
はじめに
モーガン・フリーマンとココナッツチョコレートが似過ぎているため、ディープラーニングを使って見分けてみることにしました。

データセット
データセットは手動でGoogleから集めました。
モーガン・フリーマン(以下モーガン)の画像が約300枚、
ココナッツチョコレートの画像が約140枚です。
もはや狂気の沙汰ですね。
前処理
その1
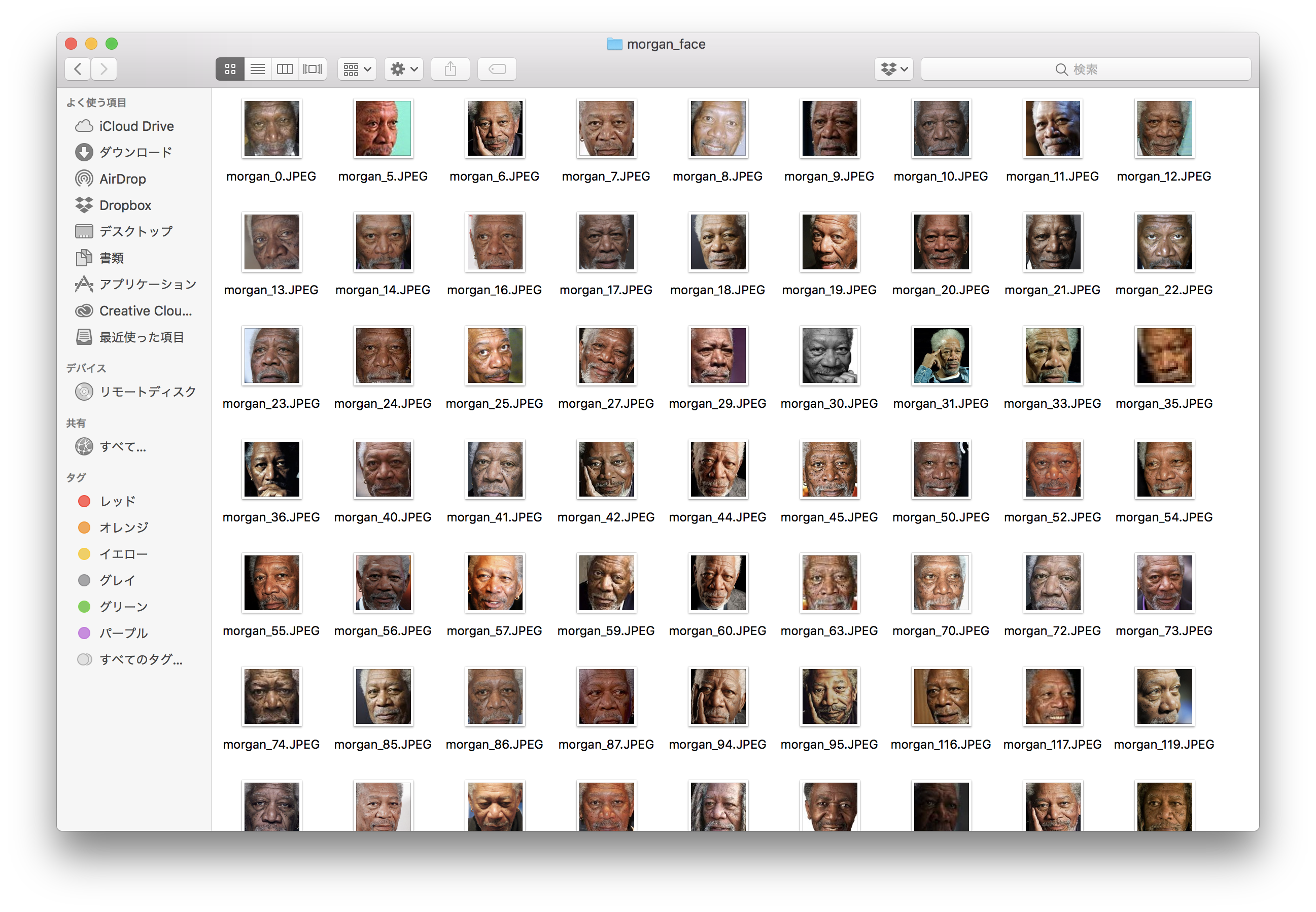
モーガンの画像はそのまま学習させてもいいのですが、写真によって背景が違ったりして学習に支障が出そうだったのでOpenCVを使って顔のみのデータセットを作り出しました。
(ちなみにココナッツチョコレートは手動でトリミングしました。)
import cv2
import numpy as np
import os
data_dir_path = 'YOUR_DIR_PATH'
save_path = 'YOUR_DIR_PATH'
cascade_path = 'YOUR_haarcascade_frontalface_default.xml7_PATH'
faceCascade = cv2.CascadeClassifier(cascade_path)
face_detect_count = 0 # 顔検知に成功した数
file_list = os.listdir(data_dir_path)
for file_name in file_list:
if file_name.endswith('.JPEG'): #フォーマット指定
img = cv2.imread(data_dir_path + str(file_name), cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face = faceCascade.detectMultiScale(gray, 1.1, 3)
if len(face) > 0:
for rect in face:
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.imwrite(save_path + str(face_detect_count) + '.JPEG', img[y:y+h, x:x+w])
