

人間性をさがせよ QiitaのTypo検出 - Qiita
にtextlintを追加しました。
まとめ
- textlintの追加は簡単だった
- ほんのり(優しく)チェックできるtextlintプラグインを探さなければならない
- ホワイトリスト機能を改善してもらった
- textlintに引っかかる投稿はそこそこある
- 誤判定は割と出る。が、一部は慣れでスルーできる
- 編集リクエストは一つにまとめて送信する
- 編集リクエストが採用されなくても泣かない
追加コード
人間性をさがせよ QiitaのTypo検出 - Qiita
のコードを見ていないとなんのこっちゃですが、diffで表示します。
--- a/index.js
+++ b/index.js
@@ -4,6 +4,9 @@ const axios = require('axios');
const DICTIONARY = require('./dictionary');
+const TextLintEngine = require('textlint').TextLintEngine;
+const engine = new TextLintEngine();
+
const { IncomingWebhook } = require('@slack/client');
const slackDefaultValue = {
username : 'Qiita typo checker',
@@ -82,12 +85,15 @@ const getItems = async () => {
module.exports = async () => {
const items = await getItems();
- items.forEach(item => {
+ // forEach await待たない問題があるので、素直にするならfor of continue にする
+ for (let item of items) {
// tagはバージョン情報などは不要なので、連結してしまう
item.tags = Object.keys(item.tags).map(key => item.tags[key].name).join(', ');
// 検索対象はタイトル、タグ、本文。一度に検索するためつなげてしまう(メモリだいぶ増)
// Markdonwの```チェックのためつなげる改行を増やしている`
let searchTarget = item.title + '\n\n' + item.body + '\n' + item.tags;
+ // 量が多すぎるとtextlintが終わらないので、バイナリ、トークンなど長大データをそのまま貼り付けた行などを排除する それでもダメならlengthで足切りを検討
+ searchTarget = searchTarget.replace(/.{200,}/g, '');
item.typos = {};
// 検索!
@@ -100,17 +106,20 @@ module.exports = async () => {
item.typos[correct] = matches.join(', ');
});
+ const result = await engine.executeOnText(searchTarget).catch(e => {
+ console.log('textlint error', e);
+ return [{messages : []}];
+ });
+ result[0].messages.forEach(message => {
+ item.typos[message.message] = message.fix || message.ruleId;
+ });
+
if (Object.keys(item.typos).length == 0) {
- return;
+ continue;
}
// console.log(item.typos); // debug
sendSlack(item);
- });
+ };
};
メインは
const result = await engine.executeOnText(searchTarget).catch(e => {
console.log('textlint error', e);
return [{messages : []}];
});
result[0].messages.forEach(message => {
item.typos[message.message] = message.fix || message.ruleId;
});
ですね。
改良の余地はまだまだありますが、ほぼこれだけで通知の方にも手を加えずに済んだのでよかったです。
表示上の今までのチェックとの違いは、同じミスが何回出たかがわからない点と、どう間違ったのかがわからないぐらいでしょうか。
ループの形式変更理由はこちら
async/awaitを、Array.prototype.forEachで使う際の注意点、という話 - Qiita
あとはこちらも…
for...of を使うなってAirbnbが言ってたから使わないようにしてたら慣れた - Qiita
私は単語的にforEachが馴染みあるのでよくfor...ofを忘れてそちらを使いますが、今の所は宗派などはない。と思います。動けば良い。
