RDSリードレプリカの負荷分散・冗長構成をRoute 53のヘルスチェックとCloudWatch Alarmで実現する


RDSの読取り性能向上に非常に有効なリードレプリカ。みなさん、お使いでしょうか。参照が多いアプリケーションの場合、書き込み用のマスターとは別に参照用のリードレプリカを構築するのがベストプラクティスです。
今回は、リードレプリカ複数台構成時の負荷分散とヘルスチェックによるルーティング制御を、Route 53のヘルスチェック機能とCloudWatch Alarmを利用して、AWSマネージドで構築した様子をお届けします。
リードレプリカの冗長構成において、アプリケーション側からアクセスさせる時、一般的にはHAProxy、MySQL Router、Consul by HashiCorpなどのソフトウェアロードバランサの導入が必要ですが、今回は、全てAWSマネージドかつDB種別に依存しない構成、という点がメリットです。
リードレプリカ以外にも応用できそうな手法なので、気になる方は是非一読をオススメいたします。
__ (祭) ∧ ∧ Y ( ゚Д゚) Φ[_ソ__y_l〉 リードレプリカダワッショイ |_|_| し'´J
リードレプリカ冗長構成のイメージ
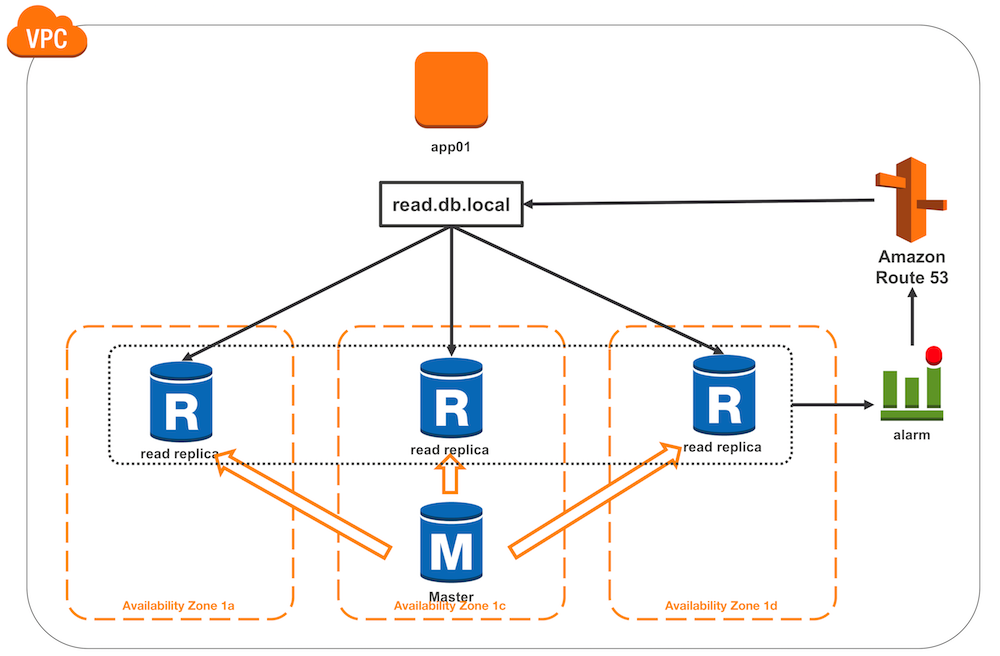
構成の特徴
- RDSのマスターから、3つのリードレプリカを、それぞれ異なるアベイラビリティゾーンに複製
- アプリケーション・サーバーからは、Route 53のプライベートホストゾーンで設定したCNAMEのread.db.localを利用し、リードレプリカにアクセス
- CNAMEは加重レコードを使用して、3つのリードレプリカにルーティングするよう設定
- 各リードレプリカのCloudWatch イベントにCloudWatch アラームをセットし、CNAME加重レコードのヘルスチェックにCloudWatch アラームを設定
Route 53のヘルスチェックには、CloudWatch アラームを利用してヘルスチェックする機能があるので、それを利用します。
この構成みて、「なんでこんな面倒くさいことやってんの?」と思った人もいるでしょう!
