
この記事について
本記事はPythonを使ったWebスクレイピングのテクニックを紹介します。
Webスクレイピングのテクニック集ですので、基本的にRubyだろうがGolangだろうがほぼ同様なことができます。
本記事で扱った方法は全て個人的に使う時に役に立った方法です。
大体これらのテクニックを使えればなんでも取得できます。
むしろ、できないWebスクレイピングができないサイトがあればコメントにて教えてください。全身全霊を持ってやってみます。
そしてこの記事にテクニック例として載せたいと思います。
また、Webスクレイピングをしたことが無い方は下記の記事を読むことをお勧めします。
Python Webスクレイピング 実践入門 - Qiita
はじめに
お約束の注意事項です。
過度なアクセスはサーバに負担をかけてしまいます。常識の範囲内での使用をオススメします。
岡崎市立中央図書館事件(Librahack事件) - Wikipedia
テクニック集
・CSSセレクターを使用してサクっと取得しよう
CSSセレクターはご存知ですか?
CSSを書いたことがある方はわかりますが、例えばこんなやつです。
#foo{
color: #red;
}
#foo > .hoge{
color: #blue;
}
どの部分がCSSセレクターかというと#fooという部分と#foo > .hogeの部分です。
このコードの意味はidがfooという要素に対してcolor: #redを適用し
idがfooの要素の子要素の中でclassがhogeという要素に対してcolor: #blueを適用するcssです。
具体的にどう変化するかと言いますと
<html>
<body>
<div id="foo">
<p>赤だよ!</p>
<div class="hoge">
<p>青だよ!</p>
</div>
<div class="hogehoge">
<p>赤だよ!</p>
</div>
</div>
</div>
</body>
</html>
って感じです。
この#fooと#foo > .hogeという部分がどこに適用するのかを指定しています。
これを使ってどこを取得するかを指定します。
CSSセレクターについて、詳しくは下記のサイトを参照してください。
CSS セレクター - MDN Web Docs
動作するコード
PythonとBeautifulSoupを使って取得します。
お題は日本経済新聞の日経平均株価を取得します。
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# アクセスするURL
url = "https://www.nikkei.com/markets/kabu/"
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(url)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
print soup.select_one("#CONTENTS_MARROW > div.mk-top_stock_average.cmn-clearfix > div.cmn-clearfix > div.mkc-guidepost > div.mkc-prices > span.mkc-stock_prices").text
ね?簡単でしょ?
といく人はまずいないでしょう。
このコードで指定するためのCSSセレクターは
