
最近、SIMD命令を使ったプログラミングというものに触れる機会があったので、どうやって入門していったかについてまとめます。この分野はどうしても「分かっている人向け」の記事が多くなりがちのようなので、基本的な知識についてまとめつつ、発展的な資料へのURL等も極力載せるようにしました。
※ 記事で取り扱うSIMD命令はAVX-512を対象としますが、その他の命令体系(e.g. x86のAVX/AVX2やARMのNEON等)とも多少は共通点があるかもしれません
前提知識とスコープ
- C/C++のごく基本的な構文を理解している人向けの記述になっています
- 記事を読む上で、計算機の構造についての基本的な理解が必要かもしれません
- e.g. CPUがあってメモリがあって〜程度でたぶん大丈夫です
- 開発環境としてLinux上のClang 5.0.1を想定します(とはいえGCC等でも同じような話になるはずです)
- 高度なチューニング等の内容については触れません
- 残念ながら筆者もよく分かっていません(数週間ぐらいしか触ったことがないので)
- 筆者自体はほとんど素人ですが、この分野のエキスパートのレビューを受けたため、この記事自体の内容はそれなりにまともなはずです
基礎知識
SIMDとは何か
Single Instruction, Multiple Data streamsのことで、計算機の古典的な分類である フリンの分類 から来ている用語です。複数のデータに対して単一の命令を適用するアーキテクチャを指します。
SIMDにおいては、複数のデータに対して1命令で処理を行うことになるためスループットが向上し、性能が向上します(実行される命令数が削減されるとも言い換えられる)。具体的には数倍〜数十倍程度の高速化が実現できることも珍しくありません。
現代のPC/サーバ向けCPU(x86 CPU)では、SIMDを拡張命令の形で利用できるようになっています。拡張命令にはいくつかのグループがあり、どの命令(群)がどのCPUから使えるかが決まっています。基本的に新しいCPUほど使える命令が多く高機能です。
| 拡張命令 | ベクトル長(bit) | 利用可能なCPU世代(Intel) | 利用可能なCPUの発売時期 1 |
|---|---|---|---|
| AVX | 256(float) | SandyBridge | 2011〜 |
| AVX2 | 256(int) | Haswell | 2013〜 |
| AVX-512 | 512 | Knights Landing / Skylake Xeon | 2016〜 |
※ 本当はもっと細かいですが、記事の本題から外れるため触れません
特に最近はSIMD命令のベクトル長(一度に処理できるデータの量)を伸ばすことでCPUの性能を引き上げるということが行われています2。
SIMD利用の段階
SIMDを利用するには対応するCPU命令を取り扱えなければなりません。が、低水準な記述を行うのは正直とても大変です。筆者はふだんスクリプト言語も書きますが、生産性の低さにびっくりします。
CPUベンダーのIntelは、プログラムをSIMDによって高速化する場合のガイドラインを提示しています3。要点としては次のようなことを言っています。
言い換えると「自力で頑張ってのSIMD化は極力するな」ということです。あとはIntel C/C++ Compilerを買えと言いたいのだろうか。
ここに載っていないアプローチも複数あるとは思います。
この記事では一番下の、intrinsics関数を使ったプログラミングの紹介をします。
intrinsics関数とは、要するに機械語の命令に対応する関数のことです。直接アセンブリ言語を書かずともCの関数を書き並べる形でSIMDプログラミングができます。
開発の下準備
エミュレータ
AVX-512に対応したCPUは、特にクライアント向けPCには、記事の執筆時点(2018/02)であまり広く普及しているとは言い難い状況にあります。AVX-512非対応環境では、AVX-512命令を含んだコードは実行できません。こんな感じにクラッシュしてしまいます。
$ ./a.out
[1] 17966 illegal hardware instruction (core dumped) ./a.out
手元に存在しないCPUに対してコードを書くために、Intelからエミュレータが提供されています。これを導入することで書いたコードの動作確認ができます。
https://software.intel.com/en-us/articles/intel-software-development-emulator
$ sde -skx -- ./a.out
Hello World
リファレンス
