA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTgiPgogIDxwYXRoIGQ9Ik0gMzAxLjUyMzQzOCA4Ni40OTYwOTQgTCAzNTMuNTM5MDYyIDg2LjQ5NjA5NCBDIDM1Ni4wMDM5MDYgODYuNDk2MDk0IDM1Ni4wMDM5MDYgNzguNjkxNDA2IDM1Ni4wMDM5MDYgNzIuODAwNzgxIEMgMzU2LjAwMzkwNiA2Ni45MTAxNTYgMzU2LjAwMzkwNiA1OS4xMDU0NjkgMzUzLjUzOTA2MiA1OS4xMDU0NjkgTCAzMDEuNTIzNDM4IDU5LjEwNTQ2OSBDIDI5OS4wNTg1OTQgNTkuMTA1NDY5IDI5OS4wNTg1OTQgNjYuOTEwMTU2IDI5OS4wNTg1OTQgNzIuODAwNzgxIEMgMjk5LjA1ODU5NCA3OC42OTE0MDYgMjk5LjA1ODU5NCA4Ni40OTYwOTQgMzAxLjUyMzQzOCA4Ni40OTYwOTQgWiBNIDMwMS41MjM0MzggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8L2RlZnM+CjxnIGlkPSJzdXJmYWNlMSI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoNTAlLDUwJSwxMDAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMS43NzM0MzggODcuNDY0ODQ0IEwgNDEuOTE3OTY5IDg3LjQ2NDg0NCBMIDQxLjkxNzk2OSA1OC4xNDA2MjUgTCAxLjc3MzQzOCA1OC4xNDA2MjUgTCAxLjc3MzQzOCA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDc1JSw3NSUsMTAwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDQwLjk0OTIxOSA4Ny40NjQ4NDQgTCAxMDYuMDExNzE5IDg3LjQ2NDg0NCBMIDEwNi4wMTE3MTkgNTguMTQwNjI1IEwgNDAuOTQ5MjE5IDU4LjE0MDYyNSBMIDQwLjk0OTIxOSA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDEwMCUsNTAlLDUwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDEwNC4wNzgxMjUgODcuNDY0ODQ0IEwgMTYzLjk0NTMxMiA4Ny40NjQ4NDQgTCAxNjMuOTQ1MzEyIDU4LjE0MDYyNSBMIDEwNC4wNzgxMjUgNTguMTQwNjI1IEwgMTA0LjA3ODEyNSA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDEwMCUsNTAlLDUwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDE2Mi4wMTE3MTkgODcuNDY0ODQ0IEwgMjIxLjg3ODkwNiA4Ny40NjQ4NDQgTCAyMjEuODc4OTA2IDU4LjE0MDYyNSBMIDE2Mi4wMTE3MTkgNTguMTQwNjI1IEwgMTYyLjAxMTcxOSA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigxMDAlLDUwJSw1MCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyMzkuNjY0MDYyIDg3LjQ2NDg0NCBMIDI5OS41MzEyNSA4Ny40NjQ4NDQgTCAyOTkuNTMxMjUgNTguMTQwNjI1IEwgMjM5LjY2NDA2MiA1OC4xNDA2MjUgTCAyMzkuNjY0MDYyIDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigxMDAlLDUwJSw1MCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyOTcuNTk3NjU2IDg3LjQ2NDg0NCBMIDM1Ny40NjQ4NDQgODcuNDY0ODQ0IEwgMzU3LjQ2NDg0NCA1OC4xNDA2MjUgTCAyOTcuNTk3NjU2IDU4LjE0MDYyNSBMIDI5Ny41OTc2NTYgODcuNDY0ODQ0ICIvPgo8L2c+CjwvZz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjcuMzgyODEyIDI1Ni4xNzgxMjUgTCAyNy4zODI4MTIgMjU1Ljg2NTYyNSBDIDI3LjM4MjgxMiAyMzYuOTU5Mzc1IDQyLjczNDM3NSAyMjEuNjQ2ODc1IDYxLjY0MDYyNSAyMjEuNjQ2ODc1IEwgMTUzMy45MDYyNSAyMjEuNjQ2ODc1IEMgMTU1Mi44MTI1IDIyMS42NDY4NzUgMTU2OC4xNjQwNjIgMjM2Ljk1OTM3NSAxNTY4LjE2NDA2MiAyNTUuODY1NjI1IEwgMTU2OC4xNjQwNjIgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDIuNzM4MjgxIDg2Ljk5MjE4OCBMIDAuODA0Njg4IDk0LjI2OTUzMSBDIDAuNzg1MTU2IDk0LjM0Mzc1IDAuNzY5NTMxIDk0LjQxNzk2OSAwLjc1MzkwNiA5NC40OTIxODggTCA0LjczODI4MSA5NC40OTIxODggQyA0LjcxNDg0NCA5NC40MTc5NjkgNC42OTUzMTIgOTQuMzQzNzUgNC42NzE4NzUgOTQuMjY5NTMxIEwgMi43MzgyODEgODYuOTkyMTg4ICIvPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNy4zODI4MTIgMzMxLjE3ODEyNSBMIDguMDQ2ODc1IDI1OC40MDQ2ODcgQyA3Ljg1MTU2MiAyNTcuNjYyNSA3LjY5NTMxMiAyNTYuOTIwMzEyIDcuNTM5MDYyIDI1Ni4xNzgxMjUgTCA0Ny4zODI4MTIgMjU2LjE3ODEyNSBDIDQ3LjE0ODQzOCAyNTYuOTIwMzEyIDQ2Ljk1MzEyNSAyNTcuNjYyNSA0Ni43MTg3NSAyNTguNDA0Njg3IFogTSAyNy4zODI4MTIgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjE0Ny40NjA5MzggMzMxLjE3ODEyNSBMIDIxNDcuNDYwOTM4IDIwMS4xIEMgMjE0Ny40NjA5MzggMTgyLjE5Mzc1IDIxMzIuMTQ4NDM4IDE2Ni44NDIxODcgMjExMy4yNDIxODggMTY2Ljg0MjE4NyBMIDYxLjY0MDYyNSAxNjYuODQyMTg3IEMgNDIuNzM0Mzc1IDE2Ni44NDIxODcgMjcuMzgyODEyIDE4Mi4xOTM3NSAyNy4zODI4MTIgMjAxLjEgTCAyNy4zODI4MTIgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjkyNC4wMjM0MzggMzMxLjE3ODEyNSBMIDI5MjQuMDIzNDM4IDkxLjUyOTY4NyBDIDI5MjQuMDIzNDM4IDcyLjYyMzQzNyAyOTA4LjY3MTg3NSA1Ny4yNzE4NzUgMjg4OS43NjU2MjUgNTcuMjcxODc1IEwgNjEuNjQwNjI1IDU3LjI3MTg3NSBDIDQyLjczNDM3NSA1Ny4yNzE4NzUgMjcuMzgyODEyIDcyLjYyMzQzNyAyNy4zODI4MTIgOTEuNTI5Njg3IEwgMjcuMzgyODEyIDMzMS4xNzgxMjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzNTAzLjM1OTM3NSAzMzEuMTc4MTI1IEwgMzUwMy4zNTkzNzUgMzYuNzI1IEMgMzUwMy4zNTkzNzUgMTcuODE4NzUgMzQ4OC4wMDc4MTIgMi41MDYyNSAzNDY5LjEwMTU2MiAyLjUwNjI1IEwgNjEuNjQwNjI1IDIuNTA2MjUgQyA0Mi43MzQzNzUgMi41MDYyNSAyNy4zODI4MTIgMTcuODE4NzUgMjcuMzgyODEyIDM2LjcyNSBMIDI3LjM4MjgxMiAzMzEuMTc4MTI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSA5NzAuNTA3ODEyIDY5MC4wODQzNzUgTCAxMDcuMzA0Njg4IDY5MC4wODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMTA0NS41NDY4NzUgNjkwLjA4NDM3NSBMIDk3MC41MDc4MTIgNzEwLjIwMTU2MiBMIDk3MC41MDc4MTIgNjcwLjAwNjI1IFogTSAxMDQ1LjU0Njg3NSA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMy4yMzA0NjkgNTEuMTAxNTYyIEwgMTAuNzMwNDY5IDUzLjEwOTM3NSBMIDEwLjczMDQ2OSA0OS4wODk4NDQgWiBNIDMuMjMwNDY5IDUxLjEwMTU2MiAiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMyLjMwNDY4OCA2OTAuMDg0Mzc1IEwgMTA3LjMwNDY4OCA2NzAuMDA2MjUgTCAxMDcuMzA0Njg4IDcxMC4yMDE1NjIgWiBNIDMyLjMwNDY4OCA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMi4zMDQ2ODggNjUyLjU4NDM3NSBMIDMyLjMwNDY4OCA3MjcuNTg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNDUuNTQ2ODc1IDY1Mi41ODQzNzUgTCAxMDQ1LjU0Njg3NSA3MjcuNTg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gOTcwLjUwNzgxMiA3OTkuNjU0Njg3IEwgMTA3LjMwNDY4OCA3OTkuNjU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNDUuNTQ2ODc1IDc5OS42NTQ2ODcgTCA5NzAuNTA3ODEyIDgxOS43MzI4MTIgTCA5NzAuNTA3ODEyIDc3OS41NzY1NjIgWiBNIDEwNDUuNTQ2ODc1IDc5OS42NTQ2ODcgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAzLjIzMDQ2OSA0MC4xNDQ1MzEgTCAxMC43MzA0NjkgNDIuMTUyMzQ0IEwgMTAuNzMwNDY5IDM4LjEzNjcxOSBaIE0gMy4yMzA0NjkgNDAuMTQ0NTMxICIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzIuMzA0Njg4IDc5OS42NTQ2ODcgTCAxMDcuMzA0Njg4IDc3OS41NzY1NjIgTCAxMDcuMzA0Njg4IDgxOS43MzI4MTIgWiBNIDMyLjMwNDY4OCA3OTkuNjU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMi4zMDQ2ODggNzYyLjE1NDY4NyBMIDMyLjMwNDY4OCA4MzcuMTU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNDUuNTQ2ODc1IDc2Mi4xNTQ2ODcgTCAxMDQ1LjU0Njg3NSA4MzcuMTU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDIwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gOTcwLjUwNzgxMiAxMDE4Ljc5NTMxMiBMIDEwNy4zMDQ2ODggMTAxOC43OTUzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMTA0NS41NDY4NzUgMTAxOC43OTUzMTIgTCA5NzAuNTA3ODEyIDEwMzguODczNDM3IEwgOTcwLjUwNzgxMiA5OTguNjc4MTI1IFogTSAxMDQ1LjU0Njg3NSAxMDE4Ljc5NTMxMiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDMuMjMwNDY5IDE4LjIzMDQ2OSBMIDEwLjczMDQ2OSAyMC4yNDIxODggTCAxMC43MzA0NjkgMTYuMjIyNjU2IFogTSAzLjIzMDQ2OSAxOC4yMzA0NjkgIi8+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMi4zMDQ2ODggMTAxOC43OTUzMTIgTCAxMDcuMzA0Njg4IDk5OC42NzgxMjUgTCAxMDcuMzA0Njg4IDEwMzguODczNDM3IFogTSAzMi4zMDQ2ODggMTAxOC43OTUzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMyLjMwNDY4OCA5ODEuMjk1MzEyIEwgMzIuMzA0Njg4IDEwNTYuMjk1MzEyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNDUuNTQ2ODc1IDk4MS4yOTUzMTIgTCAxMDQ1LjU0Njg3NSAxMDU2LjI5NTMxMiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDk3MC41MDc4MTIgMTEyOC4zNjU2MjUgTCAxMDcuMzA0Njg4IDExMjguMzY1NjI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNDUuNTQ2ODc1IDExMjguMzY1NjI1IEwgOTcwLjUwNzgxMiAxMTQ4LjQ0Mzc1IEwgOTcwLjUwNzgxMiAxMTA4LjI0ODQzNyBaIE0gMTA0NS41NDY4NzUgMTEyOC4zNjU2MjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAzLjIzMDQ2OSA3LjI3MzQzOCBMIDEwLjczMDQ2OSA5LjI4NTE1NiBMIDEwLjczMDQ2OSA1LjI2NTYyNSBaIE0gMy4yMzA0NjkgNy4yNzM0MzggIi8+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzMi4zMDQ2ODggMTEyOC4zNjU2MjUgTCAxMDcuMzA0Njg4IDExMDguMjQ4NDM3IEwgMTA3LjMwNDY4OCAxMTQ4LjQ0Mzc1IFogTSAzMi4zMDQ2ODggMTEyOC4zNjU2MjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMyLjMwNDY4OCAxMDkwLjg2NTYyNSBMIDMyLjMwNDY4OCAxMTY1Ljg2NTYyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxMDQ1LjU0Njg3NSAxMDkwLjg2NTYyNSBMIDEwNDUuNTQ2ODc1IDExNjUuODY1NjI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDI2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzQ4NS4wMzkwNjIgNjkwLjA4NDM3NSBMIDExMzAuMzkwNjI1IDY5MC4wODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAzNTYuMDAzOTA2IDUxLjEwMTU2MiBMIDM0OC41MDM5MDYgNDkuMDg5ODQ0IEwgMzQ4LjUwMzkwNiA1My4xMDkzNzUgWiBNIDM1Ni4wMDM5MDYgNTEuMTAxNTYyICIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAzNTYwLjAzOTA2MiA2OTAuMDg0Mzc1IEwgMzQ4NS4wMzkwNjIgNzEwLjIwMTU2MiBMIDM0ODUuMDM5MDYyIDY3MC4wMDYyNSBaIE0gMzU2MC4wMzkwNjIgNjkwLjA4NDM3NSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDI5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDEwNS41MzkwNjIgNTEuMTAxNTYyIEwgMTEzLjAzOTA2MiA1My4xMDkzNzUgTCAxMTMuMDM5MDYyIDQ5LjA4OTg0NCBaIE0gMTA1LjUzOTA2MiA1MS4xMDE1NjIgIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNTUuMzkwNjI1IDY5MC4wODQzNzUgTCAxMTMwLjM5MDYyNSA2NzAuMDA2MjUgTCAxMTMwLjM5MDYyNSA3MTAuMjAxNTYyIFogTSAxMDU1LjM5MDYyNSA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxMDU1LjM5MDYyNSA2NTIuNTg0Mzc1IEwgMTA1NS4zOTA2MjUgNzI3LjU4NDM3NSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzU2MC4wMzkwNjIgNjUyLjU4NDM3NSBMIDM1NjAuMDM5MDYyIDcyNy41ODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTEiIHg9IjIwLjAzOTgiIHk9IjgxLjgyOTkiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEiIHg9IjExLjYzOTgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTIiIHg9IjE3Ljc1OTc5OSIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDM5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iMjMuMjc5Nzk4IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0xIiB4PSIzMC4zNjAxIiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNCIgeD0iNTkuMzk5OSIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjY0LjMxOTgyNSIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjY4Ljc1OTgyNiIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTciIHg9IjcyLjExOTgyMyIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9Ijc3LjE1OTgyMiIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTgiIHg9IjgxLjU5OTgyNCIgeT0iNzUuMjI5ODUiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTEiIHg9IjEzMi4yNCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iMTIyLjY0IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMCIgeD0iMTI5LjI0IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIxMzYuNDM5OTk3IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0xIiB4PSIxNDMuNjQiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0yIiB4PSIxOTAuMiIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iMTgwLjYiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEwIiB4PSIxODcuMiIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iMTk0LjM5OTk5NyIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDczKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDItMiIgeD0iMjAxLjYiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDMtMSIgeD0iMjI0LjUyIiB5PSI3NS43MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDMtMSIgeD0iMjI5LjIwMDEwMiIgeT0iNzUuNzEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgzLTEiIHg9IjIzMy44ODAyMDQiIHk9Ijc1LjcxIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTMiIHg9IjI2Ny44NCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iMjUyLjcyMDEiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEwIiB4PSIyNTkuMzIwMDg4IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDgyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIyNjYuNTIwMDk3IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNC0xIiB4PSIyNzMuNzIwMSIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg1LTEiIHg9IjI3OS4wMDAxOCIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgyLTEiIHg9IjI4NC43NjAzNCIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTQiIHg9IjMyNi4wNCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDkxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iMzE1LjM2MDMiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEwIiB4PSIzMjEuOTYwMjg4IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIzMjkuMTYwMjk3IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNC0xIiB4PSIzMzYuMzYwMyIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMSIgeD0iNDMuOCIgeT0iNTMuNTEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTgiIHg9IjQ5LjMxOTk5OSIgeT0iNTMuNTEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjUyLjA4IiB5PSI1My41MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTIiIHg9IjU5LjAzOTg0IiB5PSI1My41MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTEiIHg9IjQzLjgiIHk9IjQyLjU5MDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTgiIHg9IjQ5LjMxOTk5OSIgeT0iNDIuNTkwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iNTIuMDgiIHk9IjQyLjU5MDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEzIiB4PSI1OS4wMzk4NCIgeT0iNDIuNTkwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDYtMSIgeD0iNDguNiIgeT0iMzEuNTQ5OSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDYtMSIgeD0iNTIuNDM5NTAyIiB5PSIzMS41NDk5Ii8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNi0xIiB4PSI1Ni4yNzkwMDQiIHk9IjMxLjU0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTExIiB4PSIzNC45MTk5IiB5PSIyMC42MyIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iNDAuNDM5ODk5IiB5PSIyMC42MyIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iNDMuMTk5OSIgeT0iMjAuNjMiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg3LTEiIHg9IjUwLjE1OTciIHk9IjIwLjYzIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNi0yIiB4PSI1OC43OTk1NCIgeT0iMjAuNjMiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEyIiB4PSI2OC4wMzkzOCIgeT0iMjAuNjMiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTExIiB4PSI0Mi43MTk4OCIgeT0iOS43MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSI0OC4yMzk4NzkiIHk9IjkuNzEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iNTAuOTk5ODgiIHk9IjkuNzEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDctMSIgeD0iNTcuODM5NzgiIHk9IjkuNzEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTQiIHg9IjE5Ny45OTk3OCIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iMjAyLjQzOTc4MiIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNyIgeD0iMjA2Ljg3OTc5NSIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTUiIHg9IjIxMS45MTk3ODIiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjIxNC42Nzk4MDEiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE2IiB4PSIyMTguMDM5NzkyIiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS04IiB4PSIyMjIuNDc5ODA2IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNyIgeD0iMjI3LjYzOTY1NiIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTgiIHg9IjIzMi42Nzk2NDMiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjIzNS40Mzk2NjMiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjIzOC43OTk2NzgiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE0IiB4PSIyNDMuMjM5NjY3IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNSIgeD0iMjQ3LjY3OTY1NiIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTkiIHg9IjI1MC40Mzk2NzYiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjI1NS40Nzk2NjMiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTIwIiB4PSIyNTguODM5Njc4IiB5PSI1My41MTAxIi8+CjwvZz4KPC9nPgo8L3N2Zz4K)
Let's look at an example to see how this construction affects the compression ratio. Suppose the kernel is 1000 bytes and decompresses to 1 MB. Then the first MB of output "costs" 1078 bytes of input:
- 31 bytes for a local file header (including a 1-byte filename)
- 47 bytes for a central directory header (including a 1-byte filename)
- 1000 bytes for the kernel itself
But every 1 MB of output after the first costs only 47 bytes—we don't need another local file header or another copy of the kernel, only an additional central directory header. So while the first reference of the kernel has a compression ratio of 1 000 000 / 1078 ≈ 928, each additional reference pulls the ratio closer to 1 000 000 / 47 ≈ 21 277. A bigger kernel raises the ceiling.
The problem with this idea is a lack of compatibility.
Because many central directory headers point to a single local file header,
the metadata—specifically the filename—cannot match for every file.
Some parsers balk at that.
Info-ZIP UnZip
(the standard Unix unzip program)
extracts the files, but with warnings:
$ unzip overlap.zip
inflating: A
B: mismatching "local" filename (A),
continuing with "central" filename version
inflating: B
...
And the Python zipfile module throws an exception:
$ python3 -m zipfile -e overlap.zip . Traceback (most recent call last): ... __main__.BadZipFile: File name in directory 'B' and header b'A' differ.
Next we will see how to modify the construction for consistency of filenames, while still retaining most of the advantage of overlapping files.
The second insight: quoting local file headers
We need to separate the local file headers for each file, while still reusing a single kernel. Simply concatenating all the local file headers does not work, because the zip parser will find a local file header where it expects to find the beginning of a DEFLATE stream. But the idea will work, with a minor modification. We'll use a feature of DEFLATE, non-compressed blocks, to "quote" local file headers so that they appear to be part of the same DEFLATE stream that terminates in the kernel. Every local file header (except the first) will be interpreted in two ways: as code (part of the structure of the zip file) and as data (part of the contents of a file).
