Maximizing Efficiency in Python — Six Best Practices for Implementing Python3.7 in Production.
Authors: Saleh Alkhalifa and Connor Clancy
Having spent much of the 2019 calendar year both writing and reviewing code, we cannot help but notice a recurring theme that has presented itself over and over. In much of the code we have reviewed, a great deal of the effort is usually attributed towards achieving a higher accuracy, or yielding a better F1 score. However, less effort is usually allocated towards improving the efficiency and overall Pythonic “agility” of various scripts— which was the main motivation for this article. We have noticed that as many data scientists begin to take on larger challenges in the realms of machine learning and natural language processing, many of the smaller first principles of python have a tendency to get lost. Although the lessons we will present here are not new topics and are in no way fully comprehensive, we will present 6 key items that we believe every Python coder should always keep in mind regardless of the project at hand. Please note that we have written this article in an attempt to cater to both experienced and inexperienced coders.
Table of Contents:
- Importing Libraries Efficiently
- Proper Code Style and Documentation
- Accounting for Memory and Efficiency
- Sorting with Efficiency
- Using Multiple Assignment and Variable Assignment
- Efficiency with Numpy Array Transformations
1. Importing Libraries Efficiently:
One of the best features of Python is the overwhelmingly large number of libraries that can be imported to accomplish various objectives and tasks. Libraries are analogous to textbooks containing useful tools and information that you would carry to class or work, with each library or textbook focusing on a specific topic of choice. Similarly to how you would never carry every textbook in your library with you to work, you should not import every library into your script. One example in particular that proves the inefficient use of this practice is the use of the collections library in custom code. Let us go ahead and import the library into our script and namespace:
from collections import *As we import everything from the collections library, we are importing the library in addition to all of its associated functions. This has two inadvertent effects: (1) It will clutter the namespace and cause issues with any previously established functions that happen to have identical names to ones you are currently using, and (2) the overall execution of your script may run slower, the extent of which is dependent on the number (and identity) of the libraries you import in this fashion.
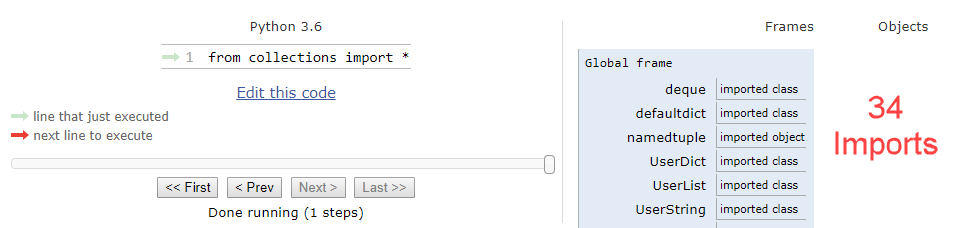
In order to visually examine the number of items imported, we will utilize a website known as pythontutor.com. This site allows you to visually examine (almost) any piece of code in a step-by-step fashion. Although it was originally intended to be used for examining data structures, we will use it today for the purposes of importing libraries into the global frame.
from collections import *
from collections import Counter
# or 'import collections' which will import the module instance
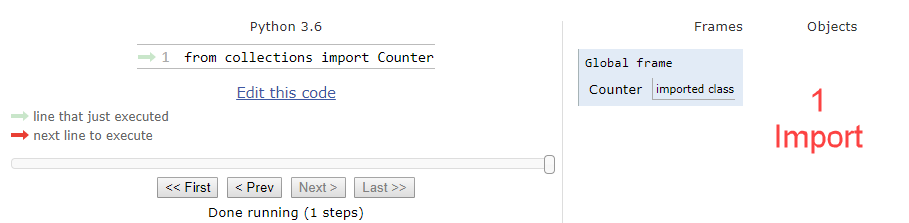
Instead of importing 34 items into our global frame, we can import one. We can quickly test the timing of the two by running some sample code. Take for example Principal Component Analysis which can be imported via scikit-learn. We will create two functions one of which imports sklearn as a whole, and another that imports just PCA from the sklearn library.
# First Import (Bad)
from sklearn import *# Second Import (Good)
from sklearn.decomposition import PCA
In order to develop a metric to compare these two pieces of code, we can import the time library. This library provides the ability to measure the timing of execution of each piece of code. The time library can be used in the following format:
start_time = time.time()from sklearn.decomposition import PCA
# from sklearn import *print("%s seconds" % (time.time() - start_time))
We can go ahead and run a comparison with a previously established script in which the first imports the library as a whole, and the second only imports the PCA component:
Output:
import_all: 1.0039 ms
import_pca: 0.0001 msThe total time taken to import all the packages in sklearn was approximately 1.0039 ms, compared to that of just PCA with a total time of 0.0001ms. While the change here is minor, larger scripts can show drastic differences in time. This change may not be valuable to you in the development phase of your project, but will be crucial (and unnecessarily expensive) in production. In summary, import only the functions that you need. Your code will be cleaner, faster, and more efficient.
