Introduction
この記事は先日行われた創作+機械学習LT会で発表した以下の資料の補足になります。
資料でも述べているように、一般的に線画着色の際のヒントの与え方は下画像のようにアタリ、タグ、リファレンスの3種類が存在します。リファレンスは少し分かりにくいですが画像を与えてこのような色配置で塗ってほしいと指定するものです。

前回の記事ではこの3種類の内アタリを与えた方式について実験した結果を述べました。今回の記事ではこのアタリ方式を少し昇華させたものと、リファレンス方式について実験した結果について述べていきます。
Method: Atari
①Improvements
前回の記事において、下画像のようなUNetをベースとしたGeneratorとDiscriminatorを用いたpix2pix方式の線画着色を行なっていました。ヒントとなる当たりは入力として与えるだけでした。

しかし、この方式では大局的には塗れているように見えるものの局所的には塗れていませんでした、例えば細かい部分が塗れていなかったり色がはみだしたりしている等です。また、前回の記事には含めていませんが学習の際にXDoGという一種類の線画抽出法を用いていたため、そのような線画だけに過学習してしまい他の種類の線画には対応できず下図のようにスプレーをかけたようになっていました。そこで、以下の3つの変更点を加えました。

(1) 入力として用いる線画の種類の増加
ヒントをタグとして与える方式であるTag2Pixにおいて、一種類の線画だけではその線画に過学習してしまうので様々な線画を用意するのがいいと述べられています。そこでTag2Pixを参考にして、線画抽出の方法として3つ使用することを検討しました。以下それらについて述べます。
- XDoG
前回の記事でも用いていた線画抽出法 - SketchKeras
UNetを用いた線画抽出法。鉛筆を用いたスケッチに近い線画を抽出 - Sketch simplification
Fully-Convolutional Networkを用いてスケッチをデジタルな線画に変換。線の太さが均一
以上3つの線画抽出法を用いました。Sketch simplificationではSketchKerasで抽出したスケッチをデジタルな線画に変換しました。上記3つの手法に対応する線画の画像は以下のようになっています。

また、線画の種類だけでなく様々な線の太さに対応するため、学習の際には抽出した線画に対して様々なサイズに拡大縮小を行なってそこからクラップするということを行いました。
(2)ヒントの与え方の変更
前回の記事ではヒントとして用いるアタリはニューラルネットワークの入力に線画とチャンネル方向に連結させて与えているだけでした。しかし、昨今の特徴の与え方を見るに中間層に連結させる方式も見受けられます。そこで、そのような特徴の与え方として上記でも述べたTag2Pixを参考にしました。Tag2Pixでは下画像に示すSECatと呼ばれるモジュールを用いて特徴を与えています。

これは、Squeeze-and-Excitation NetworkでGlobal Average Poolingをした後に、予めタグ情報を特徴抽出しておいたもの(図中のCVT encoder出力)をチャンネル方向に連結させて与えるというものです。この手法をアタリが持つ空間情報を保持させるため、以下のようなSACatというモジュールを用いました。Spatial Attentionの前にヒントから抽出した特徴量をチャンネル方向に連結しています。

(3) Multi-Scale Discriminator
線画を細部まで綺麗に塗るためには大局的な特徴を見るだけでなく、局所的な細部特徴まで捉えなければいけません。従ってAdversarial learningにおいてDiscriminatorも大局的な特徴から局所的な特徴まで判別出来る必要があります。そこでpix2pixHDを参考に様々なスケールの画像を入力にしたMulti-Scale Discriminatorを用いました。今回は3段階のマルチスケールで行なっています。具体的には以下の画像のような方式と構造になります。

