

こんにちは。
pythonについて勉強していて、その応用として初めて自分で1からやったのでその備忘録として書かせていただきます。
また今回コードを見ただけで何をしているのかわかりやすくするために、コード内にコメントを多数入れました。
目次
- 背景
- 画像収集
- 顔の抽出
- 訓練データとテストデータに分割
- CNNで学習
- 結果
- 今後の課題
- まとめ
1.背景
pythonでスクレイピング、そして画像認識について勉強していて、この二つを同時に使い何か作ろうと思い何かいいテーマがないか探していました。
そんな中この夏坂道合同オーディションが開かれるが、
「どのように乃木坂・欅坂に決めるのだろうか」と疑問に思いまして、
「あ、その人の顔でどちら顔に近いか分類できたら面白くね」という考えに落ち着いたのでこのテーマについてスクレイピング、画像認識を応用してみることにしました。実際にやってみることが大事だと思ったので。
(今回はけやき坂は対象外にさせていただきました。)
使用するライブラリ
スクレイピング:selenium
機械学習 : keras
最終的なディレクトリ構成は以下のようになっております。
sakamichi
|――image
| |――face_keyaki
| |――face_nogi
| |――keyaki
| |――nogi
| |――test
| | |――keyaki
| | |――nogi
| |――train
| |――keyaki
| |――nogi
|
|――data
| |――train.npy
| |――X_test.npy
| |――Y_test.npy
|
|――model
| |――saka^model.hdf5
|
|――get_data_n.py
|――get_data_k.py
|――face_recog.py
|――make_data.py
|――CNN.py
参考
今回の画像認識をするにあたり、以下の2つの記事をかなり参考にさせていただきました。
とても感謝しております。
画像認識で「綾鷹を選ばせる」AIを作る
ディープラーニングでザッカーバーグの顔を識別するAIを作る
2.画像収集
機械学習で一番大事といっても過言ではないであろうデータをスクレイピングで収集していきます。
どちらのグループもブログの画像を対象に集めていきたいと思います。
ブログ画像をまとめているサイトが両グループともあったので、そのサイト内の画像を今回はseleniumを用いてある程度の数収集できるまでスクレイピングしました。
乃木坂ブログ画像まとめさいと
欅坂ブログ画像まとめさいと
以下は乃木坂のブログ画像を取るコードです。
import cv2
import urllib.request as req
from selenium import webdriver
import os
import time
driver = webdriver.Chrome(executable_path='C:/driver/chromedriver.exe')
count=1
#対象URLの指定
driver.get("https://keyaki.foxtrotalphalima.com/blog/nogi?id=all&vw=1&p=0")
time.sleep(3)
while True:
#ブログリスト取得
blog_list = driver.find_elements_by_class_name('blog')
for blog in blog_list:
#画像リスト取得
images = blog.find_elements_by_css_selector('ul > li')
for image in images:
#画像のURL取得
image_url = image.find_element_by_css_selector('img').get_attribute('src')
#画像保存
try:
image = req.urlopen(image_url).read()
if not os.path.exists('./image/nogi'):
os.mkdir('./image/nogi')
with open('./image/nogi/'+str(count)+'.jpg',mode='wb') as f:
f.write(image)
print('download - {}'.format(count))
except:
print('cant open url')
count += 1
if count > 3500:
break
#次ページのURLを取得し移動
print('------------------- go to next page --------------------------')
next_url = driver.find_element_by_css_selector('body > main > ul > ul > li:nth-child(2) > a').get_attribute('href')
driver.get(next_url)
time.sleep(5)
driver.quit()
これで指定したディレクトリに、1.jpg,2.jpg...と保存されていきます。
同じように欅の画像もとってきて合計で欅:2129枚、乃木坂:3544枚もの画像を取ってくることができました![]()
こんな感じになりました。

僕が selenium のスクレイピングでは、まず取ってきたい大枠の要素をfind_elements_by...を用いて取得し、これはリスト型で取得することができるのでfor文各大枠の要素に対してfind_element_by...で取りたいデータを詳しく取るということを意識しています。
3.顔の抽出
このままではデータとして不完全であるので、OpenCVを使い、集めた画像データから顔を切り抜きます。
import cv2
