

pohotos by Ronnie Macdonald
「AIが人間の仕事を奪う」と言われ始めてしばらく経ちますが、今や「幻滅期に入った」なんて言われ方もしています。おかげで僕は仕事を奪われることもなく、毎日満員電車に揺られています。奪う奪う詐欺もいいとこです。
そんなAIの発展にはもう少し時間がかかりそうな一方で、学べる環境は簡単に手に入るようになりました。触るなら、皆が幻滅しかかっている今な気もします。ということで、今更ですがAIの力を知るべく、ディープラーニングに触れてみることにしました。
いろいろ試したのですが、ここでは結果をメインに「無知の状態から勉強しても、ディープラーニングでこれぐらいは楽しめるよ」ということを伝えてみます。プログラムはお手本になるようなものではないので、見たい人だけに有料で公開してみます。
Kaggleでディープラーニングのお手並み拝見
最初にディープラーニングの基礎となる数学を少し勉強しました。いやー…なかなか心折れますね。数式に次ぐ数式。知らなくてもコードは書けますが、数学的な意味を知っておくと理解が進むので、概要だけでも学んでおいて損はないんだろうなーというのが感想です。
ということで軽く勉強後、まずはディープラーニングの力を確かめるために、機械学習で有名なお題「タイタニックの生存者予測」で試してみることに。各乗客の年齢や性別などの属性をもとに、誰が生き残ったのかを予測するやつ。
環境はGoogle Colaboratory、実装は最も簡単そうなTensorFlowを使います。Googleのチュートリアルを参考にするだけで簡単に作れました。予測結果をアップロードすると、スコアが返ってきます。

正解率76.5%。初心者が適当に作ったモデルで8割近く正解です。パラメータやデータを調整すればもっと上がるでしょう。
本来は、「女性や子供が優先して助けられたのでは?」とかいろいろ考えて試行錯誤で分析するんですが、そこをまるごとディープラーニングがやってくれたわけです。確かにディープラーニング、結構すごい。
すごいけど、面白くない
もっと触ってみたいと感じる一方で、この予測をしていて、僕は大きな問題を感じました。
面白くない…。ディープラーニングが、ではなく、テーマが面白くないんです。100年以上前に沈んだ海外の船の乗客の生死を予測しても、全っ然面白くない!
「ジェームス…お前死んだと思ってたのに…生きてたのか!」とか「レイナ…なんで死んじまったんだよぉぉー!!」みたいに一喜一憂するわけにもいかないじゃないですか。誰も知らないし。もう全員死んどるし。てかそもそもKaggleは正解教えてくれないし。
もっとわくわくするテーマがいいなぁ…。ということで、前々からやってみたかった、お金に絡むこのテーマに。
ディープラーニングを使って競馬で回収率100%を超えてみる
競馬は控除率が20%ぐらいらしいので、リターンは平均80%スタートです。回収率100%を超えるのは割と厳しいはず。でも過去のデータは山ほどあるはずだし、ディープラーニングならやってくれるのでは?という期待を込めて試してみます。
ゴールは「複勝馬券で回収率100%を超えること」。
競馬の特性上、複勝よりも配当が大きな馬券を狙った方が効率的なのかもしれませんが、当たりやすい馬券でないと面白くなさそうなので複勝に絞りました。
対象データ
学習用:2010~2017年
検証用:2018~2019年(11月初旬まで)
検証用データで100%超えを目指します。まずはネットでスクレイピングして、こんなデータを揃えました。
