
概要
大井競馬場に行く機会があったので、機械学習を使って競馬の結果を予測できるかをやってみました。
その結果、帝王賞で一位を当てることができたので、記事を書きます。
かなり適当な予測なので、遊びとして見てもらえたらと思います。
証拠
当たったという証拠に、記念でとった馬券画像。
機械学習で予測したものと、パドックを見て予測したものと、2つ買いました。
(びびって複勝、しかも300円)

問題の設定
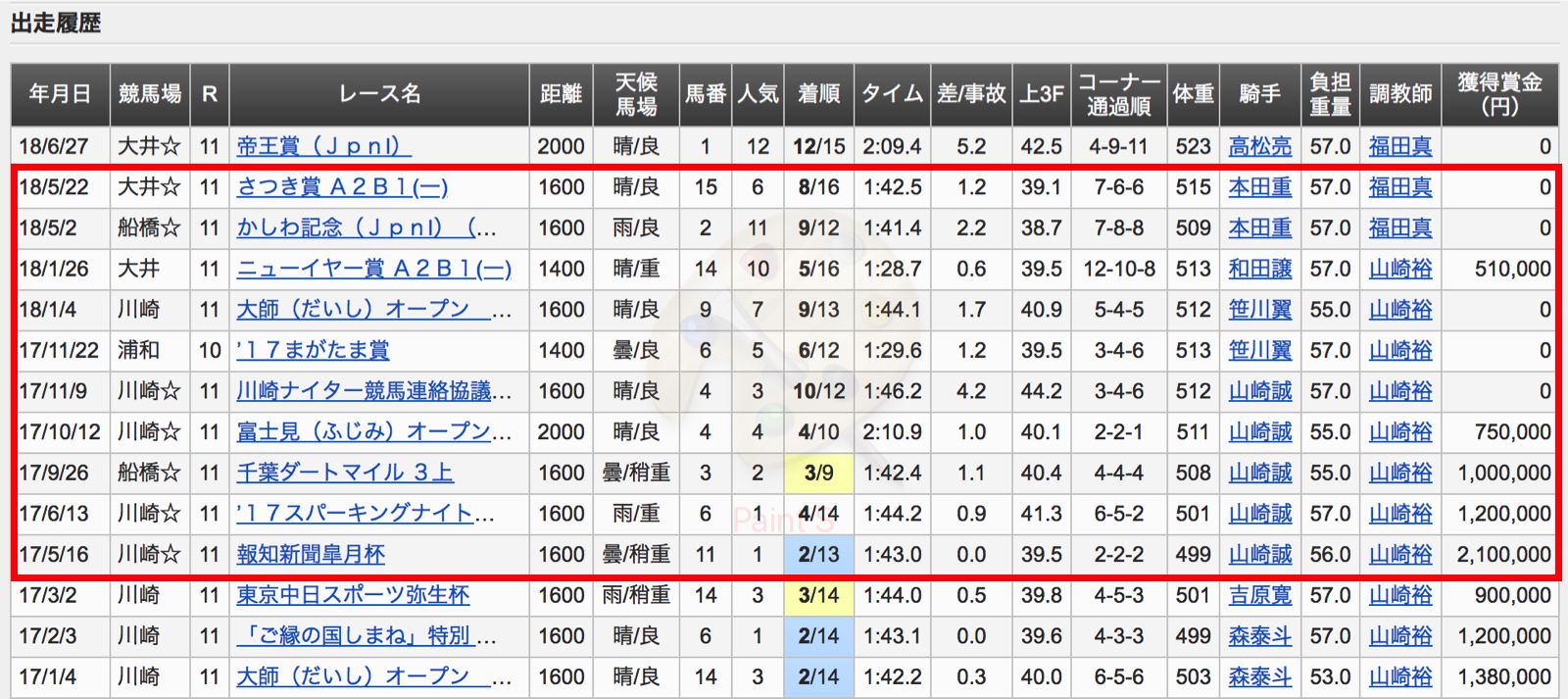
大井競馬場で行われる帝王賞の1位のみを当てます。
競馬には、色々な馬券の買い方がありますが、今回は簡単でシンプルな問題設定としたかったので、1位のみを予測することにしました。
データの取得
教師あり学習を行うので、過去の競馬結果のデータが必要です。
こちらのサイトからデータをクローリングしました。
南関東4競馬場公式ウェブサイト
レース情報のページから、レースに出る馬の過去情報があるページへのリンクを取得し、そのリンク先のページから直近10レース、その馬がどのようなレース結果だったのかを取得します。
レースページは2018年に大井競馬場で行われたレースのみに絞りました。
スクレイピングにはPythonのライブラリBeautifulSoupを使いました。
import requests
from bs4 import BeautifulSoup
def url_to_soup(url):
req = requests.get(url)
return BeautifulSoup(req.content, 'html.parser')
各馬の過去情報があるページへのリンク取得

def horse_page_link(url):
soup = url_to_soup(url)
link_list = [HOME_URL + x.get('href') for x in soup.find_all('a', class_='tx-mid tx-low') ]
return link_list
各馬の過去情報取得(feature用)
年月日と、レース当日の日付を比べて、当日より前の情報だけを学習用の特徴量として取得します。
tag_to_text = lambda x: p.sub("", x).split('\n')
split_tr = lambda x: str(x).split('</tr>')
def get_previous_race_row(soup):
race_table = soup.select("table.tb01")[2]
return [tag_to_text(x) for x in split_tr(race_table)]
def horse_data(url, race_date):
soup = url_to_soup(url)
# 過去のレースデータ
pre_race_data = get_previous_race_row(soup)
df = pd.DataFrame(pre_race_data)[1:][[2,3,10,11,13,14,15,19,23]].dropna().rename(columns={
