

[kaggle]0から本当に機械学習を理解するために学ぶべきこと~一流のデータサイエンティストを例に~
[データラングリング編]0から本当に機械学習を理解するために学ぶべきこと~一流のデータサイエンティストを例に~
前回までのあらすじ
上記の記事では、タイタニック号の水難事故である人が生き残るかどうかを正確に判別できるような機械学習モデルを作るべく、訓練データの傾向や歴史的な事実を用いて仮説を立て、それに基づいて特徴量の作成など、様々な操作を行ってきました。ここからはいよいよ実際にscikit-learnを使って機械学習モデルの作成に入ります。
モデルを作って予測する
ついに長きに渡った前処理を終えて、結果を予測させることができるようになりました。ここでは、その使いやすさで絶大な人気を誇る機械学習ライブラリのscikit-learnを使うことになります。
この段階では、どんなアルゴリズムを使うか考えていくのですが、画像分類や異常検知などの特殊なケースでない場合は、取り敢えず実際にアルゴリズムに掛けてみて精度がいいものを採用する形になります。
scikit-learnの開発チームが、どのような場合にどのようなアルゴリズムを用いるとよいかということを纏めた画像が以下の図です。大体どのシチュエーションでどのアルゴリズムを用いるのか、把握しておきましょう。
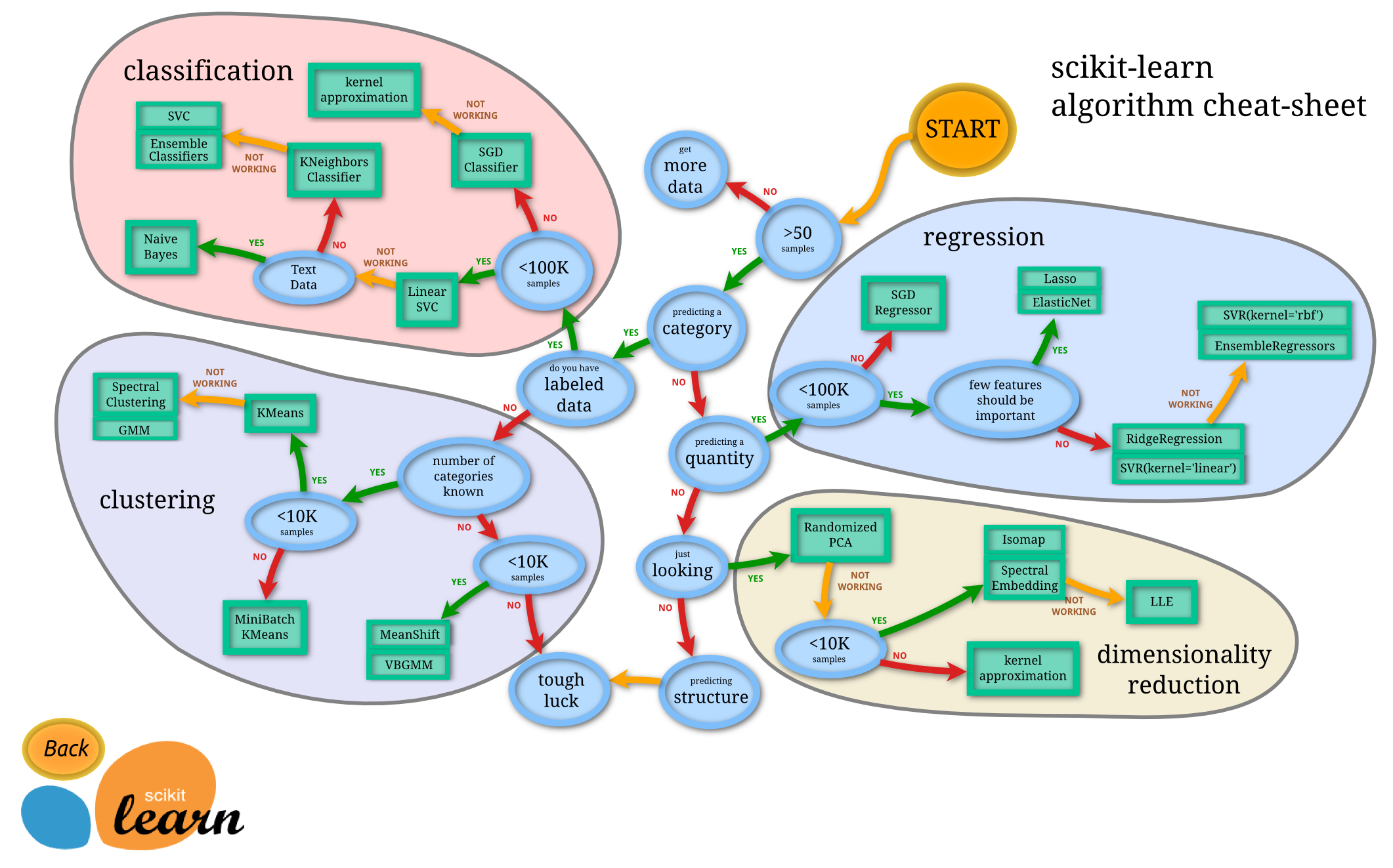
以下は今回用いているアルゴリズムの一覧です。
折角なので簡単な説明をつけました。
-
Logistic Regression
- ロジスティック回帰。回帰とついてますが、分類もできます。古くから用いられている伝統的なアルゴリズムです。計算量が少なく済み、モデルの更新が素早く行えます。しかし、複雑な問題では精度が落ちてしまうことが多いです。
-
KNN or k-Nearest Neighbors
- KNNまたはk近傍法。ざっくり言うと、予測したいモノとn次元空間内で一番近いモノを見ることで結果を予測しています。
-
Support Vector Machines
- SVM。割と早い計算速度でありながら、複雑な問題にも対処できる可能性があります。
-
Naive Bayes classifier
- ナイーブベイズまたは単純ベイズ分類器。ベイズ統計の理論を用いたアルゴリズムです。スパムメールの検出などで活躍します。
-
Decision Tree
- 決定木。その特徴はなんといっても予測結果の解釈が容易だということです。アルゴリズムどういうときにどういう結果になると予測するのか、その原理が明快に出てきます。
-
Random Forrest
