
こんにちは。理系大学院で修業中のスーパーケロケロです。趣味で自然言語解析(NLP)の勉強をしています。最近、テキストに含まれた情報を有向グラフに変換するPythonライブラリーnaruhodoを作ったので、ライブラリーの紹介も兼ねて、テキストを有向グラフに変換する話を少ししてみたいと思います。
naruhodoのGithubリポジトリはこちら、最新バージョンは![]() です。
です。
自然言語解析の流れ
自然言語解析を料理に例えれば、入力されたテキストは収穫待ちのコムギのようで、そのままでは使えない。このコムギを形態素解析で脱殻し(形態素単位で分離)、さらに词类(Part-Of-Speech)や依存構造解析で小麦粉にしてから(文法情報の付与)、ようやくパンのような美味しい食べ物が作れる(実際の応用)。

テキストが処理されるごとに、使える情報が増えて、応用の幅が広げるわけです。
文=>木、文章=>有向グラフ
例えば、テキストに依存構造解析を施すと、下の図のように、依存文法の情報が単語間の繋がりとして付与される。
依存構造ーー
文の構文構造の表現形式のひとつ。文内の単語間の依存関係(係り受け関係)の集合によって文の構文構造を表現する。日本語では文節の係り受け関係を依存構造と呼ぶこともある。英語と日本語の依存構造の例を以下に示す。単語もしくは文節の依存関係を表わす矢印の向きは、通常は係り先から係り元の方向であるが、日本語では逆に係り元から係り先の方向であることが多い。ーーJAIST言語情報処理ポータル
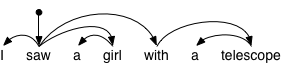
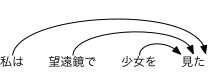
日本語依存構造解析ツールCabochaの典型的な出力はこのようになっている。
* 0 3D 0/1 -1.591231
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 1 3D 0/1 -1.591231
望遠鏡 名詞,一般,*,*,*,*,望遠鏡,ボウエンキョウ,ボーエンキョー
で 助詞,格助詞,一般,*,*,*,で,デ,デ
* 2 3D 0/1 -1.591231
少女 名詞,一般,*,*,*,*,少女,ショウジョ,ショージョ
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
* 3 -1D 0/1 0.000000
見 動詞,自立,*,*,一段,連用形,見る,ミ,ミ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
文はチャンクごとに分離され、依存構造はチャンクのIDで表されています。例えば、IDが0の”私は”はIDが3の”見た”に依存している事を”3D”で表示します。それぞれの文は必ず一つのROOTが存在するので(”‐1D”のチャンク)、典型的な木構造(もっと正確に言うと有向根付き木)になっています。
当然、複数の文から複数の木が得られます。木の間にもし共通するノードがあれば、繋がるようになります。このような木の連合は結果的に有向グラフになります。
さらにノードの出現回数や词类に応じて、ノードのサイズやカラーを調整すれば、きれいなグラフになるのではないか?こういったグラフはWord Cloudなんかよりずっと情報量が多く、可視化したらめちゃくちゃ格好いいに違いない。=>これがnaruhodoを作るきっかけになった。
