
概要
某T大学で情報系を専攻している学生です。Qiitaの記事を色々見ていたら、こんな記事を発見。
この記事の回収率100%達成に関しては、購入シミュレーションした馬券の数が少ないので、他の期間でも成立するのかはわかりません。ソースコードも有料なのでどうやっているのかの詳細もわかりません。しかし、自分で競馬予測をしてみても面白そうだと思ったので、勉強するつもりで実際にやってみました。
データ収集・分析・予測のすべてを行うことになるのでかなり勉強になります。
なぜ競馬なのか?
もしかしたらお金になるかもしれないという欲もありましたが、競馬は控除率が高いらしいのであまり期待はできません。
大きな理由としては最近話題になっていたから・ディープラーニングをやってみたかったから、ですかね。
競馬を選んだ他の理由としては、
- レース結果が観客によって左右されることが少ない
- 説明変数が足りていればそこそこの精度で予測ができそう
というのが挙げられます。
株をテーマにするのも良さそうですが、これは多くの人間の意思決定によって値段が変動するので、取引する人がよく見るニュースなどの情報を取り入れないと、良い精度で予測することが難しそうです。
さらに、たくさんの機関投資家がアルゴリズムに応じて注文を自動で行うので、これに左右されることになりそうです。
以上から今の技術では簡単にはできなさそうだと思ったので、競馬のほうがディープラーニング向きだと思いました。
競馬は出走馬の数がレースごとに違うのですが、競艇なんかは出場選手の数が一定らしいです。詳しいデータが得られれば機械学習しやすそうですね。
競馬が初めての人への説明
「競馬(けいば、英: horse racing)は、騎手の乗った馬により競われる競走競技、およびそれの着順を予想する賭博である」(引用:競馬 - Wikipedia)。
私も今回のデータ分析をするまでは競馬に関しての知識がほとんど無かったので、この記事を読むために必要そうだなと思った知識をまとめておきます。
まず基礎知識として馬券の種類について知っておきましょう。単勝・複勝くらいをななめ読みするくらいで大丈夫です。
参考: 馬券の種類:はじめての方へ JRA
他の用語は以下を参考に
- オッズ: 単勝時にもらえるお金が、掛けたお金の何倍かを表す倍率
- 上がり: レースや調教における終盤のこと
- 馬番(うまばん): 出走馬に一意に割り当てられる番号
- 枠番: 1から8まである。出走時のゲート2つに対して1つの番号
- 着順: ゴールへの到達順位
- 中央競馬: 日本中央競馬会が開催する競馬。 札幌・函館・福島・新潟・中山・東京・中京・京都・阪神・小倉の10箇所がある
- 地方競馬場: 中央競馬とは違い、地方公共団体が主催する競馬
参考: 競馬用語辞典 JRA
そこまで詳しくないので間違っていたら教えて下さい...
機械学習では、ドメイン知識が重要と言われるので、予測精度を上げるためには競馬に詳しくなることが必要条件となるでしょう。
大まかな手順
競馬の予測をすると行っても、考えること・やるべきことは大量にあります。大きく手順を分けると以下のとおりでしょうか。
- データ収集(クローリング・スクレイピング)
- データ整形(pandas・SQLなど)
- モデル作成(機械学習)
競馬予測をしようと思う人にとってまず大きな課題となるのは、データ収集・整形の部分でしょう。Kaggleなどのコンペではデータセットがはじめから与えられるのでかなり楽ですが、今回はデータ収集から始める必要があります。
また、モデル作成についても、様々な方法が考えられるので難しいです。最近はライブラリで簡単に勾配ブースティング・ディープラーニングなどを用いることができますが、予測精度を上げるためには色々な手法を試してみる必要があるでしょう。
前提知識
- HTML, CSS などの基礎知識
- Selenium の基本的な使い方
- Beautifulsoup の基本的な使い方
- pandas の基本的な使い方
- keras の基本的な使い方
結果の概要
使用データ
- 学習データ:2008年1月~2017年7月23日
- 検証用データ: 2017年7月23日~2019年11月あたり
結果
- 単勝正解率: 0.2450
- 複勝正解率: 0.5434