動けば良いと言えばfor...ofに変えることは必須ではありませんでした。
textlintで各処理が詰まって負荷が高まってそうだったことと、並列で処理されるので件数が多いとSlackへの過postでたまにエラーが出ていたぐらいです。
base64形式の画像をtextlintが処理する過程でパフォーマンスが落ちていたので、調査の中で直してしまいました。
configは同階層の.textlintrcを自動で読み込んでくれます。
diff --git a/package.json b/package.json
index 6dbba91..c390972 100644
--- a/package.json
+++ b/package.json
@@ -3,17 +3,22 @@
"version": "1.0.0",
"description": "",
"main": "index.js",
- "bin" : "bin.js",
+ "bin": "bin.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "khsk",
"license": "MIT",
"dependencies": {
- "@slack/client": "^4.0.1",
+ "@slack/client": "^4.3.1",
"axios": "^0.18.0",
"date-utils": "^1.2.21",
"dotenv": "^5.0.1",
+ "textlint": "^10.2.1",
+ "textlint-filter-rule-whitelist": "^2.0.0",
+ "textlint-rule-ja-no-abusage": "^1.2.1",
+ "textlint-rule-ja-no-successive-word": "^1.0.2",
+ "textlint-rule-ja-unnatural-alphabet": "^2.0.0",
"yarn": "^1.5.1"
}
}
プラグインの解説は後ほど。
スクリーンショット
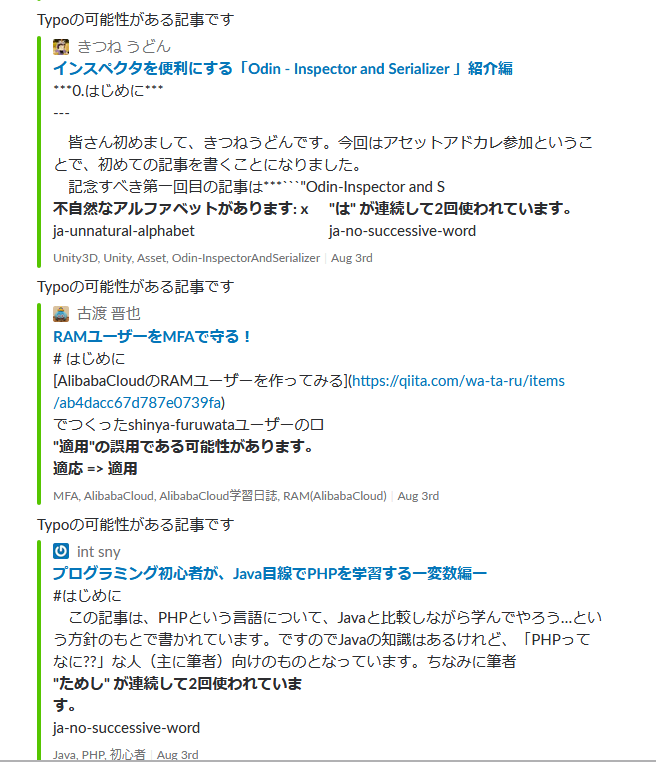
textlintプラグイン
使用しているものはpackage.jsonのとおり、
- textlint-ja/textlint-rule-ja-no-abusage: よくある日本語の誤用をチェックするtextlintルール
- textlint-ja/textlint-rule-ja-no-successive-word: 同一の単語を間違えて連続しているのを見つけるtextlintルール
- textlint-ja/textlint-rule-ja-unnatural-alphabet: 不自然なアルファベットを検知するtextlintルール
に加え、無視できるワードを指定できる
です。
texlintのプラグインの探しかたがわからず(Collection of textlint rule · textlint/textlint Wikiぐらい?)、
今回は自作の単語帳の補助的に日本語文章をlintしたいということで、
textlint-ja
から良さそうなものを探しました。
また、他人の文章をチェックする性質から、文章のスタイルを正す・統一するというよりは、typoに属する人の「うっかりミス」を見つけるルールを探しました。
流石に目的がニッチ過ぎて使えたものは多くはないのですが。
textlint-ja/textlint-rule-ja-no-abusage: よくある日本語の誤用をチェックするtextlintルール
は主にQiita上で指摘された誤用ルールです。
自作で入れようか悩んでいましたが、こちらのほうがちゃんと文脈を読んで検出してくれているようで、誤判定問題が少ないので助かります。
textlint-ja/textlint-rule-ja-no-successive-word: 同一の単語を間違えて連続しているのを見つけるtextlintルール
こちらも手組は面倒そうな手合です。
textlintなら例外はホワイトリストに書き出せるので楽ちん。
文字の長さも例文の
これはは
など一文字の連続ではなく、
なるほどなるほど
など長い文字の連続も見つけてくれることがありがたいですね。
おそらく、現在一番編集リクエストを作成しているルールです。
textlint-ja/textlint-rule-ja-unnatural-alphabet: 不自然なアルファベットを検知するtextlintルール
入力ミスを見つけるルールで、具体的にはおおよそ
「全角文字に挟まれた英字」
を見つけてくれます。
これは結構多いんじゃないかな?と予想していたのですが、
案外本当のミスは少ないです。
逆に機械学習やアルゴリズムで頻出するxやkやnなどが文中で使われよく引っかかります。
誤検出ナンバーワンで、ホワイトリストを拡充するとともに、数学的な記事タイトルで誤検出と決めつける、という属人的な運用をしています。
(ホワイトリストを頑張りすぎると取りこぼしもでそうなので)
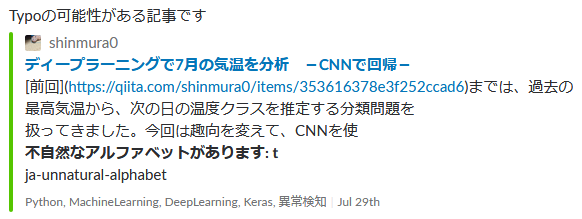
スルーする・スルーしやすい記事例。
textlint/textlint-filter-rule-whitelist: textlint filter rule that filter any word by white list.
