
Apache Spark縛りでKaggleのコンペティションやってみた #Spark
★ 3

こんにちは。木内です。
今回はデータサイエンティストのコンペティションサイトとして有名な kaggle に Apache Spark で挑戦してみたいと思います。
使っている方は知ってはいるのですが、実は kaggle では Apache Spark を使用している人はあまり多くありません。日本でも kaggle の例を見てみると、Python+numpy+pandas+scikit-learn(+TensorFlow)という組み合わせで挑戦している方が多数です。
今回の記事はあえてApache Spark縛りで kaggle のコンペティションに参加してみて、実際 Pandas/numpy/scikit-learnでやっていることをApache Sparkに置き換えることができるのか、置き換えるとしたらどうするのか、というところに着目し、実際に結果を投稿するところまでやってみたいと思います。
Apache Sparkを利用するメリットとしては、処理するPCが比較的大きくなくても、大きなデータセットを扱うことができる点です。つまり時間をかけても構わないのであれば、クラスタ構成でした処理できないような大規模データを手元のパソコンで処理することができるようになります。もちろんクラスタ構成で Apache Spark を使用すれば処理ノード数に応じた性能の向上を期待することができます。
もちろん kaggle のコンペティションは処理速度だけではなく機械学習アルゴリズムそのものの性能や、以下にデータから特徴を引き出せるかによって順位に大きな変動が出るため、Apache Spark で大きなデータセットを扱うことや処理性能を向上させることと Kaggle で competitve かどうかは別の話です。あしからず。
でははじめましょう。
参考にしたサイト
ここでは Qiita の "Kaggleの練習問題(Regression)を解いてKagglerになる" : https://qiita.com/katsu1110/items/a1c3185fec39e5629bcb を参考に、できるだけ Apache Spark の機能を使って同じことをすることにします。
従って行うコンペティションは練習用の "House Prices: Advanced Regression Techniques" とします。処理用のデータセットは予め手元にダウンロードしておきます。
データのロード、表示
Pandas では CSV データのロードは非常にかんたんで、 "read_csv" を呼ぶだけです。読み込んだ CSV は Pandas の Dataframe になります。
import pandas as pd
df = pd.read_csv("train.csv.gz")
Apache Spark は少し前までは CSV の読み込みを標準でサポートしていなかったのですが、最近ではそのまま読み込むことができます。以下のようにすれば CSV ファイルを読み込み、Apache Spark の Dataframe になります。
python
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").getOrCreate()
# CSVのデータファイルを読み込み
df = spark.read.format("csv") \
.options(header="true", \
nanValue="NA", \
nullValue="NA", \
inferSchema=True) \
.load("train.csv.gz")
Jupyter Notebook(あるいはJupyterLab) を使用している場合、Pandas Dataframeの表示は非常にかんたんです。きれいな表で表示され、列の数が多い場合でも適宜省略したり、スクロールして内容をかんたんに把握することができます。
from IPython.core.display import display
display(df.head(5))

Apache Spark では Dataframe の "show()" メソッドで表示することができるのですが、全てテキストで表示されてしまうため、列の数が多くなると内容の確認がやりづらくなってしまいます。これではデータの確認だけでげんなりしてしまいそうです。
df.show(5)

分析においてはデータの状況をざっと見ることができることも重要な点です。しかしこれではざっと内容を確認することが難しく、実用には適しません。そこで Spark Dataframe の内容を Pandas Dataframe に変換して表示するように、お助け関数を作成します。
def printDf(sprkDF):
# format Spark Dataframe like pandas dataframe
# sparkのdataframeをpandasのdataframeのように整形して出力する
newdf = sprkDF.toPandas()
from IPython.core.display import display, HTML
return HTML(newdf.to_html())
display(printDf(df.limit(5)))
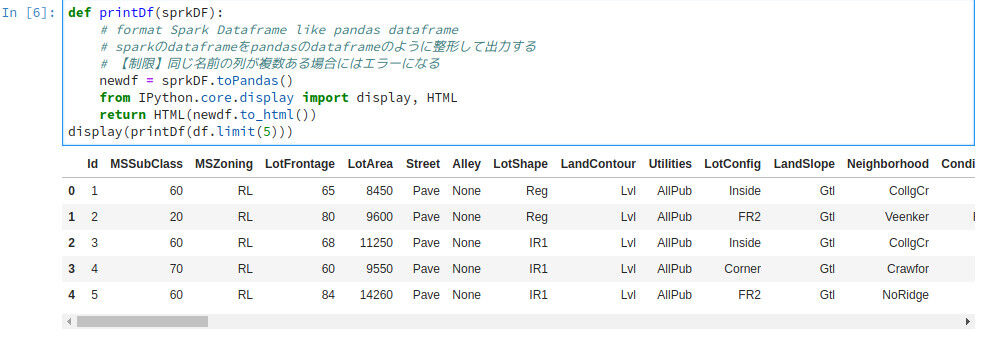
これでだいぶ見やすくなりました!データも見やすくなり、やる気が出てきますね!
