目次
検証環境
- Windows 10 Pro 64bit (April 2018 Update)
- HTTrack(WinHTTrack) 64-bit 3.49.2
使おうと思った経緯
geocitiesが2019年3月末サービス終了
サービス終了のお知らせ – Yahoo!ジオシティーズ
…なのでgeocitiesのサイトで「自分のChrome内ブックマーク」「自分のURLショートカットファイル」「自分が登録したはてなブックマーク」「人気のはてなブックマーク」にある物から自分がチョイスした物だけでも保存しておこうと思いました
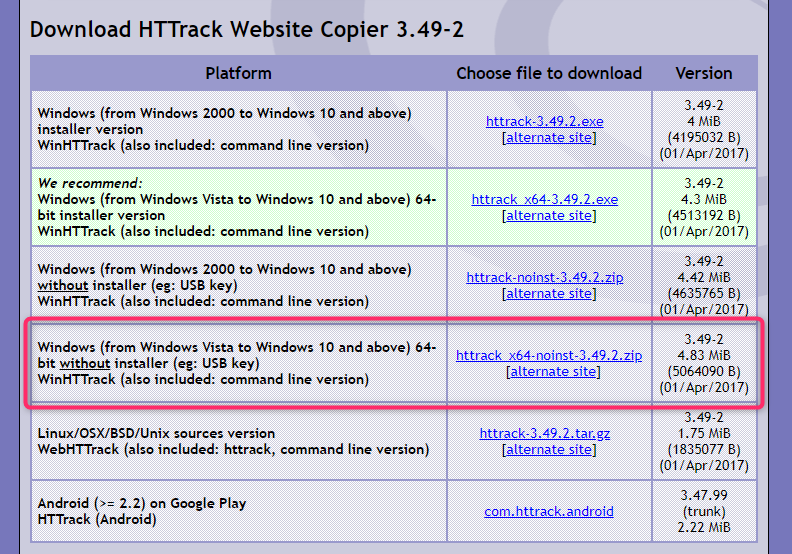
HTTrack(WinHTTrack) は以下の場所でダウンロードできます、私はzipの64bit版「httrack_x64-noinst-3.49.2.zip」を使っています
Download HTTrack Website Copier 3.49-2 – HTTrack Website Copier – Free Software Offline Browser (GNU GPL)