競馬初心者の自分よりも精度が高いモデルができました
さっそくデータ収集からはじめてみる
データも無いのにいきなり機械学習はできません。クローリング・スクレイピングをしましょう。
まずは対象となるサイトから、過去のレース結果や馬の情報を取得します。
ここで得るデータはなるべく生のデータに近いものにして、学習のために後でデータ整形をすることとします。
対象サイト
国内最大規模の競馬情報サイトです。過去のレースデータから馬の血統情報まで、無料でかなり詳しくデータを手に入れることができます。
有料会員になればより詳細なデータを得られるようです。よりモデルの精度を上げたい場合には有効ですね。
収集データ
今回は情報量が多く、仕組みが統一されている中央競馬場におけるレース結果を中心にデータ収集をすることにしました。
たくさんのデータがあるので、様々なデータを収集して使うことで良いモデルが作れるでしょう。ですが、血統情報やオーナー・調教師などのデータまで収集するのはかなり手間なので今回は見送りました。
このあたりのデータを追加すれば予測精度が上がりそうですね。
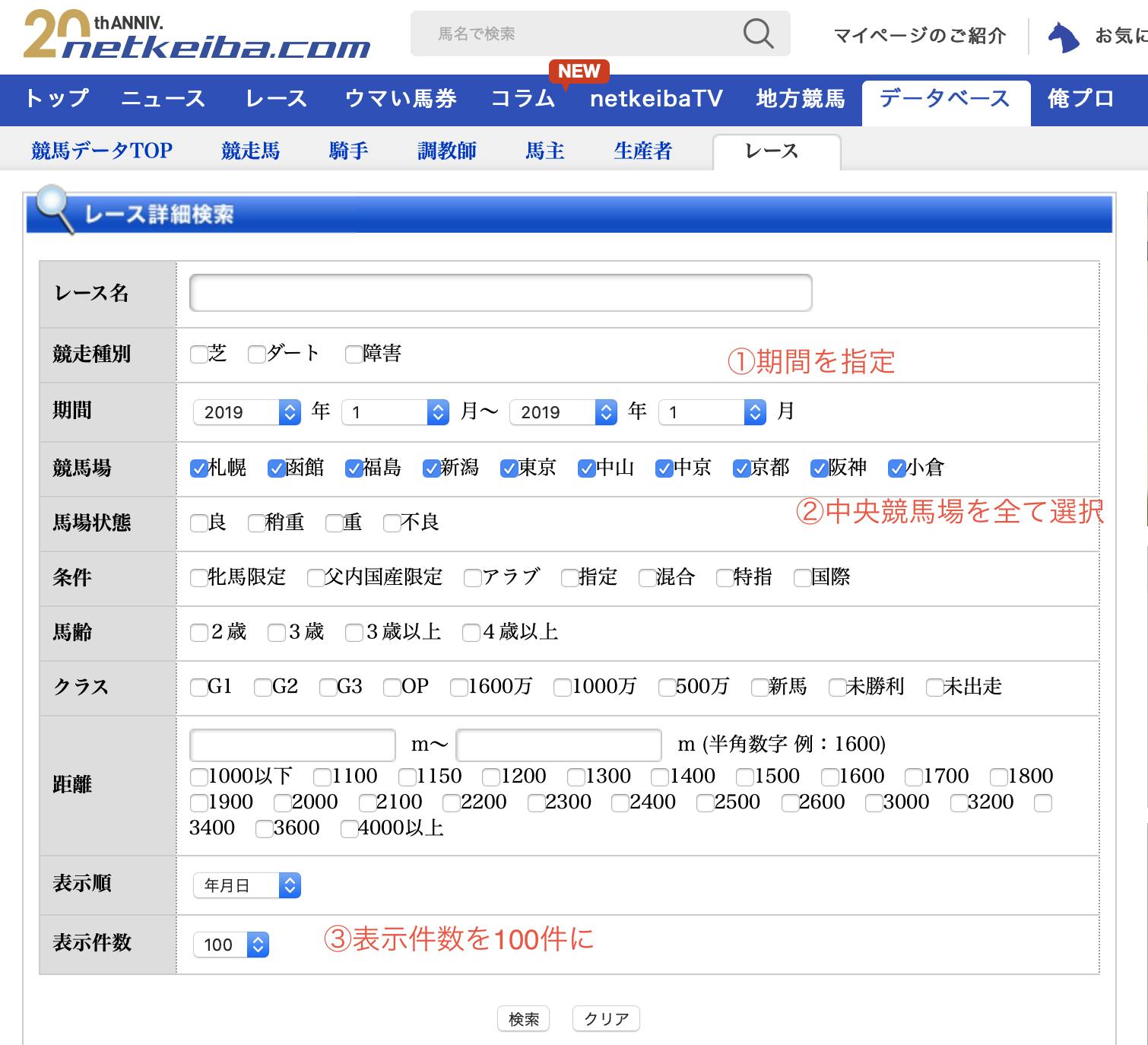
まずは全レースへのURLを取得する
サイト中のレース詳細検索画面から、Seleniumを使用してレース結果へのURLを全て取得します。
Pythonでクローリング・スクレイピングする際によく用いられるrequestsとBeautifulSoupを使用しない理由としては、検索時のURLも検索結果のURLもhttps://db.netkeiba.com/?pid=race_search_detailで変化していないからです。
JavaScriptやPHPなどで動的に画面を生成している場合は、単純にhtmlをダウンロードしてきても望むデータは得ることができません。
Seleniumを用いると実際のブラウザ操作で画面遷移が行えるので、このようなボタンのクリックなどで表示が変わるサイトや、ログインが必要なサイトなどでもwebクローリングを行うことができます。
(ログインが必要なサイトは、会員規約などでクローリングを禁止している場合も多いのでご注意ください)。
まずは必要なものの準備
import time
from selenium import webdriver
from selenium.webdriver.support.ui import Select,WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless') # ヘッドレスモードに
driver = webdriver.Chrome(chrome_options=options)
wait = WebDriverWait(driver,10)
フォームの入力を埋める
フォーム上の入力欄のうち必要なものを埋めていきます。送信をしたら検索結果が表示されるまで待ちましょう。
URL = "https://db.netkeiba.com/?pid=race_search_detail"
driver.get(URL)
time.sleep(1)
wait.until(EC.presence_of_all_elements_located)
# 月ごとに検索
year = 2019
month = 1
# 期間を選択
start_year_element = driver.find_element_by_name('start_year')
start_year_select = Select(start_year_element)
start_year_select.select_by_value(str(year))
start_mon_element = driver.find_element_by_name('start_mon')
start_mon_select = Select(start_mon_element)
start_mon_select.select_by_value(str(month))
end_year_element = driver.find_element_by_name('end_year')
end_year_select = Select(end_year_element)