という事で、早速naruhodoでこういうグラフを可視化してみようではないか。
注1:グラフ理論に詳しい人なら、木の集合を言うとまず森だと認識するかも知れませんが、グラフ理論で言う森は"閉路を持たない(連結であるとは限らない)無向グラフ"なので、前述の"共通するノードで繋がる(かも知れない)有向根付き木の集合"とは違うものになっています。更に共通するノードで繋がる事を許すと、閉路を形成する可能性もあるので、有向非巡回グラフでもありません。
注2:依存構造解析の結果は有向根付き木であることは間違いありません。ただ、
naruhodoのように可視化する時、文の中に同じノードが複数回出現する場合は一つのノードに合併するようにしています。ノードの合併によって、各ノードからROOTまでは複数のパスが存在できる。この場合、有向根付き木の"各ノードからROOTまでに唯一のパスが存在する"という性質が満たされなくなるので、生成されたグラフは厳格な有向根付き木でもなく、単純な連結有向グラフである。でもこのグラフは唯一のROOTを持っている事や階層構造を持っているなど、木の特徴がまだ一部残っているので、複数の文から生成されるグラフと区分するために、ここではとにかく木と呼ぶことにします。
依存構造グラフの可視化
naruhodoはMeCabとCabochaで形態素解析と依存構造解析を行います、だからまずはこちらの記事を参照してMeCabとCabochaをインストールしましょう。
MeCabとCabochaがインストールできたら、pipでnaruhodoをインストールします。
pip install naruhodo
naruhodoをインストールできたら、まずはパーサを取得します。
from naruhodo import parser
dp = parser(gtype="d")
ここのgtypeはグラフの種類のことで、今は依存構造のグラフを生成したいので、”d”に指定します。
準備が整えたので、addでテキストをグラフに追加します。
dp.add("私は望遠鏡で少女を見た。")
よし、それではこの文で生成した木構造を確認しましょう。
Jupyter Notebookを使っているならば、showで図を見れます。
dp.show()
それ以外の場合は、plotToFileで図を出力します。
dp.plotToFile(filename="pic.png")
こういう図が生成された。ちゃんとイイ感じに依存構造を表しています。
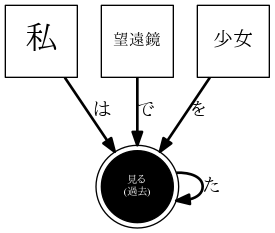
それでは、共通している部分を含む新しい文を追加してみよう。
dp.add("見た少女は美人だった。")
dp.show()
すると、こういうグラフになります。
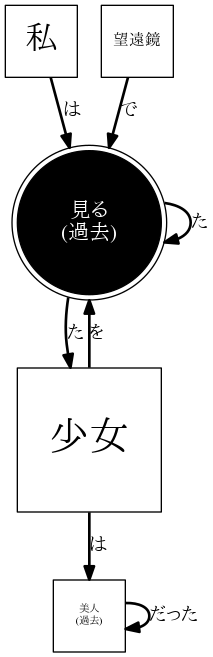
うん、ストーカーがいる事がグラフからでもよく分かりそうです。( o∀o)
よし、もう少し複雑なテキストを投げてみよう。
# まずはグラフをリセットします
dp.reset()
# 文を順番に沿って追加
dp.add("田中一郎は田中次郎が描いた絵を田中三郎に贈った。")
dp.add("三郎はこの絵を持って市場に行った。")
dp.add("市場には人がいっぱいだ。")
# 図を表示
dp.show()
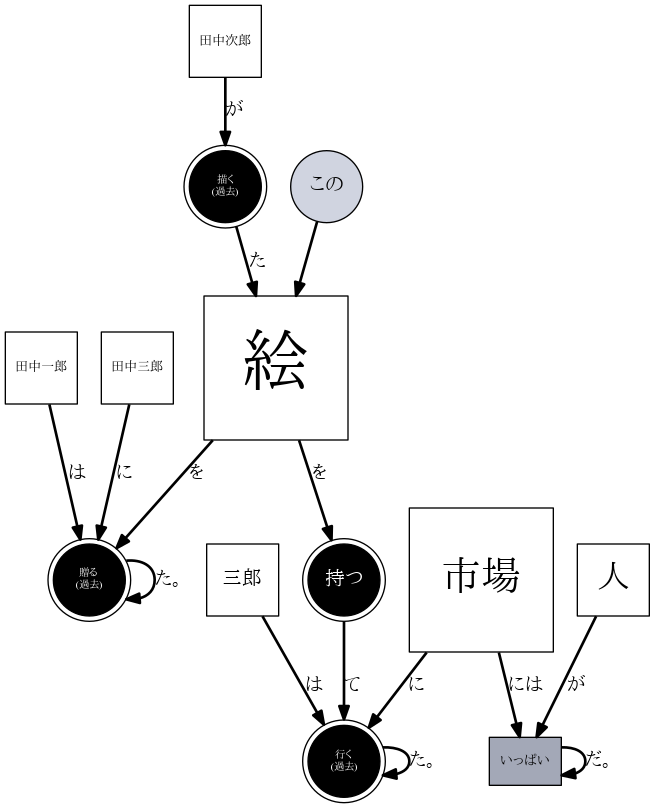
おお、イイ感じではないか?
