

やりたいこと
下のようにいくつかの年月が含まれているデータを月ごと、日ごとに分解してファイルに落とし込みます。
今回扱うのはCSVファイルです。ライブラリはPandasを使います。
2018/08/31 23:59
2018/09/01 00:00
完成形
目指す形はこのような感じになります。
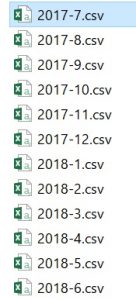
使うもの
・Python3.6.5
・Pandas
考え方
ここから本題に移ります。連続しているデータをどやって切り出すのかということですが、いろいろ考えた結果、前後の差分を取り、その値の結果で月が替わるかどうかを判定することにしました。
各データを細かい配列に分解し、その配列をループで読み取っていきます。
現在の配列がi(t)なら、i(t)-i(t-1)で差分を見てやります。例えば6月のデータ同士なら差分が0になるので同月⇒月替りしない、逆に6月と7月なら差分は1になるので月替りということで処理を分岐させます。
ただし、差分をとっただけでは6月の最後尾データに7月の先頭データ(2017/07/01 00:00)が、7月の先頭データは2017/07/01 00:01から入ってしまい時間がずれてしまいますで後述の処理で補正します。
元データの前提条件
ここで言う一月のデータの定義は2017年6月とすると2017/06/01 00:00 ~ 2017/6/30 23:59までです。
(業務の関係上HH:MMとしていますが、原理としてはHH:MM:SSも同じです)
今回使用する元データは最新の状態まで含まれているデータとします。
つまりきれいに1ヶ月入っているわけではなく、月半ばまでのデータが最後となるような
データファイルに対しての処理となっています。また最初の月のデータも途中から始まっていることを条件にします(最初=00:00)から入っていてもいいものとします。
1.データの読み込み
大本となるCSVデータは以下の状態で一つのファイルとしてまとめられています。
DATETIME DATA
2017/06/30 23:59 3.1415
2017/07/01 00:00 1.4142</pre>
ここでは見やすさのためスペース区切りにしましたが、実際はカンマ区切りです。
また、日付は%mm/%ddで書いていますが以下では元のデータ形式のため%m/%dであることに注意してください。
import pandas
filepath = "hogehoge.csv"
df = pd.read_csv(filepath, index_col=0)
df = df.reset_index()
#読み込み時の日付フォーマット(文字列型)をdatetime型に変換しカラムを再定義します
df['DATETIME'] = pd.to_datetime(df['DATETIME'], format = '%Y/%m/%d %H:%M')
df['DATA'] = df['DATA'].values.astype(float)
#日時データをラムダ関数を使って年・月に分解します
df['year'] = df['DATETIME'].map(lambda x: x.year)
df['month'] = df['DATETIME'].map(lambda x: x.month)</pre>
2.配列とデータフレームから数値の抽出
以下でループ処理するために配列を用意します。またファイルから取り出したデータはそのまま使うことができないのでvalueメソッドを使って値を取り出す処理を書きます。
#sep_dateには元データの日時がそのまま入ります
sep_date = []
sep_data = []
#sep_yearとsep_monthには先程ラムダ関数で分解した年・月データが入ります
sep_year = []
sep_month = []
#この配列は例えば6月の配列に含まれた7月データを取り除くときに使用します
last_date = []
last_data = []
#以下では各データの値を抽出します
df_datetime = df.DATETIME.values
df_data = df.data.values
df_year = df.year.values
df_month = df.month.values
3.ループ処理開始
本当は内包表記などを使いたいのですが今回はプロトタイプの状態で書いてあるので少し汚いコードになります。
#以下の配列で使うためのカウンタを初期化
i = 0
j = 0
#元ファイルの行数分だけループ処理します
for idx in range(df.shape[0]):
#ループごとに先に数値を、先程用意した配列に格納していきます
sep_data.append(df_cpu[idx])
sep_date.append(df_datetime[idx])
sep_year.append(df_year[idx])
