
仰々しいタイトルになってしまいましたが、内容はこんな便利な学習モデルの書き方が出来るよって紹介です。A Purely Functional Typed Approach to Trainable Models (Part 1)で語られているコードをベースにして説明していきたいと思っています。
この記事で紹介する内容は新しい機械学習の理論でもなければ明日から役に立つデータサイエンティストの知識でもありません。線形回帰やニューラルネットワークといった既存の学習理論を表題にもあるような可微分プログラミング(Differentiable Programming)と純粋関数型言語を使って統一的に記述してみようというものです。こういった抽象化は理論に対する理解を深め、時に新しい構造の発見につながるでしょう。
可微分プログラミング
本編に入る前に可微分プログラミングという概念について簡単に触れておきます。
まず可微分プログラミングという言葉はDifferentiable Programmingという言葉の拙訳です。調べたところDifferentiable Programmingという英語の定訳はなさそうで(あったら教えてください ![]() )、最適化問題の文脈ということもありProgrammingを「計画法」と訳そうかとも考えましたが、後に述べるようにプログラミング言語との類似性も強調されているため「プログラミング」とそのまま訳しました。
)、最適化問題の文脈ということもありProgrammingを「計画法」と訳そうかとも考えましたが、後に述べるようにプログラミング言語との類似性も強調されているため「プログラミング」とそのまま訳しました。
可微分プログラミングはCNNを発明したYann LeCun氏がDeepLearningで使われているテクニックを発展させた概念として紹介したものです。そのテクニックは微分可能な変数で計算グラフを作り勾配法で最適化するというもので、例えばTensorFlowでは
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.truncated_normal([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.add(tf.matmul(x, W), b)
のように書くことで以下のような計算グラフを作ることができ、誤差関数と学習データを与えることで最適化を行い$W, b$の値を推定することができます。
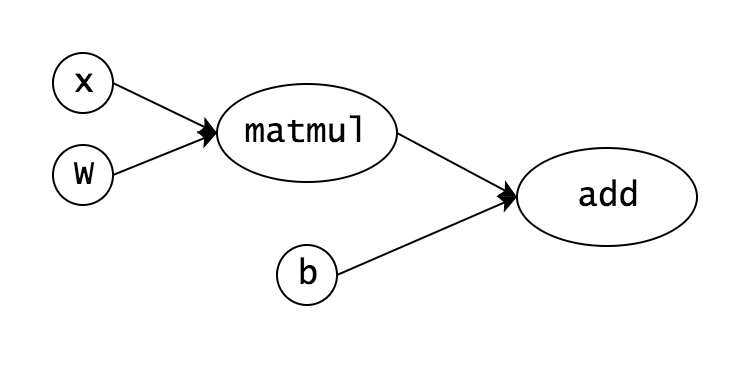
Yann LeCun氏はPyTorchやChainerのように動的に計算グラフを構築するテクニックも一般的になってきており、それはパラメータ化され・自動微分があり・学習と最適化が行われるという点を除いて、通常のプログラムとほとんど変わらないと述べています。そういった動的な計算グラフを構築するアーキテクチャはDeepLearningを一般化したものであり、可微分プログラミングと呼ばれているというわけです。
可微分プログラミングの分野ではそのコンパイラを改善して動作を速くするといった研究が行われていおり、Microsoft Researchもそういった研究に取り組んでいるようです。また可微分プログラミングで構築される計算グラフの構造と関数型プログラミングの類似性も指摘されており、純粋な数学からの研究のアプローチも期待されています。
この記事ではHaskellを使って可微分プログラミングの実装を行い、学習モデルの実装が純粋関数型言語を通して簡潔に書けることを見ていきたいと思います。
教師あり学習
教師あり学習は機械学習の手法の一つで、入力と出力の観測データが与えられた時に、パラメータ化された関数の族の中から観測データの評価誤差が最小になるような関数を探索する問題です。数式で書くと、入力変数を$x$、出力変数を$y$、パラメータを$p$と置いたとき、
$$
y = f_p(x)
$$
となるような関数の中で、
$$
\sum_i{\rm loss}\left(y_i, f_p(x_i)\right)
$$
を最小にするようパラメータ$p$を求める問題となります。($x_i, y_i$は与えられた観測データを表しています。)
ここで出てきたパラメータ化された関数$f_p$は、入力変数と出力変数の値が取りうる集合を$X, Y$と置いて、定義域と値域を明示的に書くと、
$$
f_p: X \rightarrow Y
$$
となり、さらにパラメータの集合を$P$と置くと
$$
f: P \times X \rightarrow Y
$$
と表せるでしょう。
これをHaskellの型で表すと
f :: (P, X) -> Y
となり、カリー化をすれば
f :: P -> X -> Y
と書けます。
こうして得られた型にModelという名前をつけておきましょう。
type Model p x y = p -> x -> y
さらに、これから可微分プログラミングを実装していくことを考えて全ての変数を微分可能な変数に置き換えます。
type Model p x y = forall z. Reifies z W
=> BVar z p
-> BVar z x
-> BVar z y
ここで出てきたBVarは微分可能な変数を表し、Reifies, Wは計算グラフを使って誤差逆伝播法を実現するための制約で、いずれもbackpropというライブラリで提供されているものです。厳つい型になってしまいましたが微分可能な変数を使っているというだけで本質はp -> a -> bと変わりません。
得られた型Modelを使って学習モデルをいくつか実装してみましょう。
線形回帰
まずは本当に簡単な例として線形回帰の中でも1変数しかない単回帰を実装します。
単回帰は
$$
y = b x + a
$$
という一次式で表されるモデルであり$a, b, x, y$は全て1次元の実数です。これを実装すると
linReg :: Model (Double, Double) Double Double
linReg (T2 a b) x = b * x + a
のようになります。T2はBVar z (a, b)をパターンマッチするためのview patternです。
この単回帰を学習させるためにまずは誤差関数を考えましょう。誤差関数は平均二乗誤差を用いるとして必要なのは学習データが与えられたときのパラメータによる誤差関数の勾配です。
lossGrad
:: (Backprop p, Backprop y, Num y)
=> Model p x y -- ^ モデル
-> x -- ^ 入力データ
-> y -- ^ 出力データ
-> p -- ^ パラメータ
