Docker漬けの一日を共に〜Docker Meetup Tokyo #23 レポート〜 #dockertokyo



本日は、こちらのイベントに参加させていただきました。
Docker Meetup Tokyo #23 - connpass
参加人数は95人と大規模な勉強会なのですが、抽選倍率はさらに3倍程度あったようで大盛況。無事当選したことはなによりの喜び。ワッセロイ。
この記事では、本ミートアップの模様をお届けいたします。メインセッション3つ、LT枠5つというてんこ盛りノンストップ休憩なしというストロングスタイルの勉強会だったのですが、自分がよく知らない界隈、興味深い話が沢山聞けて物凄く楽しかったです。
訂正・補足事項などがあれば、濱田(@hamako9999)までメンションなりなんなりでご連絡いただければ、随時対応させていただきます。
それでは、皆さん、楽しんで行きましょう!
__ (祭) ∧ ∧ Y ( ゚Д゚) Φ[_ソ__y_l〉 Docker祭りダ ワッショイ |_|_| し'´J
講演内容一覧
| 講演内容 | 発表者 |
|---|---|
| Docker Meetup Tokyo #23 - Zenko Open Source Multi-Cloud Data Controller | Laure Vergeron, R&D Engineer and Technology Evangelist @Scality |
| 機械学習デプロイを支えるコンテナ技術 | Chie Hayashida, Cookpad |
| KubeCon EU報告(ランタイム関連,イメージ関連) | Akihiro Suda, NTT |
| KubeCon報告とmicroscanner試してみた | @CS_Toku |
| Docker_Meetup_Tokyo_23_gVisor_network_traffic_benchmark // Speaker Deck | makocchi |
| 5分でわかるCapabilityとPrivilege | Masaya Aoyama |
| Dockerイメージのバージョン管理はGitのCommitHashよりもTreeでやると良い | Yuki Yoshida |
| KubeCon EU でおもしろかったもの (caicloudのunionpay事例, cilium) | Toshihiro Iwamoto |
講演資料はこちらにまとめられています。
Docker Meetup Tokyo #23 - 資料一覧 - connpass
Avoiding public cloud vendor lock-in: how Zenko, the multi-cloud data controller can help

マルチクラウドという文脈で、AWSのストレージをさらに安く利用するアプローチが最初の始まりでした。マルチクラウドのユースケースはたくさんあります。Zenkoでは、マルチクラウドデータコントローラーを提供しています。
公式サイトはこちら。
Zenko CloudServer - Open Source S3 Server written in Node.js
プロダクトの主な特徴はこちら。
- Single Interface to any Cloud
- Allow reuse in the Cloud
- Always know your data and where it is
- Trigger actions based on data
一つのインターフェース(S3 APIベース)で、様々なクラウドへのインターフェースを利用可能。クラウドネイティブなフォーマットに対応し、APIで差分を吸収する。例えばDynamoDBへのアクセスなども同様のインターフェースでアクセス可能。
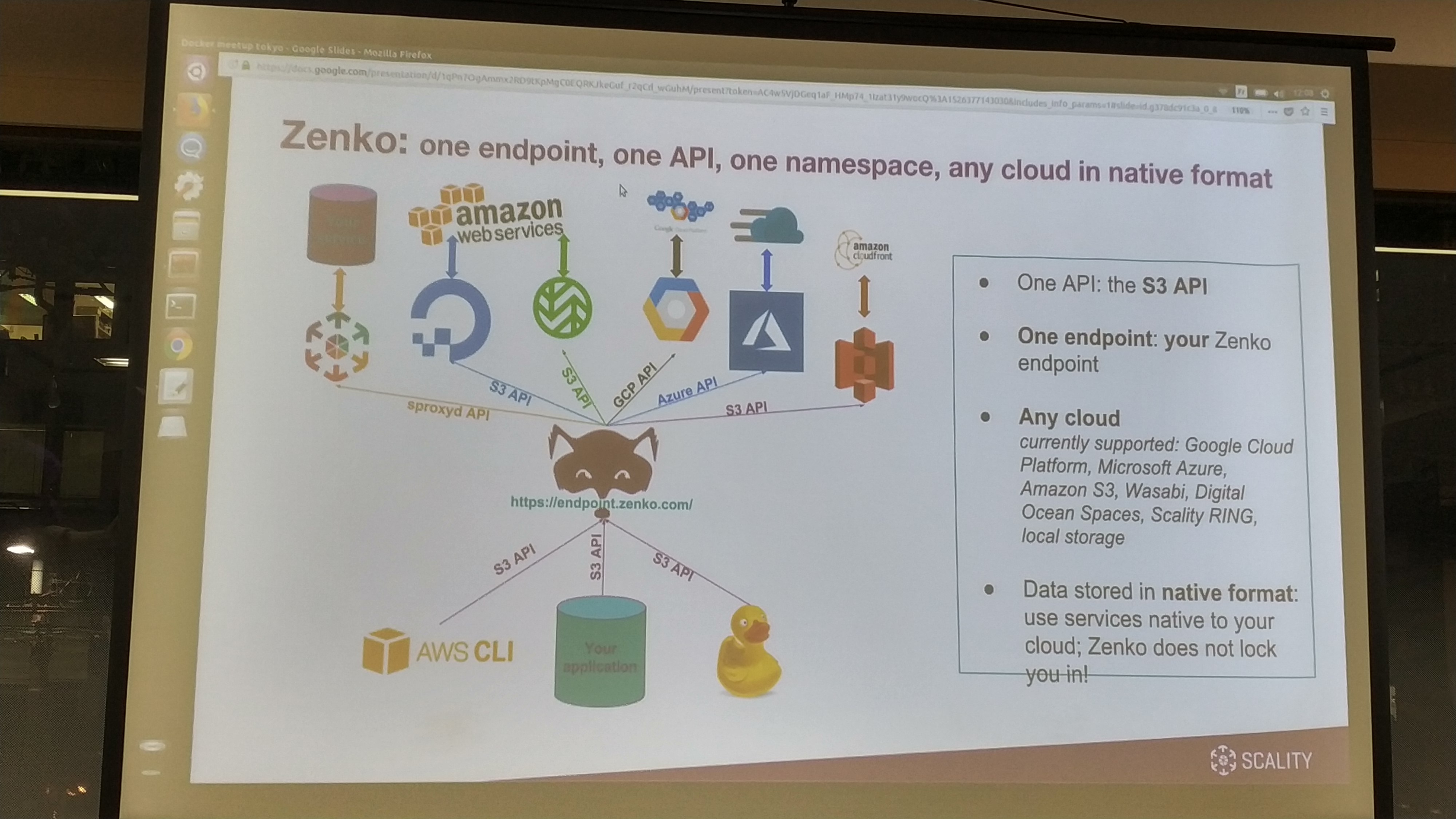
この特徴により、ベンダーロックインを防ぎます。。また、データ更新をトリガーとしたデータワークフローにより、データのレプリケーションやロケーション変更にも対応しています。
Zenkoは、一つのエンドポイント、一つのAPI、一つのネームスペース、そして複数のクラウドネイティブフォーマットを提供します。
クライアントアプリケーションからのインターフェースはS3API形式に一本化されており、その後ろで、独自サービス、AWSストレージ(S3、DynamoDB)、GCP、Microsoft Azureなどに対応。
Zenko Orbit(Multi-Cloud management made easy)
