
はじめに
以前からちょこちょこ新しいWEBサービスを作っているということをQiitaの記事に掲載していましたが、このたび「SCORERA(verβ)」を正式にリリースしました。
(現在、クラウドファンディングも行っています。コンセプトに共感された方は、ぜひご支援をお願いします!)
サービス構築、リリースにあたって色々と知見がたまったので、作成過程で詰まったことや、リリースにかかる作業のうち技術的な側面のものを中心に公開しておこうと思います。
目次
前提
トピック
- SCORERAのディレクトリとモジュール構成
- RxJSの状態管理
- 外部ライブラリの選定
- FirebaseのRealtime DatabaseとFirestore
- クライアントサイドのエラー取得
- AngularプロジェクトのSEO
- 技術面以外でやったこと、やること
前提
どんなサービス?
「SCORERA(verβ)」はスポーツ競技や文化系競技(将棋、ゲームなど)といった大会の集客、エントリ管理、結果管理を行うことのできるサービスです。
これまで各競技の大会で、集客だけを行うサービス、結果の管理だけを行うサービスはありましたが、大会全般をWEB上で管理しようとするサービスはほとんどありませんでした。
SCORERAは「大会運営を簡単に、より良いものに」することをコンセプトに、大会運営のプラットフォームとなることを目指していきます。
使用している技術、サービス
サーバーサイド
- Firebase Authentication(ユーザー管理)
- Cloud Firestore(データベース管理)
- Cloud Functions for Firebase(バックエンド処理)
- Cloud Storage for Firebase(ストレージ)
- Firebase Hosting(ホスティング)
- SendGrid(メール配信)
クライアントサイド
- Angular5(JSフレームワーク)
- Angularfire2(AngularとFirebaseのミドルウェア)
- Angular Service Worker(Service Worker管理)
- Angular2 materialize(デザインフレームワーク)
- Angulartics2(タグマネージャー管理)
- ngx-translate(多言語対応)
- Sentry(クラッシュ管理)
トピック
SCORERAのディレクトリとモジュール構成
SCORERAはAngularとFirebaseで作成していますが、この組み合わせでどのような構成がベストプラクティスなのか、といった情報は今のところあまり公開されていないので、かなり試行錯誤しながら設計しています。
2018年4月リリース時点で、SCORERAの大枠のディレクトリ構成は下記のようになっています。
プロジェクト
├ e2e
├ functions // Cloud Functions関連
│ ├ src // オリジナルの構成部分
│ │ ├ api
│ │ ├ db
│ │ ├ storage
│ │ ├ index.ts
│ │ └ util.ts
│ ├ environment.ts
│ ├ package.json
│ └ tsconfig.json
├ src
│ ├ app // オリジナルの構成部分
│ │ ├ account
│ │ ├ competition
│ │ ├ contact
│ │ ├ core
│ │ ├ dashboard
│ │ ├ favorite
│ │ ├ note
│ │ ├ search
│ │ ├ shared
│ │ ├ site
│ │ ├ sponsor
│ │ ├ animations.ts
│ │ ├ app-routing.module.ts
│ │ ├ app.component.ts
│ │ └ app.module.ts
│ ├ assets
│ ├ environments
│ ├ favicon.ico
│ ├ index.html
│ ├ main.ts
│ ├ manifest.json
│ ├ ngsw-config.json
│ ├ polyfills.ts
│ ├ test.ts
│ ├ tsconfig.app.json
│ ├ tsconfig.spec.json
│ └ typings.d.ts
├ .angular-cli.json
├ .editorconfig
/// 省略
├ tsconfig.json
└ tslint.json
基本はangular-cliとfirebase-toolの構成
SCORERAのディレクトリ構成は、angular-cliとfirebase-toolで自動作成されたものをベースにしています。
グローバルに上記ライブラリを入れた状態で下記コマンドを実行すると、「オリジナルの構成部分」と書かれたところ以外は大体同じ1になるはずです。
// angular-cli
ng new project-name --service-worker
// firebase-tool
firebase init
機能モジュールを読み込む単位は、ユーザー体験(UX)に合わせて
Angularの公式ガイドでは、モジュールをコアモジュール、共有モジュール、機能モジュールの3種類に分類しています。
SCORERAではこのガイドにならってモジュールを配置し、「アカウント管理」「大会管理」といった単位で機能を切り出し、それぞれをAccountModule、CompetitionModuleのような形で配置しています。
ただここで考慮しないといけないのが、Angularは基本的にモジュール単位でロードを行う2ので、どこまでを初回ロードの対象とするか、といった視点からのモジュール構成です。
SCORERAは当初、ページ単位でモジュールの配置を考えたのですが、それだと必ずしもユーザーにとって得にならないと考え直し、ユーザー体験(UX)と離脱シーンをベースにしてモジュールを配置しました。
まず、ユーザーの属性とその目的を下記のように書き出しました。
- サイト訪問者(非会員):サイトのことを知りたい
- サイト訪問者(非会員):サイトのことを問合せたい
- 大会運営者(会員):サイトの機能をフルに利用したい
- 大会参加者(非会員):自分の参加する大会のみを見たい
- etc.
