Lambdaを使わずにS3にPutされたCSVファイルをRDSに自動一括登録する


はじめに
サーバーレス開発部@大阪の岩田です。
現在従事しているプロジェクトで、S3へのCSVファイルのPutをトリガーにCSVファイルの中身をRDSに一括登録したいという要件がありました。 S3へのPutをトリガーにLambdaを起動して〜というアーキテクチャはサーバーレス開発の定番ですがRDSへの一括登録となると話が変わってきます。 Lambdaの実行時間や、RDSへの同時接続数といった制限を意識しなくてはいけません。
実現方法としてCloudWatch Eventsのルールを使用してAWS Batchを起動する構成について調査したので、手順をご紹介します。
構成概要
今回ご紹介する構成は、下記のような構成です。

下記のエントリでも紹介されているように、2018年3月のアップデートにより、CloudWatch EventsをトリガーにAWS Batchのジョブが起動できるようになっています。 この機能を使用して環境を構築していきます。
注意点としては、
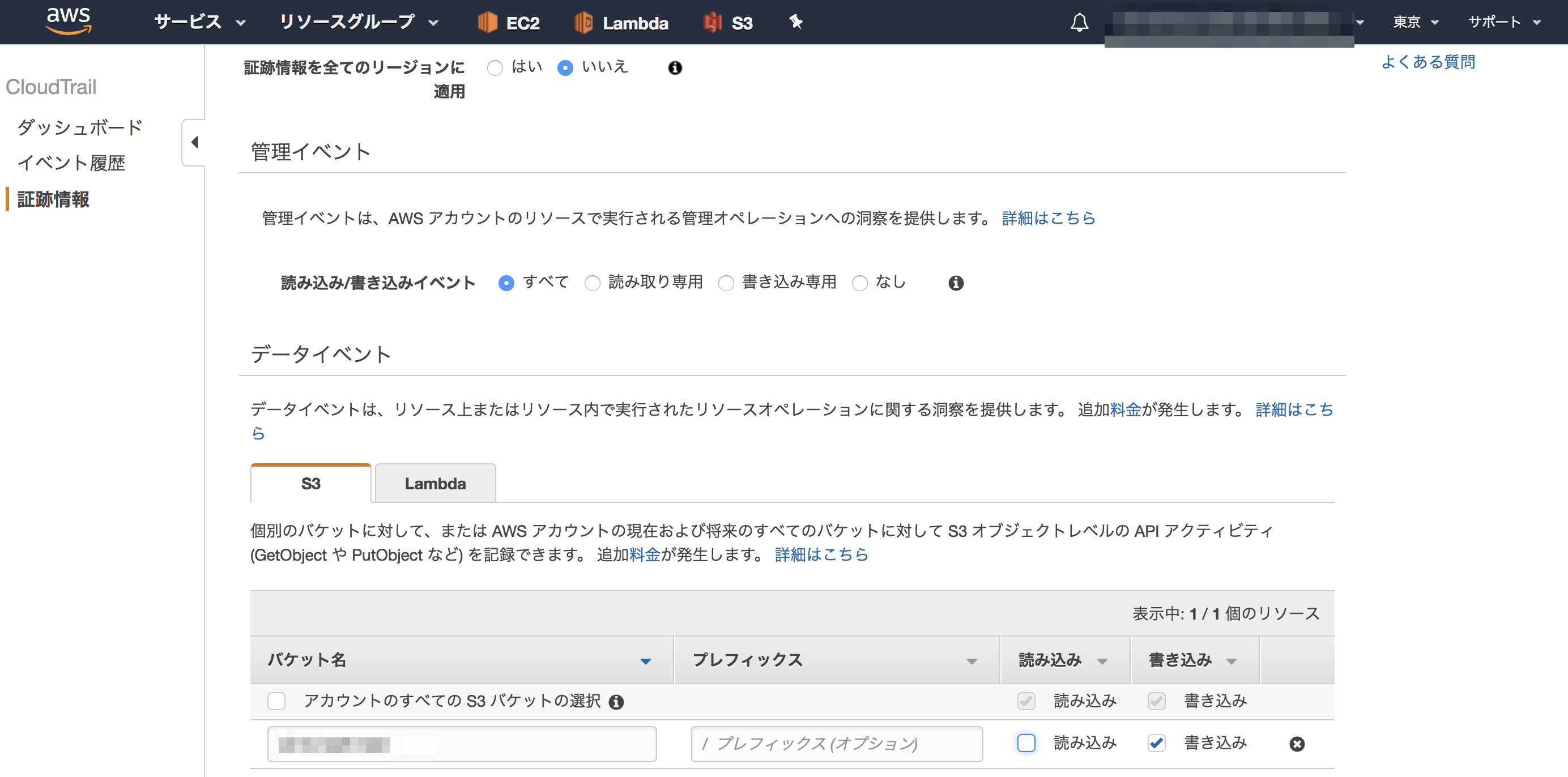
- 対象のS3バケットにCloudTrailを有効化しておくこと
- S3バケット、CloudTrail、AWS Batch全てのリソースを同一リージョンに作成していること
が挙げられます。
設定手順
実際に設定を行なっていきます。
S3バケットの作成とCloudTrailの有効化
まずは検証用のS3バケットを作成します
1 | aws s3 mb s3://<対象のバケット名> |