#CONTENTS_MARROW > div.mk-top_stock_average.cmn-clearfix > div.cmn-clearfix > div.mkc-guidepost > div.mkc-prices > span.mkc-stock_prices
とバカでかいです。
これをいちいち書いていたらサクッとどころの話ではありません。
でも実は簡単にCSSセレクターを生成することができるんです。
そう、「Google Chrome」ならね
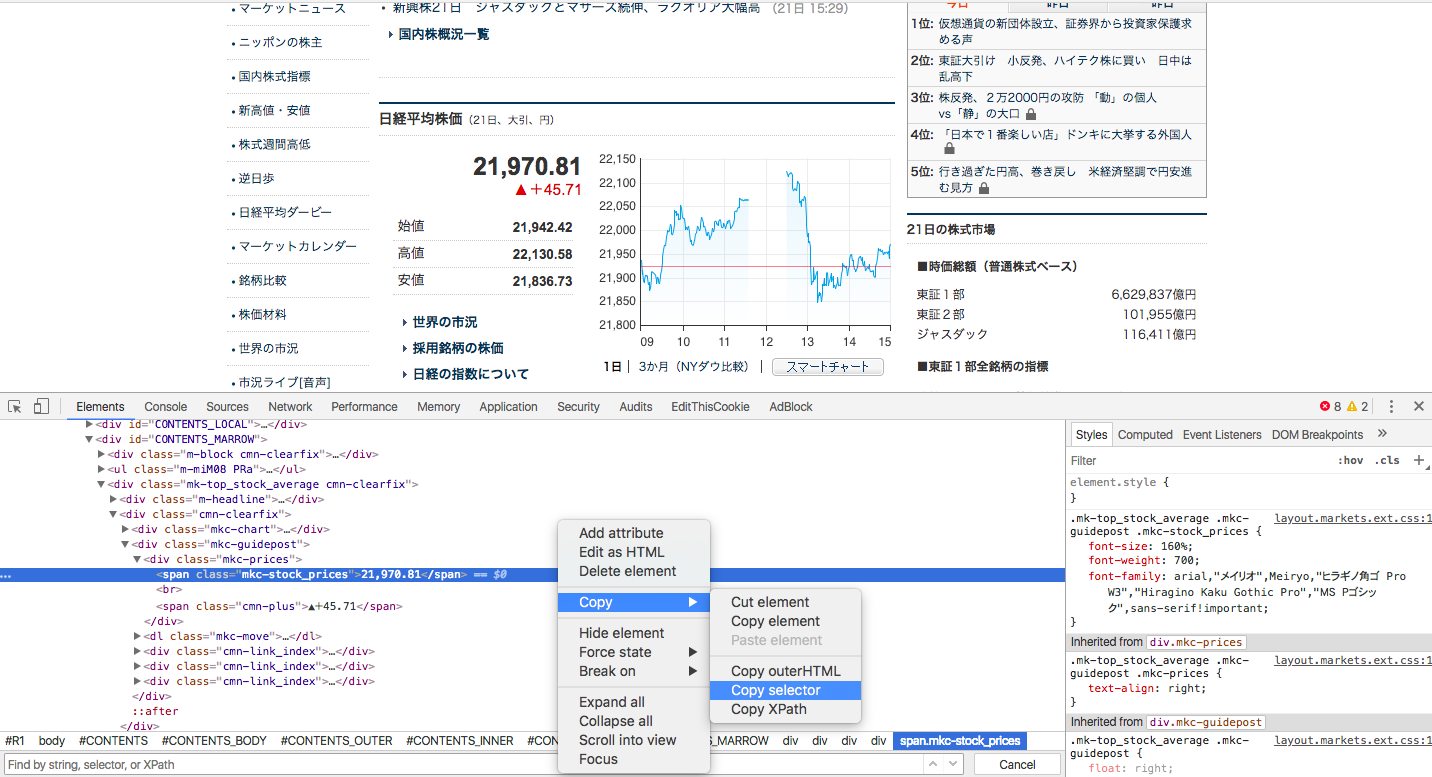
いつもの開発者ツールを使って、欲しい値が存在する要素を「右クリック→Copy→Copy selector」とするとあら不思議クリップボードにCSSセレクターがコピーされています。
後はpythonのselect_one関数の引数にぶち込むだけでおけおけおっけー!
ね?簡単でしょ?
基本的にCSSセレクターをマスターすればどんな値であろうが取得できます。
Google Chromeの生成するCSSセレクターで出来ない場合
Google Chromeの生成するCSSセレクターで出来ない場合があるんです。
例えば下記のHTMLだと出来ません。最初は出来ても次からは出来ない可能性が高いです。
<html>
<body>
<div id="20171224">
<p>今日の日経平均株価は</p>
<div class="114514">
<p>114514</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</div>
</body>
</html>
見たらわかると思いますが、idとclassの値が動的なのがわかりますよね?
日付と日経平均の値がそのままidになってます。
おそらく明日になるとこう変化するでしょう
<html>
<body>
<div id="20171225">
<p>今日の日経平均株価は</p>
<div class="114194">
<p>114194</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</div>
</body>
</html>
そして、Google Chromeが生成するCSSセレクターはこうなります。
#20171224 > div.114514 > p
これではその日は良くても次の日からは確実に値を取得することができません。
手動でちゃんと書けばそんなことにはならないんですが、いちからCSSセレクターを書くのも面倒ですよね。。。
でも大丈夫!......そう、「Google Chrome」ならね
そういう時は開発者ツールでHTML上からidやclassを消してしまいばいいんです。
開発者ツールでは読み込んだHTMLを自由に編集することができるので下記のように編集します
<html>
<body>
<div>
<p>今日の日経平均株価は</p>
<div>
<p>114194</p>
</div>
<div class="hoge">
<p>円です!</p>
</div>
</div>
</body>
</html>
そして、Google Chromeでもう一度生成をします。すると・・・
body > div:nth-child(1) > div:nth-child(1) > p
というふうに動的に変化する物を除いてCSSセレクターを再生成します。
これなら明日以降でも大丈夫そうですね!
RSS Feedを活用しよう!