ラベルエンコーディング
次は文字列で構成されている列を機械学習アルゴリズムに与えやすいよう数字に置き換えます。
scikit-learn の "LabelEncoder" ライブラリは文字列で構成されたカラムを読み込み、数値に置き換えてくれます。これは非常に便利なライブラリです。
from sklearn.preprocessing import LabelEncoder
for i in range(train.shape[1]):
if train.iloc[:,i].dtypes == object:
lbl = LabelEncoder()
lbl.fit(list(train.iloc[:,i].values) + list(test.iloc[:,i].values))
train.iloc[:,i] = lbl.transform(list(train.iloc[:,i].values))
test.iloc[:,i] = lbl.transform(list(test.iloc[:,i].values))
さて Apache Spark で同じことをやるにはどうすればよいでしょうか。
Apache Spark ではいったん Dataframe に入れた値は immutable となり、上書きで変更することはできません。では文字列で構成されたカラムを数字に置き換えるにはどうすればよいでしょうか。
Apache Spark の場合は各カラムの文字を読み取り、それに対応した処理を行って生成した数字が入る新しいカラムを Dataframe の末尾に追加することになります。その後に、必要に応じて元のカラムを削除すれば、見た目上カラムの値を置き換えたことになります。
以下は私が作成した、文字列カラムの値を数値に置き換える Apache Spark 用関数です。あとで別の DataFrame に同じ変換ができるように、文字列と数値の対応も保存することができるようにしました。
def labelEncode(df, labelDict):
# encode labels with value between 0 and n_classes-1
# if labelDict is passed, encode label in same way as first.
if labelDict == None:
labelDict = {}
cols = df.columns
for i in df.schema:
colName = i.name
nColName = colName + "-encoded"
colType = i.dataType
if isinstance(colType, StringType):
if colName in labelDict:
eItems = labelDict[colName]
else:
eItems = {}
for (x, i) in enumerate(df.groupBy(colName).agg({colName: "count"}).select(colName).collect()):
eItems[i[0]] = x
labelDict[colName] = eItems
print(colName, eItems)
eItems = spark.sparkContext.broadcast(eItems)
def colLabelEncoder(a):
topic = eItems.value
if a in topic:
return topic[a]
else:
sys.stderr.write("unencoded value found: "+str(a)+". assigned -1.\n")
return -1
udfColLabelEncoder = udf(colLabelEncoder, IntegerType())
df2 = df.withColumn(nColName, udfColLabelEncoder(df[colName])).drop(colName).withColumnRenamed(nColName, colName)
df = df2.select(cols)
else:
pass
return (df, labelDict)
実際に使用すると以下のようになります。
# String型の列をそれぞれグループ化し、整数に変換する
(df3, labelDict) = labelEncode(df2, None)
display(printDf(df3.limit(10)))
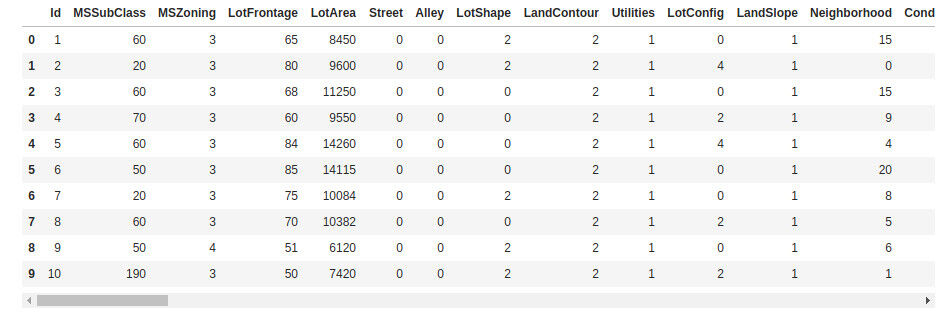
これで scikit-learn の "LabelEncode" 相当の処理を行うことができました。
NaN値の補完
次は元データの中の NaN 値を置き換えます。NaN 値をどのように置き換えるかはデータによって異なります。単純に全ての NaN 値を 0(ゼロ) で置き換えることがいいこともありますし、そうではないもっと別の値で置き換えたほうがいいこともあります。