バケットが作成できたら、CloudTrailを有効化します。 前述のようにS3へのアクションをCloudWatch Eventとして受け取るためには対象のS3バケットにCloudTrailを設定する必要があるためです。
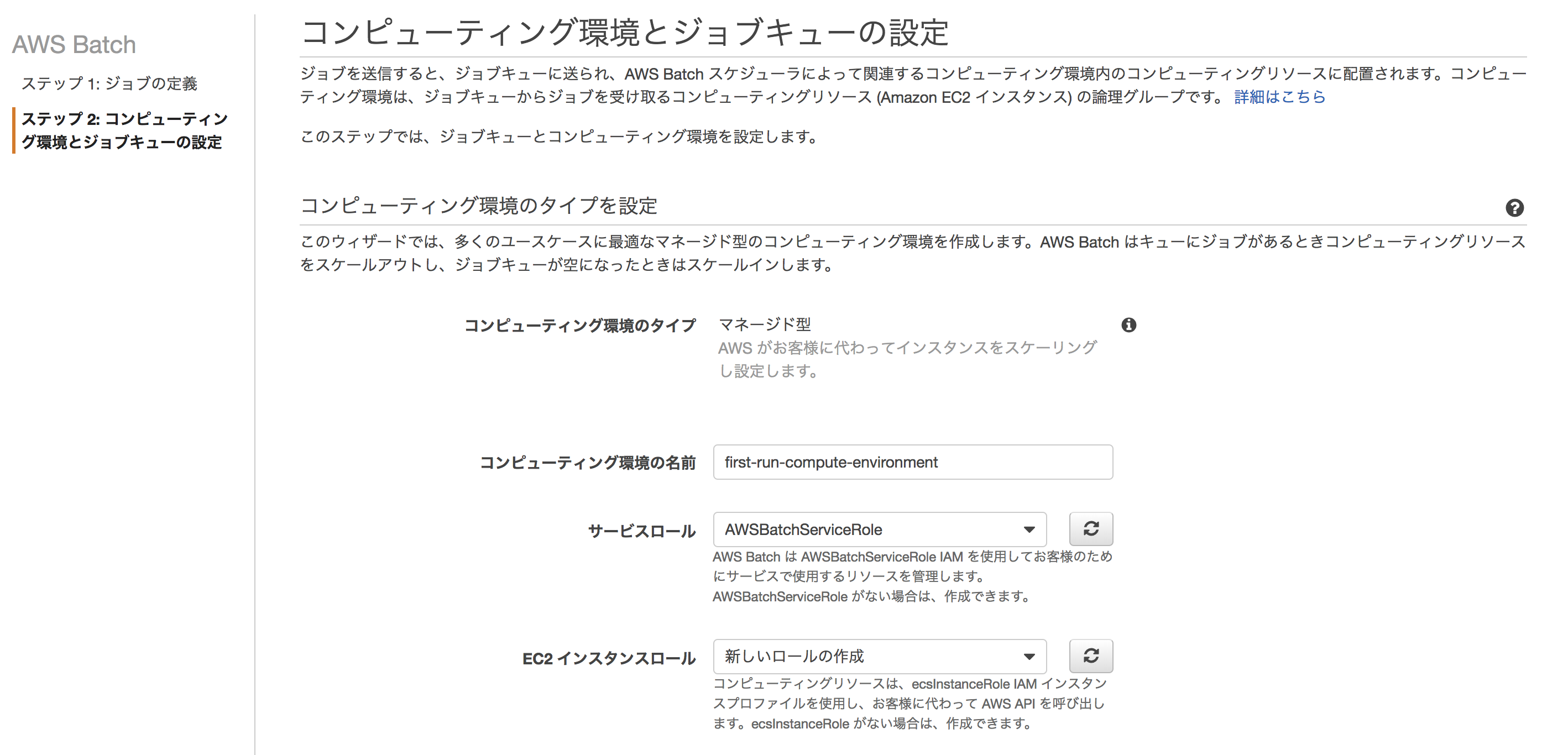
AWS Batchのジョブキュー作成
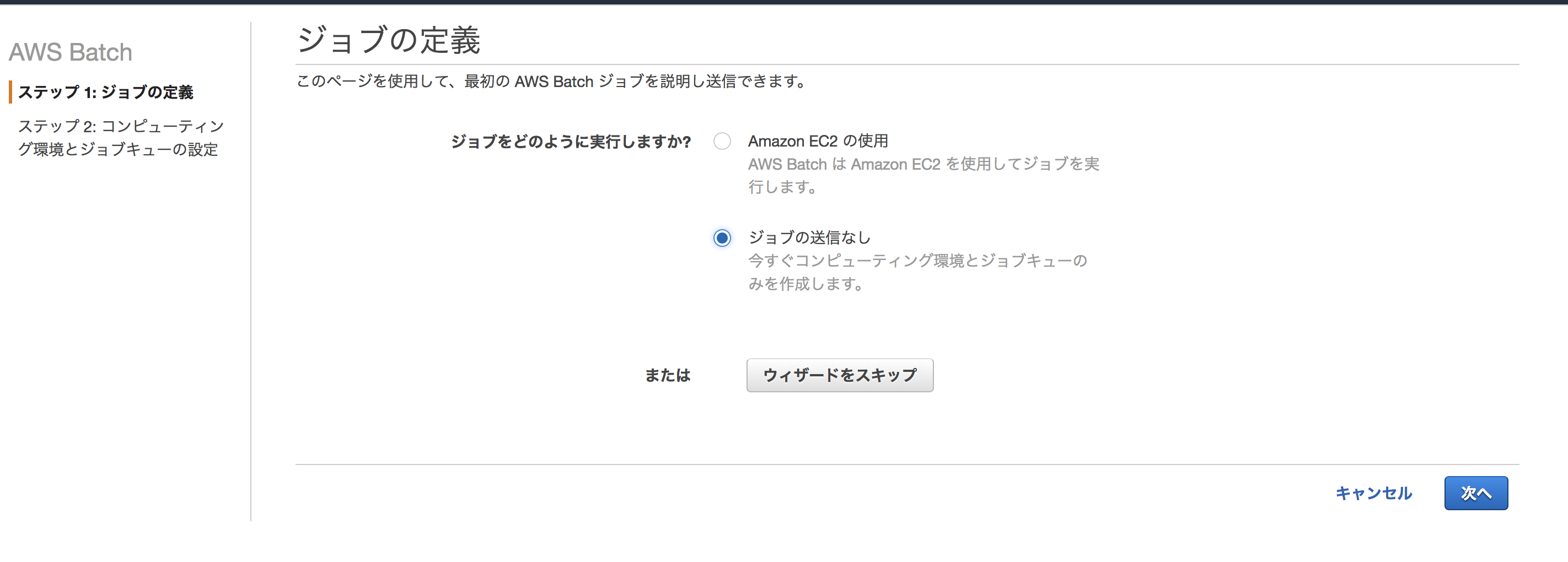
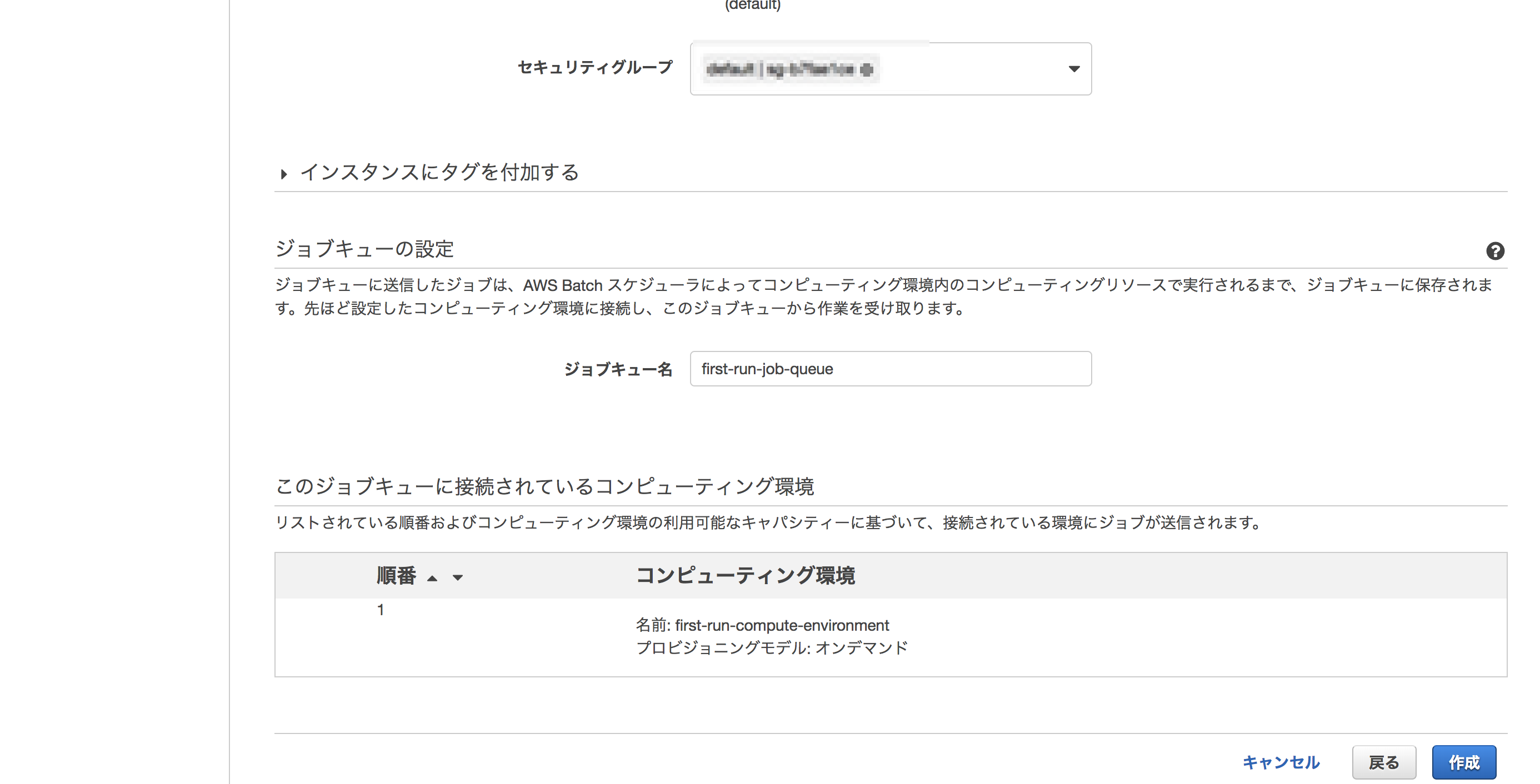
次にAWS Batchのジョブキューを作成します。 ウィザードに従って、デフォルトの設定でポチポチと進めていきます。
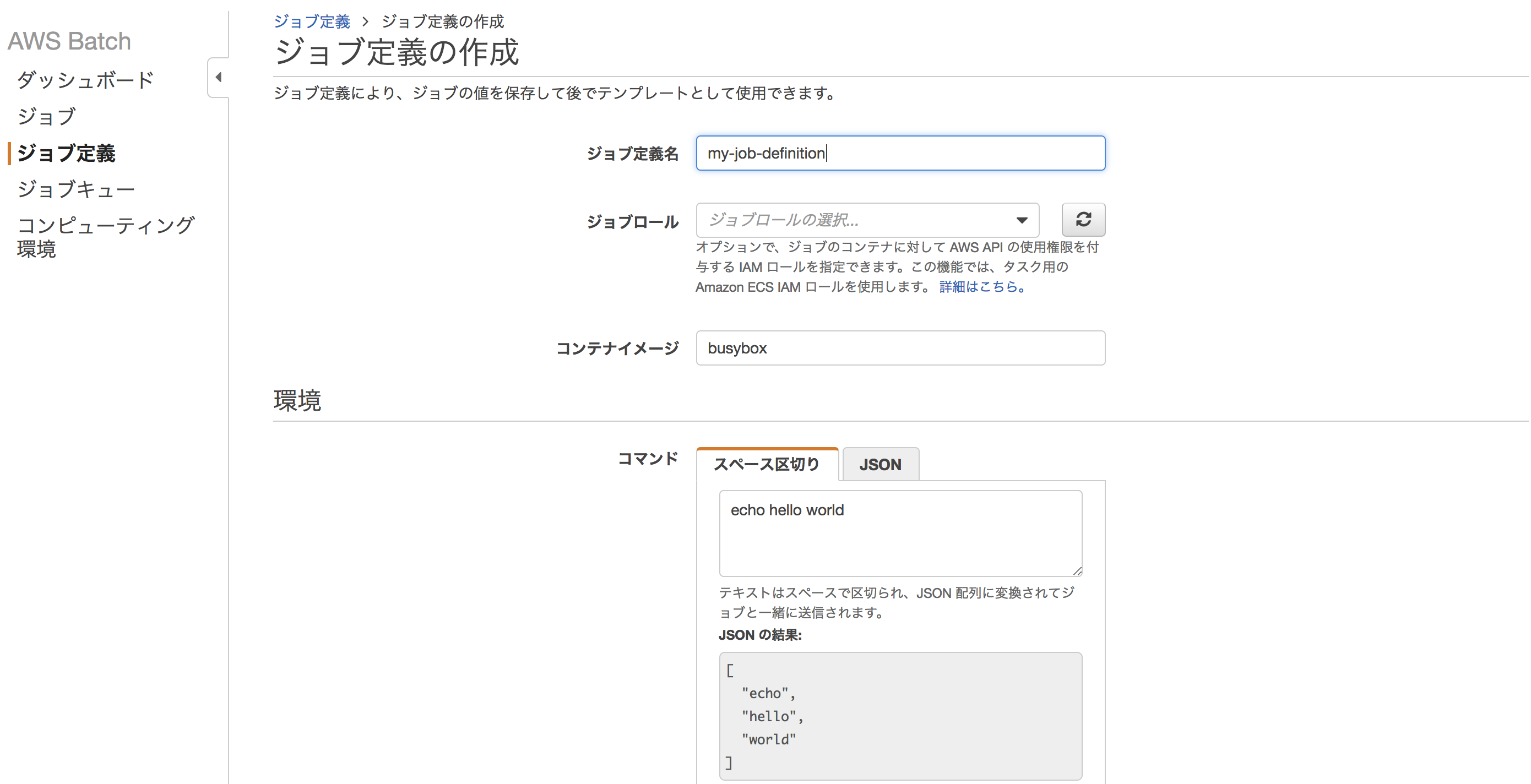