使用方法(雑雑雑)
取得前提
以下の前提で取得します
geocitiesにあるシンプルな静的ページという想定で、ちょっと凝ったページだと上手く取得できない可能性もありますが、それは仕方ないという事で割り切ります
- 指定したドメイン・フォルダ(とその下位ファイル・フォルダ)以外のファイルは取得しない様にする
- robots.txt の指定を無視して取得する
手順
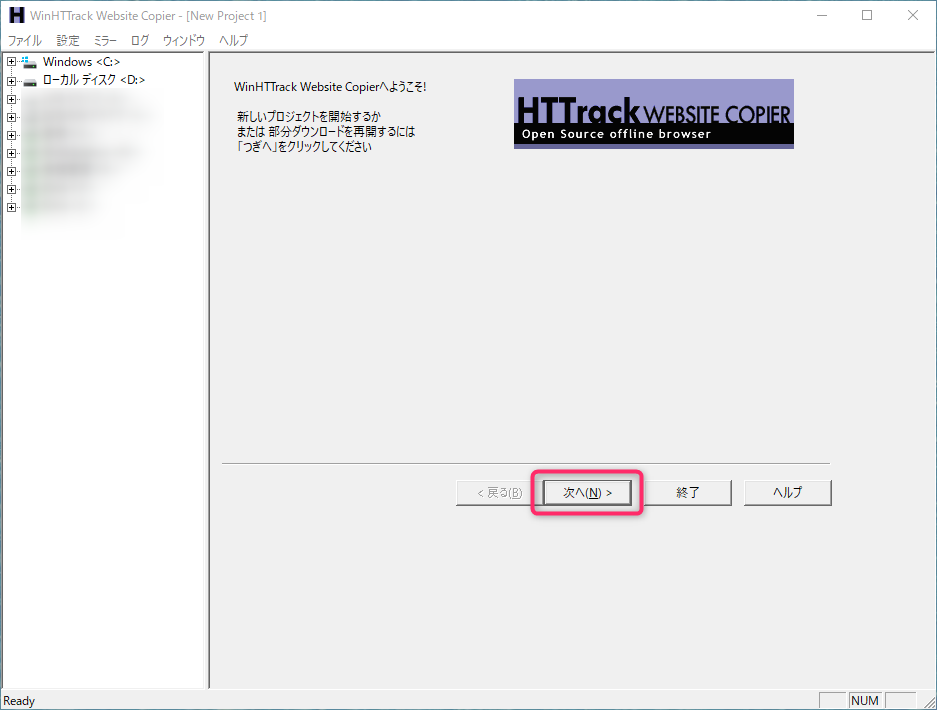
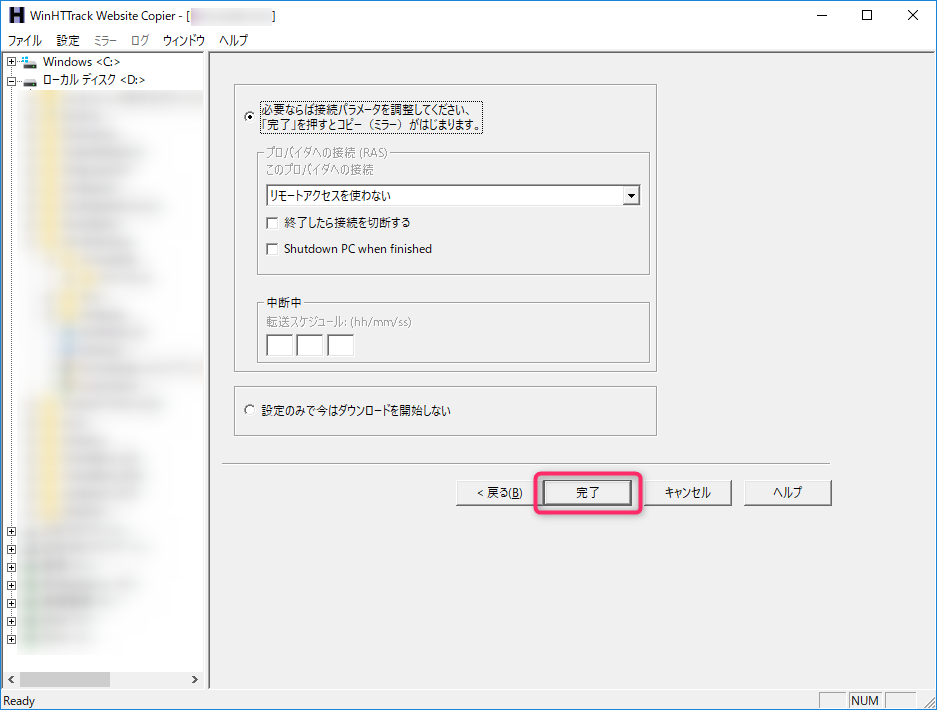
- HTTrack(WinHTTrack)を起動すると、以下の様な画面が出るので「次へ」ボタンを選択

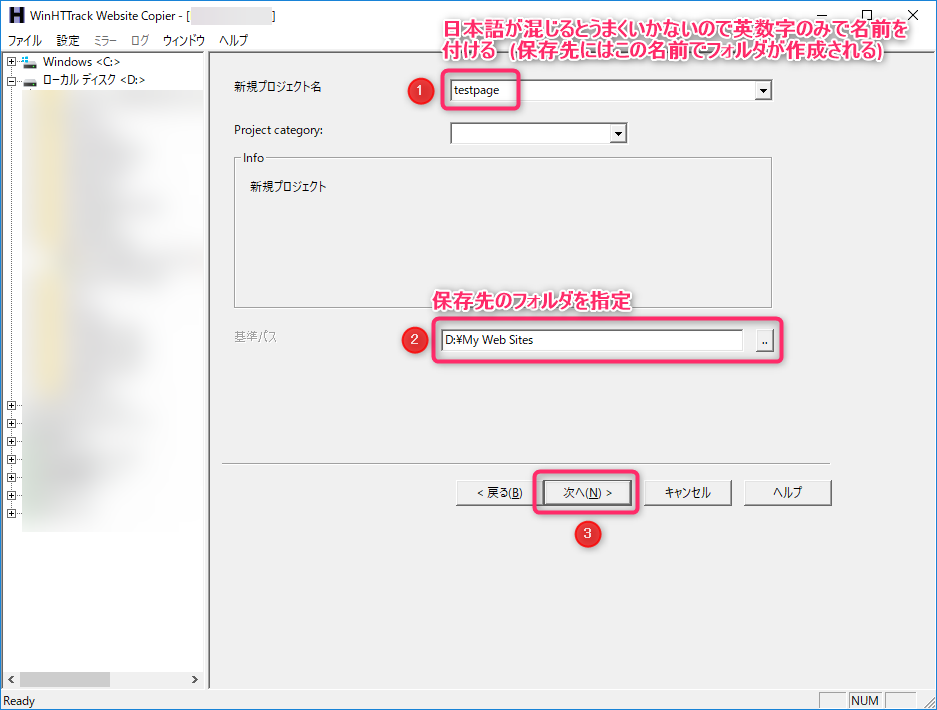
- 新規プロジェクト名・基準パス(保存先のフォルダ)を指定して「次へ」ボタンを選択

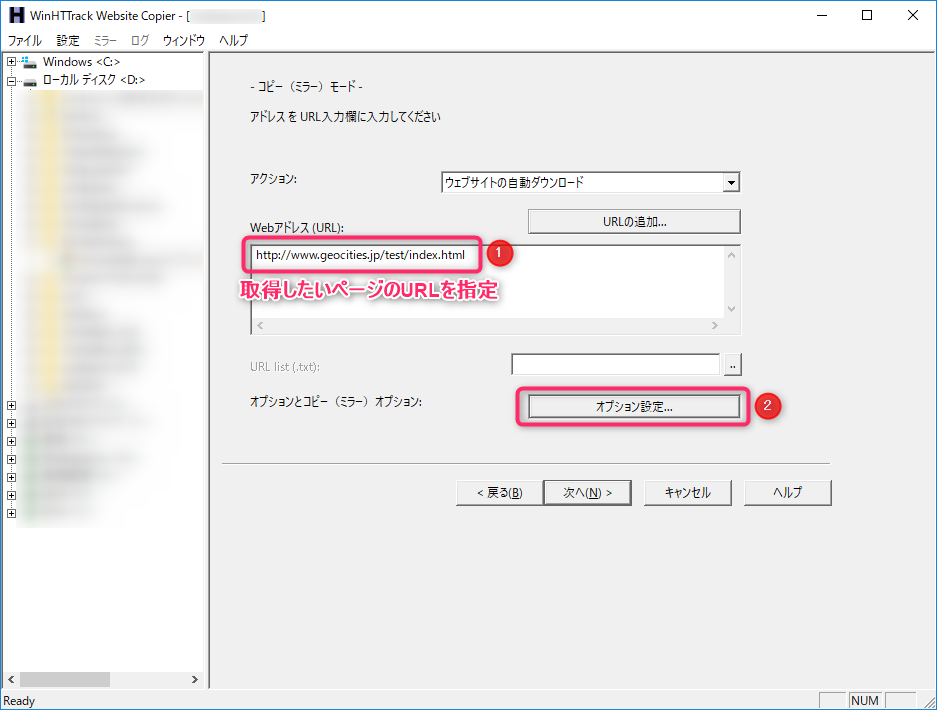