2. Use Proper Code Style and Documentation
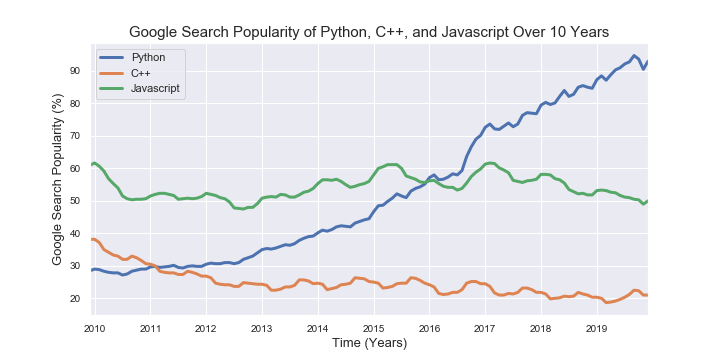
The Python community has seen a large influx of new coders over the last few years, outranking many of the other languages seen across the data science and software engineering industries. The following graph was generated showing the google search popularity taken from GoogleTrends of the search popularity of Python, C++ and JavaScript, showing Python to have increased drastically over the last few years. Given this increase, it is plausible that many more people will know Python, and therefore it is crucial to effectively present, share, and communicate your code.
Much of the code written today will eventually be shared and distributed through various channels, whether it is through internal company platforms, online publications, or GitHub. The moral of the story is that code will be eventually shared, and therefore should be nicely structured and well documented. A personal preference of ours when it comes to structure is the PEP 8 Style Guide for Python. It would be redundant of me to reiterate the lessons you can learn directly from their article, however, there are three main items we hope you will take with you:
First, tab is not always a correct indentation. A correct indentation is defined as exactly four spaces, as shown below. While this will not always cause issues on some interpreters, you should always be consistent with how you indent. As python tutors, we have had at least one student every year complain about an error that was eventually due to an indentation issue. The differences between the two are presented below.
# Using Tab
def someFunction():
print("This is bad")# Using Four Spaces
def someFunction():
print("This is good")
Second, align wrapped elements in a function. When a function containing many elements or arguments is extending to multiple lines, it is best practice to align the arguments using whats known as a hanging indent. Taken directly from the PEP-8 Style Guide, the following first two statements articulate the concept quite clearly. The last statement, in my opinion, is the best way to list the variables of elements of a function and identifying them. Although this will increase the number of lines your script contains, the level of organization and explanation will be worth it.
# Bad:
foo = long_function_name(var_one, var_two,
var_three, var_four)# Good:
foo = long_function_name(var_one, var_two,
var_three, var_four)# Best?:
foo = long_function_name(var_one, #Var one does this
var_two, #Var two does this
var_three, #Var three does this
var_four) #Var four does this
Third, documenting functions is essential. While this is not by definition a problem, it is good practice to document your functions effectively. There are two ways to document your code. You can add comments using the “#” symbol, or add a docstring using the triple quotation marks. Take for example the following functions. The first is documented using using comments, and the second using a docstring. While both articulate similar information regarding the code, the second function presents the information in a user-friendly manner.
# This is bad:def cubeFunction(x): #function name where you enter x as input
y= x**3 # do the calculation to get the cube
return y # return the result of the calculation
# This is better:def cubeFunction(x)"
'''
Takes the input and returns the cube of the number.
x: a numerical input value
y: a numerical output value
'''
y = x**3
return y
3. Always Account For Memory and Efficiency
Simple python programs will generally never run into issues relating to memory, however this topic will become crucial as scripts grow larger and more complex. Unlike other languages, the Python interpreter performs memory management in the background leaving users with no control whatsoever. For more information regarding memory management in Python, we recommend this article by realpython.com. There are a number of ways to handle memory issues within python, however, we have selected two common operations that we have seen when it comes to numerical and non-numerical values.
Efficiency through list comprehension. There are a number of ways to iterate through data sets or lists such as for loops and while loops. For loops in particular present an attractive method to iterate through lists as they easy to understand and visualize. Take for example the following piece of code. We utilize a for loop to iterate through a range of numbers and append each number to a list called my_list.
number = 100000def forLoop_square():
my_list = []
for i in range(number):
my_list.append(i)
return my_list
Python beginners will often read the for loop statement as: “for every item in the range of 0 to 100000, append the item to my_list”. This translation is easy to read and easy to understand making it an attractive and comfortable option.