end_year_select.select_by_value(str(year))
end_mon_element = driver.find_element_by_name('end_mon')
end_mon_select = Select(end_mon_element)
end_mon_select.select_by_value(str(month))
# 中央競馬場をチェック
for i in range(1,11):
terms = driver.find_element_by_id("check_Jyo_"+ str(i).zfill(2))
terms.click()
# 表示件数を選択(20,50,100の中から最大の100へ)
list_element = driver.find_element_by_name('list')
list_select = Select(list_element)
list_select.select_by_value("100")
# フォームを送信
frm = driver.find_element_by_css_selector("#db_search_detail_form > form")
frm.submit()
time.sleep(5)
wait.until(EC.presence_of_all_elements_located)
簡単のために2019年1月のURLを入手するようにしてあります。さらに広範囲のデータが欲しい場合は以下のどれかを行って下さい。
- 年月のフォームを入力しないようにする
- ループで各年月についてURLを取得する
- 選択する年月の範囲を変更する
(githubのコード上では、2008年からまだ取得していないレースデータを収集するようにしてあります。)
競馬場の選択までしっかり埋めないと、海外で行われたレースのデータなども入ってしまいます。中央競馬場10個のチェックをちゃんとやっておきましょう。
中央競馬場以外のデータは出走馬が少なかったり、データが不完全であったりすることもあるので、今回は使わないことにしました。
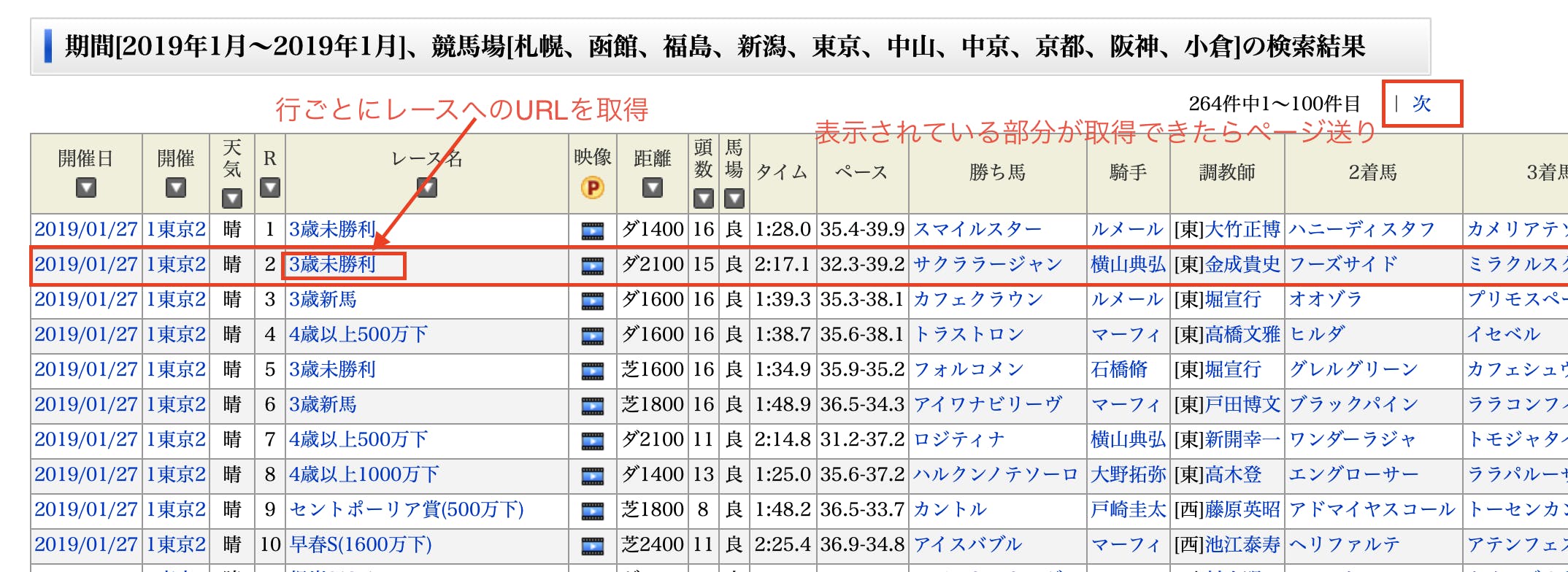
ページ送りをしながらURLを保存
Seleniumでボタンをクリックして、100件ずつ表示させたURLを保存していきます。
with open(str(year)+"-"+str(month)+".txt", mode='w') as f:
while True:
time.sleep(5)
wait.until(EC.presence_of_all_elements_located)
all_rows = driver.find_element_by_class_name('race_table_01').find_elements_by_tag_name("tr")
for row in range(1, len(all_rows)):
race_href=all_rows[row].find_elements_by_tag_name("td")[4].find_element_by_tag_name("a").get_attribute("href")
f.write(race_href+"\n")
try:
target = driver.find_elements_by_link_text("次")[0]
driver.execute_script("arguments[0].click();", target) #javascriptでクリック処理
except IndexError:
break
ファイルをオープンして、得られたURLを行ごとに書き込んで行きます。レースのURLはテーブルの5列目にあるので、配列の要素が0始まりのPythonではfind_elements_by_tag_name("td")[4] などと選択して下さい。
ページ送りをwhileループで行っていきます。最後のページではクリックできなくなるので、tryを使って例外をキャッチしています。
try内のdriver.execute_script("arguments[0].click();", target)の部分ですが、これを単純なtarget.click()にすると、ヘッドレスモードでElementClickInterceptedExceptionが発生しました。