参照元の Pandas では NaN 値を各カラム毎 median(中央値) で置き換えています。
Xmat = pd.concat([X_train, X_test])
Xmat = Xmat.drop(['LotFrontage','MasVnrArea','GarageYrBlt'], axis=1)
Xmat = Xmat.fillna(Xmat.median())
Apache Spark にも "fillna" 関数があるのですが、この関数はカラムごとではなく、Dataframe 全体の NaN を指定した値で一律に置き換えてしまいます。今回はカラムごとに置き換える値を変えたいので、自作の関数で対応することにします。
def fillNa(df, method):
# fill Nan row in each column which doesn't have StringType type.
# method can be specified items(avg, max, min, sum, count) which is defined in pyspark.dataframe.groupBy.agg
# 文字列以外のカラムのNaN部分を埋める。文字列のカラムは無視される。
# methodにはpyspark.sql.dataframe.groupBy.aggで指定可能な項目(avg, max, min, sum, count)を指定する
cols = df.columns
for i in df.schema:
colName = i.name
nColName = colName + "-filled"
colType = i.dataType
if isinstance(colType, DoubleType):
meanValue = df.agg({colName: method}).collect()
def replaceNullValueDouble(beforeVal, afterVal):
if beforeVal == None:
return float(afterVal)
else:
return float(beforeVal)
udfReplaceNullValueDouble = udf(replaceNullValueDouble, DoubleType())
df2 = df.withColumn(nColName, udfReplaceNullValueDouble(df[colName], lit(meanValue[0][0]))).drop(colName).withColumnRenamed(nColName, colName)
df = df2.select(cols)
elif isinstance(colType, IntegerType):
meanValue = df.agg({colName: method}).collect()
def replaceNullValueInt(beforeVal, afterVal):
if beforeVal == None:
return int(afterVal)
else:
return int(beforeVal)
udfReplaceNullValueInt = udf(replaceNullValueInt, IntegerType())
df2 = df.withColumn(nColName, udfReplaceNullValueInt(df[colName], lit(meanValue[0][0]))).drop(colName).withColumnRenamed(nColName, colName)
df = df2.select(cols)
else:
pass
colType = df.schema[colName].dataType
実際に使用すると以下のようになります。
df2 = fillNa(df, "mean")
display(printDf(df2.limit(10)))
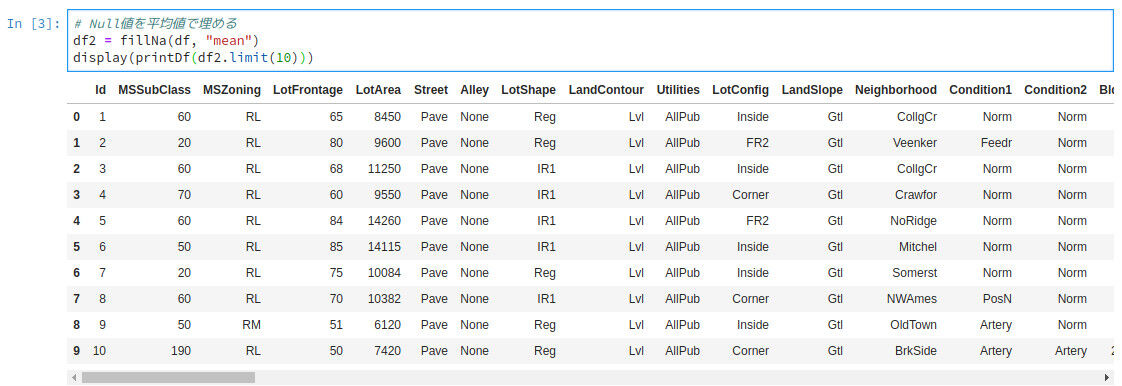
上記の例では各カラムの NaN 値を mean(平均値) で置き換えています。関数の内部では Apache Spark の "pyspark.sql.dataframe.groupBy.agg" で集計をしています。残念ながら Apache Spark の "agg" 関数には median(中央値) を集計する機能がないので近しい値として mean(平均値) を代替して使用しています。
ともあれ、これで NaN 値への対応もすることができました。
複数のカラムを結合して新しいカラムを作る
データ分析の現場では、元データの複数のカラムを結合して新しいカラムを作成したり、反対に元データの1つのカラムを複数のカラムに分割したりすることはよく行われる作業です。