2:'date', 3:'place', 10:'len', 11:'wether', 13:'popularity', 14:'rank', 15:'time',19:'weight',23:'money'})
return df
レースの結果を取得
当日の1位の情報を正解ラベルとして取得します。
また、当日の土の状態、レースの長さ、レースの日付を特徴量を編集する用に取得します。
def result_data(url):
soup = url_to_soup(url)
# 土の状態
condition = soup.find(id="race-data02").get_text().replace('\n','').split(';')[1].split(' ')[2][0:1]
# レースの長さ
race_len = int(soup.find(id="race-data01-a").get_text().replace('\n','').split(' ')[3].replace(',','')[1:5])
# 1位
hukusyo_list = []
hukusyo_list.append(int(p.sub("", str(soup.find_all('tr', class_='bg-1chaku')[0]).split('</td>')[2]).replace('\n','') ))
# レース日
race_date_str = soup.find(id="race-data01-a").get_text().replace('\n','').split(';')[0].split('日')[0]
race_date = dt.strptime(race_date_str, '%Y年%m月%d')
return hukusyo_list, condition, race_len, race_date
前処理
取得したデータから、データセットを作成します。
DataFrameのcolumnsは以下の通りです。
| column | |
|---|---|
| horse_cnt | 頭数 |
| money | 獲得賞金金額 |
| result_rank | 順位 |
| len | レースの長さ |
| popularity | 人気 |
| weight | 体重 |
| sec | タイム(秒) |
| same_place | 大井競馬場かどうか |
| soil_heavy | 馬場状態が重 |
| soil_s_heavy | 馬場状態が稍重 |
| soil_good | 馬場状態が良 |
| soil_bad | 馬場状態が不良 |
def add_soil_columns(row):
row['soil_heavy'] = 1 if row['wether'][-2:] =='/重' else 0
row['soil_s_heavy'] = 1 if row['wether'][-2:] =='稍重' else 0
row['soil_good'] = 1 if row['wether'][-2:] =='/良' else 0
row['soil_bad'] = 1 if row['wether'][-2:] =='不良' else 0