| 分類 | 項目 |
|---|---|
| 馬情報 | 馬番 |
| 枠番 | |
| 年齢 | |
| 性別 | |
| 体重(現在) | |
| 体重(前走との差分) | |
| 負担重量 | |
| 当日レース情報 | レース場 |
| 出走馬数 | |
| コース距離 | |
| コース種類 | |
| コースタイプ(ダ/芝/障) | |
| 天気 | |
| 馬場状態 | |
| 同馬の過去レース情報(×5走分) | オッズ |
| 人気 | |
| 順位 | |
| タイム(秒) | |
| 着差 | |
| 前走からの経過日数 | |
| コース距離 | |
| コース種類 | |
| コースタイプ(ダ/芝/障) | |
| 天気 | |
| 馬場状態 |
※当日の「オッズ」や「人気」は勝敗に直接関係ないと判断して省いています。
※この記事での「オッズ」は単勝オッズを指します。
3着以内の馬を予測
このデータをインプットに、ディープラーニングで「3着以内かどうか」を予測します。予測値は0~100の数値(これを「3着指数」と呼ぶことに)にしました。この値が大きいほど、3着以内になりやすいはず。
ちなみにディープラーニングの核となる、予測モデル作成部分のコードは、たったこれだけ。
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(300, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu, input_dim=len(train_df.columns)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(300, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
model.compile(
loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
fit = model.fit(train_df,
train_labels,
validation_data=(valid_df, valid_labels),
epochs=30,
batch_size=32)
※シグモイド関数の出力結果を100倍したものを3着指数としています。
全レースで購入してみる
作成したモデルで、レースごとに3着指数が最も大きい馬券を購入してみます。2018年以降の全レースでシミュレーションした結果がこれです。
| 項目 | 結果 |
|---|---|
| 対象レース数(※) | 3639 |
| 対象レコード数 | 41871 |
| 購入数 | 3639 |
| 的中数 | 1976 |
| 的中率 | 54.3% |
| 回収率 | 82.7% |
※欠損値(過去レース情報含む)のない馬が5頭以上のレースのみを対象としています。
そこそこ的中していますが、回収率が伸びません。そもそも3着指数と、的中率(実際に3着以内であった割合)や回収率がどのような関係になっているのか気になります。
3着指数と的中率/回収率の関係
3着指数と的中率の関係はこのようになっていました。
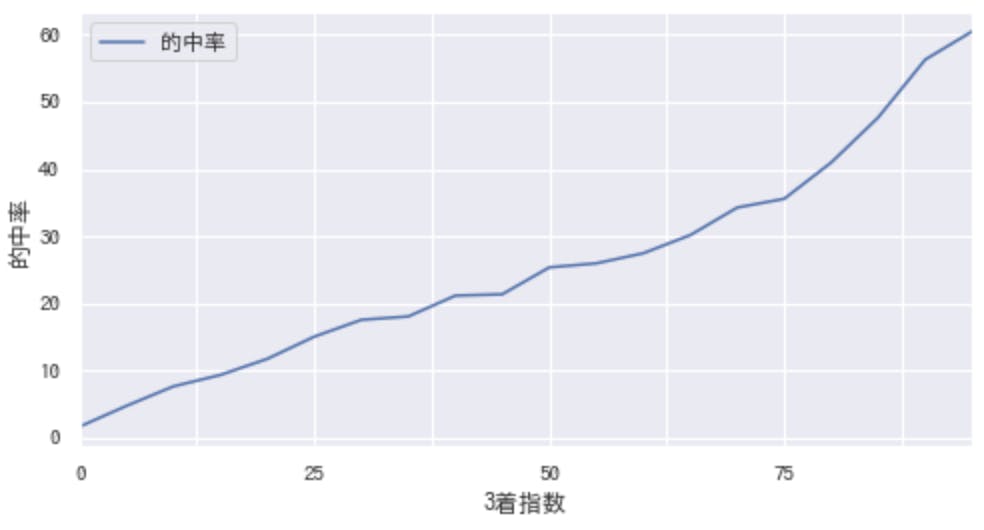
3着指数が高いほど的中率が上がっているので、3着以内を当てるモデルとしては機能していそう。それなら、この指数が高い馬に絞って買えば、回収率100%を超えるのか?