どうやら要素が重なっていると認識されて上手くクリックできなかったようです。こちらに解決方法が乗っていたのですが、上記のようなJavaScriptでのクリック処理にするとうまくできました。
取得したURLをもとにhtmlを得る
先程得られたhtmlは、ページの表示にPHPやJavaScriptなどを大きく利用していないようなので、ここでやっとrequestsを使用していきます。
先程のURLの情報をもとに、htmlを取得して保存するのですが、1ページ取得するごとに数秒待つので結構時間がかかります。
import os
import requests
save_dir = "html"+"/"+str(year)+"/"+str(month)
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
with open(str(year)+"-"+str(month)+".txt", "r") as f:
urls = f.read().splitlines()
for url in urls:
list = url.split("/")
race_id = list[-2]
save_file_path = save_dir+"/"+race_id+'.html'
response = requests.get(url)
response.encoding = response.apparent_encoding
html = response.text
time.sleep(5)
with open(save_file_path, 'w') as file:
file.write(html)
文字コードの都合上、素直に取得すると文字化けする可能性があります。response.encoding = response.apparent_encodingとしてやればうまくいきました。
参考: Requestsで日本語を扱うときの文字化けを直す
htmlを解析してcsvを作成する
レースの詳細・各出走馬の情報をcsvにそれぞれします。以下のような形式のcsvを作成することにしました。
-
レース詳細
- レースID
- 何ラウンド目か
- レースのタイトル
- コースについて
- 天候
- 土の状態
- 日時
- 競技場
- 1着から3着までの馬番・枠番
- 各馬券のオッズ
-
馬詳細
- レースID
- 順位
- 馬ID
- 馬番
- 枠番
- 性別年齢
- 負担重量
- タイム
- 着差
- 上がりのタイム
- オッズ
- 人気
他にも取得できる情報はあります。有料会員ではスピード指数と呼ばれるものなども取得できるようです。
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
CSV_DIR = "csv"
if not os.path.isdir(CSV_DIR):
os.makedirs(CSV_DIR)
save_race_csv = CSV_DIR+"/race-"+str(year)+"-"+str(month)+".csv"
horse_race_csv = CSV_DIR+"/horse-"+str(year)+"-"+str(month)+".csv"
# race_data_columns, horse_data_columnsは長くなるので省略
race_df = pd.DataFrame(columns=race_data_columns )
horse_df = pd.DataFrame(columns=horse_data_columns )
html_dir = "html"+"/"+str(year)+"/"+str(month)
if os.path.isdir(html_dir):
file_list = os.listdir(html_dir)
for file_name in file_list:
with open(html_dir+"/"+file_name, "r") as f:
html = f.read()
list = file_name.split(".")