return row
def add_race_data(df):
df_ =pd.DataFrame()
for idx, row in df.iterrows():
if row['popularity'] == '':
continue
# 馬場状態
row = add_soil_columns(row)
row['money']=int(row['money'].replace(',',''))
row['horse_cnt'] = int(row['rank'].split('/')[1])
row['result_rank'] = int(row['rank'].split('/')[0])
row['len'] = int(row['len'][0:4])
row['popularity'] = int(row['popularity'])
row['weight'] = int(row['weight'])
# 競馬場の一致
row['same_place'] = 1 if row['place'].startswith(PLACE) else 0
# タイム(秒)
try:
time = datetime.datetime.strptime(row['time'], '%M:%S.%f')
row['sec'] = time.minute*60 + time.second + time.microsecond/1000000
except ValueError:
time = datetime.datetime.strptime(row['time'], '%S.%f')
row['sec'] = time.second + time.microsecond/1000000
row['sec'] = int(row['sec'])
df_ = df_.append(row, ignore_index=True)
return df_
出力結果
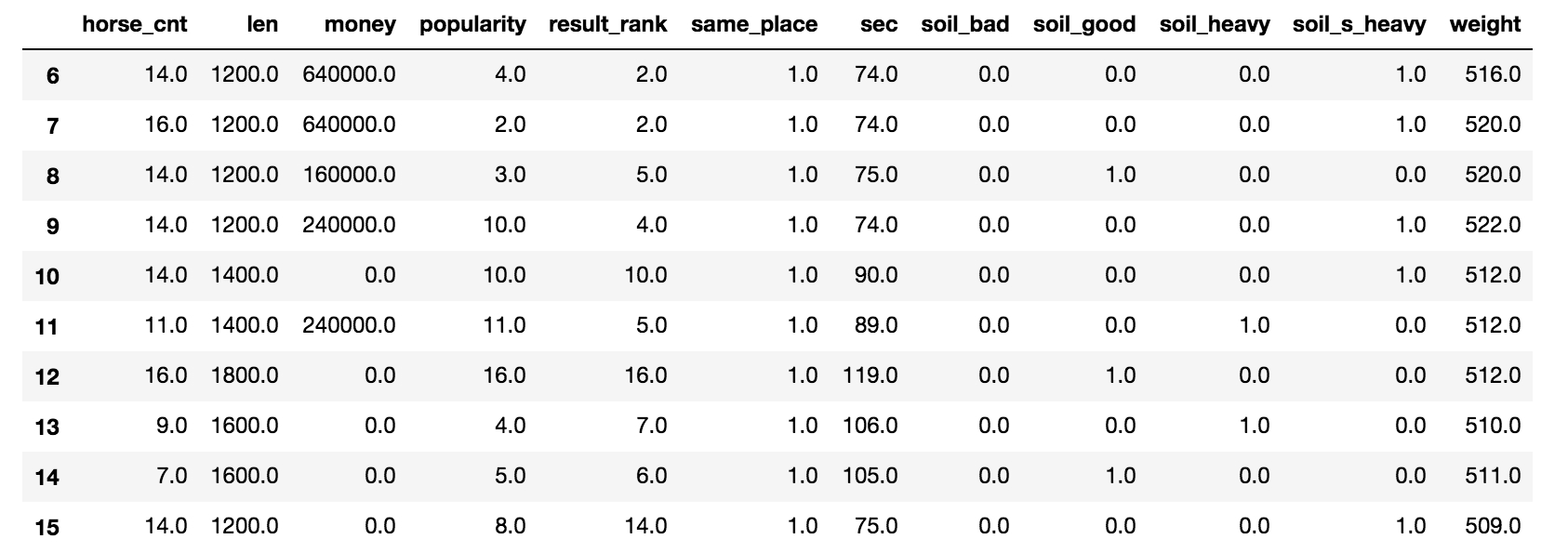
各馬の直近10レースのデータを取得しますが、10レースも出場していない馬もいます。その場合は、足りない行を全てゼロ埋めにしました。
また、lenは、当日のレースの距離との差分に変換し、soilは当日と同じcolumnだけを残した。
そのため、最終的な特徴量は9つです。
| column | |
|---|---|
| horse_cnt | 頭数 |
| money | 獲得賞金金額 |
| result_rank | 順位 |
| len | 当日のレースの長さとの差 |
| popularity | 人気 |
| weight | 体重 |
| sec | タイム(秒) |
| same_place | 大井競馬場かどうか |
| soil_heavy | 馬場状態が当日と同じか |
予測 MLP
一番簡単なMLPをkerasで実装。
MLP 実装
inputは、各馬の直近10レースの結果「9(特徴量) * 10(レース)」を15頭分のflattenデータ(shape: 1350)です。
ただし、15頭に満たない場合は、0埋め、15頭より多い場合は、切り捨ててしまってます。。。