疑問①「何故、Route 53自体が持っているヘルスチェック機能を使わないのか?」
Route 53のヘルスチェッカーはVPCの外にあるため、VPC内のプライベートなリソースのエンドポイントへの正常性確認ができません。今回のユースケースでは、リードレプリカへのアクセスは、VPC内EC2のみに限定するため、この方法が利用できません。
疑問点②「NLB(Network Load Balancer)をインターナルで使えば良いのでは?」
NLBはターゲットをインスタンスかIPアドレスで指定します。リードレプリカはIPアドレスを持ちますが、各ノードのIPアドレスは普遍ではなく変わる可能性があるため、NLBをリードレプリカの負荷分散に利用するのは難しいです。(Lambda等で定期的にIPアドレスをチェックし、変わったらターゲットグループを付け替えるという方法もありますが、運用環境でやるには現実的ではないでしょう。)
今回の構成の理由、ご理解いただけましたでしょうか?では、この構成を作る手順を紹介していきます。
リードレプリカ冗長構成構築の手順
- リードレプリカを3台作成し、各リードレプリカに対して、CloudWatch Alarmを設定する
- Route 53のヘルスチェックを設定し、CloudWatch Alarmを割り当てる
- Route 53のプライベートホストゾーンを作成する
- リードレプリカに対するCNAMEレコードを3つ作成し、それぞれにヘルスチェックを割り当てる
ほな、気軽にいってみましょ。
手順1「リードレプリカを3台作成し、各リードレプリカに対して、CloudWatch Alarmを設定する」
最初にRDSのリードレプリカを3台構成します。今回はRDS(MySQL)を利用。マスターを1つ作成し、そこから3台のリードレプリカを作成します。
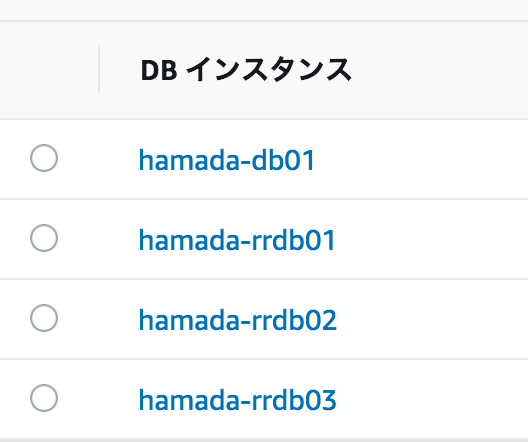
今回の内訳は以下の通り。
| 役割 | Nameタグ |
|---|---|
| マスターデータベース | hamada-db01 |
| リードレプリカ1号機 | hamada-rrdb01 |
| リードレプリカ2号機 | hamada-rrdb02 |
| リードレプリカ3号機 | hamada-rrdb03 |