専用のUIが提供されています。1TBまでのバックエンドデータの扱いまで無料で利用可能。エンドポイント、ネームスペース、APIのバージョン、異常コンテナのブロックなどが可能。
Zenko S3 API Support & Roadmap
現在は、Core S3 APIs、Adbanced S3 Apisに対応。2018年には、バケットライフサイクルや、メタデータ検索拡張にも対応予定。
Zenkomunity

デベロッパーコミュニティーの構築に注力している。
まとめ(濱田主観)
最後に、動作デモをみることができました。基本的なセットアップはWebのGUIベースで実施可能。minicubeから、S3API(筆者には見慣れたAWS CLIベースのインターフェース)で、Windows Azure上にバケットが作成される体験はなかなか衝撃的でした。ストレージの種別が隠蔽されているのは、面白いですね。
細かな仕様の違いをどう吸収するのかはいろいろ興味がつきませんが、まずは、触ってみようと思います。
Docker for Machine Learning(機械学習を支えるコンテナ技術)
講演者はクックパッドの、Chie Hayashidaさん。
PyConJPでPySparkについて発表したり、Web+DB Pressで機械学習系の記事を書いている。実験管理のOSSを作ったりしている。
機械学習の活かし方
機械学習とは、「人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法」。
ただ、理論自体は1960年ぐらいの昔からあったが、普及には2つのハードルがあった。
- 機械学習アルゴリズムの実現の難しさ
- アプリケーションとしての導入の難しさ
機械学習のプロセスとは、データの特徴を表す「モデル」をつくり、それを猫だと判定できるようにするもの。ただ、大量のデータと大規模な計算リソースが必要で、それだけの物理装置を用意することができなかった → 実用化が難しかった。
最近発展している背景には、実現するためのハードウェアやソフトウェアの進化があることが関係している。
- hadoop
- GPU
- ライブラリの確率
- Arxiv
- GitHubによるソースコードの公開
これらにより、誰でも機械学習を実装できるようになった。しかし、アプリケーションとしての導入の難しさは残る。モノリシックな環境において、機械学習導入は難しいものだった。各ロジックのインターフェースが複雑で、ソフトウェアスタックの違いを吸収するのが難しい。通常のWebアプリケーションとは、言語やライブラリが全然違う。
さらに、データサイエンティストにとって、サービス開発に必要な非機能要件の検討が難しい。作ったら、作りっぱなしになったり、運用要件の確率や可用性、冗長化の設計に慣れていなかったりする。そこに、コンテナ技術の進歩による機械学習のマイクロサービス化が進んできた。
- 独立したソフトウェアスタックによる、それぞれのロジックの分離
- リソースの分離
- 非機能要件をコードで管理
- 作業分担を明確化
- CD(Continuous Delivery)
マイクロサービス的に1サービスのみを独立した機械学習アプリケーションとして提供可能になった。開発もデバッグも、依存関係が整理されるので、非常にやりやすくなった。
コンテナ技術により、今までの機械学習アプリケーション導入の難しさが解消されつつある。
とはいえ、アーキテクチャの複雑さの問題がなくなったわけではない。
アーキテクチャ検討例①「コンテナの分離」
モデルの違いにより必要なリソースタイプが異なる。例えば、データ処理はメモリを使うことが多く、推論はCPUやGPUを酷使する。ここは分けたほうがリソースコーリツが良い。
モデルの再利用を意識したコンテナの分け方がキモになる。
アーキテクチャ検討例②「スケーラビリティの設計」
コンテナの分離により、コンテナ毎のスケーラビリティの確保が可能
アーキテクチャ検討例③「コンテナ配置設計」
各ハードウェアリソースに対するコンテナの配置を物理的に考慮する必要あり。
アーキテクチャ検討例④「GPU環境へのデプロイの難しさ」
- cgroupによるリソース管理の対象外なので、GPUへのデータ転送などが難しい
- GPUリソースの監視の導入
- GKEでもalphaクラスタでしか使えない
アーキテクチャ検討例⑤「モデル再学習」
モデルの再学習にはGPU環境との連携が必要。流行語の変遷を追うためには、定期的に再学習を実施する必要あり。
Kubeflowについて
- 中小規模の利用にはスペックオーバーな気がする
- tf.servingは便利で、それで十分かも
- 分散学習が必要な規模のプロジェクトは日本では多くない
