
クックパッドの新規サービスKomercoを設計した@1amageekです。
クックパッドの新規サービスKomercoはTechConfでも発表した通り全てサーバーレスで開発されています。サーバーレスの利点や開発におけるメリットはこの資料に説明しているので、今日はFirestoreについて深く説明したいと思います。また、Firestoreのざっくりした説明に関してはこちらをご覧下さい。
FirestoreはCloud Spannerの上に構築されている
FirestoreはCloud Spannerの上に構築されています。つまりCloud Spannerの特性を理解することでFirestoreのコアを知ることが可能です。この記事ではCloud Spannerにフォーカスして説明して行きます。
Cloud Spannerをご存知でしょうか? Cloud SpannerはGoogleが提供している地球規模のデータベースです。地球規模と表現しましたが、ここが重要なポイントなのでぜひこのまま読み進めて貰えると嬉しいです。
Cloud Spannerのページでは次のように説明されています。
水平スケーリング可能で高い整合性を備えた、初のリレーショナル データベース サービス
水平スケーリング可能で高い整合性とはどう言うことでしょうか?データベースの根幹からCloud Spannerについて理解して行きましょう。
データベースがかかえるハードウエアの限界
データベースの特性はハードウエアに大きく依存しています。データベースは一体どのようなハードウエアの特性に縛られているのか考えてみましょう。まず容易に想像できるのはマシンの性能です。マシンの性能はCPUの処理速度だけでなくストレージのRead/Write速度や、故障率などもあります。
次に、私たちが利用するデータベースのほとんどはクラウドに存在するのでネットワークにも依存します。ネットワークについてもう少しブレイクしてみましょう。ネットワークは回線速度と距離に依存しています。
データベースは次のことを考える必要がある。
- 処理速度
- 故障率
- 回線速度
- 距離
上記の課題をインターネットの歴史でどのように解決してきたのでしょうか?実は全て同じ方法で問題を解決しています。それは冗長化・並列化です。
- 一台のマシンでは処理速度に限界があるので複数のマシンで処理する。
- マシンは必ず故障するので故障率を考慮して複数のマシンで運用する。
- 一つのネットワーク帯域では回線速度に限界があるので複数の回線を使う。
- 拠点を一つにすると距離が離れている通信に遅延があるので複数拠点を置く。
データベースではシャーディングと呼ばれています。シャーディングの技術はクラウドのニーズが高まるに連れて重要度を増して行きました。クラウド技術の中核は分散処理であると言っても過言ではないと思います。
冗長化・並列化はスケールアウト(水平スケール)と呼びます、一方でマシンの性能を上げていく方法をスケールアップ(垂直スケール)と呼びます。
あらゆるデータベースにシャーディングの機能は備わっています。Cloud Spannerにももちろん備わっています。では他のデータベースとCloud Spannerでは何が違うのでしょうか?
それを理解するためには、データベースの重要な機能であるトランザクションについて知る必要があります。
トランザクション
データベースの中でも非常に重要な機能がトランザクションです。トランザクションとはなんでしょうか?
トランザクションとは
コンピュータ システムにおける、永続的なデータに対する不可分な一連の処理。
よくわかりませんね。素晴らしい記事があるのでこちらをご参考ください。
ざっくり言うとこんな感じです。