作成した3台のリードレプリカに、それぞれCloudWatch Alarmを設定します。リードレプリカを選択すると、詳細が表示されます。中段あたりに、「CloudWatch アラーム」の設定箇所があるので、「アラームの作成」をクリックします。
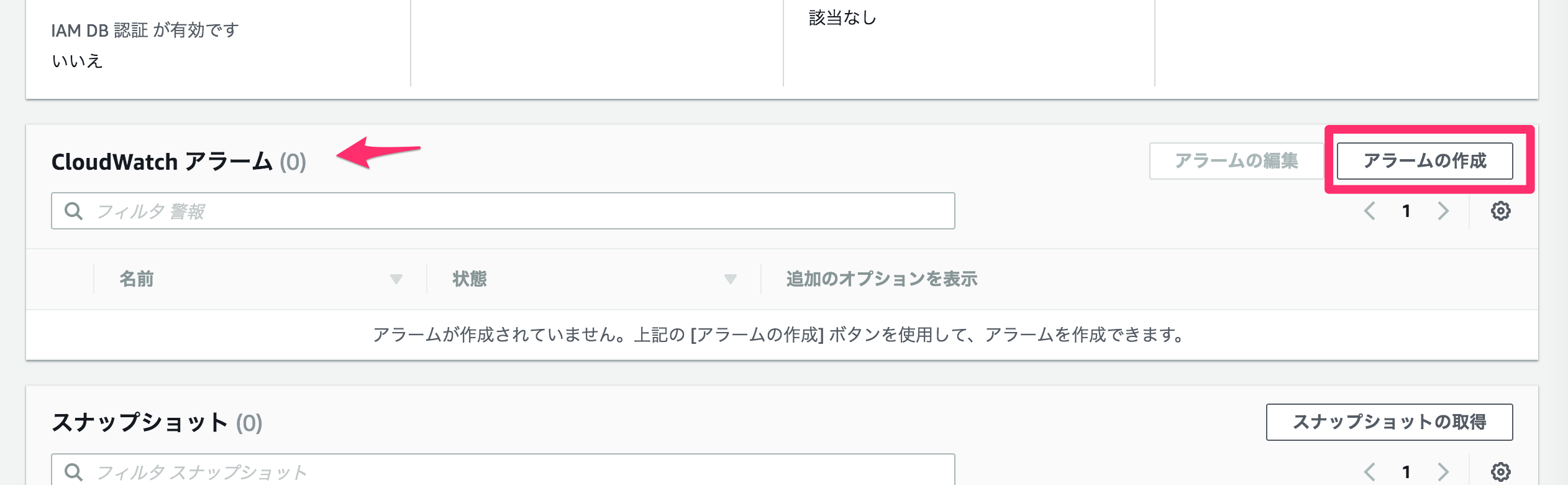
アラームを作成します。今回は検証を簡単にするため、DB接続が1以上でアラームが発生するように設定します。通知もオフです。

- 通知の送信
- 「いいえ」
- メトリクス
- 「Average」 of 「DB接続」
- しきい値
- 「>=1カウント」
- 評価期間
- 「1」間隔「1分間」
- アラーム名
- awsrds-hamada-rrdb01-High-DB-connection
アラームの作成をクリックします。
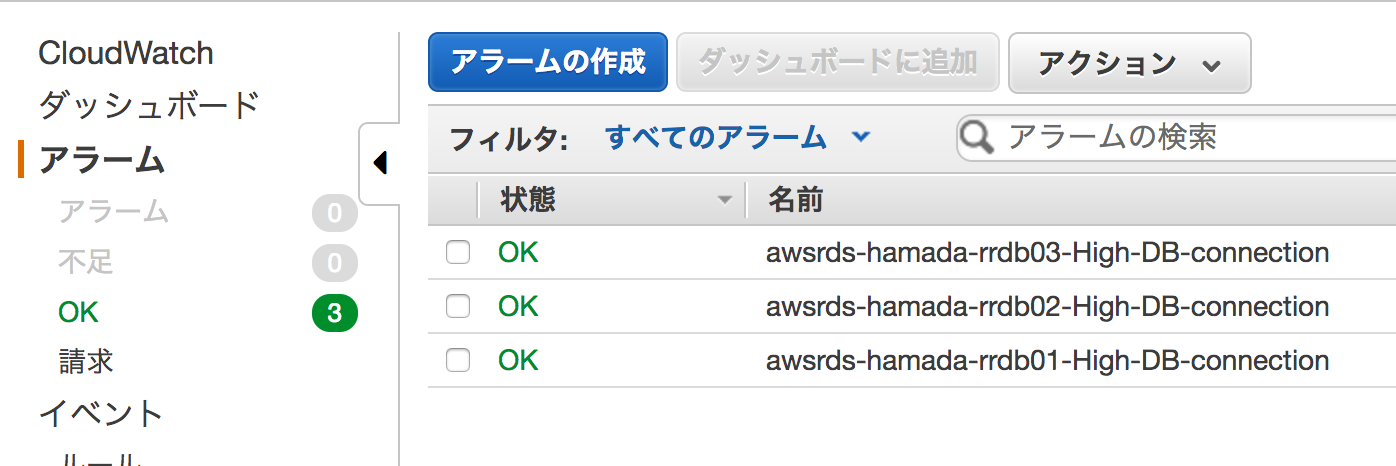
同様の手順で、残りの2つのリードレプリカに対しても、アラームを設定します。アラーム名は、それぞれ、awsrds-hamada-rrdb02-High-DB-connectionと、awsrds-hamada-rrdb03-High-DB-connectionとしておきます。
設定が完了したら、CloudWatchの画面に遷移しアラームを確認します。登録したアラームが表示されていればOKです。
ここで、VPC内の適当なアプリケーション・サーバーからmysqlコマンドで接続し、無事アラームが発動すればアラームが正常に動作していることがわかります。下では、リードレプリカ3号機に接続した状態です。無事、アラートが発動しました。
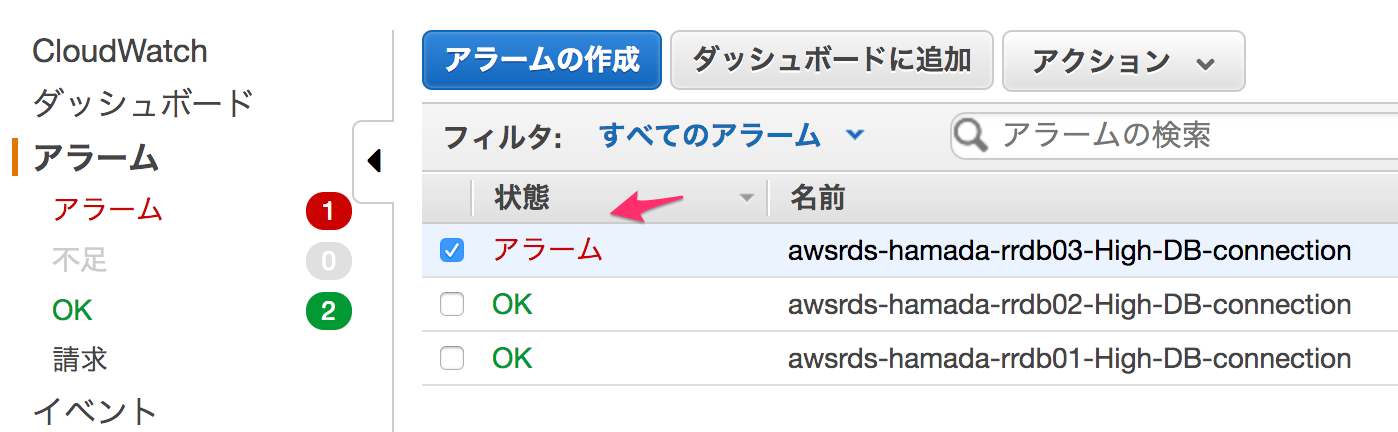
アラームの正常起動が確認できれば、次に進みます。
手順2「 Route 53のヘルスチェックを設定し、CloudWatch Alarmを割り当てる」
次に、Route 53のヘルスチェックを設定していきます。このヘルスチェックに、先程作成したリードレプリカに対するCloudWatch Alarmを割り当てます。
Route 53メニューの「Health checks」一覧から「 Create health check」をクリックすると、ヘルスチェック作成画面が表示されます。

- Name
