BigQueryと上手に付き合う4つのTips
この記事は Google Cloud Japan Customer Engineer Advent Calendar 2019 の 20日目の記事です。
はじめに
こんにちわ、20日目の記事は、僕も大好きな BigQuery について書いてみたいと思います。BigQuery はサーバーレスでスケーラビリティに優れたデータ ウェアハウスです。インフラストラクチャの管理が不要なため、すぐに使い始めることができます!2日目の記事で keiji-san が BigQuery について書いてくれてますので、BigQueryとはなんぞやという方はご参考ください。
このブログでは既に BigQuery を使い始めたユーザーのみなさんがより BigQuery を使いこなしていくための Tips を 4つ厳選してご紹介します!
- カスタム割り当てを利用して、コストをコントロールする。
- 承認済みビューを利用して、ビューのみの参照権限を付与する。
- ストレージを最適に利用する。
- UNNEST 関数を利用して、配列型のデータをテーブル化する。
1. カスタム割り当てを利用して、コストをコントロールする。
まずはコスト管理です。コスト管理は、BigQuery を使う際に、必ず議論となる Topic のうちの1つです。カスタム割り当てを利用することによって、コストを管理する方法について記載します。
もともと BigQuery は無料枠があるので、表計算ソフトや CSV で処理する程度のデータであれば、無料枠内で多くのクエリを実行できます。また、クエリの実行結果は一時的なキャッシュ結果テーブルに書き込まれ 、再利用されます。キャッシュ結果テーブルから再読み込みされる場合にはクエリのコストは発生しません。とはいえ、大量にデータ分析を行う場合には、やはり利用限度を設定しておくと安心して使うことができます。
まずは BigQuery のコストの主な構成要素についてみてみます。( 詳細はこちら )
1.ストレージのデータ保存
2.クエリ実行
3.ストリーミングインサート料金
カスタム割り当てを利用することで、[ 2.クエリ実行 ] の利用量に制限をかけることができます。ユーザー単位・もしくはプロジェクト単位で割り当ての設定が可能です。
IAM の管理 > 割り当て > サービスで [ BigQuery API ] を選択し、以下の2つの 割り当ての設定を行うことが可能です。
Query usage /日 /ユーザー・・・ユーザー単位の1日のクエリの実行量
Query usage /日 ・・・プロジェクト単位の1日のクエリの実行量
これらの割り当ては太平洋時間の0時でリセットされます。(日本では夕方の17時ですね。)
「コスト管理は気になるけど、ユーザの利用を制限したくない」そんな状況もあると思います。目の前にデータがあるのに自由に分析できないなんて・・・そんな場合には、定額のプランもあります。定額のプランは500slotから購入が可能ですので、ご検討ください。
2. 承認済みビューを利用して、あのビューのみの参照権限を付与する。
承認済みビューを利用すると、テーブル自体 ( データセット ) へのアクセス権がないユーザーにも、ビューによって抽出したデータを共有することができます。また、各レコードのデータを見る必要がないユーザーに対して、直接的にテーブルへのアクセス権を渡すことなく、情報提供を行うことが可能となります。