import sys
import os
import glob
from PIL import Image
import time
groups = ['nogi','keyaki']
root_dir = './image'
image_size = 50
count = 1
def image_data(file,path,group):
global count
#カスケードファイルのパスを指定
cascade_file = "C:/haarcascades/haarcascade_frontalface_alt.xml"
#画像の読み込み
image = cv2.imread(file)
#グレースケールに変更
image_gs = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#物体認識(顔認識)の実行
#image – CV_8U 型の行列.ここに格納されている画像中から物体が検出されます
#objects – 矩形を要素とするベクトル.それぞれの矩形は,検出した物体を含みます
#scaleFactor – 各画像スケールにおける縮小量を表します
#minNeighbors – 物体候補となる矩形は,最低でもこの数だけの近傍矩形を含む必要があります
#flags – このパラメータは,新しいカスケードでは利用されません.古いカスケードに対しては,cvHaarDetectObjects 関数の場合と同じ意味を持ちます
#minSize – 物体が取り得る最小サイズ.これよりも小さい物体は無視されます
#顔認識実行
cascade = cv2.CascadeClassifier(cascade_file)
#顔の範囲を返す(左上の点のx座標, y座標, 幅, 高さ)のリスト(配列)
face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(20,20))
#顔が認識されているかどうかで場合分け
if len(face_list)>0:
for i,face in enumerate(face_list):
x,y,w,h = face
face = image[y:y+h,x:x+w]
#画像サイズを一定にリサイズする
face = cv2.resize(face,(image_size,image_size))
#描画結果をファイルに書き込む
if not os.path.exists(path+'/face_'+group):
os.mkdir(path+'/face_'+group)
cv2.imwrite(path+'/face_'+group+'/'+str(count)+'.PNG',face)
count += 1
print('save - {}'.format(count))
else:
print('no face')
def main():
for group in groups:
count = 1
print('************** {} ******************'.format(group))
path = root_dir+'/'+group
#全画像ファイル取得
files = glob.glob(path+'/*.jpg')
print(len(files))
#顔抽出
for file in files:
time.sleep(1)
print(file)
image_data(file,root_dir,group)
if __name__ == '__main__':
main()
これで指定したファイルに、1.png,2.png...と顔部分のみが抽出された画像が保存されます。
抽出された画像は合計で欅:3137枚、乃木坂:2291枚
こんな感じ。

しかしOpenCVも確実に顔だけを抽出できるわけではないので


このような全く関係のないものまで抽出されてしまうので手作業で取り除いていきます。
ここはもう粘り強くやるしかなく、この作業にだいたい1時間費やして関係のない画像を取り除きました。
その結果、欅:1669枚、乃木坂:1653枚になりました。計2106枚を消す作業はかなり根気がいりました![]()
そしてここまでの工程でimageディレクトリはこのようになります。
image
|――face_keyaki
|――face_nogi
|――keyaki
|――nogi
4.訓練データとテストデータに分割
これまでに用意したデータを学習する準備として学習用データと検証用データ、そしてにモデルを評価するためのテストデータ分けます。
また画像データを学習機に読み込ませるために、Numpyで読めるデータ形式に変換して保存しておきます。
from sklearn.model_selection import train_test_split
from PIL import Image
import os,glob
import numpy as np
import shutil
import math
import random
#分類のカテゴリーを選ぶ
root_dir = './image/face_'
train_dir = './image/train/'
test_dir = './image/test/'
groups = ['nogi','keyaki']
nb_classes = len(groups)
image_size = 50
#顔をtrain,testに分けるコード
for idx,group in enumerate(groups):
print('----{}を処理中----'.format(group))
image_dir = root_dir + group
move_train_dir = train_dir + group
move_test_dir = test_dir + group