書き出しが終わったら、次はその優先度を考えます。
上記の場合で一番重視すべきは「大会参加者(非会員)」です。初めてサイトを訪問したときにある程度サイトの印象が決まり、サイトからの離脱へ繋がってしまうため、まずここを中心に設計を考えました。
「自分の参加する大会」、つまりCompetitionModuleを初回ロード用の上位モジュールとして組み込み、さらに下階層で「大会運営者(会員)」しか使わない機能(編集や管理画面など)は下位モジュールとして切り出して初回ロードの対象から外しました。
RxJSの状態管理
ここでいう状態管理とは、ReduxやFluxに代表されるデータアーキテクチャのことです。
Angularだとngrxという公式ライブラリを使えばReduxのような状態管理をすることができるのですが、SCORERA設計時にはまだそのライブラリは公式となっていなかったので、Angularに標準で搭載されていたRxJSのみで設計を行いました。
RxJSを使えばWEBアプリ上で自由にデータの受け渡しを行うことができるのですが、逆に自由すぎて、何も考えずに使っていると設計が破たんします。
unsubscribeを忘れずに!
RxJSはSubjectの作成からunsubscribeまでを必ずセットで考える必要があります。
というのも、unsubscribeせずに他のコンポーネントにいってそのままにしておくと、そのストリームはその後もデータを受け続け、メモリを圧迫していきます。
もしそのような設計になっている場合は、ページ遷移を繰り返しているうちにパフォーマンスが飛躍的に落ちていくので注意してください。
なので、SCORERAでは次のようにしています。
private subject: BehaviorSubject<string>;
public state$: Observable<string>;
// コンポーネント読み込み時
ngOnInit(): void {
this.subject= new BehaviorSubject<string>('data')
this.state$ = this.subject.asObservable();
this.Subscription = this.state$