race_id = list[-2]
race_list, horse_list_list = get_rade_and_horse_data_by_html(race_id, html) # 長くなるので省略
for horse_list in horse_list_list:
horse_se = pd.Series( horse_list, index=horse_df.columns)
horse_df = horse_df.append(horse_se, ignore_index=True)
race_se = pd.Series(race_list, index=race_df.columns )
race_df = race_df.append(race_se, ignore_index=True )
race_df.to_csv(save_race_csv, header=True, index=False)
horse_df.to_csv(horse_race_csv, header=True, index=False)
レースごとに、レースの詳細・各出走馬の情報などをリストに入れて、pandasのデータフレームに1行ずつ追加していきます。
get_rade_and_horse_data_by_html関数や、race_data_columns, horse_data_columnsについては、複雑になってしまうのでここでは載せません。
軽く説明しておくと、get_rade_and_horse_data_by_html関数はBeautifulSoupを利用してhtmlから欲しいデータをリストにして返す関数です。
race_data_columns, horse_data_columnsは取得するデータのカラム名です。
その他注意事項
クローリングをする際は、サーバーへの攻撃とならないように、時間をあけてアクセスするようにしましょう。
他にも法律的な詳しい注意事項をまとめてくださっている方がいるので、実際に行う場合は、Webスクレイピングの注意事項一覧-Qiitaなどを参考にしてください。
データが得られたら整形・分析をやっていく
csv形式のデータを取得するまではできたので、あとはデータを扱いやすい状態にきれいにしましょう。
次にデータの状態を見ながらどのようなモデルを作るか考えます。その後、自分が作成したいモデルに合わせて、trainデータを作成していきましょう。
データを扱いやすく整形する
データを扱いやすい状態に整形して行きましょう。
例えば、文字列の日付データや数値を、datetimeオブジェクトやintに変換する。また、一つのカラムにあるデータはなるべくシンプルな方が今後楽なので、性別と年齢を2つのカラムに分けたりする。
など、やることはたくさんあります。
スクレイピングの際に同時にやってしまったほうが良かったかもしれませんが、スクレイピングのコードが煩雑になりそうだったので今回は分けて行うことにしました。
以下はその一部です。
# 時間情報を抜き出して、日付情報と結合。datetime型にする
race_df["time"] = race_df["time"].str.replace('発走 : (\d\d):(\d\d)(.|\n)*', r'\1時\2分')
race_df["date"] = race_df["date"] + race_df["time"]
race_df["date"] = pd.to_datetime(race_df['date'], format='%Y年%m月%d日%H時%M分')
# もともとのtimeは不要なので削除
race_df.drop(['time'], axis=1, inplace=True)
# 何ラウンド目かのカラムに余分なRや空白・改行が含まれているので取り除く
race_df['race_round'] = race_df['race_round'].str.strip('R \n')
データの分析
整形したデータを分析して、どのような分布になっているのかなどを大まかに確認していきます。モデルの作成をする際は、なるべくデータの偏りが内容に学習させる必要があるので、モデルの問題設定にとっても重要です。
また、特徴量をどのようにするかを考える上でもデータの分析は重要になってきます。
ディープラーニング等の場合は特徴量エンジニアリングにそこまでこだわる必要はなさそうですが、LightGBMなどの勾配ブースティングといったディープではない普通の機械学習をする際は、特徴量をどの様にするかをよく考える必要があります。
Kaggleなどでも、良い特徴量を見つけられれば上位に食い込める可能性が上がるみたいですね。
trainデータの作成
先程のデータ分析などを参考にしながら、どのようなモデルを作るか決めたら、trainデータを作成していきましょう。