もちろん Pandas ではこれらの作業をかんたんに行うことができます。参照元の記事では "TotalBsmtSF", "1stFlrSF", "2ndFlrSF" の3つのカラムの数字を合計して、新しいカラム "TotalSF" を作成しています。
# add a new feature 'total sqfootage'
Xmat['TotalSF'] = Xmat['TotalBsmtSF'] + Xmat['1stFlrSF'] + Xmat['2ndFlrSF']
Apache Spark では新しいカラムの作成は "withColumn" 関数を使用します。 "withColumn" 関数から UDF(User Defined Function) を呼び出して計算し、計算結果を収めた新しいカラムを Dataframe に追加します。上記の処理を Apache Spark に対応させて書き直すと以下のようになります。
def addFSColumns(bsmt, fflr, sflr):
return int(bsmt+fflr+sflr)
udfAddSFColumns = udf(addFSColumns, IntegerType())
df4 = df3.withColumn("TotalSF", udfAddSFColumns(df3["TotalBsmtSF"], df3["1stFlrSF"], df3["2ndFlrSF"]))
正直 Pandas と比べると少し冗長かもしれないですね・・・。ともあれこれでカラムの結合もできました。
可視化ライブラリにデータを渡して Feature の重要性を見る
大量の Feature(説明変数, 特徴とも呼ばれる) から目的変数に合わせて有効な Feature を選ぶこともデータ分析の現場では重要です。しかし場合によっては元データに含まれる Feature が数十、数百とある場合、何が有効なのかを人間が目で見て決めることは難しいことになります。
そこで各種ライブラリの支援を借りることになります。各機械学習のライブラリは、教師データでモデルをトレーニングした際にどの Feature をどの程度重視したかを指標として出力することができます。また教師データの各カラム間の相関関係を指数として表すためのライブラリもあります。
参照元の記事では教師データを Random Forest アルゴリズムに渡してトレーニングし、その際に出力される "Feature Importance" 値を見て、実際に使用する Feature を決めています。
# feature importance using random forest
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=80, max_features='auto')
rf.fit(X_train, y_train)
print('Training done using Random Forest')
ranking = np.argsort(-rf.feature_importances_)
f, ax = plt.subplots(figsize=(11, 9))
sns.barplot(x=rf.feature_importances_[ranking], y=X_train.columns.values[ranking], orient='h')
ax.set_xlabel("feature importance")
plt.tight_layout()
plt.show()

Apache Spark の MLlib にも Random Forest がありますので、同じようにやってみましょう。ここでは Random Forest のトレーニング、Feature Importance の値の取得は MLlib の関数を使用し、その可視化には Python の seaborn ライブラリを使用しています。
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import RandomForestRegressor as RF</p>
<h1>Feature(説明変数)として使用する列の一覧を作成する</h1>
<p>featureCols = df5.columns
featureCols.remove("Id")
featureCols.remove("SalePrice")
featureCols.remove("SalePrice2")
display(print(featureCols))</p>
<h1>Feature対象カラムを結合して特徴ベクトルを作成し、カラム名'feature'に入れる</h1>
<p>assembled_feature = VectorAssembler(inputCols=featureCols, outputCol='feature')
pipeline = Pipeline(stages=[assembled_feature])