.subscribe((str: string) => {
// 処理
});
}
// 離脱時
ngOnDestroy(): void {
if (this.Subscription) {
this.Subscription.unsubscribe();
this.Subscription = null;
}
})
コンポーネント読み込み時(ngOnInit)にBehaviorSubject(Subjectの拡張)を読み込んだときは、そのコンポーネント離脱時(ngOnDestroy)にunsubscribeを行っています。
状態管理は上位モジュール単位で
SCORERAは設計当初、モジュール単位でサーバーサイドであるFirestoreと接続していたのですが、その設計だと同じFirestoreのcollectionにたいして複数の接続を行ってしまうため、パフォーマンス低下につながっていました。
そこでFirestoreとの接続を上述した上位モジュールだけに絞り込み、それよりも下位のモジュールに対しては、上位モジュールからRxJSで流し込むという設計に修正しました。
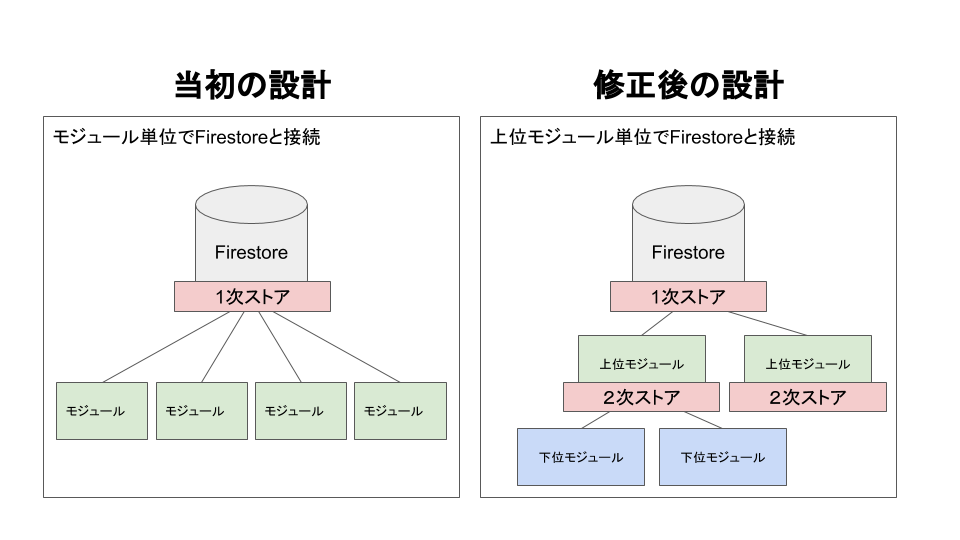
これによりFirestoreとの接続回数が激減してパフォーマンスが向上したのですが、結局上位のストアから下位のコンポーネントにデータを流し込むというReduxの思想と変わらない設計になりました。
外部ライブラリの選定
SCORERAでは外部ライブラリを使用するにあたって、次のようなことに注意しました。
- 原則、公式のライブラリを使う
- 公式でない場合
- 頻繁に更新されているライブラリを使う
- 設計思想にあったライブラリを使う
- こちらでオーバーラップできるくらいの小さなライブラリを使う
以前参加したプロジェクトでReactを扱ったときに、ライブラリ選定でかなり苦しめられたので、今回のプロジェクトではできるだけ安定したライブラリを使おうと思っていました。
ただ結局のところどのライブラリも不具合は起こるのですが、サポートがあるかないかで対応が大きく変わってくるので、そのライブラリが少しでも信頼できることが重要です。