先程のグラフに、平均した回収率を加えてみます。
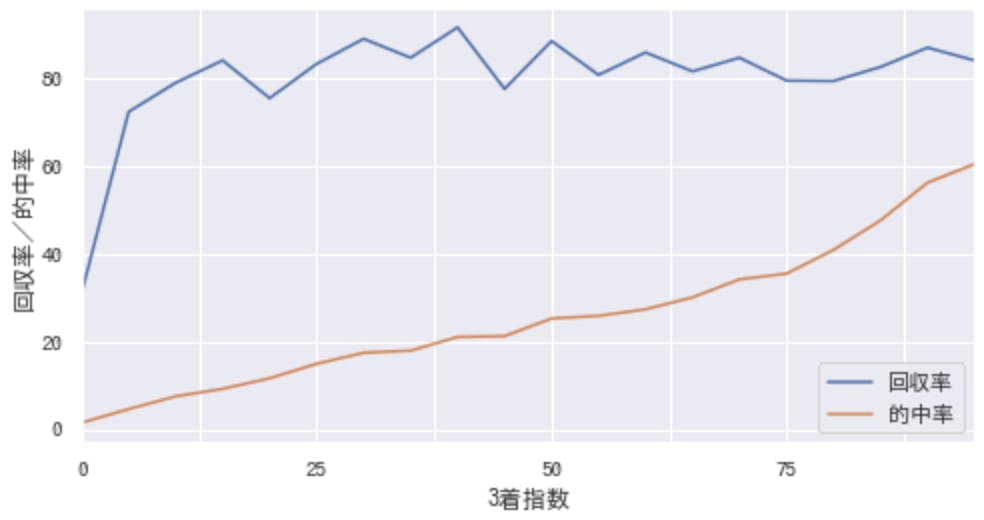
回収率は、的中率にあまり関係なく80%~90%付近に。つまり、3着指数が高い馬(勝ちそうな馬)ほど、リターンが小さいということになる。
となると、この指数と的中率の関係は、オッズと的中率の関係に似ている気がします(オッズは低いほどリターンが小さい)。ということで一応、3着指数と平均したオッズとの関係を調べてみると…
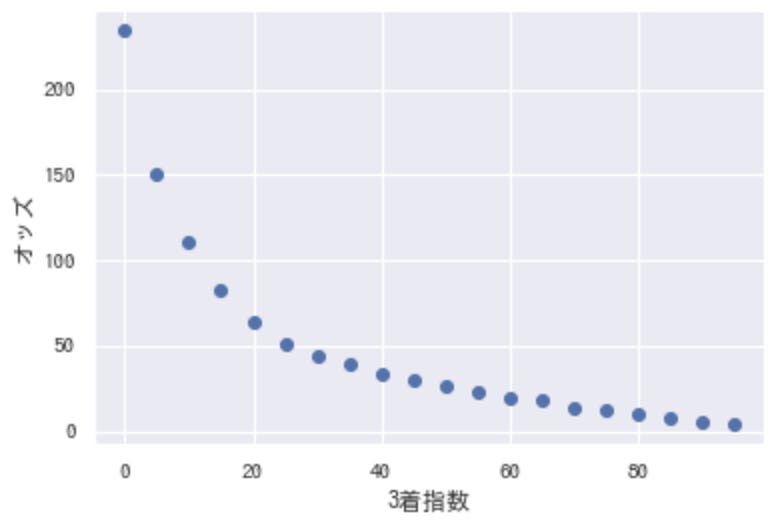
反比例のグラフに。やはり3着指数が高い馬はオッズが低い。オッズを見ずに予測しても結局こうなるんですね。面白いけど、これが競馬の難しさでもありそう。
回収率100%を超えるために
3着指数とオッズがほぼ反比例なのはわかりました。でもそれは平均オッズの話。ひとつひとつを見れば、「3着指数が高い割に、オッズも高い馬」も存在するはず。回収率を上げるには、そのようなオッズの歪みを突くのが良さそうです。
ですが、例えば3着指数が70以上、オッズが100以上の馬券をすべて買うと、こんな悲惨な結果になります。
| 項目 | 結果 |
|---|---|
| 購入数 | 73 |
| 的中数 | 1 |
| 的中率 | 1.37% |
| 回収率 | 16.9% |
オッズがとても高い馬は、たとえ指数が高くても的中率が低いようです。高いオッズには、それなりの理由があるのでしょう。逆にオッズが低すぎると、当然配当が少なく回収率が上がりません。であれば、狙うは中間です。
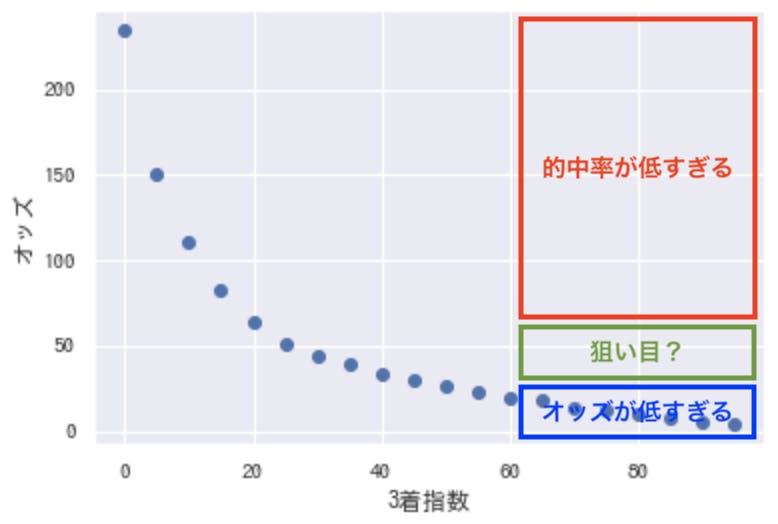
2018年の予測結果で3着指数が60以上、かつオッズが高すぎない一部の範囲(55〜60あたり)に絞ってシミュレーションしてみたところ、回収率227%となり、かなり良い感じに。
| 項目 | 結果 |
|---|---|
| 購入数 | 45 |
| 的中数 | 11 |
| 的中率 | 24.4% |
| 回収率 | 227.6% |
とはいえこれは2018年の良いとこ取りなので、良い結果で当たり前。ですが同じ予測方法で、2019年でもシミュレーションしてみたところ、こちらも回収率201%に。2年トータル(約22ヶ月)ではこうなりました。
| 項目 | 結果 |
|---|---|
| 購入数 | 98 |
| 的中数 | 20 |
| 的中率 | 20.4% |