それではようやくメインディッシュのニュースをグラフ化にしましょう。
今回は〔マーケットアイ〕外為:ドル105円半ばで小動き、実需筋の売り買い交錯というニュースでグラフを生成してみます。
こういった試行錯誤を便利にできるため、naruhodoにaddUrlsというウェブページからテキストを取ってくる機能も実装しました。指定されたウェブページから<p>タッグに含まれる内容を集めるという簡単なスクレーピング機能です。
# まずはグラフをリセットします
dp.reset()
# ウェブページのUrlを追加します。複数のUrlがある場合、Urlのリストを渡してもオッケイです
dp.addUrls("https://jp.reuters.com/article/tokyo-frx-idJPL3N1RA2SG")
# 図を表示
dp.show()
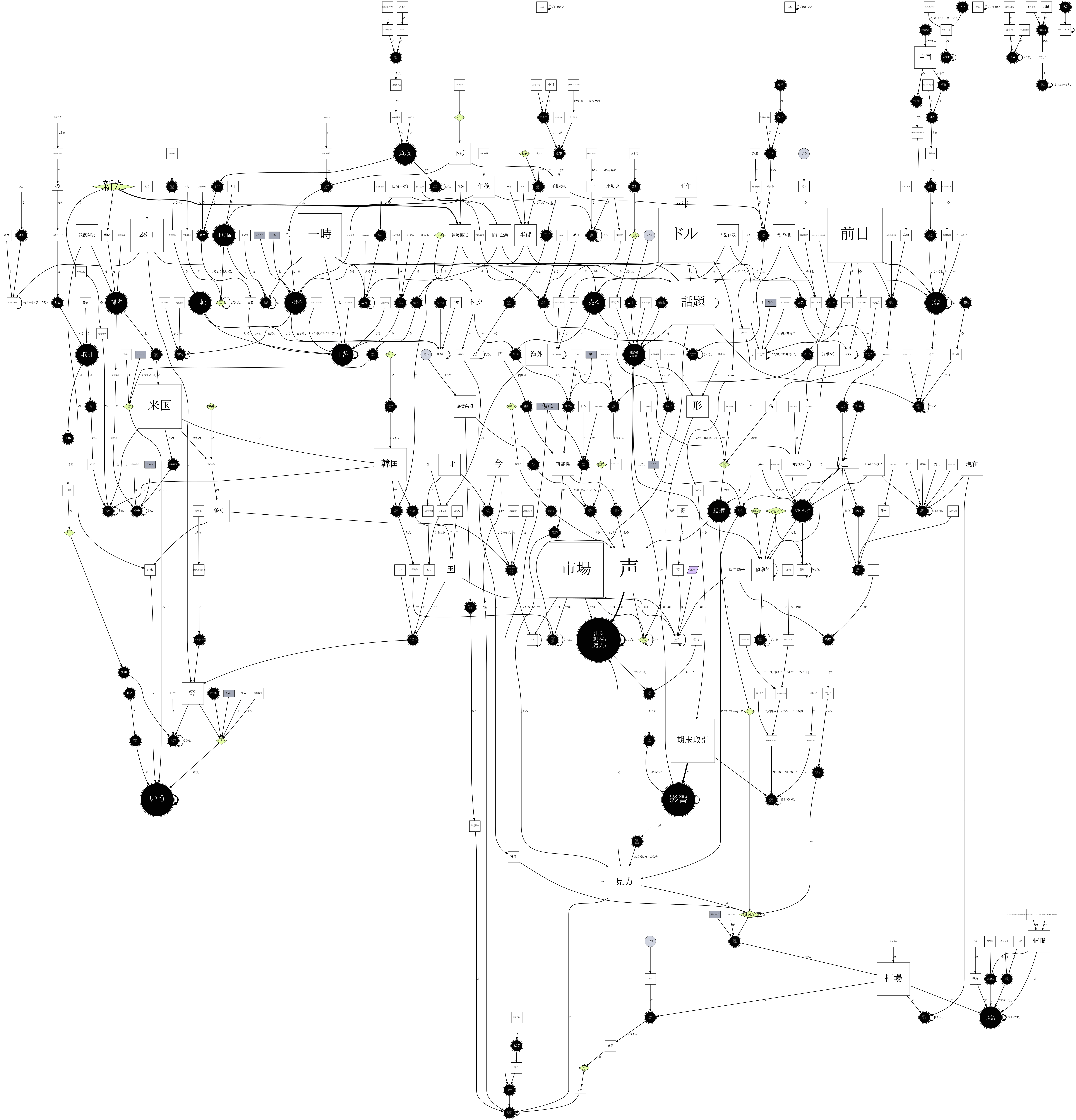
......
............
..................
うん、なにこれ(・∀・)
なんか使えそうだけどまだこれだけでは何も分からないグラフです。
次回の依存構造グラフの章でこのグラフに含まれる情報について考察してみます。

この 作品 は クリエイティブ・コモンズ 表示 - 継承 4.0 国際 ライセンスの下に提供されています。