Angular2 materialize
SCORERAは基本的にメジャーなライブラリばかり使用していますが、その中でAngular2 materializeだけはちょっとマイナーなライブラリになっています。
このライブラリはデザインフレームワークである「Materialize」をAngular用にラップしたもので、Googleのマテリアルデザインというデザイン思想をベースに設計されています。
SCORERA設計当初から「マテリアルデザインで作りたい!」という気持ちが強かったのですが、マテリアルデザインの公式ライブラリである「Angular Material」はまだほとんど実装が進んでおらず、選択肢としては難しいものでした。
そこでその時頻繁に更新のあったAngular2 materializeを採用し、順調に実装を進めていたのですが、大元であった「Materialize」の新バージョンが出るとともに更新が途絶え、いくつかの不具合は放置されたまま音沙汰がなくなるという事態になりました。
今は不具合があった場合は自分でオーバーラップして対応していますが、個人で作成してもらっているライブラリの利用には常にこういったリスクがあるんだと肝に銘じています。
FirebaseのRealtime DatabaseとFirestore
SCORERAを作り始めた当初、FiresbaseのRealtime Database(RTDB)を利用していました。
RTDBはデータ変更があると接続している端末すべてに即データを送ってくれるという優れものなのですが、データの接続点が第一階層に1つしかなく、データ更新時はその階層以下に登録されているjsonツリーがすべて送られてくるという仕様になっています。
なので、データは基本的に第一階層でしか分けることができず、Relational Database(RDB)のようなリレーションを組みたい場合は、全てのjsonツリーに関連するjsonツリーのパスを持たせなければ実現できません。
また、RTDBはクエリが1つしか設定できず、検索のような機能を実装したい場合は1クエリだけ絞って残りのデータをすべてダウンロードし、それ以降はクライアント側で絞り込みを行う必要がありました。
