動機など
最近、Serverlessの文脈からDynamoDBのテーブル設計の相談を受けることが多くなってきていて、Podcastでも話したけどけっこう図とかが無いと説明しづらい領域なので、まとまった資料がほしいなということでまとめてみる。
どう考えても長編大作エントリ不可避なので気力が続けば第二巻以降に続きます…!(フィードバックが多いと頑張れるかも…!)
本巻の対象と前提知識
本巻はDynamoDBのデータモデリングにスコープを絞っています。DynamoDBおよびデータベースの一般用語などについての説明は省きます。 前提知識としては以下のようなものになるかと思います。
- DynamoDBのサービスとしての概要や用語(
WCU,RCU,GSI,LSIなど)を知っている - Hash TableやB-Tree(B+Tree)といったデータ構造がどんなものか分かる
- RDBで第3以上の正規化されたデータモデリングができる
- ACIDがそれぞれ何か分かっている
DynamoDBの概要と少し踏み込んだユースケースなどを知るにはこちらのAWS Black Belt Online Seminarの資料がオススメです。
www.slideshare.net
正規化やACIDについてはおググりください。
本巻を読む必要がない方
最近(2018年の5月頃だったかな?)DynamoDBのデータモデリングをする上でとても有益なドキュメントが公式に公開されています。これを全て(かなりのボリュームがありますが)何の疑問もなく読めて理解できてしまう方はきっとこの虎の巻を読む必要はありません。本巻でもかなり引用させてもらう予定です。
DynamoDBはどんなデータベースか
実際にDynamoDBのデータモデリングの話に入る前に、DynamoDBが サービスではなくデータベースとして どのようなものであるかを知っておくと色々な場面で理解の助けになります。
DynamoDBはNoSQLの中で強いて分類するなら分散KVSという種類のデータベースになります。Keyによってデータが分散配置されるデータベースです。KVSと一口に言っても本当にKeyによる完全一致で1つずつしかデータを更新・取得できないものもあれば、内部的にインデックスを構築することで範囲検索や前方一致検索、全文検索などができるものもあります。
DynamoDBにおけるデータの物理構成
DynamoDBの物理的なデータ配置に関する有名なモデルとしてはクォーラムなどの仕組みを利用した分散同期と合意アルゴリズムが挙げられますが、これは内部的な話であり読み込みクォーラムを増やすことで強い整合性のある読み込みができる場合とできない場合があることを抑えておけば良いです。より深く知りたい方は論文を読んでみることをオススメします。
Amazon's Dynamo - All Things Distributed
それよりもデータモデリングにおいて大事なのが、データの物理的な分散配置を決める Partition Key による分散方式です。この Partition Key をハッシュ関数にかけた結果によってデータの配置が決まります。逆に言うと、この Partition Key がなければデータがどのPartition(イメージとしてはDynamoDBのクラスタを構成するデータノード)にあるかと特定することができません。そのため、DynamoDBにおいて Partition Key はテーブルに必須のものであり、フルスキャンを除いた検索クエリにおいては必ず Partition Key を指定する必要があるのです。

そして、DynamoDBテーブルの定義には前述の Partition Key と共に Sort Key というキーとの組み合わせをプライマリキー(主キー)とすることができます。この Sort Key は Partition Key によって配置されたPartitionの中にB+Treeインデックス *1 として構築されます。DynamoDBで Sort Key だけのインデックス探索ができないのは、Partition毎にインデックスが構成されているためなのです。
では、何故わざわざSort Keyだけで検索できた方が便利であるはずなのにPartition毎に構成する必要があったのでしょうか?それは(おそらく)性能を優先した結果です。 Sort Key を共有のインデックス空間に配置してしまうとあらゆるデータのインデックスがそこに構築されてしまい、RDBでは扱いにくい膨大なデータ量やハイトラフィックを扱うためのデータベースとしては致命的なボトルネックになりえます。また、 Partition Key で配置が決まるということは、Partitionの偏りを許容して Partition Key を全て同じ値にしてしまえば一つのインデックスとして構築できるわけで、分散を基本とすることは合理的であると言えます。
DynamoDBにおけるインデックス「GSI」と「LSI」
