
概要
webサービスを公開するにあったて必ず使われることになるのがブラウザです。ブラウザがユーザーにwebページを表示する仕組みを理解することで、フロントエンド開発に役立てたり、ページ表示までのレスポンスの改善などに役立てていきたいと思い、今回ブラウザのレンダリングの仕組みの基本事項についてまとめました。
レンダリングの流れ

ブラウザがWebページをレンダリングする仕組みは上のような一連の流れになっています。以下でその一つ一つの工程の内容をみていきます。
レンダリングエンジンとJavaScriptエンジン
各工程をみる前に、ブラウザの構成要素をみていきます。
ブラウザにはレンダリングエンジンとJavaScriptエンジンという2つのエンジンが動作しています。
レンダリングエンジン
HTMLやCSSなどを解析し、実際の画面に描画するためのもの。
レンダリングエンジンによってHTMLやCSSの解釈に差があるためデザインがブラウザによって崩れるという問題があります。
JavaScriptエンジン
JavaScriptを実行するためのエンジン。
【主なブラウザと各種エンジン】
| ブラウザ | レンダリングエンジン | JavaScriptエンジン |
|---|---|---|
| Google Chrome | Blink | V8 |
| Safari | Webkit | Nitro |
| IE | Trident | Chakra |
| Microsoft Edge | Blink | V8 |
| Mozilla Firefox | Gecko | SpiderMonkey |
| Opera | Blink | V8 |
Microsoft Edgeの新しいversion(Chromiumベース)が来年の1月15日にリリース予定です。
https://forest.watch.impress.co.jp/docs/news/1216492.html
リソースのダウンロード
ブラウザにURLが与えられると、ブラウザは画面のレンダリングに必要なリソース(HTMLやCSSファイル、JavaScriptファイルや画像ファイルなど)を読み込み始めます。
リソースは通常サーバ上に保存されていて、TCP/IPプロトコルを用いてブラウザはサーバーにリクエストしてレスポンスとしてリソースを受け取ります。
オブジェクトモデルの構築
ブラウザではレンダリングを行うために取得したリソースから「オブジェクトモデル」と呼ばれるものを構築します。この時、HTMLはDOMに、CSSはCSSOMに変換されます。
以下の図のように、
バイト→文字列→トークン→ノード→オブジェクトモデル(DOM/CSSOM)
という流れでオブジェクトモデルは構築されます。
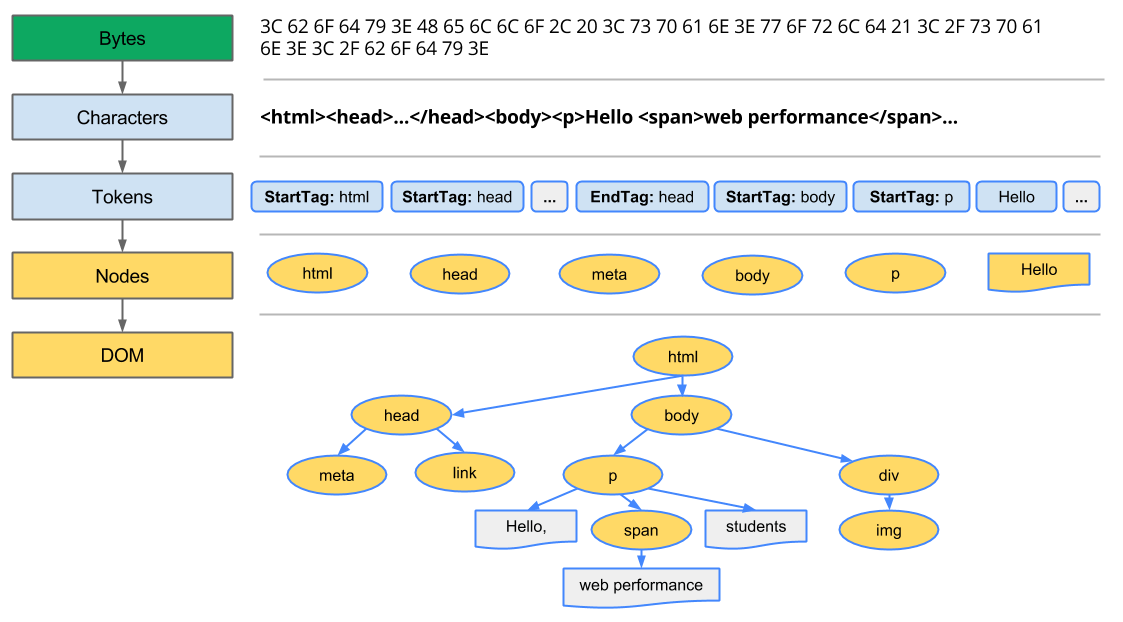
DOMツリーの構築
変換
ブラウザはディスクやネットワークからHTMLのバイトを読み取り、utf8などの文字コードに応じてや
のような文字列に変換しますトークン化
文字列をStartTag:htmlやEndTag:headといったトークンに変換します(W3C HTML5 standardによって決められています)。
字句解析
トークンはプロパティとルールを定義するオブジェクトに変換されます。
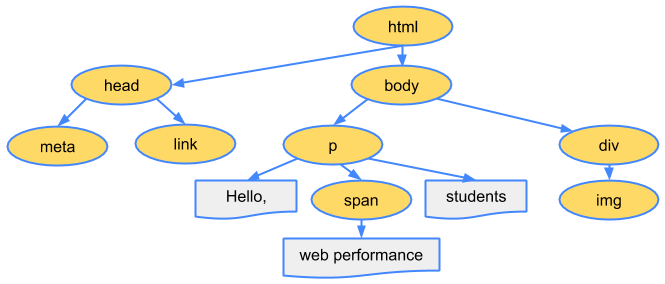
DOMの構築