intrinsics関数にどういったものがあるか、開発中は(特に慣れないうちは)頻繁に調べることになります。
Intelコンパイラのリファレンスが見やすくカテゴリ分けされているので便利です。Clangでも提供されている関数はほとんど同じです。
公式なリファレンスではないですが、こちらのサイトは非常に利便性が高いです。特に、複雑な演算でどういった処理が行えるかの図示がとても見やすい点や、各種の型変換が表の形で整理されている箇所はとても見やすいです。
生成されたアセンブリ出力をどうしても読みたい/読まなければならないこともあります。その際には命令セットリファレンスが詳しいです(CPU製造元のリファレンスなので詳しいというか網羅されているのは当たり前ですが)。
加えて、当たり前ではありますが言語処理系のリファレンスは重要です。場合によっては各言語処理系のドキュメントを読まなければならない時もあります。
ちなみに、下手にぐぐるよりもinfoコマンドの情報を参照した方が良い場合すらあるとか……。
AVX-512について
概要
以降、この記事では、拡張命令の最新世代であるAVX-512について扱います。
AVX-512は、最近のXeon PhiやXeonにて導入された、最新の拡張命令です。
概要としては↓の辺りを読んでおけば大丈夫な気がします
https://software.intel.com/en-us/node/523777
intrinsicsプログラミングにあたってひとまず重要(だと思う)箇所をいくつか列挙します。
- AVX-512はいくつかのカテゴリに分かれている
- 基本になるAVX-512Fに加えて、AVX-512BW、AVX-512VLなどいくつかに分類されている
- CPUごとに利用できるカテゴリに制限がある
- AVX-512ERIとAVX-512PFIはXeon Phiでしか利用できない
- IFMA, VBMI, 4VNNIW, 4FMAPSは次世代のXeon Phiなどでしか利用できない
- もちろん記述時点では、の話です
- レジスタは512ビットある
- CPU的にはzmmレジスタと呼ばれ、32本ある
- AVX-512VLで定義された命令群を使うと、zmmレジスタの一部を256/128ビットレジスタとして操作できるようになった
- EVEXと呼ばれるフォーマットに従っている
- どんなフォーマットか詳細を知っている必要はないですが、Instruction Set Referenceを読む際にはEVEXと書かれている箇所を参照します。
- マスクレジスタによる分岐ができる
- CPU的にはkレジスタと呼ばれ、8本ある(うち、任意の値を入れられるのが7つ)
- プログラミングに影響のある概念なため後述します。要素ごとに処理を分岐したい場合に使います
- その他
- 例えばレジスタの本数や組み込みブロードキャストなど、従来の拡張命令より進歩した箇所はいくつもあるらしいのですが、コンパイラがレジスタや命令選択をある程度管理してくれるので、とりあえず触る程度の入門レベルでは把握している必要はあんまりありません
プログラミングという観点からのAVX-512 intrinsics
何はともあれ#includeは必要
intrinsicsを利用するには、専用のヘッダファイルをインクルードします。ひとまずは
#include <immintrin.h>
としておけばOKです。ちなみに程度の話ですが、このヘッダはAVX-512以外の拡張命令に対応するintrinsicsもインクルードします。
参考: https://stackoverflow.com/a/31185861
SIMDレジスタは特定の型の変数として表される
SIMDレジスタは__m<ベクトル長> で表される型で表します。C言語レベルでは変数に見えますが、この型は言語処理系によってコンパイル時に(できる限り)SIMDレジスタが割り付けられます。
また、__m<ベクトル長>i / __m<ベクトル長>dという型も定義されており、こちらは中身がそれぞれ整数 / 浮動小数点数であることを表します。
同様に、マスクレジスタを表す型として__mask<ビット数>が定義されています(数種類あります)。
void f()
{
__m512d z;
__m256i y;
__m128 x;
}
ベクトル長とデータ型から、そのレジスタに何要素入るかが自然に定まります。一例を表で示します。
| ベクトル長 | 要素の型 | 要素数 |
|---|---|---|
| 512 | double(64ビット倍精度浮動小数点数) | 512/64 = 8 |
| 256 | 16ビット整数型 | 256/16 = 16 |
つまり入れられる要素数が多いほど一度に演算できる要素数が多くなり、結果として計算のスループットは出ることになります。ただし、要素の型によっては欲しい処理を行う命令が存在しないこともあります。