![A block diagram of a zip file with quoted local file headers. The central directory header consists of central directory headers CDH[1], CDH[2], ..., CDH[N−1], CDH[N], with filenames A, B, ..., Y, Z. The central directory headers point to corresponding local file headers LFH[1], LFH[2], ..., LFH[N−1], LFH[N] with filenames A, B, ..., Y, Z. The files are drawn and labeled to show that file 1 does not end before file 2 begins; rather file 1 contains file 2, file 2 contains file 3, and so on. There is a small green-colored space between LFH[1] and LFH[2], and between LFH[2] and LFH[3], etc., to stand for quoting the following local file header using an uncompressed DEFLATE block. The file data of the final file, whose local file header is LFH[N] and whose filename is Z, does not contain any other files, only the compressed kernel.](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4KPHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHhtbG5zOnhsaW5rPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rIiB3aWR0aD0iNTA0cHQiIGhlaWdodD0iMTIwLjExcHQiIHZpZXdCb3g9IjAgMCA1MDQgMTIwLjExIiB2ZXJzaW9uPSIxLjEiPgo8ZGVmcz4KPGc+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9IiIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0xIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0LjI1IC0xLjk2ODc1IEwgNC45MjE4NzUgMCBMIDUuODU5Mzc1IDAgTCAzLjU2MjUgLTYuNTMxMjUgTCAyLjQ4NDM3NSAtNi41MzEyNSBMIDAuMTU2MjUgMCBMIDEuMDQ2ODc1IDAgTCAxLjczNDM3NSAtMS45Njg3NSBaIE0gNC4wMTU2MjUgLTIuNjU2MjUgTCAxLjkzNzUgLTIuNjU2MjUgTCAzLjAxNTYyNSAtNS42NDA2MjUgWiBNIDQuMDE1NjI1IC0yLjY1NjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0yIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjcwMzEyNSAwIEwgMy42NTYyNSAwIEMgNC4yODEyNSAwIDQuNzM0Mzc1IC0wLjE3MTg3NSA1LjA3ODEyNSAtMC41NDY4NzUgQyA1LjQwNjI1IC0wLjg5MDYyNSA1LjU5Mzc1IC0xLjM1OTM3NSA1LjU5Mzc1IC0xLjg1OTM3NSBDIDUuNTkzNzUgLTIuNjU2MjUgNS4yMzQzNzUgLTMuMTI1IDQuMzkwNjI1IC0zLjQ1MzEyNSBDIDQuOTg0Mzc1IC0zLjczNDM3NSA1LjI5Njg3NSAtNC4yMTg3NSA1LjI5Njg3NSAtNC44NzUgQyA1LjI5Njg3NSAtNS4zNTkzNzUgNS4xMjUgLTUuNzgxMjUgNC43ODEyNSAtNi4wNzgxMjUgQyA0LjQzNzUgLTYuMzkwNjI1IDMuOTg0Mzc1IC02LjUzMTI1IDMuMzU5Mzc1IC02LjUzMTI1IEwgMC43MDMxMjUgLTYuNTMxMjUgWiBNIDEuNTQ2ODc1IC0zLjcxODc1IEwgMS41NDY4NzUgLTUuNzk2ODc1IEwgMy4xNTYyNSAtNS43OTY4NzUgQyAzLjYyNSAtNS43OTY4NzUgMy44OTA2MjUgLTUuNzM0Mzc1IDQuMTA5Mzc1IC01LjU2MjUgQyA0LjM0Mzc1IC01LjM5MDYyNSA0LjQ2ODc1IC01LjEyNSA0LjQ2ODc1IC00Ljc2NTYyNSBDIDQuNDY4NzUgLTQuNDA2MjUgNC4zNDM3NSAtNC4xNDA2MjUgNC4xMDkzNzUgLTMuOTUzMTI1IEMgMy44OTA2MjUgLTMuNzgxMjUgMy42MjUgLTMuNzE4NzUgMy4xNTYyNSAtMy43MTg3NSBaIE0gMS41NDY4NzUgLTAuNzM0Mzc1IEwgMS41NDY4NzUgLTIuOTg0Mzc1IEwgMy41NzgxMjUgLTIuOTg0Mzc1IEMgMy45ODQzNzUgLTIuOTg0Mzc1IDQuMjUgLTIuODkwNjI1IDQuNDUzMTI1IC0yLjY3MTg3NSBDIDQuNjQwNjI1IC0yLjQ2ODc1IDQuNzUgLTIuMTcxODc1IDQuNzUgLTEuODU5Mzc1IEMgNC43NSAtMS41NDY4NzUgNC42NDA2MjUgLTEuMjUgNC40NTMxMjUgLTEuMDQ2ODc1IEMgNC4yNSAtMC44MjgxMjUgMy45ODQzNzUgLTAuNzM0Mzc1IDMuNTc4MTI1IC0wLjczNDM3NSBaIE0gMS41NDY4NzUgLTAuNzM0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMC0zIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjQ2ODc1IC0yLjU2MjUgTCA1LjkyMTg3NSAtNi41MzEyNSBMIDQuOTM3NSAtNi41MzEyNSBMIDMuMDYyNSAtMy4zNTkzNzUgTCAxLjE0MDYyNSAtNi41MzEyNSBMIDAuMTA5Mzc1IC02LjUzMTI1IEwgMi42NDA2MjUgLTIuNTYyNSBMIDIuNjQwNjI1IDAgTCAzLjQ2ODc1IDAgWiBNIDMuNDY4NzUgLTIuNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDAtNCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNS4yMDMxMjUgLTYuNTMxMjUgTCAwLjUgLTYuNTMxMjUgTCAwLjUgLTUuNzk2ODc1IEwgNC4xNzE4NzUgLTUuNzk2ODc1IEwgMC4yNSAtMC43MzQzNzUgTCAwLjI1IDAgTCA1LjIzNDM3NSAwIEwgNS4yMzQzNzUgLTAuNzM0Mzc1IEwgMS4yOTY4NzUgLTAuNzM0Mzc1IEwgNS4yMDMxMjUgLTUuNzgxMjUgWiBNIDUuMjAzMTI1IC02LjUzMTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDUuNzE4NzUgLTEuNzM0Mzc1IEMgNS41NDY4NzUgLTEuMzU5Mzc1IDUuNDA2MjUgLTEuMTI1IDUuMjUgLTAuOTUzMTI1IEMgNC45MDYyNSAtMC41NjI1IDQuMzU5Mzc1IC0wLjM5MDYyNSAzLjUzMTI1IC0wLjM5MDYyNSBMIDIuODU5Mzc1IC0wLjM5MDYyNSBDIDIuMTQwNjI1IC0wLjM5MDYyNSAyIC0wLjQ1MzEyNSAyIC0wLjc5Njg3NSBMIDIgLTUuNTE1NjI1IEMgMiAtNi4yMTg3NSAyLjE0MDYyNSAtNi4zNTkzNzUgMi45Mzc1IC02LjQwNjI1IEwgMi45Mzc1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4wOTM3NSBDIDAuOTg0Mzc1IC0wLjM5MDYyNSAwLjg0Mzc1IC0wLjIzNDM3NSAwLjEyNSAtMC4xODc1IEwgMC4xMjUgMCBMIDUuNDg0Mzc1IDAgTCA1Ljk2ODc1IC0xLjczNDM3NSBaIE0gNS43MTg3NSAtMS43MzQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzgxMjUgLTIuMjk2ODc1IEwgNC43ODEyNSAtNC42MDkzNzUgTCA0LjU0Njg3NSAtNC42MDkzNzUgQyA0LjQyMTg3NSAtMy44MTI1IDQuMjUgLTMuNjcxODc1IDMuNDUzMTI1IC0zLjY3MTg3NSBMIDIgLTMuNjcxODc1IEwgMiAtNS44NzUgQyAyIC02LjE1NjI1IDIuMDQ2ODc1IC02LjIxODc1IDIuMzI4MTI1IC02LjIxODc1IEwgMy42NzE4NzUgLTYuMjE4NzUgQyA0LjgxMjUgLTYuMjE4NzUgNS4wMzEyNSAtNi4wNzgxMjUgNS4xODc1IC01LjE3MTg3NSBMIDUuNDM3NSAtNS4xNzE4NzUgTCA1LjQwNjI1IC02LjU5Mzc1IEwgMC4xMjUgLTYuNTkzNzUgTCAwLjEyNSAtNi40MDYyNSBDIDAuODU5Mzc1IC02LjM0Mzc1IDAuOTg0Mzc1IC02LjIwMzEyNSAwLjk4NDM3NSAtNS41MTU2MjUgTCAwLjk4NDM3NSAtMS4yMDMxMjUgQyAwLjk4NDM3NSAtMC4zNzUgMC44NzUgLTAuMjM0Mzc1IDAuMTI1IC0wLjE4NzUgTCAwLjEyNSAwIEwgMi45MDYyNSAwIEwgMi45MDYyNSAtMC4xODc1IEMgMi4xNDA2MjUgLTAuMjM0Mzc1IDIgLTAuMzc1IDIgLTEuMDkzNzUgTCAyIC0zLjI2NTYyNSBMIDMuNDUzMTI1IC0zLjI2NTYyNSBDIDQuMjUgLTMuMjY1NjI1IDQuNDIxODc1IC0zLjEwOTM3NSA0LjU0Njg3NSAtMi4yOTY4NzUgWiBNIDQuNzgxMjUgLTIuMjk2ODc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0zIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAyLjA3ODEyNSAtMy41NzgxMjUgTCAyLjA3ODEyNSAtNS41MTU2MjUgQyAyLjA3ODEyNSAtNi4yMzQzNzUgMi4xODc1IC02LjM0Mzc1IDIuOTUzMTI1IC02LjQwNjI1IEwgMi45NTMxMjUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNTkzNzUgTCAwLjE4NzUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjA2MjUgLTYuMjM0Mzc1IDEuMDYyNSAtNS41MTU2MjUgTCAxLjA2MjUgLTEuMjAzMTI1IEMgMS4wNjI1IC0wLjM1OTM3NSAwLjk2ODc1IC0wLjIzNDM3NSAwLjE4NzUgLTAuMTg3NSBMIDAuMTg3NSAwIEwgMi45NTMxMjUgMCBMIDIuOTUzMTI1IC0wLjE4NzUgQyAyLjIxODc1IC0wLjI1IDIuMDc4MTI1IC0wLjM3NSAyLjA3ODEyNSAtMS4wOTM3NSBMIDIuMDc4MTI1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0zLjE0MDYyNSBMIDUuMTA5Mzc1IC0xLjIwMzEyNSBDIDUuMTA5Mzc1IC0wLjM1OTM3NSA1IC0wLjIzNDM3NSA0LjIzNDM3NSAtMC4xODc1IEwgNC4yMzQzNzUgMCBMIDcgMCBMIDcgLTAuMTg3NSBDIDYuMjUgLTAuMjUgNi4xMjUgLTAuMzc1IDYuMTI1IC0xLjA5Mzc1IEwgNi4xMjUgLTUuNTE1NjI1IEMgNi4xMjUgLTYuMjM0Mzc1IDYuMjM0Mzc1IC02LjM0Mzc1IDcgLTYuNDA2MjUgTCA3IC02LjU5Mzc1IEwgNC4yMzQzNzUgLTYuNTkzNzUgTCA0LjIzNDM3NSAtNi40MDYyNSBDIDUgLTYuMzQzNzUgNS4xMDkzNzUgLTYuMjM0Mzc1IDUuMTA5Mzc1IC01LjUxNTYyNSBMIDUuMTA5Mzc1IC0zLjU3ODEyNSBaIE0gMi4wNzgxMjUgLTMuNTc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS00Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjA2MjUgLTYuMjAzMTI1IEMgMC4yMDMxMjUgLTYuMjE4NzUgMC4yOTY4NzUgLTYuMjM0Mzc1IDAuMzkwNjI1IC02LjIzNDM3NSBDIDAuNzE4NzUgLTYuMjM0Mzc1IDAuODEyNSAtNi4wOTM3NSAwLjgxMjUgLTUuNjI1IEwgMC44MTI1IC0wLjgxMjUgQyAwLjgxMjUgLTAuMjk2ODc1IDAuNzgxMjUgLTAuMjY1NjI1IDAuMDYyNSAtMC4xNTYyNSBMIDAuMDYyNSAwIEwgMi40MDYyNSAwIEwgMi40MDYyNSAtMC4xNTYyNSBMIDIuMjAzMTI1IC0wLjE1NjI1IEMgMS43OTY4NzUgLTAuMTcxODc1IDEuNjU2MjUgLTAuMzEyNSAxLjY1NjI1IC0wLjY3MTg3NSBMIDEuNjU2MjUgLTIuNSBMIDMuMDQ2ODc1IC0wLjY0MDYyNSBMIDMuMDc4MTI1IC0wLjU5Mzc1IEMgMy4wOTM3NSAtMC41NjI1IDMuMTI1IC0wLjUzMTI1IDMuMTU2MjUgLTAuNTE1NjI1IEMgMy4yMzQzNzUgLTAuNDA2MjUgMy4yNjU2MjUgLTAuMzQzNzUgMy4yNjU2MjUgLTAuMjk2ODc1IEMgMy4yNjU2MjUgLTAuMjAzMTI1IDMuMTcxODc1IC0wLjE1NjI1IDMuMDQ2ODc1IC0wLjE1NjI1IEwgMi44NTkzNzUgLTAuMTU2MjUgTCAyLjg1OTM3NSAwIEwgNS4wMzEyNSAwIEwgNS4wMzEyNSAtMC4xNTYyNSBDIDQuNTkzNzUgLTAuMTcxODc1IDQuMjgxMjUgLTAuMzc1IDMuODc1IC0wLjg3NSBMIDIuMzQzNzUgLTIuODEyNSBMIDIuNjI1IC0zLjA3ODEyNSBDIDMuMzQzNzUgLTMuNzM0Mzc1IDMuOTUzMTI1IC00LjIwMzEyNSA0LjI1IC00LjI4MTI1IEMgNC4zOTA2MjUgLTQuMzEyNSA0LjUzMTI1IC00LjM0Mzc1IDQuNzAzMTI1IC00LjM0Mzc1IEwgNC43ODEyNSAtNC4zNDM3NSBMIDQuNzgxMjUgLTQuNDg0Mzc1IEwgMi43NSAtNC40ODQzNzUgTCAyLjc1IC00LjM0Mzc1IEMgMy4xNDA2MjUgLTQuMzQzNzUgMy4yNSAtNC4yOTY4NzUgMy4yNSAtNC4xNTYyNSBDIDMuMjUgLTQuMDc4MTI1IDMuMTU2MjUgLTMuOTM3NSAzLjAxNTYyNSAtMy44MTI1IEwgMS42NTYyNSAtMi42MDkzNzUgTCAxLjY1NjI1IC02Ljc4MTI1IEwgMS42MDkzNzUgLTYuODEyNSBDIDEuMjM0Mzc1IC02LjY4NzUgMC45NTMxMjUgLTYuNjA5Mzc1IDAuMzc1IC02LjQ1MzEyNSBMIDAuMDYyNSAtNi4zNzUgWiBNIDAuMDYyNSAtNi4yMDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuMDYyNSAtMS42NDA2MjUgQyAzLjU5Mzc1IC0wLjg3NSAzLjE1NjI1IC0wLjU5Mzc1IDIuNTE1NjI1IC0wLjU5Mzc1IEMgMS45NTMxMjUgLTAuNTkzNzUgMS41MzEyNSAtMC44NzUgMS4yMzQzNzUgLTEuNDUzMTI1IEMgMS4wNjI1IC0xLjgyODEyNSAwLjk4NDM3NSAtMi4xNTYyNSAwLjk2ODc1IC0yLjc2NTYyNSBMIDQuMDMxMjUgLTIuNzY1NjI1IEMgMy45NTMxMjUgLTMuNDA2MjUgMy44NTkzNzUgLTMuNzAzMTI1IDMuNjA5Mzc1IC00LjAxNTYyNSBDIDMuMzEyNSAtNC4zNzUgMi44NDM3NSAtNC41NzgxMjUgMi4zMjgxMjUgLTQuNTc4MTI1IEMgMS44MjgxMjUgLTQuNTc4MTI1IDEuMzU5Mzc1IC00LjQwNjI1IDAuOTg0Mzc1IC00LjA2MjUgQyAwLjUxNTYyNSAtMy42NTYyNSAwLjI1IC0yLjk1MzEyNSAwLjI1IC0yLjE0MDYyNSBDIDAuMjUgLTAuNzUgMC45Njg3NSAwLjA5Mzc1IDIuMTA5Mzc1IDAuMDkzNzUgQyAzLjA2MjUgMC4wOTM3NSAzLjgxMjUgLTAuNDg0Mzc1IDQuMjM0Mzc1IC0xLjU2MjUgWiBNIDAuOTg0Mzc1IC0zLjA3ODEyNSBDIDEuMDkzNzUgLTMuODU5Mzc1IDEuNDM3NSAtNC4yMzQzNzUgMi4wNDY4NzUgLTQuMjM0Mzc1IEMgMi42NTYyNSAtNC4yMzQzNzUgMi44OTA2MjUgLTMuOTUzMTI1IDMuMDE1NjI1IC0zLjA3ODEyNSBaIE0gMC45ODQzNzUgLTMuMDc4MTI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS02Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAwLjA2MjUgLTMuODkwNjI1IEMgMC4yMDMxMjUgLTMuOTIxODc1IDAuMjk2ODc1IC0zLjkyMTg3NSAwLjQyMTg3NSAtMy45MjE4NzUgQyAwLjY3MTg3NSAtMy45MjE4NzUgMC43NSAtMy43NjU2MjUgMC43NSAtMy4zMjgxMjUgTCAwLjc1IC0wLjg0Mzc1IEMgMC43NSAtMC4zNDM3NSAwLjY4NzUgLTAuMjY1NjI1IDAuMDQ2ODc1IC0wLjE1NjI1IEwgMC4wNDY4NzUgMCBMIDIuNDM3NSAwIEwgMi40Mzc1IC0wLjE1NjI1IEMgMS43NjU2MjUgLTAuMTcxODc1IDEuNTkzNzUgLTAuMzI4MTI1IDEuNTkzNzUgLTAuODkwNjI1IEwgMS41OTM3NSAtMy4xNDA2MjUgQyAxLjU5Mzc1IC0zLjQ1MzEyNSAyLjAzMTI1IC0zLjk1MzEyNSAyLjI5Njg3NSAtMy45NTMxMjUgQyAyLjM1OTM3NSAtMy45NTMxMjUgMi40Mzc1IC0zLjkwNjI1IDIuNTQ2ODc1IC0zLjgxMjUgQyAyLjcxODc1IC0zLjY3MTg3NSAyLjgyODEyNSAtMy42MDkzNzUgMi45NTMxMjUgLTMuNjA5Mzc1IEMgMy4xODc1IC0zLjYwOTM3NSAzLjM0Mzc1IC0zLjc4MTI1IDMuMzQzNzUgLTQuMDYyNSBDIDMuMzQzNzUgLTQuMzkwNjI1IDMuMTI1IC00LjU3ODEyNSAyLjc5Njg3NSAtNC41NzgxMjUgQyAyLjM3NSAtNC41NzgxMjUgMi4wNzgxMjUgLTQuMzU5Mzc1IDEuNTkzNzUgLTMuNjU2MjUgTCAxLjU5Mzc1IC00LjU2MjUgTCAxLjU0Njg3NSAtNC41NzgxMjUgQyAxLjAxNTYyNSAtNC4zNTkzNzUgMC42NTYyNSAtNC4yMzQzNzUgMC4wNjI1IC00LjA0Njg3NSBaIE0gMC4wNjI1IC0zLjg5MDYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtNyI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC4xNTYyNSAtMy45Njg3NSBDIDAuMjE4NzUgLTQgMC4zMTI1IC00IDAuNDIxODc1IC00IEMgMC43MDMxMjUgLTQgMC43OTY4NzUgLTMuODU5Mzc1IDAuNzk2ODc1IC0zLjM3NSBMIDAuNzk2ODc1IC0wLjg5MDYyNSBDIDAuNzk2ODc1IC0wLjMyODEyNSAwLjY4NzUgLTAuMTg3NSAwLjE3MTg3NSAtMC4xNTYyNSBMIDAuMTcxODc1IDAgTCAyLjI5Njg3NSAwIEwgMi4yOTY4NzUgLTAuMTU2MjUgQyAxLjc4MTI1IC0wLjE4NzUgMS42NDA2MjUgLTAuMzEyNSAxLjY0MDYyNSAtMC42NzE4NzUgTCAxLjY0MDYyNSAtMy40Njg3NSBDIDIuMTA5Mzc1IC0zLjkyMTg3NSAyLjMyODEyNSAtNC4wMzEyNSAyLjY1NjI1IC00LjAzMTI1IEMgMy4xNTYyNSAtNC4wMzEyNSAzLjM5MDYyNSAtMy43MzQzNzUgMy4zOTA2MjUgLTMuMDc4MTI1IEwgMy4zOTA2MjUgLTAuOTg0Mzc1IEMgMy4zOTA2MjUgLTAuMzU5Mzc1IDMuMjY1NjI1IC0wLjE4NzUgMi43NjU2MjUgLTAuMTU2MjUgTCAyLjc2NTYyNSAwIEwgNC44MjgxMjUgMCBMIDQuODI4MTI1IC0wLjE1NjI1IEMgNC4zNDM3NSAtMC4yMDMxMjUgNC4yMzQzNzUgLTAuMzEyNSA0LjIzNDM3NSAtMC44MTI1IEwgNC4yMzQzNzUgLTMuMDkzNzUgQyA0LjIzNDM3NSAtNC4wMzEyNSAzLjc4MTI1IC00LjU3ODEyNSAzLjA0Njg3NSAtNC41NzgxMjUgQyAyLjU5Mzc1IC00LjU3ODEyNSAyLjI4MTI1IC00LjQyMTg3NSAxLjYwOTM3NSAtMy43ODEyNSBMIDEuNjA5Mzc1IC00LjU2MjUgTCAxLjUzMTI1IC00LjU3ODEyNSBDIDEuMDQ2ODc1IC00LjQwNjI1IDAuNzAzMTI1IC00LjI5Njg3NSAwLjE1NjI1IC00LjE0MDYyNSBaIE0gMC4xNTYyNSAtMy45Njg3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtOCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMC4xODc1IC02LjIwMzEyNSBMIDAuMjUgLTYuMjAzMTI1IEMgMC4zNTkzNzUgLTYuMjE4NzUgMC40ODQzNzUgLTYuMjM0Mzc1IDAuNTYyNSAtNi4yMzQzNzUgQyAwLjg3NSAtNi4yMzQzNzUgMC45ODQzNzUgLTYuMDkzNzUgMC45ODQzNzUgLTUuNjI1IEwgMC45ODQzNzUgLTAuODc1IEMgMC45ODQzNzUgLTAuMzI4MTI1IDAuODQzNzUgLTAuMjAzMTI1IDAuMjAzMTI1IC0wLjE1NjI1IEwgMC4yMDMxMjUgMCBMIDIuNTYyNSAwIEwgMi41NjI1IC0wLjE1NjI1IEMgMS45Mzc1IC0wLjE4NzUgMS44MTI1IC0wLjI5Njg3NSAxLjgxMjUgLTAuODQzNzUgTCAxLjgxMjUgLTYuNzgxMjUgTCAxLjc4MTI1IC02LjgxMjUgQyAxLjI1IC02LjY0MDYyNSAwLjg3NSAtNi41NDY4NzUgMC4xODc1IC02LjM3NSBaIE0gMC4xODc1IC02LjIwMzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtOSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNi4xODc1IC00LjQ4NDM3NSBMIDYuMDkzNzUgLTYuNzM0Mzc1IEwgNS44NzUgLTYuNzM0Mzc1IEMgNS44MjgxMjUgLTYuNTMxMjUgNS42NTYyNSAtNi40MDYyNSA1LjQ2ODc1IC02LjQwNjI1IEMgNS4zNzUgLTYuNDA2MjUgNS4yMTg3NSAtNi40Mzc1IDUuMDc4MTI1IC02LjUgQyA0LjU3ODEyNSAtNi42NTYyNSA0LjA5Mzc1IC02LjczNDM3NSAzLjYyNSAtNi43MzQzNzUgQyAyLjc5Njg3NSAtNi43MzQzNzUgMS45Njg3NSAtNi40Mzc1IDEuMzU5Mzc1IC01Ljg3NSBDIDAuNjU2MjUgLTUuMjY1NjI1IDAuMjgxMjUgLTQuMzQzNzUgMC4yODEyNSAtMy4yMzQzNzUgQyAwLjI4MTI1IC0yLjMxMjUgMC41NzgxMjUgLTEuNDUzMTI1IDEuMDkzNzUgLTAuODkwNjI1IEMgMS42ODc1IC0wLjIzNDM3NSAyLjYwOTM3NSAwLjE0MDYyNSAzLjU5Mzc1IDAuMTQwNjI1IEMgNC43MTg3NSAwLjE0MDYyNSA1LjcwMzEyNSAtMC4zMTI1IDYuMzEyNSAtMS4xMjUgTCA2LjEyNSAtMS4zMTI1IEMgNS4zOTA2MjUgLTAuNTkzNzUgNC43MzQzNzUgLTAuMjk2ODc1IDMuOTA2MjUgLTAuMjk2ODc1IEMgMy4yODEyNSAtMC4yOTY4NzUgMi43MTg3NSAtMC41IDIuMjk2ODc1IC0wLjg3NSBDIDEuNzUgLTEuMzU5Mzc1IDEuNDM3NSAtMi4yNjU2MjUgMS40Mzc1IC0zLjM3NSBDIDEuNDM3NSAtNS4xNzE4NzUgMi4zNTkzNzUgLTYuMzQzNzUgMy44MTI1IC02LjM0Mzc1IEMgNC4zNzUgLTYuMzQzNzUgNC44OTA2MjUgLTYuMTI1IDUuMjk2ODc1IC01LjczNDM3NSBDIDUuNjA5Mzc1IC01LjQwNjI1IDUuNzY1NjI1IC01LjE0MDYyNSA1Ljk1MzEyNSAtNC40ODQzNzUgWiBNIDYuMTg3NSAtNC40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTEwIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAxLjAzMTI1IC0xLjA5Mzc1IEMgMS4wMzEyNSAtMC4zNzUgMC45MjE4NzUgLTAuMjM0Mzc1IDAuMTU2MjUgLTAuMTg3NSBMIDAuMTU2MjUgMCBMIDIuOTg0Mzc1IDAgQyA0LjE0MDYyNSAwIDUuMTg3NSAtMC4zMjgxMjUgNS44MTI1IC0wLjg5MDYyNSBDIDYuNDUzMTI1IC0xLjQ2ODc1IDYuODI4MTI1IC0yLjM1OTM3NSA2LjgyODEyNSAtMy4zMjgxMjUgQyA2LjgyODEyNSAtNC4yMzQzNzUgNi41MzEyNSAtNSA1Ljk4NDM3NSAtNS41NDY4NzUgQyA1LjI5Njg3NSAtNi4yMzQzNzUgNC4yMTg3NSAtNi41OTM3NSAyLjg0Mzc1IC02LjU5Mzc1IEwgMC4xNTYyNSAtNi41OTM3NSBMIDAuMTU2MjUgLTYuNDA2MjUgQyAwLjk1MzEyNSAtNi4zNDM3NSAxLjAzMTI1IC02LjI1IDEuMDMxMjUgLTUuNTE1NjI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSBDIDIuMDQ2ODc1IC02LjE1NjI1IDIuMTU2MjUgLTYuMjM0Mzc1IDIuNTc4MTI1IC02LjIzNDM3NSBDIDMuNDIxODc1IC02LjIzNDM3NSA0LjA3ODEyNSAtNi4wNzgxMjUgNC41NjI1IC01LjczNDM3NSBDIDUuMzI4MTI1IC01LjE4NzUgNS43MzQzNzUgLTQuMzQzNzUgNS43MzQzNzUgLTMuMjY1NjI1IEMgNS43MzQzNzUgLTIuMDc4MTI1IDUuMzI4MTI1IC0xLjI1IDQuNTMxMjUgLTAuNzgxMjUgQyA0LjAxNTYyNSAtMC40ODQzNzUgMy40Mzc1IC0wLjM3NSAyLjU3ODEyNSAtMC4zNzUgQyAyLjE3MTg3NSAtMC4zNzUgMi4wNDY4NzUgLTAuNDUzMTI1IDIuMDQ2ODc1IC0wLjc4MTI1IFogTSAyLjA0Njg3NSAtNS44NDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDAuMzEyNSAtNC4xNTYyNSBMIDAuOTg0Mzc1IC00LjE1NjI1IEwgMC45ODQzNzUgLTAuOTM3NSBDIDAuOTg0Mzc1IC0wLjI5Njg3NSAwLjg3NSAtMC4xNzE4NzUgMC4zMTI1IC0wLjE1NjI1IEwgMC4zMTI1IDAgTCAyLjUxNTYyNSAwIEwgMi41MTU2MjUgLTAuMTU2MjUgQyAxLjk1MzEyNSAtMC4xODc1IDEuODI4MTI1IC0wLjMyODEyNSAxLjgyODEyNSAtMC44NzUgTCAxLjgyODEyNSAtNC4xNTYyNSBMIDIuNjg3NSAtNC4xNTYyNSBDIDMuNjQwNjI1IC00LjE1NjI1IDMuNjg3NSAtNC4xMjUgMy42ODc1IC0zLjU5Mzc1IEwgMy42ODc1IC0wLjk2ODc1IEMgMy42ODc1IC0wLjI5Njg3NSAzLjYyNSAtMC4yMDMxMjUgMyAtMC4xNTYyNSBMIDMgMCBMIDUuMTg3NSAwIEwgNS4xODc1IC0wLjE1NjI1IEMgNC42NDA2MjUgLTAuMjAzMTI1IDQuNTMxMjUgLTAuMzI4MTI1IDQuNTMxMjUgLTAuOTY4NzUgTCA0LjUzMTI1IC0zLjU3ODEyNSBDIDQuNTMxMjUgLTMuNzk2ODc1IDQuNTMxMjUgLTQuMDMxMjUgNC41NDY4NzUgLTQuNTYyNSBMIDQuNSAtNC41NzgxMjUgQyA0LjA2MjUgLTQuNTE1NjI1IDMuNzgxMjUgLTQuNDg0Mzc1IDMuMzc1IC00LjQ4NDM3NSBMIDEuODEyNSAtNC40ODQzNzUgTCAxLjgxMjUgLTQuOTIxODc1IEMgMS44MTI1IC01LjM1OTM3NSAxLjg0Mzc1IC01LjY1NjI1IDEuODkwNjI1IC01LjgyODEyNSBDIDIuMDMxMjUgLTYuMjY1NjI1IDIuNDIxODc1IC02LjU2MjUgMi44NzUgLTYuNTYyNSBDIDMuMTU2MjUgLTYuNTYyNSAzLjM0Mzc1IC02LjQzNzUgMy41NzgxMjUgLTYuMDkzNzUgQyAzLjc2NTYyNSAtNS44MjgxMjUgMy44OTA2MjUgLTUuNzE4NzUgNC4wNjI1IC01LjcxODc1IEMgNC4yODEyNSAtNS43MTg3NSA0LjQyMTg3NSAtNS44OTA2MjUgNC40MjE4NzUgLTYuMTA5Mzc1IEMgNC40MjE4NzUgLTYuNTMxMjUgMy45MjE4NzUgLTYuODEyNSAzLjE1NjI1IC02LjgxMjUgQyAyLjQwNjI1IC02LjgxMjUgMS44MjgxMjUgLTYuNTQ2ODc1IDEuNDY4NzUgLTYuMDYyNSBDIDEuMTcxODc1IC01LjY1NjI1IDEuMDYyNSAtNS4yODEyNSAxIC00LjQ4NDM3NSBMIDAuMzEyNSAtNC40ODQzNzUgWiBNIDAuMzEyNSAtNC4xNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuOTA2MjUgLTYuNzM0Mzc1IEwgMS4xMDkzNzUgLTUuODI4MTI1IEwgMS4xMDkzNzUgLTUuNjg3NSBDIDEuMjE4NzUgLTUuNzM0Mzc1IDEuMzI4MTI1IC01Ljc4MTI1IDEuMzc1IC01Ljc5Njg3NSBDIDEuNTYyNSAtNS44NzUgMS43MTg3NSAtNS45MDYyNSAxLjgyODEyNSAtNS45MDYyNSBDIDIuMDMxMjUgLTUuOTA2MjUgMi4xMjUgLTUuNzY1NjI1IDIuMTI1IC01LjQzNzUgTCAyLjEyNSAtMC45MjE4NzUgQyAyLjEyNSAtMC41OTM3NSAyLjA0Njg3NSAtMC4zNzUgMS44OTA2MjUgLTAuMjgxMjUgQyAxLjczNDM3NSAtMC4xODc1IDEuNTkzNzUgLTAuMTU2MjUgMS4xNzE4NzUgLTAuMTU2MjUgTCAxLjE3MTg3NSAwIEwgMy45MjE4NzUgMCBMIDMuOTIxODc1IC0wLjE1NjI1IEMgMy4xNDA2MjUgLTAuMTU2MjUgMi45ODQzNzUgLTAuMjY1NjI1IDIuOTg0Mzc1IC0wLjczNDM3NSBMIDIuOTg0Mzc1IC02LjcxODc1IFogTSAyLjkwNjI1IC02LjczNDM3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTMiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzM0Mzc1IC0xLjM1OTM3NSBMIDQuNjA5Mzc1IC0xLjQyMTg3NSBDIDQuMjM0Mzc1IC0wLjg0Mzc1IDQuMTA5Mzc1IC0wLjc1IDMuNjU2MjUgLTAuNzUgTCAxLjI4MTI1IC0wLjc1IEwgMi45NTMxMjUgLTIuNTE1NjI1IEMgMy44NDM3NSAtMy40Mzc1IDQuMjM0Mzc1IC00LjIwMzEyNSA0LjIzNDM3NSAtNC45Njg3NSBDIDQuMjM0Mzc1IC01Ljk2ODc1IDMuNDIxODc1IC02LjczNDM3NSAyLjM3NSAtNi43MzQzNzUgQyAxLjgyODEyNSAtNi43MzQzNzUgMS4zMTI1IC02LjUxNTYyNSAwLjk1MzEyNSAtNi4xMjUgQyAwLjYyNSAtNS43ODEyNSAwLjQ4NDM3NSAtNS40Njg3NSAwLjMxMjUgLTQuNzUgTCAwLjUxNTYyNSAtNC43MDMxMjUgQyAwLjkyMTg3NSAtNS42ODc1IDEuMjgxMjUgLTYgMS45Njg3NSAtNiBDIDIuNzk2ODc1IC02IDMuMzc1IC01LjQzNzUgMy4zNzUgLTQuNTkzNzUgQyAzLjM3NSAtMy44MTI1IDIuOTA2MjUgLTIuODkwNjI1IDIuMDc4MTI1IC0yIEwgMC4yOTY4NzUgLTAuMTI1IEwgMC4yOTY4NzUgMCBMIDQuMTg3NSAwIFogTSA0LjczNDM3NSAtMS4zNTkzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgxLTE0Ij4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSAzLjk2ODc1IC0xLjU2MjUgQyAzLjQ4NDM3NSAtMC44NTkzNzUgMy4xMjUgLTAuNjI1IDIuNTYyNSAtMC42MjUgQyAxLjY1NjI1IC0wLjYyNSAxLjAxNTYyNSAtMS40MjE4NzUgMS4wMTU2MjUgLTIuNTYyNSBDIDEuMDE1NjI1IC0zLjU5Mzc1IDEuNTYyNSAtNC4yOTY4NzUgMi4zNzUgLTQuMjk2ODc1IEMgMi43MzQzNzUgLTQuMjk2ODc1IDIuODU5Mzc1IC00LjE4NzUgMi45NTMxMjUgLTMuODEyNSBMIDMuMDE1NjI1IC0zLjU5Mzc1IEMgMy4wOTM3NSAtMy4zMTI1IDMuMjgxMjUgLTMuMTQwNjI1IDMuNDg0Mzc1IC0zLjE0MDYyNSBDIDMuNzUgLTMuMTQwNjI1IDMuOTY4NzUgLTMuMzI4MTI1IDMuOTY4NzUgLTMuNTYyNSBDIDMuOTY4NzUgLTQuMTA5Mzc1IDMuMjY1NjI1IC00LjU3ODEyNSAyLjQzNzUgLTQuNTc4MTI1IEMgMS45Mzc1IC00LjU3ODEyNSAxLjQzNzUgLTQuMzkwNjI1IDEuMDMxMjUgLTQuMDMxMjUgQyAwLjUzMTI1IC0zLjU5Mzc1IDAuMjUgLTIuOTA2MjUgMC4yNSAtMi4xMjUgQyAwLjI1IC0wLjgyODEyNSAxLjAzMTI1IDAuMDkzNzUgMi4xNDA2MjUgMC4wOTM3NSBDIDIuNTkzNzUgMC4wOTM3NSAyLjk4NDM3NSAtMC4wNjI1IDMuMzQzNzUgLTAuMzc1IEMgMy42MjUgLTAuNjA5Mzc1IDMuODEyNSAtMC44NzUgNC4xMDkzNzUgLTEuNDY4NzUgWiBNIDMuOTY4NzUgLTEuNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTUiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuNTQ2ODc1IC00LjQ4NDM3NSBMIDEuNTMxMjUgLTQuNDg0Mzc1IEwgMS41MzEyNSAtNS42NDA2MjUgQyAxLjUzMTI1IC01LjczNDM3NSAxLjUzMTI1IC01Ljc2NTYyNSAxLjQ2ODc1IC01Ljc2NTYyNSBDIDEuMzkwNjI1IC01LjY4NzUgMS4zMjgxMjUgLTUuNTkzNzUgMS4yNjU2MjUgLTUuNSBDIDAuODkwNjI1IC00LjkzNzUgMC40NTMxMjUgLTQuNDY4NzUgMC4yOTY4NzUgLTQuNDIxODc1IEMgMC4xODc1IC00LjM1OTM3NSAwLjEyNSAtNC4yODEyNSAwLjEyNSAtNC4yMzQzNzUgQyAwLjEyNSAtNC4yMDMxMjUgMC4xNDA2MjUgLTQuMTg3NSAwLjE3MTg3NSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtNC4xNzE4NzUgTCAwLjcwMzEyNSAtMS4xNzE4NzUgQyAwLjcwMzEyNSAtMC4zMjgxMjUgMSAwLjA5Mzc1IDEuNTc4MTI1IDAuMDkzNzUgQyAyLjA3ODEyNSAwLjA5Mzc1IDIuNDUzMTI1IC0wLjE0MDYyNSAyLjc4MTI1IC0wLjY1NjI1IEwgMi42NTYyNSAtMC43NjU2MjUgQyAyLjQzNzUgLTAuNTE1NjI1IDIuMjY1NjI1IC0wLjQyMTg3NSAyLjA0Njg3NSAtMC40MjE4NzUgQyAxLjY4NzUgLTAuNDIxODc1IDEuNTMxMjUgLTAuNjg3NSAxLjUzMTI1IC0xLjMxMjUgTCAxLjUzMTI1IC00LjE3MTg3NSBMIDIuNTQ2ODc1IC00LjE3MTg3NSBaIE0gMi41NDY4NzUgLTQuNDg0Mzc1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMS0xNiI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNC40MDYyNSAtMC42NTYyNSBDIDQuMjM0Mzc1IC0wLjUxNTYyNSA0LjEwOTM3NSAtMC40Njg3NSAzLjk2ODc1IC0wLjQ2ODc1IEMgMy43MzQzNzUgLTAuNDY4NzUgMy42NzE4NzUgLTAuNjA5Mzc1IDMuNjcxODc1IC0xLjA0Njg3NSBMIDMuNjcxODc1IC0yLjk4NDM3NSBDIDMuNjcxODc1IC0zLjUxNTYyNSAzLjYyNSAtMy43OTY4NzUgMy40Njg3NSAtNC4wMzEyNSBDIDMuMjUgLTQuMzkwNjI1IDIuODI4MTI1IC00LjU3ODEyNSAyLjIzNDM3NSAtNC41NzgxMjUgQyAxLjI5Njg3NSAtNC41NzgxMjUgMC41NjI1IC00LjA5Mzc1IDAuNTYyNSAtMy40Njg3NSBDIDAuNTYyNSAtMy4yMzQzNzUgMC43NSAtMy4wNDY4NzUgMC45ODQzNzUgLTMuMDQ2ODc1IEMgMS4yMTg3NSAtMy4wNDY4NzUgMS40Mzc1IC0zLjIzNDM3NSAxLjQzNzUgLTMuNDUzMTI1IEMgMS40Mzc1IC0zLjUgMS40MjE4NzUgLTMuNTQ2ODc1IDEuNDIxODc1IC0zLjYyNSBDIDEuMzkwNjI1IC0zLjcwMzEyNSAxLjM5MDYyNSAtMy43ODEyNSAxLjM5MDYyNSAtMy44NTkzNzUgQyAxLjM5MDYyNSAtNC4xMjUgMS43MDMxMjUgLTQuMzQzNzUgMi4xMDkzNzUgLTQuMzQzNzUgQyAyLjU5Mzc1IC00LjM0Mzc1IDIuODU5Mzc1IC00LjA2MjUgMi44NTkzNzUgLTMuNTE1NjI1IEwgMi44NTkzNzUgLTIuOTA2MjUgQyAxLjMyODEyNSAtMi4yOTY4NzUgMS4xNTYyNSAtMi4yMTg3NSAwLjczNDM3NSAtMS44MjgxMjUgQyAwLjUxNTYyNSAtMS42NDA2MjUgMC4zNzUgLTEuMjk2ODc1IDAuMzc1IC0wLjk2ODc1IEMgMC4zNzUgLTAuMzQzNzUgMC44MTI1IDAuMDkzNzUgMS40MjE4NzUgMC4wOTM3NSBDIDEuODU5Mzc1IDAuMDkzNzUgMi4yNjU2MjUgLTAuMTA5Mzc1IDIuODc1IC0wLjYyNSBDIDIuOTIxODc1IC0wLjEwOTM3NSAzLjA5Mzc1IDAuMDkzNzUgMy41MTU2MjUgMC4wOTM3NSBDIDMuODQzNzUgMC4wOTM3NSA0LjA2MjUgLTAuMDE1NjI1IDQuNDA2MjUgLTAuNDA2MjUgWiBNIDIuODU5Mzc1IC0xLjIxODc1IEMgMi44NTkzNzUgLTAuOTIxODc1IDIuODEyNSAtMC44MjgxMjUgMi42MDkzNzUgLTAuNzAzMTI1IEMgMi4zNTkzNzUgLTAuNTYyNSAyLjA3ODEyNSAtMC40ODQzNzUgMS44NzUgLTAuNDg0Mzc1IEMgMS41MzEyNSAtMC40ODQzNzUgMS4yNSAtMC44MTI1IDEuMjUgLTEuMjUgTCAxLjI1IC0xLjI4MTI1IEMgMS4yNSAtMS44NzUgMS42NTYyNSAtMi4yMzQzNzUgMi44NTkzNzUgLTIuNjcxODc1IFogTSAyLjg1OTM3NSAtMS4yMTg3NSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTciPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDMuNDIxODc1IDAuMDkzNzUgTCA0Ljg5MDYyNSAtMC40MjE4NzUgTCA0Ljg5MDYyNSAtMC41NzgxMjUgQyA0LjcxODc1IC0wLjU2MjUgNC42ODc1IC0wLjU2MjUgNC42NzE4NzUgLTAuNTYyNSBDIDQuMzEyNSAtMC41NjI1IDQuMjM0Mzc1IC0wLjY3MTg3NSA0LjIzNDM3NSAtMS4xNDA2MjUgTCA0LjIzNDM3NSAtNi43ODEyNSBMIDQuMTcxODc1IC02LjgxMjUgQyAzLjcwMzEyNSAtNi42NDA2MjUgMy4zNDM3NSAtNi41NDY4NzUgMi43MTg3NSAtNi4zNzUgTCAyLjcxODc1IC02LjIwMzEyNSBDIDIuNzk2ODc1IC02LjIxODc1IDIuODQzNzUgLTYuMjE4NzUgMi45Mzc1IC02LjIxODc1IEMgMy4yOTY4NzUgLTYuMjE4NzUgMy4zOTA2MjUgLTYuMTI1IDMuMzkwNjI1IC01LjcxODc1IEwgMy4zOTA2MjUgLTQuMTU2MjUgQyAzLjAxNTYyNSAtNC40Njg3NSAyLjczNDM3NSAtNC41NzgxMjUgMi4zNDM3NSAtNC41NzgxMjUgQyAxLjIwMzEyNSAtNC41NzgxMjUgMC4yNjU2MjUgLTMuNDUzMTI1IDAuMjY1NjI1IC0yLjA0Njg3NSBDIDAuMjY1NjI1IC0wLjc2NTYyNSAxLjAxNTYyNSAwLjA5Mzc1IDIuMTA5Mzc1IDAuMDkzNzUgQyAyLjY3MTg3NSAwLjA5Mzc1IDMuMDQ2ODc1IC0wLjA5Mzc1IDMuMzkwNjI1IC0wLjU2MjUgTCAzLjM5MDYyNSAwLjA2MjUgWiBNIDMuMzkwNjI1IC0xLjAxNTYyNSBDIDMuMzkwNjI1IC0wLjk1MzEyNSAzLjMxMjUgLTAuODI4MTI1IDMuMjE4NzUgLTAuNzE4NzUgQyAzLjA0Njg3NSAtMC41MTU2MjUgMi43OTY4NzUgLTAuNDIxODc1IDIuNSAtMC40MjE4NzUgQyAxLjY3MTg3NSAtMC40MjE4NzUgMS4xMjUgLTEuMjE4NzUgMS4xMjUgLTIuNDM3NSBDIDEuMTI1IC0zLjU2MjUgMS42MDkzNzUgLTQuMzEyNSAyLjM3NSAtNC4zMTI1IEMgMi45MDYyNSAtNC4zMTI1IDMuMzkwNjI1IC0zLjg0Mzc1IDMuMzkwNjI1IC0zLjMxMjUgWiBNIDMuMzkwNjI1IC0xLjAxNTYyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTgiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDEuNzUgLTQuNTc4MTI1IEwgMC4yMDMxMjUgLTQuMDMxMjUgTCAwLjIwMzEyNSAtMy44OTA2MjUgTCAwLjI4MTI1IC0zLjg5MDYyNSBDIDAuNDA2MjUgLTMuOTIxODc1IDAuNTMxMjUgLTMuOTIxODc1IDAuNjI1IC0zLjkyMTg3NSBDIDAuODU5Mzc1IC0zLjkyMTg3NSAwLjk1MzEyNSAtMy43NjU2MjUgMC45NTMxMjUgLTMuMzI4MTI1IEwgMC45NTMxMjUgLTEuMDE1NjI1IEMgMC45NTMxMjUgLTAuMjk2ODc1IDAuODQzNzUgLTAuMTg3NSAwLjE1NjI1IC0wLjE1NjI1IEwgMC4xNTYyNSAwIEwgMi41MTU2MjUgMCBMIDIuNTE1NjI1IC0wLjE1NjI1IEMgMS44NTkzNzUgLTAuMjAzMTI1IDEuNzgxMjUgLTAuMjk2ODc1IDEuNzgxMjUgLTEuMDE1NjI1IEwgMS43ODEyNSAtNC41NjI1IFogTSAxLjI4MTI1IC02LjgxMjUgQyAxIC02LjgxMjUgMC43ODEyNSAtNi41NzgxMjUgMC43ODEyNSAtNi4yOTY4NzUgQyAwLjc4MTI1IC02LjAxNTYyNSAxIC01Ljc5Njg3NSAxLjI4MTI1IC01Ljc5Njg3NSBDIDEuNTYyNSAtNS43OTY4NzUgMS43OTY4NzUgLTYuMDE1NjI1IDEuNzk2ODc1IC02LjI5Njg3NSBDIDEuNzk2ODc1IC02LjU3ODEyNSAxLjU2MjUgLTYuODEyNSAxLjI4MTI1IC02LjgxMjUgWiBNIDEuMjgxMjUgLTYuODEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMTkiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuNSAtNC41NzgxMjUgQyAxLjIwMzEyNSAtNC41NzgxMjUgMC4yOTY4NzUgLTMuNjI1IDAuMjk2ODc1IC0yLjI1IEMgMC4yOTY4NzUgLTAuOTA2MjUgMS4yMTg3NSAwLjA5Mzc1IDIuNDY4NzUgMC4wOTM3NSBDIDMuNzM0Mzc1IDAuMDkzNzUgNC42ODc1IC0wLjk1MzEyNSA0LjY4NzUgLTIuMzI4MTI1IEMgNC42ODc1IC0zLjY0MDYyNSAzLjc2NTYyNSAtNC41NzgxMjUgMi41IC00LjU3ODEyNSBaIE0gMi4zNTkzNzUgLTQuMzEyNSBDIDMuMjAzMTI1IC00LjMxMjUgMy43ODEyNSAtMy4zNDM3NSAzLjc4MTI1IC0xLjk4NDM3NSBDIDMuNzgxMjUgLTAuODU5Mzc1IDMuMzQzNzUgLTAuMTcxODc1IDIuNTkzNzUgLTAuMTcxODc1IEMgMi4yMDMxMjUgLTAuMTcxODc1IDEuODI4MTI1IC0wLjQyMTg3NSAxLjYyNSAtMC44MTI1IEMgMS4zNDM3NSAtMS4zMjgxMjUgMS4xODc1IC0yLjAzMTI1IDEuMTg3NSAtMi43MzQzNzUgQyAxLjE4NzUgLTMuNjg3NSAxLjY1NjI1IC00LjMxMjUgMi4zNTkzNzUgLTQuMzEyNSBaIE0gMi4zNTkzNzUgLTQuMzEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDEtMjAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDQuNzM0Mzc1IC00LjQ4NDM3NSBMIDMuMzkwNjI1IC00LjQ4NDM3NSBMIDMuMzkwNjI1IC00LjM0Mzc1IEMgMy43MDMxMjUgLTQuMzQzNzUgMy44NzUgLTQuMjUgMy44NzUgLTQuMDkzNzUgQyAzLjg3NSAtNC4wNDY4NzUgMy44NTkzNzUgLTMuOTg0Mzc1IDMuODI4MTI1IC0zLjkyMTg3NSBMIDIuODU5Mzc1IC0xLjE3MTg3NSBMIDEuNzE4NzUgLTMuNjg3NSBDIDEuNjU2MjUgLTMuODI4MTI1IDEuNjA5Mzc1IC0zLjk1MzEyNSAxLjYwOTM3NSAtNC4wNjI1IEMgMS42MDkzNzUgLTQuMjUgMS43NjU2MjUgLTQuMzEyNSAyLjE4NzUgLTQuMzQzNzUgTCAyLjE4NzUgLTQuNDg0Mzc1IEwgMC4xNDA2MjUgLTQuNDg0Mzc1IEwgMC4xNDA2MjUgLTQuMzQzNzUgQyAwLjQwNjI1IC00LjMxMjUgMC41NjI1IC00LjIwMzEyNSAwLjY0MDYyNSAtNC4wMzEyNSBMIDEuNzgxMjUgLTEuNTc4MTI1IEwgMS44MTI1IC0xLjUgTCAxLjk2ODc1IC0xLjIwMzEyNSBDIDIuMjUgLTAuNzAzMTI1IDIuNDA2MjUgLTAuMzQzNzUgMi40MDYyNSAtMC4xODc1IEMgMi40MDYyNSAtMC4wNDY4NzUgMi4xNzE4NzUgMC41OTM3NSAyIDAuODkwNjI1IEMgMS44NTkzNzUgMS4xNDA2MjUgMS42NDA2MjUgMS4zMjgxMjUgMS41IDEuMzI4MTI1IEMgMS40NTMxMjUgMS4zMjgxMjUgMS4zNTkzNzUgMS4zMTI1IDEuMjUgMS4yNjU2MjUgQyAxLjA2MjUgMS4yMDMxMjUgMC44OTA2MjUgMS4xNTYyNSAwLjczNDM3NSAxLjE1NjI1IEMgMC41IDEuMTU2MjUgMC4yOTY4NzUgMS4zNTkzNzUgMC4yOTY4NzUgMS41OTM3NSBDIDAuMjk2ODc1IDEuOTIxODc1IDAuNjI1IDIuMTcxODc1IDEuMDMxMjUgMi4xNzE4NzUgQyAxLjcwMzEyNSAyLjE3MTg3NSAyLjE4NzUgMS42MDkzNzUgMi43MTg3NSAwLjE3MTg3NSBMIDQuMjUgLTMuODkwNjI1IEMgNC4zOTA2MjUgLTQuMjAzMTI1IDQuNSAtNC4zMTI1IDQuNzM0Mzc1IC00LjM0Mzc1IFogTSA0LjczNDM3NSAtNC40ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgyLTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDItMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMi4xNDA2MjUgLTQuOTg0Mzc1IEwgMC44MTI1IC00LjMxMjUgTCAwLjgxMjUgLTQuMjE4NzUgQyAwLjkwNjI1IC00LjI1IDAuOTg0Mzc1IC00LjI4MTI1IDEuMDE1NjI1IC00LjI5Njg3NSBDIDEuMTU2MjUgLTQuMzQzNzUgMS4yODEyNSAtNC4zNzUgMS4zNDM3NSAtNC4zNzUgQyAxLjUgLTQuMzc1IDEuNTc4MTI1IC00LjI2NTYyNSAxLjU3ODEyNSAtNC4wMzEyNSBMIDEuNTc4MTI1IC0wLjY4NzUgQyAxLjU3ODEyNSAtMC40Mzc1IDEuNTE1NjI1IC0wLjI2NTYyNSAxLjM5MDYyNSAtMC4yMDMxMjUgQyAxLjI4MTI1IC0wLjE0MDYyNSAxLjE4NzUgLTAuMTI1IDAuODc1IC0wLjEwOTM3NSBMIDAuODc1IDAgTCAyLjkwNjI1IDAgTCAyLjkwNjI1IC0wLjEwOTM3NSBDIDIuMzI4MTI1IC0wLjEyNSAyLjIwMzEyNSAtMC4xODc1IDIuMjAzMTI1IC0wLjU0Njg3NSBMIDIuMjAzMTI1IC00Ljk2ODc1IFogTSAyLjE0MDYyNSAtNC45ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgyLTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDMuNSAtMS4wMTU2MjUgTCAzLjQwNjI1IC0xLjA0Njg3NSBDIDMuMTQwNjI1IC0wLjYyNSAzLjAzMTI1IC0wLjU2MjUgMi43MDMxMjUgLTAuNTYyNSBMIDAuOTM3NSAtMC41NjI1IEwgMi4xODc1IC0xLjg1OTM3NSBDIDIuODQzNzUgLTIuNTQ2ODc1IDMuMTI1IC0zLjEwOTM3NSAzLjEyNSAtMy42ODc1IEMgMy4xMjUgLTQuNDIxODc1IDIuNTMxMjUgLTQuOTg0Mzc1IDEuNzY1NjI1IC00Ljk4NDM3NSBDIDEuMzU5Mzc1IC00Ljk4NDM3NSAwLjk2ODc1IC00LjgyODEyNSAwLjcwMzEyNSAtNC41MzEyNSBDIDAuNDY4NzUgLTQuMjgxMjUgMC4zNTkzNzUgLTQuMDQ2ODc1IDAuMjM0Mzc1IC0zLjUxNTYyNSBMIDAuMzkwNjI1IC0zLjQ4NDM3NSBDIDAuNjcxODc1IC00LjIwMzEyNSAwLjkzNzUgLTQuNDM3NSAxLjQ1MzEyNSAtNC40Mzc1IEMgMi4wNzgxMjUgLTQuNDM3NSAyLjUgLTQuMDE1NjI1IDIuNSAtMy40MDYyNSBDIDIuNSAtMi44MjgxMjUgMi4xNTYyNSAtMi4xNDA2MjUgMS41MzEyNSAtMS40ODQzNzUgTCAwLjIxODc1IC0wLjA5Mzc1IEwgMC4yMTg3NSAwIEwgMy4wOTM3NSAwIFogTSAzLjUgLTEuMDE1NjI1ICIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoMy0wIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGgzLTEiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDIuMjk2ODc1IC0yLjk4NDM3NSBDIDIuMjk2ODc1IC0zLjMyODEyNSAyLjAxNTYyNSAtMy42MjUgMS42NTYyNSAtMy42MjUgQyAxLjMxMjUgLTMuNjI1IDEuMDMxMjUgLTMuMzI4MTI1IDEuMDMxMjUgLTIuOTg0Mzc1IEMgMS4wMzEyNSAtMi42NDA2MjUgMS4zMTI1IC0yLjM1OTM3NSAxLjY1NjI1IC0yLjM1OTM3NSBDIDIuMDE1NjI1IC0yLjM1OTM3NSAyLjI5Njg3NSAtMi42NDA2MjUgMi4yOTY4NzUgLTIuOTg0Mzc1IFogTSAyLjI5Njg3NSAtMi45ODQzNzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg0LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDQtMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNS4zNTkzNzUgLTQuODEyNSBMIDMuODkwNjI1IC00LjgxMjUgTCAzLjg5MDYyNSAtNC43MDMxMjUgQyA0LjMxMjUgLTQuNjU2MjUgNC40MDYyNSAtNC41OTM3NSA0LjQwNjI1IC00LjMyODEyNSBDIDQuNDA2MjUgLTQuMjM0Mzc1IDQuMzkwNjI1IC00LjE0MDYyNSA0LjM0Mzc1IC00IEMgNC4zNDM3NSAtMy45Njg3NSA0LjMyODEyNSAtMy45NTMxMjUgNC4zMjgxMjUgLTMuOTM3NSBMIDMuNTc4MTI1IC0xLjE0MDYyNSBMIDIuMDQ2ODc1IC00LjgxMjUgTCAwLjg1OTM3NSAtNC44MTI1IEwgMC44NTkzNzUgLTQuNzAzMTI1IEMgMS4yMDMxMjUgLTQuNjcxODc1IDEuMzU5Mzc1IC00LjU3ODEyNSAxLjQ4NDM3NSAtNC4yODEyNSBMIDAuNjA5Mzc1IC0xLjIwMzEyNSBDIDAuMzI4MTI1IC0wLjI2NTYyNSAwLjI2NTYyNSAtMC4xNzE4NzUgLTAuMTQwNjI1IC0wLjEyNSBMIC0wLjE0MDYyNSAwIEwgMS4zMTI1IDAgTCAxLjMxMjUgLTAuMTI1IEMgMC45Mzc1IC0wLjE0MDYyNSAwLjc5Njg3NSAtMC4yMzQzNzUgMC43OTY4NzUgLTAuNDM3NSBDIDAuNzk2ODc1IC0wLjUzMTI1IDAuODEyNSAtMC42NzE4NzUgMC44NTkzNzUgLTAuODI4MTI1IEwgMS43MDMxMjUgLTMuOTUzMTI1IEwgMy40MDYyNSAwLjEwOTM3NSBMIDMuNTMxMjUgMC4xMDkzNzUgTCA0LjU5Mzc1IC0zLjU5Mzc1IEMgNC44NzUgLTQuNTQ2ODc1IDQuODkwNjI1IC00LjU5Mzc1IDUuMzU5Mzc1IC00LjcwMzEyNSBaIE0gNS4zNTkzNzUgLTQuODEyNSAiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDUtMCI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9IiIvPgo8L3N5bWJvbD4KPHN5bWJvbCBvdmVyZmxvdz0idmlzaWJsZSIgaWQ9ImdseXBoNS0xIj4KPHBhdGggc3R5bGU9InN0cm9rZTpub25lOyIgZD0iTSA0Ljg1OTM3NSAtMS43MDMxMjUgQyA0Ljk4NDM3NSAtMS43MDMxMjUgNS4xMjUgLTEuNzAzMTI1IDUuMTI1IC0xLjg0Mzc1IEMgNS4xMjUgLTEuOTg0Mzc1IDQuOTg0Mzc1IC0xLjk4NDM3NSA0Ljg1OTM3NSAtMS45ODQzNzUgTCAwLjg3NSAtMS45ODQzNzUgQyAwLjc1IC0xLjk4NDM3NSAwLjYwOTM3NSAtMS45ODQzNzUgMC42MDkzNzUgLTEuODQzNzUgQyAwLjYwOTM3NSAtMS43MDMxMjUgMC43NSAtMS43MDMxMjUgMC44NzUgLTEuNzAzMTI1IFogTSA0Ljg1OTM3NSAtMS43MDMxMjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg2LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDYtMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gMS45MDYyNSAtMi41IEMgMS45MDYyNSAtMi43ODEyNSAxLjY3MTg3NSAtMy4wMTU2MjUgMS4zOTA2MjUgLTMuMDE1NjI1IEMgMS4wOTM3NSAtMy4wMTU2MjUgMC44NTkzNzUgLTIuNzgxMjUgMC44NTkzNzUgLTIuNSBDIDAuODU5Mzc1IC0yLjIwMzEyNSAxLjA5Mzc1IC0xLjk2ODc1IDEuMzkwNjI1IC0xLjk2ODc1IEMgMS42NzE4NzUgLTEuOTY4NzUgMS45MDYyNSAtMi4yMDMxMjUgMS45MDYyNSAtMi41IFogTSAxLjkwNjI1IC0yLjUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg2LTIiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSJNIDYuNTYyNSAtMi4yOTY4NzUgQyA2LjczNDM3NSAtMi4yOTY4NzUgNi45MjE4NzUgLTIuMjk2ODc1IDYuOTIxODc1IC0yLjUgQyA2LjkyMTg3NSAtMi42ODc1IDYuNzM0Mzc1IC0yLjY4NzUgNi41NjI1IC0yLjY4NzUgTCAxLjE3MTg3NSAtMi42ODc1IEMgMSAtMi42ODc1IDAuODI4MTI1IC0yLjY4NzUgMC44MjgxMjUgLTIuNSBDIDAuODI4MTI1IC0yLjI5Njg3NSAxIC0yLjI5Njg3NSAxLjE3MTg3NSAtMi4yOTY4NzUgWiBNIDYuNTYyNSAtMi4yOTY4NzUgIi8+Cjwvc3ltYm9sPgo8c3ltYm9sIG92ZXJmbG93PSJ2aXNpYmxlIiBpZD0iZ2x5cGg3LTAiPgo8cGF0aCBzdHlsZT0ic3Ryb2tlOm5vbmU7IiBkPSIiLz4KPC9zeW1ib2w+CjxzeW1ib2wgb3ZlcmZsb3c9InZpc2libGUiIGlkPSJnbHlwaDctMSI+CjxwYXRoIHN0eWxlPSJzdHJva2U6bm9uZTsiIGQ9Ik0gNy4yNSAtNi41MTU2MjUgTCA1LjI2NTYyNSAtNi41MTU2MjUgTCA1LjI2NTYyNSAtNi4zNDM3NSBDIDUuODI4MTI1IC02LjI5Njg3NSA1Ljk2ODc1IC02LjIwMzEyNSA1Ljk2ODc1IC01Ljg0Mzc1IEMgNS45Njg3NSAtNS43MTg3NSA1LjkzNzUgLTUuNjA5Mzc1IDUuODc1IC01LjQwNjI1IEMgNS44NTkzNzUgLTUuMzc1IDUuODU5Mzc1IC01LjMyODEyNSA1Ljg1OTM3NSAtNS4zMjgxMjUgTCA0LjgyODEyNSAtMS41MzEyNSBMIDIuNzY1NjI1IC02LjUxNTYyNSBMIDEuMTU2MjUgLTYuNTE1NjI1IEwgMS4xNTYyNSAtNi4zNDM3NSBDIDEuNjI1IC02LjMxMjUgMS44MjgxMjUgLTYuMTg3NSAyLjAxNTYyNSAtNS43OTY4NzUgTCAwLjgyODEyNSAtMS42NDA2MjUgQyAwLjQ1MzEyNSAtMC4zNTkzNzUgMC4zNzUgLTAuMjM0Mzc1IC0wLjIwMzEyNSAtMC4xNTYyNSBMIC0wLjIwMzEyNSAwIEwgMS43ODEyNSAwIEwgMS43ODEyNSAtMC4xNTYyNSBDIDEuMjY1NjI1IC0wLjIwMzEyNSAxLjA3ODEyNSAtMC4zMTI1IDEuMDc4MTI1IC0wLjU5Mzc1IEMgMS4wNzgxMjUgLTAuNzE4NzUgMS4xMDkzNzUgLTAuOTIxODc1IDEuMTcxODc1IC0xLjEyNSBMIDIuMjk2ODc1IC01LjMyODEyNSBMIDQuNTkzNzUgMC4xNTYyNSBMIDQuNzgxMjUgMC4xNTYyNSBMIDYuMjAzMTI1IC00Ljg1OTM3NSBDIDYuNTc4MTI1IC02LjE1NjI1IDYuNjI1IC02LjIwMzEyNSA3LjI1IC02LjM0Mzc1IFogTSA3LjI1IC02LjUxNTYyNSAiLz4KPC9zeW1ib2w+CjwvZz4KPGNsaXBQYXRoIGlkPSJjbGlwMSI+CiAgPHBhdGggZD0iTSAzIDU5IEwgNDIgNTkgTCA0MiA4NyBMIDMgODcgWiBNIDMgNTkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDIiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMiPgogIDxwYXRoIGQ9Ik0gNDAgNTkgTCA2NiA1OSBMIDY2IDg3IEwgNDAgODcgWiBNIDQwIDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0Ij4KICA8cGF0aCBkPSJNIDUuNjk5MjE5IDg2LjQ5NjA5NCBMIDYyLjY0NDUzMSA4Ni40OTYwOTQgQyA2NS4xMDkzNzUgODYuNDk2MDk0IDY1LjEwOTM3NSA3OC42OTE0MDYgNjUuMTA5Mzc1IDcyLjgwMDc4MSBDIDY1LjEwOTM3NSA2Ni45MTAxNTYgNjUuMTA5Mzc1IDU5LjEwNTQ2OSA2Mi42NDQ1MzEgNTkuMTA1NDY5IEwgNS42OTkyMTkgNTkuMTA1NDY5IEMgMy4yMzA0NjkgNTkuMTA1NDY5IDMuMjMwNDY5IDY2LjkxMDE1NiAzLjIzMDQ2OSA3Mi44MDA3ODEgQyAzLjIzMDQ2OSA3OC42OTE0MDYgMy4yMzA0NjkgODYuNDk2MDk0IDUuNjk5MjE5IDg2LjQ5NjA5NCBaIE0gNS42OTkyMTkgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1Ij4KICA8cGF0aCBkPSJNIDQ3IDU5IEwgODcgNTkgTCA4NyA4NyBMIDQ3IDg3IFogTSA0NyA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNiI+CiAgPHBhdGggZD0iTSA1MC4wNzAzMTIgODYuNDk2MDk0IEwgMTMxLjY3MTg3NSA4Ni40OTYwOTQgQyAxMzQuMTM2NzE5IDg2LjQ5NjA5NCAxMzQuMTM2NzE5IDc4LjY5MTQwNiAxMzQuMTM2NzE5IDcyLjgwMDc4MSBDIDEzNC4xMzY3MTkgNjYuOTEwMTU2IDEzNC4xMzY3MTkgNTkuMTA1NDY5IDEzMS42NzE4NzUgNTkuMTA1NDY5IEwgNTAuMDcwMzEyIDU5LjEwNTQ2OSBDIDQ3LjYwNTQ2OSA1OS4xMDU0NjkgNDcuNjA1NDY5IDY2LjkxMDE1NiA0Ny42MDU0NjkgNzIuODAwNzgxIEMgNDcuNjA1NDY5IDc4LjY5MTQwNiA0Ny42MDU0NjkgODYuNDk2MDk0IDUwLjA3MDMxMiA4Ni40OTYwOTQgWiBNIDUwLjA3MDMxMiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDciPgogIDxwYXRoIGQ9Ik0gODUgNTkgTCAxMzUgNTkgTCAxMzUgODcgTCA4NSA4NyBaIE0gODUgNTkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDgiPgogIDxwYXRoIGQ9Ik0gNTAuMDcwMzEyIDg2LjQ5NjA5NCBMIDEzMS42NzE4NzUgODYuNDk2MDk0IEMgMTM0LjEzNjcxOSA4Ni40OTYwOTQgMTM0LjEzNjcxOSA3OC42OTE0MDYgMTM0LjEzNjcxOSA3Mi44MDA3ODEgQyAxMzQuMTM2NzE5IDY2LjkxMDE1NiAxMzQuMTM2NzE5IDU5LjEwNTQ2OSAxMzEuNjcxODc1IDU5LjEwNTQ2OSBMIDUwLjA3MDMxMiA1OS4xMDU0NjkgQyA0Ny42MDU0NjkgNTkuMTA1NDY5IDQ3LjYwNTQ2OSA2Ni45MTAxNTYgNDcuNjA1NDY5IDcyLjgwMDc4MSBDIDQ3LjYwNTQ2OSA3OC42OTE0MDYgNDcuNjA1NDY5IDg2LjQ5NjA5NCA1MC4wNzAzMTIgODYuNDk2MDk0IFogTSA1MC4wNzAzMTIgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA5Ij4KICA8cGF0aCBkPSJNIDEwNSA1OSBMIDE0NSA1OSBMIDE0NSA4NyBMIDEwNSA4NyBaIE0gMTA1IDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMCI+CiAgPHBhdGggZD0iTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCBMIDE2NC45NDkyMTkgODYuNDk2MDk0IEMgMTY3LjQxNDA2MiA4Ni40OTYwOTQgMTY3LjQxNDA2MiA3OC42OTE0MDYgMTY3LjQxNDA2MiA3Mi44MDA3ODEgQyAxNjcuNDE0MDYyIDY2LjkxMDE1NiAxNjcuNDE0MDYyIDU5LjEwNTQ2OSAxNjQuOTQ5MjE5IDU5LjEwNTQ2OSBMIDEwOC4wMDM5MDYgNTkuMTA1NDY5IEMgMTA1LjUzOTA2MiA1OS4xMDU0NjkgMTA1LjUzOTA2MiA2Ni45MTAxNTYgMTA1LjUzOTA2MiA3Mi44MDA3ODEgQyAxMDUuNTM5MDYyIDc4LjY5MTQwNiAxMDUuNTM5MDYyIDg2LjQ5NjA5NCAxMDguMDAzOTA2IDg2LjQ5NjA5NCBaIE0gMTA4LjAwMzkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExIj4KICA8cGF0aCBkPSJNIDE0MyA1OSBMIDE2OCA1OSBMIDE2OCA4NyBMIDE0MyA4NyBaIE0gMTQzIDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMiI+CiAgPHBhdGggZD0iTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCBMIDE2NC45NDkyMTkgODYuNDk2MDk0IEMgMTY3LjQxNDA2MiA4Ni40OTYwOTQgMTY3LjQxNDA2MiA3OC42OTE0MDYgMTY3LjQxNDA2MiA3Mi44MDA3ODEgQyAxNjcuNDE0MDYyIDY2LjkxMDE1NiAxNjcuNDE0MDYyIDU5LjEwNTQ2OSAxNjQuOTQ5MjE5IDU5LjEwNTQ2OSBMIDEwOC4wMDM5MDYgNTkuMTA1NDY5IEMgMTA1LjUzOTA2MiA1OS4xMDU0NjkgMTA1LjUzOTA2MiA2Ni45MTAxNTYgMTA1LjUzOTA2MiA3Mi44MDA3ODEgQyAxMDUuNTM5MDYyIDc4LjY5MTQwNiAxMDUuNTM5MDYyIDg2LjQ5NjA5NCAxMDguMDAzOTA2IDg2LjQ5NjA5NCBaIE0gMTA4LjAwMzkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzIj4KICA8cGF0aCBkPSJNIDE0OSA1OSBMIDE4OSA1OSBMIDE4OSA4NyBMIDE0OSA4NyBaIE0gMTQ5IDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNCI+CiAgPHBhdGggZD0iTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBMIDI0OC43Njk1MzEgODYuNDk2MDk0IEMgMjUxLjIzNDM3NSA4Ni40OTYwOTQgMjUxLjIzNDM3NSA3OC42OTE0MDYgMjUxLjIzNDM3NSA3Mi44MDA3ODEgQyAyNTEuMjM0Mzc1IDY2LjkxMDE1NiAyNTEuMjM0Mzc1IDU5LjEwNTQ2OSAyNDguNzY5NTMxIDU5LjEwNTQ2OSBMIDE1Mi4zNzg5MDYgNTkuMTA1NDY5IEMgMTQ5LjkxNDA2MiA1OS4xMDU0NjkgMTQ5LjkxNDA2MiA2Ni45MTAxNTYgMTQ5LjkxNDA2MiA3Mi44MDA3ODEgQyAxNDkuOTE0MDYyIDc4LjY5MTQwNiAxNDkuOTE0MDYyIDg2LjQ5NjA5NCAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBaIE0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1Ij4KICA8cGF0aCBkPSJNIDE4NyA1OSBMIDI1MiA1OSBMIDI1MiA4NyBMIDE4NyA4NyBaIE0gMTg3IDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNiI+CiAgPHBhdGggZD0iTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBMIDI0OC43Njk1MzEgODYuNDk2MDk0IEMgMjUxLjIzNDM3NSA4Ni40OTYwOTQgMjUxLjIzNDM3NSA3OC42OTE0MDYgMjUxLjIzNDM3NSA3Mi44MDA3ODEgQyAyNTEuMjM0Mzc1IDY2LjkxMDE1NiAyNTEuMjM0Mzc1IDU5LjEwNTQ2OSAyNDguNzY5NTMxIDU5LjEwNTQ2OSBMIDE1Mi4zNzg5MDYgNTkuMTA1NDY5IEMgMTQ5LjkxNDA2MiA1OS4xMDU0NjkgMTQ5LjkxNDA2MiA2Ni45MTAxNTYgMTQ5LjkxNDA2MiA3Mi44MDA3ODEgQyAxNDkuOTE0MDYyIDc4LjY5MTQwNiAxNDkuOTE0MDYyIDg2LjQ5NjA5NCAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBaIE0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE3Ij4KICA8cGF0aCBkPSJNIDI1MiA1OSBMIDMxMCA1OSBMIDMxMCA4NyBMIDI1MiA4NyBaIE0gMjUyIDU5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOCI+CiAgPHBhdGggZD0iTSAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBMIDMwNi42OTkyMTkgODYuNDk2MDk0IEMgMzA5LjE2NDA2MiA4Ni40OTYwOTQgMzA5LjE2NDA2MiA3OC42OTE0MDYgMzA5LjE2NDA2MiA3Mi44MDA3ODEgQyAzMDkuMTY0MDYyIDY2LjkxMDE1NiAzMDkuMTY0MDYyIDU5LjEwNTQ2OSAzMDYuNjk5MjE5IDU5LjEwNTQ2OSBMIDI1NC42ODM1OTQgNTkuMTA1NDY5IEMgMjUyLjIxODc1IDU5LjEwNTQ2OSAyNTIuMjE4NzUgNjYuOTEwMTU2IDI1Mi4yMTg3NSA3Mi44MDA3ODEgQyAyNTIuMjE4NzUgNzguNjkxNDA2IDI1Mi4yMTg3NSA4Ni40OTYwOTQgMjU0LjY4MzU5NCA4Ni40OTYwOTQgWiBNIDI1NC42ODM1OTQgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxOSI+CiAgPHBhdGggZD0iTSAzMTAgNTkgTCAzNjggNTkgTCAzNjggODcgTCAzMTAgODcgWiBNIDMxMCA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjAiPgogIDxwYXRoIGQ9Ik0gMzEyLjYxNzE4OCA4Ni40OTYwOTQgTCAzNjQuNjMyODEyIDg2LjQ5NjA5NCBDIDM2Ny4wOTc2NTYgODYuNDk2MDk0IDM2Ny4wOTc2NTYgNzguNjkxNDA2IDM2Ny4wOTc2NTYgNzIuODAwNzgxIEMgMzY3LjA5NzY1NiA2Ni45MTAxNTYgMzY3LjA5NzY1NiA1OS4xMDU0NjkgMzY0LjYzMjgxMiA1OS4xMDU0NjkgTCAzMTIuNjE3MTg4IDU5LjEwNTQ2OSBDIDMxMC4xNTIzNDQgNTkuMTA1NDY5IDMxMC4xNTIzNDQgNjYuOTEwMTU2IDMxMC4xNTIzNDQgNzIuODAwNzgxIEMgMzEwLjE1MjM0NCA3OC42OTE0MDYgMzEwLjE1MjM0NCA4Ni40OTYwOTQgMzEyLjYxNzE4OCA4Ni40OTYwOTQgWiBNIDMxMi42MTcxODggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyMSI+CiAgPHBhdGggZD0iTSAzODcgNTkgTCA0NDUgNTkgTCA0NDUgODcgTCAzODcgODcgWiBNIDM4NyA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjIiPgogIDxwYXRoIGQ9Ik0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgTCA0NDIuMjg5MDYyIDg2LjQ5NjA5NCBDIDQ0NC43NTM5MDYgODYuNDk2MDk0IDQ0NC43NTM5MDYgNzguNjkxNDA2IDQ0NC43NTM5MDYgNzIuODAwNzgxIEMgNDQ0Ljc1MzkwNiA2Ni45MTAxNTYgNDQ0Ljc1MzkwNiA1OS4xMDU0NjkgNDQyLjI4OTA2MiA1OS4xMDU0NjkgTCAzOTAuMjY5NTMxIDU5LjEwNTQ2OSBDIDM4Ny44MDQ2ODggNTkuMTA1NDY5IDM4Ny44MDQ2ODggNjYuOTEwMTU2IDM4Ny44MDQ2ODggNzIuODAwNzgxIEMgMzg3LjgwNDY4OCA3OC42OTE0MDYgMzg3LjgwNDY4OCA4Ni40OTYwOTQgMzkwLjI2OTUzMSA4Ni40OTYwOTQgWiBNIDM5MC4yNjk1MzEgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyMyI+CiAgPHBhdGggZD0iTSA0NDUgNTkgTCA1MDMgNTkgTCA1MDMgODcgTCA0NDUgODcgWiBNIDQ0NSA1OSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjQiPgogIDxwYXRoIGQ9Ik0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgTCA1MDAuMjE4NzUgODYuNDk2MDk0IEMgNTAyLjY4MzU5NCA4Ni40OTYwOTQgNTAyLjY4MzU5NCA3OC42OTE0MDYgNTAyLjY4MzU5NCA3Mi44MDA3ODEgQyA1MDIuNjgzNTk0IDY2LjkxMDE1NiA1MDIuNjgzNTk0IDU5LjEwNTQ2OSA1MDAuMjE4NzUgNTkuMTA1NDY5IEwgNDQ4LjIwMzEyNSA1OS4xMDU0NjkgQyA0NDUuNzM4MjgxIDU5LjEwNTQ2OSA0NDUuNzM4MjgxIDY2LjkxMDE1NiA0NDUuNzM4MjgxIDcyLjgwMDc4MSBDIDQ0NS43MzgyODEgNzguNjkxNDA2IDQ0NS43MzgyODEgODYuNDk2MDk0IDQ0OC4yMDMxMjUgODYuNDk2MDk0IFogTSA0NDguMjAzMTI1IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMjUiPgogIDxwYXRoIGQ9Ik0gMTQ5IDg2IEwgNDk4IDg2IEwgNDk4IDEyMC4xMDkzNzUgTCAxNDkgMTIwLjEwOTM3NSBaIE0gMTQ5IDg2ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyNiI+CiAgPHBhdGggZD0iTSAxMCA1MCBMIDExNS43MzQzNzUgNTAgTCAxMTUuNzM0Mzc1IDUyIEwgMTAgNTIgWiBNIDEzOC43MzA0NjkgNTAgTCAyNDQgNTAgTCAyNDQgNTIgTCAxMzguNzMwNDY5IDUyIFogTSAxMzguNzMwNDY5IDUwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyNyI+CiAgPHBhdGggZD0iTSAyNDMgNDkgTCAyNTEuNzI2NTYyIDQ5IEwgMjUxLjcyNjU2MiA1NCBMIDI0MyA1NCBaIE0gMjQzIDQ5ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyOCI+CiAgPHBhdGggZD0iTSAyNDMgNDggTCAyNTEuNzI2NTYyIDQ4IEwgMjUxLjcyNjU2MiA1NCBMIDI0MyA1NCBaIE0gMjQzIDQ4ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAyOSI+CiAgPHBhdGggZD0iTSAyLjczODI4MSA0OCBMIDExIDQ4IEwgMTEgNTQgTCAyLjczODI4MSA1NCBaIE0gMi43MzgyODEgNDggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMwIj4KICA8cGF0aCBkPSJNIDIuNzM4MjgxIDQ3IEwgNCA0NyBMIDQgNTYgTCAyLjczODI4MSA1NiBaIE0gMi43MzgyODEgNDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMxIj4KICA8cGF0aCBkPSJNIDI1MCA0NyBMIDI1MS43MjY1NjIgNDcgTCAyNTEuNzI2NTYyIDU2IEwgMjUwIDU2IFogTSAyNTAgNDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMyIj4KICA8cGF0aCBkPSJNIDU0IDM5IEwgMTM3LjkyMTg3NSAzOSBMIDEzNy45MjE4NzUgNDEgTCA1NCA0MSBaIE0gMTYwLjkxNzk2OSAzOSBMIDI0NCAzOSBMIDI0NCA0MSBMIDE2MC45MTc5NjkgNDEgWiBNIDE2MC45MTc5NjkgMzkgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDMzIj4KICA8cGF0aCBkPSJNIDI0MyAzOCBMIDI1MS43MjY1NjIgMzggTCAyNTEuNzI2NTYyIDQzIEwgMjQzIDQzIFogTSAyNDMgMzggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM0Ij4KICA8cGF0aCBkPSJNIDI0MyAzNyBMIDI1MS43MjY1NjIgMzcgTCAyNTEuNzI2NTYyIDQzIEwgMjQzIDQzIFogTSAyNDMgMzcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM1Ij4KICA8cGF0aCBkPSJNIDQ3LjExMzI4MSAzOCBMIDU2IDM4IEwgNTYgNDMgTCA0Ny4xMTMyODEgNDMgWiBNIDQ3LjExMzI4MSAzOCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMzYiPgogIDxwYXRoIGQ9Ik0gNDcuMTEzMjgxIDM3IEwgNTYgMzcgTCA1NiA0MyBMIDQ3LjExMzI4MSA0MyBaIE0gNDcuMTEzMjgxIDM3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAzNyI+CiAgPHBhdGggZD0iTSA0Ny4xMTMyODEgMzYgTCA0OCAzNiBMIDQ4IDQ1IEwgNDcuMTEzMjgxIDQ1IFogTSA0Ny4xMTMyODEgMzYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM4Ij4KICA8cGF0aCBkPSJNIDI1MCAzNiBMIDI1MS43MjY1NjIgMzYgTCAyNTEuNzI2NTYyIDQ1IEwgMjUwIDQ1IFogTSAyNTAgMzYgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDM5Ij4KICA8cGF0aCBkPSJNIDExMiAxNyBMIDE1OC4zMTI1IDE3IEwgMTU4LjMxMjUgMTkgTCAxMTIgMTkgWiBNIDE5OC40NjA5MzggMTcgTCAyNDQgMTcgTCAyNDQgMTkgTCAxOTguNDYwOTM4IDE5IFogTSAxOTguNDYwOTM4IDE3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0MCI+CiAgPHBhdGggZD0iTSAyNDMgMTYgTCAyNTEuNzI2NTYyIDE2IEwgMjUxLjcyNjU2MiAyMSBMIDI0MyAyMSBaIE0gMjQzIDE2ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0MSI+CiAgPHBhdGggZD0iTSAyNDMgMTUgTCAyNTEuNzI2NTYyIDE1IEwgMjUxLjcyNjU2MiAyMSBMIDI0MyAyMSBaIE0gMjQzIDE1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0MiI+CiAgPHBhdGggZD0iTSAxMDUuMDQ2ODc1IDE2IEwgMTE0IDE2IEwgMTE0IDIxIEwgMTA1LjA0Njg3NSAyMSBaIE0gMTA1LjA0Njg3NSAxNiAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNDMiPgogIDxwYXRoIGQ9Ik0gMTA1LjA0Njg3NSAxNSBMIDExNCAxNSBMIDExNCAyMSBMIDEwNS4wNDY4NzUgMjEgWiBNIDEwNS4wNDY4NzUgMTUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ0Ij4KICA8cGF0aCBkPSJNIDEwNS4wNDY4NzUgMTQgTCAxMDYgMTQgTCAxMDYgMjMgTCAxMDUuMDQ2ODc1IDIzIFogTSAxMDUuMDQ2ODc1IDE0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NSI+CiAgPHBhdGggZD0iTSAyNTAgMTQgTCAyNTEuNzI2NTYyIDE0IEwgMjUxLjcyNjU2MiAyMyBMIDI1MCAyMyBaIE0gMjUwIDE0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0NiI+CiAgPHBhdGggZD0iTSAxNTcgNyBMIDE4Ny45ODQzNzUgNyBMIDE4Ny45ODQzNzUgOCBMIDE1NyA4IFogTSAyMTMuMTY0MDYyIDcgTCAyNDQgNyBMIDI0NCA4IEwgMjEzLjE2NDA2MiA4IFogTSAyMTMuMTY0MDYyIDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ3Ij4KICA8cGF0aCBkPSJNIDI0MyA1IEwgMjUxLjcyNjU2MiA1IEwgMjUxLjcyNjU2MiAxMCBMIDI0MyAxMCBaIE0gMjQzIDUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDQ4Ij4KICA8cGF0aCBkPSJNIDE0OS40MjE4NzUgNSBMIDE1OCA1IEwgMTU4IDEwIEwgMTQ5LjQyMTg3NSAxMCBaIE0gMTQ5LjQyMTg3NSA1ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA0OSI+CiAgPHBhdGggZD0iTSAxNDkuNDIxODc1IDMgTCAxNTEgMyBMIDE1MSAxMiBMIDE0OS40MjE4NzUgMTIgWiBNIDE0OS40MjE4NzUgMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTAiPgogIDxwYXRoIGQ9Ik0gMjUwIDMgTCAyNTEuNzI2NTYyIDMgTCAyNTEuNzI2NTYyIDEyIEwgMjUwIDEyIFogTSAyNTAgMyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTEiPgogIDxwYXRoIGQ9Ik0gMjU5IDUwIEwgMzQ0LjAzOTA2MiA1MCBMIDM0NC4wMzkwNjIgNTIgTCAyNTkgNTIgWiBNIDQxMC44NjMyODEgNTAgTCA0OTYgNTAgTCA0OTYgNTIgTCA0MTAuODYzMjgxIDUyIFogTSA0MTAuODYzMjgxIDUwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA1MiI+CiAgPHBhdGggZD0iTSAyNTEuNzI2NTYyIDQ4IEwgMjYwIDQ4IEwgMjYwIDU0IEwgMjUxLjcyNjU2MiA1NCBaIE0gMjUxLjcyNjU2MiA0OCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTMiPgogIDxwYXRoIGQ9Ik0gMjUxLjcyNjU2MiA0NyBMIDI1MyA0NyBMIDI1MyA1NiBMIDI1MS43MjY1NjIgNTYgWiBNIDI1MS43MjY1NjIgNDcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU0Ij4KICA8cGF0aCBkPSJNIDIwIDc1IEwgMjYgNzUgTCAyNiA4MiBMIDIwIDgyIFogTSAyMCA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTUiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU2Ij4KICA8cGF0aCBkPSJNIDExIDY0IEwgMTggNjQgTCAxOCA3MSBMIDExIDcxIFogTSAxMSA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTciPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDU4Ij4KICA8cGF0aCBkPSJNIDE3IDY0IEwgMjQgNjQgTCAyNCA3MSBMIDE3IDcxIFogTSAxNyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNTkiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDYwIj4KICA8cGF0aCBkPSJNIDIzIDY0IEwgMzEgNjQgTCAzMSA3MSBMIDIzIDcxIFogTSAyMyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjEiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDYyIj4KICA8cGF0aCBkPSJNIDMxIDY3IEwgMzQgNjcgTCAzNCA3MyBMIDMxIDczIFogTSAzMSA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjMiPgogIDxwYXRoIGQ9Ik0gNS42OTkyMTkgODYuNDk2MDk0IEwgNjIuNjQ0NTMxIDg2LjQ5NjA5NCBDIDY1LjEwOTM3NSA4Ni40OTYwOTQgNjUuMTA5Mzc1IDc4LjY5MTQwNiA2NS4xMDkzNzUgNzIuODAwNzgxIEMgNjUuMTA5Mzc1IDY2LjkxMDE1NiA2NS4xMDkzNzUgNTkuMTA1NDY5IDYyLjY0NDUzMSA1OS4xMDU0NjkgTCA1LjY5OTIxOSA1OS4xMDU0NjkgQyAzLjIzMDQ2OSA1OS4xMDU0NjkgMy4yMzA0NjkgNjYuOTEwMTU2IDMuMjMwNDY5IDcyLjgwMDc4MSBDIDMuMjMwNDY5IDc4LjY5MTQwNiAzLjIzMDQ2OSA4Ni40OTYwOTQgNS42OTkyMTkgODYuNDk2MDk0IFogTSA1LjY5OTIxOSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY0Ij4KICA8cGF0aCBkPSJNIDY1IDc1IEwgNzEgNzUgTCA3MSA4MiBMIDY1IDgyIFogTSA2NSA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjUiPgogIDxwYXRoIGQ9Ik0gNTAuMDcwMzEyIDg2LjQ5NjA5NCBMIDEzMS42NzE4NzUgODYuNDk2MDk0IEMgMTM0LjEzNjcxOSA4Ni40OTYwOTQgMTM0LjEzNjcxOSA3OC42OTE0MDYgMTM0LjEzNjcxOSA3Mi44MDA3ODEgQyAxMzQuMTM2NzE5IDY2LjkxMDE1NiAxMzQuMTM2NzE5IDU5LjEwNTQ2OSAxMzEuNjcxODc1IDU5LjEwNTQ2OSBMIDUwLjA3MDMxMiA1OS4xMDU0NjkgQyA0Ny42MDU0NjkgNTkuMTA1NDY5IDQ3LjYwNTQ2OSA2Ni45MTAxNTYgNDcuNjA1NDY5IDcyLjgwMDc4MSBDIDQ3LjYwNTQ2OSA3OC42OTE0MDYgNDcuNjA1NDY5IDg2LjQ5NjA5NCA1MC4wNzAzMTIgODYuNDk2MDk0IFogTSA1MC4wNzAzMTIgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2NiI+CiAgPHBhdGggZD0iTSA1NiA2NCBMIDYyIDY0IEwgNjIgNzEgTCA1NiA3MSBaIE0gNTYgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDY3Ij4KICA8cGF0aCBkPSJNIDUwLjA3MDMxMiA4Ni40OTYwOTQgTCAxMzEuNjcxODc1IDg2LjQ5NjA5NCBDIDEzNC4xMzY3MTkgODYuNDk2MDk0IDEzNC4xMzY3MTkgNzguNjkxNDA2IDEzNC4xMzY3MTkgNzIuODAwNzgxIEMgMTM0LjEzNjcxOSA2Ni45MTAxNTYgMTM0LjEzNjcxOSA1OS4xMDU0NjkgMTMxLjY3MTg3NSA1OS4xMDU0NjkgTCA1MC4wNzAzMTIgNTkuMTA1NDY5IEMgNDcuNjA1NDY5IDU5LjEwNTQ2OSA0Ny42MDU0NjkgNjYuOTEwMTU2IDQ3LjYwNTQ2OSA3Mi44MDA3ODEgQyA0Ny42MDU0NjkgNzguNjkxNDA2IDQ3LjYwNTQ2OSA4Ni40OTYwOTQgNTAuMDcwMzEyIDg2LjQ5NjA5NCBaIE0gNTAuMDcwMzEyIDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNjgiPgogIDxwYXRoIGQ9Ik0gNjIgNjQgTCA2OCA2NCBMIDY4IDcxIEwgNjIgNzEgWiBNIDYyIDY0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA2OSI+CiAgPHBhdGggZD0iTSA1MC4wNzAzMTIgODYuNDk2MDk0IEwgMTMxLjY3MTg3NSA4Ni40OTYwOTQgQyAxMzQuMTM2NzE5IDg2LjQ5NjA5NCAxMzQuMTM2NzE5IDc4LjY5MTQwNiAxMzQuMTM2NzE5IDcyLjgwMDc4MSBDIDEzNC4xMzY3MTkgNjYuOTEwMTU2IDEzNC4xMzY3MTkgNTkuMTA1NDY5IDEzMS42NzE4NzUgNTkuMTA1NDY5IEwgNTAuMDcwMzEyIDU5LjEwNTQ2OSBDIDQ3LjYwNTQ2OSA1OS4xMDU0NjkgNDcuNjA1NDY5IDY2LjkxMDE1NiA0Ny42MDU0NjkgNzIuODAwNzgxIEMgNDcuNjA1NDY5IDc4LjY5MTQwNiA0Ny42MDU0NjkgODYuNDk2MDk0IDUwLjA3MDMxMiA4Ni40OTYwOTQgWiBNIDUwLjA3MDMxMiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDcwIj4KICA8cGF0aCBkPSJNIDY3IDY0IEwgNzUgNjQgTCA3NSA3MSBMIDY3IDcxIFogTSA2NyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzEiPgogIDxwYXRoIGQ9Ik0gNTAuMDcwMzEyIDg2LjQ5NjA5NCBMIDEzMS42NzE4NzUgODYuNDk2MDk0IEMgMTM0LjEzNjcxOSA4Ni40OTYwOTQgMTM0LjEzNjcxOSA3OC42OTE0MDYgMTM0LjEzNjcxOSA3Mi44MDA3ODEgQyAxMzQuMTM2NzE5IDY2LjkxMDE1NiAxMzQuMTM2NzE5IDU5LjEwNTQ2OSAxMzEuNjcxODc1IDU5LjEwNTQ2OSBMIDUwLjA3MDMxMiA1OS4xMDU0NjkgQyA0Ny42MDU0NjkgNTkuMTA1NDY5IDQ3LjYwNTQ2OSA2Ni45MTAxNTYgNDcuNjA1NDY5IDcyLjgwMDc4MSBDIDQ3LjYwNTQ2OSA3OC42OTE0MDYgNDcuNjA1NDY5IDg2LjQ5NjA5NCA1MC4wNzAzMTIgODYuNDk2MDk0IFogTSA1MC4wNzAzMTIgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXA3MiI+CiAgPHBhdGggZD0iTSA3NCA2NyBMIDc5IDY3IEwgNzkgNzMgTCA3NCA3MyBaIE0gNzQgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDczIj4KICA8cGF0aCBkPSJNIDUwLjA3MDMxMiA4Ni40OTYwOTQgTCAxMzEuNjcxODc1IDg2LjQ5NjA5NCBDIDEzNC4xMzY3MTkgODYuNDk2MDk0IDEzNC4xMzY3MTkgNzguNjkxNDA2IDEzNC4xMzY3MTkgNzIuODAwNzgxIEMgMTM0LjEzNjcxOSA2Ni45MTAxNTYgMTM0LjEzNjcxOSA1OS4xMDU0NjkgMTMxLjY3MTg3NSA1OS4xMDU0NjkgTCA1MC4wNzAzMTIgNTkuMTA1NDY5IEMgNDcuNjA1NDY5IDU5LjEwNTQ2OSA0Ny42MDU0NjkgNjYuOTEwMTU2IDQ3LjYwNTQ2OSA3Mi44MDA3ODEgQyA0Ny42MDU0NjkgNzguNjkxNDA2IDQ3LjYwNTQ2OSA4Ni40OTYwOTQgNTAuMDcwMzEyIDg2LjQ5NjA5NCBaIE0gNTAuMDcwMzEyIDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzQiPgogIDxwYXRoIGQ9Ik0gMTIyIDc1IEwgMTI5IDc1IEwgMTI5IDgyIEwgMTIyIDgyIFogTSAxMjIgNzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDc1Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzYiPgogIDxwYXRoIGQ9Ik0gMTA4IDY0IEwgMTE1IDY0IEwgMTE1IDcxIEwgMTA4IDcxIFogTSAxMDggNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDc3Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwNzgiPgogIDxwYXRoIGQ9Ik0gMTE0IDY0IEwgMTIwIDY0IEwgMTIwIDcxIEwgMTE0IDcxIFogTSAxMTQgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDc5Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODAiPgogIDxwYXRoIGQ9Ik0gMTIwIDY0IEwgMTI3IDY0IEwgMTI3IDcxIEwgMTIwIDcxIFogTSAxMjAgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDgxIj4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODIiPgogIDxwYXRoIGQ9Ik0gMTI3IDY3IEwgMTMzIDY3IEwgMTMzIDczIEwgMTI3IDczIFogTSAxMjcgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDgzIj4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODQiPgogIDxwYXRoIGQ9Ik0gMTMzIDcwIEwgMTM4IDcwIEwgMTM4IDcxIEwgMTMzIDcxIFogTSAxMzMgNzAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDg1Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODYiPgogIDxwYXRoIGQ9Ik0gMTM5IDY3IEwgMTQyIDY3IEwgMTQyIDczIEwgMTM5IDczIFogTSAxMzkgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDg3Ij4KICA8cGF0aCBkPSJNIDEwOC4wMDM5MDYgODYuNDk2MDk0IEwgMTY0Ljk0OTIxOSA4Ni40OTYwOTQgQyAxNjcuNDE0MDYyIDg2LjQ5NjA5NCAxNjcuNDE0MDYyIDc4LjY5MTQwNiAxNjcuNDE0MDYyIDcyLjgwMDc4MSBDIDE2Ny40MTQwNjIgNjYuOTEwMTU2IDE2Ny40MTQwNjIgNTkuMTA1NDY5IDE2NC45NDkyMTkgNTkuMTA1NDY5IEwgMTA4LjAwMzkwNiA1OS4xMDU0NjkgQyAxMDUuNTM5MDYyIDU5LjEwNTQ2OSAxMDUuNTM5MDYyIDY2LjkxMDE1NiAxMDUuNTM5MDYyIDcyLjgwMDc4MSBDIDEwNS41MzkwNjIgNzguNjkxNDA2IDEwNS41MzkwNjIgODYuNDk2MDk0IDEwOC4wMDM5MDYgODYuNDk2MDk0IFogTSAxMDguMDAzOTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwODgiPgogIDxwYXRoIGQ9Ik0gMTY3IDc1IEwgMTczIDc1IEwgMTczIDgyIEwgMTY3IDgyIFogTSAxNjcgNzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDg5Ij4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTAiPgogIDxwYXRoIGQ9Ik0gMTU3IDY0IEwgMTY0IDY0IEwgMTY0IDcxIEwgMTU3IDcxIFogTSAxNTcgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDkxIj4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTIiPgogIDxwYXRoIGQ9Ik0gMTYzIDY0IEwgMTY5IDY0IEwgMTY5IDcxIEwgMTYzIDcxIFogTSAxNjMgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDkzIj4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTQiPgogIDxwYXRoIGQ9Ik0gMTY5IDY0IEwgMTc3IDY0IEwgMTc3IDcxIEwgMTY5IDcxIFogTSAxNjkgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDk1Ij4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTYiPgogIDxwYXRoIGQ9Ik0gMTc2IDY3IEwgMTgyIDY3IEwgMTgyIDczIEwgMTc2IDczIFogTSAxNzYgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDk3Ij4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwOTgiPgogIDxwYXRoIGQ9Ik0gMjA2IDY4IEwgMjEyIDY4IEwgMjEyIDc2IEwgMjA2IDc2IFogTSAyMDYgNjggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDk5Ij4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTAwIj4KICA8cGF0aCBkPSJNIDIxMSA3MCBMIDIxNiA3MCBMIDIxNiA3NiBMIDIxMSA3NiBaIE0gMjExIDcwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDEiPgogIDxwYXRoIGQ9Ik0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgTCAyNDguNzY5NTMxIDg2LjQ5NjA5NCBDIDI1MS4yMzQzNzUgODYuNDk2MDk0IDI1MS4yMzQzNzUgNzguNjkxNDA2IDI1MS4yMzQzNzUgNzIuODAwNzgxIEMgMjUxLjIzNDM3NSA2Ni45MTAxNTYgMjUxLjIzNDM3NSA1OS4xMDU0NjkgMjQ4Ljc2OTUzMSA1OS4xMDU0NjkgTCAxNTIuMzc4OTA2IDU5LjEwNTQ2OSBDIDE0OS45MTQwNjIgNTkuMTA1NDY5IDE0OS45MTQwNjIgNjYuOTEwMTU2IDE0OS45MTQwNjIgNzIuODAwNzgxIEMgMTQ5LjkxNDA2MiA3OC42OTE0MDYgMTQ5LjkxNDA2MiA4Ni40OTYwOTQgMTUyLjM3ODkwNiA4Ni40OTYwOTQgWiBNIDE1Mi4zNzg5MDYgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDIiPgogIDxwYXRoIGQ9Ik0gMjE1IDcwIEwgMjE5IDcwIEwgMjE5IDc2IEwgMjE1IDc2IFogTSAyMTUgNzAgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwMyI+CiAgPHBhdGggZD0iTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBMIDI0OC43Njk1MzEgODYuNDk2MDk0IEMgMjUxLjIzNDM3NSA4Ni40OTYwOTQgMjUxLjIzNDM3NSA3OC42OTE0MDYgMjUxLjIzNDM3NSA3Mi44MDA3ODEgQyAyNTEuMjM0Mzc1IDY2LjkxMDE1NiAyNTEuMjM0Mzc1IDU5LjEwNTQ2OSAyNDguNzY5NTMxIDU5LjEwNTQ2OSBMIDE1Mi4zNzg5MDYgNTkuMTA1NDY5IEMgMTQ5LjkxNDA2MiA1OS4xMDU0NjkgMTQ5LjkxNDA2MiA2Ni45MTAxNTYgMTQ5LjkxNDA2MiA3Mi44MDA3ODEgQyAxNDkuOTE0MDYyIDc4LjY5MTQwNiAxNDkuOTE0MDYyIDg2LjQ5NjA5NCAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBaIE0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwNCI+CiAgPHBhdGggZD0iTSAyMTggNzAgTCAyMjQgNzAgTCAyMjQgNzYgTCAyMTggNzYgWiBNIDIxOCA3MCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTA1Ij4KICA8cGF0aCBkPSJNIDE1Mi4zNzg5MDYgODYuNDk2MDk0IEwgMjQ4Ljc2OTUzMSA4Ni40OTYwOTQgQyAyNTEuMjM0Mzc1IDg2LjQ5NjA5NCAyNTEuMjM0Mzc1IDc4LjY5MTQwNiAyNTEuMjM0Mzc1IDcyLjgwMDc4MSBDIDI1MS4yMzQzNzUgNjYuOTEwMTU2IDI1MS4yMzQzNzUgNTkuMTA1NDY5IDI0OC43Njk1MzEgNTkuMTA1NDY5IEwgMTUyLjM3ODkwNiA1OS4xMDU0NjkgQyAxNDkuOTE0MDYyIDU5LjEwNTQ2OSAxNDkuOTE0MDYyIDY2LjkxMDE1NiAxNDkuOTE0MDYyIDcyLjgwMDc4MSBDIDE0OS45MTQwNjIgNzguNjkxNDA2IDE0OS45MTQwNjIgODYuNDk2MDk0IDE1Mi4zNzg5MDYgODYuNDk2MDk0IFogTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTA2Ij4KICA8cGF0aCBkPSJNIDIyNCA3MCBMIDIyOSA3MCBMIDIyOSA3NiBMIDIyNCA3NiBaIE0gMjI0IDcwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDciPgogIDxwYXRoIGQ9Ik0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgTCAyNDguNzY5NTMxIDg2LjQ5NjA5NCBDIDI1MS4yMzQzNzUgODYuNDk2MDk0IDI1MS4yMzQzNzUgNzguNjkxNDA2IDI1MS4yMzQzNzUgNzIuODAwNzgxIEMgMjUxLjIzNDM3NSA2Ni45MTAxNTYgMjUxLjIzNDM3NSA1OS4xMDU0NjkgMjQ4Ljc2OTUzMSA1OS4xMDU0NjkgTCAxNTIuMzc4OTA2IDU5LjEwNTQ2OSBDIDE0OS45MTQwNjIgNTkuMTA1NDY5IDE0OS45MTQwNjIgNjYuOTEwMTU2IDE0OS45MTQwNjIgNzIuODAwNzgxIEMgMTQ5LjkxNDA2MiA3OC42OTE0MDYgMTQ5LjkxNDA2MiA4Ni40OTYwOTQgMTUyLjM3ODkwNiA4Ni40OTYwOTQgWiBNIDE1Mi4zNzg5MDYgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMDgiPgogIDxwYXRoIGQ9Ik0gMjI4IDY4IEwgMjMxIDY4IEwgMjMxIDc2IEwgMjI4IDc2IFogTSAyMjggNjggIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEwOSI+CiAgPHBhdGggZD0iTSAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBMIDI0OC43Njk1MzEgODYuNDk2MDk0IEMgMjUxLjIzNDM3NSA4Ni40OTYwOTQgMjUxLjIzNDM3NSA3OC42OTE0MDYgMjUxLjIzNDM3NSA3Mi44MDA3ODEgQyAyNTEuMjM0Mzc1IDY2LjkxMDE1NiAyNTEuMjM0Mzc1IDU5LjEwNTQ2OSAyNDguNzY5NTMxIDU5LjEwNTQ2OSBMIDE1Mi4zNzg5MDYgNTkuMTA1NDY5IEMgMTQ5LjkxNDA2MiA1OS4xMDU0NjkgMTQ5LjkxNDA2MiA2Ni45MTAxNTYgMTQ5LjkxNDA2MiA3Mi44MDA3ODEgQyAxNDkuOTE0MDYyIDc4LjY5MTQwNiAxNDkuOTE0MDYyIDg2LjQ5NjA5NCAxNTIuMzc4OTA2IDg2LjQ5NjA5NCBaIE0gMTUyLjM3ODkwNiA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExMCI+CiAgPHBhdGggZD0iTSAyNzkgNzUgTCAyODUgNzUgTCAyODUgODIgTCAyNzkgODIgWiBNIDI3OSA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTExIj4KICA8cGF0aCBkPSJNIDI1NC42ODM1OTQgODYuNDk2MDk0IEwgMzA2LjY5OTIxOSA4Ni40OTYwOTQgQyAzMDkuMTY0MDYyIDg2LjQ5NjA5NCAzMDkuMTY0MDYyIDc4LjY5MTQwNiAzMDkuMTY0MDYyIDcyLjgwMDc4MSBDIDMwOS4xNjQwNjIgNjYuOTEwMTU2IDMwOS4xNjQwNjIgNTkuMTA1NDY5IDMwNi42OTkyMTkgNTkuMTA1NDY5IEwgMjU0LjY4MzU5NCA1OS4xMDU0NjkgQyAyNTIuMjE4NzUgNTkuMTA1NDY5IDI1Mi4yMTg3NSA2Ni45MTAxNTYgMjUyLjIxODc1IDcyLjgwMDc4MSBDIDI1Mi4yMTg3NSA3OC42OTE0MDYgMjUyLjIxODc1IDg2LjQ5NjA5NCAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBaIE0gMjU0LjY4MzU5NCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExMiI+CiAgPHBhdGggZD0iTSAyNjkgNjMgTCAyNzYgNjMgTCAyNzYgNzEgTCAyNjkgNzEgWiBNIDI2OSA2MyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTEzIj4KICA8cGF0aCBkPSJNIDI1NC42ODM1OTQgODYuNDk2MDk0IEwgMzA2LjY5OTIxOSA4Ni40OTYwOTQgQyAzMDkuMTY0MDYyIDg2LjQ5NjA5NCAzMDkuMTY0MDYyIDc4LjY5MTQwNiAzMDkuMTY0MDYyIDcyLjgwMDc4MSBDIDMwOS4xNjQwNjIgNjYuOTEwMTU2IDMwOS4xNjQwNjIgNTkuMTA1NDY5IDMwNi42OTkyMTkgNTkuMTA1NDY5IEwgMjU0LjY4MzU5NCA1OS4xMDU0NjkgQyAyNTIuMjE4NzUgNTkuMTA1NDY5IDI1Mi4yMTg3NSA2Ni45MTAxNTYgMjUyLjIxODc1IDcyLjgwMDc4MSBDIDI1Mi4yMTg3NSA3OC42OTE0MDYgMjUyLjIxODc1IDg2LjQ5NjA5NCAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBaIE0gMjU0LjY4MzU5NCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExNCI+CiAgPHBhdGggZD0iTSAyNzYgNjQgTCAyODMgNjQgTCAyODMgNzEgTCAyNzYgNzEgWiBNIDI3NiA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTE1Ij4KICA8cGF0aCBkPSJNIDI1NC42ODM1OTQgODYuNDk2MDk0IEwgMzA2LjY5OTIxOSA4Ni40OTYwOTQgQyAzMDkuMTY0MDYyIDg2LjQ5NjA5NCAzMDkuMTY0MDYyIDc4LjY5MTQwNiAzMDkuMTY0MDYyIDcyLjgwMDc4MSBDIDMwOS4xNjQwNjIgNjYuOTEwMTU2IDMwOS4xNjQwNjIgNTkuMTA1NDY5IDMwNi42OTkyMTkgNTkuMTA1NDY5IEwgMjU0LjY4MzU5NCA1OS4xMDU0NjkgQyAyNTIuMjE4NzUgNTkuMTA1NDY5IDI1Mi4yMTg3NSA2Ni45MTAxNTYgMjUyLjIxODc1IDcyLjgwMDc4MSBDIDI1Mi4yMTg3NSA3OC42OTE0MDYgMjUyLjIxODc1IDg2LjQ5NjA5NCAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBaIE0gMjU0LjY4MzU5NCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExNiI+CiAgPHBhdGggZD0iTSAyODMgNjQgTCAyOTEgNjQgTCAyOTEgNzEgTCAyODMgNzEgWiBNIDI4MyA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTE3Ij4KICA8cGF0aCBkPSJNIDI1NC42ODM1OTQgODYuNDk2MDk0IEwgMzA2LjY5OTIxOSA4Ni40OTYwOTQgQyAzMDkuMTY0MDYyIDg2LjQ5NjA5NCAzMDkuMTY0MDYyIDc4LjY5MTQwNiAzMDkuMTY0MDYyIDcyLjgwMDc4MSBDIDMwOS4xNjQwNjIgNjYuOTEwMTU2IDMwOS4xNjQwNjIgNTkuMTA1NDY5IDMwNi42OTkyMTkgNTkuMTA1NDY5IEwgMjU0LjY4MzU5NCA1OS4xMDU0NjkgQyAyNTIuMjE4NzUgNTkuMTA1NDY5IDI1Mi4yMTg3NSA2Ni45MTAxNTYgMjUyLjIxODc1IDcyLjgwMDc4MSBDIDI1Mi4yMTg3NSA3OC42OTE0MDYgMjUyLjIxODc1IDg2LjQ5NjA5NCAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBaIE0gMjU0LjY4MzU5NCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDExOCI+CiAgPHBhdGggZD0iTSAyOTEgNjcgTCAyOTQgNjcgTCAyOTQgNzMgTCAyOTEgNzMgWiBNIDI5MSA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTE5Ij4KICA8cGF0aCBkPSJNIDI1NC42ODM1OTQgODYuNDk2MDk0IEwgMzA2LjY5OTIxOSA4Ni40OTYwOTQgQyAzMDkuMTY0MDYyIDg2LjQ5NjA5NCAzMDkuMTY0MDYyIDc4LjY5MTQwNiAzMDkuMTY0MDYyIDcyLjgwMDc4MSBDIDMwOS4xNjQwNjIgNjYuOTEwMTU2IDMwOS4xNjQwNjIgNTkuMTA1NDY5IDMwNi42OTkyMTkgNTkuMTA1NDY5IEwgMjU0LjY4MzU5NCA1OS4xMDU0NjkgQyAyNTIuMjE4NzUgNTkuMTA1NDY5IDI1Mi4yMTg3NSA2Ni45MTAxNTYgMjUyLjIxODc1IDcyLjgwMDc4MSBDIDI1Mi4yMTg3NSA3OC42OTE0MDYgMjUyLjIxODc1IDg2LjQ5NjA5NCAyNTQuNjgzNTk0IDg2LjQ5NjA5NCBaIE0gMjU0LjY4MzU5NCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyMCI+CiAgPHBhdGggZD0iTSAzMzcgNzUgTCAzNDMgNzUgTCAzNDMgODIgTCAzMzcgODIgWiBNIDMzNyA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTIxIj4KICA8cGF0aCBkPSJNIDMxMi42MTcxODggODYuNDk2MDk0IEwgMzY0LjYzMjgxMiA4Ni40OTYwOTQgQyAzNjcuMDk3NjU2IDg2LjQ5NjA5NCAzNjcuMDk3NjU2IDc4LjY5MTQwNiAzNjcuMDk3NjU2IDcyLjgwMDc4MSBDIDM2Ny4wOTc2NTYgNjYuOTEwMTU2IDM2Ny4wOTc2NTYgNTkuMTA1NDY5IDM2NC42MzI4MTIgNTkuMTA1NDY5IEwgMzEyLjYxNzE4OCA1OS4xMDU0NjkgQyAzMTAuMTUyMzQ0IDU5LjEwNTQ2OSAzMTAuMTUyMzQ0IDY2LjkxMDE1NiAzMTAuMTUyMzQ0IDcyLjgwMDc4MSBDIDMxMC4xNTIzNDQgNzguNjkxNDA2IDMxMC4xNTIzNDQgODYuNDk2MDk0IDMxMi42MTcxODggODYuNDk2MDk0IFogTSAzMTIuNjE3MTg4IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTIyIj4KICA8cGF0aCBkPSJNIDMyNyA2MyBMIDMzNCA2MyBMIDMzNCA3MSBMIDMyNyA3MSBaIE0gMzI3IDYzICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjMiPgogIDxwYXRoIGQ9Ik0gMzEyLjYxNzE4OCA4Ni40OTYwOTQgTCAzNjQuNjMyODEyIDg2LjQ5NjA5NCBDIDM2Ny4wOTc2NTYgODYuNDk2MDk0IDM2Ny4wOTc2NTYgNzguNjkxNDA2IDM2Ny4wOTc2NTYgNzIuODAwNzgxIEMgMzY3LjA5NzY1NiA2Ni45MTAxNTYgMzY3LjA5NzY1NiA1OS4xMDU0NjkgMzY0LjYzMjgxMiA1OS4xMDU0NjkgTCAzMTIuNjE3MTg4IDU5LjEwNTQ2OSBDIDMxMC4xNTIzNDQgNTkuMTA1NDY5IDMxMC4xNTIzNDQgNjYuOTEwMTU2IDMxMC4xNTIzNDQgNzIuODAwNzgxIEMgMzEwLjE1MjM0NCA3OC42OTE0MDYgMzEwLjE1MjM0NCA4Ni40OTYwOTQgMzEyLjYxNzE4OCA4Ni40OTYwOTQgWiBNIDMxMi42MTcxODggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjQiPgogIDxwYXRoIGQ9Ik0gMzMzIDY0IEwgMzQxIDY0IEwgMzQxIDcxIEwgMzMzIDcxIFogTSAzMzMgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyNSI+CiAgPHBhdGggZD0iTSAzMTIuNjE3MTg4IDg2LjQ5NjA5NCBMIDM2NC42MzI4MTIgODYuNDk2MDk0IEMgMzY3LjA5NzY1NiA4Ni40OTYwOTQgMzY3LjA5NzY1NiA3OC42OTE0MDYgMzY3LjA5NzY1NiA3Mi44MDA3ODEgQyAzNjcuMDk3NjU2IDY2LjkxMDE1NiAzNjcuMDk3NjU2IDU5LjEwNTQ2OSAzNjQuNjMyODEyIDU5LjEwNTQ2OSBMIDMxMi42MTcxODggNTkuMTA1NDY5IEMgMzEwLjE1MjM0NCA1OS4xMDU0NjkgMzEwLjE1MjM0NCA2Ni45MTAxNTYgMzEwLjE1MjM0NCA3Mi44MDA3ODEgQyAzMTAuMTUyMzQ0IDc4LjY5MTQwNiAzMTAuMTUyMzQ0IDg2LjQ5NjA5NCAzMTIuNjE3MTg4IDg2LjQ5NjA5NCBaIE0gMzEyLjYxNzE4OCA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEyNiI+CiAgPHBhdGggZD0iTSAzNDEgNjQgTCAzNDkgNjQgTCAzNDkgNzEgTCAzNDEgNzEgWiBNIDM0MSA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTI3Ij4KICA8cGF0aCBkPSJNIDMxMi42MTcxODggODYuNDk2MDk0IEwgMzY0LjYzMjgxMiA4Ni40OTYwOTQgQyAzNjcuMDk3NjU2IDg2LjQ5NjA5NCAzNjcuMDk3NjU2IDc4LjY5MTQwNiAzNjcuMDk3NjU2IDcyLjgwMDc4MSBDIDM2Ny4wOTc2NTYgNjYuOTEwMTU2IDM2Ny4wOTc2NTYgNTkuMTA1NDY5IDM2NC42MzI4MTIgNTkuMTA1NDY5IEwgMzEyLjYxNzE4OCA1OS4xMDU0NjkgQyAzMTAuMTUyMzQ0IDU5LjEwNTQ2OSAzMTAuMTUyMzQ0IDY2LjkxMDE1NiAzMTAuMTUyMzQ0IDcyLjgwMDc4MSBDIDMxMC4xNTIzNDQgNzguNjkxNDA2IDMxMC4xNTIzNDQgODYuNDk2MDk0IDMxMi42MTcxODggODYuNDk2MDk0IFogTSAzMTIuNjE3MTg4IDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTI4Ij4KICA8cGF0aCBkPSJNIDM0OCA2NyBMIDM1MiA2NyBMIDM1MiA3MyBMIDM0OCA3MyBaIE0gMzQ4IDY3ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMjkiPgogIDxwYXRoIGQ9Ik0gMzEyLjYxNzE4OCA4Ni40OTYwOTQgTCAzNjQuNjMyODEyIDg2LjQ5NjA5NCBDIDM2Ny4wOTc2NTYgODYuNDk2MDk0IDM2Ny4wOTc2NTYgNzguNjkxNDA2IDM2Ny4wOTc2NTYgNzIuODAwNzgxIEMgMzY3LjA5NzY1NiA2Ni45MTAxNTYgMzY3LjA5NzY1NiA1OS4xMDU0NjkgMzY0LjYzMjgxMiA1OS4xMDU0NjkgTCAzMTIuNjE3MTg4IDU5LjEwNTQ2OSBDIDMxMC4xNTIzNDQgNTkuMTA1NDY5IDMxMC4xNTIzNDQgNjYuOTEwMTU2IDMxMC4xNTIzNDQgNzIuODAwNzgxIEMgMzEwLjE1MjM0NCA3OC42OTE0MDYgMzEwLjE1MjM0NCA4Ni40OTYwOTQgMzEyLjYxNzE4OCA4Ni40OTYwOTQgWiBNIDMxMi42MTcxODggODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzAiPgogIDxwYXRoIGQ9Ik0gNDE0IDc1IEwgNDIxIDc1IEwgNDIxIDgyIEwgNDE0IDgyIFogTSA0MTQgNzUgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzMSI+CiAgPHBhdGggZD0iTSAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBMIDQ0Mi4yODkwNjIgODYuNDk2MDk0IEMgNDQ0Ljc1MzkwNiA4Ni40OTYwOTQgNDQ0Ljc1MzkwNiA3OC42OTE0MDYgNDQ0Ljc1MzkwNiA3Mi44MDA3ODEgQyA0NDQuNzUzOTA2IDY2LjkxMDE1NiA0NDQuNzUzOTA2IDU5LjEwNTQ2OSA0NDIuMjg5MDYyIDU5LjEwNTQ2OSBMIDM5MC4yNjk1MzEgNTkuMTA1NDY5IEMgMzg3LjgwNDY4OCA1OS4xMDU0NjkgMzg3LjgwNDY4OCA2Ni45MTAxNTYgMzg3LjgwNDY4OCA3Mi44MDA3ODEgQyAzODcuODA0Njg4IDc4LjY5MTQwNiAzODcuODA0Njg4IDg2LjQ5NjA5NCAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBaIE0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzMiI+CiAgPHBhdGggZD0iTSAzOTkgNjMgTCA0MDYgNjMgTCA0MDYgNzEgTCAzOTkgNzEgWiBNIDM5OSA2MyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTMzIj4KICA8cGF0aCBkPSJNIDM5MC4yNjk1MzEgODYuNDk2MDk0IEwgNDQyLjI4OTA2MiA4Ni40OTYwOTQgQyA0NDQuNzUzOTA2IDg2LjQ5NjA5NCA0NDQuNzUzOTA2IDc4LjY5MTQwNiA0NDQuNzUzOTA2IDcyLjgwMDc4MSBDIDQ0NC43NTM5MDYgNjYuOTEwMTU2IDQ0NC43NTM5MDYgNTkuMTA1NDY5IDQ0Mi4yODkwNjIgNTkuMTA1NDY5IEwgMzkwLjI2OTUzMSA1OS4xMDU0NjkgQyAzODcuODA0Njg4IDU5LjEwNTQ2OSAzODcuODA0Njg4IDY2LjkxMDE1NiAzODcuODA0Njg4IDcyLjgwMDc4MSBDIDM4Ny44MDQ2ODggNzguNjkxNDA2IDM4Ny44MDQ2ODggODYuNDk2MDk0IDM5MC4yNjk1MzEgODYuNDk2MDk0IFogTSAzOTAuMjY5NTMxIDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTM0Ij4KICA8cGF0aCBkPSJNIDQwNiA2NCBMIDQxMyA2NCBMIDQxMyA3MSBMIDQwNiA3MSBaIE0gNDA2IDY0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzUiPgogIDxwYXRoIGQ9Ik0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgTCA0NDIuMjg5MDYyIDg2LjQ5NjA5NCBDIDQ0NC43NTM5MDYgODYuNDk2MDk0IDQ0NC43NTM5MDYgNzguNjkxNDA2IDQ0NC43NTM5MDYgNzIuODAwNzgxIEMgNDQ0Ljc1MzkwNiA2Ni45MTAxNTYgNDQ0Ljc1MzkwNiA1OS4xMDU0NjkgNDQyLjI4OTA2MiA1OS4xMDU0NjkgTCAzOTAuMjY5NTMxIDU5LjEwNTQ2OSBDIDM4Ny44MDQ2ODggNTkuMTA1NDY5IDM4Ny44MDQ2ODggNjYuOTEwMTU2IDM4Ny44MDQ2ODggNzIuODAwNzgxIEMgMzg3LjgwNDY4OCA3OC42OTE0MDYgMzg3LjgwNDY4OCA4Ni40OTYwOTQgMzkwLjI2OTUzMSA4Ni40OTYwOTQgWiBNIDM5MC4yNjk1MzEgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxMzYiPgogIDxwYXRoIGQ9Ik0gNDEzIDY0IEwgNDIxIDY0IEwgNDIxIDcxIEwgNDEzIDcxIFogTSA0MTMgNjQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzNyI+CiAgPHBhdGggZD0iTSAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBMIDQ0Mi4yODkwNjIgODYuNDk2MDk0IEMgNDQ0Ljc1MzkwNiA4Ni40OTYwOTQgNDQ0Ljc1MzkwNiA3OC42OTE0MDYgNDQ0Ljc1MzkwNiA3Mi44MDA3ODEgQyA0NDQuNzUzOTA2IDY2LjkxMDE1NiA0NDQuNzUzOTA2IDU5LjEwNTQ2OSA0NDIuMjg5MDYyIDU5LjEwNTQ2OSBMIDM5MC4yNjk1MzEgNTkuMTA1NDY5IEMgMzg3LjgwNDY4OCA1OS4xMDU0NjkgMzg3LjgwNDY4OCA2Ni45MTAxNTYgMzg3LjgwNDY4OCA3Mi44MDA3ODEgQyAzODcuODA0Njg4IDc4LjY5MTQwNiAzODcuODA0Njg4IDg2LjQ5NjA5NCAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBaIE0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDEzOCI+CiAgPHBhdGggZD0iTSA0MjAgNjcgTCA0MjYgNjcgTCA0MjYgNzMgTCA0MjAgNzMgWiBNIDQyMCA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTM5Ij4KICA8cGF0aCBkPSJNIDM5MC4yNjk1MzEgODYuNDk2MDk0IEwgNDQyLjI4OTA2MiA4Ni40OTYwOTQgQyA0NDQuNzUzOTA2IDg2LjQ5NjA5NCA0NDQuNzUzOTA2IDc4LjY5MTQwNiA0NDQuNzUzOTA2IDcyLjgwMDc4MSBDIDQ0NC43NTM5MDYgNjYuOTEwMTU2IDQ0NC43NTM5MDYgNTkuMTA1NDY5IDQ0Mi4yODkwNjIgNTkuMTA1NDY5IEwgMzkwLjI2OTUzMSA1OS4xMDU0NjkgQyAzODcuODA0Njg4IDU5LjEwNTQ2OSAzODcuODA0Njg4IDY2LjkxMDE1NiAzODcuODA0Njg4IDcyLjgwMDc4MSBDIDM4Ny44MDQ2ODggNzguNjkxNDA2IDM4Ny44MDQ2ODggODYuNDk2MDk0IDM5MC4yNjk1MzEgODYuNDk2MDk0IFogTSAzOTAuMjY5NTMxIDg2LjQ5NjA5NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQwIj4KICA8cGF0aCBkPSJNIDQyNiA3MCBMIDQzMSA3MCBMIDQzMSA3MSBMIDQyNiA3MSBaIE0gNDI2IDcwICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNDEiPgogIDxwYXRoIGQ9Ik0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgTCA0NDIuMjg5MDYyIDg2LjQ5NjA5NCBDIDQ0NC43NTM5MDYgODYuNDk2MDk0IDQ0NC43NTM5MDYgNzguNjkxNDA2IDQ0NC43NTM5MDYgNzIuODAwNzgxIEMgNDQ0Ljc1MzkwNiA2Ni45MTAxNTYgNDQ0Ljc1MzkwNiA1OS4xMDU0NjkgNDQyLjI4OTA2MiA1OS4xMDU0NjkgTCAzOTAuMjY5NTMxIDU5LjEwNTQ2OSBDIDM4Ny44MDQ2ODggNTkuMTA1NDY5IDM4Ny44MDQ2ODggNjYuOTEwMTU2IDM4Ny44MDQ2ODggNzIuODAwNzgxIEMgMzg3LjgwNDY4OCA3OC42OTE0MDYgMzg3LjgwNDY4OCA4Ni40OTYwOTQgMzkwLjI2OTUzMSA4Ni40OTYwOTQgWiBNIDM5MC4yNjk1MzEgODYuNDk2MDk0ICIvPgo8L2NsaXBQYXRoPgo8Y2xpcFBhdGggaWQ9ImNsaXAxNDIiPgogIDxwYXRoIGQ9Ik0gNDMyIDY3IEwgNDM1IDY3IEwgNDM1IDczIEwgNDMyIDczIFogTSA0MzIgNjcgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0MyI+CiAgPHBhdGggZD0iTSAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBMIDQ0Mi4yODkwNjIgODYuNDk2MDk0IEMgNDQ0Ljc1MzkwNiA4Ni40OTYwOTQgNDQ0Ljc1MzkwNiA3OC42OTE0MDYgNDQ0Ljc1MzkwNiA3Mi44MDA3ODEgQyA0NDQuNzUzOTA2IDY2LjkxMDE1NiA0NDQuNzUzOTA2IDU5LjEwNTQ2OSA0NDIuMjg5MDYyIDU5LjEwNTQ2OSBMIDM5MC4yNjk1MzEgNTkuMTA1NDY5IEMgMzg3LjgwNDY4OCA1OS4xMDU0NjkgMzg3LjgwNDY4OCA2Ni45MTAxNTYgMzg3LjgwNDY4OCA3Mi44MDA3ODEgQyAzODcuODA0Njg4IDc4LjY5MTQwNiAzODcuODA0Njg4IDg2LjQ5NjA5NCAzOTAuMjY5NTMxIDg2LjQ5NjA5NCBaIE0gMzkwLjI2OTUzMSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0NCI+CiAgPHBhdGggZD0iTSA0NzIgNzUgTCA0NzggNzUgTCA0NzggODIgTCA0NzIgODIgWiBNIDQ3MiA3NSAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ1Ij4KICA8cGF0aCBkPSJNIDQ0OC4yMDMxMjUgODYuNDk2MDk0IEwgNTAwLjIxODc1IDg2LjQ5NjA5NCBDIDUwMi42ODM1OTQgODYuNDk2MDk0IDUwMi42ODM1OTQgNzguNjkxNDA2IDUwMi42ODM1OTQgNzIuODAwNzgxIEMgNTAyLjY4MzU5NCA2Ni45MTAxNTYgNTAyLjY4MzU5NCA1OS4xMDU0NjkgNTAwLjIxODc1IDU5LjEwNTQ2OSBMIDQ0OC4yMDMxMjUgNTkuMTA1NDY5IEMgNDQ1LjczODI4MSA1OS4xMDU0NjkgNDQ1LjczODI4MSA2Ni45MTAxNTYgNDQ1LjczODI4MSA3Mi44MDA3ODEgQyA0NDUuNzM4MjgxIDc4LjY5MTQwNiA0NDUuNzM4MjgxIDg2LjQ5NjA5NCA0NDguMjAzMTI1IDg2LjQ5NjA5NCBaIE0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0NiI+CiAgPHBhdGggZD0iTSA0NjIgNjMgTCA0NjkgNjMgTCA0NjkgNzEgTCA0NjIgNzEgWiBNIDQ2MiA2MyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ3Ij4KICA8cGF0aCBkPSJNIDQ0OC4yMDMxMjUgODYuNDk2MDk0IEwgNTAwLjIxODc1IDg2LjQ5NjA5NCBDIDUwMi42ODM1OTQgODYuNDk2MDk0IDUwMi42ODM1OTQgNzguNjkxNDA2IDUwMi42ODM1OTQgNzIuODAwNzgxIEMgNTAyLjY4MzU5NCA2Ni45MTAxNTYgNTAyLjY4MzU5NCA1OS4xMDU0NjkgNTAwLjIxODc1IDU5LjEwNTQ2OSBMIDQ0OC4yMDMxMjUgNTkuMTA1NDY5IEMgNDQ1LjczODI4MSA1OS4xMDU0NjkgNDQ1LjczODI4MSA2Ni45MTAxNTYgNDQ1LjczODI4MSA3Mi44MDA3ODEgQyA0NDUuNzM4MjgxIDc4LjY5MTQwNiA0NDUuNzM4MjgxIDg2LjQ5NjA5NCA0NDguMjAzMTI1IDg2LjQ5NjA5NCBaIE0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE0OCI+CiAgPHBhdGggZD0iTSA0NjggNjQgTCA0NzYgNjQgTCA0NzYgNzEgTCA0NjggNzEgWiBNIDQ2OCA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTQ5Ij4KICA8cGF0aCBkPSJNIDQ0OC4yMDMxMjUgODYuNDk2MDk0IEwgNTAwLjIxODc1IDg2LjQ5NjA5NCBDIDUwMi42ODM1OTQgODYuNDk2MDk0IDUwMi42ODM1OTQgNzguNjkxNDA2IDUwMi42ODM1OTQgNzIuODAwNzgxIEMgNTAyLjY4MzU5NCA2Ni45MTAxNTYgNTAyLjY4MzU5NCA1OS4xMDU0NjkgNTAwLjIxODc1IDU5LjEwNTQ2OSBMIDQ0OC4yMDMxMjUgNTkuMTA1NDY5IEMgNDQ1LjczODI4MSA1OS4xMDU0NjkgNDQ1LjczODI4MSA2Ni45MTAxNTYgNDQ1LjczODI4MSA3Mi44MDA3ODEgQyA0NDUuNzM4MjgxIDc4LjY5MTQwNiA0NDUuNzM4MjgxIDg2LjQ5NjA5NCA0NDguMjAzMTI1IDg2LjQ5NjA5NCBaIE0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1MCI+CiAgPHBhdGggZD0iTSA0NzUgNjQgTCA0ODMgNjQgTCA0ODMgNzEgTCA0NzUgNzEgWiBNIDQ3NSA2NCAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTUxIj4KICA8cGF0aCBkPSJNIDQ0OC4yMDMxMjUgODYuNDk2MDk0IEwgNTAwLjIxODc1IDg2LjQ5NjA5NCBDIDUwMi42ODM1OTQgODYuNDk2MDk0IDUwMi42ODM1OTQgNzguNjkxNDA2IDUwMi42ODM1OTQgNzIuODAwNzgxIEMgNTAyLjY4MzU5NCA2Ni45MTAxNTYgNTAyLjY4MzU5NCA1OS4xMDU0NjkgNTAwLjIxODc1IDU5LjEwNTQ2OSBMIDQ0OC4yMDMxMjUgNTkuMTA1NDY5IEMgNDQ1LjczODI4MSA1OS4xMDU0NjkgNDQ1LjczODI4MSA2Ni45MTAxNTYgNDQ1LjczODI4MSA3Mi44MDA3ODEgQyA0NDUuNzM4MjgxIDc4LjY5MTQwNiA0NDUuNzM4MjgxIDg2LjQ5NjA5NCA0NDguMjAzMTI1IDg2LjQ5NjA5NCBaIE0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjxjbGlwUGF0aCBpZD0iY2xpcDE1MiI+CiAgPHBhdGggZD0iTSA0ODIgNjcgTCA0ODkgNjcgTCA0ODkgNzMgTCA0ODIgNzMgWiBNIDQ4MiA2NyAiLz4KPC9jbGlwUGF0aD4KPGNsaXBQYXRoIGlkPSJjbGlwMTUzIj4KICA8cGF0aCBkPSJNIDQ0OC4yMDMxMjUgODYuNDk2MDk0IEwgNTAwLjIxODc1IDg2LjQ5NjA5NCBDIDUwMi42ODM1OTQgODYuNDk2MDk0IDUwMi42ODM1OTQgNzguNjkxNDA2IDUwMi42ODM1OTQgNzIuODAwNzgxIEMgNTAyLjY4MzU5NCA2Ni45MTAxNTYgNTAyLjY4MzU5NCA1OS4xMDU0NjkgNTAwLjIxODc1IDU5LjEwNTQ2OSBMIDQ0OC4yMDMxMjUgNTkuMTA1NDY5IEMgNDQ1LjczODI4MSA1OS4xMDU0NjkgNDQ1LjczODI4MSA2Ni45MTAxNTYgNDQ1LjczODI4MSA3Mi44MDA3ODEgQyA0NDUuNzM4MjgxIDc4LjY5MTQwNiA0NDUuNzM4MjgxIDg2LjQ5NjA5NCA0NDguMjAzMTI1IDg2LjQ5NjA5NCBaIE0gNDQ4LjIwMzEyNSA4Ni40OTYwOTQgIi8+CjwvY2xpcFBhdGg+CjwvZGVmcz4KPGcgaWQ9InN1cmZhY2UxIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig1MCUsNTAlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAxLjc3MzQzOCA4Ny40NjQ4NDQgTCA0MS45MTc5NjkgODcuNDY0ODQ0IEwgNDEuOTE3OTY5IDU4LjE0MDYyNSBMIDEuNzczNDM4IDU4LjE0MDYyNSBMIDEuNzczNDM4IDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMCUsMTAwJSw1MCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSA0MC45NDkyMTkgODcuNDY0ODQ0IEwgNjYuNTcwMzEyIDg3LjQ2NDg0NCBMIDY2LjU3MDMxMiA1OC4xNDA2MjUgTCA0MC45NDkyMTkgNTguMTQwNjI1IEwgNDAuOTQ5MjE5IDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoNTAlLDUwJSwxMDAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gNDYuMTQ4NDM4IDg3LjQ2NDg0NCBMIDg2LjI4OTA2MiA4Ny40NjQ4NDQgTCA4Ni4yODkwNjIgNTguMTQwNjI1IEwgNDYuMTQ4NDM4IDU4LjE0MDYyNSBMIDQ2LjE0ODQzOCA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDAlLDEwMCUsNTAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gODUuMzI0MjE5IDg3LjQ2NDg0NCBMIDEzNS41OTM3NSA4Ny40NjQ4NDQgTCAxMzUuNTkzNzUgNTguMTQwNjI1IEwgODUuMzI0MjE5IDU4LjE0MDYyNSBMIDg1LjMyNDIxOSA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig1MCUsNTAlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAxMDQuMDc4MTI1IDg3LjQ2NDg0NCBMIDE0NC4yMjI2NTYgODcuNDY0ODQ0IEwgMTQ0LjIyMjY1NiA1OC4xNDA2MjUgTCAxMDQuMDc4MTI1IDU4LjE0MDYyNSBMIDEwNC4wNzgxMjUgODcuNDY0ODQ0ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDAlLDEwMCUsNTAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMTQzLjI1NzgxMiA4Ny40NjQ4NDQgTCAxNjguODc1IDg3LjQ2NDg0NCBMIDE2OC44NzUgNTguMTQwNjI1IEwgMTQzLjI1NzgxMiA1OC4xNDA2MjUgTCAxNDMuMjU3ODEyIDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYig1MCUsNTAlLDEwMCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAxNDguNDUzMTI1IDg3LjQ2NDg0NCBMIDE4OC41OTc2NTYgODcuNDY0ODQ0IEwgMTg4LjU5NzY1NiA1OC4xNDA2MjUgTCAxNDguNDUzMTI1IDU4LjE0MDYyNSBMIDE0OC40NTMxMjUgODcuNDY0ODQ0ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDc1JSw3NSUsMTAwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDE4Ny42Mjg5MDYgODcuNDY0ODQ0IEwgMjUyLjY5MTQwNiA4Ny40NjQ4NDQgTCAyNTIuNjkxNDA2IDU4LjE0MDYyNSBMIDE4Ny42Mjg5MDYgNTguMTQwNjI1IEwgMTg3LjYyODkwNiA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMTAwJSw1MCUsNTAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMjUwLjc2MTcxOSA4Ny40NjQ4NDQgTCAzMTAuNjI1IDg3LjQ2NDg0NCBMIDMxMC42MjUgNTguMTQwNjI1IEwgMjUwLjc2MTcxOSA1OC4xNDA2MjUgTCAyNTAuNzYxNzE5IDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDIwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9IiBzdHJva2U6bm9uZTtmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigxMDAlLDUwJSw1MCUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAzMDguNjkxNDA2IDg3LjQ2NDg0NCBMIDM2OC41NTg1OTQgODcuNDY0ODQ0IEwgMzY4LjU1ODU5NCA1OC4xNDA2MjUgTCAzMDguNjkxNDA2IDU4LjE0MDYyNSBMIDMwOC42OTE0MDYgODcuNDY0ODQ0ICIvPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDEwMCUsNTAlLDUwJSk7ZmlsbC1vcGFjaXR5OjE7IiBkPSJNIDM4Ni4zNDc2NTYgODcuNDY0ODQ0IEwgNDQ2LjIxMDkzOCA4Ny40NjQ4NDQgTCA0NDYuMjEwOTM4IDU4LjE0MDYyNSBMIDM4Ni4zNDc2NTYgNTguMTQwNjI1IEwgMzg2LjM0NzY1NiA4Ny40NjQ4NDQgIi8+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDIzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMTAwJSw1MCUsNTAlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gNDQ0LjI3NzM0NCA4Ny40NjQ4NDQgTCA1MDQuMTQ0NTMxIDg3LjQ2NDg0NCBMIDUwNC4xNDQ1MzEgNTguMTQwNjI1IEwgNDQ0LjI3NzM0NCA1OC4xNDA2MjUgTCA0NDQuMjc3MzQ0IDg3LjQ2NDg0NCAiLz4KPC9nPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDI3LjM4MjgxMiAyNTYuMTc4MTI1IEwgMjcuMzgyODEyIDI1NS44NjU2MjUgQyAyNy4zODI4MTIgMjM2Ljk1OTM3NSA0Mi43MzQzNzUgMjIxLjY0Njg3NSA2MS42NDA2MjUgMjIxLjY0Njg3NSBMIDMwMDAuNzAzMTI1IDIyMS42NDY4NzUgQyAzMDE5LjY0ODQzOCAyMjEuNjQ2ODc1IDMwMzQuOTYwOTM4IDIzNi45NTkzNzUgMzAzNC45NjA5MzggMjU1Ljg2NTYyNSBMIDMwMzQuOTYwOTM4IDMzMS4xNzgxMjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyLjczODI4MSA4Ni45OTIxODggTCAwLjgwNDY4OCA5NC4yNjk1MzEgQyAwLjc4NTE1NiA5NC4zNDM3NSAwLjc2OTUzMSA5NC40MTc5NjkgMC43NTM5MDYgOTQuNDkyMTg4IEwgNC43MzgyODEgOTQuNDkyMTg4IEMgNC43MTQ4NDQgOTQuNDE3OTY5IDQuNjk1MzEyIDk0LjM0Mzc1IDQuNjcxODc1IDk0LjI2OTUzMSBMIDIuNzM4MjgxIDg2Ljk5MjE4OCAiLz4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjcuMzgyODEyIDMzMS4xNzgxMjUgTCA4LjA0Njg3NSAyNTguNDA0Njg3IEMgNy44NTE1NjIgMjU3LjY2MjUgNy42OTUzMTIgMjU2LjkyMDMxMiA3LjUzOTA2MiAyNTYuMTc4MTI1IEwgNDcuMzgyODEyIDI1Ni4xNzgxMjUgQyA0Ny4xNDg0MzggMjU2LjkyMDMxMiA0Ni45NTMxMjUgMjU3LjY2MjUgNDYuNzE4NzUgMjU4LjQwNDY4NyBaIE0gMjcuMzgyODEyIDMzMS4xNzgxMjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDQ3MS4xMzI4MTIgMjU2LjE3ODEyNSBMIDQ3MS4xMzI4MTIgMjAxLjEgQyA0NzEuMTMyODEyIDE4Mi4xOTM3NSA0ODYuNDQ1MzEyIDE2Ni44NDIxODcgNTA1LjM1MTU2MiAxNjYuODQyMTg3IEwgMzU4MC4wMzkwNjIgMTY2Ljg0MjE4NyBDIDM1OTguOTQ1MzEyIDE2Ni44NDIxODcgMzYxNC4yOTY4NzUgMTgyLjE5Mzc1IDM2MTQuMjk2ODc1IDIwMS4xIEwgMzYxNC4yOTY4NzUgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gNDcxLjEzMjgxMiAzMzEuMTc4MTI1IEwgNDUxLjAxNTYyNSAyNTYuMTc4MTI1IEwgNDkxLjIxMDkzOCAyNTYuMTc4MTI1IFogTSA0NzEuMTMyODEyIDMzMS4xNzgxMjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNTAuNDY4NzUgMjU2LjE3ODEyNSBMIDEwNTAuNDY4NzUgOTEuNTI5Njg3IEMgMTA1MC40Njg3NSA3Mi42MjM0MzcgMTA2NS43ODEyNSA1Ny4yNzE4NzUgMTA4NC42ODc1IDU3LjI3MTg3NSBMIDQzNTYuNjAxNTYyIDU3LjI3MTg3NSBDIDQzNzUuNTA3ODEyIDU3LjI3MTg3NSA0MzkwLjgyMDMxMiA3Mi42MjM0MzcgNDM5MC44MjAzMTIgOTEuNTI5Njg3IEwgNDM5MC44MjAzMTIgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMTA1MC40Njg3NSAzMzEuMTc4MTI1IEwgMTAzMC4zNTE1NjIgMjU2LjE3ODEyNSBMIDEwNzAuNTQ2ODc1IDI1Ni4xNzgxMjUgWiBNIDEwNTAuNDY4NzUgMzMxLjE3ODEyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDE0OTQuMjE4NzUgMjU2LjE3ODEyNSBMIDE0OTQuMjE4NzUgMzYuNzI1IEMgMTQ5NC4yMTg3NSAxNy44MTg3NSAxNTA5LjUzMTI1IDIuNTA2MjUgMTUyOC40Mzc1IDIuNTA2MjUgTCA0OTM1Ljg5ODQzOCAyLjUwNjI1IEMgNDk1NC44MDQ2ODggMi41MDYyNSA0OTcwLjE1NjI1IDE3LjgxODc1IDQ5NzAuMTU2MjUgMzYuNzI1IEwgNDk3MC4xNTYyNSAzMzEuMTc4MTI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDE0OTQuMjE4NzUgMzMxLjE3ODEyNSBMIDE0NzQuMTAxNTYyIDI1Ni4xNzgxMjUgTCAxNTE0LjI5Njg3NSAyNTYuMTc4MTI1IFogTSAxNDk0LjIxODc1IDMzMS4xNzgxMjUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNDM3LjM0Mzc1IDY5MC4wODQzNzUgTCAxMDcuMzA0Njg4IDY5MC4wODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAyNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAyNTEuMjM0Mzc1IDUxLjEwMTU2MiBMIDI0My43MzQzNzUgNDkuMDg5ODQ0IEwgMjQzLjczNDM3NSA1My4xMDkzNzUgWiBNIDI1MS4yMzQzNzUgNTEuMTAxNTYyICIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMjgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNTEyLjM0Mzc1IDY5MC4wODQzNzUgTCAyNDM3LjM0Mzc1IDcxMC4yMDE1NjIgTCAyNDM3LjM0Mzc1IDY3MC4wMDYyNSBaIE0gMjUxMi4zNDM3NSA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAzLjIzMDQ2OSA1MS4xMDE1NjIgTCAxMC43MzA0NjkgNTMuMTA5Mzc1IEwgMTAuNzMwNDY5IDQ5LjA4OTg0NCBaIE0gMy4yMzA0NjkgNTEuMTAxNTYyICIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDI5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMzIuMzA0Njg4IDY5MC4wODQzNzUgTCAxMDcuMzA0Njg4IDY3MC4wMDYyNSBMIDEwNy4zMDQ2ODggNzEwLjIwMTU2MiBaIE0gMzIuMzA0Njg4IDY5MC4wODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDMyLjMwNDY4OCA2NTIuNTg0Mzc1IEwgMzIuMzA0Njg4IDcyNy41ODQzNzUgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDI1MTIuMzQzNzUgNjUyLjU4NDM3NSBMIDI1MTIuMzQzNzUgNzI3LjU4NDM3NSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDMyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjQzNy4zNDM3NSA3OTkuNjU0Njg3IEwgNTUxLjA1NDY4OCA3OTkuNjU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMjUxLjIzNDM3NSA0MC4xNDQ1MzEgTCAyNDMuNzM0Mzc1IDM4LjEzNjcxOSBMIDI0My43MzQzNzUgNDIuMTUyMzQ0IFogTSAyNTEuMjM0Mzc1IDQwLjE0NDUzMSAiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDM0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjUxMi4zNDM3NSA3OTkuNjU0Njg3IEwgMjQzNy4zNDM3NSA4MTkuNzMyODEyIEwgMjQzNy4zNDM3NSA3NzkuNTc2NTYyIFogTSAyNTEyLjM0Mzc1IDc5OS42NTQ2ODcgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSA0Ny42MDU0NjkgNDAuMTQ0NTMxIEwgNTUuMTA1NDY5IDQyLjE1MjM0NCBMIDU1LjEwNTQ2OSAzOC4xMzY3MTkgWiBNIDQ3LjYwNTQ2OSA0MC4xNDQ1MzEgIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDQ3Ni4wNTQ2ODggNzk5LjY1NDY4NyBMIDU1MS4wNTQ2ODggNzc5LjU3NjU2MiBMIDU1MS4wNTQ2ODggODE5LjczMjgxMiBaIE0gNDc2LjA1NDY4OCA3OTkuNjU0Njg3ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMzcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSA0NzYuMDU0Njg4IDc2Mi4xNTQ2ODcgTCA0NzYuMDU0Njg4IDgzNy4xNTQ2ODcgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAzOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDI1MTIuMzQzNzUgNzYyLjE1NDY4NyBMIDI1MTIuMzQzNzUgODM3LjE1NDY4NyAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDM5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjQzNy4zNDM3NSAxMDE4Ljc5NTMxMiBMIDExMzAuMzkwNjI1IDEwMTguNzk1MzEyICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMjUxLjIzNDM3NSAxOC4yMzA0NjkgTCAyNDMuNzM0Mzc1IDE2LjIyMjY1NiBMIDI0My43MzQzNzUgMjAuMjQyMTg4IFogTSAyNTEuMjM0Mzc1IDE4LjIzMDQ2OSAiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjUxMi4zNDM3NSAxMDE4Ljc5NTMxMiBMIDI0MzcuMzQzNzUgMTAzOC44NzM0MzcgTCAyNDM3LjM0Mzc1IDk5OC42NzgxMjUgWiBNIDI1MTIuMzQzNzUgMTAxOC43OTUzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSIgc3Ryb2tlOm5vbmU7ZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxOyIgZD0iTSAxMDUuNTM5MDYyIDE4LjIzMDQ2OSBMIDExMy4wMzkwNjIgMjAuMjQyMTg4IEwgMTEzLjAzOTA2MiAxNi4yMjI2NTYgWiBNIDEwNS41MzkwNjIgMTguMjMwNDY5ICIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxMDU1LjM5MDYyNSAxMDE4Ljc5NTMxMiBMIDExMzAuMzkwNjI1IDk5OC42NzgxMjUgTCAxMTMwLjM5MDYyNSAxMDM4Ljg3MzQzNyBaIE0gMTA1NS4zOTA2MjUgMTAxOC43OTUzMTIgIiB0cmFuc2Zvcm09Im1hdHJpeCgwLjEsMCwwLC0wLjEsMCwxMjAuMTEpIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA0NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDEwNTUuMzkwNjI1IDk4MS4yOTUzMTIgTCAxMDU1LjM5MDYyNSAxMDU2LjI5NTMxMiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQ1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjUxMi4zNDM3NSA5ODEuMjk1MzEyIEwgMjUxMi4zNDM3NSAxMDU2LjI5NTMxMiAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQ2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjQzNy4zNDM3NSAxMTI4LjM2NTYyNSBMIDE1NzQuMTQwNjI1IDExMjguMzY1NjI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbC1ydWxlOm5vbnplcm87ZmlsbDpyZ2IoMjUlLDI1JSwyNSUpO2ZpbGwtb3BhY2l0eToxO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNTEyLjM0Mzc1IDExMjguMzY1NjI1IEwgMjQzNy4zNDM3NSAxMTQ4LjQ0Mzc1IEwgMjQzNy4zNDM3NSAxMTA4LjI0ODQzNyBaIE0gMjUxMi4zNDM3NSAxMTI4LjM2NTYyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDQ4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMTQ5OS4xNDA2MjUgMTEyOC4zNjU2MjUgTCAxNTc0LjE0MDYyNSAxMTA4LjI0ODQzNyBMIDE1NzQuMTQwNjI1IDExNDguNDQzNzUgWiBNIDE0OTkuMTQwNjI1IDExMjguMzY1NjI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNDkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAxNDk5LjE0MDYyNSAxMDkwLjg2NTYyNSBMIDE0OTkuMTQwNjI1IDExNjUuODY1NjI1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNTEyLjM0Mzc1IDEwOTAuODY1NjI1IEwgMjUxMi4zNDM3NSAxMTY1Ljg2NTYyNSAiIHRyYW5zZm9ybT0ibWF0cml4KDAuMSwwLDAsLTAuMSwwLDEyMC4xMSkiLz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDUxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gNDk1MS44MzU5MzggNjkwLjA4NDM3NSBMIDI1OTcuMTg3NSA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsLXJ1bGU6bm9uemVybztmaWxsOnJnYigyNSUsMjUlLDI1JSk7ZmlsbC1vcGFjaXR5OjE7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDUwMjYuODM1OTM4IDY5MC4wODQzNzUgTCA0OTUxLjgzNTkzOCA3MTAuMjAxNTYyIEwgNDk1MS44MzU5MzggNjcwLjAwNjI1IFogTSA1MDI2LjgzNTkzOCA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8cGF0aCBzdHlsZT0iIHN0cm9rZTpub25lO2ZpbGwtcnVsZTpub256ZXJvO2ZpbGw6cmdiKDI1JSwyNSUsMjUlKTtmaWxsLW9wYWNpdHk6MTsiIGQ9Ik0gMjUyLjIxODc1IDUxLjEwMTU2MiBMIDI1OS43MTg3NSA1My4xMDkzNzUgTCAyNTkuNzE4NzUgNDkuMDg5ODQ0IFogTSAyNTIuMjE4NzUgNTEuMTAxNTYyICIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDUyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPHBhdGggc3R5bGU9ImZpbGw6bm9uZTtzdHJva2Utd2lkdGg6NTtzdHJva2UtbGluZWNhcDpyb3VuZDtzdHJva2UtbGluZWpvaW46cm91bmQ7c3Ryb2tlOnJnYigyNSUsMjUlLDI1JSk7c3Ryb2tlLW9wYWNpdHk6MTtzdHJva2UtbWl0ZXJsaW1pdDoxMDsiIGQ9Ik0gMjUyMi4xODc1IDY5MC4wODQzNzUgTCAyNTk3LjE4NzUgNjcwLjAwNjI1IEwgMjU5Ny4xODc1IDcxMC4yMDE1NjIgWiBNIDI1MjIuMTg3NSA2OTAuMDg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNTMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8cGF0aCBzdHlsZT0iZmlsbDpub25lO3N0cm9rZS13aWR0aDo1O3N0cm9rZS1saW5lY2FwOnJvdW5kO3N0cm9rZS1saW5lam9pbjpyb3VuZDtzdHJva2U6cmdiKDI1JSwyNSUsMjUlKTtzdHJva2Utb3BhY2l0eToxO3N0cm9rZS1taXRlcmxpbWl0OjEwOyIgZD0iTSAyNTIyLjE4NzUgNjUyLjU4NDM3NSBMIDI1MjIuMTg3NSA3MjcuNTg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8L2c+CjxwYXRoIHN0eWxlPSJmaWxsOm5vbmU7c3Ryb2tlLXdpZHRoOjU7c3Ryb2tlLWxpbmVjYXA6cm91bmQ7c3Ryb2tlLWxpbmVqb2luOnJvdW5kO3N0cm9rZTpyZ2IoMjUlLDI1JSwyNSUpO3N0cm9rZS1vcGFjaXR5OjE7c3Ryb2tlLW1pdGVybGltaXQ6MTA7IiBkPSJNIDUwMjYuODM1OTM4IDY1Mi41ODQzNzUgTCA1MDI2LjgzNTkzOCA3MjcuNTg0Mzc1ICIgdHJhbnNmb3JtPSJtYXRyaXgoMC4xLDAsMCwtMC4xLDAsMTIwLjExKSIvPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMSIgeD0iMjAuMDM5OCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMSIgeD0iMTEuNjM5OCIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDU4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA1OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMiIgeD0iMTcuNzU5Nzk5IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDYxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSIyMy4yNzk3OTgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgyLTEiIHg9IjMwLjM2MDEiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0yIiB4PSI2NC40Mzk4IiB5PSI4MS44Mjk5Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNjYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xIiB4PSI1NS45MTk4OCIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDY4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA2OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMiIgeD0iNjIuMDM5ODg0IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDcxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0zIiB4PSI2Ny41NTk4NzkiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgyLTIiIHg9Ijc0Ljc2MDA4IiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgzLTEiIHg9Ijg4LjkxOTkiIHk9Ijc1LjcxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMy0xIiB4PSI5My41OTk5OSIgeT0iNzUuNzEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgzLTEiIHg9Ijk4LjI4MDA4IiB5PSI3NS43MSIvPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC0zIiB4PSIxMjIuNCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDc2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMSIgeD0iMTA4LjM2MDIiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA3OCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwNzkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTIiIHg9IjExNC40ODAxOTgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4MCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTMiIHg9IjEyMC4wMDAxOTkiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwODMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg0LTEiIHg9IjEyNy4yIiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDUtMSIgeD0iMTMyLjQ4MDA4IiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDItMSIgeD0iMTM4LjI0MDI0IiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDg4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA4OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtNCIgeD0iMTY3LjA0IiB5PSI4MS44Mjk5Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDkxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xIiB4PSIxNTcuNDQiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTIiIHg9IjE2My41NTk5OTgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTMiIHg9IjE2OS4wNzk5OTkiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5NikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwOTcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg0LTEiIHg9IjE3Ni4yODAyIiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDk4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXA5OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNCIgeD0iMjA2LjA0IiB5PSI3NS4yMjk4NSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwMCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTAxKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIyMTAuOTU5OTE5IiB5PSI3NS4yMjk4NSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTAzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIyMTUuMzk5OTA4IiB5PSI3NS4yMjk4NSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwNCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS03IiB4PSIyMTguNzU5OTIzIiB5PSI3NS4yMjk4NSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEwNikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA3KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIyMjMuNzk5OTEiIHk9Ijc1LjIyOTg1Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTA4KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMDkpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTgiIHg9IjIyOC4yMzk5MjQiIHk9Ijc1LjIyOTg1Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTEwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTEiIHg9IjI3OSIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTEzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS05IiB4PSIyNjkuMjgwMDgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTAiIHg9IjI3NS44ODAwNjgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMTYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iMjgzLjA4MDA3NyIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDExOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTE5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0xIiB4PSIyOTAuMzk5OTgiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTIwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMjEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgwLTIiIHg9IjMzNi44NCIgeT0iODEuODI5OSIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyMikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTIzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS05IiB4PSIzMjcuMjQiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMjQpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyNSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTAiIHg9IjMzMy44Mzk5ODgiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMjYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyNykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iMzQxLjAzOTk5NyIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEyOCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTI5KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMi0yIiB4PSIzNDguMjQiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDMtMSIgeD0iMzcxLjE2IiB5PSI3NS43MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDMtMSIgeD0iMzc1Ljg0MDEwMiIgeT0iNzUuNzEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgzLTEiIHg9IjM4MC41MjAyMDQiIHk9Ijc1LjcxIi8+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzMSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDAtMyIgeD0iNDE0LjQ4IiB5PSI4MS44Mjk5Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTMyKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzMpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTkiIHg9IjM5OS4zNjAxIiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTM0KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzUpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEwIiB4PSI0MDUuOTYwMDg4IiB5PSI3MC42Njk3Ii8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTM2KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzcpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTMiIHg9IjQxMy4xNjAwOTciIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxMzgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDEzOSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDQtMSIgeD0iNDIwLjM2MDEiIHk9IjcyLjEwOTkzIi8+CjwvZz4KPC9nPgo8L2c+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQwKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDEpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg1LTEiIHg9IjQyNS42NDAxOCIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDIpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0MykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDItMSIgeD0iNDMxLjQwMDM0IiB5PSI3Mi4xMDk5MyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0NCkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTQ1KSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMC00IiB4PSI0NzIuNjgiIHk9IjgxLjgyOTkiLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDYpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0NykiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOSIgeD0iNDYxLjk5OTkiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNDgpIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE0OSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTAiIHg9IjQ2OC41OTk5MTIiIHk9IjcwLjY2OTciLz4KPC9nPgo8L2c+CjwvZz4KPGcgY2xpcC1wYXRoPSJ1cmwoI2NsaXAxNTApIiBjbGlwLXJ1bGU9Im5vbnplcm8iPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1MSkiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMyIgeD0iNDc1Ljc5OTkyMSIgeT0iNzAuNjY5NyIvPgo8L2c+CjwvZz4KPC9nPgo8ZyBjbGlwLXBhdGg9InVybCgjY2xpcDE1MikiIGNsaXAtcnVsZT0ibm9uemVybyI+CjxnIGNsaXAtcGF0aD0idXJsKCNjbGlwMTUzKSIgY2xpcC1ydWxlPSJub256ZXJvIj4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNC0xIiB4PSI0ODIuOTk5OSIgeT0iNzIuMTA5OTMiLz4KPC9nPgo8L2c+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMSIgeD0iMTE3LjEyIiB5PSI1My41MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMTIyLjYzOTk5IiB5PSI1My41MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtNSIgeD0iMTI1LjM5OTk5NyIgeT0iNTMuNTEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEyIiB4PSIxMzIuMzU5ODM3IiB5PSI1My41MSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTEiIHg9IjEzOS4zMiIgeT0iNDIuNTkwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMTQ0LjgzOTk5IiB5PSI0Mi41OTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIxNDcuNTk5OTk3IiB5PSI0Mi41OTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xMyIgeD0iMTU0LjU1OTgzNyIgeT0iNDIuNTkwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDYtMSIgeD0iMTU4LjYzOTkiIHk9IjMxLjU0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg2LTEiIHg9IjE2Mi40Nzk0MDIiIHk9IjMxLjU0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg2LTEiIHg9IjE2Ni4zMTg5MDQiIHk9IjMxLjU0OTkiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTExIiB4PSIxNTkuNDgwMTM0IiB5PSIyMC42MyIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMTY1LjAwMDEyNCIgeT0iMjAuNjMiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjE2Ny43NjAxMzEiIHk9IjIwLjYzIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoNy0xIiB4PSIxNzQuNjAwMDM0IiB5PSIyMC42MyIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDYtMiIgeD0iMTgzLjIzOTg3NCIgeT0iMjAuNjMiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTEyIiB4PSIxOTIuNDc5NzE0IiB5PSIyMC42MyIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTEiIHg9IjE4OS4zNjAxODQiIHk9IjkuNzEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMTk0Ljg4MDE3NCIgeT0iOS43MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIxOTcuNjQwMTgxIiB5PSI5LjcxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGg3LTEiIHg9IjIwNC41OTk5ODQiIHk9IjkuNzEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTQiIHg9IjM0NC42Mzk5ODQiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTUiIHg9IjM0OS4wNzk5NzMiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTciIHg9IjM1My41MTk5ODciIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE1IiB4PSIzNTguNTU5OTc0IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIzNjEuMzE5OTkzIiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNiIgeD0iMzY0LjY3OTk4NCIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtOCIgeD0iMzY5LjExOTk5OCIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTciIHg9IjM3NC4yNzk4NDgiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE4IiB4PSIzNzkuMzE5ODM1IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS02IiB4PSIzODIuMDc5ODU0IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS01IiB4PSIzODUuNDM5ODciIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTE0IiB4PSIzODkuODc5ODU5IiB5PSI1My41MTAxIi8+CjwvZz4KPGcgc3R5bGU9ImZpbGw6cmdiKDAlLDAlLDAlKTtmaWxsLW9wYWNpdHk6MTsiPgogIDx1c2UgeGxpbms6aHJlZj0iI2dseXBoMS0xNSIgeD0iMzk0LjMxOTg0OCIgeT0iNTMuNTEwMSIvPgo8L2c+CjxnIHN0eWxlPSJmaWxsOnJnYigwJSwwJSwwJSk7ZmlsbC1vcGFjaXR5OjE7Ij4KICA8dXNlIHhsaW5rOmhyZWY9IiNnbHlwaDEtMTkiIHg9IjM5Ny4wNzk4NjciIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTYiIHg9IjQwMi4xMTk4NTQiIHk9IjUzLjUxMDEiLz4KPC9nPgo8ZyBzdHlsZT0iZmlsbDpyZ2IoMCUsMCUsMCUpO2ZpbGwtb3BhY2l0eToxOyI+CiAgPHVzZSB4bGluazpocmVmPSIjZ2x5cGgxLTIwIiB4PSI0MDUuNDc5ODciIHk9IjUzLjUxMDEiLz4KPC9nPgo8L2c+Cjwvc3ZnPgo=)
A DEFLATE stream is a sequence of blocks, where each block may be compressed or non-compressed. Compressed blocks are what we usually think of; for example the kernel is one big compressed block. But there are also non-compressed blocks, which start with a 5-byte header with a length field that means simply, "output the next n bytes verbatim." Decompressing a non-compressed block means only stripping the 5-byte header. Compressed and non-compressed blocks may be intermixed freely in a DEFLATE stream. The output is the concatenation of decompressing all the blocks in order. The "non-compressed" notion only has meaning at the DEFLATE layer; the file data still counts as "compressed" at the zip layer, no matter what kind of blocks are used.
It is easiest to understand this quoted-overlap construction from the inside out, beginning with the last file and working backwards to the first. Start by inserting the kernel, which will form the end of file data for every file. Prepend a local file header LFHN and add a central directory header CDHN that points to it. Set the "compressed size" metadata field in the LFHN and CDHN to the compressed size of the kernel. Now prepend a 5-byte non-compressed block header (colored green in the diagram) whose length field is equal to the size of LFHN. Prepend a second local file header LFHN−1 and add a central directory header CDHN−1 that points to it. Set the "compressed size" metadata field in both of the new headers to the compressed size of the kernel plus the size of the non-compressed block header (5 bytes) plus the size of LFHN.