| 回収率 | 213.3% |
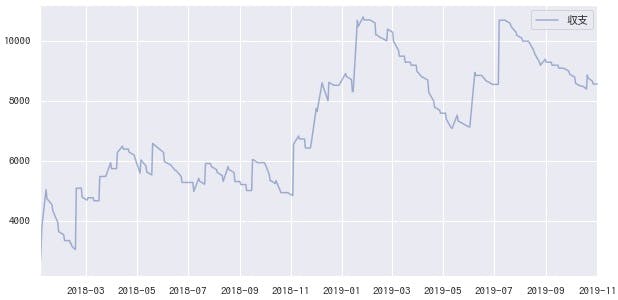
これで、無事に目標にしていた回収率100%を超えました。ちなみに2018年以降、この予測に従って毎回100円ずつ買った場合の収支グラフはこうなります。大きく下げることなく、安定して上昇しています。

この2年間が好調な可能性もゼロではありませんが、ここまで階段状であればある程度信用できそうです。購入数は多くはない(月に4回程度)ですが、勝てない敵を選ばないことは勝つための必須条件でもあるでしょう。
(おまけ)配当が高い馬を予測
これで終わってもいいのですが、せっかくなので、3着予測とは別のパターンとして「配当の期待値」の予測も試してみます。
オッズもインプットに含めたデータをディープラーニングに与えて予測した結果を、先ほどと同じようにグラフ化してみます。オッズが高くても勝ちそうな馬が、期待値高めになっているように見えます。(グラフ横軸はまだ先がありますが、省略しています)

期待値と、回収率/的中率の関係です。
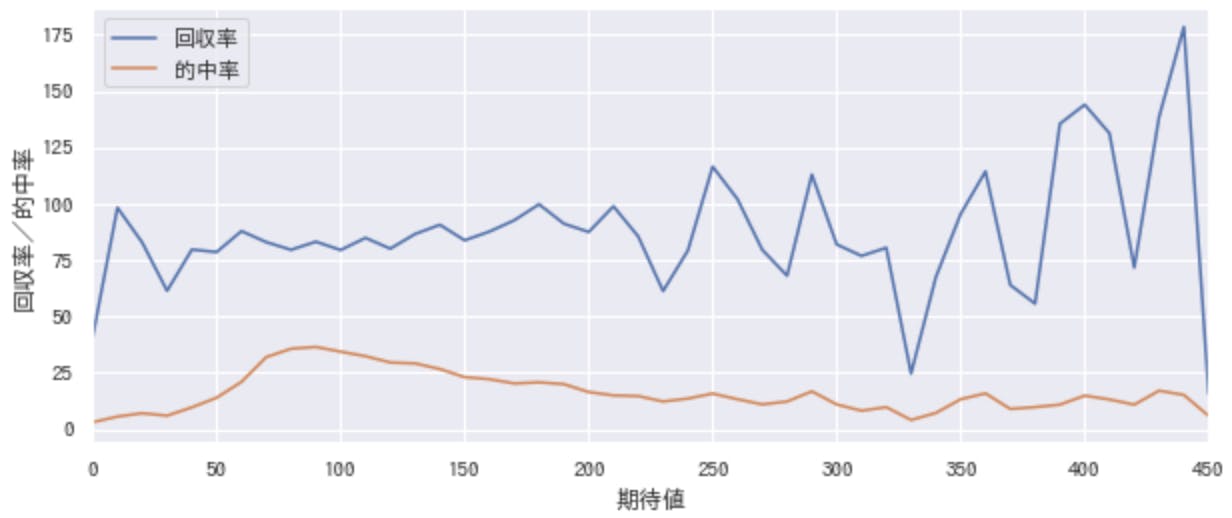
右肩上がりの回収率を見る限り、期待値が高い馬券を永遠に買い続ければ回収率が高まりそうですが、こちらも1〜2年程度では数が少なく安定しないみたいです。
仮にグラフ上で成績の良い期待値が390~450の馬を全て購入すれば、一応100%を超えますが、局所的な上昇に見えるので継続的な安定はなさそうです。
| 項目 | 結果 |
|---|---|
| 購入数 | 275 |
| 的中数 | 37 |
| 的中率 | 13.5% |
| 回収率 | 131.1% |
収支も3着指数のときより乱高下します。オッズ高めを狙うので、当てたときのリターンは大きいんですが。
やったことは以上です。
プログラムはこちら
3着指数の予測モデル作成と検証までのプログラム(Python)は、実験的に有料で下記ページで公開しています。教科書的に使えるような美しいものではないので、お金と心に余裕がある好奇心の強い暇な方だけ見てください。
ディープラーニングさえあれば、競馬で回収率100%を超えられる(プログラム)
あとがき
最近、QR決済の多額のキャンペーン合戦により、やっとモバイル決済が普及してきました。決済以外でも、何を流行らせるにも還元やクーポンが乱発される様子を見て、人を動かすのは、まだ「お金」なんだなぁと改めて感じてから、次はお金絡みの記事を書こうと思っていたので、こうして書けて満足です。
