昨年、松尾先生の書いた名著「人工知能は人間を超えるか」を読んでものすごく面白そうだったんだけどネットにサンプルがあまりないのでどうすれば実装できるのかよくわかんなあと思って放っておいたもののひとつがStacked Auto Encoderだった。
Auto Encoderとは、入力と出力が一緒になるように学習させることで、入力データの特徴を上手く掴むように学習させる手法である。
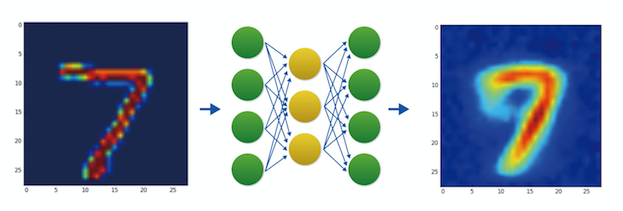
入力データを一度少ない次元に変換してから、もとの状態に復元するので、たしかにこれを見るとうまく次元圧縮できているような気もする。
次元が圧縮できるということは、要は『特徴量」を掴むための条件が揃ったということだ。我々人間は、入力された画像が数字の7で、出力された画像も数字の7であると判別できる。
「数字の7」と判別できるのは、我々はMNISTのデータが0から9までの10次元しかないと知っているからだけれども、もっと一般的なものに範囲を広げれば、カタカナの「フ」とか、ハングルの「フ」に見えるかもしれない。
28x28ドット=784次元の入力を10次元まで圧縮するには、このオートエンコーダを積み重ねていけばいい。
具体的には、768次元を400次元に圧縮して、次に同じ要領で400次元を100次元に圧縮、僕の場合、可視化にこだわっていたので、100の次は49次元(7x7)、その次は16次元(4x4)、最後に3次元に圧縮する。
さて、これはこれでこのオートエンコーダは勝手に特徴量を掴んでくれているはずである。
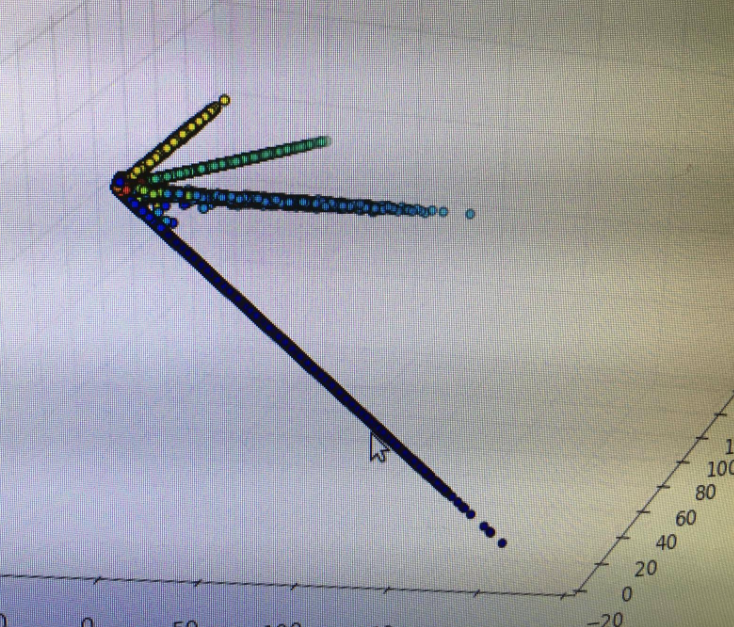
この状態のまま、MNISTのデータを読ませて三次元空間にマッピングするとどうなるか。

「な、何も成長していない・・・・」
まあタイミングによっては、「お、ここがクラスターになってるのかな?」「お、ちょっとだけ分離できてるのかな」というふうに見えるタイミングがなくもないが、実際的にはなにも成長していないように見える。
それもそのはず、この三次元散布グラフの点の色は数字を表している。0が青、赤が9というように。その基準で見ると、一見、全く特徴量を掴めてないようにも見える。
これは要するにニューラルネットワーク本人(?)は「オレはアレがこうなって、アレがこうだっていう感じがしてんだよなあ」と「分かった気になってる」状態であって、彼女(今後僕はAIを女性だと思うことにする)は彼女なりに自分で理解できてるつもりでも、言葉にできるほど明晰に理解できてるわけではない。
さて、この状態に持っていくのに実はけっこう時間がかかる。
というのは、たとえば畳込みだと入力から出力までをただつないで、出力から逆伝搬をかければ理論的にはどれだけ深いニューラルネットワークでも学習できる。
オートエンコーダの場合は、一層ずつ順番に学習しなければならない。500エポックまわすなら、5層で25000エポック回す必要がある。畳込みなら全体で20エポックも回せばMNISTくらいの問題なら簡単に精度が出る。このあたりが、オートエンコーダがやや不人気になってしまった理由かもしれない。
