ベクトル検索(近似最近傍探索)でいい感じの MoreLikeThis を実現する
この記事は,「情報検索・検索エンジン Advent Calendar 2019」23日目のエントリーです。モノは生煮えですが,背景含めて頑張って説明したいと思うので,ご容赦ください…。
目次
- Apache Lucene とは
- Lucene にベクトル検索を実装してみた
- ベクトル検索版 MoreLikeThis
- Unsolved issues(積み残し)
雰囲気だけ知りたいという方は,「ベクトル検索版 MoreLikeThis」 のところだけ眺めると良いかもしれません。
Apache Lucene とは
Apache Lucene は,ピュア Java で書かれた,高速・スケーラブルな検索エンジンライブラリです。OSS 検索エンジンとして人気の高い Elasticsearch や Solr のコアエンジンとして使われているため [1],検索システムに携わっている方なら,名前は聞いたことがあるかもしれません。もともとは,多言語に対応した Text Analysis フレームワーク [2] を備えた全文検索エンジン [3] としてスタートした Lucene ですが,開発コミュニティの広がりとともに,数値や日時,緯度経度による範囲検索 [4] や,高速なソート [5],検索キーワードのオートコンプリート [6],検索結果のリスコア(リランク) [7] もサポートし,さまざまな検索ニーズに対応するように発展してきました。
[1] Lucene のアクティブコミッターの多くは,Elasticsearch や Solr の開発者でもあります。
[2] みんな大好き(?)日本語形態素解析器 Kuromoji はここに含まれます。
[3] 基本となるデータ構造は,水平分散によりスケールアウトがしやすい転置インデックスです。また,Skip list や Block-max WAND といった,高速化の工夫が多数取り入れられています。
[4] 範囲検索には現在, Block kd-tree が使われています。スカラ値はもちろん,8 次元までの多次元データを扱うことができます。
[5] ソートには Doc values と呼ばれる列指向なデータ構造が使われています。Elasticsearch の Aggregation も doc values を使って実装されています。
[6] Suggester とも呼ばれます。
[7] BM25 などの,軽量なスコアリング関数でヒットした検索結果の上位 N 件を,別の(通常,より表現力と計算コストが高い)スコアリング関数で並び換えるもので,機械学習を用いて検索結果ランキングを行う Learning to Rank などでは必須の機能といえます。
Lucene にベクトル検索を実装する
Lucene は,トラディショナルな Bag-of-Words 型のキーワード検索エンジンであり,意味的に類似しているドキュメントをヒットさせるためには,シノニム辞書を丁寧に整備していく必要があります。近年の,自然言語処理分野で発展した word/document embedding (Word2Vec, GloVe, Doc2Vec, BERT, etc.) を使うと,辞書整備などの労力をかけることなく意味レベルのマッチングがとれる — というと何のことやらですが,検索エンジニアを悩ませる同義語や多義語をいい感じで吸収してマッチングしてくれる — ことが期待されていますが,今のところ Lucene は高次元ベクトルの検索を行うためのインデクサーは備えていません(Elasticsearch の dense vector [1][2] や,3rd party による試みはいくつかあります[3][4])。
画像処理や自然言語処理の背中を追うように,情報検索分野でも Neural 系の手法が主流になってきており[6][7][8],Google が Web 検索エンジンに BERT を組み込んだという話 [9] も記憶に新しいです。(と,知ったようなことを書いていますが,私は Neural IR の流れをきちんと追っているわけではいないので,[5][6] など,アカデミックの最先端を紹介してくださっている他の方のアドベントカレンダー記事もぜひ参照ください。)
Lucene 開発コミュニティでも,もちろんこの潮流は捉えており,ベクトル検索(正確には,近似最近傍探索 — Approximate k-nearest neighbor search — の 2019 年現在 SOTA と言われる Hierarchical NSW [10])を Lucene Core に取り込もうという Jira issue [11] が上がっています。近似,というのを強調したように,この issue で議論されているのは,正確な近傍探索ではなく,ドキュメント数が数百万〜数千万以上というオーダーのコーパスを扱う際に必要となる,近似解を求める手法です。issue で提案されている HNSW はグラフベースの手法ですが,古典的な LSH や kd-tree から始まり,Facebook Research の Faiss で採用されている Product Quantization,Spotify の Annoy など,多くの流派があるようです。
issue を読んで興味が湧いたので,ドラフトとして上がっていたパッチのアイディアを拝借しながら,HNSW を Lucene Core に組み込む形で実装してみました 。作業中のブランチは以下で公開しています 👇
https://github.com/mocobeta/lucene-solr-mirror/commits/jira/LUCENE-9004-aknn-2
まだパッチという形に仕上がってはいないのですが,基本的な機能(インデクシング,バイナリフォーマットへのエンコーディング/デコーディング,検索)について実装済みです。最初のパッチを上げた Michael Sokolov さんという方がレビューしてくれて,良いね,というフィードバックをもらったので,ディスカッションしつつ少しずつ実装を進めています。
なんでこんな面倒なことをしているの?筆者(@moco_beta)は,5年ほど Luke というインデックスブラウジング/デバッグのためのツール [12] をメンテしており,今年になってやっと本体へのバンドルが完了したのをきっかけに,Lucene/Solr プロジェクトのコミッターとして招待を受けました[13]。とはいえ,もともと興味があった core モジュールの深いところはいまだなかなか歯が立ちません。この issue は,(もちろん面白そうというのもありますが,)そのあたりを深堀りするのによさそうな題材でした[14]。
[1] Text similarity search with vector fields
[2] Elasticsearchで分散表現を使った類似文書検索
[3] What problem does BERT hope to solve for search?