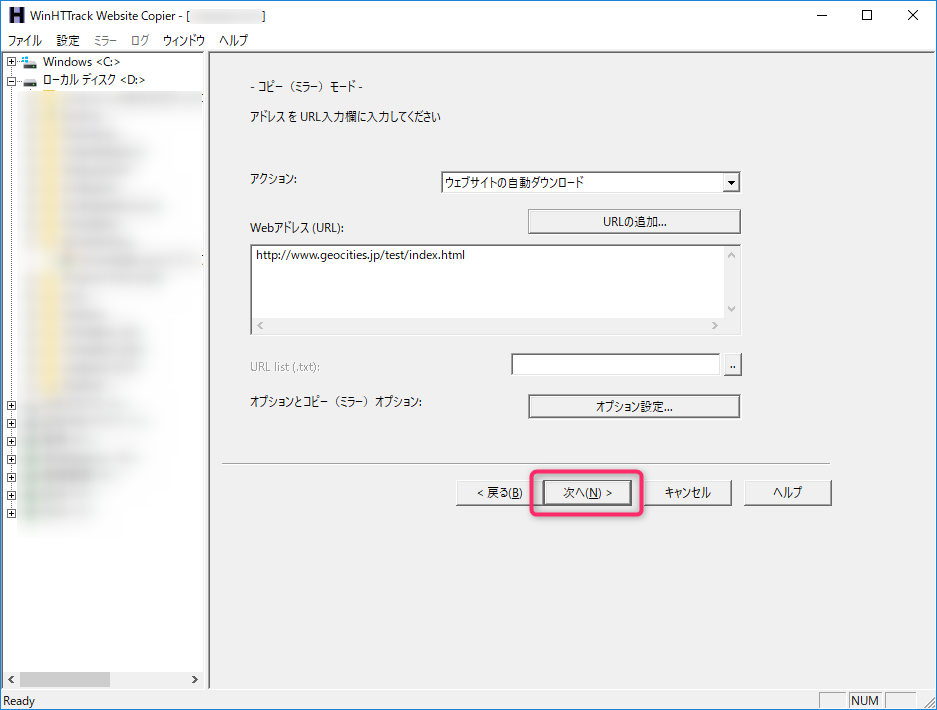
- 取得したいWebページのURLを指定して「オプション指定」ボタンを選択

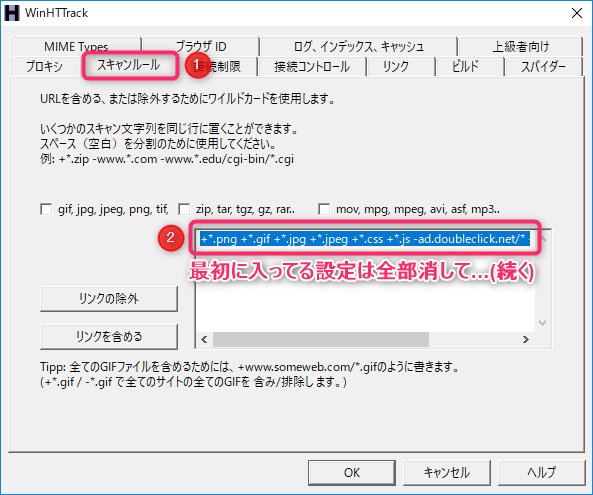
- 「スキャンルール」タブ→最初に入ってる設定は全部消して…

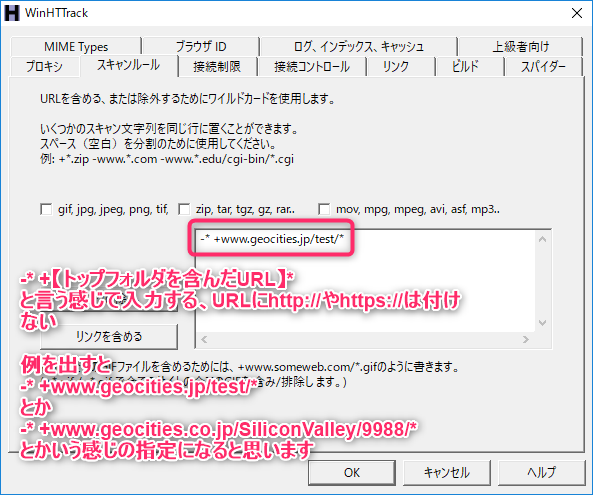
- 以下のフォーマットで、トップフォルダを含むURLを指定する
-* +【トップフォルダーを含んだURL】* ※ここで入力するURLにhttp://やhttps://は付けない 例①: -* +www.geocities.jp/test/* 例②: -* +www.geocities.co.jp/SiliconValley/9988/*
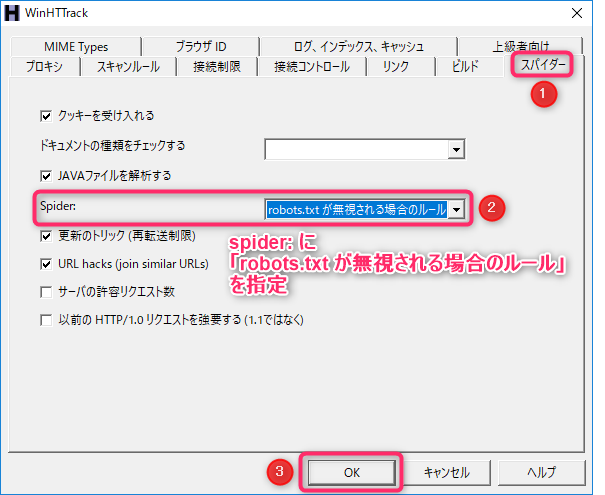
- 「スパイダー」タブ→「Spider:」を「robots.txt が無視される場合のルール」に設定→「OK」ボタンを選択

- 「次へ」ボタンを選択

- 「完了」ボタンを選択