今回の予測のインプットには、「馬名」「騎手名」を含んでいません。つまり馬の血統や騎手の戦歴、相性なども考慮すれば、さらに精度の高い予測ができるでしょう。また、欠損データの補完やバッチ正規化あたりはもちろん、単純にディープラーニングとしてのパラメータ調整だけでも向上すると思いますし、複勝以外の馬券も期待できます。要するに、伸びしろがまだまだあります。
便利な反面、1点だけ気になったのは、こうして競馬をAIで予測していると「自分の頭で予想する楽しみ」が損なわれるんじゃないか、ということでした。自身の直感、馬への愛着など、自分から溢れる想いと共に選んだ馬が勝ったときの喜びは、AIでは得られない気がします。
いずれ誰もが、あらゆる未来予測にAIを使い出したとき、それでも人々は、今のように競馬場に集まり、我を忘れて熱狂し続けられるんでしょうか。あの大量の馬券が空に舞う姿は、いつまで見られるんでしょうか。迫り来るAIの波に、仕事だけでなく心まで奪われないよう、うまく活用していきたいものです。


過去の戦歴から馬の相性を考慮して損失関数を定義しているモデルがこちらの記事で紹介されています。
競馬より競艇の方が出走するレーサーの数が6人に固定されている点で人工知能での予想がしやすい
https://qiita.com/Gambler_AI/items/9c819525177fe73b986d
>自身の直感、馬への愛着など、自分から溢れる想いと共に選んだ馬が買ったときの喜びは、AIでは得られない気がします。
「馬が買ったときの喜びは」→「馬が勝ったときの喜びは」
誤字を見つけたのでお知らせまで。
valid_df, valid_labelsは2018-2019年のデータですか?
だとすると...(^^;)
mashさん
モデル作成時に、検証データに対して結果が良いものを作れば精度が高くなるのではないか?ということでしょうか。
確かに2018-2019のデータを一応入れていますが、そこはモデルの作成にあたり全く参考にしていないので大丈夫です。(エポック数などパラメータは適当に決めて学習を流しただけで、早い段階で横ばいになったため、検証データを見ながらのチューニングに意味がなさそうで)
とはいえ納得感が薄いと思うので、時間ができたらもっと過去のデータも学習させて2018-2019のデータを登場させずに試してみますね。
よくわからないけどこのプログラム買って働かずに生きていくぞ!!!!!