レジスタの中に入っている要素が何であるかは、型を見ても大雑把にしかわかりません。上の例でいうと、変数zにfloatを16個入れて使うかdoubleを8個入れて使うかは、プログラマが意識的にコントロールしなければなりません。浮動小数点数だけでなく、整数に関しても同様です。
SIMD命令は関数で表される
例えば、レジスタに保持されているdouble型の要素すべてに1.0を足すincを次のように書けます。
__m512d inc(__m512 x)
{
__m512 one = _mm512_set1_pd(1.0); // `one`はレジスタをdouble型の要素1.0で埋めたもの
__m512 sum = _mm512_add_pd(x, one); // `x`と`one`に保持されているdouble同士で足し算する
return sum;
}
_mm512_add_pdはAVX-512命令でいうとvaddpdとしてコンパイルされると期待されます。このように、intrinsicsによって機械語の命令を置くよりも高水準なプログラミングができます。
ただし、SIMD命令と対応しないintrinsicsも存在します。上の例でいうと_mm512_set1_pdは対応する命令が存在しないため、コンパイラ任せでの命令生成が行われます(この場合だと、例えば組み込みブロードキャストになるはずです)。また、通常のプログラミングと同様に、コンパイラが意味を変えない範囲で命令の選択を変えたり、命令の並べ替えを行うこともあります。
レジスタに何が入っていると”みなす”かは関数によって決まる
繰り返しになりますが、intrinsicsプログラミングで利用する型は非常にゆるふわです。整数か浮動小数点数か、ぐらいの区別しかありません。
したがって、レジスタを表す型に実際に何が入っているかは、プログラマが管理することになります。プログラマは、その変数にどの型を入れているか? を意識しながら実装しなければなりません。
コードを見ながら具体的に説明します。前節の関数incの32/64ビット整数版です。
__m512i inc32(__m512i x)
{
__m512i one = _mm512_set1_epi32(1);
__m512i sum = _mm512_add_epi32(x, one);
return sum;
}
__m512i inc64(__m512i x)
{
__m512i one = _mm512_set1_epi64(1);
__m512i sum = _mm512_add_epi64(x, one);
return sum;
}
inc32とinc64の違いはoneに代入される値を比べてみるとわかりやすいです。
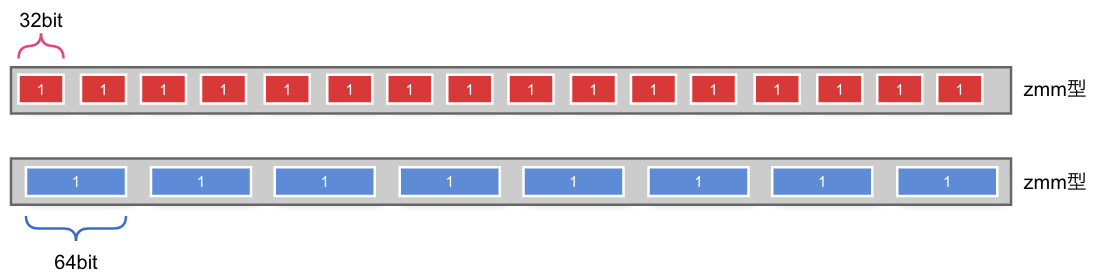
上がinc32、下がinc64のoneです。型としては同じ__m512型で、全体が512ビットなのは同じですが、入っている要素が32ビット/64ビットであるとして値の操作(今回は1をset)が行われます。後続のaddについても同様です。
オペランドの型が何か(何であると見なすか)は関数によって決まりますが、intrinsicsは命名規則が決まっています。末尾に注目すると
- epi: Nビット(符号付き)整数型
- ps: 32ビット浮動小数点数型
- pd: 64ビット浮動小数点数型
※ 本当はたくさん種類があります。一覧についてはコンパイラのリファレンス等を参照してください。
ここから、例えば_mm512_add_epi64は、要素が64ビット整数型であるとみなしてレジスタの加算を行う命令だとわかります。
このように、SIMDレジスタの要素を具体的にどんな型であると決めて演算する、そのための関数を適切に選ぶのは、繰り返しになりますがプログラマの責任です。
演算によっては関数の適用前後で中身の型が変わることがあるので、それにも注意した方が良さそうです。型変換などは典型的ですが、変数としての型が変わらないのに中身の「みなしている型」が変わることもあります4。
例えば_mm512_mul_epi32は2つのレジスタに入っている各要素(32ビット整数)の積を計算する関数ですが、計算結果は64ビットで得られます。
命令はいっぱいある。どのような操作ができるかは知っておいたほうがよい
命令はいくつかのカテゴリに分かれています。メモリとのロード・ストアや四則演算のような基本的なものから、Gather/Scatter5のように非常に複雑な処理をこなせる命令もあります。オペランドの組み合わせも非常に膨大です。