ジョブ定義の作成
ジョブキューが作成できたら、次はジョブ定義の作成です。
まずは定番のhello worldからはじめてみましょう。
hello worldとechoするだけの簡単なジョブを設定しています。
Cloud Watchのルール作成
AWS Batchの方が設定できたので、Cloud Watchイベントのルールを作成し、S3へのPutObjectをトリガーにAWS Batchのジョブを起動するよう設定します。
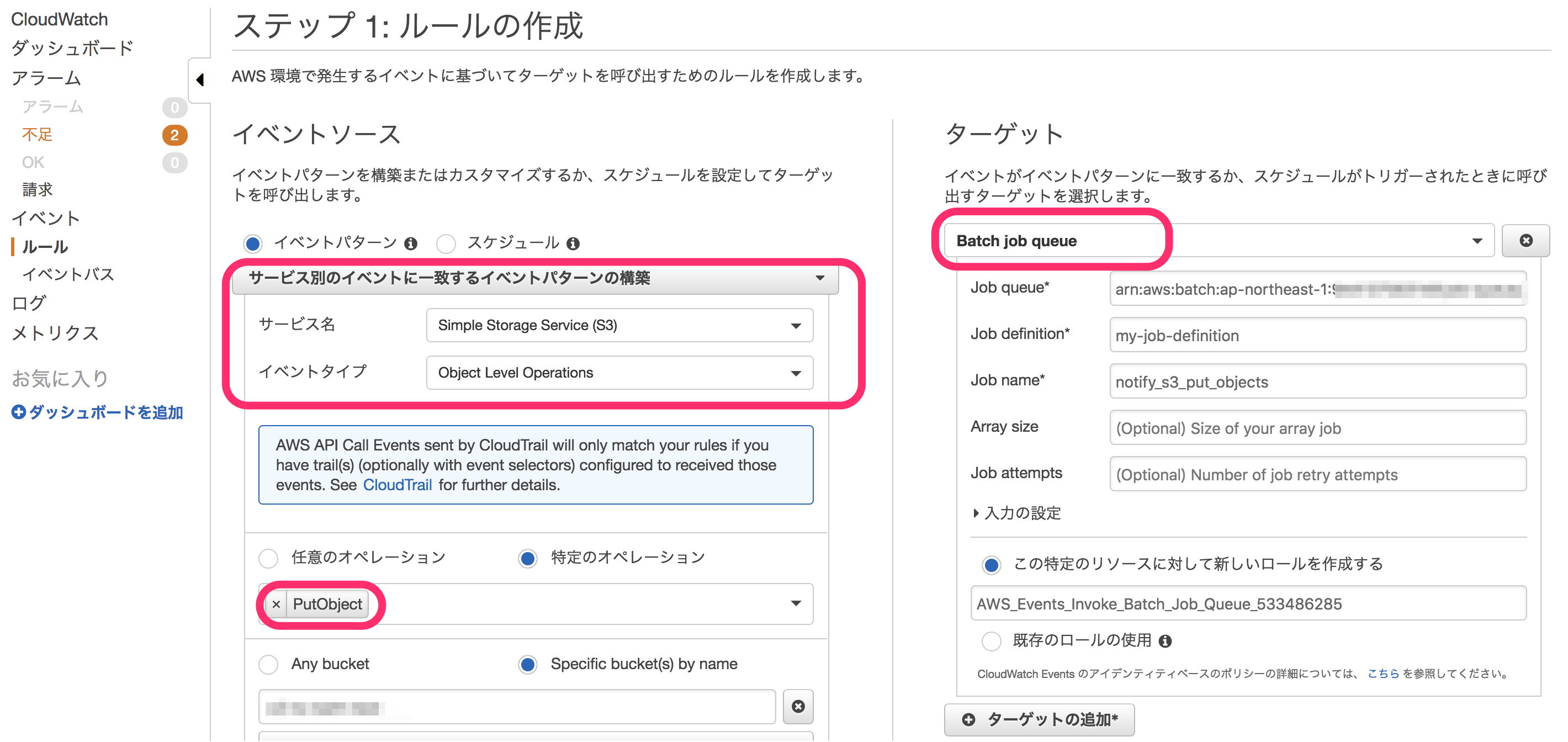
イベントソースに対象のS3バケットへのPutObjectを指定、ターゲットには先ほど作成したAWS Batchのジョブ定義を指定しています。
S3へのPutを試してみる