- 任意の名前を設定します。ここでは、readrepclica01-hcとします
- What to monitor
- 先程リードレプリカに設定したCloudWatch Alarmを利用するため、State of CloudWatch alarmを選択
- CloudWatch region
- 東京リージョンap-northeast-1を選択
- CloudWatch alarm
- 先程リードレプリカに設定したアラームを選択します。ここではリードレプリカ1号機のアラームを紐付けるため、awsrds-hamada-rrdb01-High-DB-connectionを選択
- (重要)Health check status
- アラームの状態がINSUFFICIENT(不定)の場合に、ヘルスチェックをどう扱うかを設定します。INSUFFICIENTは、アラーム設定直後、メトリクスが利用できない、データが不足していてアラームの状態を判定できない状況などを表します。リードレプリカに何らかの障害が発生している可能性が高いので、ヘルスチェック上はunhealtyとするのを推奨します。
- the status is unhealthyを設定
- Invert health check status
- チェックしない
一通り項目を入力したら、次へいきます。
ヘルスチェックに失敗した時の通知を設定します。運用環境ではYesにすることを推奨しますが、ここではNoでヘルスチェックを作成します。
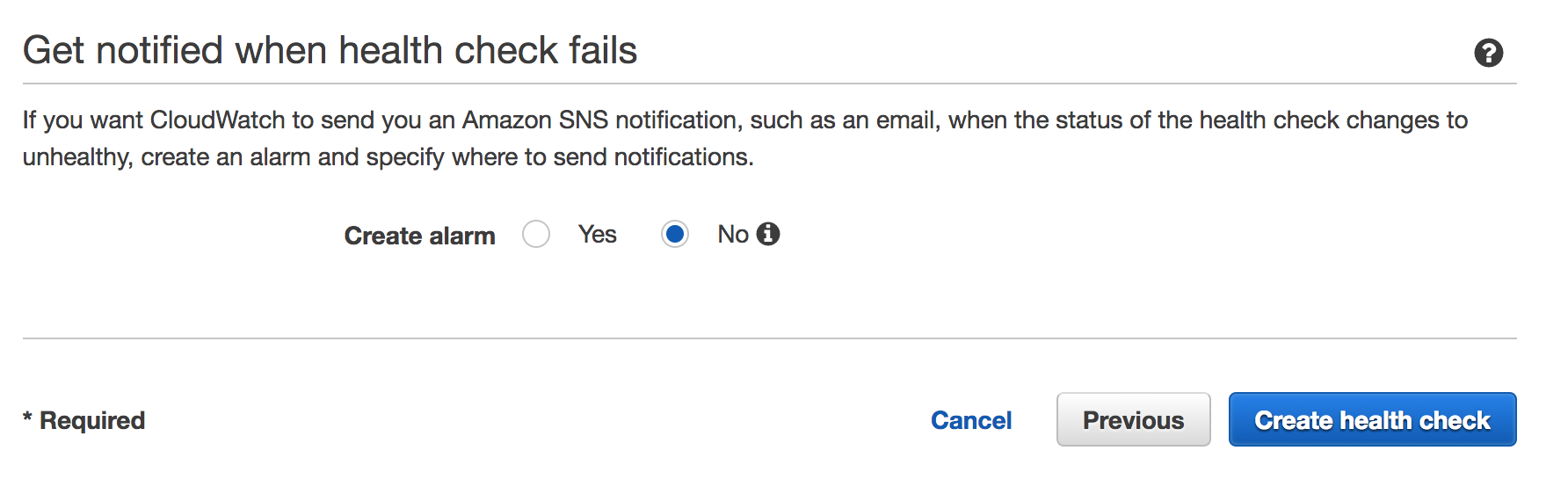
ヘルスチェック、無事作成できましたでしょうか。同様の手順で、リードレプリカ2号機、3号機のヘルスチェックも作成していきます。
ヘルスチェックを3つ作成後、それぞれのヘルスチェックがCloudWatch Alarmと連動してHealthyになることを確認します。
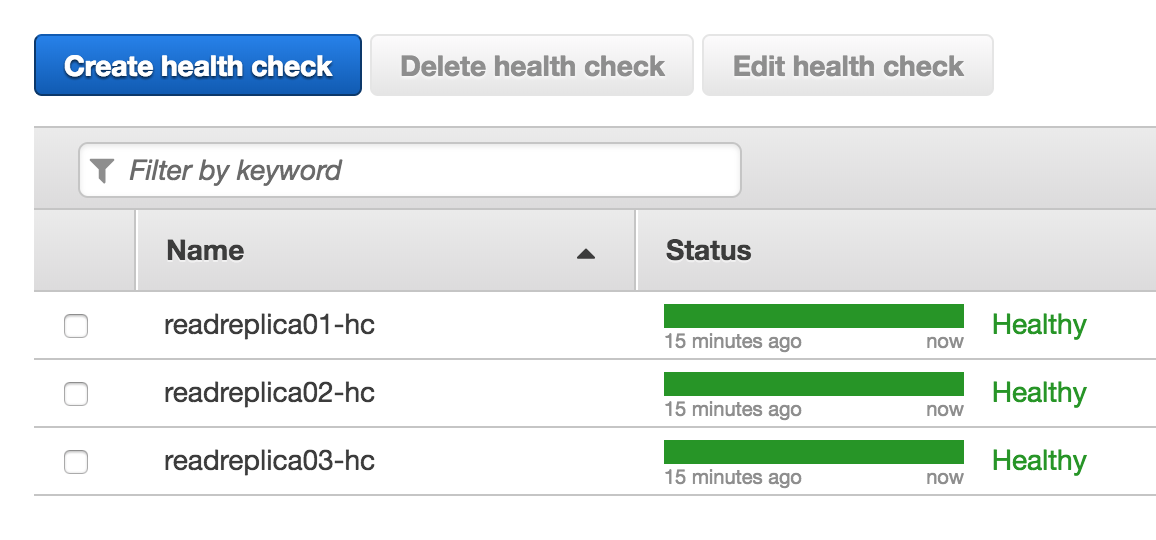
もし、ここがいつまでたってもHealthyにならないのであれば、何かしら設定が間違っているので、CloudWatch Alarm自体がきちんと値を返しているか、確認しましょう。
手順3「Route 53のプライベートホストゾーンを作成する」
今回は、VPC内のみで利用するDNSを作成するので、プライベートホストゾーンを作成します。