- 実験環境とプロダクション環境の切り分けも必要
フルマネージドサービス
- SageMaker
- Cloud ML Engine
- Azure ML
かなり進化してきたので、便利に使える感触はあるが、まだまだ発展途上の感がある。
実証段階からDockerを利用する
研究開発部には所属しているが、プロダクトとしてデプロイすることを前提としている。そのために、プロダクトデプロイのためのコンテナも意識する必要がある。
CookieCutter Docker Science
- リサーチャーもDockerを利用可能
- 実験段階から環境を共通化
- 実験の共有
- 再現性の担保
- デプロイの簡易さ
まとめ
- コンテナ技術は機械学習デプロイに欠かせない存在になりつつある
- マイクロサービスにより全てが解決するわけではないが、サービスの堅牢性を高める手段として便利
- 実験のタイミングからデプロイを意識する
- 分散学習やGPUを用いた推論への対応やマネージド・サービスへの期待もある
KubeCon EU報告(ランタイム関連,イメージ関連)
KubeCon + CloudNativeCon EU 2018、に参加してきました。そこで自分的に気になったトピックを4つほど紹介します。
参加者4000名、日本からは50名ほど。どんどんDocker界隈が盛り上がっているのを肌で感じます。
トピックはこちら。
- Container Isolation at Scale(... and introducing gVisor)
- The Route To Rootless Containers
- Entitlements: Understandable Container Security Controls
- Building Images on Kubernates - Toward a first class aproach
gVisor
コンテナとホストカーネルの愛大にはいり、セキュリティを強化しtOCIコンテナランタイムをrunscを提案
- Linuxカーネルをユーザランドで再実装(Go)
- ptrace版とKVM版がある
- runcの代替として使える
- Meltdownを防ぐデモが展示されていた
嬉しいことは、CPUのセキュリティリスクからコンテナーが隔離される点など。
- 向いているもの
- 小さいコンテナー
- 向いていないもの
- システムコールを頻繁に呼ぶもの、信頼されたイメージ
手元で試して見た限りでは、gvisorを利用すると、おおよそ7倍ぐらい処理が重たくなる感触。
The Route To Rootless Containers
概要:root権限無しでコンテナランタイムを動かすことで、セキュリティを強化する取り組み
- 課題1:複数ユーザーをコンテナーで利用する場合がある
- newuidmapを使用する
- 課題2:cgoupsを利用可能にする
- 予めrootでchownしておく
- 課題3:CoWファイルシステム
- Ubuntuならrootlessでoverlayfsが利用できる
Entitlements: Understandable Container Security Controls
セキュリティコントロールをもっと簡易にできるようにする試み。Docker runにつけるフラグが複雑すぎるので設定ファイル
Imageを作る時に、Imageにサインする動作。
Docker統合の準備はできているが、デザインが固まっていないため、まだPRはでていない。Kubernatesへの実装も容易されている。
Building Images on Kubernetes - Toward a first class aproach
概要:Kubernetes上でコンテナイメージをビルドする取り組み。
Kubernatesに関係するイメージビルドツールが登場している。是非一度触ってみて欲しい。
LT: KubeCon報告とmicroscanner試してみた
気になった要素
- gVisor
- CSI
- Cilium
- セキュリティ系
- Kube-bench
- microscanner
Aqua Securityuが出しているツール。microscannerは、コンテナイメージに対するセキュリティスキャンをしてくれる。Free版、SaaS版、PaaS版がある。Free版はパッケージスキャンのみ。
Free版を試してみた
- 登録してトークンを取得
- Dockerfileの最後にコマンドを追加
- 結果を確認
パッケージが古いほど、沢山脆弱性がでてくる。導入コストは低いので、とりあえずやっておいて損はないのでは?まずはFree版で試してみましょう!