分散処理すると並列に複数の処理が同時に走ることになるので、データの整合性が取れなくなります。整合性を取るためにルールを設け運用する。
データの交通整理をする技術と想像してもらえるといいと思います。実際にデータベースは、データに対して赤信号(ロック)のようなものを出してデータをせき止めたりしています。
トランザクションと同時実行制御
トランザクションについてもう少し理解を深めて行きましょう。Cloud Spannerは直列化可能性を持ったデータベースです。直列化可能性とは
分散コンピューティングにおいて、トランザクションスケジュール(履歴)の結果(最終的なデータベースの状態およびデータベースデータの値)がトランザクションを直列的に実行した場合、つまり、時間的な重複無くシリアルに実行した場合と結果が等しい時、直列化可能である、あるいは直列化可能性という性質を持っていると言う。
ざっくり言うとこんな感じです。
処理を並列化しても、直列的な結果を得られること
Cloud Spannerのトランザクション
Cloud Spannerのトランザクションは次のように実行されます。
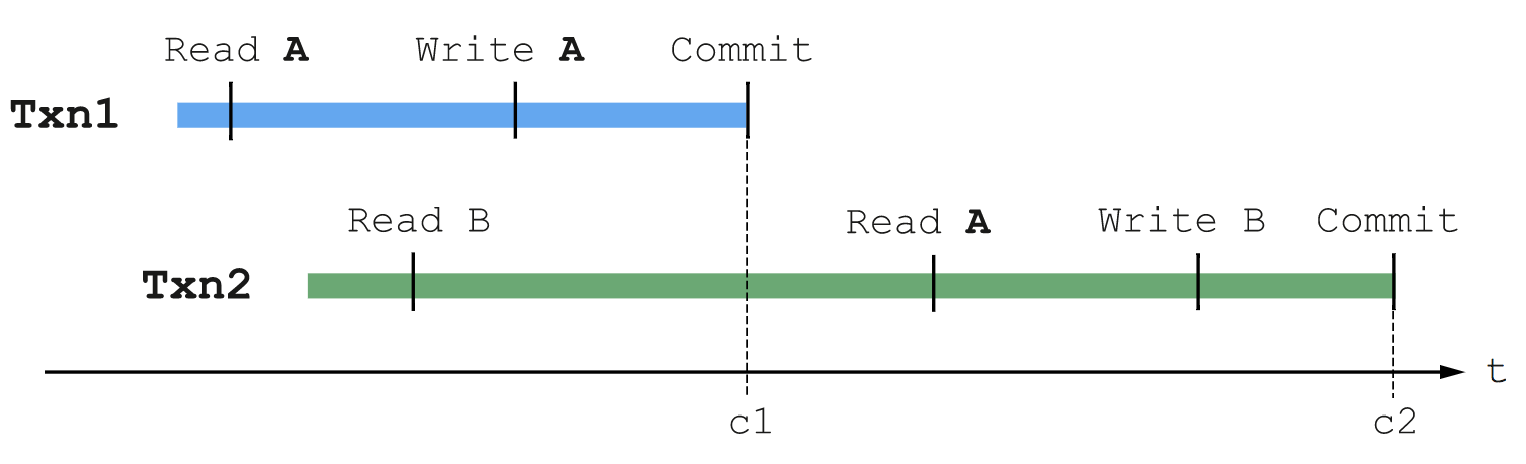
青色のトランザクション Txn1 は、データ A を読み取り、書き込みを A でバッファリングして、正常に commit します。緑色のトランザクション Txn2 は Txn1 の後に開始し、データ B を読み取った後、データ A を読み取ります。Txn2 は、Txn1 が A への書き込みを commit した後に A の値を読み取るので、Txn1 の完了前に Txn2 が開始したとしても、Txn2 は Txn1 が A に書き込んだ効果を見ることができます。
Txn1 と Txn2 の実行時間には多少のオーバーラップがあるものの、commit タイムスタンプ c1 および c2 は線形のトランザクション順序に従います。つまり、Txn1 の読み取りと書き込みのすべての効果が単一の時点(c1)で発生したように見え、Txn2 の読み取りと書き込みのすべての効果が単一の時点(c2)で発生したように見えます。更に、c1 < c2 となります(これは、Txn1 と Txn2 の両方が書き込みを commit することで保証されます。
直列化可能性と外部整合性より引用。
トランザクションの性能
ここでトランザクションの性能は何に依存しているのか考えて見ましょう。データベースは、その性能と可用性を向上させるために分散させて来ました。しかし大規模に分散化させていくと一貫性を保証するトランザクション処理は困難になって行きます。なぜでしょうか?
その原因は時間にあります。分散化されたデータベースでは時間を原因としてどのような問題が発生するのでしょうか。その問題を理解するためまず外部整合性を理解して行きましょう。外部整合性は他のデータベースが持っていないCloud Spannerの特徴でもあります。
外部整合性
外部整合性について、次のように説明されています。
外部整合性は、強整合性と追加的なプロパティ(直列化可能性と線形化可能性など)を兼ね備えたプロパティです。
Cloud Spanner ではトランザクションの挙動が、トランザクションが順次実行された場合と同じになり、かつトランザクションが実際に実行される順序と、トランザクションの commit が認識される順序が必ず整合することを意味します。
外部整合性は、線形化可能性よりも強いプロパティです。線形化可能性は、単一オブジェクトに対する単一の読み取りまたは書き込みオペレーションのみがトランザクションに含まれる、外部整合性の特殊なケースと見なすことができます。
ざっくり言うと