- ランダムフォレスト。バギングと決定木を組み合わせて一般化したものです。決定木よりも高い精度になる場合が多いですが、結果の解釈性は失われます。最近はこのランダムフォレストがKaggleで大人気です。
-
Perceptron
- パーセプトロン。流行のディープラーニングの元になったアルゴリズムです。正直あんまり使われません。
-
Artificial neural network
- ニューラルネットワーク。人間の脳の機能をヒントに作られたアルゴリズムです。ディープラーニングで有名です。画像認識など、線形分離不能な問題に対して高い性能を発揮します。
データを読み込ませる準備
X_train = train_df.drop(“Survived”, axis=1)
Y_train = train_df[“Survived”]
X_test = test_df.drop(“PassengerId”, axis=1).copy()
X_train.shape, Y_train.shape, X_test.shape
((891, 8), (891,), (418, 8))
まずはscikit-learnに読み込ませるために、訓練データとテストデータを用意します。以下のことに注意しましょう。
- X_trainには応答変数(答えとなる特徴量)を除いた予測変数(応答変数を予測するために使う特徴量のこと)を入れる。
- Y_trainには応答変数のみを入れる。
X_testにはテストデータを格納したデータフレームを入れます。
先程のX_trainとY_trainのデータを使って訓練したモデルが、訓練データの予測変数から応答変数を予測したときに、どの程度正解できるのかということが、このモデルの予測精度の推定になります。
ここでは、取り敢えず大まかな流れを把握するということで、この予測精度を実際の予測精度の推定値としていますが、ホントはよくありません。訓練データを使って学習したモデルで訓練データを使って予測させるのですから、実際の予測精度
よりも良い値が一般的に出てきます。さらに、それはモデルが複雑であるほど大きな差異となり、あんまり複雑にしすぎると、むしろ過剰適合となり、実際の精度は下がってしまいます。
このような自体を防ぐため、一般的に交差検証という手法が用いられます。興味のある方は調べてみてください。
以下のコードはロジスティック回帰をscikit-learnを使って行い、精度を表示するコードです。
ロジスティック回帰
# Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
acc_log
80.359999999999999
どうですか?簡単そうだと思えるのではないでしょうか?