[4] Elasticsearch における類似度ベクトル検索のベストプラクティスを求めて
[5] 情報検索とその周辺
[6] クランフィールド検索実験から2019年のニューラルモデルまで
[7] https://twitter.com/IR_oldie/status/1206853823706234880
[8] Deep Learning for Search (tutorial at FIRE 2019)
[9] Understanding searches better than ever before
[10] Yu. A. Malkov, D. A. Yashunin, Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
[11] [LUCENE-9004] Approximate nearest vector search
[12] 多分,日本であまり知られていないですが,開発や運用で役立つツールなので,稿を改めていつか紹介したいと思っています。
[13] Luke becomes an Apache Lucene module (as of Lucene 8.1)!
[14] 既存の Codec (データフォーマット)やコンポーネントの流用が難しく,低レベルの codecs パッケージから上位層の search パッケージまで,あらゆる箇所に影響が及ぶ大改造になったおかげで,最初の思惑以上に内部構造の理解が捗りました 😇
HNSW の(簡単な)説明
HNSW は,先ほど書いたとおりグラフベース (k-nearest neighbor graph) の手法です。詳細に興味があれば前節の論文 [10] を参考にしていただきたいのですが,ベースとなるアイディアは
インデクシング時に筋の良いグラフを作っておくことで,探索時に,ベクトル間の距離計算をしらみつぶしに行わなくても良いようにする
というものです。正確な最近傍探索をしようとすると,クエリベクトルと,インデクシングされているすべてのベクトルとの距離計算が必要です。(グラフベースの)近似最近傍探索では,あらかじめ近いノード同士だけにエッジを張った kNN グラフを構築しておくことで,探索時は,エッジが張られたノード間のみ距離計算をするだけで済ませます。ただし,エッジ数を減らすほど Recall が下がるため,時間/空間計算量と Recall の適切なバランスを取る必要があります(そのためのパラメータがいくつかあります)。ここでいう「筋の良いグラフ」が Navigable Small World というものですが,Coursera の講義ビデオ [1] で視覚的に説明されていてわかりやすかったので,興味のある方は見てみてください。
なお,HNSW では,“Hierarchical” NSW という名前の通り,NSW を階層的に重ねることで,探索効率をより向上させています(Fig. 1)。
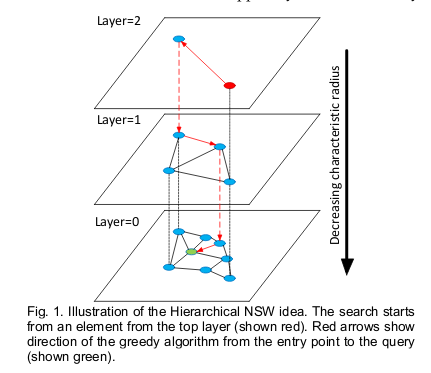
[1] Networks Illustrated: Principles without Calculus (Week 7: It’s a Small World)
動作検証
こいつ,動くぞ… というところまで来た時点で,インデクシング/検索がただしく動作することを確認するため,日本語 Wikipedia エンティティベクトルを投入して検証しました。
- データ件数:エンティティベクトル 1,015,475 件 (20170201.tar.bz2)
- 次元数:200
- HNSW パラメータ:M=6, M0=12, efConst=50
- 検証環境:Core i7–8700, OpenJDK 11.0.3, Java heap size 4GB
ベクトルのインデクシングと検索のコードはこちらに置いています 👇
https://gist.github.com/mocobeta/532ea1508bfcb619d654cfa1743bb6a9#file-entityvectorsearch-java
エンティティベクトル検索の例を記載します。比較のため,gensim での実行結果も併記しています。ここではたまたま同じ結果になっていますが,gensim の most_similar() は正確な近傍探索であるのに対し HNSW のほうはあくまで近似解なので,クエリによっては差異が発生します。
検索速度についてはきちんとベンチマークをとらないといけないのですが,このデータセットの場合は(十分なメモリがあれば)おおむね 100 msec を切るレイテンシで結果が返ってきていて,これなら実用上も十分と言えそうです。ただし,kNN グラフはオンメモリ上に保持している状態で,グラフのロード時間は検索実行時間に含みません。
### gensim
### Word2Vec.most_similar()In [11]: model.most_similar('[ヤマハ発動機]')
Out[11]:
[('[本田技研工業]', 0.915203332901001),
('[スズキ_(企業)]', 0.8829678297042847),
('[ドゥカティ]', 0.8509892821311951),
('[ホンダF1]', 0.8462636470794678),
('[ワークス・チーム]', 0.838498592376709),
('[プジョー]', 0.8383729457855225),
('[メルセデス・ベンツ]', 0.8377079963684082),
('[トヨタ]', 0.8359073400497437),