List Comprehension, however, has a slightly different syntax yet reaches the final goal in a more efficient (and faster) fashion. Take for example the following code. If you were to read this as an English statement, it would read as “my list is equal to the item for every item in the range of 0 to 100000”. The sentence is not as direct as the previous one, but the process is faster and the end result is the same. The reason that list comprehension performs better is because it does not need to load the append attribute and call it as a function for every element in your list.
number = 100000def listComp_square():
my_list = [i for i in range(number)]
return my_list
Upon reviewing the code, you notice that we will not only improve efficiency, but also reduce the number of lines in our code making for a cleaner and more ‘pythonic’ script. Using the timeit library, we can once again measure the time difference.
timeit.timeit(forLoop_square, number = 1000)
timeit.timeit(listComp_square, number = 1000)# Results:
forLoop_square: 6.57 s
listComp_square: 3.87 s
Using this simple change, we were able to reduce the run-time of this operation by roughly 50%! In summary, account for memory and the underlying mechanisms of functions to help improve the efficiency of your code.
Efficiency through string concatenation. In the section above, we showed that there can be notable differences in performance when it comes the use of for loops and list comprehension. However, those were focused on (but not exclusive to) the use of numerical values. One of the most common operations is the concatenation of strings. The method of choice when it comes to combining elements can have a major impact on memory and subsequently performance. Since strings are immutable, and when more than two strings are combined, the strings are copied and combined in pairs.
One of the more common approaches can be seen in the following few lines of code though a process known as concatenation:
string_1 = 'This is an example'string_2 = 'To show concatenation of long strings'string_3 = 'and related associated efficiencies'full_str_concat = string_1 + "." + string_2 + "," + string_3 + "!"
Here, we use the “+” operator to concatenate the various strings together to yield an overall string presented as:
This is an example. To show concatenation of long strings, and related associated efficiencies!The process of concatenating strings is slow given that each string is concatenated one at a time. There are several alternative processes that can address this inefficiency such as string substitution (%-formatting), and string joining. As of the Python 3.6 release, there is now a new and improved method to concatenating strings known as ‘formatted string literals’, or ‘f-strings’. The bonus with f-strings is that expressions are evaluated at runtime, and subsequently formatted using the __format__ protocol allowing it to achieve a faster runtime. We can examine the use of f-strings below:
full_str_fstrng = f'{string_1}. {string_2}, {string_3}!'In order to compare the efficiencies of the two processes, we can once again use the timeit library:
# Results:
full_str_concat: 0.0362 s
full_str_fstrng: 0.0183 sThe results here show a roughly 50% improvement in runtime using f-strings relative to their concatenation counterparts — both of which yield the same final result.
4. Sorting with Efficiency
When speed and efficiency are of the essence, it is always best practice to try various different approaches when conducting any type of python operation. One common operation that will always require several attempts with different algorithms is sorting. With the increasing number and size of datasets across the industry, the need to sort entries or observations is pertinent. There currently exists a number of different methods to sort values (both numerical and textual) in ascending or descending order. For the purposes of illustrating efficiency in the context of this article, we will discuss two algorithms: quickSort and mergeSort — both of which are divide-and-conquer algorithms.
We will begin with quickSort. This algorithm has two core parts . The first is that it takes an unsorted list as input and determines whats known as a pivot. A pivot is an element within the collection that acts as a starting point (illustrated below with the 4). Next, the algorithm uses the pivot to divide the unsorted list into to parts: smaller than, and greater than the pivot. The elements smaller than the pivot are placed on the left, and those greater are placed on the right. This process will continue to divide the elements in a recursive fashion.

The second algorithm here is mergeSort. This algorithm, similarly to quickSort, consists of two core parts. First, the elements of the list are divided into equal parts based on length. The process continues until the elements can no longer be divided. Next, the algorithm reassembles (or merges) the individual elements in order of size and this process continues recursively until the now-sorted list has been reassembled. The example below illustrates the concept.