一通り設定ができたので、実際に動作確認してみましょう。 対象のS3バケットに適当にファイルをPutしてみます。
1 | aws s3 cp test.txt s3://<対象のバケット名> |
Cloud WatchLogsのログを確認
Cloud WatchLogsをのログを確認してみます。
AWS Batchのログは、ロググループ/aws/batch/jobの配下に出力されていきます。

hello worldと出力されています!! S3へのPutObjectをトリガーに、AWS Batchのジョブ実行まで、うまく流れていそうです。
Cloud Watchイベントの設定修正
ここまでで、S3へのPutObjectと連動してAWS Batchのジョブを実行するところまで成功しましたが、実際にCSVファイルをRDSに登録するには、ジョブに対してバケット名とオブジェクトキーを渡してやる必要があります。 CloudWatchのインプットトランスフォーマーという機能を使用して、ジョブにバケット名とオブジェクトキーを渡せるように設定してみます。
先ほど作成したCloud Watchイベントのルールを編集し、インプットトランスフォーマーの入力パスに
1 | {"S3BucketValue":"$.detail.requestParameters.bucketName","S3KeyValue":"$.detail.requestParameters.key"} |
と、入力テンプレートに
1 | {"Parameters" : {"S3bucket": <S3BucketValue>, "S3key": <S3KeyValue>}} |