Route 53のHosted zonesを選択し、「Create Hosted Zone」をクリック。必要な項目を入力していきます。
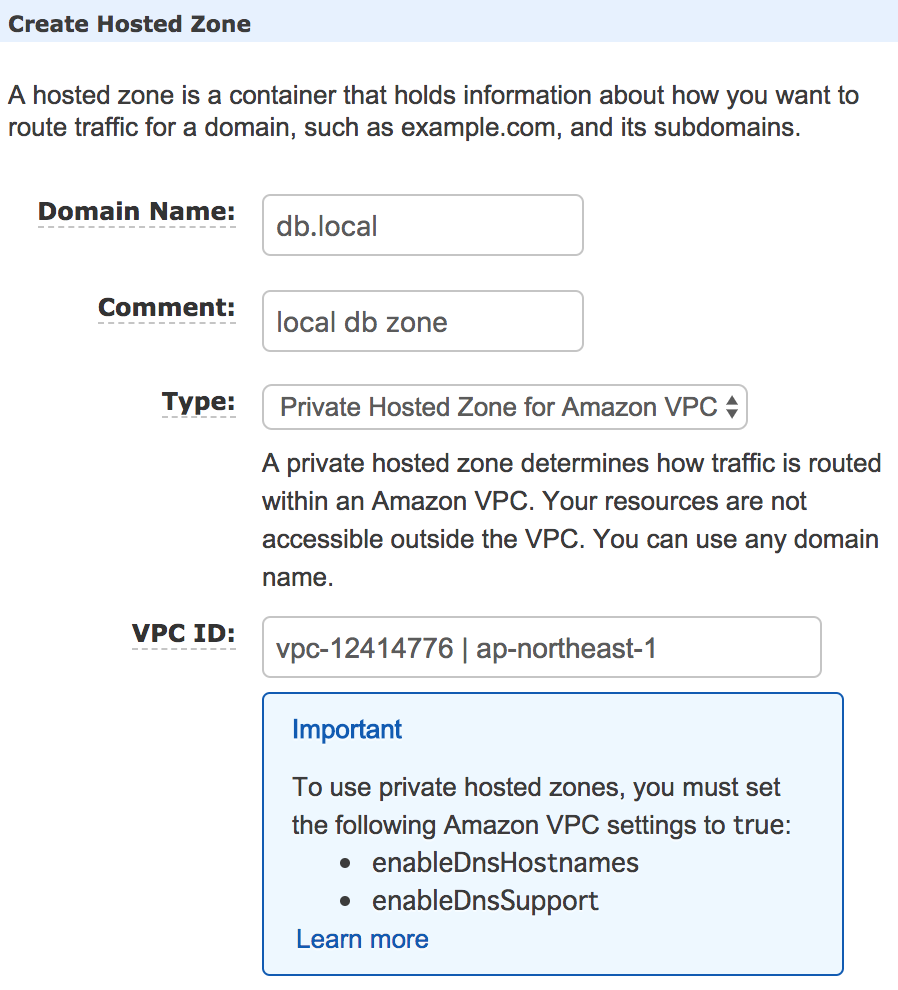
| 設定項目 | 入力値 | 説明 |
|---|---|---|
| Domain Name | db.local | VPC内で利用する任意のドメイン名 |
| Comment | local db zone | 任意の説明 |
| Type | Private Hosted Zone | ホストゾーンをパブリックで利用するかどうか |
| VPC ID | 割り当てるVPCID | プライベートゾーンの場合、割り当てるVPC |
プライベートホストゾーンが作成されます。
また、プライベートホストゾーンを割り当てたVPCでは、DNSサポートを更新する必要があります。こちら(VPC での DNS の使用)を参考に、設定しておいてください。
手順4「リードレプリカに対するCNAMEレコードを作成し、ヘルスチェックを割り当てる」
作成したプライベートホストゾーンで、「Create Record Set」をクリックし、レコードを作成します。まずは、リードレプリカ1号機に対して設定します。

- Name
- アプリケーションサーバからリードレプリカにアクセスする時に利用するCNAMEを指定します
- ここでは、readを指定します。これにより、read.db.localで、リードレプリカにアクセスできます
- Type
- Cnameを設定
- Alias:Noを選択
- 切替を迅速にするためTTLを10に指定
- Valueには、リードレプリカのエンドポイントを設定します。ここでは、リードレプリカ1号機のエンドポイントを指定
- Routing Pollicy:Weightedを選択
- Weightに10、Set IDに任意の説明文(ここでは、readreplica01)を指定
- Associate With Health Check:Yesを選択
- 割り当てるヘルスチェックを指定。ここでは、リードレプリカ1号機に対する設定のため、先程作成したreadreplica01-hcを指定
