

1.きっかけ
KaggleとかSIGNATEのcsv系のコンペで前処理をする際に文字で表されたカテゴリデータ(例えば、天気・メーカーなど)があって、このようなデータはone-hotベクトルに変換しないといけない。
scikit-learnのpreprocessingメソッド使っても上手くいかないこと多々ある。
それならNumpyとPandas使って自分でプログラム書いた方が楽なのではと思ったので、この記事を書くに至りました。
2.scikit-learn使った場合
import sklearn.preprocessing as sp
import pandas as pd
train = pd.read_csv(file_path)
le = sp.LabelEncoder()
le.fit(train.カラム名.unique())
train.カラム名 = le.fit_transform(train.カラム名)
ohe = sp.OneHotEncoder()
add = ohe.fit_transform(train.カラム名.values.reshape(1, -1).transpose())
temp = pd.DataFrame(index=train.カラム名.index, columns=le_train.classes_, data=add.toarray())
new_data = pd.concat([train, temp], axis=1)
del new_data['venue']
train = new_data
scikit-learnのpreprocessingメソッドを使えばこんな感じでone-hotベクトルに変換できるはずなのですが、エラーが出て上手くいかないことがあります。
3.NumpyとPandasだけ使った場合
使うデータは現在、SIGNATEで開催されているJリーグの観客人数予測コンペの訓練データとします。データはこんな感じです。
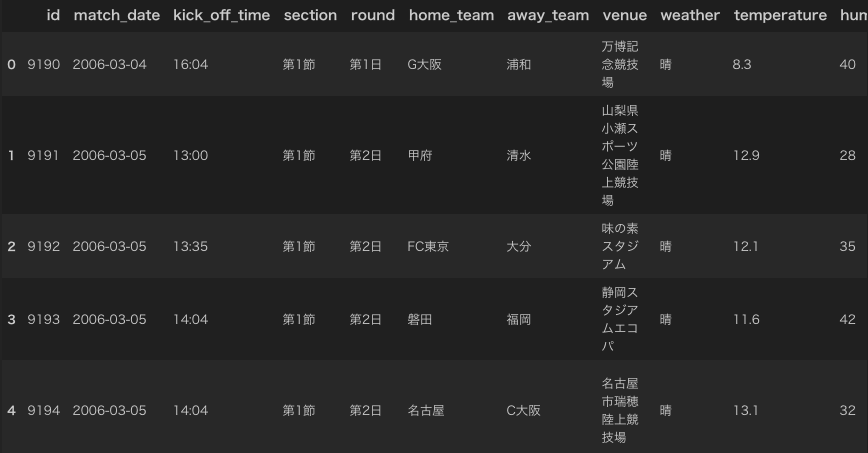
今回は会場データvenueをone-hotベクトルに変換していきます。この他にも、チームや天気などもカテゴリデータなのでone-hotに変換していく必要があります。
import pandas as pd
import numpy as np
train = pd.read_csv(file_path)
#最初に文字データを整数に変換
venue_list = np.array(train["venue"].unique().tolist())
for i in range(train.shape[0]):
for j in range(len(venue_list)):
if train.loc[:, "venue"].values[i] == venue_list[j]:
train["venue"][i] = j
#新しいカラムの追加と文字と整数を対応させた辞書を生成
venue_dic = {}
for i in range(len(venue_list)):
train[str(venue_list[i])] = 0
venue_dic[str(venue_list[i])] = i
#辞書をSeriesに変換
venue = pd.Series(venue_dic)
#one-hot表現に変換
for i in range(train.shape[0]):
for j in range(venue.shape[0]):
if train["venue"][i] == venue[j]:
train[str(venue_list[j])][i] = 1
#最後に元のvenueカラムを削除して終了
del train["venue"]
このプログラムを走らせた結果が以下のようになります。
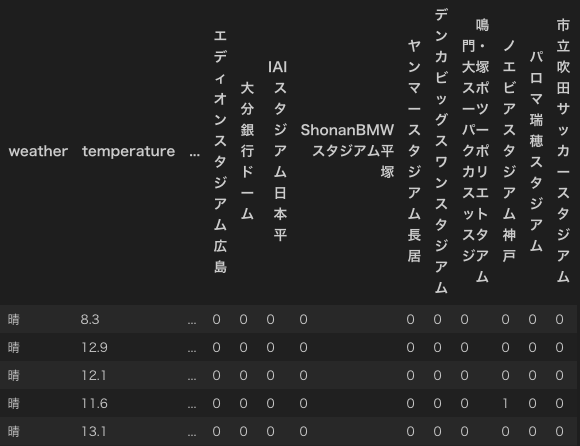
途中省略されているところはありますが、one-hotベクトルに変換されていることが確認できる(特に4行目)と思います。
4.まとめ
NumpyとPandasだけで書いた僕のプログラムはおそらく見る人が見ればだいぶ汚いので、もっとエレガントな変換の方法があればコメントお願いします。