と設定します。
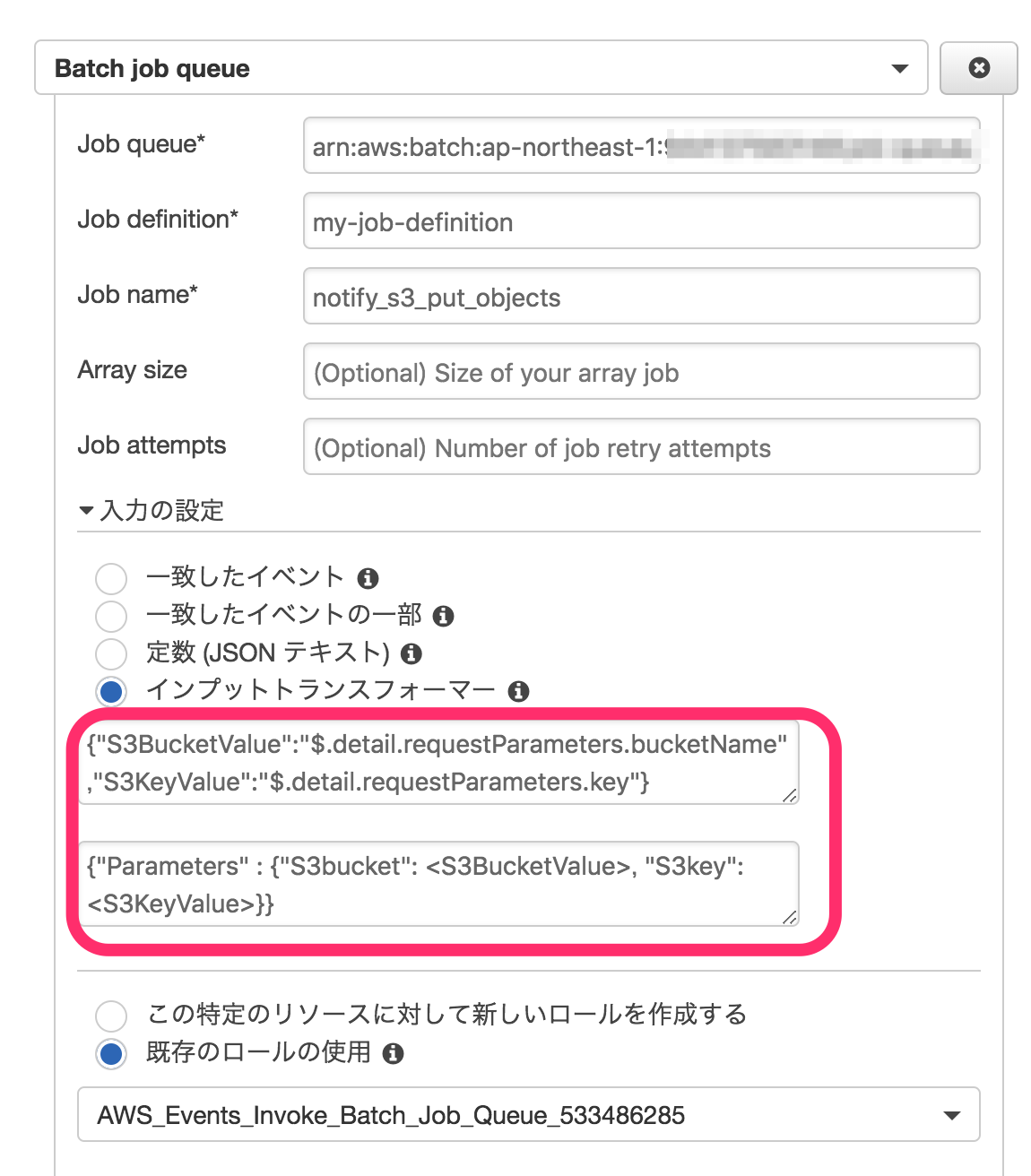
これでAWS Batchのジョブ定義からS3bucket、S3keyという名前のパラメータが参照できるようになりました。
ジョブ定義を修正
次にAWS Batchのジョブ定義を修正し、パラメータで渡されたS3バケット名とオブジェクトキーをechoするよう設定してみます。
ジョブ定義に渡されたパラメータはRef::<パラメータ名>と指定することで参照できるので、ジョブ定義を下記のように修正します。
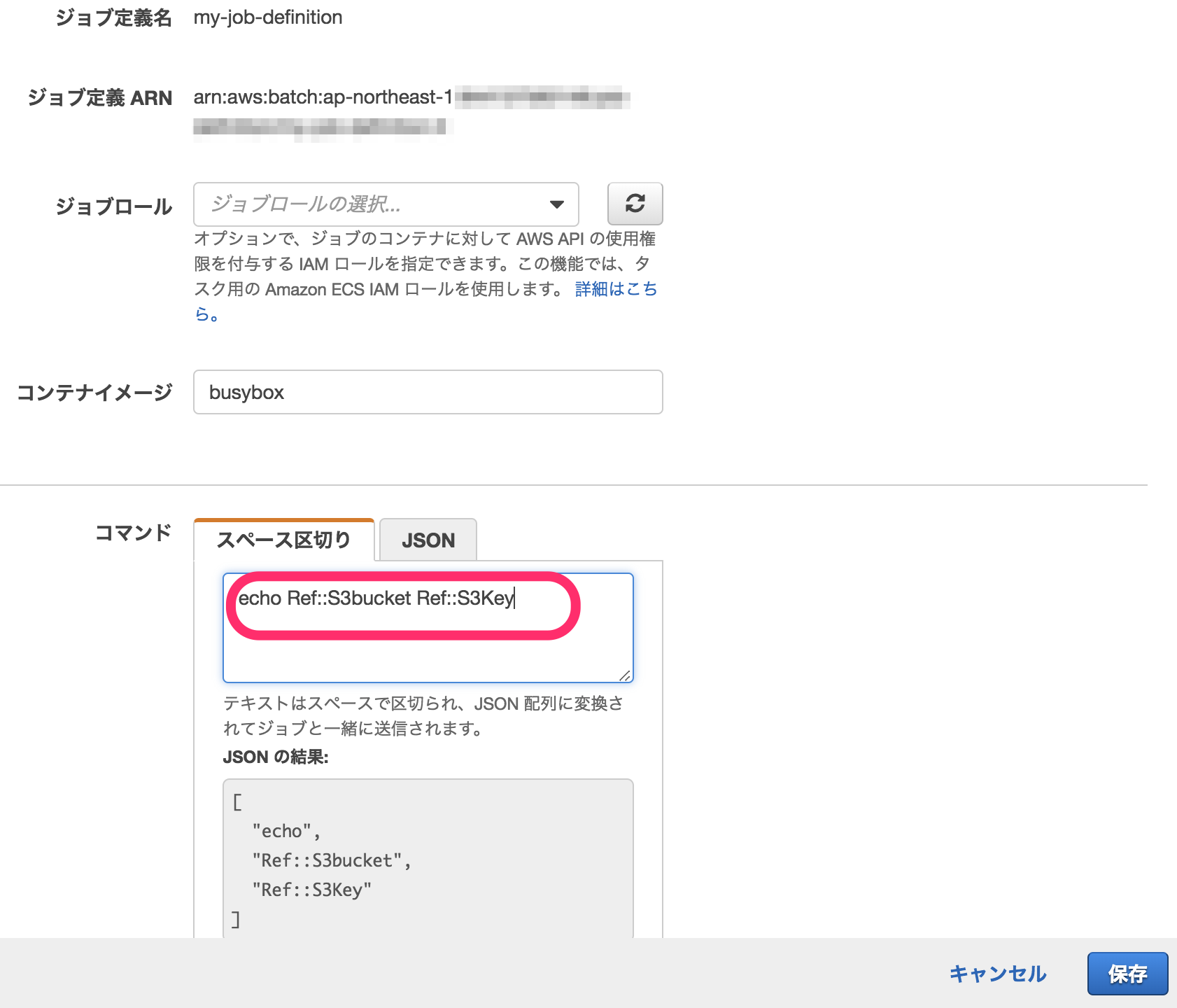
再確認
1 | aws s3 cp test.txt s3://<対象のバケット名> |
再度適当なファイルをPutし、Cloud WatchLogsをのログを確認してみます。

バケット名、オブジェクトキーがログに出力されています。 この要領でバケット名、オブジェクトキーを引数に取り、CSVファイルをRDSに取り込むプログラムを実装すれば自動一括登録の環境構築完了です。
まとめ
Cloud Watchのイベントを使用して、AWS Batchのジョブを実行する方法について見てきました。 AWS Batchを利用することでLambdaの実行時間や、RDSへの同時接続数といった制限から解放されるため、CSVファイルの一括登録のようなユースケースではAWS Batchが有効な選択肢になるのではないでしょうか?
誰かの参考になれば幸いです。
参考
