

本記事について
本記事では、Deep Learningを用いた学習の要となる学習率の決め方、また学習率更新関数の決め方ご説明します。
これから説明する方法は、米国で数多の機械学習エンジニアを輩出している学習講座 fast.ai に取り入れられている手法で、その手法はDeep Learningフレームワークに導入、または導入検討されているものです。
この学習率決定法・更新関数は導入が簡単な割に、精度が数%上昇したり既存の精度までに到達する学習時間(Epoch数)が半分以下なるため、取り入れないのはもったいないと思いから記事にしました。
この記事は fast.ai 及び 論文『Cyclical Learning Rates for Training Neural Networks』を参考しにしています。
初期学習率の決め方: LR range test
LR range testとは
初期学習率を決める手段としてLR range testと呼ばれる手法が有ります。
それはある幅で学習率を徐々に増加させながらAccuracyないしLossを観察し、決める手法です。
ここではLossを観察する際に決定する手法を説明します。
LR range testでは次のようなステップを踏みます。
- 初めに極小な学習率を採用します(e.g. )
- 通常の学習処理を走らせ、その時のLossを記録します
- 学習率を1ステップ増加させます
- 調べたい学習率を超えるまで、複数回手順2-3を繰り返します
- 学習率をx軸:学習率-y軸:Lossをプロットし、最もLossが落ちている学習率を採用します
以上がこの手法のステップです。
具体例
上記の手順に沿って具体例を示します。
- 初期学習率
- 1ステップで学習率をx
- 最終的に学習率が までなるよう7回繰り返す
として適当なモデルの学習を行った時の様子が下記図です。(x軸を対数変換しています)
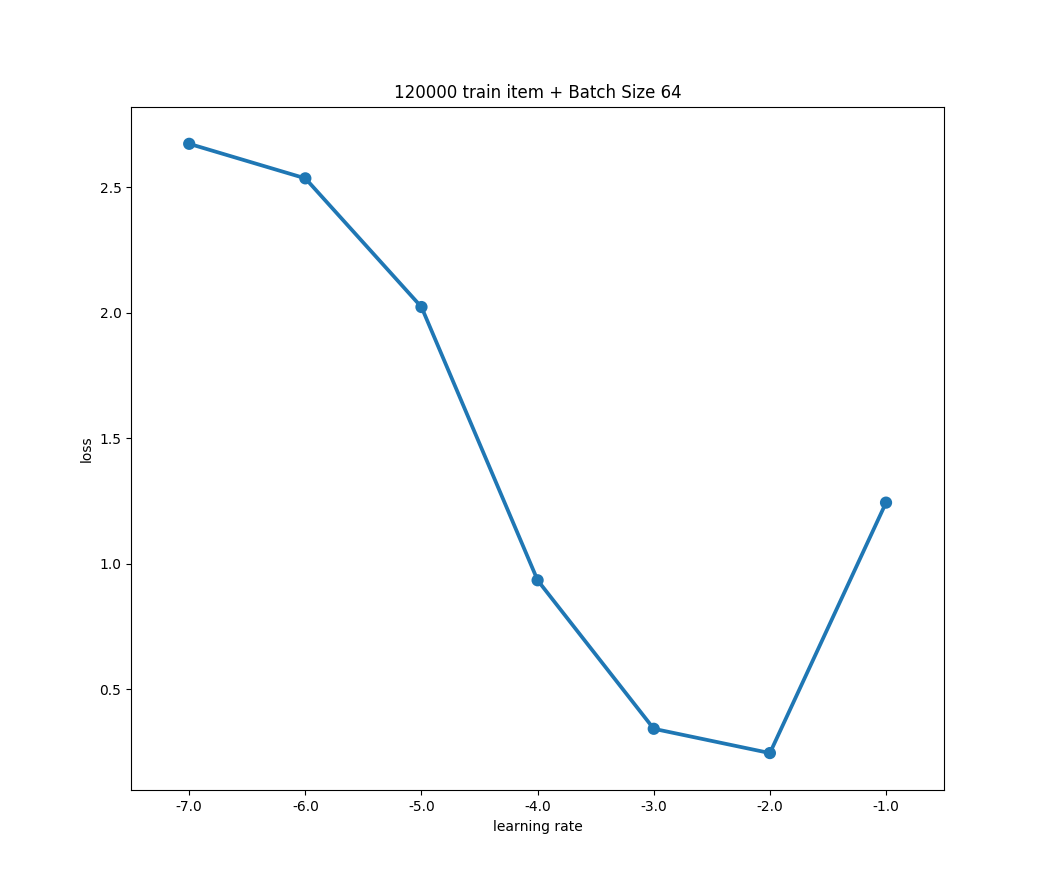
学習データやモデルアーキテクチャの違いによって多少の変化はあるものの、おおよそ上のようなプロット図になると思います。はじめの学習率から値が上昇するに連れて徐々にLossの減少が急になり、あるところから下落が緩やかに、そして最後には跳ね上がるような形にです。
この時の学習率の決め方は、最もLossが落ちている学習率を選択するのが良いと報告されています。
この図ではが良い学習率と言えます。
この時注意したいのは、良い学習率はプロット図の最下点ではないことです。
また変化が平坦になり始めた点も避けるべきだと報告されています。
これらはなぜかと言うと、その時点では学習率が大き過ぎて、最適点を通り過ぎた結果である恐れがあるためです。
以上が初期学習率を効率的に決めるベストプラクティスでした。