同様の手順で、同じCNAMEを利用してリードレプリカの2号機と3号機に対しても設定します。異なる値は、リードレプリカのエンドポイントと、SetID、割り当てるヘルスチェックです。
このように、同じCNAMEread.db.localに対して、レコードが3つ登録できればOKです。

アプリケーションサーバにログインして確認します。digで、先程設定したread.db.localを名前解決します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [ec2-user@ip-10-0-3-208 ~]$ dig read.db.local; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.62.rc1.57.amzn1 <<>> read.db.local;; global options: +cmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5271;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0;; QUESTION SECTION:;read.db.local. IN A;; ANSWER SECTION:read.db.local. 10 IN CNAME hamada-rrdb01.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com.hamada-rrdb01.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com. 3 IN A 10.0.4.253;; Query time: 0 msec;; SERVER: 10.0.0.2#53(10.0.0.2);; WHEN: Sat Mar 3 01:14:33 2018;; MSG SIZE rcvd: 120 |
リードレプリカ1号機が返却されました。TTLが10秒で設定されているので、再度繰り返し実行しながら、リードレプリカ1〜3号機が均等に返却されればOKです。
今回は、各レコードのWeightを全て同じ値の10に設定していますが、この数字を調整することで、それぞれのリードレプリカに対する負荷を調整することができます。
これにて設定は完了。お疲れ様でした!
