

背景
弁護士向けの業務効率化ツールを作ってみました。
URL => https://caselaw.jp/
思ったよりか〜〜〜〜なり大変でした。
作成体験談を書いてみます。
宣伝の意味も込めて笑
研修のグループワークが一緒になった同期が機械学習に詳しく
それがきっかけで今回のWebサービスを思いつきました。

URL => https://caselaw.jp/
内容に間違いが合ったらすいません!
コメントください。
自分のスキルセット
新卒でWeb系の会社に入社しました。
研修でJavaとSQLを3ヶ月ほど叩き込まれました!ありがたいです。
・C++
学生時代は、ネットワーク系の研究室に在籍し、
遅延耐性ネットワークに関係する研究をしていました。
Arduinoを使ったプロタイプを作っていたので、C++ベースの言語を使っていました。
・Java
・Swift(objective-c)
・JavaScript(React)
いずれの言語もYoutubeをみて勉強していました。
特にJava,Swift,JavaScriptはひたすらYoutubeみて、サンプルアプリ作ってました。
Youtubeおすすめです。
サービス概要
弁護士向けの業務効率化ツールです。
弁護士は, 日々依頼を受けて法律事務を処理をします。
依頼を受けた内容と過去に似たようなケースが無いか調べます。
この類似した判例1を探す作業に多くの時間をかかります。
PDF100ページ以上ある判例も存在します。。
ITを使ってこれを改善します![]()
技術
1. Ruby on Rails
のちの拡張性を考えると最初にapサーバは欲しいです。
次にバッチサーバ。
その次にwebサーバ(フロント)だと思っています。
検索してヒントが出て来やすそうなのでRailsを選択しました。。笑
2. さくらVPS
レコード数が数万件で、読み書きを頻繁に行うのでHeroku等、Firebaseはコスト的にNG
またapacheやnginxを使ったことがなかったのでVPSを借りて挑戦しました。
apacheでやってみたのですが、nginxの方が良いようですね。。
サーバ代は、月2000円くらいです。
それプラスでドメインとSSL証明書を作りました。
ドメインと証明書は5000円くらいでした。
3. TF-IDF
詳しい解説はわからないので、リンクのみ載せておきます。。^^;
=> https://dev.classmethod.jp/machine-learning/yoshim_2017ad_tfidf_1-2/
この技術がこのサービスのキモとなります。
工夫した点
1. 進め方
謎な部分が多く出て来て、何度もやめようかと考えました。
6万次元の配列が出て来たり、それを圧縮したり復元したりで自分の実装が合ってるのかどうか判断することが難しい局面は多かったです。
また、それを考えている最中に他にもやらなきゃいけない事が出て来て、もう何がなんだか。。笑
=> 付箋を使って解決!!
~~~~~~~~
導入方法
1. 思いつくだけのタスクを付箋に書き出す