以上(1)~(3)の3つの変更を加えた学習を行いました。
②Dataset
データセットとしてはKaggleのTagged Anime Illustrationsを用いました。学習前にSketchKerasとSketch Simplificationを用いて線画を抽出しました。学習時には(1)でも述べたようにこれら線画に対して様々なサイズ(280✕280 ~ 768✕768からランダムに選択)にBicubic補間でリサイズし、そこから256✕256をクラップしたものをニューラルネットワークを入力として用いました。
③Training Details
以下学習時の詳細を示します。
- バッチサイズは16
- 損失関数としてはAdversarial loss、Content loss(出力画像と正解画像の平均絶対値誤差)に加えてStyle2paints V3で用いられているPositive Regulation lossを用いている。Positive Regulation lossによって色のバリエーションを増やすことを目指す。またAdversarial lossにはHinge lossを用いている
それぞれの係数はAdversarial lossが0.01、Content lossが1.0、Positive Regulation lossが0.001である - 最適化手法はAdam(α=0.0002、β1=0.5)
- XDoGのパラメータにおいてσは学習時に0.3, 0.4, 0.5からランダムに選択している
④Results
それではテストデータに対する結果を見ていきます。まずは所望の着色が得られている例です。











かなり細かい色の漏れは存在しますが、問題なく塗れているかと思います。しかし、以下に示す着色結果のようにうまく塗れてない例も存在します。

これらテストデータの特徴としては線画をXDoG, SketchKeras等で作ったものではない、つまり学習データに含めていない線画の種類であるということです。勿論線画によっては学習データに含まれていないものでも塗れているのですが、ものによっては上画像のような色の膨張やアーティファクトが生じてしまいます。今回は入力データとして線画の種類を3種類、また線の太さに対応するためリサイズ&クラップをしていますがそれだけでは不十分という事だと推測しました。線画着色の論文も様々にありますが、線画の種類による着色の変わり方について触れている論文は見受けられないのでこの辺を対処していきたいです(知見がある方は教えていただければ幸いです)。取り敢えず線画の種類を増やす(3種類の線画のブレンド)等のAugmentationでどう変わるのか見ていきたいです。
⑤Other Methods
今回行なった3点の工夫以外に、以下の事を試しました。所望の結果が得られなかったので採用しませんでした。
- GauGAN
GauGANはSpatially-Adaptive Normalization(SPADE)を用いた手法です。今回は以下の図のように線画をEncoderによって特徴抽出した後SPADEによってアタリ画像を与えながら着色出来ないかと思い検討しました。
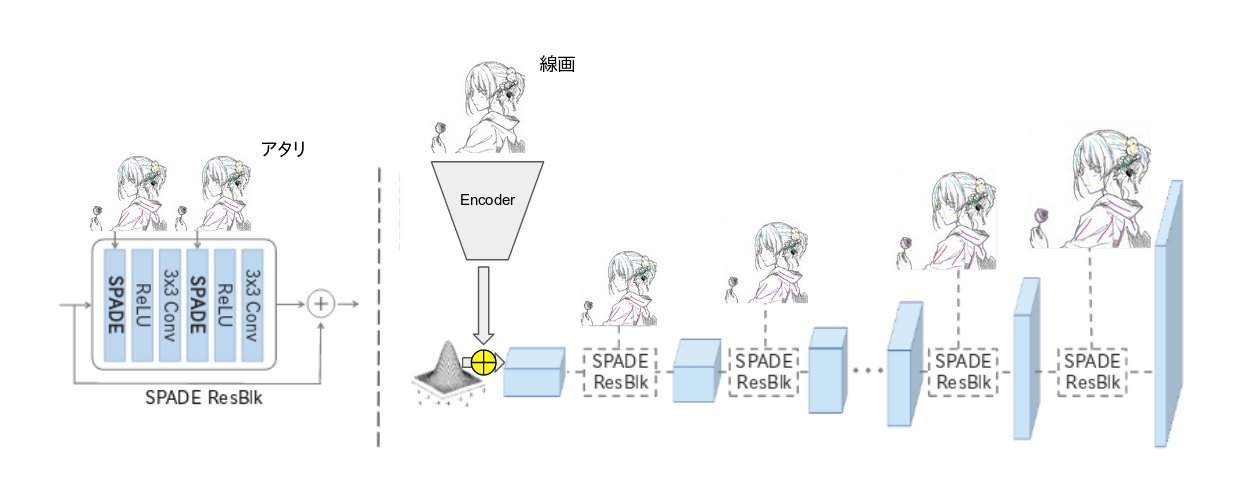
しかし以下の学習結果が示すように色はアタリ画像のものを選んではいるものの着色結果がかなりアーティファクトを含むものでした。