RTDBはダウンロード量によって課金額が変わるので、大量のデータから絞り込みを行うようなアプリケーションには不向きといえます。
Collection単位で接続ができるFirestore
そんなことを思っていた矢先に登場したのが、Firestore(ベータ版)です。
FirestoreにはCollectionという概念があり、第二階層以降であってもクライアントサイドと直接接続を行うことができるようになりました。
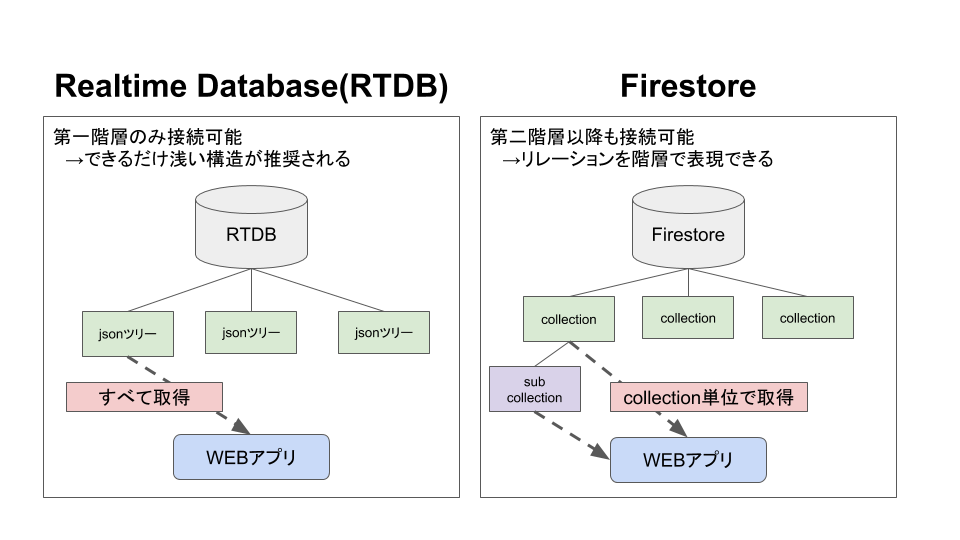
これによって各jsonツリーごとに保有しなければなからかった他のjsonツリーへのリレーションパスを設定する必要がなくなり、データ追加毎に行っていた1対1リレーション接続のための更新をする必要がなくなりました。
また、クエリも複数指定することが可能になり、必要な条件で絞り込んだリクエストを送ることが可能になっています。
このほか、Firestoreに切り替えることで上記に挙げたRTDBの課題は解決されることになりましたが、特にRTDBでのリレーション処理は鬼門だったのでこれがある程度解決できた3のは大きいです。
その他の比較は公式ガイドに記載されていますので、そちらを参照してください。
クライアントサイドのエラー取得
2017年に投稿されたこの記事にも記載されていましたが、SPA構築にあたってクライアントサイドのエラー情報を管理することは非常に重要だと思っています。
その記事では自前でエラーを収集する方法が記載されていましたが、私は「Sentry」というサービスを利用することにしました。
AngularにSentryを実装する
AngularでSentryを実装することはそれほど難しくなく、プロジェクト配下で下記コマンドを実行し、アカウントを作成後に発行されるAPIキーをモジュールに読み込ませるだけで使用できるようになります。
npm install raven-js --save
import Raven = require('raven-js');
import { BrowserModule } from '@angular/platform-browser';