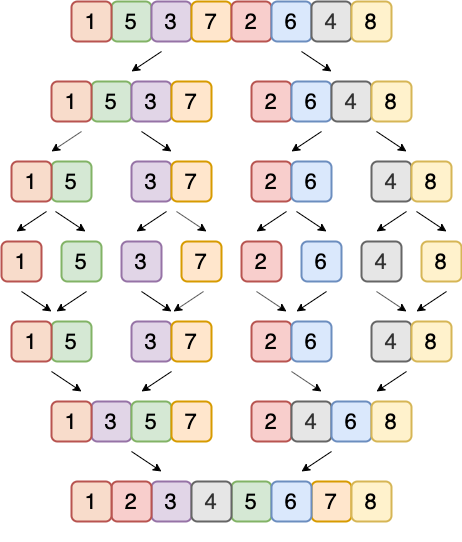
Now that we have an understanding of the two algorithms, let us note some of the pros and cons of each algorithm which are summarized in the table below. The main message here is that mergeSort is much more efficient for larger data sets, whereas quickSort is much more efficient for smaller data sets.
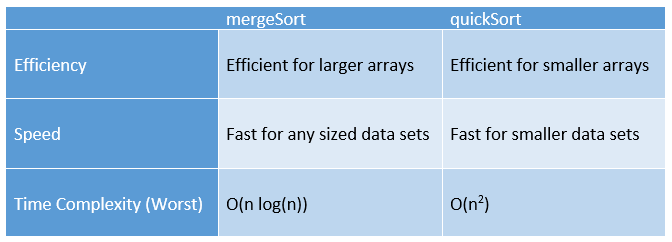
Lets take a look at the change in efficiency using the following code. We begin by creating a list of 10,000 random integers.
random_list_of_nums = random.sample(range(1, 10001), 10000)If we sort this script using both mergeSort and quickSort, we can see the average times for this list noted below in which quickSort shows a faster run time (by nearly 50%) relative to mergeSort. This in part is due to the partition concept discussed above, however, this efficacy will heavily depend on the type and size of the data at hand.
merge_sort(random_list_of_nums)
# Average Time = 0.09312 squick_sort(random_list_of_nums)
# Average Time = 0.05394 s
It is important to have an understanding of how sorting algorithms work in order to make better decisions regarding which to use for a particular scenario. When sorting 10,000 elements, the difference may be negligible. However, when sorting through millions of elements, the difference can be large. Let us now take a moment to explore the two two built-in sorting algorithms in Python known as sort and sorted. These are two highly optimized sorting functions available in any Python distribution.
There are two main differences when discussing these two functions. First, the sort function will simply modify the existing list to sort the elements in order. On the other hand, sorted will create a new list of the same elements in order without modifying the original list. Second, another difference is that sort is simply a list method, whereas sorted is a global function. There is no “better” option between the two — this is almost exclusively dependent on the users intentions regarding the status of the list.
random_list_of_nums = random.sample(range(1, 10001), 10000)#Sorted:
sorted_list = sorted(random_list_of_nums)#Sort:
random_list_of_nums.sort()
In summary, there are many sorting algorithms out there. The purpose of this section is not an attempt to make you an expert at sorting, but to simply communicate that there exists a variety of sorting algorithms out there. Each algorithm has its own advantages and disadvantages, and knowing that will help guide your code development in a more efficient manner. More importantly, sorting in Python is an interview discussion that will not disappear anytime soon!
5. Multiple Assignment and Variable Swapping
One of the many important concepts in Python is the process of assigning values to variables. If the value of ‘5’ were to be assigned to the variable ‘x’, anytime the variable ‘x’ is entered, the value of ‘5’ would be returned. There are rules that govern the process of assignment, which can usually be broken down into different categories based on mutability and datatypes. In the case we outlined above, we are assigning the integer value of 5 to the variable ‘x’ shown below. We can also assign a different value to y, and another to z.
x = 5
y = 10
z = 15For three minor variables, these few lines of code will successfully accomplish the task. However, when incorporating many variables in scripts with hundreds of lines, it is important to be concise about your code. A better practice would be the use of multiple assignment to assign your variables in one line:
x, y, z = 5, 10, 15The end result here is you reduce the number of lines needed and improve the elegance of your script.