順番に実行された2つのトランザクション
t1t2を考え、最初に実行されたt1よりも後に実行されたt2のタイムスタンプは必ずt1.timestamp < t2.timestampとなる
もっとざっくり言うと
現実に実行された順番通りにデータベースに保存する
一つのマシンで直列実行していた場合であれば、至極当然のような整合性ですが、別々のマシンで並列化された場合であればそうも行きません。
2台のマシンを考えそれぞれほぼ同時にトランザクションが実行されたと想定します。この時2台マシンでタイムスタンプがずれていたとすればどうでしょうか? 例えば2台のマシンでタイムスタンプがΔtずれているとします、実際はt1よりt2の方が後の実行されたとしても、次のようにずれの方が大きい場合、t2の方が先に実行されたように記録され整合性が保てなくなります。
t2.timestamp - t1.timestamp < Δt
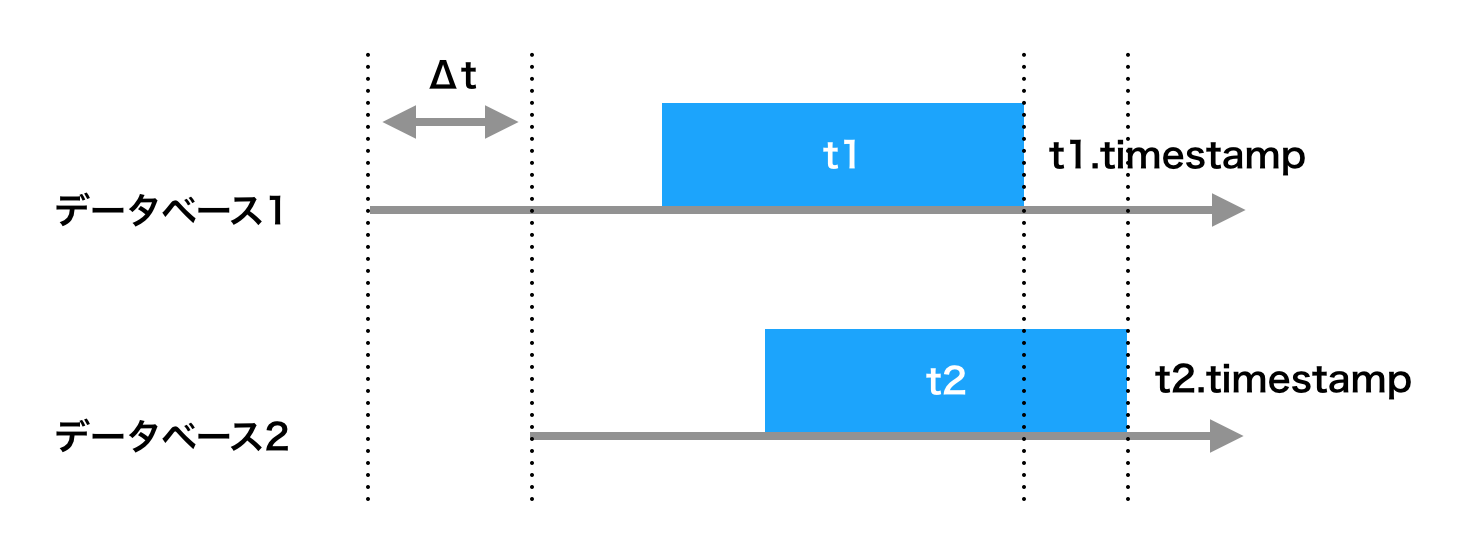
これが、分散化されたデータベースに起こる問題です。これをクロック不確実性問題と言います。
そしてΔtを極限まで小さくすることが整合性を保つには非常に重要であると言えます。
- Cloud Spanner: TrueTime と外部整合性
- Cloud Spanner が外部整合性を提供する理由
- Information Storage in a Decentralized Computer System
- Spanner
TrueTimeとCommit Wait
Cloud SpannerはTrueTimeとCommit Waite呼ばれる技術を用い外部整合性を実現します。Commit Waitはコミットが完了した後2εの時間の間意図的にロックを保持します。そしてεはTrueTimeによって保証されます。
TrueTime
TrueTime は、すべての Google サーバー上のアプリケーションに提供される高可用性分散クロックです。
簡単に言うとGoogleが提供するNTP(Network Time Protocol)です。普通のNTPとの違いは、極限まで離れたサーバ同士の時間を同一に保つことを実現していることです。NTPでは情報がネットワークを行き来する際に誤差が生まれ、完全に正確な時刻同期はできません。
TrueTimeはとってもGoogleらしく強力な方法でこの問題を解決しています。
TrueTimeのテクノロジー
各データセンターに原子時計とGPS受信機を備え、マスターサーバーへ接続されています。これにより地球上でどこにいてもε以下の誤差で同期された時間を取得出来るようになりました。
TrueTimeはCloud Spanner内の時刻の誤差をε以下に抑えるように時刻を頻繁に再同期し、同期が取れないマシンを故障としてサーバーから除外することに利用されています。
また、地球規模で分散化されたデータベースでは、通信速度に律速し、トランザクションの性能を落として行きます。Cloud Spannerでは次のようにそれを解決しています。
- すべてのデータセンターが3本以上の独立したプライベートな光ファイバー回線で接続されている
- 2フェーズコミットとPaxosグループを用いている
- TrueTimeを使って全てのデータベースの時間を高精度で同期する
まとめ
- 分散化されたデータベースでトランザクションの性能を保つため、各データセンターの時間の誤差が小さくする必要がある。
- 誤差よりも長い時間データベースをロックするとことで整合性は保証できる。
- 誤差を最小にすることで性能を向上できる。
- Cloud Spannerは原子時計とGPSを用いで誤差を最小化している。