import { NgModule, ErrorHandler } from '@angular/core';
import { AppComponent } from './app.component';
Raven
.config('https://<key>@sentry.io/<project>')
.install();
export class RavenErrorHandler implements ErrorHandler {
handleError(err:any) : void {
Raven.captureException(err.originalError || err);
}
}
@NgModule({
imports: [ BrowserModule ],
declarations: [ AppComponent ],
bootstrap: [ AppComponent ],
providers: [ { provide: ErrorHandler, useClass: RavenErrorHandler } ]
})
export class AppModule { }
このサービスを利用すると、クラッシュした端末の情報、エラーの内容、発生日時、同一エラーの発生回数といった情報を取得することができるようになります。
また、WEBアプリ側のリリースバージョンを仕込むこともできるので、どのバージョンのエラーかを特定することも可能です。
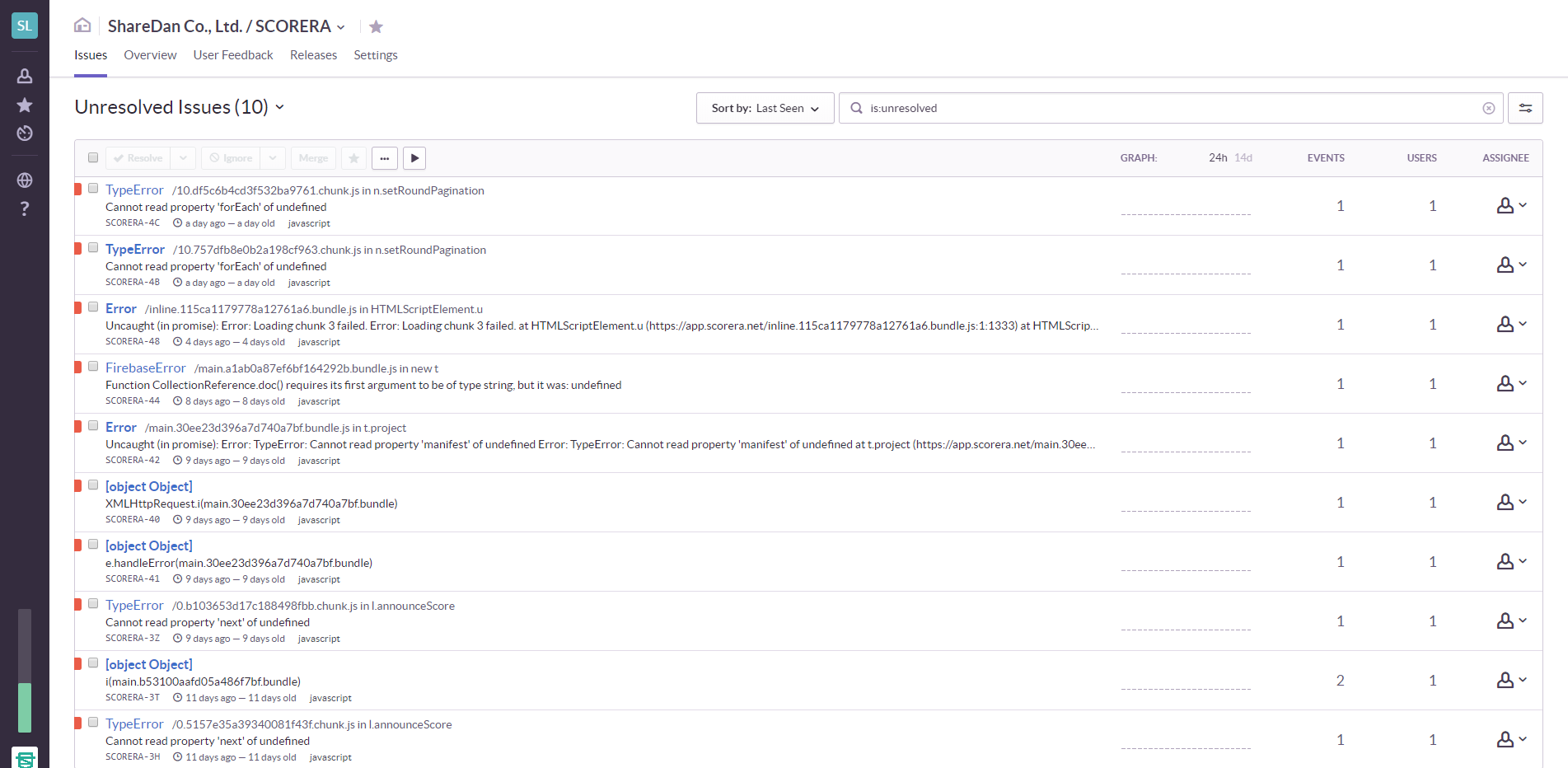
エラー管理画面
AngularプロジェクトのSEO
昔からSPAのWEBアプリケーションはSEOが苦手でした。
botがJavaScriptを読み込んでくれず、内容のないindex.htmlの結果でインデックスされてしまうというのが常でしたので、今回もきっとそうだろうと思ってSEOを考えていました。
で、実際のところSearch ConsoleのFetch as Googleでレンダリングしてみた結果がこちらです。
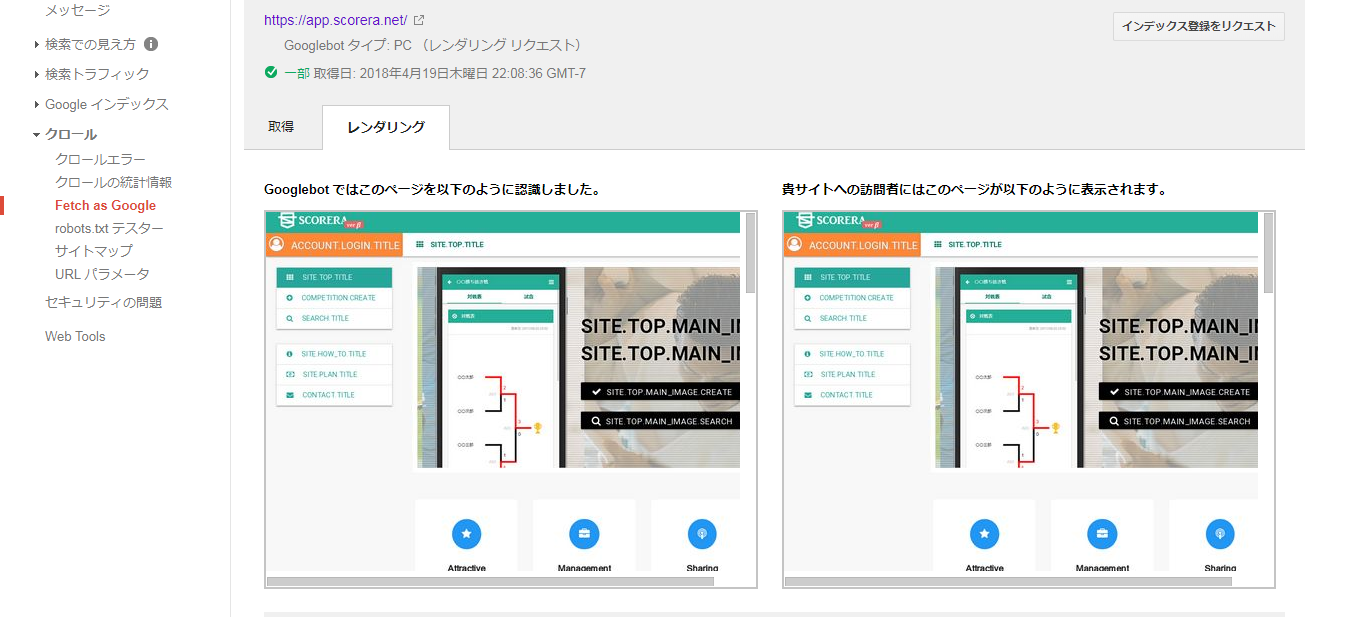
あれ、もしかしてレンダリングされてる?