BigQuery では、データセットの単位で権限をコントロールします。テーブル、ビュー、列、行に対する権限の付与を行うことができません。ただ、実際の業務においては、あるユーザーに対して、集計データは表示させたいが、行レベルのデータは参照させたくないというケースがあると思います。そういった場合には、承認済みビューを利用することで実現が可能です。元テーブルから抽出したデータを、一時テーブルに格納するという手もありますが、重複してデータを保持したくないとか、検索のタイミングで必ず最新のデータを参照したい場合には、承認済みビューを利用することがおすすめです。
以下の例をみてみましょう。
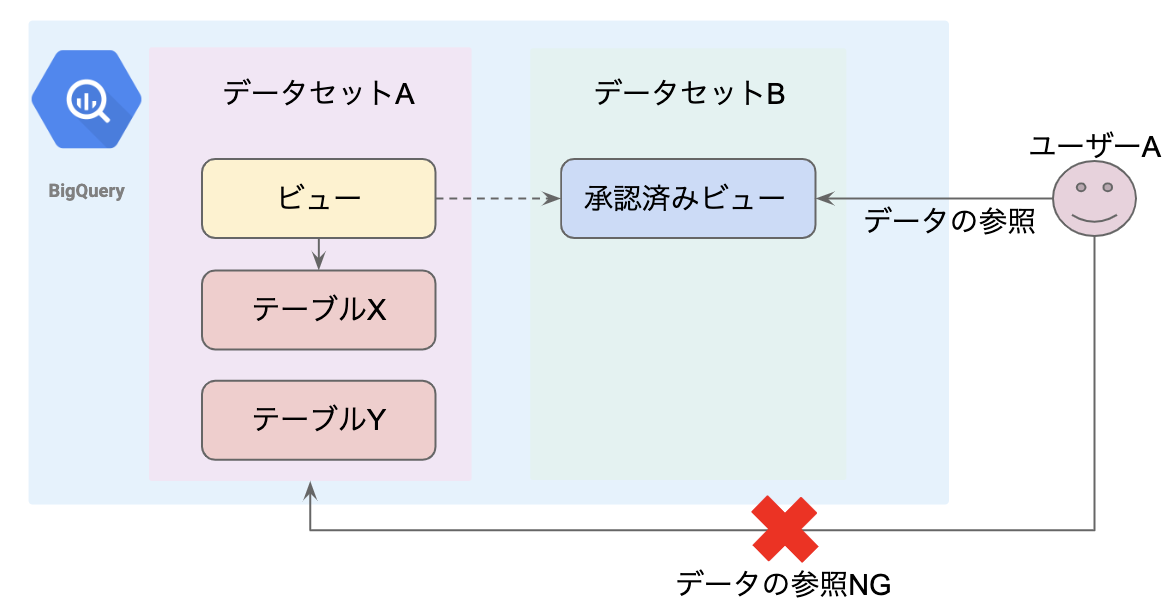
ユーザー A は、特定のデータをサマリーされたデータだけを見る必要があります。サマリー前の元データはテーブル X に格納されています。また、ksテーブル Y はテーブル X と同じデータセットの中に格納されています。
ユーザー Aは、サマリーされたデータにアクセスする必要がありますが、テーブル X、テーブル Yの各レコードを参照できる必要はありません。
こういった状況の中で、承認済みビューを活用することができます。ユーザー Aはデータセット Bにアクセスができ、データセット B に承認済みビューを設定します。この承認済みビューの作成時に、データセットA のビューを指定します。
このように設定をすると、ユーザー A は承認済みビューの結果のみにアクセスすることができますが、データセット A のすべてのリソースにアクセスすることができません。
3.ストレージを最適に利用する。
BigQuery では、ストレージを最適に利用すること( 不要なデータを保持しない )ことはコストを最適化するためにも重要です。テーブル、パーティションに対して、有効期限を設定し、不要なデータは自動的に削除することができます。
もし、BigQuery にデータを長期保存したい場合もご安心ください。長期保存 ( 3ヶ月以上更新されていないテーブル、パーティション ) のストレージのコストは、自動的に安くなります。(参考:US では $0.010 per GB 2019.12 時点)
BigQuery ではデータセット、テーブル、パーティションそれぞれに有効期限を設定することができます。有効期限を設定することで、有効期限を過ぎたデータは自動的に削除されます。通常運用において、一定期間が経過したデータを自動的に削除するには、パーティションに有効期限を設定することで実現できます。テストとして利用する場合や、一時テーブルなどの削除にはテーブル単位に有効期限を設定することが有効です。現在、GCPのコンソールでは設定可能なパラメータが限られているため、ご留意ください。以下の設定を行うことができます。
[ データセットに設定をする場合 ]
データセットに設定する場合は、データセット内に作成されるテーブルのデフォルトの有効期限を設定します。本設定をした後に作成される全てのテーブルに対して、デフォルトの有効期限として設定されます。
[ テーブルに設定をする場合 ]
テーブルの有効期限となる日時を設定します。
[ パーティションに設定する場合 ]
テーブルのパーティション有効期限を設定するとすべてのパーティションに対して、設定された有効期限が設定されます。
[ 各設定の優先順位 ]
設定された有効期限は以下の優先順位で有効となります。
・データセットレベルで設定される設定より、テーブルレベルで設定した設定が優先される。
・パーティション化テーブルにテーブルの有効期限が設定されている場合、パーティションの有効期限より優先される。