('[アルファロメオ]', 0.8327696323394775),
('[チーム・ロータス]', 0.8326400518417358)]
—
### Lucene fork for HNSW
### org.apache.lucene.search.KnnGraphQuery== Search similar entity to [ヤマハ発動機] (elapsed=64 msec) ==
Rank 1: doc=16847 name=[ヤマハ発動機] score=1.0
Rank 2: doc=9614 name=[本田技研工業] score=0.9152032
Rank 3: doc=16135 name=[スズキ_(企業)] score=0.882968
Rank 4: doc=48631 name=[ドゥカティ] score=0.85098964
Rank 5: doc=35096 name=[ホンダF1] score=0.84626377
Rank 6: doc=28053 name=[ワークス・チーム] score=0.83849865
Rank 7: doc=29354 name=[プジョー] score=0.83837295
Rank 8: doc=17770 name=[メルセデス・ベンツ] score=0.83770806
Rank 9: doc=40133 name=[トヨタ] score=0.83590746
Rank 10: doc=28594 name=[アルファロメオ] score=0.83276993
ベクトル検索版 MoreLikeThis
類似文書検索というと,Lucene にはすでに MoreLikeThis というコンポーネントが実装されています。Elasticsearch や Solr にも組み込まれているので,簡易なコンテンツベース推薦として活用している方も多いかもしれません。MoreLikeThis のアルゴリズムは,指定されたドキュメントから,TF/IDF 値の高い上位 25 個(デフォルト)の term を feature として選択し,それらで OR 検索をおこなうというもので,とてもシンプルですが,そのぶん高速で実用的です。
もし Lucene にベクトル検索が入るとしたら,もっとも自然な応用先のひとつは,おそらく MoreLikeThis の置き換えでしょう。 “Deep Learning for Search” [1] という書籍にも,Paragraph Vector (doc2vec) で MoreLikeThis を実装する,という例が掲載されています。
ということで,日本語 wikipedia から gensim で学習させた doc2vec モデル (PV-DM) を使い,近傍探索による MoreLikeThis っぽいことをやってみます。
データは 2019/12/09 時点の CirrusSearch のダンプを,学習には [2] で公開してくださっているスクリプトを使わせていただきました。
参考までに,EC2 の m5.8xlarge (128 GiB RAM) という大きめのインスタンスを使って 6 時間程度で学習が完了しました。学習以外の準備,データアップロード/ダウンロードにかかった時間も入れて,トータルでかかった 💸 は $20 くらいです。
- データ件数:1,179,449 エントリ
- 単語分割:MeCab + neologd
- 次元数:300
- HNSW パラメータ:M=6, M0=12, efConst=50
- 検証環境:Core i7–8700, OpenJDK 11.0.3, Java heap size 8GB
インデクシング,検索を実行するコードはこちらに置いています 👇
https://gist.github.com/mocobeta/532ea1508bfcb619d654cfa1743bb6a9#file-paragraphvectorsearch-java
先ほどのエンティティベクトルの検索ではクエリとしてベクトルそのものを与えていましたが,少し手を加え,Query オブジェクトにはドキュメントのID を指定し,クエリベクトルはインデックス中から取得してくるようにしています。
(a) 既存の MoreLikeThis と,(b) ベクトル検索版 MoreLikeThis の結果をいくつか併記します。検索結果はだいぶ異なり,(b) の場合は確かに,単語レベルのマッチングではかからないような類似ドキュメントがヒットしている雰囲気があります。どちらの精度が良いか,というのは場合によりけりですが,“PayPay” に対して “Kyash” や “Origami” が出てくるのはよさそうに見えますね :-)
検索速度については,既存実装のほうが速そうですが,とはいえベクトル検索版も,後述のセグメントマージが実装されると同等程度にはなるかもしれません。
(a) MoreLikeThis== Search similar entity to 日本銀行 (elapsed=66 msec) ==
Rank 1: doc=742441 name=日本銀行 score=50.685184
Rank 2: doc=715648 name=日本銀行法 score=40.31833
Rank 3: doc=44695 name=日本銀行政策委員会 score=38.868637
Rank 4: doc=161401 name=中原伸之 score=31.009663
Rank 5: doc=376547 name=速水優 score=30.722044
Rank 6: doc=366863 name=水野温氏 score=30.475336