dfF = pipeline.fit(df5).transform(df5)
display(printDf(dfF.limit(5)))</p>
<h1>RandomForestRegressorモデルを作成する。</h1>
<h1>説明変数は 'feature', 目的変数は 'SalePrice'</h1>
<p>rf = RF(labelCol='SalePrice', featuresCol='feature', numTrees=200, maxDepth=20, seed=42)
model = rf.fit(dfF)</p>
<h1>RandomForestによって算出された説明変数の重要度を出力する</h1>
<h1>np.argsort(model.featureImportances.toArray())</h1>
<p>pdf = pd.DataFrame({'Name': featureCols, 'Importance': model.featureImportances.toArray()})
pdf2 = pdf.sort_values(by=['Importance'], ascending=False).reset_index().drop(['index'], axis=1)
display(pdf2.head(5))
f, ax = plt.subplots(figsize=(11,16))
sns.barplot(x=pdf2["Importance"], y=pdf2["Name"], orient='h')
ax.set_xlabel("feature inportance")
plt.show()
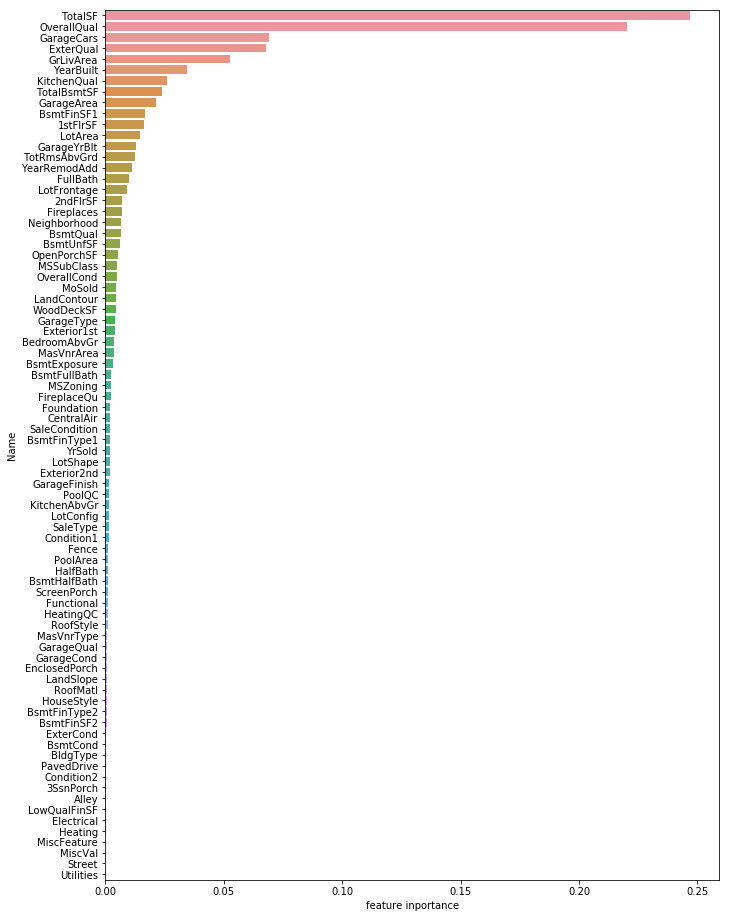
Apache Spark の MLlib の使い方は scikit-learn のお作法とは少し異なっています。まず教師データとして使いたいカラムを選択し、それらをベクトルとして結合したカラムを作成し、そのカラムを教師データとして "fit" 関数を呼び出して機械学習モデルをトレーニングします。予測についても scikit-learn では "predict" 関数を呼び出すのに対して、Apache Spark ではトレーニング済みのモデルを使って "transform" 関数を呼び出すことで、教師データの入っている Dataframe に予測値の入ったカラムを追加することで、予測値を得ることができます。
上記の例では予測はやっていません。モデルをトレーニングした際の Feature Importance を取り出し、 Pandasで並び替えた上で seaborn に渡しています。Apache Sparkの関数から取り出した Dataframe や Vector は、 "toArray" 関数を使うことで Numpy ndarray の形式に変換したり、 "toPandas" 関数で Pandas の Dataframe に変換することができます。逆に Pandas の Dataframe を Spark の Dataframe にする場合は "createDataFrame" 関数で容易に変換することが可能です。これらの関数に慣れておくと、Apache Spark と Pandas, Numpy の間を柔軟に行き来することができるようになります。
外れ値を削除する
現実のデータには予測精度に影響を与える「外れ値(Anomary, アノマリー)」がしばしば含まれています。これを削除してみます。元記事の Pandas では以下のようにやっています。
Xmat = Xmat.drop(Xmat[(Xmat['TotalSF']>5) & (Xmat['SalePrice']<12.5)].index)
Xmat = Xmat.drop(Xmat[(Xmat['GrLivArea']>5) & (Xmat['SalePrice']<13)].index)
Spark では "filter" 関数で処理を行うことができます。以下のようになります。値を正規化していないので数字は異なっています。
df5_mat = df5.filter(~((df5.TotalSF >= 5500) & (df5.SalePrice <= 300000))) \
.filter(~((df5.GrLivArea >= 4000) & (df5.SalePrice <= 300000)))
アンサンブルを作成する
これでデータセットを整形できたので、機械学習アルゴリズムを構築します。また、複数の回帰モデルを混合させるアンサンブルもやってみます。
元記事では XGBoost, Neural Network, Support Vector Machine(SVR) の3種類で行っていますが、残念ながら Apache Spark には同じ関数はないため、LinearRegression(Lasso), RandomForestRegression, Gradient-boosted tree regression の3種類でアンサンブルしてみます。上記で記述したとおり、事前に Feature Vector を作成しておきます。