いざ実装をしようとしてみると、びっくりするほど複雑な処理が1命令でできちゃったりするので、命令リファレンスを俯瞰しておくのは大切そうだと思いました。
シャッフルやマスクレジスタを活用したプログラミングはSIMD特有かもしれない
SIMD命令には一般的なプログラミングでなじみ深いものもあれば、そうでないものもあります。後者の、とても耳慣れない概念としてシャッフルとマスクレジスタがあるので、ここで紹介しておきます。
シャッフルとはSIMDレジスタ内でデータを並べ替える操作のことです。多くのSIMD演算命令は複数のレジスタ間の同じ位置にある要素を対象にしています。例えばこんな感じです。

※ Intelのサイトより引用
言い換えると、異なる位置にある要素同士で演算をしたい場合、演算前に要素を並べ替える、という操作が必要になります。この時に行う操作がシャッフルです。シャッフルのための命令はオペランドの組み合わせも含めて大量に存在するので、リファレンスから必要なものを探すことになります。
マスクレジスタは、レジスタの要素のうち一部の演算結果を捨てるために使うレジスタです。条件分岐を消すために使います。
例として整数の絶対値の計算を考えます6 。
int32_t abs(int32_t x)
{
if (x < 0) {
return -x;
}
return x;
}
このアルゴリズムを512ビットSIMDレジスタに格納された16要素に行うように拡張することを考えると、普通にif文を使うことはできません。なぜなら要素ごとに負の値かどうか(= if文の真偽)は異なる可能性があるためです。
マスクレジスタを使う場合、問題を「要素を0と比較して負だったものについてはマスクを立てる。マスクが立っている要素については符号を反転させる」と読み替えます。そして、要素ごとの比較をしてマスクを立てる比較演算と、マスク付きの符号反転演算によって実装できます。
__m512i abs_simd(__m512i x)
{
// xの各32ビット整数要素に関して、0と比較する。負の値の要素に対応するマスクビットが立つ
__mmask16 k =_mm512_cmp_epi32_mask(x, _mm512_setzero_epi32(), _MM_CMPINT_LT);
// 0-xなので符号反転した値を準備する
__m512i neg = _mm512_sub_epi32(_mm512_setzero_epi32(), x);
// マスクビットが立っている箇所を符号反転させた値に差し替える
return _mm512_mask_mov_epi32(x, k, neg);
}
このように、マスクレジスタを使うと、SIMD化できなさそうな箇所も意外になんとかなるので面白いです。
AVX-512では多くの演算にマスクレジスタを取ることができるようになっています。intrinsics関数名でいうとmaskと関数名の中ほどに付いているものがマスクをとります(e.g. _mm512_mask_add_epi32)。マスクビットが立っていない箇所で値をゼロにするバリエーションが提供されている場合もあります(e.g. _mm512_maskz_add_epi32)。
実際にコードを書いてみる
前提知識と下準備を元に、さっそくコーディングをしてみます。
お題として使うのは画像の拡大縮小です。筆者がSIMDが必要になったのも、これについて調べていたからでした。と言っても、あまり複雑な処理について解説するのは大変(であり、かつその知識も筆者にはない)なので、問題をごく単純化します。
- アルゴリズムはシンプルなnearest neighbor法(NN法)
- 処理対象の画像はraw画像で、ビット深度が8bitのグレースケール
- つまりメタデータ等の余分なものが付いておらず、1byteでピクセル1つが表現されている
サンプル画像を準備する
imagemagickでraw画像を作っておきます。ここではサンプル画像としてLenna7を使います。
$ convert -depth 8 Lenna.png gray:Lenna.raw
まず非SIMD(スカラ)版を実装する
とりあえず普通に実装してみること。これが意外に重要だと思いました。
実現したかった処理はそれほど重くないかもしれません。コンパイラが最適化でなんとかしてくれる可能性もあります。前述のように、わざわざintrinsics/アセンブリ言語で書くのは最適化の最終手段にあたるので、コストのかかる実装をせずに済むならそれに越したことはないはずです。
さらに、スカラ版の実装があると、SIMD版の実装が正しいのか検証しやすくなります。アルゴリズムが理解できるので実装方針が立てやすくなります。いいことずくめです。
というわけで、やってみます。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <immintrin.h>