face_detect_count = face_detect_count + 1
else:
print('image' + str(file_name) + ':NoFace')
顔認識にはOpenCVのデフォルト分類機を使用するため、分類機のファイルをローカルに作成してcascade_pathに指定します。
顔が検出されなかった場合は切り出しが行われないため、ここで若干データセットの画像数が減ります。
顔じゃない部分を顔として認識したり、小さく後ろに写り込んでいる人の顔を拾ったりもするので、精度を上げたい場合は手動でチェックする必要もあるかなと思います。
その2
モーガンとココナッツチョコレートの画像をOpenCVで100×100にリサイズし、全ての画像とそのラベルをnumpyのarrayに保存します。
今回はデータセットの画像が少なかったため、上下左右を反転させた画像も保存してデータセットを水増ししました。
import os
import numpy as np
import cv2 as cv
data_dir_path = 'YOUR_DIR_PATH'
tmp = os.listdir(data_dir_path)
tmp=sorted([x for x in tmp if os.path.isdir(data_dir_path+x)])
dir_list = tmp
print(dir_list)
image_arr=[]
for dir_name in dir_list:
file_list = os.listdir(data_dir_path+dir_name)
print(dir_name)
for file_name in file_list:
if file_name.endswith('.JPEG'): #フォーマット指定
print(file_name)
image_path=os.path.join(str(data_dir_path)+str(dir_name),str(file_name))
image = cv.imread(image_path)
image = cv.resize(image, (100, 100))
image = image.transpose(2,0,1)
image = image/255.