しかし畳込みは局所性を利用しているので「ちょっと邪道」と考える一派もいる。
あくまでニューラルネットワークは全結合層をベースに考えるべきだと。まあ僕はどっちの派閥の言うことも一理あると思うので面白くて便利ならば両方やろうという派である。
問題はここからで、今の状態では、いわばきちんと教育を受けていない幼児のような状態で、特徴を掴むことはできるが、彼女が掴んだ特徴を我々人類が理解できるレベルにブレークダウンできていない。三次元へ射影すると混沌とするというのは、要はインターフェースの問題である。
そこで、ほんの少しだけファインチューニングをかけてやる。
この「ほんの少しだけ」というところがミソで、ガッツリとかけると却ってバカになってしまう。
ファインチューニングとは、できあがったニューラルネットワークに僅かな教師付きデータを与えてあげて、学習させるという手法だ。
つまり、彼女の頭のなかで「アレは丸くて、ピョッと線が出てクルッとなってる」と漠然と感じている特徴量を、「それは9だよ」と教えてあげる。
すると彼女のあたまの中では「ああ、丸いのと線が出てクルッとなってるのは9なんだ」と整理される。
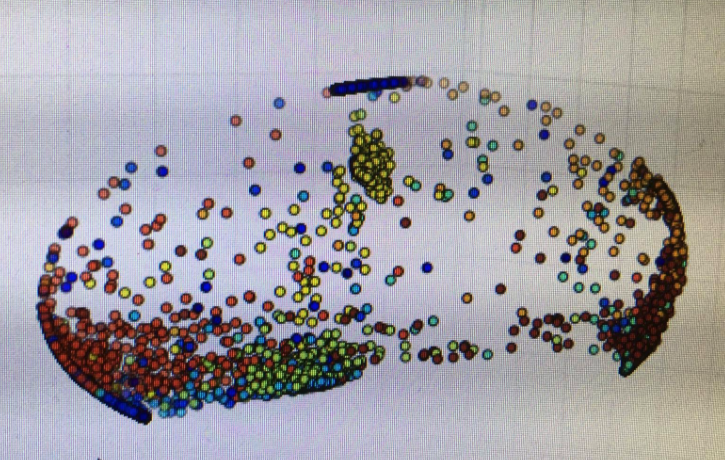
今回の場合、ファインチューニングをわずか8エポックほどかけた結果はこうなる。
バビューン!
なんと明晰!
それぞれの数字が綺麗に一直線に並ぶ。
この3次元空間上にこつ然と出現した10本の軸(パッと見で見えるのは4本だが、他の軸は中央付近にわずかに折りたたまれている)は、それぞれが「0っぽさ」「1っぽさ」などの手書き数字の特徴量に沿った軸になっているのだろう。
よちよち歩きだった彼女が、数時間に渡るオートエンコーダの学習と、わずかなファインチューニングによってここまで明晰に状況を理解できるようになったというのは、ある意味で感動的でさえある。
しかしこれでは真ん中あたりにある小さいクラスターを見つけづらい。
そこで角特徴量のベクトルを正規化して可視化してみると
こんな感じで、さっきは気づかなかった黄色や緑の軸がクラスターごとにある程度まとまっているというのを視覚的に確認できる。
ただし、通常のディスプレイを使うとこの手のものを確認しようと思っても、どうしても三次元空間のものを二次元に写像したものを眺めるということで、立体感に欠ける。
色々なデータを文字通り様々な角度から眺めて新しい知見を得たい、という目的には、二次元のディスプレイはいかにも狭すぎるのだ。
そこでVRの登場である。
VRで空間的に配置した各データ群を識別し、どのようなクラスターに別れるか、クラスターはどんな形をしているのか、直接確かめることができるシステムを作れば、今までにない知見を得られるかもしれない。
これは画像以外でもあらゆるデータに対して適用可能な非常に汎用性の高い手法なので、なるほど確かに畳込みは邪道、というのはわからんでもない、と思ったりした。でもGPUで使う以上は畳込みは速くて便利なんだけどね