

なんか最近Google Colaboratoryが流行ってるらしいですね。
Jupyter notebookをクラウド上で走らせることができるGoogleのウェブサービスですが、注目すべきはGPUもTPUも無料ということでしょう。
「ま、まぁオレもね、本気を出せばKaggleで上位狙えるんだけどね、ちょ、ちょっと手持ちにフツーのラップトップしかなくて、スペック的にアニメ観るくらいしかできないんだよね」
という言い訳ももう通用しない時代に突入しました。
Kaggleは、というより機械学習全般は計算機の能力がものをいいます。課題のデータ量が増大している今、Kaggle内のKernelでは学習が捗らないことも多く、私も去年Kaggleの練習問題(Regression)を解いてKagglerになるという入門記事を書いてからKaggleを去りました(ぉぃ
が、Google colabolatoryの登場により最近「ちょっとまたKaggleやってもいいかな……」と思い始めてきました。そこで、機械学習では定番のMNIST、KaggleではDigit Recognizerと呼ばれる練習問題を用いて、
- Kaggle上のデータをGoogle colaboratoryにロード
- Google colaboratory上でCNNのトレーニング
- Google colaboratory上でKaggleに結果を提出
という流れをまとめたいと思います。Google、Kaggleのアカウントを持っていることは前提とします。
Kaggle上のデータをGoogle colaboratoryにロード
Google Driveを開き、Colab Notebookというフォルダー(名前はなんでも大丈夫)を作ります。そこで右クリック -> More -> Colaboratoryで、Google colaboratoryを始めることができます。
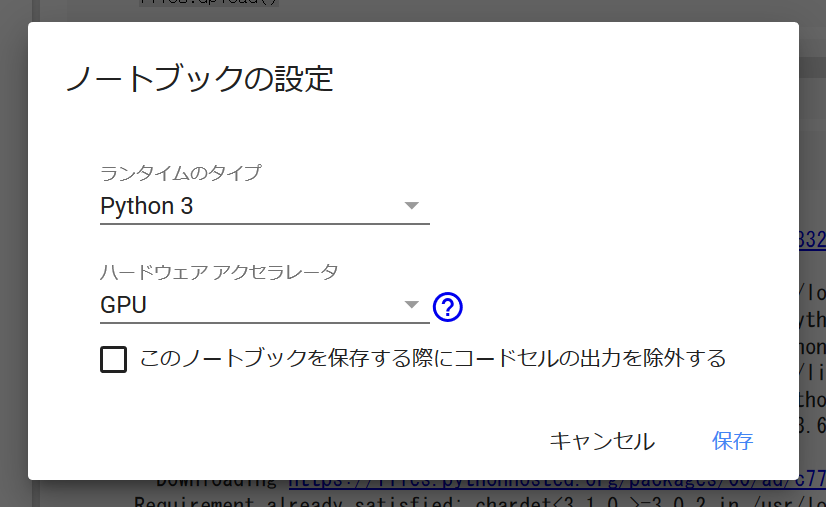
GPUを使いたいので、編集 -> ノートブックの設定より、ハードウェアアクセラレータをGPUに変更、保存します。
さて、Google colaboratory上でKaggleのデータを扱うためには、まずKaggle上でAPIを作成する必要があります。KaggleのHPへ行き、右上の自分のアイコンをクリック -> My Account -> (下の方にある)APIの項目の"Create New API Token"をクリックします。ダウンロードウィンドウがポップアップで出てくるので、kaggle.jsonをダウンロードします。