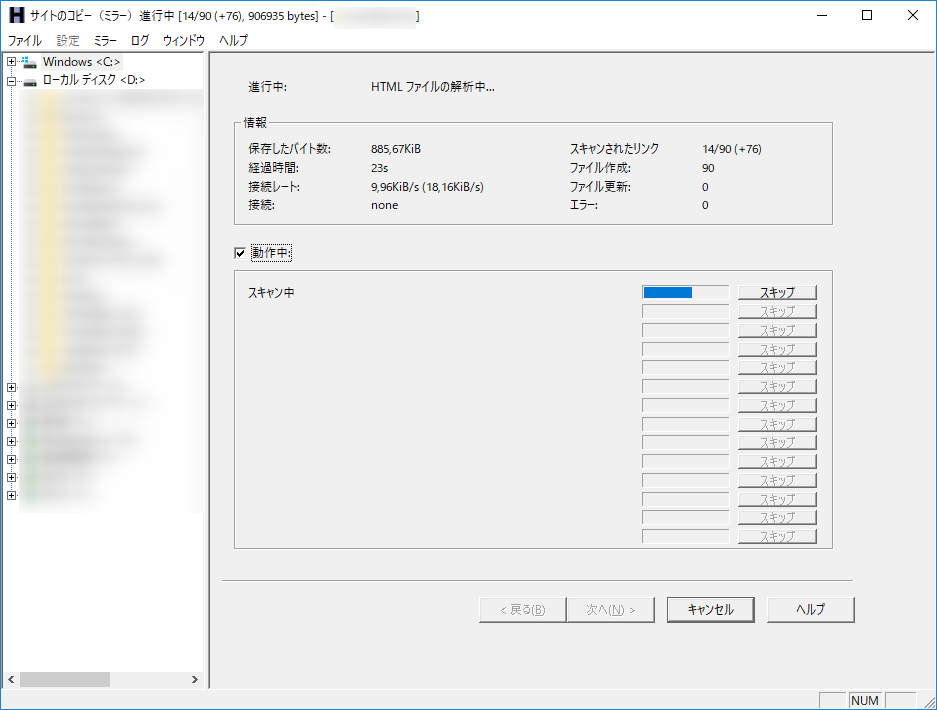
- 取得が始まりますので、終わるまで待ちます

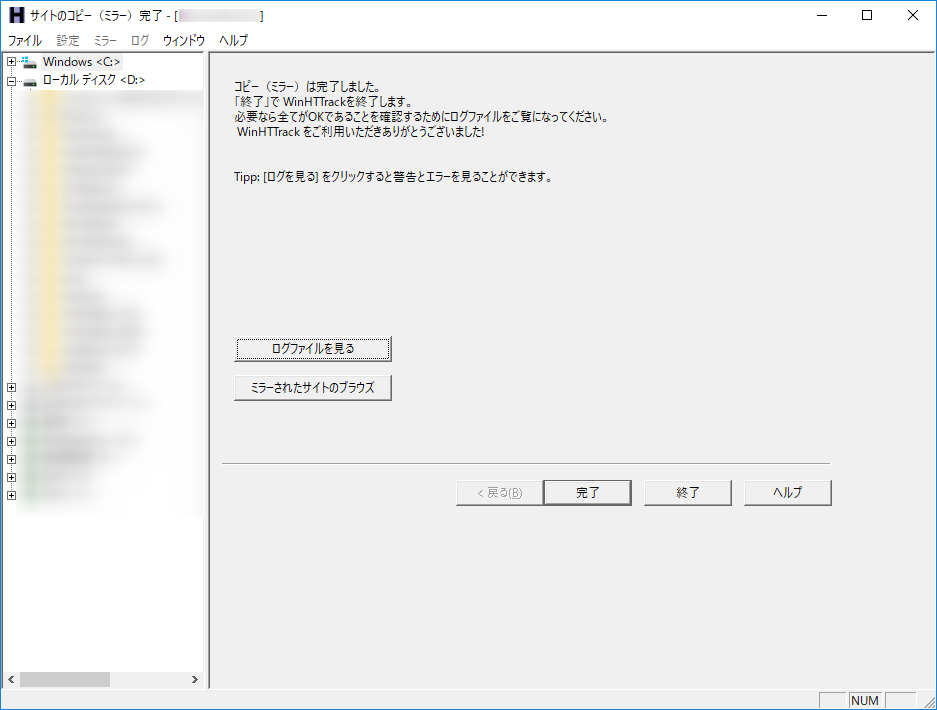
- 「コピー(ミラー)は完了しました」と出れば完了です

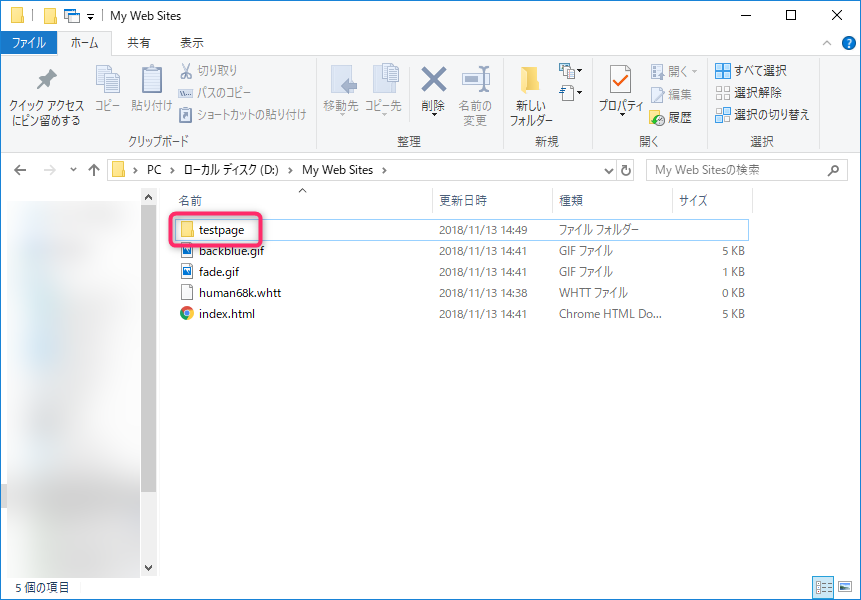
- 基準パス(保存先のフォルダ)に、新規プロジェクト名の名前でフォルダが作成され、この中に取得したサイトのWebデータが入ります


ここにあるファイルは、HTTrackで複数のサイトを保管・管理するための物なのですが、私はWebサイトのデータが取れれば良いので不要です
スキャンルールのおまけ話①
今回はGeositiesだけにあるファイルを取り込もうと思ったので
-* +【トップフォルダーを含んだURL】*
※ここで入力するURLにhttp://やhttps://は付けない
例①:
-* +www.geocities.jp/test/*
例②:
-* +www.geocities.co.jp/SiliconValley/9988/*というフォーマットにしましたが、もうちょっと再現性を高めようと思ったら
-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +【トップフォルダーを含んだURL】* -ad.doubleclick.net/* -mime:application/foobar
※ここで入力するURLにhttp://やhttps://は付けない
例①:
-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +www.geocities.jp/test/* -ad.doubleclick.net/* -mime:application/foobar
例②:
-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +www.geocities.co.jp/SiliconValley/9988/* -ad.doubleclick.net/* -mime:application/foobarとかでも良いと思います、サイトによってはより再現性が高まる…かもしれません
※デフォルト設定されてるスキャンルールを合わせてみた物です
スキャンルールのおまけ話②(Yahoo!ブログ)
Yahoo!ブログでは画像が以下の3つのドメインに点在しており、この画像が取得できる事が最低条件となります
- blogs.yahoo.co.jp
- blogs.c.yimg.jp
- blog-001.west.edge.storage-yahoo.jp
しかしHTTrackを使うとhtmlファイルが異常増殖したり、一部のhtmlファイルの拡張子がtxtに(00000.html.txt とか) なったりと問題が起きるため、断念しました
HTTrackを使う事を諦め、別のアプリ「ホームページクローン作成」を使う事で上手くサルベージできました、画像も問題なく取得できている様です
ホームページクローン作成の詳細情報 : Vector ソフトを探す!
トラックバック URL
https://moondoldo.com/wordpress/wp-trackback.php?p=3394