- style2paints V3
前回の記事のFuture Worksでstyle2paints V3について述べました。style2paints V3では二段構成の学習を行なっており、一段目で大雑把に塗った後二段目で詳細に塗るという手順を取っています。その二段目の学習においては、大雑把な着色結果をシミュレートして入力に与えます。style2paints V3では大雑把な着色結果で起こりうる塗り間違いを3種類に分けて、それぞれをシミュレートしました。以下、3種類のシミュレート手法について簡単に述べます。
(1)Random region proposal and pasting
他の画像の一部の領域等を貼り付けるシミュレート手法です。これにより本来あるべき色の間違いを助長します。
(2)Random transform
Spatial Transformerを用いて画像内の物体を変形させるシミュレート手法です。これにより色の歪みやぼかしを助長します。
(3)Random color spray
画像内で優勢な色を用いてスプレーをふりかけるようなシミュレート手法です。これにより色のはみ出しを助長します。
今回の実験でも上記3つのシミュレート手法を用いて以下のような学習データを作成し、二段目の学習を行いました。


着色結果を以下に示します。画像の一番右が二段目の出力になります。



このように一段目である今回の着色結果に対して、二段目で補正を行うようにしたのですが特に変わっていないどころか線に余計な色がついていたり悪さをしている部分もあります。style2paints V3でははみ出しの修正も行なっている例もありますが、今回の学習結果ではそのような修正は見受けられませんでした。はみ出しの助長を行うRandom color sprayをもっと大袈裟にやる等改善点はあるかもしれないですが現時点では学習に失敗しています(実装力の無さ….)。
⑥Summary
この章ではアタリ画像を用いた線画着色を検討しました。結論としては結局線画の種類によってうまく着色できていない部分もあるので、今後はその対処をするというものでした。これらの対処が出来るようになった後、方向性としては以下2つのものを考えています。
- レイヤー毎の着色
実際にデジタル絵を塗られたことのある方は経験があるかと思いますが、実際の着色ではレイヤーに分けて着色を行います(ベタ塗りをするレイヤーと厚塗りをするレイヤーに分ける or 各パーツ毎にレイヤーを分ける etc)。このように絵師さんが行なっている方式をトレースすることでより線画着色の精度を上げるというものです。 - 様々なスタイルを指定可能な着色
今回はイラストを用いて学習を行なったので、着色結果もイラスト風の塗り方なのですが塗り方は何も一つではないので様々なスタイルが指定出来ればと思います。以下のように今回学習したモデルを用いながら、少し画像処理を加えるだけで着色結果も変わったものになります。従ってなるべく省力化してスタイルの幅を増やしていきたいです。


Method: Reference
①Related Work
リファレンス画像を与える方式とは、下の図のように着色された画像を用意して線画をこのように塗ってほしいと指定するものです。

このようなリファレンス画像を与える方式で着色する手法としてはstyle2paints V1があります。style2paints V1では下図のようにリファレンス画像をVGGによって4096次元の特徴ベクトルに変換し、それをUNetの中間層に挟むことでリファレンス画像の特徴を利用した着色を行なっています。

UNetの着色に対してAdversarial lossを用いて着色をより自然にします。ACGANと同様に単にReal/Fakeを判別するだけでなく、先ほどVGGを通すことで求めた4096次元のベクトルにDiscriminatorの出力ベクトルがなるように学習を行います。

しかしこのようなマルチラベルかつクラス数の多い学習は一般的に難しいです。そこで、style2paints V3ではUNetの途中にGuide Decoderを設置して勾配消失が起こらないようにしました。実際にGuide Decoderによって意図した着色がされるようになったと以下の図で主張しています。