入力データですが、大体は以下の通りです。
- 予測したいレースの情報
- 馬番
- 枠番
- 年齢
- 負担重量
- 体重
- 前回からの体重変化
- 負担重量/体重
- 性別
- 距離
- レースに参加する馬の数
- 障害レースかどうか
- 地面の状態
- 芝かダートか
- コースが右回りか左回りか直線か
- 天気
- 開催地
- 前回と騎手やオーナーが変わっているかどうか
- 前回レースとの時間差
- 過去5レースの情報
- 予測したいレースの情報と同じ内容
- 順位
- ゴールタイム
- 途中順位の平均
- 上がりのタイム
- 平均速度
予測したいレースにおけるオッズは、試合直前まで変動するのでデータに入れないことにします。
いよいよモデル作成(ディープラーニング)
はじめに概要を述べておくと、今回はkerasでディープラーニング行います。
ある馬のデータを入力として、
- 1位になる確率を予測するモデル
- 3位以内に入る確率を予測するモデル
の2つを作りました。
モデルをどう決めたか
分類問題・回帰問題のどちらを解くのかを考える必要があります。
回帰問題の場合は、馬が何位になるのか(1.2位みたいなのを許容することになるでしょう)や、タイムなどを予測させることになるかと思います。
分類問題の場合は、馬が何位になるのか(こちらは1~16までの自然数で分類されます)や、1位になるかどうか、上位に入るかどうかなどを予測させることになるでしょう。
タイムや速度は競馬場やコースによって大きく変化するので、分けて予測させないと難しいでしょう。今回は単純に分類問題として「上位に入るかどうか」を予測させます。
モデル作成でやったことや過学習への対応方法など
モデルを作成するにあたって、色々と試したことを書いていきます。
また、モデルを作っても、過学習をさせないような工夫、過学習をしていないかどうかの検証が不可欠です。
機械学習をして、手元のデータで良さそうな結果が出ても、そのモデルが他のデータにも良い精度で予測ができるとは限りません。
学習用とテスト用にデータセットを分割する
まずは基本的なことから。
モデルを作っても、それが良いものかどうかを評価できなければ意味がありません。
収集・整形したデータの80%を学習データとして、20%をテストデータとしました。つまり、
- 学習データ:2008年1月~2017年7月23日
- テストデータ: 2017年7月23日~2019年11月あたり
といった形です。はじめに書いた正答率はこのテストデータを用いています。
学習の際は、学習データを更に分割して、train用とvalidation用に分けました。
重みの正則化とドロップアウト
過学習を抑制するための手段として、重みの正則化とドロップアウトがあり、kerasでは簡単にそれらを使用することができます。
ネットワークの損失関数に重みに応じたコストを加えるのが重みの正則化、訓練時に層から出た特徴量をランダムで0にする(落とす)のがドロップアウトです。
重みの正則化にはL2正則化を用いました。
参考: 過学習と学習不足について知る | TensorFlow Core
model = tf.keras.Sequential([
tf.keras.layers.Dense(300, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu, input_dim=df_columns_len), # l2正則化を加えた層
tf.keras.layers.Dropout(0.2), # ドロップアウト
tf.keras.layers.Dense(100, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu), # l2正則化を加えた層
tf.keras.layers.Dropout(0.2), # ドロップアウト
tf.keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
クロスバリデーション
通常は学習用データを更に分割して、
特定の期間だけを用いた単純なホールドアウト検証では、たまたまその期間に良い結果がでるように過学習してしまっている可能性があります。
Kaggleなどのコンペでクロスバリデーションが行われているように、手元のデータで良いモデルかどうかの検証をしましょう。
問題となるのは、時系列データなので単純にデータを分割するKFoldではいけないということです。
時系列データを入力とするときは、未来の情報をtrainにして、過去の情報をvalidationにしてしまうと、本来よりも良い結果になってしまうことがあるそうです。実際に、最初間違えて未来のデータを入れて学習させてしまったのですが、複勝の予測確率が7割を超えてしまいました。