void scale_nn(uint8_t *src, int src_width, int src_height, uint8_t *dst, int dst_width, int dst_height)
{
double scale_w = (double)src_width / dst_width;
double scale_h = (double)src_height / dst_height;
for (int y = 0; y < dst_height; y++) {
for (int x = 0; x < dst_width; x++) {
// 現在求めたいのは拡大縮小後の画像における座標(x, y)にあるピクセルの色。
// これは元の画像でいうと(x * scale_w, y * scale_h)に相当する。
// 座標が整数である保証はないので、補完処理によってこの座標の値を計算しなければならない。
// nearest neighbor法では単純に最も近い点の値を使うので、整数に丸める処理をして元画像におけるピクセル(x0, y0)を得る
int x0 = (int)round(x * scale_w);
int y0 = (int)round(y * scale_h);
dst[dst_height * y + x] = src[src_height * y0 + x0];
}
}
}
// ファイルからraw画像(Lenna)を読み取る。
// 簡素化を優先し、エラーハンドリング等をやっていない手抜き実装である点に注意する。
uint8_t *read_lenna(size_t size)
{
FILE *fp;
uint8_t *buff = (uint8_t *)malloc(size);
fp = fopen("Lenna.raw", "rb");
fread(buff, 1, size, fp);
return buff;
}
// raw画像の書き出しを行う。簡素化を優先し(以下略
void write_raw_image(int size, uint8_t *buff)
{
FILE *fp;
fp = fopen("output.raw", "w");
fwrite(buff, 1, size, fp);
}
int main()
{
uint8_t *src = read_lenna(512 * 512);
uint8_t *dst = (uint8_t *)malloc(256 * 256);
scale_nn(src, 512, 512, dst, 256, 256);
write_raw_image(256 * 256, dst);
}
サンプルとしては大きな実装をしてしまいましたが、本題はscale_nnのみです。他はファイル入出力などの補助的な関数に過ぎません。
SIMD版の方針を立てる
scale_nnのSIMD化を考えます。関数名はscale_nn_simdにします。
SIMDであることを生かすには、SIMDレジスタに複数の要素を詰め込んで一気に演算させる必要があります。今回の計算対象は画像なため、できるだけたくさんのピクセルを同時に読み込んで演算させたいものです。
ただし、プログラムを見てわかるように、演算の依存関係をたどると、ループ変数x, yから座標計算を行う所から出発しています。つまり、複数ピクセルを同時処理するには、複数の座標をSIMDレジスタに詰め込む所が出発点です。
詰めこめるピクセル数はできるだけ多いと効率が良いですが、座標計算では途中に浮動小数点数が出現します。zmmレジスタには倍精度だと8要素、単精度だと16要素入りますが、今回のような用途だと単精度で十分です。一方で整数部分はどの箇所も16ビットも確保できれば足りています。
以上の議論から、scale_nn_simdの基本構造は次のようになりそうです。
void scale_nn_simd(uint8_t *src, int src_width, int src_height, uint8_t *dst, int dst_width, int dst_height)
{
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x += 16) {
// 1. 16個のx座標(x,x+1,x+2,...,x+15)を準備する
// 2. 元画像のピクセル座標計算
// 3. ピクセルの読み出しと書き込み
}
}
}
ところが、このままでは不完全な実装です。なぜならwidthが16の倍数であるとは限らないからです。例えばwidth=18のとき、2回目のループで16, 17, ..., 31を読み出してしまいます。