(大井競馬場はどの距離もフルゲートが16なので、16に合わせればよかったと後悔。クローリング後に調べたら、16番目の馬が1位になったレースはありませんでした。)
隠れ層がノード数128の全結合の全3層です。
前処理に、各インプットを0~1の範囲になるよう正規化しました。
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import Adam
from keras.layers.normalization import BatchNormalization
model = Sequential()
model.add(Dense(1350, activation='relu', input_dim=1350))
model.add(Dropout(0.8))
model.add(BatchNormalization())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(15, activation='softmax'))
adam = Adam()
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=100, batch_size=50, validation_split=0.1)
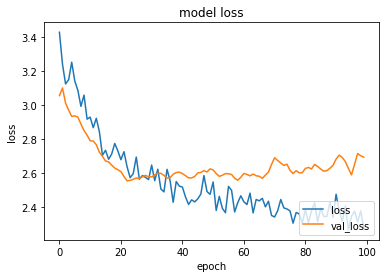
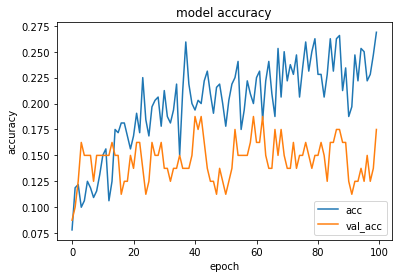
MLP 結果
30~40epochあたりから、過学習してたので、実際に利用したモデルは40epochで学習を止めたものです。
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy = {:.2f}".format(accuracy))
結果
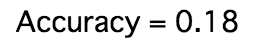
15頭のレースでランダムに選択すると、当たる確率は、0.0666...なので、それよりは少しいいですね。
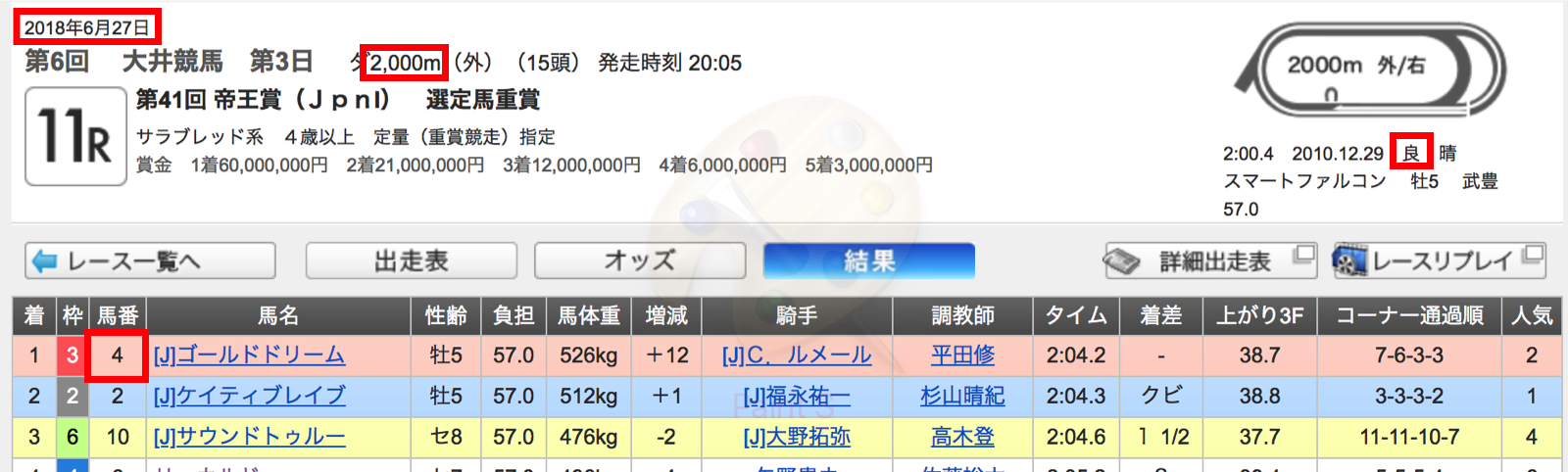
帝王賞の予測
実際に学習したモデルで、帝王賞を予測しました。
def get_verification_data(race_page, today_condition, race_len, race_date_str):
race_date = dt.strptime(race_date_str, '%Y/%m/%d')
df_horses_data = horses_data(race_page, race_date)
hourse_data = preprocessing(df_horses_data, today_condition, race_len)
X, df_X = reshape_X_data(hourse_data)
return X
def pred(X):
score = list(model.predict(X.reshape(1,1350))[0])
result = pd.DataFrame([], columns=['num','score'])