python
# Lasso
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol="feature", labelCol="SalePrice", predictionCol="predict", elasticNetParam=1)
model_lr = lr.fit(mat2)
mat2_lr_pred = model_lr.transform(mat2)
# RandomForest Regression
from pyspark.ml.regression import RandomForestRegressor
rf = RandomForestRegressor(featuresCol="feature", labelCol="SalePrice", predictionCol="predict", numTrees=200, maxDepth=20, seed=42)
model_rf = rf.fit(mat2)
mat2_rf_pred = model_rf.transform(mat2)
# Gradient-boosted tree regression
from pyspark.ml.regression import GBTRegressor
gb = GBTRegressor(featuresCol="feature", labelCol="SalePrice", predictionCol="predict")
model_gb = gb.fit(mat2)
mat2_gb_pred = model_gb.transform(mat2)
# LassoのDataframeからIdと予測結果だけを取り出し
ens_df_lr = mat2_lr_pred.select([mat2_lr_pred.Id, mat2_lr_pred.predict]) \
.withColumnRenamed("predict", "pred_lr") \
.withColumnRenamed("Id", "Id_lr")
# RandomForestのDataframeからIdと予測結果だけを取り出し
ens_df_rf = mat2_rf_pred.select([mat2_rf_pred.Id, mat2_rf_pred.predict]) \
.withColumnRenamed("predict", "pred_rf") \
.withColumnRenamed("Id", "Id_rf")
# Gradient-boosted tree regressionのDataframeはfeature vectorのみ落とす
ens_df_gb = mat2_gb_pred.withColumnRenamed("predict", "pred_gb") \
.withColumnRenamed("Id", "Id_gb") \
.drop("feature")
# 3つのDataframeをjoin
ens_df = ens_df_lr.join(ens_df_rf, ens_df_lr.Id_lr == ens_df_rf.Id_rf)
ens_df2 = ens_df.join(ens_df_gb, ens_df.Id_lr == ens_df_gb.Id_gb)
display(printDf(ens_df2.limit(3)))
# 3つの予測結果からFeature vectorを作成し、Lassoで回帰させる
assembled_feature = VectorAssembler(inputCols=["pred_lr", "pred_rf", "pred_gb"], outputCol='feature')
pipeline = Pipeline(stages=[assembled_feature])
ens_df3 = pipeline.fit(ens_df2).transform(ens_df2)
lr2 = LinearRegression(featuresCol="feature", labelCol="SalePrice", predictionCol="predict", elasticNetParam=1)
model_lr2 = lr2.fit(ens_df3)
ens_pred = model_lr2.transform(ens_df3)
Apache Spark の Linear Regression にはお作法にクセがあり、 "elasticNetParam" パラメータを変更することで正則化を制御します。 "elasticNetParam=0" で L2(Ridge Regression) 、 "elasticNetParam=1" で L1(Lasso) 、 "elasticNetParam=0 から 1の間" で L1+L2(ElasticNet) となります。scikit-learn では Lasso, Ridge, ElasticNet それぞれ関数が用意されているところからすると少し違和感がありますが、慣れの問題かもしれません。今回は L1 正則化を使用します。