Rank 7: doc=503591 name=木内登英 score=30.21684
Rank 8: doc=824486 name=布野幸利 score=30.184124
Rank 9: doc=577287 name=政井貴子 score=29.81465
Rank 10: doc=533598 name=櫻井眞 score=28.847675== Search similar entity to PayPay (elapsed=73 msec) ==
Rank 1: doc=1062663 name=PayPay score=78.35689
Rank 2: doc=1125751 name=QR・バーコード決済 score=40.51069
Rank 3: doc=832360 name=ヤフオク! score=28.520924
Rank 4: doc=870157 name=Yahoo!_JAPAN score=27.666096
Rank 5: doc=780665 name=信用照会端末 score=27.048323
Rank 6: doc=63084 name=ヤフー_(企業) score=26.881903
Rank 7: doc=459615 name=ワイジェイカード score=25.985676
Rank 8: doc=566105 name=榛葉淳 score=25.020779
Rank 9: doc=307354 name=DiDiモビリティジャパン score=24.24394
Rank 10: doc=718891 name=Alipay score=23.564753== Search similar entity to 葛飾北斎 (elapsed=82 msec) ==
Rank 1: doc=1168030 name=葛飾北斎 score=24.39734
Rank 2: doc=496812 name=川原慶賀 score=21.579926
Rank 3: doc=74777 name=葛飾応為 score=20.05349
Rank 4: doc=576503 name=堤等琳_(3代目) score=18.009438
Rank 5: doc=644396 name=葛飾北明 score=17.141546
Rank 6: doc=67022 name=葛飾北斎_(2代目) score=17.10954
Rank 7: doc=511585 name=存斎光一 score=16.567303
Rank 8: doc=922559 name=露木為一 score=16.379852
Rank 9: doc=416269 name=生出神社 score=16.315296
Rank 10: doc=28532 name=ヤン・コック・ブロンホフ score=16.274002== Search similar entity to 鉄腕アトム (elapsed=96 msec) ==
Rank 1: doc=1095802 name=鉄腕アトム score=39.51811
Rank 2: doc=719467 name=アストロボーイ・鉄腕アトム score=30.061914
Rank 3: doc=186949 name=鉄腕アトム_(アニメ第2作) score=29.46311
Rank 4: doc=382716 name=ASTRO_BOY・鉄腕アトム_-アトムハートの秘密- score=26.703938
Rank 5: doc=977860 name=手塚治虫が消えた!?_20世紀最後の怪事件 score=25.274942
Rank 6: doc=1152216 name=PLUTO score=25.269333
Rank 7: doc=1157861 name=GO!GO!アトム score=21.860027
Rank 8: doc=877147 name=ATOM_(映画) score=21.479927
Rank 9: doc=213150 name=鉄腕アトム_(実写版) score=21.371815
Rank 10: doc=387119 name=手塚漫画のキャラクター一覧 score=21.089872
—
(b) ベクトル検索版 MoreLikeThis== Search similar entity to 日本銀行 (elapsed=282 msec) ==
Rank 1: doc=800154 name=日本銀行 score=1.0
Rank 2: doc=313501 name=黒田東彦 score=0.5933535
Rank 3: doc=606226 name=石田浩二 score=0.58012307
Rank 4: doc=696527 name=翁邦雄 score=0.5723916
Rank 5: doc=113085 name=白川方明 score=0.56868726
Rank 6: doc=303698 name=外資金庫 score=0.56457376
Rank 7: doc=16796 name=日本共同証券 score=0.56067026
Rank 8: doc=301794 name=佐藤健裕 score=0.5606088
Rank 9: doc=663487 name=金融調節 score=0.5579636
Rank 10: doc=499306 name=日本銀行法 score=0.5574749== Search similar entity to PayPay (elapsed=296 msec) ==
Rank 1: doc=716843 name=Kyash score=0.5692681