そこで今回は、時系列データの交差検証で用いられる分割方法を用いてみました(sklearnのTimeSeriesSplit)。
ざっくりと説明すると、下の図のようにデータセットを時系列を加味して分割して、一部を検証用のデータにします。
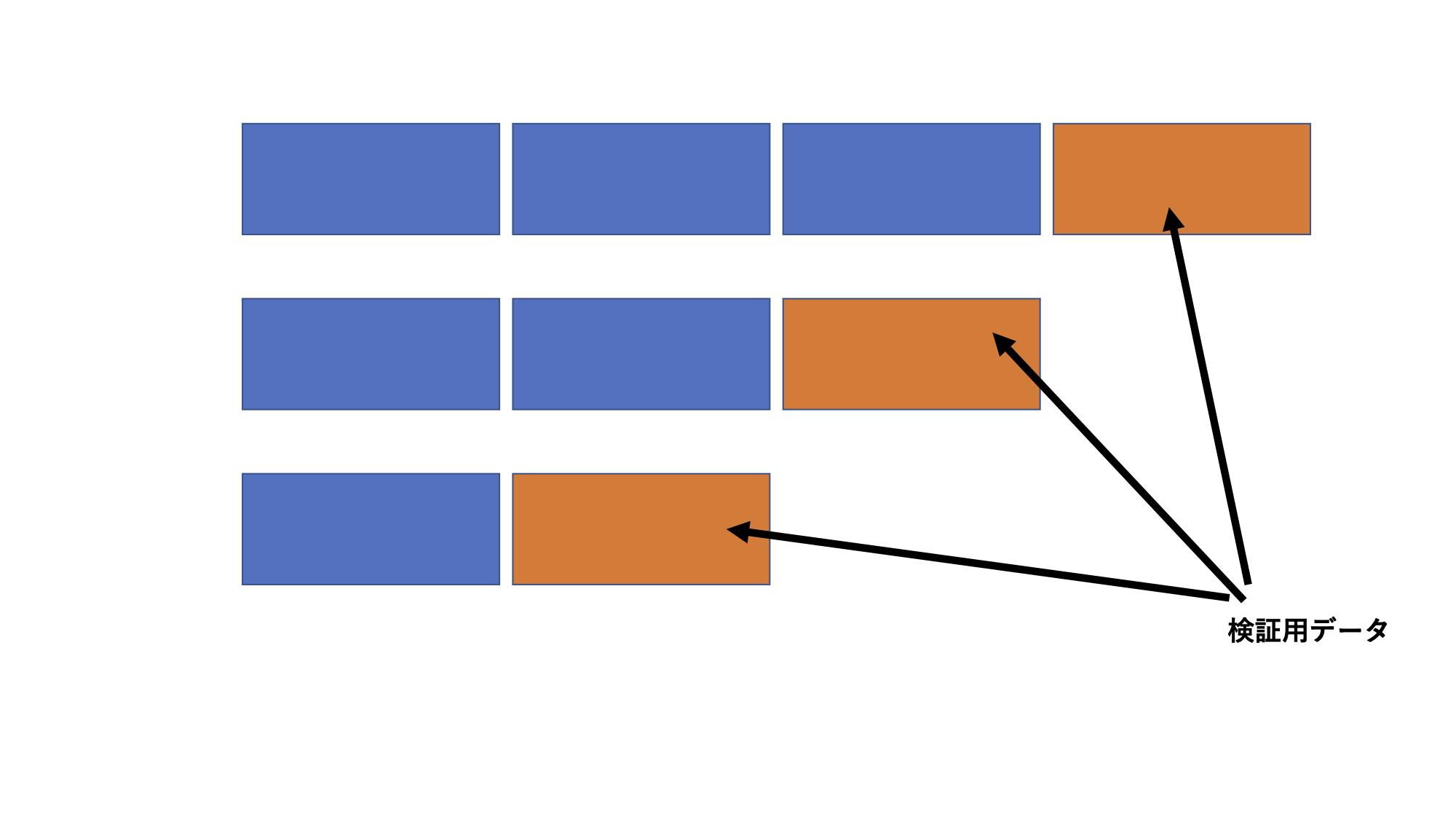
この図では3回学習することになりますね。
ただ、一部の学習データが少なくなってしまうので、データ数が少ない場合は単純なホールドアウトの方が良いかもしれません。
tscv = TimeSeriesSplit(n_splits=3)
for train_index, val_index in tscv.split(X_train,Y_train):
train_data=X_train[train_index]
train_label=Y_train[train_index]
val_data=X_train[val_index]
val_label=Y_train[val_index]
model = train_model(train_data,train_label,val_data,val_label,target_name)
ハイパーパラメータチューニング
機械学習におけるハイパーパラメータは重要です。
例えば、ディープラーニングでは、間にある層が大きいほど中間変数が多くなり、学習データが少ないと容易にオーバーフッティングしてしまうことになります。逆に小さければ、データ量が十分にあっても柔軟性が足りずに正しく学習できない可能性があります。
やり方については色々と議論が分かれる部分でしょう。これは人によって違うようです。
今回は、hyperasというkerasのパラメータチューニングを自動調整してくれるライブラリがあったのでそれを使ってみることにしました。割と直感的でわかりやすかったです。
簡単な使い方としては、データ準備の関数・trainして最小化させたい値を返す関数の2つをoptim.minimizeに渡すだけです。
調整させたい幅は、整数値ならchoice, 実数ならuniformで指定します。
詳しくはこちらを参考に:https://github.com/maxpumperla/hyperas
import keras
from keras.callbacks import EarlyStopping
from keras.callbacks import CSVLogger
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from hyperopt import Trials, STATUS_OK, tpe
from hyperas import optim
from hyperas.distributions import choice, uniform
def prepare_data_is_hukusyo():
"""
ここでデータの準備を色々やる
"""
return X_train, Y_train, X_test, Y_test
def create_model_is_hukusyo(X_train, Y_train, X_test, Y_test):
train_size = int(len(Y_train) * 0.8)
train_data = X_train[0:train_size]
train_label = Y_train[0:train_size]
val_data = X_train[train_size:len(Y_train)]
val_label = Y_train[train_size:len(Y_train)]
callbacks = []
callbacks.append(EarlyStopping(monitor='val_loss', patience=2))
model = Sequential()
model.add(Dense({{choice([512,1024])}}, kernel_regularizer=keras.regularizers.l2(0.001), activation="relu", input_dim=train_data.shape[1]))
model.add(Dropout({{uniform(0, 0.3)}}))
model.add(Dense({{choice([128, 256, 512])}}, kernel_regularizer=keras.regularizers.l2(0.001), activation="relu"))
model.add(Dropout({{uniform(0, 0.5)}}))
if {{choice(['three', 'four'])}} == 'three':