result['score'] = score
result['num'] = list(range(1,16))
display(result.sort_values(by='score', ascending=False))
X = get_verification_data(race_page='https://www.nankankeiba.com/race_info/2018062720060311.do',
today_condition='良',
race_len=2000,
race_date_str='2018/6/27')
pred(X)
結果
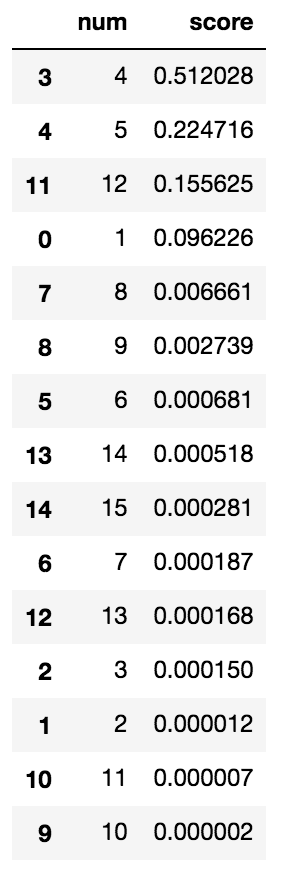
numのカラムが馬番なので、4番のゴールドドリームが一番との予測が出たので4番を買いました!
単勝のあたり馬券を買える確率をあげる
kerasのscoreはsoftmaxの出力なので、確率として考えることができます。なので、帝王賞でゴールドドリームが1番だという確率は51%と表されています。
予測結果のスコアが均衡しているレースは、予測が困難だとも言えます。1位予測のスコアが何%だったかを調べることで、1位を当てる確率をあげることができるのではないかと仮説を立てました。
def get_prediction(X, y):
score = list(model.predict(X.reshape(1,1350))[0])
result = pd.DataFrame([], columns=['num','score'])
result['score'] = score
result['num'] = list(range(1,16))
df_result = result.sort_values(by='score', ascending=False).iloc[0]
df_result['true'] = np.where(y == 1)[0][0] + 1
return df_result
df = pd.DataFrame()
for i in range(len(X_test)):
df_result = get_prediction(X_test[i], y_test[i])
df = df.append(df_result, ignore_index=True)
df['correct'] = df.apply(lambda x: 1 if x['num'] == x['true'] else 0, axis=1)
for v in range(0, 10):
l_score = v / 10
acc = len(df[(df['score']>l_score) &(df['correct']==1)]) / len(df[(df['score']>l_score)])
print('score: {} 以上 -> 正解率 : {}'.format(l_score, acc))
結果
一位のスコアが・・・
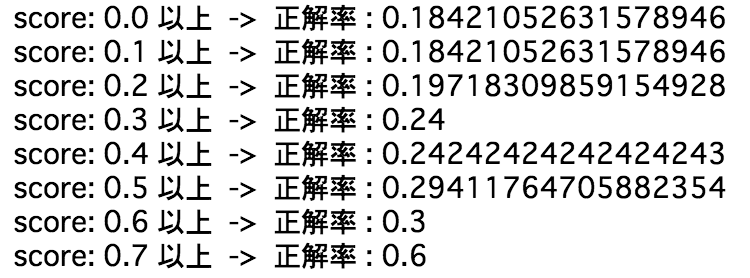
テストデータは77件で少ないのですが、一応、仮説通りスコアが高ければ、正解率も上がってます!