Rank 2: doc=551461 name=Google_Checkout score=0.5417748
Rank 3: doc=644428 name=LINEモバイル score=0.52877945
Rank 4: doc=1176962 name=Origami score=0.5198931
Rank 5: doc=1122195 name=Yahoo!ショッピング score=0.5165478
Rank 6: doc=1089811 name=セブン・ペイ score=0.5149246
Rank 7: doc=438377 name=Yahoo!リスティング広告 score=0.49233538
Rank 8: doc=74263 name=マーケットスピード score=0.48775947
Rank 9: doc=1022944 name=エフレジ score=0.4843942
Rank 10: doc=210088 name=ソーイージー score=0.4828788== Search similar entity to 葛飾北斎 (elapsed=301 msec) ==
Rank 1: doc=415364 name=魚屋北渓 score=0.58227384
Rank 2: doc=628332 name=礒田湖龍斎 score=0.56182164
Rank 3: doc=445047 name=歌川広重_(2代目) score=0.5478962
Rank 4: doc=597920 name=宮川長春 score=0.5424614
Rank 5: doc=114568 name=宮川春水 score=0.5374308
Rank 6: doc=597036 name=鳥居清長 score=0.53469473
Rank 7: doc=482074 name=勝川春暁 score=0.53425366
Rank 8: doc=176774 name=菱川師宣 score=0.5319288
Rank 9: doc=463096 name=不韻斎 score=0.5294361
Rank 10: doc=767144 name=村松以弘 score=0.52842003== Search similar entity to 鉄腕アトム (elapsed=294 msec) ==
Rank 1: doc=1101715 name=鉄腕アトム score=1.0
Rank 2: doc=495238 name=アストロボーイ・鉄腕アトム score=0.5850105
Rank 3: doc=823575 name=宇宙エース score=0.5347867
Rank 4: doc=483250 name=海の王子 score=0.53320885
Rank 5: doc=615857 name=100万年地球の旅_バンダーブック score=0.5133201
Rank 6: doc=160300 name=ジャングル大帝 score=0.51141
Rank 7: doc=739855 name=人造人間キカイダー_(漫画) score=0.50419194
Rank 8: doc=467737 name=マジンガーZ score=0.5035781
Rank 9: doc=955394 name=火の鳥_(漫画) score=0.50180763
Rank 10: doc=906713 name=ドラえもん_のび太のワンニャン時空伝 score=0.50143737
[1] Deep Learning for Search. Tommaso Teofili, 2019, Manning
[2] 日本語Wikipediaで学習したdoc2vecモデル
積み残し
これが,Lucene 本体にパッチとして受け入れられるためには,クリアしないといけないことが(主にパフォーマンス面で)色々あります。
- セグメントマージ
サンプルとして Gist に上げたコードを注意深く読んだ方がいれば気づいたかもしれませんが,IndexWriterConfig に “NoMergePolicy” を指定しています。まだ,セグメントのマージに対応していないためです。マージの都度 kNN グラフを最初から構築し直すこともできますが,そうするとおそらく実用に耐えられないほどインデクシングが遅くなってしまうため,もう少し賢いマージ方法を検討したいところです…。
2. メモリ消費
kNN グラフをオンメモリに載せていますが,たいへんメモリ食い 😓 なので,フットプリントを小さくする必要があります。
3. 起動時のグラフロード速度
アプリを起動直後の初回検索時だけですが,kNN グラフのロードが遅く,今回実験したくらいのデータ件数(110万 docs)だと20秒くらいかかってしまうので,もう少し速くしたい…。
その他,テストや Recall 性能検証やドキュメンテーションなど,やることは山積みなので,本体にマージ可能なパッチが本当に作れるのかわからないですが,もう少しがんばってみるかなーと思っています。
少し長くなりました。ここまで読んでくださってありがとうございました。自分ならもっと上手く実装できる!という方は,ぜひパッチを送ってください。現場からは以上です。(‘ー’*)ゞ
—
最後に CM ですが,私が所属している 株式会社 LegalForce では,ソフトウェアエンジニア,学生インターンを募集しています。Legal x Technology という成長市場で挑戦してみたい方,スタートアップで裁量を持って働きたい方の応募をお待ちしています 🤝