一般に、SIMD化するとき、このようなループからはみ出る余剰部分をどう処理するかの問題が生じることがあるようです。解決策の一例としては、ループ回数を1回減らし、はみ出た部分をループの後ろで別途処理する(loop remainderというらしいです)などの方針があるようです。
今回の実装ではマスクレジスタを利用し、16の倍数からはみ出た部分をマスクすることで、処理しないようにします。
SIMD版を実装してみる
前節で確認した方針のもと、実装を行ってみます。
void scale_nn_simd(uint8_t *src, int src_width, int src_height, uint8_t *dst, int dst_width, int dst_height)
{
__m512 scale_w = _mm512_set1_ps((float)src_width / dst_width);
__m512 scale_h = _mm512_set1_ps((float)src_height / dst_height);
for (int y = 0; y < dst_height; y++) {
__m512i vx = _mm512_set_epi32(15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0);
for (int x = 0; x < dst_width; x += 16) {
// 今回処理する対象のベクトル
__m512 v = _mm512_cvt_roundepi32_ps(vx, _MM_FROUND_TO_NEAREST_INT |_MM_FROUND_NO_EXC);
// マスクを作っておく
__mmask16 mask = _mm512_cmp_epu32_mask(vx, _mm512_set1_epi32(dst_width), _MM_CMPINT_LT);
// int x0 = (int)nearbyint(x * scale_w);
// int y0 = (int)nearbyint(y * scale_h);
__m512 x0f = _mm512_mul_ps(v, scale_w);
__m512 y0f = _mm512_mul_ps(_mm512_set1_ps(y), scale_h);
__m512i x0 = _mm512_cvt_roundps_epi32(x0f, _MM_FROUND_TO_NEAREST_INT |_MM_FROUND_NO_EXC);
__m512i y0 = _mm512_cvt_roundps_epi32(y0f, _MM_FROUND_TO_NEAREST_INT |_MM_FROUND_NO_EXC);
// dst[height * y + x] = src[HEIGHT * y0 + x0];
__m512i src_index = _mm512_add_epi32(_mm512_mullo_epi32(_mm512_set1_epi32(src_height), y0), x0);
__m512i data = _mm512_mask_i32gather_epi32(_mm512_setzero_epi32(), mask, src_index, src, 1);
_mm512_mask_cvtepi32_storeu_epi8(dst + dst_width * y + x, mask, data);
// ループの更新に合わせてvxの更新
vx = _mm512_add_epi32(vx, _mm512_set1_epi32(16));
}
}
}
こんな感じでしょうか。同時に計算した座標に対してgatherで一度に要素を取得できているため、比較的簡潔に書けています。
最終的な全体のコードは長いのでGistとして貼っておきます。
https://gist.github.com/saka1/c99777db3282ac5bbfa8fcd42b9ab613
コンパイルして実行し、生成物を確認してみます。今回はAVX-512Fの命令群のみを利用しているので、AVX-512特有のオプションは-mavx512fです。
clang -Wall -O2 -mavx512f nn.c
sde -skx -- ./a.out
convert -depth 8 -size 256x256 gray:output.raw output.png
上手くいけば、縮小された画像が得られるはずです。

記事で紹介していないこと
もちろん沢山ありますが、力尽きた結果省略している内容もあります。もし余裕があったら別の記事にするかもしれません。
- メモリアライメント(本来は必須級に重要ですが....)