files = glob.glob(image_dir+'/*.png')
print(len(files))
th = math.floor(len(files)*0.2)
random.shuffle(files)
#データの20%をtestディレクトリに移動させる
for i in range(th):
shutil.move(files[i],move_test_dir)
#残りすべてをtrainディレクトリに移動させる
files = glob.glob(image_dir+'/*.png')
for file in files:
shutil.move(file,move_train_dir)
"""画像データをNumpy形式に変換"""
root_dir = './image/train/'
#訓練データ
#フォルダごとの画像データを読み込む
X = []
Y = []
for idx,group in enumerate(groups):
image_dir = root_dir + group
files = glob.glob(image_dir+'/*.png')
print('----{}を処理中----'.format(group))
for i,f in enumerate(files):
img = Image.open(f)
img = img.convert('RGB') #カラーモードの変更
img = img.resize((image_size,image_size))#画像サイズの変更
data = np.asarray(img)
X.append(data)#画像をベクトルにしたもの
Y.append(idx)#二値化問題
X = np.array(X)
Y = np.array(Y)
#学習用データと検証用データに分ける
X_train,X_test,y_train,y_test = train_test_split(X,Y,random_state=0)
xy = (X_train,X_test,y_train,y_test)
np.save('./data/train.npy',xy)
print(X_train.shape[1:])
print('ok',len(Y))
#テストデータ
#フォルダごとの画像データを読み込む
X = []
Y = []
for idx,group in enumerate(groups):
image_dir = root_dir + group
files = glob.glob(image_dir+'/*.png')
print('----{}を処理中----'.format(group))
for i,f in enumerate(files):
img = Image.open(f)
img = img.convert('RGB') #カラーモードの変更
img = img.resize((image_size,image_size))#画像サイズの変更
data = np.asarray(img)
X.append(data)#画像をベクトルにしたもの
Y.append(idx)#二値化問題
X = np.array(X)
Y = np.array(Y)
#テストデータ保存
np.save('./data/X_test.npy',X)
np.save('./data/y_test.npy',Y)
print(X_train.shape[1:])
print('ok',len(Y))
ここではまず用意した画像をshutil.move()をもちいて画像を訓練データとテストデータそれぞれ別のディレクトリに移動させ、そのあとにNumpy形式のデータとして保存しました。
学習用データとして1994枚、検証用データが665枚、テストデータが664枚となりました。
この工程でdataディレクトリはこんな感じになります。
data
|――train.npy
|――X_test.npy
|――Y_test.npy
5.CNNで学習
CNNのモデルを構築し、学習させていきます。
長くなってしまったので、わかりやすくするために分けて記述していきます。
#モジュールのインポート
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D
from keras.layers import Activation,Dropout,Flatten,Dense
from keras.utils import np_utils
import matplotlib.pyplot as plt
#カテゴリ
groups = ['nogi','keyaki']
nb_classes = len(groups)
image_size =50
以下で、モデルを構築する関数build_model(),正解率、損失値をグラフに描く関数draw_graph,モデルを学習する関数model_train(),モデルを評価する関数model_eval()を定義していきます。
まずはモデルを構築する関数から
#モデル構築
def build_model(in_shape):
model = Sequential()
model.add(Conv2D(32,(3,3),padding='same',input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),data_format='channels_first'))
model.add(Conv2D(64,(3,3),padding='same'))
model.add(Activation('relu'))
#model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('sigmoid'))
#モデル構成の確認
#model.summary()
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