ホワイトリストがついていないルールにも適用できるフィルターです。
ja-unnatural-alphabetにはallowオプションがついているので、
ja-no-abusage, ja-no-successive-word用です。
誤判定というよりは許したい表現を列挙しています。
ホワイトリスト周りは
textlint-filter-rule-whitelistとルール独自のallowオプションによる正規表現の違いに注意する - Qiita
で改良を加えていただきました…感謝。
遭遇したエラー
検出Typoの体感
助詞の連続が多い。です。
無心で
をを → を, はは → は, にに → に
などと送り続けていると、我ながら細かいなあと思います。
最初は技術的用語誤りの修正が主眼でしたが、図らずも多く送っているものがこれだと、ステレオタイプな意地悪姑になっているような気分です。
明確なミスだとわかりやすいのはとても助かるのですが…
広い気持ちで受け入れてもらえるとありがたいです。
以上を踏まえた.textlintrc
整理がかなり適当ですが、ホワイトリストを備えた.textlintrcです。
{
"filters": {
"whitelist": {
"allow": [
//// ja-no-successive-word
// エモい繰り返し(畳語)などを許可する
"!",
"?",
"ある",
"ぜひ",
"是非",
"など",
"ほぼ",
"さらに",
"さて",
"よし",
"ポチ",
"とか",
"ダメ",
"/よくよく((考え|見)((た|る|て|れ)|.{,6}(ると|たら)))/",
"めでたし",
"もっと",
"ずっと",
"毎度",
"毎回",
"重ね",
"なんと",
"なるほど",
"/つど|都度/",
"/っ{3,}/", // 三回以上はエモ
"要所",
"/(ってて|してて|れてて|(立|た)てて|(見|み)てて|(す|過)ぎてて|(書|か|使|つか).てて|(出来|でき)てても|べてて|(眺め|ながめ)てて)|(聞|き)いてて/",// 口語っぽいてて い抜き
//"見える", // 見える見える 微妙?