- チューニング
まとめ
これぐらい分かっていれば少なくともコードを書き始めることはできた、という経験ができたので、その内容を記事にしてみました。
SIMDプログラミングはパズル感が楽しく、かつある種の分野では大幅な高速化をもたらすことができるので、実益もあります。プログラムとしては複雑化しがちですが、簡単な画像処理ぐらいなら現実的な作業時間でSIMD化できてしまうので、今回は画像処理(NearestNeighbor法)を例にSIMDプログラミングしました。
参考資料
基本になるリファレンスはCPUベンダーのものです。
- Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B, 2C & 2D): Instruction Set Reference, A-Z
- https://software.intel.com/sites/default/files/managed/c5/15/architecture-instruction-set-extensions-programming-reference.pdf
最適化についてのリファレンスマニュアルも出ています。Intel CPUとSIMDに関わる人々はみんな読んでいるらしい(?)です。
SIMD界隈(?)では有名なページらしいです。特にInstruction tablesはよく参照されているのを目にします。
Appendix
インラインアセンブラ
intrinsics関数を使えばAVX-512プログラミングは問題なくできるのですが、時として機械語の1命令単位で挙動を確認したい場合があります。また、intrinsicsは命令やレジスタの選択に関してコンパイラに裁量を与えるのですが、もっと細かくプログラマが制御したい場合もあり、そういう時にはインラインアセンブラを使うとよさそうです。
インラインアセンブラの書き方については、ぐぐると詳しいサイトが沢山出てくるのであまり深くは触れません(筆者があまりよく分かってないのもあります)。概要のみ示します。
以下のサンプルはあくまでClangでの例です。インラインアセンブラは処理系によって互換性がない面があるため、ポータビリティには注意してください。
その命令を埋め込みたい場所にasm()を書き、引数としてアセンブリ命令を文字列の形で埋め込めるのがインラインアセンブラです。
void f() {
asm("vpxord %zmm0, %zmm0, %zmm0\n");
}
asm文に変数の値を渡したり、逆にasm文での処理結果を変数に書き出したい場合があります。そういう場合には拡張asm記法を使います。
__m512 add(__m512i a, __m512i b)
{
__m512 sum;
asm(
"vpadd %%zmm0, %1, %2\n"
"vmovdqa32 %0, %%zmm0\n"
: "=v"(sum)
: "v"(a), "v"(b)
: "%zmm0"
);
return sum;
}
%をエスケープしている点に注意してください。
拡張asm記法では : を区切り文字として、順に OutputOperands/InputOperands/Clobbersを記述します。それぞれ大雑把に言って、asm文の中から値を書きたい/値を読みたい/中で使いたい、オブジェクトを指定します。
それぞれの変数には制約と(もし必要なら)修飾子を与えます。sumを例にとると、vが制約、=が修飾子です。vはzmmレジスタを、=はasm文によって変数の値が更新されることを表します。
| 制約 | 意味 |
|---|---|
| r | 変数を汎用レジスタに割り付ける |
| m | 変数をメモリに割り付ける |
| v | 変数をzmmレジスタに割り付ける |
| 修飾子 | 意味 |
|---|---|
| (なし) | アセンブラ側から読み出される |
| = | アセンブラ側から書き込まれる |
| + | アセンブラ側から読み書きされる |
※ これで全てではありません。もっとたくさんあります。
これらのややこしい記述が必要なのは、コンパイラに適切なレジスタ割り付けをしてもらうためのようです。つまり、プログラマとしてはこの変数をどう扱ってほしいかを適切に伝える必要があるということです(e.g. レジスタに乗せてほしい、メモリに置いてほしい、このレジスタには値が入るから破壊されるとみなして良い、等)。
ちなみに制約は組み合わせることができる等、もっと複雑なルールがあるようで、詳細はコンパイラのドキュメントを参照してください。