return model
過学習を抑制するために全結合層にDropoutを組み込んでみました。
次に正解率、損失値をグラフに描く関数です。
#正解率、損失値のグラフ
def draw_graph(model):
fig, (axL, axR) = plt.subplots(ncols=2, figsize=(16,8))
acc = model.history['acc'] #学習用データの正解率
val_acc = model.history['val_acc'] #検証用データの正解率
loss = model.history['loss'] #学習用データの損失値
val_loss = model.history['val_loss'] #検証用データの損失値
axL.plot(acc,label='Training acc')
axL.plot(val_acc,label='Validation acc')
axL.set_title('Accuracy')
axL.legend(loc='best')
axR.plot(loss,label='Training loss')
axR.plot(val_loss,label='Validation loss')
axR.set_title('Loss')
axR.legend(loc='best')
plt.show()
正解率、損失値のグラフを左右に分けて描いていきます。
グラフを1画面に複数書くときにこちらが参考になるかと思います。
Matplotlibで複数のグラフを描画する方法
#モデルを訓練する
def model_train(X,y,X_t,y_t):
model = build_model(X.shape[1:])
history = model.fit(X,y,batch_size=8,epochs=10,validation_data=(X_t,y_t))
draw_graph(history)
#モデルを保存する
hdf5_file = './model/saka^model.hdf5'
model.save_weights(hdf5_file)
return model
モデルを学習させ、saka^model.hdf5という名前で保存します。
また今回は学習時間を短くするためにエポック数を10にして学習させます。
バッチサイズは8にしました。
#モデルの評価
def model_eval(model):
X = np.load('./data/X_test.npy')
y_test = np.load('./data/y_test.npy')
#データの正規化
X_test = X.astype('float') /256
y_test = np_utils.to_categorical(y_test,nb_classes)
score = model.evaluate(x=X_test,y=y_test)
print('loss : ',score[0])
print('accuracy : ',score[1])
ここで未知のデータでモデルを評価します。
#学習開始
def main():
X_train,X_test,y_train,y_test = np.load('./data/train.npy')
print('X_train shape : ',X_train.shape)
print('X_test shape : ',X_test.shape)
print('y_train shape : ',y_train.shape)
print('y_test shape : ',y_test.shape)
#データの正規化
X_train = X_train.astype('float') /256
X_test = X_test.astype('float') /256
y_train = np_utils.to_categorical(y_train,nb_classes)
y_test = np_utils.to_categorical(y_test,nb_classes)
#モデルを訓練し評価する
model = model_train(X_train,y_train,X_test,y_test)
model_eval(model)
これまでに作った関数を使いデータの読み込みから、学習、そして評価をしていきます。
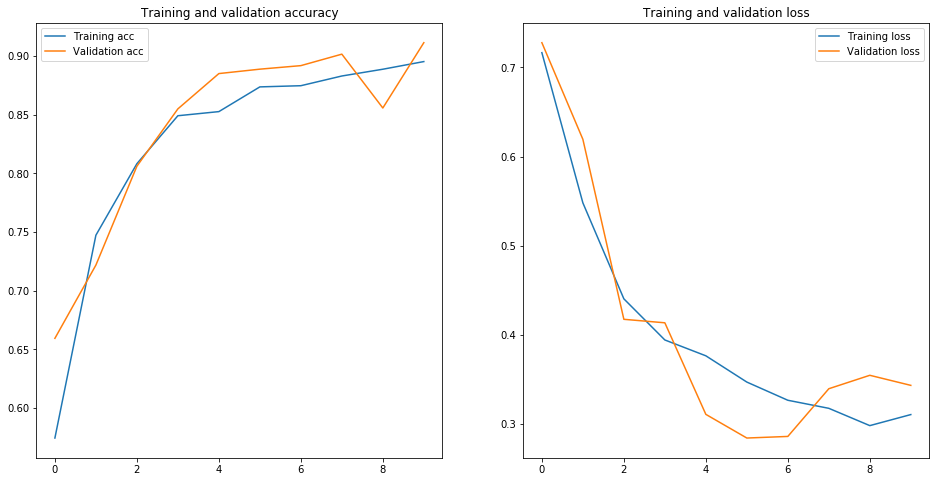
6.結果
5で学習した結果は以下になります。
X_train shape : (1994, 50, 50, 3)
X_test shape : (665, 50, 50, 3)
y_train shape : (1994,)
y_test shape : (665,)
Train on 1994 samples, validate on 665 samples
Epoch 1/10
1994/1994 [==============================] - 110s 55ms/step - loss: 0.7165 - acc: 0.5745 - val_loss: 0.7277 - val_acc: 0.6594
Epoch 2/10
1994/1994 [==============================] - 105s 53ms/step - loss: 0.5480 - acc: 0.7472 - val_loss: 0.6193 - val_acc: 0.7218
Epoch 3/10
1994/1994 [==============================] - 105s 52ms/step - loss: 0.4403 - acc: 0.8082 - val_loss: 0.4174 - val_acc: 0.8060
Epoch 4/10