今回は使用しませんでしたが、 "ParamGridBuilder" を活用したグリッドサーチも可能です。
最終的な投稿用のデータを作成する
ここまででモデリングできたので、Kaggle に投稿するためのデータを作成します。
python
dftest = spark.read.format("csv").options(header="true", nanValue="NA", nullValue="NA", inferSchema=True).load("test.csv.gz")
dftest2 = fillNa(dftest, "mean")
(dftest3, labelDict2) = labelEncode(dftest2, labelDict)
# (中略)
# アンサンブルモデルで予測値を追加
test_pred = model_lr2.transform(test_ens3)
test_pred.select(test_pred.Id, test_pred.predict) \
.withColumnRenamed("predict", "SalePrice") \
.write.format("csv").options(header="true", nanValue="NA", nullValue="NA", inferSchema=True).save("houseprice.csv")
実行したディレクトリの下に houseprice.csv/part-XXXX.csv が作成されます。あとはこれを Kaggle に投稿して完了です。
Apache Spark は Kaggle 向きなのか?
どのようなツールにも慣れがありますので、基本的には手慣れたツールを使ったほうがよいかとは思いますが、 優秀な機械学習ライブラリは Python module としてまっさきに提供される傾向があるため、全てを Apache Spark でやるというのはあまりおすすめできません。
反面大量のデータのETL, EDA処理については Pandas, Numpy, scikit-learn にはオンメモリの制約、並列化の難度があり、どうしても分散処理をしなければいけない状況では、比較的 Apache Spark に分があるのかもしれません。
相変わらずのコメントかもしれませんが、適材適所で使い分けていくことになるかと思います。上記の例でもわかるとおり、 "いずれか1つ" を選択しなければいけないわけではなく、必要に応じて scikit-learn, XGBoost などにデータを渡すようにしていければよいのではないかと思います。
さいごに
今回作成した完全なコードは https://github.com/m-kiuchi/house-prices-advanced-regression-techniques で公開しています。フィードバックなどありましたらぜひコメント頂けるとうれしいです!
それでは!

CL LAB Mail Magazine
メールアドレス: 登録
※登録後メールに記載しているリンクをクリックして認証してください。Related post
- e19(千京)を紹介します #e19 #spark #DataAnalytics
- e19: 初回ログイン~UI説明 #e19 #spark #DataAnalytics
- ”Cassandra Summit Tokyo 2017″に弊社の木内が登壇いたします。#Cassandra #datastax
- Azure Databricks の紹介 #Microsoft #Azure #DataBricks #spark
- 2018年7月29日に開催されるJuly Tech Festa 2018に、弊社シニアコンサルタント木内が登壇致します。#JTF2018 #e19 #AlibabaCloud
Popular ranking
- View
 GitLab
GitLabGitLab CEをインストールしてみた #gitlab #DevOps #GitLab
2017.09.11
 Docker
DockerDocker認定試験(Docker Certified Associate Exam)挑戦記 #docker
2018.06.22
 DataAnalytics e19 Spark
DataAnalytics e19 SparkApache Spark縛りでKaggleのコンペティションやってみた #Spark
2018.06.27
 Docker Kubernetes
Docker KubernetesDocker for Windows DesktopにもKubernetesを搭載! #docker #kubernetes #k8s
2018.02.07