今回、Angularのプロジェクトとしてやれること以外は特に何もしていなかったのですが、なんとJavaScript実行後の画面をbotが認識してくれるということがわかりました。
polyfillを使って表示を直す
レンダリングされていることに浮かれていたのも束の間、よくよくレンダリング後画面を見てみると、文字情報がなにやらおかしい。
どうもDOMの非同期レンダリングにかかる部分がうまく表示されていないようです。
インデックスはされていたので公開当初はそのままでいいかと思っていたのですが、スパムのような状態でインデックスされてしまったため、検索順位は日が経つにつれてどんどん下がっていきました。
中途半端なレンダリングをインデックスされてしまうのは、SEO的にはむしろ逆効果になっていたようです。
そこでサーバサイドレンダリング(SSR)を含む対応策を色々と考えたのですが、それらによる工数を考えるとなかなか実行に踏み切れませんでした。
色々模索しているうちにこの記事と出会い、googlebotのレンダリング機能はchromeの41と同程度のスペック4だということがわかりました。
つまり、IEに対して行うようなレガシーブラウザ対応を行えば、きちんと表示してくれるということです。
angular-cliで作成したプロジェクトには、最初からIE向けのpolyfillがコメントアウトされているので、それらを有効化しました。
/** IE9, IE10 and IE11 requires all of the following polyfills. **/
import 'core-js/es6/symbol';
import 'core-js/es6/object';
import 'core-js/es6/function';
import 'core-js/es6/parse-int';
import 'core-js/es6/parse-float';
import 'core-js/es6/number';
import 'core-js/es6/math';
import 'core-js/es6/string';
import 'core-js/es6/date';
import 'core-js/es6/array';
import 'core-js/es6/regexp';
import 'core-js/es6/map';
import 'core-js/es6/weak-map';
import 'core-js/es6/set';
その後、再度Fetch as Googleで検証してみた結果がこちらです。
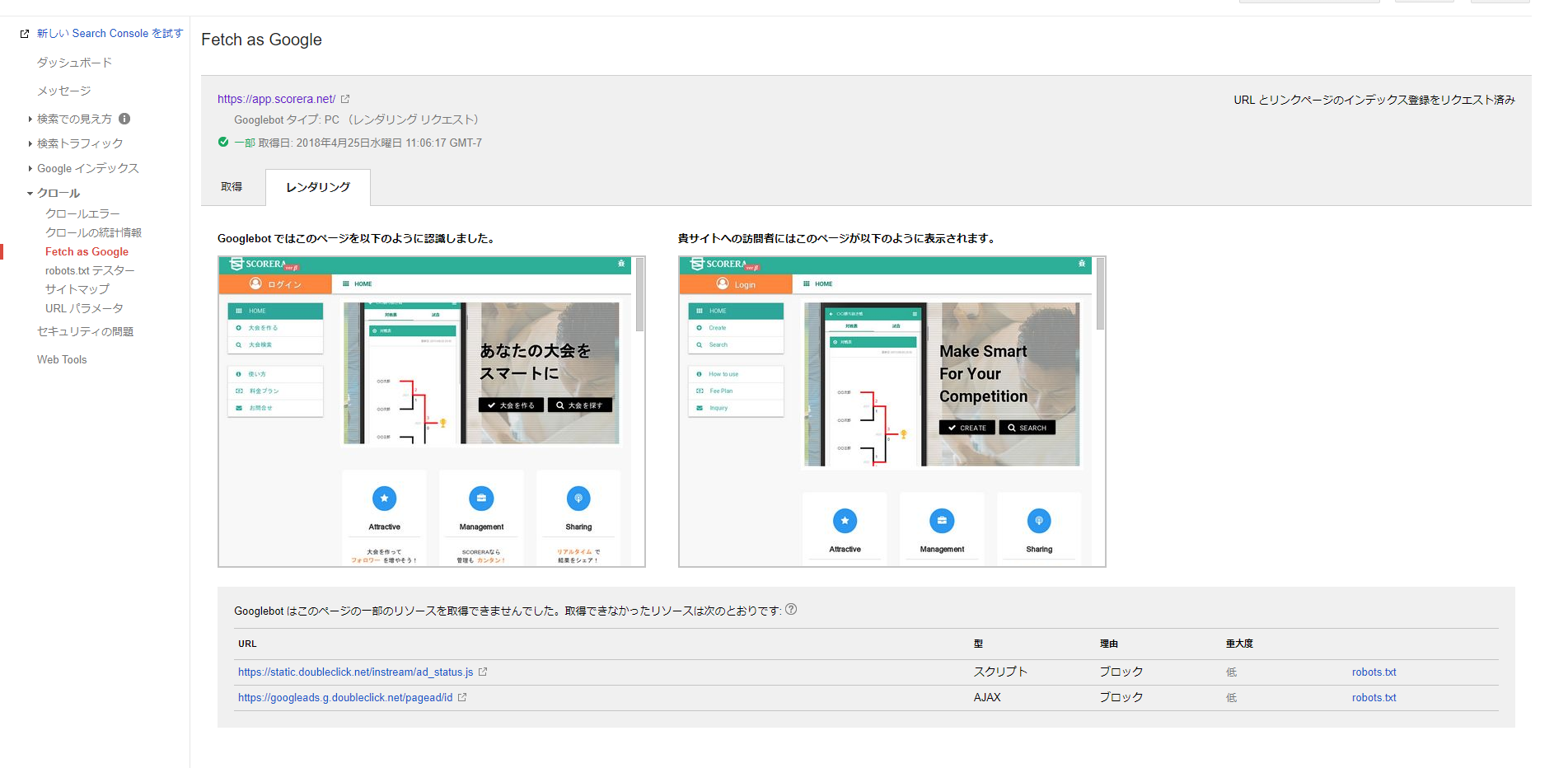
問題なくレンダリングされるようになりました。
『これでSSRも必要ないな』と思ったのですが、結局JavaScriptを実行してくれるのはgooglebotだけなので、この記事を参考にtitleとmetaタグだけはサーバーサイドで差し替えるようにしました。
sitemap.xmlの対応
公開されている大会をインデックスしていきたかったので、SCORERAではsitemap.xmlを動的に作成することにしました。
スプレッドシートでsitemapを作成するという新たな選択肢もありましたが、ページの順位づけも行いたかったので、伝統的なsitemap.xmlの作成で対応することにしました。
Cloud Functionsでsitemap.jsというライブラリを読み込み、動的にsitemap.xmlが作成される環境を作ります。