LT: gVisor での Network Traffic の性能を比較してみた
ネットワークトラフィックについて、性能をためしてみた。
install gVisor
gVisorの導入の仕方は簡単。Dockerで動かす場合は、runtimeを追加してあげればOK。
limitation of gVisor
- Dockerで動かすなら 17.09以上が必要
- Podの中に1つのコンテナしかサポートしてない
- 一部のsystem callが動かない
gVisor's Network Performance
iperf3を利用。比較のためにVM同士とruncも計測。実際に計測してみると、かなりネットワーク性能が落ちる。Sentryがpacketを処理するためにそこがネックになる。
まとめ
普通に使うとかなりNetwork性能は落ちるが、--network=hostを設定することで、ある程度はパフォーマンスを出すことができる。その他考慮点を頭に入れ、適切なユースケースで使うのが望ましい。
LT: 5分でわかるCapabilityとPrivilege
root権限と一口にいっても、rootの中にも複数の種類が割り当てられている。デフォルトのCapabilityではホスト名の変更は受け付けられない。その場合は、必要なCapabilitiesを渡してあげる必要がある。
LT: Dockerイメージのバージョン管理はGitのCommitHashよりもTreeでやると良い
(濱田:ごっつ面白かったので資料をもらいたい・・・)
- AWSのECRとECSを利用
- デプロイはTeffaform
- アプリはGo、Python、Javaなどいろいろ
- GitHubとDrone
- 開発はGitHub Flow
- デプロイにはGitLab Flow
開発の流れは以下の通り
- ECRを本番環境AWSアカウントに構築
- イメージは不要な更新により即、プロダクション環境に影響がある
- 開発環境からのスイッチロールでアクセスを制限することにより、ECRにアクセスする人を制限
- GitLab Flowにより、各環境(開発、ステージング、本番)用にブランチを作成
- デプロイ先環境とブランチを1対1で対応させることで、デプロイを直感的にわかりやすくしている
このフローをそのまま回すと、ECRにイメージが各環境ごとに複数作成されるためムダが多い。そのため、Treeを利用してイメージにタグを付けることで、ディレクトリ構成のファイル内容と同一のものは同じイメージを利用することで、ムダを省きデプロイフローをシンプル化することに成功した。
LT: KubeCon EU でおもしろかったもの (caicloudのunionpay事例, cilium)
Kubernetes on Supporting $8 Trillion Card Payments in Chine
- SSO
- 一回ログインすればk8sでもOpenStackでもつかえる
- マルチテナント
- ネットワーク
非常に面白いセッションだったので、ぜひ皆さんもググって参考にして欲しい。
Accelerating Envoy with the Linux Kernel
参加レポートなど、まとめは、近日こちらで公開予定!!
まとめ「Docker界隈あつすぎやろ、これ」
ぶっちゃけ自分は、Dockerやコンテナ全般に対して知見が深いわけではないので、非常に楽しみにしていた勉強会でした。期待にそぐわず、セッション内容が多岐にわたっていて盛りだくさんで、各発表者の熱量もすごく、懇親会も含めてすごく楽しめた勉強会でした。
AWS界隈でも既に実績が豊富なECSから、東京リージョンが熱望されるFargate、GAが待ち遠しいEKSなど、今後のリリースロードマップが非常に豊富で、楽しみなところ。
アプリケーションホスティングの選択肢として完全に無視できなくなっているコンテナ界隈。今後もウォッチし続けていこうと思います。
それでは、今日はこのへんで。濱田(@hamako9999)でした。