-> p -- ^ パラメータの勾配
lossGrad f x y = gradBP $ \p -> (f p (auto x) - auto y) ^ 2
lossGradの実装を見ると素直に二乗誤差のパラメータによる勾配をとっているのがわかると思います。この勾配を使って全ての観測データを使って学習する関数を作ってみましょう。
trainModel
:: (Fractional p, Backprop p, Num y, Backprop y)
=> Model p x y -- ^ 学習モデル
-> p -- ^ 初期パラメータ
-> [(x,y)] -- ^ 観測データ
-> p -- ^ 更新後のパラメータ
trainModel f = foldl $ \p (x,y) -> p - 0.1 * lossGrad f x y p
学習係数を0.1として全ての観測データで逐次的にパラメータの更新を行っています。最後に初期パラメータを乱数で与えて学習するtrainModelの簡単なラッパーを作ります。
trainModelIO
:: (Fractional p, Backprop p, Num b, Backprop b, Random p)
=> Model p a b -- ^ 学習モデル
-> [(a,b)] -- ^ 観測データ
-> IO p -- ^ 推定パラメータ
trainModelIO m xs = do
p0 <- randomIO
return $ trainModel m p0 xs
これで準備は完了です!早速学習させてみましょう。
学習させるのは
$$
y = -1 + 2x
$$
という簡単な数式です。
> samples = [(1,1),(2,3),(3,5),(4,7),(5,9)]
> trained <- trainModelIO linReg $ take 5000 (cycle samples)
> trained
(-1.000000000000004,2.000000000000001)
ちゃんと学習できていますね!1
パーセプトロン
さて、今度はニューラルネットワークの一種であるパーセプトロンを実装してみましょう。といってもすごく簡単で、
logistic :: Floating a => a -> a
logistic x = 1 / (1 + exp (-x))
dense
:: (KnownNat i, KnownNat o)
=> Model (L o i, R o) (R i) (R o)
dense (T2 w b) x = w #> x + b
これで終わりです。活性化関数と全結合層を定義できました。LとRはhmatrixのNumeric.LinearAlgebra.Staticで定義されている行列とベクトルを表す型です。入力の次元と出力の次元がそれぞれi, oという型変数で表されているのもポイントです。
早速学習させてみましょう。今回学習させるのはAND回路です。学習に使う関数は線形回帰のときに使ったものをそのまま使うことができます。
> :{
| model :: Model _ (R 2) (R 1)
| model = (logistic.) . dense
| :}
> samples = [(H.vec2 0 0, 0), (H.vec2 1 0, 0), (H.vec2 0 1, 0), (H.vec2 1 1, 1)]
> trained <- trainModelIO model $ take 10000 (cycle samples)
> evalBP2 model trained (H.vec2 0 0)
(8.239947400168375e-4 :: R 1)
> evalBP2 model trained (H.vec2 0 1)
(8.09836651380813e-2 :: R 1)
> evalBP2 model trained (H.vec2 1 0)
(8.087207168002301e-2 :: R 1)
> evalBP2 model trained (H.vec2 1 1)
(0.9038634635519932 :: R 1)
ニューラルネットワーク(多層パーセプトロン)
以下のような演算子を定義すれば複数の Model を簡単に合成することもできます。
(<~)
:: (Backprop p, Backprop q)
=> Model p b c
-> Model q a b
-> Model (p, q) a c
(f <~ g) (T2 p q) = f p . g q
infixr 8 <~
この演算子を使って多層パーセプトロンを実装してみましょう。
> :{
| model :: Model _ (R 2) (R 1)
| model = (logistic.) . dense @4 <~ (logistic.) . dense
| :}
このように記述すれば4ユニットの中間層を持った3層のニューラルネットワークを記述することができました。実際に線形分離不可能なXOR回路を学習させてみましょう。
> samples = [(H.vec2 0 0, 0), (H.vec2 1 0, 1), (H.vec2 0 1, 1), (H.vec2 1 1, 0)]
> trained <- trainModelIO model $ take 10000 (cycle samples)
> evalBP2 model trained (H.vec2 0 0)
(4.844419123993396e-2 :: R 1)
> evalBP2 model trained (H.vec2 0 1)
(0.9433700120764607 :: R 1)
> evalBP2 model trained (H.vec2 1 0)
(0.9440509953610613 :: R 1)
> evalBP2 model trained (H.vec2 1 1)
(6.384537994361744e-2 :: R 1)
うまく学習できていますね!
まとめ
今回紹介したModelのような型で学習モデルの実装を統一することのメリットは高次の学習モデルが関数の合成やfoldといった関数型プログラミングの基本的なコンビネータを使って簡単に構築できることだと思います。Auto Encoderや非線形回帰、CNNなどもModelとして実装可能で、<~を使って自由に組み合わせることができます。また今回参考にしたブログ記事のPart 2には時系列モデルに拡張したModelSを使ってARモデルやRNNを記述する方法が紹介されています。このシリーズはPart 3まで存在するので気になる人は是非読んでみてください。