ヘルスチェックが正常に動作しているか確認する
最後に、ヘルスチェックが正常に動作しているか確認します。今回は、DB接続が1以上でアラートが出るように設定しているので、MySQLでログインして、アラートからヘルスチェックがUnhealthyになるか確認します。
まずは、リードレプリカ1号機にmysqlログイン。
1 2 3 | [ec2-user@ip-10-0-3-208 ~]$ mysql -u hamadadbmaster -h hamada-rrdb01.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com -pEnter password:Welcome to the MySQL monitor. Commands end with ; or \g. |
CloudWatch Alarmに1号機のアラームが上がります。

しばらくすると、Route 53のヘルスチェックも1号機がUnhealthy状態となります。
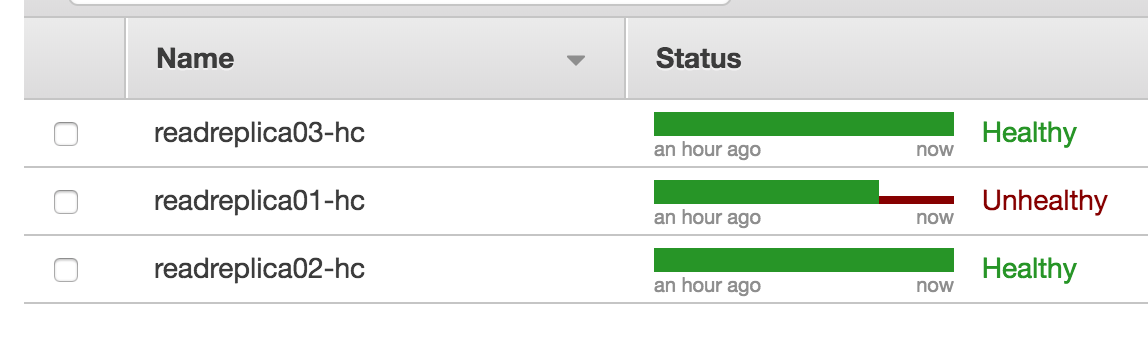
この状態で、digでread.db.localを引いて、何度やってもリードレプリカ1号機が帰ってこないことを確認します。ヘルスチェックがきちんと稼働しているようです。
この状態で、リードレプリカ2号機にmysqlアクセスします。
1 2 3 | [ec2-user@ip-10-0-3-208 ~]$ mysql -u hamadadbmaster -h hamada-rrdb02.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com -pEnter password:Welcome to the MySQL monitor. Commands end with ; or \g. |
今度は、2号機のヘルスチェックがUnhealthyとなります。
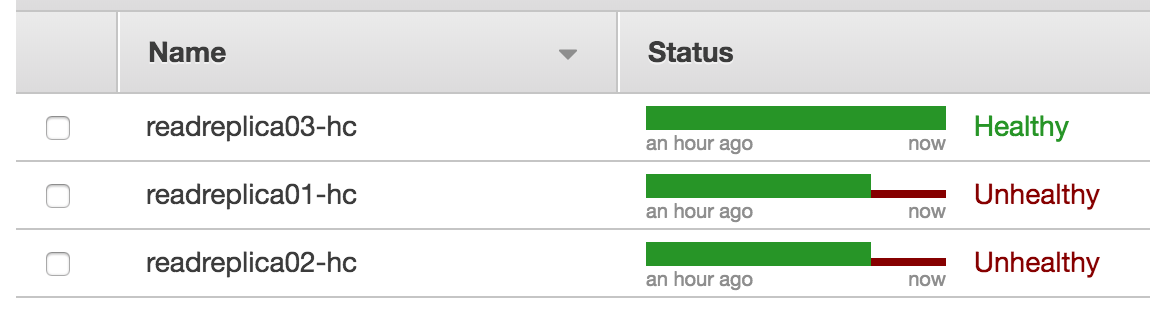
この状態で、read.db.localをひくと3号機しか返ってきません。
さらに3号機にログインすると、全てUnhealty状態に。
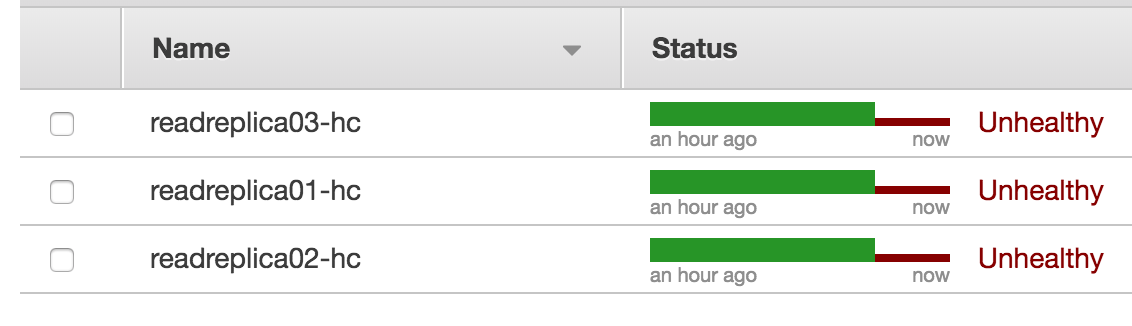
全てUnhealty状態で、read.db.localをひくと、普通に1号機〜3号機のレコードが返ってきます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [ec2-user@ip-10-0-3-208 ~]$ dig read.db.local; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.62.rc1.57.amzn1 <<>> read.db.local;; global options: +cmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59090;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0;; QUESTION SECTION:;read.db.local. IN A;; ANSWER SECTION:read.db.local. 8 IN CNAME hamada-rrdb03.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com.hamada-rrdb03.cdizdukjvbee.ap-northeast-1.rds.amazonaws.com. 3 IN A 10.0.5.119;; Query time: 0 msec;; SERVER: 10.0.0.2#53(10.0.0.2);; WHEN: Sat Mar 3 01:36:25 2018;; MSG SIZE rcvd: 120 |
これは、Route 53のヘルスチェック仕様によるものですが、挙動として意識しておいた方が良いかと思います。
接続していたmysqlからログアウトすると、無事にヘルスチェックがHealtyに戻るのも確認しておきましょう。
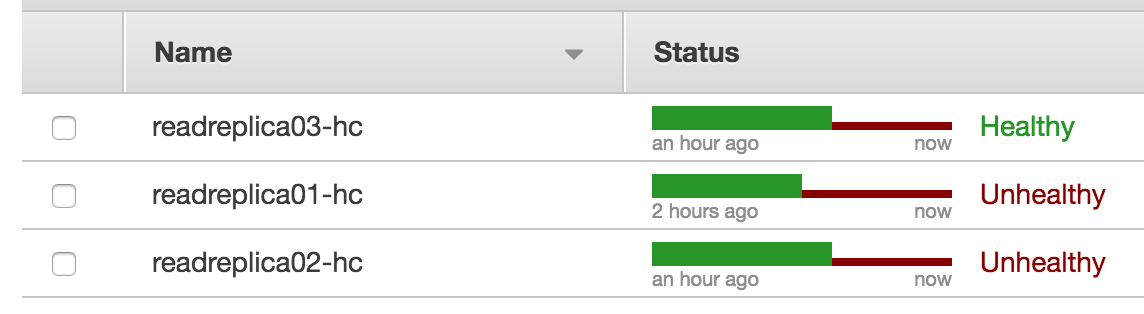
お疲れ様でした!