オブジェクトはツリー構造にリンクされます。このツリー構造はオリジナルのマークアップの親子関係をそのまま保持します。つまり、HTMLオブジェクトはbodyオブジェクトの親であり、bodyは
オブジェクトの親であるという関係になります。ブラウザでは以降このページを処理する際に必ずこのDOMを使用します。
ブラウザはHTMLを処理する度に上のDOM構築の一連の流れを全て行うため処理するHTMLが多い場合は一連のプロセスに時間がかかりボトルネックになってしまいます。
ページのライフサイクルイベントのDOMContentLoadedはDOMツリーの構築が完了した時点でレンダリングエンジンにより発火されます。そのためDOMContentLoadedイベントの時点では画像やCSSは読み込まれていない可能性があります。同じライサイクルであるloadイベントは画像やCSSなどを含む全てのリソースを読み込んだ時点で発火します。
CSSOMツリーの構築

ブラウザでDOMを構築している際にドキュメントのheadタグで外部のcssスタイルシートを参照しているlinkタグに遭遇すると、ブラウザはページのレンダリングにこのリソースが必要であると想定してこのリソースに対するリクエストを即座にディスパッチし、CSSのパースを行います。HTMLと同様にバイトが文字列、トークン、ノードに変換され最終的にCSSOMツリーを構築します。
DOMツリーとCSSOMツリーはそれぞれ独立しており後の工程で出てくるレンダリングツリーによってリンクされます。
JavaScriptの実行
各種リソースを読み込んだ後は、JavaScriptエンジンによってJavaScriptのコードが解析、実行されます。
まずJavaScriptのコードが字句解析されトークンとなり、次に構文解析され抽象構文木となり、最後にコンパイルされて実行可能なファイルとなり実行されます。
レンダリングツリーの構築
コンテンツを記述したDOMツリーととドキュメントに適用するスタイルルールを記述したCSSOMツリーを結合することでレンダリングツリーを構築する必要があります。レンダリングツリーは各表示要素のレイアウトを計算するために使用され、画面にピクセルをレンダリングするペイント処理の入力となります。
レンダリングツリー構築の手順として、DOMツリーの各要素に対してどのCSSプロパティがマッチするかを計算します。CSSのルールセットにはh1やpのようなCSSセレクタと、widthやcolorのようなCSSプロパティがあり、最初にCSSセレクタによってDOMツリーの要素とCSSルールのマッチングを行います。その後、各DOM要素にどのCSSプロパティがマッチングするかを計算します。

CSSセレクタのマッチンング
レンダリングエンジンはCSSセレクタを右側から順に評価していきます。
ex)
.name > ul > li > p {
color: red;
}
上のような場合、レンダリングエンジンはページ内の全ての要素に対して次のように判定します
- DOMがpである
- pの親要素がliである
- liの親要素がulである
- ulの親要素のclass名にnameが含まれている
CSSプロパティのマッチング
どのCSSプロパティがDOM要素に適用されるかをレンダリングエンジンが決定するための詳細度という仕組みがあります。詳細度には3つのレベルがあり、各CSSセレクタとの関連は次のようになっています