(今回のテストデータでは、スコアが0.8以上のデータは0件でした。)
スコアが0.5以上だと、3割あたると言えそうですね。
モデル自体の精度向上とは違いますが、馬券を買う・買わないの選択も含めて、買う馬券の当たる確率をあげる方法の一つとして、スコアの値は使えそうです!
第20回 ジャパンダートダービー 選定馬重賞
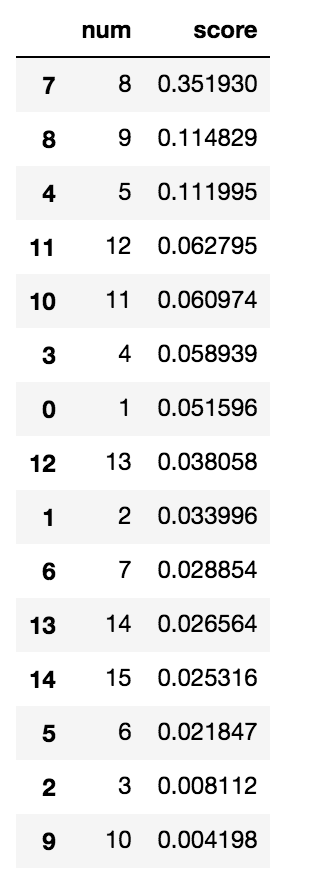
ちなみに、明日(2018/7/11)、大井競馬場で開催のジャパンダートダービーを同じモデルで予測したら、ドンフォルティスでした!!
どうでしょう笑?
X = get_verification_data(race_page='https://www.nankankeiba.com/race_info/2018071120070311.do',
today_condition='良',
race_len=2000,
race_date_str='2018/7/11')
pred(X)
結果
今後の改良
1レース16頭の前提でデータを作る
大井競馬場のフルゲートが15だと思っていたので、16という前提でデータを作り直したいです。
過去データをもっと集める
今回、時間がなかったので、2018年より前のデータをクローリングしませんでした。
ちゃんと時間を確保して、もっと前のデータも集めて学習データの量を増やしたいです。
血統データを入れる
特徴量に、馬の母・父・母父のデータを入れたいと思っているのですが、ダミー変数で入れると、横に大量のカラムを持つ必要があるので、ちょっと現実的じゃないかなぁ・・・と思いつつ、どうにかして入れたいと思ってます。
ジョッキーのデータを入れる
これも、血統データと同じく、ジョッキーのダミー変数を入れると、横に大量のカラムが必要ですね。
昼間開催orナイター情報を入れる
夜に強い馬とかいるのかなぁ、という仮説のもと、昼間開催かナイターかの情報を入れたいです。これは比較的簡単にできそう。
回収率をあげる
どんなに予測が当たっても、人気の馬ばかり予測していたら回収率が下がるので、予測結果の確率と払戻金を合わせた数値で、回収率向上をはかりたいです。
おわり
Kaggleなどのコンペもとても面白いですが、競馬データも機械学習の勉強になかなか適しているのではないでしょうか?実際に現金でリターンがあるのも、モチベーションの一つですね![]()
明日のダービーも予測が当たるか楽しみです!!