"/そうそう(?=(な|無)い)/",
"/外(だ|出)しし/", // ~ます、ておきます など
"長押しし",
// 動作に関するエモ
"/ぬる|カク|カツ|ギリ|ゴリ|キビ/",
// 記述にかんするエモ
"/ベタ|ペタ|かき|めも|メモ/",
// 副詞・感動詞っぽいもの
"/(ま|や|さ)(あ|ぁ)/",
// 〇〇など記号類は一般的
"/○|〇|●|X|〜|─|※|★|\\^|^|■|□|◆|◇|▲|△|▼|▽/",
"/←|↑|→|↓/",
// 泣き顔;;
";",
// 三点リーダー風な、うーん、慚愧?悔い的なニュアンスでエモるので。 というか区別できない。
"。",
"、",
// 三点リーダーの代わりの点類
"・",
".",
// レイアウト作りたがってる人が多くて、半角やmarkdown促すほどでもないので。
" ",
// 全角数字は対象外
"/[0-9]/",
// お先にシルブプレ
"/ひとつ|一つ|1つ|1つ/",
// 結びの挨拶 JSには\z系はなく、mオプションをつけなければ全体の末尾に
"/(では|でわ)。?$/",
// 意外に出会う
"ばなな", // ももは誤字の可能性があるので除外
// ~ だった あった した ため
"/たた(?=め)/",
// 草刈り 誤判定考慮しひとまず行末とセリフ末のみで
"/(w|w)+(。|、|)*($|」|\\)|))/im",
// 新宝島
"丁寧丁寧丁寧",
// 九九プログラミングが流行ったので
"九"
]
}
},
"rules": {
"ja-no-abusage": true,
"ja-no-successive-word": true,
"ja-unnatural-alphabet": {
allow: [
// デフォルト
"a", "i", "u", "e", "o", "n",
// 大文字は対象外
"/[A-ZA-Z]/",
// 助詞が続く場合は変数について述べているとする。
"/[a-zA-Za-zA-Z](が|の|を|に|へ|と|より|から|で|や)/",
// 助詞以外の変数についての述懐
"/[a-zA-Za-zA-Z](は|または)/",
// 任意の数について述べている
"/[a-zA-Za-zA-Z](個|回|件|秒|番|乗)/",
// 全角かっこに囲まれて検出は無視
"/([a-zA-Za-zA-Z])/",
// スラング系
"/お(k|k)/i",
"/う(p|p)/i",
// 日付フォーマット
"/(年m月)|(月d日)|(時m分)/i",
// 座標
"/(x|y|z)(座標|軸|方向)/i",
// C言語生成物
"/(c|c|h|h)ファイル/i",
"k近傍",
// HTML
"/(p|p)(タグ|要素)/"
],
"allowCommonCase": true
}
},
}
textlint自体の導入はすぐ出来たんですが、ホワイトリストの拡充をちょっとずつ行っていたので、なかなか投稿できませんでした。
そろそろ一区切りをつけたいので、まだまだ誤検出はあるものの、現状を公開です。
編集リクエスト編
ここからは本題から外れます。
編集リクエストを積極的に送り出して約半年ほど。
4月ごろにも思うところがあったものの、
今回はさらに気づいた編集リクエストとの付き合い方を書こうと思います。
編集リクエストはひとつにまとめよ
プログラミングができるみなみなさまは十分承知のことと存じますが、
我々はいろいろなものを小さく、意味のある単位に分けることを良しとします。
クラスだったりメソッドだったりサービスだったり。
コミットも一つの変更を表したり、
コミットは作業ログではない! - Qiita#1つのコミットで1つを行う
プルリクエスト(まさに編集リクエスト!)も小さいほうが好まれるはず。
…typoに限れば「fix typo」でがばっと一気に変更加えることはあるんですが、あくまで自分のコードの話。
編集リクエストでも「A → A'」「B → B'」と別々のtypoは別々に編集リクエストを送っていました。
しかし、どうにも採用率がよくない。
1つ目は採用されるが2つ目が採用されない。
というパターンが結構出てきました。
あるいは2つ目採用されたときに1つ目の変更がもとに戻ってしまっている…なんてことも。
編集リクエストの通知・導線が悪いのかはわかりませんが、どうにもよろしくない。
なので、信条をまげて全ての変更を
「A → A', B → B'」
と一つの編集リクエストにして送るようにしました。
他の方の編集リクエストを観察しても、小分けに送っている方って全然見かけないので、手抜くことが双方の利益かなと思っています。
サイレント採用がある
こちらも導線の問題なのか。
編集リクエストは採用も確認済み(非採用)にもされず、
だけれど指摘した内容は投稿者自身の普通の編集で改善済み。
というパターンがあります。
採用したくないのかやり方がわからないのかまではわかりませんが…。
編集リクエストが採用されないことを気にしない。ということは大前提なのですが、中には採用通知が来ないけれど直っているものもあるんだよ。
っということに気づいておいて貰えればなと。
気の持ちようです。
そもそも編集リクエストの認知度が低くない?
上記は少数派のパターンではあるのですが、お互いやる気はあるのにボタンの掛け違いのようにズレてうまくいかないなあと思います。
編集リクエストがより身近になったり、操作画面がよりわかりやすくなってくれれば改善するのかなと思う一方、
Qiitaが注力したい場所はここじゃないよなあ。
とも思います。
なので、今しばらくは何かよいアイデアで回していきたいものです。