Google colaboratoryに戻り、一行目に以下を打ち込みます。
from google.colab import files
files.upload()
このセルを実行すると、先ほどダウンロードしたkaggle.jsonを開くように求められます。kaggle.jsonを開き、以下を打ち込むことでパスを設定します。
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
Kaggleをインストールします。
!pip install kaggle
すると、以下のようにばーっとインストールが進むはずです。
アクセスパーミッションのため、以下を打ち込みます。
!chmod 600 /root/.kaggle/kaggle.json
さて、これでもうKaggle上のデータをダウンロードできます。Kaggle上で各CompetitionのDataのページに行くと、APIのアドレスが見つかります。
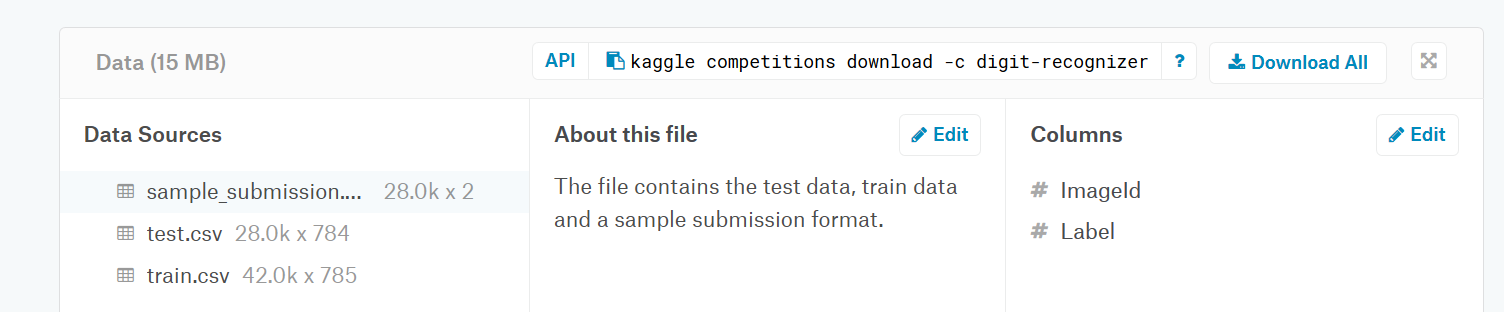
ダウンロードのコマンドは以下のようになります。
!kaggle competitions download -c digit-recognizer
これを実行すると無事、ファイルがロードされます。
画面左側で、ロードされたファイルたちが確認できますね。
Google colaboratory上でCNNのトレーニング
データがロードできたら、後は好きにモデルを組んでトレーニングするだけです。MNISTは画像分類課題なので、何も考えずにCNN (Convolutional Neural Network) を使います。より頭を使わなくて済むよう、Kerasで実装します。
Google colaboratoryでKerasをインストールするには、以下を実行します。
!pip install -q keras
ありがたいことにNumpyやPandasは既に入っているため、今回はもう追加するものはありません。必要なライブラリをimportします。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# keras
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D, GlobalAveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.preprocessing.image import ImageDataGenerator
from keras.utils.np_utils import to_categorical
from keras.optimizers import SGD, RMSprop
from keras.callbacks import ReduceLROnPlateau
from sklearn.model_selection import train_test_split
ダウンロードしたデータは、/content/以下にあるので以下のようにPandasで読み込みます。
# load training & test datasets
train = pd.read_csv("/content/train.csv")
test = pd.read_csv("/content/test.csv")
今回の記事の目的はGoogle colaboratory上でKaggleのデータを扱うことなので、モデルの詳細については説明しません。ここに書かれているモデルでも上位30%は入れると思いますが(保証はしませんー)、きっとKaggleのPublic Kernel上にもっといいのがあるので、そっちをパクってくることをおススメします。
Train, Test
# pandas to numpy
y_train = train["label"]
X_train = train.drop(labels=["label"], axis=1)
del train
# normalize
X_train = X_train/255.0
test = test/255.0
# reshape the data so that the data
# represents (label, img_rows, img_cols, grayscale)
X_train = X_train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)
# one-hot vector as a label
y_train = to_categorical(y_train, num_classes=10)
CNN
# convolution -> batch normalization -> ReLU actuvation -> pooling
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(28,28,1)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(3, 3)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
# Fully connected layer
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
Compile
# compile model
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
for cross validation
# cross validation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.10, random_state=1220)
data argumentation
# data argumentation
gen = ImageDataGenerator(rotation_range=8, width_shift_range=0.08, shear_range=0.3,
height_shift_range=0.08, zoom_range=0.08)
train_generator = gen.flow(X_train, y_train, batch_size=64)
decreasing learning rate
# learning rate
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc', patience=3, verbose=1, factor=0.5, min_lr=0.00001)
training model
# model training
model.fit_generator(train_generator, epochs=30, validation_data = (X_val, y_val), verbose=2, steps_per_epoch=X_train.shape[0]/36,
callbacks=[learning_rate_reduction])
あとはGPUがモデルを訓練し終わるのを待つだけです。
Google colaboratory上でKaggleに結果を提出
モデルの訓練が終わったら、Google colaboratory上から結果をKaggleに提出しましょう。
まず、モデルのテストデータに対する予測は、
# model prediction on test data
predictions = model.predict_classes(test, verbose=0)
次に、提出用csvを作ります。
# make a submission file
submissions = pd.DataFrame({"ImageId": list(range(1,len(predictions)+1)),
"Label": predictions})
submissions.to_csv("my_submission.csv", index=False, header=True)
これを、以下のコマンドでKaggleに提出することができます。
# submit the file to kaggle
!kaggle competitions submit digit-recognizer -f my_submission.csv -m "Yeah! I submit my file through the Google Colab!"

上のように表示されたら、結果はKaggleに提出されています。
終わりに
Google colaboratoryに登場によって、計算能力が比較的劣るコンピューターしかない個人でも、PythonをGPUやTPUを使って無料で走らせられるようになりました。こうした、個人の可能性が広がるサービスって素晴らしいですね!