運用環境での設定における注意点4つ
今回の構成は、あくまで動作検証を主体にしているため、運用環境にそのまま導入するにはいくらか注意点が有ります。
注意点1「適切なCloudWatch メトリクスとアラームを設定する」
今回は、DB接続数をモニタリングしアラーム対象としましたが、実際の運用環境でどのメトリクスをアラーム対象とするかは別途検討が必要です。
以下のページを参考に、適切なモニタリング対象を設定してください。CPU利用率や、IOPS、SELECTスループットなどが設定可能です。
もし、その他任意のメトリクスの利用が必要であれば、CloudWatchのカスタムメトリクスを作成し、それにアラームを設定することも可能です。何かの監視用サーバーからのポート監視なども検討できると思います。
注意点2「Route 53のヘルスチェックにおけるアラーム評価でINSUFFICIENTはUnhealtyにする」
これは検証手順の中で説明した内容です。CloudWatch アラームがINSUFFICIENTを返している場合は、ヘルスチェック結果としては、Unhealtyにすることをオススメします。CloudWatch アラームがINSUFFICIENTとは、メトリクスの値が何らかの原因で取得できていない状況を表します。
例えば極端な例ですが、リードレプリカにメトリクスを設定しアラートを作成したのち、リードレプリカごと削除した場合、アラームの状態は「NG」ではなく「INSUFFICIENT」になります。
「INSUFFICIENT」になる原因は他にも可能性がありますが、何かしらデータベースに不具合がある可能性が高いので、ヘルスチェックとしては、「Unhealthy」にすることをオススメいたします。
注意点3「CloudWatch アラーム、およびRoute 53のヘルスチェックは必ず通知する」
検証手順では省略しましたが、CloudWatch アラームの発生時、およびRoute 53のヘルスチェックがUnhealtyになった時は、必ず通知が来るように設定しておきましょう。ヘルスチェックによるルーティング変更はあくまでアプリケーションの可用性を高めるための暫定対応。異常発生時は、障害原因の究明はできるだけ早急に実施するべきです。
注意点4「CNAMEレコードのTTLを短めに設定しておく」
Route 53のヘルスチェックにより、レコードがUnhealtyになったとしても、CNANMEのTTLが長い場合、アプリケーション・サーバーにキャッシュが残り、エンドポイントの切替が遅くなります。
特に問題がなければ、今回の設定と同じ10秒、もしくはもっと短く5秒〜1秒で設定しても良いかと思います。
AWSマネージドサービスのみでの冗長構成手段の手法として検討に入れておきたい
今回は、RDSのリードレプリカを題材に、VPC内のプライベート領域における負荷分散および冗長構成をCloudWatch アラームとRoute 53のみで設定してみました。
通常、リードレプリカを複数台構成しアプリケーションサーバからアクセスさせる場合、間にプロキシサーバーを構築する方法もありますが、其の場合そのプロキシサーバーがSPOF(単一障害点)になるというジレンマがあります。
アプリケーションサーバにHAProxyをインストールする方法もありますが、通常はアプリケーションサーバも複数台構成なので、インストールの手間や設定の同期など、運用負荷が高くなってしまいがちです。
こういったジレンマを解決する時に、今回紹介した方法は有用かと思います。運用上の注意点はありますが、それを考慮した上で導入を検討いただければと思います。
それでは、今日はこのへんで。濱田(@hamako9999)でした。
余談:リーダーエンドポイントがあるAuroraの素晴らしさ
実はAuroraには、リードレプリカアクセスを一意にするための読み込みエンドポイントが提供されています。
現在、AuroraにはMySQLだけではなくPostgreSQLも提供されているので、このユースケースの場合、まずはAuroraへの移行も検討してみてください。