firebase.jsonのrewritesに新しいsourceを追加し、Cloud Functionsとhostingを連携させます。
"rewrites": [
{
"source": "/sitemap.xml",
"function": "returnSiteMap"
},
次にfunctionsでnpm install sitemap --saveを実行して、sitemap.jsをインストールします。
あとはhttpsトリガーでfunctinsを起動させ、sitemap.xmlを作成します。
exports.returnSiteMap =
functions.https.onRequest((req, res) => {
const sitemap = sm.createSitemap({
hostname: 'https://app.scorera.net/',
cacheTime: 600000, // 600 sec - cache purge period
urls: [
{url: '/', priority: 1.0},
{url: '/search', priority: 0.6},
]
});
// ここに公開中の大会を取得するコード
// sitemapの作成
sitemap.toXML((error, xml) => {
if (error) {
return res.status(500).end(
}
res.header('Content-Type', 'application/xml');
res.send(xml);
});
});
これでbotが参照する都度、新しいsitemap.xmlを返すようになりました。
技術面以外でやったこと、やること
市場調査
SCORERAを開発したきっかけは、日本合気道協会が主催する『国際合気道フェスティバル』の運営を楽にするため、ということだったのですが、いざやってみると色々な問題点がわかってきました。
そしてこの問題点を他の大会運営者にもヒアリングしてみたところ、やはり同じようなところで問題になることが多かったため、ある程度の需要があるのではないかと推測しています。
スポーツイベントの国内市場は約1.7兆円5、東京オリンピックに向けて各団体が盛り上がっていることも踏まえて、チャレンジしてみる価値はあるという結論に至りました。
ユーザーテスト
ここ2カ月ほど、クローズドβとして友人を対象にユーザーテストを行っていました。
実際にユーザーが使用している場面を横から見ていると、ユーザーは驚くほど文章を読みません。
判断基準の多くは直感で、色や形といった視覚的な情報がほとんどを占めていました。
正直このユーザービリティーの部分はまだまだ粗削な部分が多く、改善すべき点だらけですが、ユーザーの声を聴きながら正式版に向けてブラッシュアップをしていこうと思います。
クラウドファンディング
いい機会なので、本サービスをクラウドファンディングに投稿させていただきました。
友人と一緒にCampfireの本社に飛び込み、担当していただいた方から多くのアドバイスいただきつつプロジェクトを作成しました。
正直マーケティングは門外漢で、わからないことばかりの中右往左往しています。
ここからはプロジェクトページやSNSで支援状況等の進捗を報告していく予定です。
さいごに
制作開始から約1年半。正直まだまだ書き足らないくらいのハックがありますが、それらはまた逐次記事にしていこうと思います。
サービスそのものはこれからどんどん改良を加え、さらに使いやすく、良いものにしていきます!
今後とも「SCORERA」を宜しくお願いいたします!
すごく参考になりました!ありがとうございます!