1994/1994 [==============================] - 104s 52ms/step - loss: 0.3942 - acc: 0.8490 - val_loss: 0.4135 - val_acc: 0.8549
Epoch 5/10
1994/1994 [==============================] - 104s 52ms/step - loss: 0.3764 - acc: 0.8526 - val_loss: 0.3107 - val_acc: 0.8850
Epoch 6/10
1994/1994 [==============================] - 104s 52ms/step - loss: 0.3470 - acc: 0.8736 - val_loss: 0.2842 - val_acc: 0.8887
Epoch 7/10
1994/1994 [==============================] - 98s 49ms/step - loss: 0.3266 - acc: 0.8746 - val_loss: 0.2860 - val_acc: 0.8917
Epoch 8/10
1994/1994 [==============================] - 96s 48ms/step - loss: 0.3175 - acc: 0.8829 - val_loss: 0.3395 - val_acc: 0.9015
Epoch 9/10
1994/1994 [==============================] - 97s 48ms/step - loss: 0.2981 - acc: 0.8887 - val_loss: 0.3546 - val_acc: 0.8556
Epoch 10/10
1994/1994 [==============================] - 100s 50ms/step - loss: 0.3105 - acc: 0.8952 - val_loss: 0.3433 - val_acc: 0.9113
664/664 [==============================] - 9s 13ms/step
loss : 0.43196878160338803
accuracy : 0.8682228915662651
グラフを見る感じ過学習を起こしていないし、テストの正解率が0.86とまずまずの結果ではないか。
そこでブログ以外からとってきた画像をこのモデルに入れてみました。
def pred(X,weight):
model = build_model(X.shape[1:])
model.load_weights(weight)
pre = model.predict(X)
print(pre)
このような予測関数を作り、画像をnumpy形式のデータに変えこの関数に入れて予測しました。
入れた画像は事前に顔だけ抽出したものです。
[[1,0]]:乃木坂、[[0,1]]:欅坂です。
まずは欅坂の米谷さん
[[0.01458696 0.9813669 ]]
ちゃんと予測できてます。
次は 


この三人一気に行きます。
[[0.00759411 0.9891127 ]]
[[0.03383902 0.958 ]]
[[0.0257055 0.9657557]]
いい感じですね。
それでは次に乃木坂のメンバー




[[0.9261864 0.07003774]]
[[0.00831657 0.98940724]]
[[0.00709109 0.9909917 ]]
[[0.00154704 0.9977156 ]]
???????????????????????????????????????????????
全然ダメやないかい。
なんでやろうか。
そこで自分なりに原因を2つ考えてみました。
①そもそもグループ特有の顔の特徴がない?
特定の人を識別するときはその人の特徴が取り出せてそれをもとに識別できるけど、グループ全員を対象としているので、特有の特徴がなく顔以外の変なところを特徴として取り出され識別しているからダメな結果になってしまうのか。
②画像サイズの問題?
今回画像サイズを50にして学習をさせていたが、なぜ画像サイズを50にしたかというと乃木坂のブログ画像がすべて160×160に統一されていて、顔抽出の時だいたい30×30程度の大きさでしか顔を取り出せず、大きいサイズにリサイズするとかなりぼやけて自分の目でも誰か判断できないほどになってしまったからである。
このように50×50に画像をリサイズしているので、顔の細かい部分の特徴をうまくが取り出せずいいモデルにならなかったのかもしれない。
7.今後の課題
1度機械学習を試してみるということを目的にやったのでここで一度投稿させていただきます。
今回は残念ながら失敗に終わってしまいましたが、今後はどのようなデータを集めたらいいのか、どのようにパラメータ設定をすればいい精度のものが得られるのかなどまだまだ勉強の余地が多くあるので引き続き勉強していきたいと思います。
また今回の失敗を活かして次は単純にメンバーを3人ほどに絞って顔識別AIをつくって見たいと思います。
8.まとめ
実は5カ月前にAidemyで「ディープラーニングで画像認識モデルを作ってみよう!」のコースをを1通り受講していたのですが、その講座を思い出しながら今回ようやくoutputまで結びつけることができました。いままで自分で何か作ってやろうというモチベーションがなく講座受講するだけ、専門書読むだけのinput人間でしたが、outputしてみて理解が深まったりするのでoutputの重要性を実感することができました。今後もoutputを意識して、いろいろと作っていきたいと思います。
最後までお読みいただきありがとうございました。
※記事の改善、アドバイスなどございましたらご指摘いただけると幸いです。