At this point the zip file contains two files, named "Y" and "Z". Let's walk through what a zip parser would see while parsing it. Suppose the compressed size of the kernel is 1000 bytes and the size of LFHN is 31 bytes. We start at CDHN−1 and follow the pointer to LFHN−1. The first file's filename is "Y" and the compressed size of its file data is 1036 bytes. Interpreting the next 1036 bytes as a DEFLATE stream, we first encounter the 5-byte header of a non-compressed block that says to copy the next 31 bytes. We write the next 31 bytes, which are LFHN, which we decompress and append to file "Y". Moving on in the DEFLATE stream, we find a compressed block (the kernel), which we decompress to file "Y". Now we have reached the end of the compressed data and are done with file "Y". Proceeding to the next file, we follow the pointer from CDHN to LFHN and find a file named "Z" whose compressed size is 1000 bytes. Interpreting those 1000 bytes as a DEFLATE stream, we immediately encounter a compressed block (the kernel again) and decompress it to the file "Z". Now we have reached the end of the final file and are done. The output file "Z" contains the decompressed kernel; the output file "Y" is the same, but additionally prefixed by the 31 bytes of LFHN.
We complete the construction by repeating the quoting procedure until the zip file contains the desired number of files. Each new file adds a central directory header, a local file header, and a non-compressed block to quote the immediately succeeding local file header. Compressed file data is generally a chain of DEFLATE non-compressed blocks (the quoted local file headers) followed by the compressed kernel. Each byte in the kernel contributes about 1032 N to the output size, because each byte is part of all N files. The output files are not all the same size: those that appear earlier in the zip file are larger than those that appear later, because they contain more quoted local file headers. The contents of the output files are not particularly meaningful, but no one said they had to make sense.
This quoted-overlap construction has better compatibility than the full-overlap construction of the previous section, but the compatibility comes at the expense of the compression ratio. There, each added file cost only a central directory header; here, it costs a central directory header, a local file header, and another 5 bytes for the quoting header.
Optimization
Now that we have the basic zip bomb construction, we will try to make it as efficient as possible. We want to answer two questions:
- For a given zip file size, what is the maximum compression ratio?
- What is the maximum compression ratio, given the limits of the zip format?
Kernel compression
It pays to compress the kernel as densely as possible, because every decompressed byte gets magnified by a factor of N. To that end, we use a custom DEFLATE compressor called bulk_deflate, specialized for compressing a string of repeated bytes.
All decent DEFLATE compressors will approach a compression ratio of 1032 when given an infinite stream of repeating bytes, but we care more about specific finite sizes than asymptotics. bulk_deflate compresses more data into the same space than the general-purpose compressors: about 26 kB more than zlib and Info-ZIP, and about 15 kB more than Zopfli, a compressor that trades speed for density.

The price of bulk_deflate's high compression ratio is a lack of generality. bulk_deflate can only compress strings of a single repeated byte, and only those of specific lengths, namely 517 + 258 k for integer k ≥ 0. Besides compressing densely, bulk_deflate is fast, doing essentially constant work regardless of the input size, aside from the work of actually writing out the compressed string.
Filenames
For our purposes, filenames are mostly dead weight. While filenames do contribute something to the output size by virtue of being part of quoted local file headers, a byte in a filename does not contribute nearly as much as a byte in the kernel. We want filenames to be as short as possible, while keeping them all distinct, and subject to compatibility considerations.
The first compatibility consideration is character encoding. The zip format specification states that filenames are to be interpreted as CP 437, or UTF-8 if a certain flag bit is set (APPNOTE.TXT Appendix D). But this is a major point of incompatibility across zip parsers, which may interpret filenames as being in some fixed or locale-specific encoding. So for compatibility, we must limit ourselves to characters that have the same encoding in both CP 437 and UTF-8; namely, the 95 printable characters of US-ASCII.
We are further restricted by filesystem naming limitations. Some filesystems are case-insensitive, so "a" and "A" do not count as distinct names. Common filesystems like FAT32 prohibit certain characters like '*' and '?'.
As a safe but not necessarily optimal compromise, our zip bomb will use filenames consisting of characters drawn from a 36-character alphabet that does not rely on case distinctions or use special characters:
Filenames are generated in the obvious way, cycling each position through the possible characters and adding a position on overflow:
"00", "01", "02", …, "0Z",
…,
"Z0", "Z1", "Z2", …, "ZZ",
"000", "001", "002", …
There are 36 filenames of length 1, 362 filenames of length 2, and so on. The length of the nth filename is ⌊log36((n + 1) / (36 / 35))⌋ + 1. Four bytes are enough to represent 1 727 604 distinct filenames.
Given that the N filenames in the zip file are generally not all of the same length, which way should we order them, shortest to longest or longest to shortest? A little reflection shows that it is better to put the longest names last, because those names are the most quoted. Ordering filenames longest last adds over 900 MB of output to zblg.zip, compared to ordering them longest first. It is a minor optimization, though, as those 900 MB comprise only 0.0003% of the total output size.
Kernel size
The quoted-overlap construction allows us to place a compressed kernel of data, and then cheaply copy it many times. For a given zip file size X, how much space should we devote to storing the kernel, and how much to making copies?
To find the optimum balance, we only have to optimize the single variable N, the number of files in the zip file. Every value of N requires a certain amount of overhead for central directory headers, local file headers, quoting block headers, and filenames. All the remaining space can be taken up by the kernel. Because N has to be an integer, and you can only fit so many files before the kernel size drops to zero, it suffices to test every possible value of N and select the one that yields the most output.
Applying the optimization procedure to X = 42 374, the size of 42.zip, finds a maximum at N = 250. Those 250 files require 21 195 bytes of overhead, leaving 21 179 bytes for the kernel. A kernel of that size decompresses to 21 841 249 bytes (a ratio of 1031.3). The 250 copies of the decompressed kernel, plus the little bit extra that comes from the quoted local file headers, produces an overall unzipped output of 5 461 307 620 bytes and a compression ratio of 129 thousand.
 zbsm.zip
42 kB → 5.5 GB
zbsm.zip
42 kB → 5.5 GB
zipbomb --mode=quoted_overlap --num-files=250 --compressed-size=21179 > zbsm.zip
Optimization produced an almost even split between the space allocated to the kernel and the space allocated to file headers. It is not a coincidence. Let's look at a simplified model of the quoted-overlap construction. In the simplified model, we ignore filenames, as well as the slight increase in output file size due to quoting local file headers. Analysis of the simplified model will show that the optimum split between kernel and file headers is approximately even, and that the output size grows quadratically when allocation is optimal.
Define some constants and variables:
| X | zip file size (take as fixed) | |
| N | number of files in the zip file (variable to optimize) | |
| CDH | = 46 | size of a central directory header (without filename) |
| LFH | = 30 | size of a local file header (without filename) |
| Q | = 5 | the size of DEFLATE non-compressed block header |
| C | ≈ 1032 | compression ratio of the kernel |
Let H(N) be the amount of header overhead required by N files. Refer to the diagram to understand where this formula comes from.
| H(N) | = N ⋅ (CDH + LFH) + (N − 1) ⋅ Q |
The space remaining for the kernel is X − H(N). The total unzipped size SX(N) is the size of N copies of the kernel, decompressed at ratio C. (In this simplified model we ignore the minor additional expansion from quoted local file headers.)
| SX(N) | = (X − H(N)) C N |
| = (X − (N ⋅ (CDH + LFH) + (N − 1) ⋅ Q)) C N | |
| = −(CDH + LFH + Q) C N2 + (X + Q) C N |
SX(N) is a polynomial in N, so its maximum must be at a place where the derivative S′X(N) is zero. Taking the derivative and finding the zero gives us NOPT, the optimal number of files.
| S′X(NOPT) | = −2 (CDH + LFH + Q) C NOPT + (X + Q) C |
| 0 | = −2 (CDH + LFH + Q) C NOPT + (X + Q) C |
| NOPT | = (X + Q) / (CDH + LFH + Q) / 2 |
H(NOPT) gives the optimal amount of space to allocate for file headers. It is independent of CDH, LFH, and C, and is close to X / 2.
| H(NOPT) | = NOPT ⋅ (CDH + LFH) + (NOPT − 1) ⋅ Q |
| = (X − Q) / 2 |
SX(NOPT) is the total unzipped size when the allocation is optimal. From this we see that the output size grows quadratically in the input size.
| SX(NOPT) | = (X + Q)2 C / (CDH + LFH + Q) / 4 |
As we make the zip file larger, eventually we run into the limits of the zip format. A zip file can contain at most 216 − 1 files, and each file can have an uncompressed size of at most 232 − 1 bytes. Worse than that, some implementations take the maximum possible values as an indicator of the presence of 64-bit extensions, so our limits are actually 216 − 2 and 232 − 2. It happens that the first limit we hit is the one on uncompressed file size. At a zip file size of 8 319 377 bytes, naive optimization would give us a file count of 47 837 and a largest file of 232 + 311 bytes.
Accepting that we cannot increase N nor the size of the kernel without bound, we would like find the maximum compression ratio achievable while remaining within the limits of the zip format. The way to proceed is to make the kernel as large as possible, and have the maximum number of files. Even though we can no longer maintain the roughly even split between kernel and file headers, each added file does increase the compression ratio—just not as fast as it would if we were able to keep growing the kernel, too. In fact, as we add files we will need to decrease the size of the kernel to make room for the maximum file size that gets slightly larger with each added file.
The plan results in a zip file that contains 216 − 2 files and a kernel that decompresses to 232 − 2 178 825 bytes. Files get longer towards the beginning of the zip file—the first and largest file decompresses to 232 − 56 bytes. That is as close as we can get using the coarse output sizes of bulk_deflate—encoding the final 54 bytes would cost more bytes than they are worth. (The zip file as a whole has a compression ratio of 28 million, and the final 54 bytes would gain at most 54 ⋅ 1032 ⋅ (216 − 2) ≈ 36.5 million bytes, so it only helps if the 54 bytes can be encoded in 1 byte—I could not do it in less than 2.) so unless you can encode the 54 bytes into 1 byte, it only lowers the compression ratio.) The output size of this zip bomb, 281 395 456 244 934 bytes, is 99.97% of the theoretical maximum (232 − 1) ⋅ (216 − 1). Any major improvements to the compression ratio can only come from reducing the input size, not increasing the output size.
zblg.zip
10 MB → 281 TB
zipbomb --mode=quoted_overlap --num-files=65534 --max-uncompressed-size=4292788525 > zblg.zip
Efficient CRC-32 computation
Among the metadata in the central directory header and local file header
is a
CRC-32
checksum of the uncompressed file data.
This poses a problem, because directly calculating the CRC-32 of each file
requires doing work proportional to the total unzipped size,
which is large by design. (It's a zip bomb, after all.)
We would prefer to do work that in the worst case is
proportional to the zipped size.
Two factors work in our advantage:
all files share a common suffix (the kernel),
and the uncompressed kernel is a string of repeated bytes.
We will represent CRC-32 as a matrix product—this
will allow us not only to compute the checksum of the kernel quickly,
but also to reuse computation across files.
The technique described in this section is a slight extension of the
crc32_combine
function in zlib,
which Mark Adler explains
here.
You can model CRC-32 as a state machine that updates a 32-bit state register for each incoming bit. The basic update operations for a 0 bit and a 1 bit are:
uint32 crc32_update_0(uint32 state) {
// Shift out the least significant bit.
bit b = state & 1;
state = state >> 1;
// If the shifted-out bit was 1, XOR with the CRC-32 constant.
if (b == 1)
state = state ^ 0xedb88320;
return state;
}
uint32 crc32_update_1(uint32 state) {
// Do as for a 0 bit, then XOR with the CRC-32 constant.
return crc32_update_0(state) ^ 0xedb88320;
}
If you think of the state register as a 32-element binary vector,
and use XOR for addition and AND for multiplication, then
crc32_update_0 is a
linear transformation;
i.e., it can be represented as multiplication by a
32×32 binary
transformation matrix.
To see why, observe that multiplying a matrix by a vector
is just summing the columns of the matrix,
after multiplying each column by the corresponding element of the vector.
The shift operation state >> 1
is just taking each bit i of the state vector
and multiplying it by a vector that is 0 everywhere except at bit i − 1
(numbering the bits from right to left).
The conditional final XOR state ^ 0xedb88320
that only happens when bit b is 1
can instead be represented as first multiplying
b by 0xedb88320
and then XORing it into the state.
Furthermore, crc32_update_1 is just
crc32_update_0 plus (XOR) a constant.
That makes crc32_update_1 an
affine transformation:
a matrix multiplication followed by a translation (i.e., vector addition).
We can represent both the matrix multiplication and the translation
in a single step
if we enlarge the dimensions of the transformation matrix to 33×33
and append an extra element to the state vector that is always 1.
(This representation is called
homogeneous coordinates.)
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
state >> 1.
Both operations crc32_update_0 and crc32_update_1
can be represented by a 33×33 transformation matrix.
The matrices M0 and M1 are shown.
The benefit of a matrix representation is that matrices compose.
Suppose we want to represent the state change effected by processing
the ASCII character 'a', whose binary representation is
011000012.
We can represent the cumulative CRC-32 state change of those 8 bits
in a single transformation matrix:
| Ma | = M0 M1 M1 M0 M0 M0 M0 M1 |
And we can represent the state change of a string of repeated 'a's by multiplying many copies of Ma together—matrix exponentiation. We can do matrix exponentiation quickly using a square-and-multiply algorithm, which allows us to compute Mn in only about log2 n steps. For example, the matrix representing the state change of a string of 9 'a's is
(Ma)9 | = Ma Ma Ma Ma Ma Ma Ma Ma Ma |
= (Ma Ma Ma Ma)2 Ma |
|
= ((Ma Ma)2)2 Ma |
|
= (((Ma)2)2)2 Ma |
The square-and-multiply algorithm is useful for computing Mkernel, the matrix for the uncompressed kernel, because the kernel is a string of repeated bytes. To produce a CRC-32 checksum value from a matrix, multiply the matrix by the zero vector. (The zero vector in homogeneous coordinates, that is: 32 0's followed by a 1. Here we omit the minor complication of pre- and post-conditioning the checksum.) To compute the checksum for every file, we work backwards. Start by initializing M := Mkernel. The checksum of the kernel is also the checksum of the final file, file N, so multiply M by the zero vector and store the resulting checksum in CDHN and LFHN. The file data of file N − 1 is the same as the file data of file N, but with an added prefix of LFHN. So compute MLFHN, the state change matrix for LFHN, and update M := M MLFHN. Now M represents the cumulative state change from processing LFHN followed by the kernel. Compute the checksum for file N − 1 by again multiplying M by the zero vector. Continue the procedure, accumulating state change matrices into M, until all the files have been processed.
Extension: Zip64
Earlier we hit a wall on expansion due to limits of the zip format—it was impossible to produce more than about 281 TB of output, no matter how cleverly packed the zip file. It is possible to surpass those limits using Zip64, an extension to the zip format that increases the size of certain header fields to 64 bits. Support for Zip64 is by no means universal, but it is one of the more commonly implemented extensions. As regards the compression ratio, the effect of Zip64 is to increase the size of a central directory header from 46 bytes to 58 bytes, and the size of a local directory header from 30 bytes to 50 bytes. Referring to the formula for optimal expansion in the simplified model, we see that a zip bomb in Zip64 format still grows quadratically, but more slowly because of the larger denominator—this is visible in the figure below in the Zip64 line's slightly lower vertical placement. In exchange for the loss of compatibility and slower growth, we get the removal of all practical file size limits.
Suppose we want a zip bomb that expands to 4.5 PB, the same size that 42.zip recursively expands to. How big must the zip file be? Using binary search, we find that the smallest zip file whose unzipped size exceeds the unzipped size of 42.zip has a zipped size of 46 MB.
zbxl.zip
46 MB → 4.5 PB (Zip64, less compatible)
zipbomb --mode=quoted_overlap --num-files=190023 --compressed-size=22982788 --zip64 > zbxl.zip
4.5 PB is roughly the size of the data captured by the Event Horizon Telescope to make the first image of a black hole, stacks and stacks of hard drives.
With Zip64, it's no longer practically interesting to consider the maximum compression ratio, because we can just keep increasing the zip file size, and the compression ratio along with it, until even the compressed zip file is prohibitively large. An interesting threshold, though, is 264 bytes (18 EB or 16 EiB)—that much data will not fit on most filesystems. Binary search finds the smallest zip bomb that produces at least that much output: it contains 12 million files and has a compressed kernel of 1.5 GB. The total size of the zip file is 2.9 GB and it unzips to 264 + 11 727 895 877 bytes, having a compression ratio of over 6.2 billion. I didn't make this one downloadable, but you can generate it yourself using the source code. It contains files so large that it uncovers a bug in Info-ZIP UnZip 6.0.
zipbomb --mode=quoted_overlap --num-files=12056313 --compressed-size=1482284040 --zip64 > zbxxl.zip
Extension: bzip2
DEFLATE is the most common compression algorithm used in the zip format, but it is only one of many options. Probably the second most common algorithm is bzip2, while not as compatible as DEFLATE, is probably the second most commonly supported compression algorithm. Empirically, bzip2 has a maximum compression ratio of about 1.4 million, which allows for denser packing of the kernel. Ignoring the loss of compatibility, does bzip2 enable a more efficient zip bomb?