image_arr.append(image)
tmp = cv.flip(image, 1)
image_arr.append(tmp)
tmp = cv.flip(image, 0)
image_arr.append(tmp)
tmp = cv.flip(tmp, 1)
image_arr.append(tmp)
count = 0
for dir_name in dir_list:
file_list = os.listdir(data_dir_path+dir_name)
for file_name in file_list:
if file_name.endswith('.JPEG'): #フォーマット指定
for i in range(4):
class_arr.append(count)
count+=1
np_class_arr = np.array(class_arr)
np.save('all_class_data.npy',np_class_arr)
np_image_arr = np.array(image_arr)
np.save('all_image_data.npy',np_image_arr)
画像データを格納したファイルall_image_data.npyと、正解ラベルを格納したファイルall_class_data.npyが出力されます。
学習
いよいよモーガンとココナッツチョコレートを学習させます。
import numpy as np
from keras.layers.convolutional import Conv2D
from keras.layers.core import Activation
from keras.layers.core import Dense
from keras.layers import Dropout, Flatten, MaxPooling2D
from keras.models import Sequential
from keras.callbacks import EarlyStopping
from keras.callbacks import LearningRateScheduler
from keras.optimizers import Adam
from keras.optimizers import SGD
import sklearn.cross_validation
np.random.seed(48694062)
X_test=np.load('all_image_data.npy')
Y_target=np.load('all_class_data.npy')
a_train, a_test, b_train, b_test = sklearn.cross_validation.train_test_split(X_test,Y_target,test_size=0.15)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=a_train.shape[1:]))
# K=64, M=3, H=3
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
# K=64, M=3, H=3
model.add(Conv2D(64, (3, 3), data_format='channels_first'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('softmax'))
init_learning_rate = 1e-2
opt = SGD(lr=init_learning_rate, decay=0.0, momentum=0.9, nesterov=False)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['acc'])
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=0, mode='auto')
lrs = LearningRateScheduler(0.01)
hist = model.fit(a_train,b_train,
batch_size=128,
epochs=23,
validation_split=0.1,
verbose=1)
model_json_str = model.to_json()