参照: https://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html#Extended-Asm
ちなみに前述のようにzmmレジスタはv、マスクレジスタはkで指定します8。
注意: IntelのドキュメントはIntel記法で書かれている
Linuxでよく使われるコンパイラ(GCC / Clang)は、デフォルトでAT&T記法でアセンブリ出力をします。
Intel記法は第1オペランドに更新対象のレジスタを書きますが、AT&T記法だと末尾(第2or第3オペランド)になるという違いがあります(間違うと致命的です)。
注意:マスクレジスタの書き方
前述のようにAT&T記法ではオペランドの位置が変わりますが、マスクレジスタはオペランドの後ろに付けます。IntelとAT&Tでマスクレジスタの位置も一緒に変わるので注意です。
さらに微妙にややこしいことに、{}はエスケープする必要があります。結局、こんな感じに書くことになります。マスクの位置と組み込みブロードキャストの書き方に注意してください。
void f(__m512 a, int32_t k) //注: 処理自体には何の意味もない関数です
{
asm(
"kxnorw %%k1, %%k1, %%k1\n"
"vpaddd %1%{1to16%}, %0, %0 %{%%k1%}\n"
:
: "v"(a), "m"(k)
: "%k1"
);
}
CPUの命令数削減≒性能向上?
記事の前半でこの仮定が正しいとして記述しましたが、厳密さに欠けるため補足します。
CPUがある処理にかかる時間は、次の計算式で求められます。
すなわちプログラムの実行命令数が削減されたとき、
- クロック周波数
- IPC(1クロックあたりに処理できる命令数)
この2つが悪化しないならプログラムは高速化されます。しかしながら、この2つが悪化しないという保証はまったくありません。
現実のCPUの例としてIntelの資料を見ると、AVX使用時のCPUはクロック周波数が低下する可能性があることが示唆されています9。また、SIMD化しやすい比較的単純な箇所の命令数がSIMD命令によって削減されると、プログラム全体のIPCは低下する可能性があります10。
もっとも、SIMDが効いた場合の命令の削減量は数倍〜数十倍のオーダーになるため、だからといってSIMDが効果的でないとも言えません(現実にいろいろなプログラムで高速化は見込めます)。実際にどれだけの効果があるかはプログラムに依存すると言えそうです。
-
時期はあくまで目安で、大雑把です。例えば、クライアント向けとサーバ向けで違っていたりします ↩
-
これだけ、というわけではないです。他の方法として例えばマルチコア化があります ↩
-
例えば https://www.isus.jp/wp-content/uploads/pdf/Vectorization_Codebook.pdf / https://software.intel.com/sites/default/files/An_Introduction_to_Vectorization_with_Intel_Fortran_Compiler_021712.pdf ↩
-
言い方を変えると、intrinsicsで提供される演算が、要素の型に関して閉じている保証は特にありません。 ↩
-
メモリアドレスを複数指定して、それらを対象にロード/ストアをまとめて行う命令群です ↩
-
実は絶対値命令vpabsdは存在するのですが、あくまで例ということで……ちなみにSIMD化した例はClangで最適化をかけるとvpabsdにしてくれます。コンパイラとても賢い。 ↩
-
https://ja.wikipedia.org/wiki/%E3%83%AC%E3%83%8A_(%E7%94%BB%E5%83%8F%E3%83%87%E3%83%BC%E3%82%BF) ↩
-
この辺の情報はドキュメントを探してもほとんど書かれておらず、頑張って検索しないと見つからない気がします ↩
-
例えば http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/performance-xeon-e5-v3-advanced-vector-extensions-paper.pdf ↩
-
そもそもみたいな話としては、SIMD化によってCPU内部でデータに対する並列演算を行ってくれるかどうかも、CPUの作りに依存してしまいます。いにしえのスーパーコンピュータではベクトル長よりも演算器が少なく、演算器に効率よくデータを投入する手段としてSIMDを使っていた事もあるようです ↩