DynamoDBをよく分からずにテーブル設計をすると、KVSというイメージからか一意となるメインのキーだけに焦点を当てがちになる印象があります。しかし、DynamoDBを真に使いこなすためにはこの GSI (Global Secondary Index) と LSI (Local Secondary Index)特に GSI の使い方こそが肝であると言えます。
LSI
LSI は、プライマリキーと Partition Key が同じで Sort Key を別の属性としたキーです。Partition Key が同じためプライマリキーと同じ物理配置となり、 WCU や RCU が GSI のように独立せずテーブル自体のキャパシティユニットを消費します。また、物理配置が同じであるため LSI の更新はデータの更新に対して同期的に行われ、LSI に対するクエリは 強い整合性 を選ぶことができます *2。この LSI はプライマリキーと同様にテーブル作成時にしか指定できず、後から追加や変更することはできません。そのため、 LSI の使い道は比較的限られています。
Partition Key が同じ、後から変更不可ということで、RDBで言う所の主キーと第2キーだけが異なるような一部の候補キーのようなものがあればそれに付けることができる他、 プライマリキーとは違い重複可能であることを利用して、例えば掲示板やチャットシステムであるようなスレッドIDを Partition Key 、その中のコメントIDを Sort Key とするような明確な親子関係を表現したテーブルにおいて子属性であるコメントの作成・更新日時などといった重複する可能性があるがソートに使用するようなキーとして使用できます。
| thread_id (Main-PK, LSI-PK) | comment_id (Main-SK) | created_at (LSI-SK) |
|---|---|---|
| aaa | ccc | 2018-07-30 00:00:00 |
| aaa | ddd | 2018-07-31 00:00:00 |
| bbb | eee | 2018-07-30 10:00:00 |
GSI
GSI の使い方こそがDynamoDBの真髄です。GSI は LSI と違い、プライマリキーのようにユニークである必要もなければ、 LSI のように Partition Key を同じくする必要もありません。その代り、 GSI はメインテーブルに対する射影として実体を持つ別のテーブルであるということを念頭に入れる必要があります。射影って言われてピンときますか?射影ってRDBでも大事な概念である集合論における重要要素ですからね??(煽り芸)
GSI は超ざっくり言うとテーブルを別の角度から切り出したソート済みのデータの部分複製です。
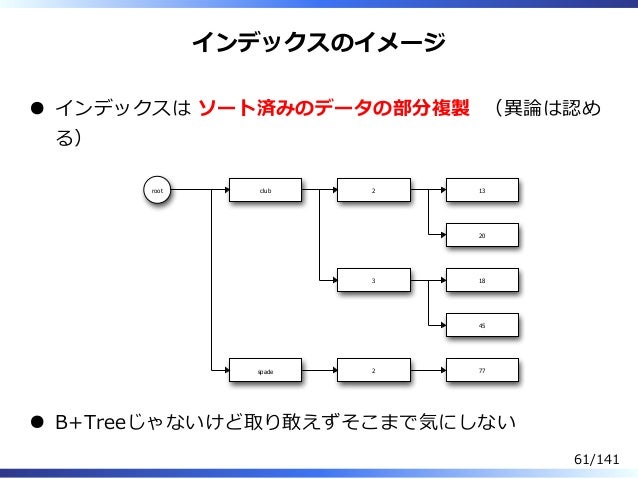
雑なMySQLパフォーマンスチューニング from yoku0825
つまり、射影として実体を持つ別のテーブルであるため、通常のテーブルと同じように独立したキャパシティを持ち Partition Key で分散した中で Sort Key によってインデックスが構築されています。セカンダリインデックスではありますが、その実体も分散しているのです。
また、 GSI は別のテーブルとして実体を持つため、本体のテーブルへの更新は非同期で反映されます。つまり、 GSI に対するクエリは結果整合性しか選ぶことができません。 結果整合性 と聞くと「ウッ」とか「大丈夫かな?」ってなる方が多い印象がありますが、MySQLのリードレプリカだって結果整合性なわけで、検索用である GSI の主な用途を考えるとほとんどがMySQLならリードレプリカに投げるようなクエリになるはずで、多くの場面で問題は無いといえるはずです。
分散したインデックスにおいて考慮すべきこと
(プライマリキーも含む)インデックスがPartitionによって分割されているということは、別々のPartitionに対してアクセスが分散されれば高い並列処理性能が出せるということです。これをまず念頭に置きましょう。それと同時に、あえて偏りを許容することで検索に都合の良いインデックスを構成するために、Partition当たりの処理性能を踏まえる必要があります。Partition当たりの処理性能は2018-07-31現在、 3000RCU および 1000WCU です。これを超えるとスロットリングが発生して処理がエラーとなります。逆に言えば、これを超えないならあえて偏りを許容することもできるのです。
次巻に向けて
SQLのような柔軟なクエリ言語を持たず、「フルスキャンしたら負け」と言われるDynamoDBにおいてテーブルの検索を効率的に行うにはこれらのインデックスの構成が非常に重要です。次回は実際のデータモデリングを行う上での考え方から入り、インデックスの設計まで踏み込めるといいなあ(願望)
次巻
書きました