open('image_recog_model.json', 'w').write(model_json_str)
model.save_weights('image_recog_model.h5')
score=model.evaluate(a_test, b_test, verbose=0)
print(score[1])
学習が終わると、image_recog_model.jsonとimage_recog_model.h5というファイル名で学習モデルと学習結果がそれぞれ出力されます。
学習の経過は↓のようになりました。
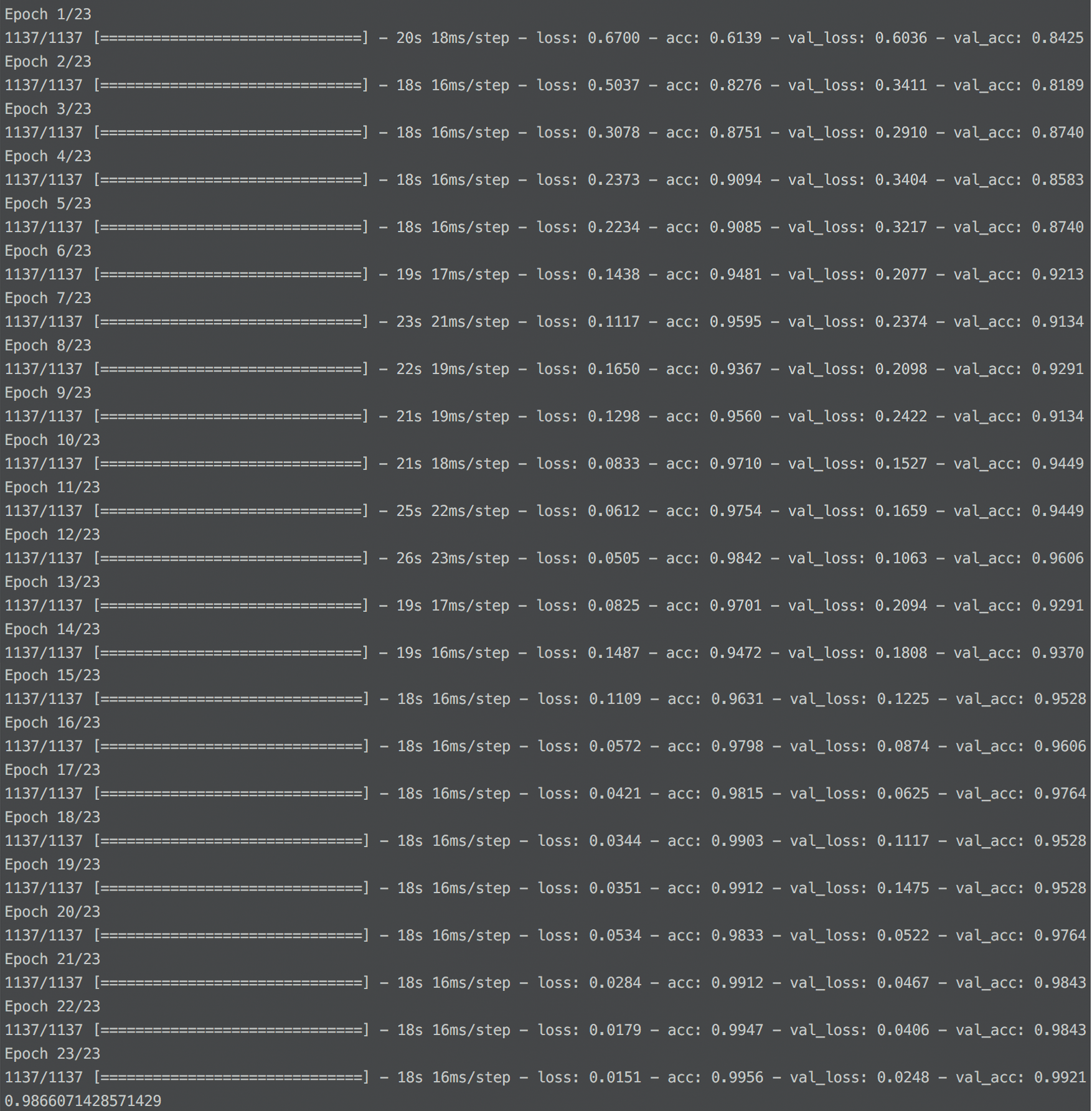
精度は約99%となっています(本当か...?)
認識
出力された学習モデルを用いて認識をしてみます。
今回認識に用いるのはこちらの似顔絵です。

本当は写真の方がよかったんですが、データセットに入ってしまっている可能性が高かったのでこちらにしました。
まあ似ていれば認識してくれるはず...
コードは以下の通りです。第一引数がファイル名、第二引数がファイルの拡張子となっています。
import numpy as np
from keras.models import model_from_json
from keras.utils import np_utils
from keras.optimizers import SGD
import sklearn.cross_validation
import cv2 as cv
from PIL import Image
import sys
np.random.seed(48694062)
model = model_from_json(open('image_recog_model.json').read())
image = cv.imread('YOUR_DIR_PATH'+sys.argv[1]+'.'+sys.argv[2]) #ファイル名は 第一引数.第二引数 で指定
type_arr = ['Morgan Freeman', 'Coconut Chocolate']
model.load_weights('image_recog_model.h5')
init_learning_rate = 1e-2
opt = SGD(lr=init_learning_rate, decay=0.0, momentum=0.9, nesterov=False)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['acc'])
if not image is None:
image = cv.bitwise_not(image)
image = cv.resize(image, (100, 100))
image = self.image.transpose(2,0,1)
image = self.image/255.
image = self.image.reshape(1,3,100,100)
else:
print('Image not found.')
sys.exit()
max_score = 0
answer_i = 0
for i in range(2):
sample_target = np.array([i])
score = model.evaluate(self.image, sample_target, verbose=0)
percent=(16.12-score[0])/16.12*100
print('{0} : {1:.2f}%'.format(type_arr[i], percent))
if percent>max_score:
max_score = percent
answer_i = i
print(self.type_arr[answer_i])
認識結果はというと...
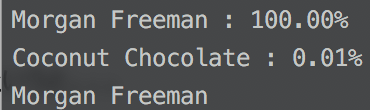
無事モーガンであると認識しました!
おわりに
今回、無性にまじめにふまじめな開発がしたくなったのでディープラーニングを用いてモーガン・フリーマンとココナッツチョコレートを識別してみました。
ちょっと書き換えればクラス数はもっと増やせると思うので、他のものを学習させることも難しくないと思います。
CNNの構造やハイパーパラメータの調整に関してはあまり深く考えずに作っているので改良の余地があるかもしれません。
めっちゃ楽しかったのでまた何か作りたいですね。
書き忘れてましたが動作環境はPython3系です。