Yes—but only for small files. The problem is that bzip2 does not have anything like the non-compressed blocks of DEFLATE that we used to quote local file headers. So it is not possible to overlap files and reuse the kernel—each file must have its own copy, and therefore the overall compression ratio is no better than the ratio of any single file. In the figure we see that no-overlap bzip2 outperforms quoted DEFLATE only for files under about a megabyte.
There is still hope for using bzip2—an alternative means of local file header quoting discussed in the next section. Additionally, if you happen to know that a certain zip parser supports bzip2 and tolerates mismatched filenames, then you can use the full-overlap construction, which has no need for quoting.

Extension: extra-field quoting
So far we have used a feature of DEFLATE to quote local file headers, and we have just seen that the same trick does not work with bzip2. There is an alternative means of quoting, somewhat more limited, that only uses features of the zip format and does not depend on the compression algorithm.
At the end of the local file header structure there is a variable-length extra field whose purpose is to store information that doesn't fit into the ordinary fields of the header (APPNOTE.TXT section 4.3.7). The extra information may include, for example, a high-resolution timestamp or a Unix uid/gid; Zip64 works by using the extra field. The extra field is a length–value structure: if we increase the length field without adding to the value, then it will grow to include whatever comes after it in the zip file—namely the next local file header. Each local file header "quotes" the local file headers that follow it by enclosing them within its own extra field. The benefits of extra-field quoting over DEFLATE quoting are threefold:
- Extra-field quoting requires only 4 bytes of overhead, not 5, leaving more room for the kernel.
- Extra-field quoting does not increase the size of files, which leaves more headroom for a bigger kernel when operating at the limits of the zip format.
- Extra-field quoting provides a way to combine quoting with bzip2.
Despite these benefits, extra-field quoting is less flexible than DEFLATE quoting. It does not chain: each local file header must enclose not only the immediately next header but all headers which follow. The extra fields increase in length as they get closer to the beginning of the zip file. Because the extra field has a maximum length of 216 − 1 bytes, it can only contain up to 1808 local file headers, or 1170 with Zip64, assuming that filenames are allocated as described. (With DEFLATE, you can use extra-field quoting for the earliest local file headers, then switch to DEFLATE quoting for the remainder.) Another problem is that, in order to conform to the internal data structure of the extra field, you must select a 16-bit header ID (APPNOTE.TXT section 4.5.2). to precede the quoted data. We want a header ID that will make parsers ignore the quoted data, not try to interpret it as meaningful metadata. Zip parsers are supposed to ignore unknown header IDs, so we could choose one at random, but there is the risk that the ID may be allocated in the future, breaking compatibility.
The figure illustrates the possibility of combining extra-field quoting with bzip2, with and without Zip64. Both "extra-field-quoted bzip2" lines have a knee at which the growth transitions from quadratic to linear. In the non-Zip64 case, the knee occurs at the maximum uncompressed file size (232 − 2 bytes); after this point, one can only increase the number of files, not their size. The line stops completely when the number of files reaches 1809, and we run out of room in the extra field. In the Zip64 case, the knee occurs at 1171 files, after which the size of files can be increased, but not their number. Extra-field quoting may also be used with DEFLATE, but the improvement is so slight that it has been omitted from the figure. It increases the compression ratio of zbsm.zip by 1.2%; zblg.zip by 0.019%; and zbxl.zip by 0.0025%.
Discussion
In related work, Plötz et al. used overlapping files to create a near-self-replicating zip file. Gynvael Coldwind has previously suggested (slide 47) overlapping files. Pellegrino et al. found systems vulnerable to compression bombs and other resource exhaustion attacks and listed common pitfalls in specification, implementation, and configuration.
We have designed the quoted-overlap zip bomb construction for compatibility, taking into consideration a number of implementation differences, some of which are shown in the table below. The resulting construction is compatible with zip parsers that work in the usual back-to-front way, first consulting the central directory and using it as an index of files. Among these is the example zip parser included in Nail, which is automatically generated from a formal grammar. The construction is not compatible, however, with "streaming" parsers, those that parse the zip file from beginning to end in one pass without first reading the central directory. By their nature, streaming parsers do not permit any kind of file overlapping. The most likely outcome is that they will extract only the first file. They may even raise an error besides, as is the case with sunzip, which parses the central directory at the end and checks it for consistency with the local file headers it has already seen.
If you need the extracted files to start with a certain prefix
(so that they will be identified as a certain file type, for example),
you can insert a data-carrying DEFLATE block just before the
block that quotes the next header.
Not every file has to participate in the bomb construction:
you can include ordinary files
alongside the bomb files
if you need the zip file to conform to some higher-level format.
(The source code has a --template
option to facilitate this use case.)
Many file formats use zip as a container;
examples are Java JAR, Android APK, and LibreOffice documents.
PDF is in many ways similar to zip. It has a cross-reference table at the end of the file that points to objects earlier in the file, and it supports DEFLATE compression of objects through the FlateDecode filter. Didier Stevens writes about having contained a 1 GB stream inside a 2.6 kB PDF file by stacking FlateDecode filters. If a PDF parser limits the amount of stacking, then it is probably possible to use the DEFLATE quoting idea to overlap PDF objects.
Detecting the specific class of zip bomb we have developed in this article is easy: look for overlapping files. Mark Adler has written a patch for Info-ZIP UnZip that does just that. In general, though, rejecting overlapping files does not by itself make it safe to handle untrusted zip files. There are zip bombs that do not rely on overlapping files, and there are malicious zip files that are not bombs. Furthermore, any such detection logic must be implemented inside the parser itself, not as a separate prefilter. One of the details omitted from the description of the zip format is that there is no single well-defined algorithm for locating the central directory in a zip file: two parsers may find two different central directories and therefore may not even agree on what files a zip file contains (slides 67–80). Predicting the total uncompressed size by summing the sizes of all files does not work, in general, because the sizes stored in metadata may not match (§4.2.2) the actual uncompressed sizes. (See the "permits too-short file size" row in the compatibility table.) Robust protection against zip bombs involves sandboxing the parser to limit its use of time, memory, and disk space—just as if you were processing image files, or any other complex file format prone to parser bugs.
| Info-ZIP UnZip 6.0 |
Python 3.7 zipfile |
Go 1.12 archive/zip |
yauzl 2.10.0 (Node.js) |
Nail examples/zip |
Android 9.0.0 r1 libziparchive |
sunzip 0.4 (streaming) |
|
|---|---|---|---|---|---|---|---|
| DEFLATE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Zip64 | ✓ | ✓ | ✓ | ✓ | ✖ | ✖ | ✓ |
| bzip2 | ✓ | ✓ | ✖ | ✖ | ✖ | ✖ | ✓ |
| permits mismatched filenames | warns | ✖ | ✓ | ✓ | ✓ | ✖ | ✓ |
| permits incorrect CRC-32 | warns | ✖ | if zero | ✓ | ✖ | ✓ | ✖ |
| permits too-short file size | ✓ | ✖ | ✖ | ✖ | ✖ | ✖ | ✖ |
| permits file size of 232 − 1 | ✓ | ✓ | ✓ | ✖ | ✓ | ✓ | ✓ |
| permits file count of 216 − 1 | ✓ | ✓ | ✓ | ✖ | ✓ | ✓ | ✓ |
| unzips overlap.zip | warns | ✖ | ✓ | ✓ | ✓ | ✖ | ✖ |
| unzips zbsm.zip and zblg.zip | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✖ |
| unzips zbxl.zip | ✓ | ✓ | ✓ | ✓ | ✖ | ✖ | ✖ |
Credits
I thank Mark Adler, Blake Burkhart, Gynvael Coldwind, Russ Cox, Brandon Enright, Joran Dirk Greef, Marek Majkowski, Josh Wolfe, and the USENIX WOOT 2019 reviewers for comments on this article or a draft. Caolán McNamara evaluated the security impact of the zip bombs in LibreOffice. @m1rko wrote a Russian translation. 北岸冷若冰霜 wrote a Chinese translation.
A version of this article appeared at the USENIX WOOT 2019 workshop. The workshop talk video, slides, and transcript are available. The source code of the paper is available. The artifacts prepared for submission are zipbomb-woot19.zip.
Did you find a system that chokes on one of these zip bombs? Did they help you demonstrate a vulnerability or win a bug bounty? Let me know and I'll try to mention it here.
- LibreOffice 6.1.5.2
-
zblg.zip renamed to zblg.odt or zblg.docx will cause LibreOffice to create and delete a number of ~4 GB temporary files as it attempts to determine the file format. It does eventually finish, and it deletes the temporary files as it goes, so it's only a temporary DoS that doesn't fill up the disk. Caolán McNamara replied to my bug report.
- Mozilla addons-server 2019.06.06
-
I tried the zip bombs against a local installation of addons-server, which is part of the software behind addons.mozilla.org. The system handles it gracefully, imposing a time limit of on extraction. The zip bomb expands as fast as the disk will let it up to the time limit, but after that point the process is killed and the unzipped files are eventually automatically cleaned up.
- UnZip 6.0
-
Mark Adler wrote a patch for UnZip to detect this class of zip bomb.
: I noticed that CVE-2019-13232 was assigned for UnZip. Personally, I would dispute that UnZip's (or any zip parser's) ability to process a zip bomb of the kind discussed here necessarily represents a security vulnerability, or even a bug. It's a natural implementation and does not violate the specification in any way that I can tell. The type discussed in this article is only one type of zip bomb, and there are many ways in which zip parsing can go wrong that are not bombs. If you want to defend against resource exhaustion attacks, you should not try to enumerate, detect, and block every individual known attack; rather you should impose external limits on time and other resources so that the parser cannot misbehave too much, no matter what kind of attack it faces. There is nothing wrong with attempting to detect and reject certain constructions as a first-pass optimization, but you can't stop there. If you do not eventually isolate and limit operations on untrusted data, your system is likely still vulnerable. Consider an analogy with cross-site scripting in HTML: the right defense is not to try and filter out bytes that may be interpreted as code, it's to escape everything properly.
Mark Adler's patch made its way into Debian in bug #931433. There were some unanticipated consequences: problems parsing certain Java JARs (bug #931895) and problems with the mutant zip format of Firefox's omni.ja file (bug #932404). SUSE decided not to do anything about CVE-2019-13232. I think both Debian's and SUSE's choices are defensible.
- ronomon/zip
-
Shortly after the publication of this article, Joran Dirk Greef published a restrictive zip parser (JavaScript) that prohibits irregularities such as overlapping files or unused space between files. While it may thereby reject certain valid zip files, the idea is to ensure that any downstream parsers will receive only clean, easy-to-parse files.
- antivirus engines
-
Overall, it seems that malware scanners have slowly begun to recognize zip bombs of this kind (or at least the specific samples available for download) as malicious. It would be interesting to see whether the detection is robust or brittle. You could reverse the order of the entries in the central directory, for example, and see whether the zip files are still detected. In the source code, there's a recipe for generating zbsm.extra.zip, which is like zbsm.zip except that it uses extra-field quoting instead of DEFLATE quoting—if you are a customer of an AV service that detects zbsm.zip but not zbsm.extra.zip, you should ask for an explanation. Another simple variant is inserting spacer files between the bomb files, which may fool certain overlap-detection algorithms.
Twitter user @TVqQAAMAAAAEAAA reports "McAfee AV on my test machine just exploded." I haven't independently confirmed it, nor do I have details such as a version number.
Tavis Ormandy points out that there are a number of "Timeout" results in the VirusTotal for zblg.zip (screenshot ). AhnLab-V3, ClamAV, DrWeb, Endgame, F-Secure, GData, K7AntiVirus, K7GW, MaxSecure, McAfee, McAfee-GW-Edition, Panda, Qihoo-360, Sophos ML, VBA32. The results for zbsm.zip (screenshot ) are similar, though with a different set of timed-out engines: Baido, Bkav, ClamAV, CMC, DrWeb, Endgame, ESET-NOD32, F-Secure, GData, Kingsoft, McAfee-GW-Edition, NANO-Antivirus, Acronis. Interestingly, there are no timeouts in the results for zbxl.zip; (screenshot ) perhaps this means that some antivirus doesn't support Zip64?
Forum user 100 reported that a certain ESET product did not detect zbxl.zip, possibly because it uses Zip64. An update in the thread three days later showed the product being updated to detect it.
In ClamAV bug 12356, Hanno Böck reported that zblg.zip caused high CPU usage in clamscan. An initial patch to detect overlapping files turned out to be incomplete because it only checked adjacent pairs of files. (I personally mishandled this issue by posting details of a workaround on the bug tracker, instead of reporting it privately.) A later patch imposed a time limit on file analysis.
In my web server logs, I noticed a number of referers that appear to point to bug trackers.
- http://jira.athr.ru/browse/WEB-12882
- https://project.avira.org/browse/ENGINE-2307
- https://project.avira.org/browse/ENGINE-2363
- https://topdesk-imp.cicapp.nl/tas/secure/mango/window/4
- https://jira-eng-rtp3.cisco.com/jira/browse/AMP4E-4849
- https://jira-eng-sjc1.cisco.com/jira/browse/CLAM-965
- https://flightdataservices.atlassian.net/secure/RapidBoard.jspa?selectedIssue=FDS-136
- https://projects.ucd.gpn.gov.uk/browse/VULN-1483
- https://testrail-int.qa1.immunet.com/index.php?/cases/view/923720
- http://redmine-int-prod.intranet.cnim.net/issues/5596
- https://bugs.drweb.com/view.php?id=159759
- https://dev-jira.dynatrace.org/browse/APM-188227
- https://webgate.ec.europa.eu/CITnet/jira/browse/EPREL-2150
- https://jira.egnyte-it.com/browse/IN-8480
- https://jira.hq.eset.com/browse/CCDBL-1492
- https://bugzilla.olympus.f5net.com/show_bug.cgi?id=819053
- https://mantis.fortinet.com/bug_view_page.php?bug_id=0570222
- https://redmine.joesecurity.org:64998/issues/4705
- http://dev.maildev.jp/mantis/view.php?id=5839
- https://confluence.managed.lu/pages/viewpage.action?pageId=47974242
- https://jira-lvs.prod.mcafee.com/browse/TSWS-653
- https://jira.modulbank.ru/browse/PV-33012
- http://jira.netzwerk.intern:8080/browse/SALES-81
- https://jira-hq.paloaltonetworks.local/browse/CON-43391
- https://jira-hq.paloaltonetworks.local/browse/GSRT-11680
- https://jira-hq.paloaltonetworks.local/browse/PAN-124201
- https://paynearme.atlassian.net/browse/PNM-4494
- https://jira.proofpoint.com/jira/browse/PE-29410
- https://dev.pulsesecure.net/jira/browse/PRS-379163
- https://qualtrics.atlassian.net/browse/APP-326
- https://jira.sastdev.net/browse/CIS-2819
- https://jira.sastdev.net/secure/RapidBoard.jspa?selectedIssue=EC-709
- https://bugzilla.seeburger.de/show_bug.cgi?id=89294
- https://svm.cert.siemens.com/auseno/create_edit_vulnerability.php?vulnid=48573
- https://jira.sophos.net/browse/CPISSUE-6560
- https://jira.vrt.sourcefire.com/browse/TT-1070
- https://task.jarvis.trendmicro.com/browse/JPSE-10432
- https://segjira.trendmicro.com:8443/browse/SEG-55636
- https://segjira.trendmicro.com:8443/browse/SEG-58824
- https://ucsc-cgl.atlassian.net/secure/RapidBoard.jspa?selectedIssue=SEAB-327
- https://jira.withbc.com/browse/BC-43950
- https://zscaler.zendesk.com/agent/tickets/849971
- web browsers
-
I didn't directly experience this myself, but reports online say that Chrome and Safari may automatically unzip files after downloading.
ittakir: "Скачал самый маленький файл на 5GB, Chrome тут же начал его распаковывать, хотя его об этом не просили, ну и кушать процессор и диск." "I downloaded the smallest file on 5GB, Chrome immediately began to unpack it, although it was not asked for it, well, to eat the processor and disk."
Rzah: "Yet another reason why 'Open Safe files after downloading' is a stupid default setting for a web browser."
Chromium commit f04d9b15bd1cba1433ad5453bc3ebff933d0e3bb is perhaps related:
Add metrics detecting anomalously high ZIP compression ratios
It's possible for a single ZIP entry to be very large, even if we only scan small ZIP archives. These metrics will measure how often that occurs.
- filesystems
-
Something I didn't anticipate: unzipping one of the bombs on a compressed filesystem can be relatively safe.
flying_gel: "If I unzip this onto a compressed zfs dataset, will the resulting file be small? Edit: Just did a small test with a 42KB->5.5GB zip bomb. I ended up with 165MB worth of files so while just 3% of the full bomb, it's still a 4028 times inflation. ... I only have the standard LZ4 compression enabled, no dedup."
-
Links to this article had been widely shared on Twitter since around , but around it began showing an "unsafe link" interstitial (screenshot, archive).
- Safe Browsing
-
Sometime around it seems that this page, and every page on a *.bamsoftware.com domain, got added to the Safe Browsing service used by web browsers to block malware and phishing sites. Site status check, block page screenshot. From a few quick checks, it looks like pages on bamsoftware.com have been demoted or delisted on the google.com search engine as well.
The Safe Browsing block is a bit annoying, because it disrupted Snowflake, a completely unrelated service that happened to use the domain snowflake-broker.bamsoftware.com, which did not even host any files but was strictly a web API server. See #31230 Firefox addon blocked from agent by Google Safe Browsing service.
- Xfinity xFi Protected Browsing
-
On , I was informed by Hooman Mohajeri Moghaddam that the Comcast Xfinity xFi "Protected Browsing" feature blocks the bamsoftware.com domain, including this page (screenshot).
- D std.zip
-
The D programming language made a modification to the std.zip module to detect overlapping files.
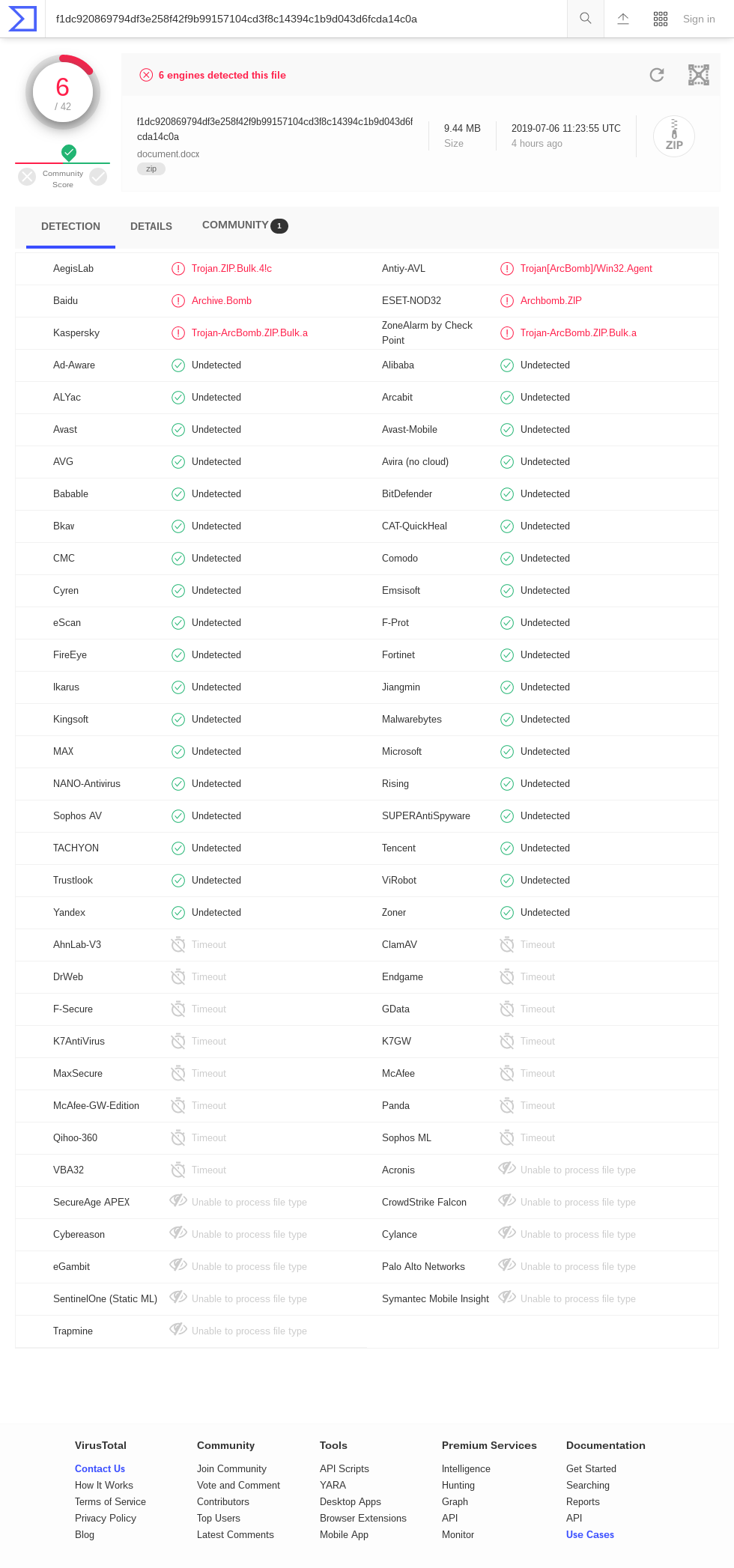{kind=link}
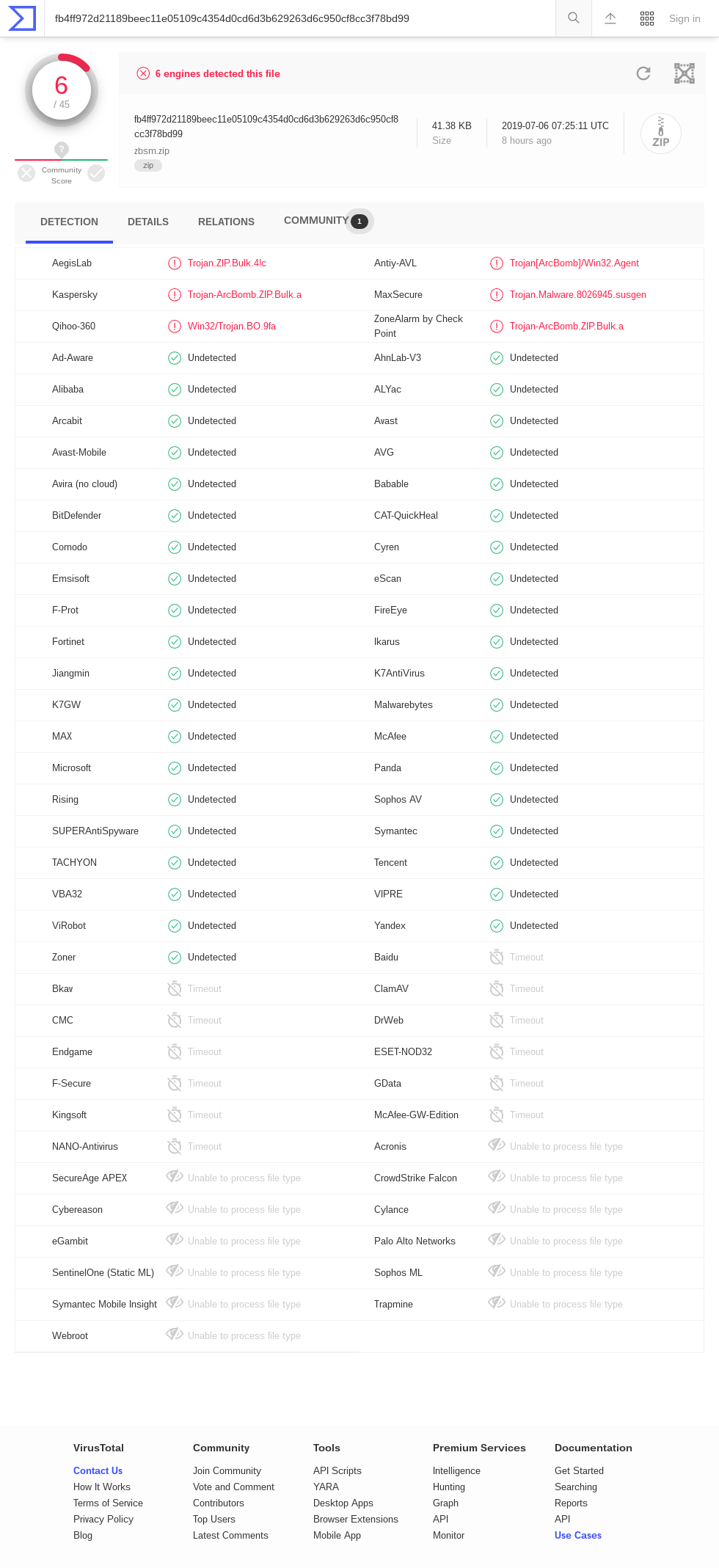{kind=link}
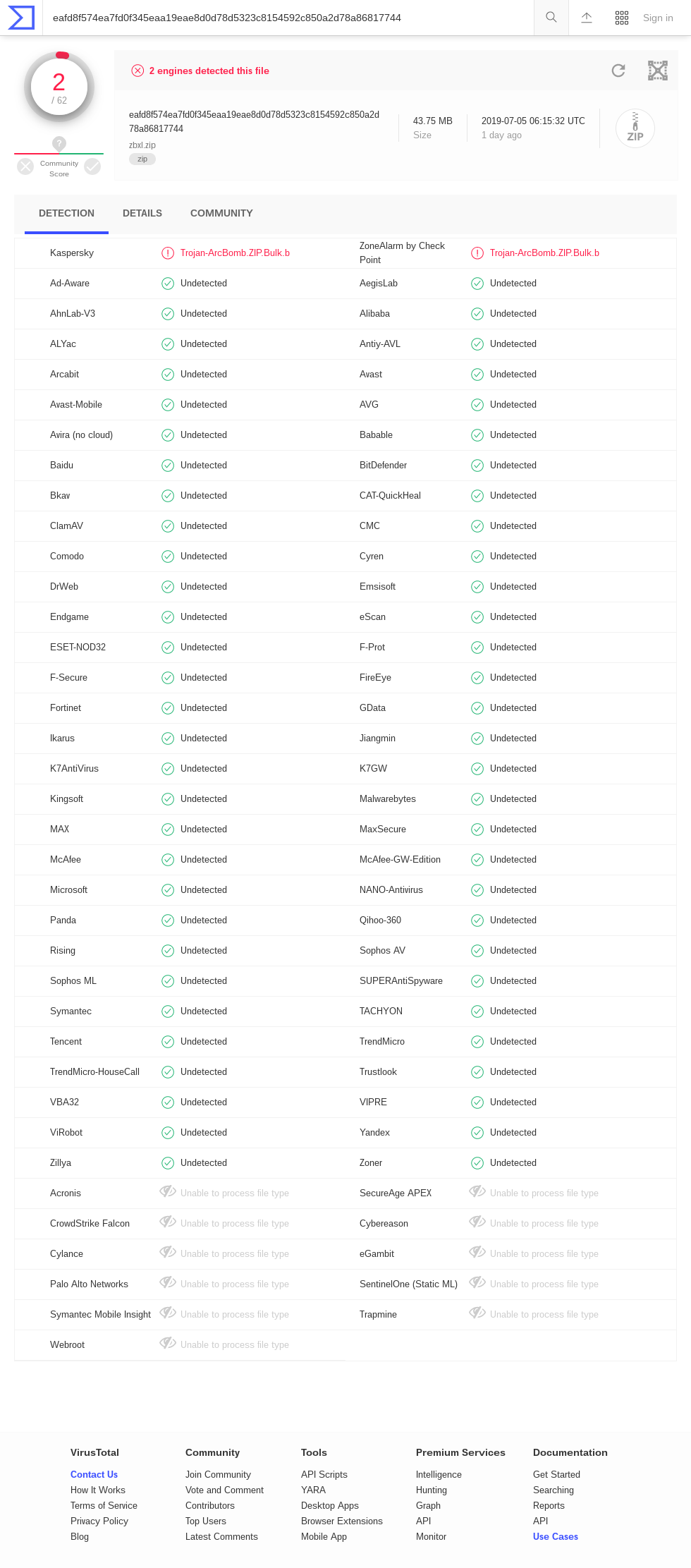{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A final plea
It's time to put an end to Facebook. Working there is not ethically neutral: every day that you go into work, you are doing something wrong. If you have a Facebook account, delete it. If you work at Facebook, quit.
And let us not forget that the National Security Agency must be destroyed.