4. UNNEST 関数を利用して、配列型のデータをテーブル化する。
最後は、UNNEST 関数について紹介します。BigQuery の良いところとして、テーブル化されたデータだけではなく、配列型や構造体型のを扱うことができます。配列型でデータを保持することにより、コスト効率高くリレーションのあるデータを格納するができます。
また、配列型のデータを扱う際にUNNEST 関数を利用すると、配列型のテーブルを各行のデータとして操作することができます。UNNEST を使いこなせるようになると、分析の幅が広がります。例えば、Google アナリティクスから連携されるデータの一部は配列型で入ってくるため、それらのデータにアクセスするにはUNNEST 関数の利用が必要となります。
では、先ほどと同じテーブルを使って説明していきたいと思います。
SELECT
id,
author_name,
books
FROM
`<project_id>.bqtest.authorbook`
WHERE
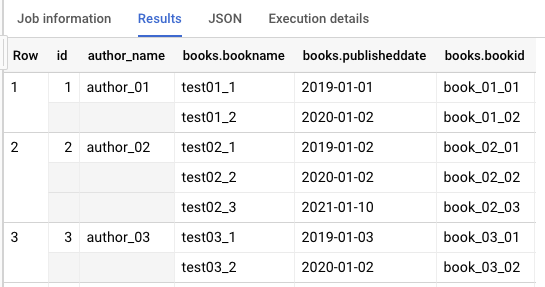
books.publisheddate <= DATE("2019-10-10")このクエリを実行すると、books.publisheddate で、publisheddate にアクセスできない旨の構文エラーが発生します。books は配列であるため、特定のデータに直接アクセスすることはできません。とりあえず、WHERE 句を外して実行すると、以下の結果を取得することができます。
books は配列としての部分を正規化したいですよね、そこでUNNEST 関数の登場です。UNNEST 関数を利用することで、以下の通り結果をテーブルの構造として出力することができます。
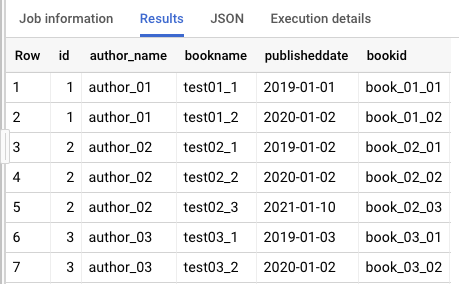
UNNEST 関数を使うことで、配列の構造体データを各レコードにすることができました。また、以下のクエリのように、books 配列内のデータの1つの要素である publisheddate を検索条件にクエリを実行することもできるようになります。
SELECT
id,
author_name,
book.bookname,
book.publisheddate,
book.bookid
FROM
`<project_id>.bqtest.authorbook`
CROSS JOIN UNNEST(books) as book
WHERE book.publisheddate <=DATE("2019-01-05")Google のサービスから BigQuery に連携されるデータの中にも、このようなレコードは登場します。この UNNEST 関数を使えるようになると、さらにBigQuery の中で自由にデータを操作できることになるでしょう。
さいごに
今年最後の締めくくりとして、BigQuery について書いてみました。そのほかにも、パーティション分割テーブル、クラスタ化テーブル、BigQuery GIS、スクリプト・・・とまだまだたくさんの機能があります。ぜひBigQueryを使ってデータ分析を楽しんでください!
いよいよ、このAdvent Calendarも終盤にさしかかってきました。明日はYutty-san の 「Agones 超入門」です。Googleが開発しているゲームの専用サーバで2020年期待のオープンソースです。ぜひ今年の締めくくりとしてキャッチアップしておきましょう!
それでは Enjoy hacking and the holidays !