Similarly, another common practice in Python is the process of swapping variables. There are a variety of ways this can be accomplished such as the use of a temporary variable. Python offers an elegant feature for this exact purpose:
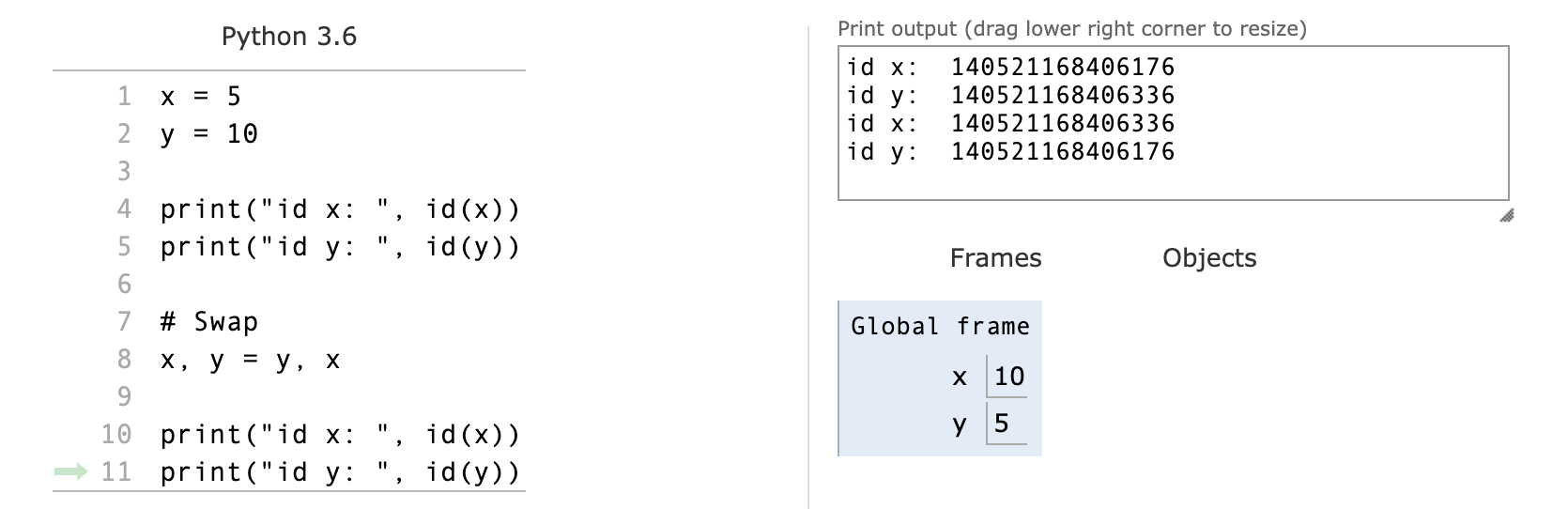
x = 5
y = 10
x, y = y, xprint("x: ", x)
print("y: ", y)
The output in this case would be x = 10 and y = 5. If we examine this from a namespace point of view, we also notice that the namespace was not cluttered with the addition of temporary variables. We started with two and ended with two. We can also confirm the identity of the variables by using id(x) and id(y). We notice that the identities of the variables were simply swapped:
For the purposes of a handful of variables, the difference is negligible. However, when dealing with a large number of variables, this differences in performance will begin to matter.
6. Efficiency with Numpy Array Transformations
Numpy Arrays are one of the most common data types used when handling large data sets. Organized by rows and columns, arrays are grids of values consisting of the same data type. When working with numerical Numpy Arrays, the transformation or application of a mathematical operation is often necessary. One common way to do this would be to use nested for loops to individually iterate through each element in each row. However, as discussed above, for loops are taxing on memory and can substantially decrease the efficiency of the code.
Numpy provides native functionality which executes these processes more efficiently such as the use of ravel and reshape. Ravel moves all of the elements into one row and allows for efficient application of an operator. Reshape can then be used to restore the array’s original shape. An example of these processes is provided below.
# Using for loops:ar = np.array([[1,2,3,4,5],[6,7,8,9,10]])
ar = np.repeat(ar, 50000, axis = 0)for r in range(len(ar)):
for e in range(len(ar[r])):
ar[r][e] = (ar[r][e] ** 10)
# Using ravel/reshape:ar = np.array([[1,2,3,4,5],[6,7,8,9,10]])
ar = np.repeat(ar, 50000, axis = 0)columns, rows = ar.shape[:2]
ar = ar.ravel()**10
ar = ar.reshape((columns, rows))
Upon executing the two processes listed above and capturing the run time for each using the timeit library, a 99% decrease in processing time is observed, leading to a substantially more efficient process.
# Results:for_loop_method: 1.352 s
native_numpy_method: 0.014 s
In summary, this article has presented six main takeaway messages that every coder should be aware of and attempt to follow when writing efficient code. As many industries begin to grow their information and analytics capabilities, it will be important for developers to be able to deploy efficient and easily understood scripts to promote more agile work environments with stronger collaborative opportunities.
We hope that the contents of this article was informative and beneficial to all readers of all levels of experience. For any suggestions relating to future articles, please feel free to reach out to us via our LinkedIn profiles at the beginning of the article.