②Network Architecture
以上のようにstyle2paints V1でリファレンス画像を用いた着色が可能なように見えたので実装して実験をしていたのですが自分の実装では成功しませんでした。4096次元という次元の大きなベクトルをDiscriminatorが予測するように学習することは難しく中々収束しない状況でした(実装力の無さ….)。そこで別の方式で達成することが出来ないかと思いAdaptive Instance Normalization(AdaIN)を用いた手法を検討しました。
AdaINについては以前の記事でも述べているのですが、元々はNeural Style Transferにおいて用いられていたもので、ある画像(content)に対して別の画像(style)のスタイルを適用するというものでした。Instance Normalizationのスケーリング係数とバイアスが学習済の限られたスタイルにしか変換出来なかったのに対して、AdaINは下式のようにスタイル画像特徴量の標準偏差と平均をスケーリング係数とバイアスに用いているので適応的に変換することが可能になりました。

先述したようにNeural Style Transferのタスクにおいて用いられていたのですが、昨今StyleGANやFew-shot系のStyle Transferで用いられているのが見受けられるので、今回のリファレンス画像を与える方式に使えないかと思い検討するに至った次第です。従って今回のタスクにおいてはcontentが線画を表し、styleがリファレンス画像を表します。線画に対してリファレンス画像というスタイルを適用することを目指します。ネットワーク構造は以下になります、着色を行うGeneratorとReal/Fakeを判別するDiscriminatorを示します。Discriminatorはアタリを与える方式同様3段階のMulti-Scale Discriminatorを用いています。



③Dataset
アタリ方式と同様にデータセットとしてはTagged Anime Illustrationsを用いました。ここからランダムに224✕224のサイズにクラップしてネットワークの入力に与えました。学習の際に入力に用いる線画はリファレンス画像から抽出したものとし、リファレンス画像を正解画像としました。
④Training details
以下学習時の詳細を示します。
- 損失関数としてはAdversarial loss, Content loss。Adversarial lossとしてはHinge lossを用いた。また、それぞれの項の係数はAdversarial lossが1.0、Content lossが10.0とした。
- バッチサイズは16
- 最適化手法はAdam(α=0.0001、β1=0.9)
⑤Results
それでは結果を見ていきます。まずはうまくいっている例です。以下の図のようにリファレンス画像のような着色が可能になっているかと思われます。







次にうまく塗れていない例を示します。主に2パターン存在します。
- 領域内を一色で塗れていない
特に線画のキャラクターが長髪の場合に顕著です。下の画像のように頭に近い髪の部分はリファレンス画像の色で塗れているのですが、頭から離れるにつれて服の色が転写されているのが分かるかと思います。


- 行き場のない色
例えばリファレンス画像のキャラクターがネクタイやリボンをしていたり帽子を被っていたりしているのに対し、線画のキャラクターがそういった類のものをしていない場合に顕著です。リボンやネクタイに使われている色を写像しようとして行き場が無くなり取り敢えずそれっぽい位置に塗っているのが分かるかと思います。


以上のように2パターン示しましたが、特に1パターン目から言えるのはリファレンス画像の色の位置と線画で塗られた色の位置が対応している必要があるということです。構造が線画とリファレンス画像で互いに異なるものは、髪の位置等を判別しながら学習をしていないので上記のような塗り間違いが起こっているものと推測します。従って画像内の領域を判別させながら対応するように学習する必要があると考えています。
例えばこちらの手法では、リファレンスの画像を上から4分割しそれぞれの領域で最も用いられている4つの色マップを作りそれを入力に加えています。上から4分割しているので結局髪等の広範囲に跨るものは難しいのではないかと思ってはいるのですが、結果を見る限り綺麗に出来ているので検討する次第です。

またリファレンス画像を与える方式では、こちらの論文において以下の図のようにMemory Networksが正解画像の特徴に対して最も一致するような色特徴を学習します。そして推論時には与えたリファレンス画像の特徴に対して学習済の最も一致する色特徴を入力画像にAdaINで与え、その色特徴を元に着色を行うというものです。こういった手法も検討する次第です。

Summary
ここまで読んでいただき有難うございます。今回はヒントを与える方式として、アタリとリファレンス画像を与えたものをそれぞれ検討しました。それなりに効果は見られているものの、どちらも予期していない入力(アタリ方式では学習データから大きく離れた種類の線画、リファレンス方式では構造の大きく異なる線画とリファレンス画像)に対しての頑健性が低いという結果となっています。次はそこへの対処をしていきたいです。