pass
elif {{choice(['three', 'four'])}} == 'four':
model.add(Dense(8, kernel_regularizer=keras.regularizers.l2(0.001), activation="relu"))
model.add(Dropout({{uniform(0, 0.5)}}))
model.add(Dense(1, activation="sigmoid"))
model.compile(
loss='binary_crossentropy',
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
history = model.fit(train_data,
train_label,
validation_data=(val_data, val_label),
epochs=30,
batch_size=256,
callbacks=callbacks)
val_loss, val_acc = model.evaluate(X_test, Y_test, verbose=0)
print('Best validation loss of epoch:', val_loss)
return {'loss': val_loss, 'status': STATUS_OK, 'model': model}
# 実際にhyperasで調整する
best_run, best_model = optim.minimize(model=create_model_is_hukusyo,
data=prepare_data_is_hukusyo,
algo=tpe.suggest,
max_evals=15,
trials=Trials())
結果をblendする
様々なモデルから得られた出力を混ぜることで、より良い精度の予測ができることがあります。
1位の予測と、3位以上の予測を平均することで、もともとの予測値よりも若干高い値を得ることができました。
1位になりやすそうな馬の特徴と、上位に入りそうな馬の特徴というのは微妙に異なる可能性があり、両者を混ぜることでより精度の高い予測が可能になっていると考えられます。
例えば、1位になる可能性はあるがレース途中でだめそうだったら無理をしない(させない)馬と、安定して上位に入る馬というのは特徴が少し異なりそうです。
結果
最終的に競馬初心者の自分よりも精度が高いモデルができました。
- 単勝正解率: 0.2450
- 複勝正解率: 0.5434
競馬で重要そうな情報はまだまだあるので、改善の余地がありそうですね。
単勝で1位のものを買い続けた時の収支は以下の通り。pandasを使って適当にプロットしました。

複勝では以下のようになりました。
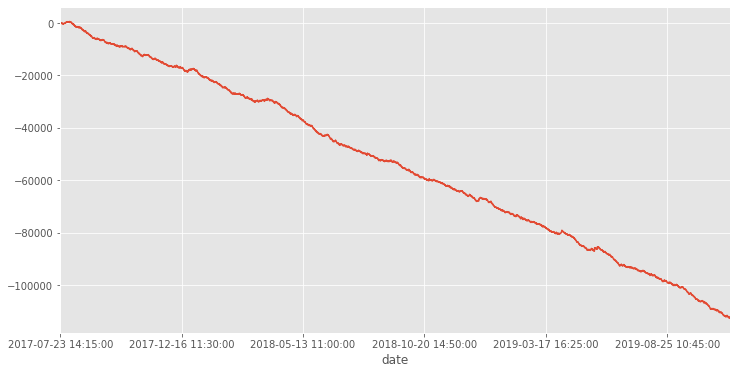
大赤字ですね。
予測値の高いものだけを買うようにしたり、低いオッズのものを買わないようにすればもう少しマシになるでしょう。
その他のtips
今回の競馬予測をするにあたって、やってみたことのうち、本筋とは関係の無いことをいくつか残しておきます。
GCPを使う
GCPの無料クレジットの期限が11月末辺りに切れそうだったので、それを消費するのが2つ目の目的でした。
寝る前にプログラムを投げて朝起きたら確認、ということができます。
無料インスタンスではCSVの作成やディープラーニングのためのメモリが足りないので、GCPを使うかたは気をつけて下さい。
LINE Notifyで通知
GCPに関連してですが、プログラムが終了したかや、エラーが起きたかどうかをLINE Notifyで送るようにしていました。
終わったらすぐに結果を確認して、次のプログラムを実行することができるので、かなり捗りました。
終わりにいくつか
学生の適当な余興なので、詳しい方から見ると色々と突っ込みどころがあると思います。間違いなどあれば、勉強になるので、コメントなりツイッターなりで優しくご指摘頂けると嬉しいです。
ツイッターID(あまりつぶやきません):@634kami
ソースコード
github上で公開しています。とりあえず動くものを作りたかったので、あまり人に見せられるものではないのですが、それでも良いとおっしゃる方だけ御覧ください。
Qiita上のコードは見やすくするため一部を変更しています。
改善できそうなところ・やってみたいこと
- 入力値の欠損データは0埋めしたので、完全なデータだけを予測するようにする
- 血統データを入れる
- 騎手データを入れる
- LightGBMなどの勾配ブースティングを使ってみる
- 同着レースのスクレイピングに失敗していたので、完全なデータにする
- etc