sep_month.append(df_month[idx])
#差分を取るため最低でも月の要素は2つ必要です。最初の格納時とそれ以降の
#処理を分けて書いています
#要素が1つしかない場合は差分が取れないので次のループに移ります。
if len(sep_month) <= 1:
i += 1
continue
#要素が2以上になったら、現在と一つ前の要素の値で差分を取ります。
#差分が0の場合は同じ月とみなすことができます。
#現在のループ回数がループ最終行までいかなければカウンタを更新しループを続けます。
if len(sep_month) > 1:
if sep_month[i] - sep_month[i-1] == 0:
if idx+1 != df.shape[0]:
i += 1
continue
else:
pass
#後述します
if len(last_date) > 0:
sep_data.insert(0, last_data[j])
sep_date.insert(0, last_date[j])
j += 1
#CSVタイトル用です
ym = str(sep_year[i-1]) + "-" + str(sep_month[i-1])
#現在のループ回数+1の回数が最終行でなければ翌月のデータが配列に
#入ってくるためそれを取り除いたデータをデータフレーム化します
#ちなみにデータフレーム化しないとファイル出力できません
if idx+1 != df.shape[0]:
monthly_data = pd.DataFrame({'DATETIME' : sep_date[:-1],
'DATA' : sep_data[:-1]})
#現在のループ回数+1の回数が元データの最終行であれば
#月半ばで終わっている今回のデータでは翌月データが乗っかってこないため
#配列に入れた要素をすべてをデータフレーム化します
if idx+1 == df.shape[0]:
monthly_data = pd.DataFrame({'DATETIME' : sep_date[:],
'DATA' : sep_data[:]})
#CSVとして出力します
df_monthly = monthly_data.to_csv(ym + ".csv")
#後述します
last_data.append(sep_data[-1])
last_date.append(sep_date[-1])
#ファイル出力したら配列を空にし、次の月のループに使えるようにします
sep_data.clear()
sep_date.clear()
sep_year.clear()
sep_month.clear()
i = 0
last_date, last_dataについて
上記コメントに書いた「後述します」についてです。
今回のような処理の場合、例えば6月と7月のデータには以下のような値が入っています。
[2017-06-01 00:01, 2017-06-01 00:02, …, 2017-07-01 00:00][2017-07-01 00:01, 2017-07-01 00:02, …, 2017-08-01 00:00]これを見ると6月の最後要素は7月の先頭要素に入るべきデータが格納されています。
後者に対してはデータフレーム化時にsep_date[:1]とすることで取り除くことができます。
一方、前者については別の方法を考える必要があります。
そこで一月のループ処理が終わった時点でdate配列およびdata配列の最終要素を別の配列last_date,laste_dataに格納し、last_の要素を次のループ時に先頭要素に追加することで補正することができます。
例:
今、6月でループを回しているとします。すると上記のように6月に入るデータは
[2017-06-01 00:01, 2017-06-01 00:02, …, 2017-07-01 00:00]です。6月は00:01から始まるのでここでは先頭要素に対して処理はしません。
最後要素の2017-07-01 00:00はsep_date[:-1]で6月配列からは除去します。
また同時にlast_date,last_dataに2017-07-01 00:00とこのときのデータを格納します。
すると次の7月のループではすべての要素を格納し終わった段階(2017-08-01 00:00も除去済み)で、
if len(last_date) > 0:
sep_data.insert(0, last_data[j])
sep_date.insert(0, last_date[j])
j += 1
が効いてくるので、この7月配列の先頭に2017-07-01 00:00が入り結果的に7月配列は
[2017-07-01 00:00 ~ 2017-07-31 23:59]
を得ます。
少し複雑になってしまいましたが、本当はもっと簡単で良い処理があるかもしれません。
簡単な考え方・書き方があったら教えていただけると幸いです。