2. 1週単位で出来そうなタスクを割り振る(3週間先くらいまで)
3. (作業してタスク消化)
![]() やらなきゃいけない事思いついた!! => 付箋追加
やらなきゃいけない事思いついた!! => 付箋追加
![]() 問題に行き詰まった... => 付箋分割
問題に行き詰まった... => 付箋分割
~~~~~~~~
タスク分割していたら、なんとなく糸口がはっきりしてくることもありました。
また、付箋を追加することで、一旦そのタスクについて考えることをやめられるので良かったです。
2. 検索時間の短縮化
最初は1回の検索で1日かかってました。
寝る前検索かけて、次の日会社から帰って来てたら類似してる判例が帰っている感じでした。
エラーが出てくると1日が無駄に終わっていました。。
ひたすらベンチマークを取って、改善しました。
以下のポイントで時間を短縮していきました。
2.1. 検索対象の判例をを減らす
判例を7つのジャンルに分類しました。
検索前にジャンルを選択してもらうことで検索対象の判例を減らしました。
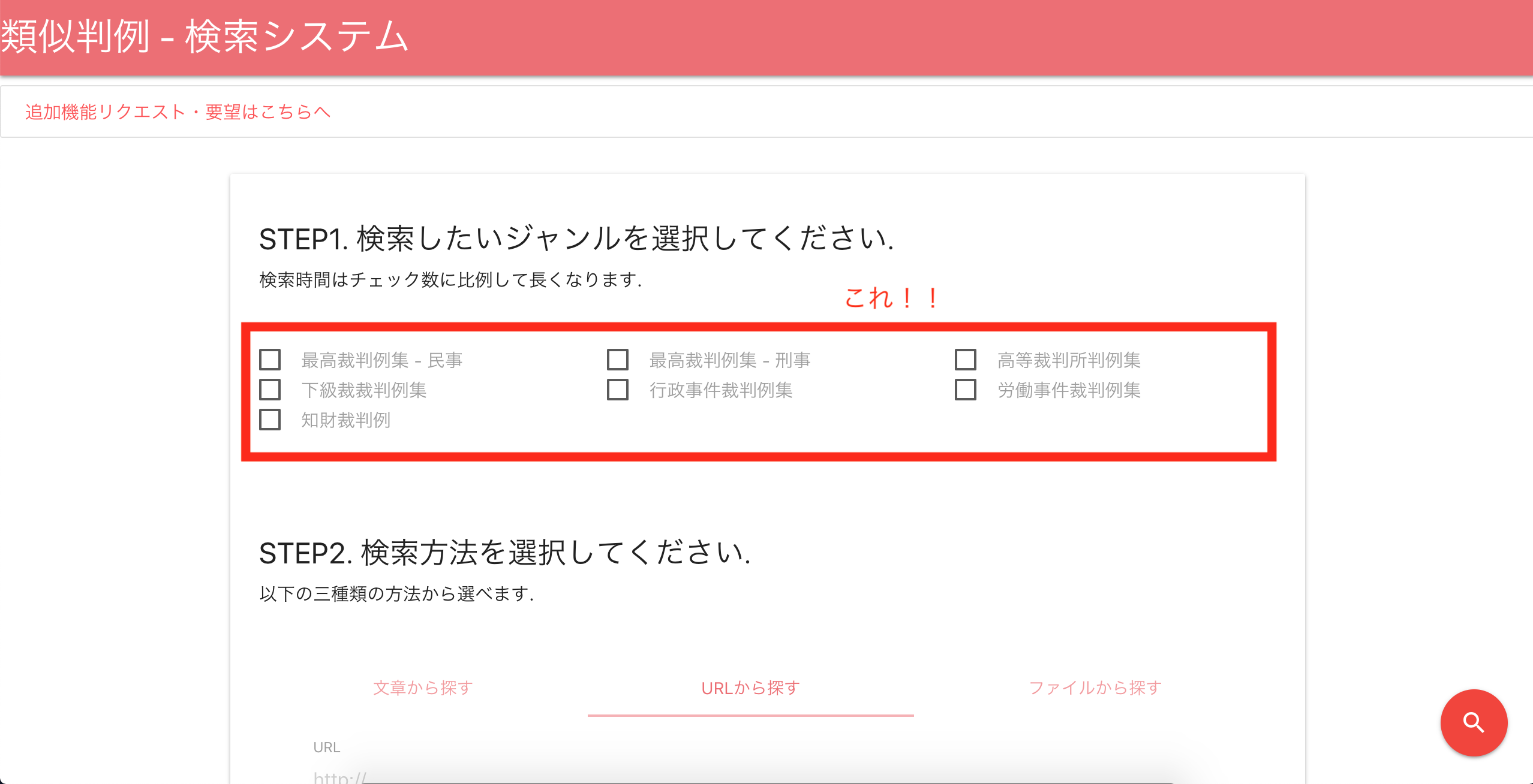
Before 24時間 => After 3.5時間![]()
2.2. cosの情報圧縮
専門用語で疎結合化?と言うらしいです。
Before 3.5時間 => After 1.0時間![]()
2.3. 特徴値ファイルやDBを事前に保持しておく
cronで定期的に文章を解析して、DBの保持したり、
キーワードとなる言葉を特徴値ファイルとして保存して置くように実装しました。
アクセスがくるとそれを見に行くだけでOKと言う感じです
Before 1.0時間 => After 10秒![]()
反省点
1. デザインにこだわりすぎた
結構時間をかけてしまったなと思っています。
綺麗なサイトだとうまくいく気がしてしまって、
本当にサービスがよくなったか分からなくなってきました。
2. 見切り発車
TF-IDFを利用して類似判例が見つかるか検証をあまりせずに実装したので
検索結果がうまく出せているか自信がありません。
もしできるなら他の会社がやっていそうな気もします。
友人に使ってもらってどうか検証中です。
TOPページに以下のようなサンプルをつけて、検証してもらいやすいようにしました。
TOPページ => https://caselaw.jp/
今後の展望
- 検索精度の向上-> 入力された文章で一番重視する言葉を選択してもらうような仕組みにします。
- メンテナンスの自動化
- サーバの増設
- テストコードを書いてみる
検索精度の向上
->入力された文章で一番重視する言葉を選択してもらうような仕組みの実装は現在進行中です。
ユーザからの手間は増えてしまうのですが、検索精度を上げるためにやむ終えずと言う感じです。。
あとがき
技術的にかなり難航しました。
が楽しい開発期間でした。
せっかくのエンジニア生活、これからも楽しんでエンジニアリングしていきたいです。
社会人頑張るぞー!!
-
裁判において具体的事件における裁判所が示した法律的判断のこと。 ↩