↑ 的中率100%ならその理屈はわかります。もし競馬ファン全員がこのプログラム買って同じ馬を買えば胴元運営できないでしょう。でも実際は的中率100%ではないし、買われることでオッズに歪みが出るので【オッズの割に指数が低い馬】になるだけだと思いますが。
yossymuraさんの実験に関係のない、あなたの思想を粗暴な言葉で書くのはどうかと思いますよ。
少し前に登録上では香港だかの外資企業が日本の競馬に定期的かつ継続的に賭け続け億単位で利益を稼いでおきながら納税を適切にしていなかった疑いの国税の事件があったと思いますが、同じような手口なのかな。(カジノのイブンゲームも確率論で勝負ができたりするが、)一定数負けてくれる人が今までのようにいないと続かないので少しは感情で戦ってくる人がいないと。。。 競馬、競艇、競輪などは出走データを常に最新化するのも肝ですよね。10年前のデータが今も有効に生きているのか、たまたまオッズの関係で勝利しているだけなのか。(この辺り統計学で分析できない?)
gmnoriさん
フォローありがとうございます。
割と多くの方に見ていただいたので、一部の否定的な意見が出てしまうのは仕方ないですね。
感覚的に95%ぐらいの方は肯定的に見てくれている気がします。
mnodaさん
昔から機械的な予測による自動売買の例はあるみたいですね。
今回はディープラーニングを例に出しただけで、他の予測方法でも同じような結果は出る気がします。
個人的には、機械予測購入の割合が増えると過去のデータはあまり参考にならなくなるのでは、と思っています。
こういう記事は大好きです。ビジネスにどう結び付けるかがネックになって、AI技術者(AI技術への機会)が不足しているので、こういうのを使って社内企画してみようかな~。
テストセットは用意してないということでしょうか?
https://qiita.com/QUANON/items/ae569961ea02b4468e23
単勝オッズで複勝の回収率を求めてません?申し訳ないですが、こんな高くなるかな?と眉唾です。。
ああ100円かけ続けたら2年で1万円くらい儲かるということか…そういう意味では合っているのか。.
Hiroyukiさん
mashさんと似た質問だと思いますが、改めて2009-2016年を学習データ、2017年を検証データとして学習したモデルで、未使用の2018-2019年データでシミュレーションをしてみたところ、ほぼ同様の結果になりました。(回収率はモデルによりますが、どれも階段状で収益が上がる形に)
機械学習をかじったことがある方は、このモデルの性能を気にされるのかもしれませんが、この記事のポイントは「機械学習で出す結果に対して、手動でひと手間加えるだけで便利になることもある」だと思っています。むしろモデルの性能はほぼチューニングしていないので多分ヘボいです。記事タイトルがやや大げさなのは申し訳ないですが。
gomiryoさん
はい、もちろんシミュレーションは複勝の配当を使ってます。
BJのカウンティングや、パチ系のバグと違って、真に有効でも織り込まれるとオッズに反映されて利益なくなるんでしょうな
さあ買うなら今だw
damselfishさん
3着以内と以外を同数にしたデータで学習させて、確かグラフ上は74%ぐらいだった気がします。
yossymuraさん
ありがとうございます。
馬券裁判の人のデータで、2010~2014年の単勝1番人気の馬における複勝的中率と回収率がそれぞれ 63.3% と 84.1% だったというものがあります。
それと「全レースで購入してみる」のデータを比較しても、特別変わっているということはないので、そんなに変なことは起きてない気がします。
ただ、2018~2019年のデータと2014~2017年あたりのデータでは出走している競走馬の被りがあることによってデータのリーケージが起きている可能性は検討の余地はあるかと思います。
馬を直接特定するデータはないのであまりないと思いますが…。
検証の際にはそのあたりもポイントにはなってくるかもしれません(ブコメにそういうこと言ってる人がいたので)。
Wow thanks, really nice post!
馬は全然わからないですけど、こういうのを見るとやりたくなりますね。
もちろん、回収率をどうUPするかというチューニングですが。
株では既に、機械学習したロボットが鎬を削って闘ってるのでしょうね。
本記事とは外れますが、賭け方という意味では、ケリー基準というものがありますので、実際に試されたい方は参考にしてみてください。