A. IDセレクタ
B. クラスセレクタ、擬似クラスセレクタ(:first-child)、属性セレクタ([type=input])
C. 要素セレクタ(div)、擬似要素セレクタ(::before)
各レベルの優先度は A > B > Cとなっていて1つでも上位レベルが含まれる場合はそれが優先され、同じレベルでは値が大きい方が優先されます。
ex)
// A=0, B=2,C=0
.wrapper > .container {
color: red;
}
// A=0, B=1, C=1
div > .container {
color: white;
}
// A=1, B=0,C=0
#id {
font-size: 20px;
}
// A=1, B=0,C=0
#id {
font-size: 30px;
}
// A=1, B=0, C=1
#id::before {
content: 'user';
}
上の例で2つのcontainerクラスが同じ要素に対して修飾されている場合、詳細度から color:redの方が優先されます。また詳細度が同じ場合は後に定義されたCSSルールセットが適用されますそのため上の例の#idの要素にはfont-size:30pxが適用されます。
レンダリングツリーのレイアウト
レイアウトの工程では端末ビューボード内での各ノードのレイアウト情報を算出しますレイアウト情報には要素の大きさやmargin/padding、x/y/z軸の位置などが含まれます。
レンダリングエンジンはレンダリングツリーのルート要素から順番に各要素が持つCSSプロパティを元にレイアウト情報を決めていきます。
ex)
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>
上のようなHTMLの場合、viewportがデバイスのサイズで倍率が1倍ということに決まります。
ネストされた2つのdivがあり、1つ目のdivがviewportの幅の50%になり、2つ目のネストしたdivの幅は親のdivの50%(全体の25%)になります。

レンダリングツリーの描画
webページの描画にはペイントとコンポジットの2つの工程があります。
ペイント
各レイヤごとにテキストや色、画像などをピクセルに書き込みます。
1. 命令リストの作成
2. ピクセルへの書き込み
の2つの工程からなります。
まず前の手順で構築したレンダリングツリーを元にグラフィックエンジンのための命令リストを作成します。命令リストでは「どのピクセルに何色を入れるのか」という命令が入っているため、その命令を元にグラフィックエンジンがピクセルの描画を行います。
次にピクセルの書き込みを行います(ラスタライゼーション)。ピクセルの書き込みはレイヤ単位で行われ、position:abosolute;やopacityといったCSSプロパティなどz軸を考慮する必要のある要素が存在する場合は新しいレイヤが作成されます。
コンポジット
ピクセルを書き出したレイヤを合成してレンダリング結果を出力します。
まとめ
ブラウザレンダリングの仕組みを各工程ごとにみることで、ページライフサイクルのイベントがどの工程で発生するのかをきちんと理解できるようになりました。レンダリングの仕組みの知識を元に、ブラウザの開発ツールを駆使して開発時にデバッグやパフォーマンスのボトルネックの分析、改善に役立てていきたいと思います。