Accuracyを観察する場合、考え方はLossを観察するときと同様、上昇がなだらかになる点を選択します。
ここでは学習率をからまで調査しましたが、もっと狭い範囲を調査してより精密に学習率を探索するのも良い手です。例えば上記の続きとしてからまでステップ毎にずつ加えていき線形に学習率を変化させながら変化を見るのも良いでしょう。
この手法の技術的な実現は比較的簡単で、Deep Learningフレームワークに実装されている学習率のスケジューラーで、ステップサイズを1にして加算・乗算すれば良いだけです。
Pytorch, Tensorflowについて、
- Pytorchなら
torch.optim.lr_scheduler.StepLR(step_size=1) - Tensorflowなら
tf.train.exponential_decay(decay_step=1)
です。
学習率の更新関数: Cyclical Learning Rate
学習率の更新関数とは、その名の通り時間経過に応じて学習率を変化させるためのロジックを指します。
学習率を時間ごとに更新するモチベーションについて軽く触れると、要は「学習後期フェーズにおいて細かいチューニングをするには初期学習率では大きすぎる」ということがあります。
そのため学習が進むに連れて、学習率を減衰させていきたいのです。
一方で学習率を早期に減衰させると、まだ学習できるポテンシャルがあるにも関わらず学習が進まなくなってしまいます。
また、学習率が低い段階で鞍点ないし局所最適に陥ると抜け出せずに学習が進まないという問題があります。
本研究ではこれらの問題に対して、Cyclical Learning Rate (CLR)と言う手法を提案しており、後続する学習率をサイクルさせる研究の発端となる論文です。
類似する研究として、本論文も引用されている後続研究のSGDRという更新関数の提案があります。
SGDRについての詳しい説明は下記Qiita記事にあります。合わせてごらんください。
「SGDR: Stochastic Gradient Descent with Warm Restarts」をちょっと改良してKerasで実装した
Cyclical Learning Rateの研究内容
本研究のコアは「上限学習率と下限学習率を決め、その間をバッチ毎に上昇または減少させる」と言うところに有ります。
バッチ処理進行に対する学習率の変化を図にすると次のようになります。
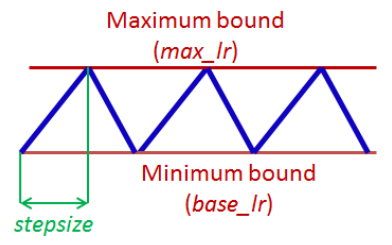
(参考: Leslie N. Smith『Cyclical Learning Rates for Training Neural Networks』)
初めはからスタートし、バッチイテレーション毎に学習率を増加、に到達したら、次はバッチイテレーション毎に学習率をまで減少させる。これを1サイクルと呼び、学習率の増加と減少を繰り返す。