ロジスティック回帰を使用して、仮説を検証できます。これは、決定関数内の特徴量の係数を計算することによって行うことができます。
正の係数は応答の対数オッズを増加させ(確率を増加させる)、負の係数は応答の対数オッズを減少させる(確率を減少させる)ことを表します。
ざっくり言うと、対数オッズの絶対値が大きいほど予測に有用な特徴量だということを表します。
- 性別が最も高い正の係数で、性別の価値が増加する(男性:0〜女性:1)ことを意味します。
- 逆にPclassが増加すると、Survived = 1の確率が最も低下します。
- Age * Classは、Survivedと2番目に高い負の相関関係を持つため、モデル化するのに適した人工的な特徴量だと言えそうです。
- 次に、タイトルが2番目に高い正の相関関係になります。
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = [‘Feature’]
coeff_df[“Correlation”] = pd.Series(logreg.coef_[0])
coeff_df.sort_values(by=‘Correlation’, ascending=False)
| Feature | Correlation | |
|---|---|---|
| 1 | Sex | 2.201527 |
| 5 | Title | 0.398234 |
| 2 | Age | 0.287163 |
| 4 | Embarked | 0.261762 |
| 6 | IsAlone | 0.129140 |
| 3 | Fare | -0.085150 |
| 7 | Age*Class | -0.311200 |
| 0 | Pclass | -0.749007 |
SVM
次に、SVM(サポートベクターマシン)を使った予測モデルの作成方法を見て行きます。SVMは一般的にロジスティック回帰よりも良い精度が出ることが多いです。
# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
acc_svc
83.840000000000003
k近傍法またはKNN
次はk近傍法またはKNNはノンパラメトリックの分類アルゴリズムです。一般的にはロジスティック回帰よりもいい精度が出ますが、SVMよりも劣ることが多いです。
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
acc_knn
84.739999999999995
単純ベイズ分類器またはナイーブベイズ分類器
次は単純ベイズ分類器またはナイーブベイズ分類器です。ざっくり言うとベイズ統計の理論を用いた分類アルゴリズムです。あまり汎用的なアルゴリズムではないので使う場面が限られます。
# Gaussian Naive Bayes
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
acc_gaussian
72.280000000000001
パーセプトロン
パーセプトロンは教師ありバイナリ分類器です。留意して欲しい点は、パーセプトロンは線形予測関数の組み合わせということと、オンライン学習が可能だという点です。
# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
acc_perceptron
78.0
決定木
次に、決定木を見て行きます。
決定木は以下の図のように予測変数がどのような時に応答変数がどうなるかということを考えるモデルです。一般的に一番精度が高くなります。
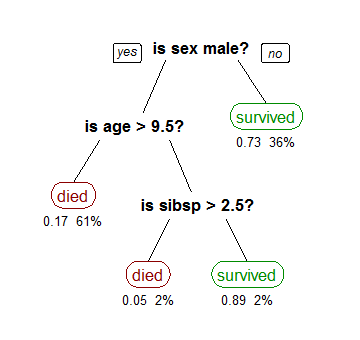
出展: Wikipedia
# Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_tree
86.760000000000005
ランダムフォレスト
次はとても人気のあるモデルのランダムフォレストです。ランダムフォレストは、トレーニング時に多数の決定木(n_estimators = 100 としているため、今回は100個)を構築し、分類、回帰および他のタスクのアンサンブル学習方法です。
モデルの予測精度はこれまでに見てきたモデルの中で最も高いです。 このモデルの出力(Y_pred)を使用して、実際に課題に提出することにします。
# Random Forest
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest
86.760000000000005
モデルの評価
さて、ここまで作成してきたモデルをランク付けしてどのモデルが最良か判断しましょう。決定木とランダムフォレストが全く同じ精度ですが、決定木はトレーニングデータセットに過剰適合(オーバーフィッティングや過学習ともいう)しやすい性質があるので、ここではランダムフォレストの方がより汎化性能(未知のデータが与えられた時にどれだけ良い精度が出せるかどうかというモデルの指標)が良いだろうと予想し、ランダムフォレストを選択します。
models = pd.DataFrame({
‘Model’: [‘Support Vector Machines’, ‘KNN’, ‘Logistic Regression’,
‘Random Forest’, ‘Naive Bayes’, ‘Perceptron’,
‘Stochastic Gradient Decent’, ‘Linear SVC’,
‘Decision Tree’],
‘Score’: [acc_svc, acc_knn, acc_log,
acc_random_forest, acc_gaussian, acc_perceptron,
acc_sgd, acc_linear_svc, acc_decision_tree]})
models.sort_values(by=‘Score’, ascending=False)
| Model | Score | |
|---|---|---|
| 3 | Random Forest | 86.76 |
| 8 | Decision Tree | 86.76 |
| 1 | KNN | 84.74 |
| 0 | Support Vector Machines | 83.84 |
| 2 | Logistic Regression | 80.36 |
| 7 | Linear SVC | 79.01 |
| 5 | Perceptron | 78.00 |
| 4 | Naive Bayes | 72.28 |
| 6 | Stochastic Gradient Decent | 70.82 |
submission = pd.DataFrame({
“PassengerId”: test_df[“PassengerId”],
“Survived”: Y_pred
})
# submission.to_csv(‘../output/submission.csv’, index=False)
私達がこの提出した結果、Kaggle全体の中で、6,082エントリー中3,883位でした。取り敢えず、手始めとして取り組んだ結果としては悪くないでしょう。精度を改善するアイデアが思いついた人が居たら是非実践して見てください。
参考文献
このノートブックは偉大な先人のお陰で作成することができました。
- A journey through Titanic
- Getting Started with Pandas: Kaggle’s Titanic Competition
- Titanic Best Working Classifier
随時加筆修正予定