「これだけで学習が上手く行くよ」と言う論文です。
各係数の決め方
この更新関数に対して与えるパラメータはの3つがあります。
これらパラメータの決め方は論文内で次のように示されています。
- について
LR range testを用いてLossの変化が急になり始めた点をに、
Lossの変化がなだらかになる直前の点をにする。 - について
1Epochに回るイテレーションサイズ(つまり、学習データ量÷バッチサイズ)の2倍〜10倍
従来研究との比較
論文では、この様に「学習率変化させる手法」と「学習率固定で学習する手法」それぞれでCIFAR-10データセットを用いて学習時間と精度を比較しています。
この図におけるLR policyがどのように学習率を変化させるかを意味しており、
- fixed:固定学習率
- triangular2: CLRによる周期的線形増減。時間共にbaseとmaxを減衰させる
- decay:ステップ的減少
- exp:指数的減少
- exp_range:CLRによる周期的指数増減
を表します。
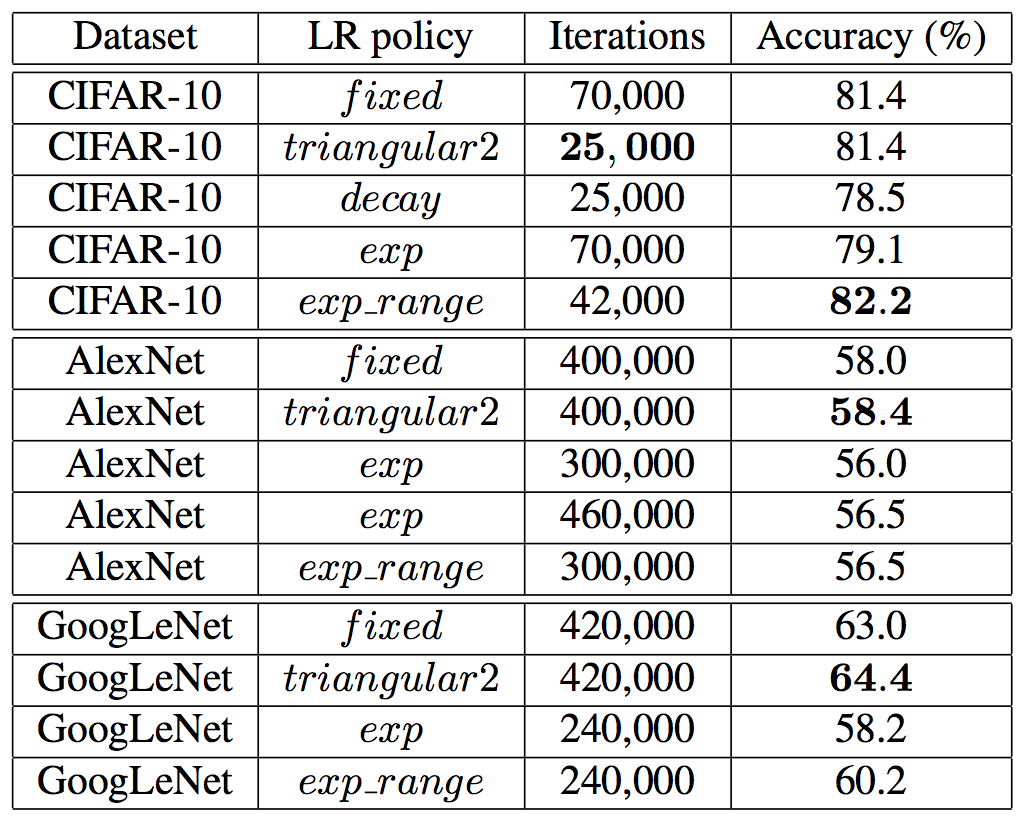
(参考: Leslie N. Smith『Cyclical Learning Rates for Training Neural Networks』)
この表から次のようなことが読み取れます。
- 固定学習率とCLRを比較して、同じ精度に到達するのにかかったIteration数が約60%減
- 固定学習率とCLRを比較して、同じIteration数学習するとCLRの精度が固定学習率の精度を上回っている
- decayとexpはイマイチな結果(パラメータチューニングされてない?)
学習率を時間と共に上下させるのみでこのような改善が見込めます。
加えて、Adaptive learning rate系学習器との比較もされいます。
まずCLRはバッチ毎に学習率のみを変化させるだけなので、重み毎パラメータ毎に計算が生じるAdaptive learning rate系学習器より計算負荷が軽いことも優位性として説かれています。
また、CLR+Adaptive learning rate系学習器と言う学習構成にすると、学習精度向上には寄与しないが、学習時間の短縮には寄与すると論文報告があります。
まとめ
学習率の選択はDeep Learningにおいて一つの大きな問題です。
本記事ではその大きな問題をほとんど悩むことなく決めることができる手法を紹介しました。
その手法をSGDと組み合わせることにより、精度の向上・学習時間の短縮を実現しました。
またこの手法は、他のAdaptive learning rate系学習器とも組み合わせる事ができます。
この論文で紹介したパラメータ決定法はその他の更新関数や、類似するSGDRのパラメータ決定にも転用できます。