例えば、1日で記事が消されてしまうサイトの記事をWebスクレイピングしてタイトルと内容を記録したい!という時にはうってつけです。
RSS Feedはサイトの情報や記事の情報が記載された物です。
サイト運営者はこのRSS Feedを使って画RSSなどで相互リンクもしますし、Google Search Console(旧Google Web Master tool)にサイトの情報を送信してインデックスしてもらいます(検索エンジンに自分のサイトを出るようにする作業みたいなものです)。
基本的にインターネット上に公開するのであれば絶対に必要な物です。
下記のサイトを使用すればRSS Feedのリンクがサクッとわかります。
RSSフィード取得・検出ツール - BeRSS.com
例としてYahooの日経トレンディネットのRSSを使います
https://headlines.yahoo.co.jp/rss/trendy-all.xml
動作するコード
今回はfeedparserというライプラリを使いますpip install feedparserでインストールできます。
ドキュメントは下記になります。
https://pythonhosted.org/feedparser/
# coding: UTF-8
import feedparser
import urllib2
from bs4 import BeautifulSoup
# 取得するRSSのURL
RSS_URL = "https://headlines.yahoo.co.jp/rss/trendy-all.xml"
# RSSから取得する
feed = feedparser.parse(RSS_URL)
# 記事の情報をひとつずつ取り出す
for entry in feed.entries:
# タイトルを出力
print entry.title
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(entry.link)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 例としてタイトル要素のみを出力する
print soup.title
あとはBeautifulSoupを使って記録したい物を記録すればいいと思います。
今回は例としてタイトル要素を摘出しています。
結果としては下記になります
高級コンパクトデジタルカメラはキヤノンとソニーの二強対決!?(日経トレンディネット)
<title>高級コンパクトデジタルカメラはキヤノンとソニーの二強対決!? (日経トレンディネット) - Yahoo!ニュース</title>
カプコン 辻本Pに聞く 新作『モンハンワールド』は何がすごい?(日経トレンディネット)
<title>カプコン 辻本Pに聞く 新作『モンハンワールド』は何がすごい? (日経トレンディネット) - Yahoo!ニュース</title>
iPad用キーボード探しの旅:Bluetooth接続の「KEYS-TO-GO」を試す!(日経トレンディネット)
<title>iPad用キーボード探しの旅:Bluetooth接続の「KEYS-TO-GO」を試す! (日経トレンディネット) - Yahoo!ニュース</title>
以下略...
JavaScriptによる描画に対応する
例えば、React.jsを使ったウェブサイトだとページにアクセスしてから必要な情報が描画される場合があります。
よくわからない人は1度下記のhtmlを保存してブラウザで表示してみてください。
すると、今日の日経平均株価は114514円ですと表示されます。
<html>
<head>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/react.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/JSXTransformer.js"></script>
</head>
<body>
<div>
<p>今日の日経平均株価は</p>
<div id="heikin"></div>
<script type="text/jsx">
/** @jsx React.DOM */
React.renderComponent(
<p>114514</p>,
document.getElementById('heikin')
);
</script>
<p>円です!</p>
</div>
</body>
</html>
<html>
<head>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/react.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/react/0.11.2/JSXTransformer.js"></script>
</head>
<body>
<div>
<p>今日の日経平均株価は</p>
<div id="heikin"><p data-reactid=".0">114514</p></div>
<script type="text/jsx">
/** @jsx React.DOM */
React.renderComponent(
<p>114514</p>,
document.getElementById('heikin')
);
</script>
<p>円です!</p>
</div>
</body></html>
<div id="heikin"><p data-reactid=".0">114514</p></div>と114514が表示されてますね。
では、Webスクレイピングしてみましょう
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# htmlオブジェクトが帰って来る
html = urllib2.urlopen("file:///Users/admin/Desktop/index.html")
# htmlオブジェクトをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 平均の値を取得する
print soup.select_one("#heikin")
<div id="heikin"></div>
あれれ・・・
JavaScriptはブラウザ側で動作するため、HTMLをそのまま持ってきただけではダメで
HTML内部のJavaScriptが実行しなければ表示がされません。
でも大丈夫!
......
そう、「Google Chrome」ならね
ブラウザで正しく描画できるならブラウザを使ってWebスクレイピングすればいいんです。
何を言ってるか分からない人が出てもおかしく無いので簡単に言うと、WebブラウザをPythonを使って操作してブラウザで描画させた後にそのHTMLを引っ張って来ます。
ブラウザをPythonで操作するためにSeleniumというソフトウェアを使います。
もともとSeleniumとは、Webブラウザを使ってWebアプリケーションをテストするツールですが、こういうことにも使えます。
ブラウザソフトは今回は一番メジャーなPhantomJSを使おうかと思いましたが、SeleniumがPhantomJSのサポートを終了するみたいなのでGoogle ChromeのHeadlessモードでやってみたいと思います。
Headlessモードとはバックグラウドで動くモードです。
実際には普通のブラウザとして動いていますが、デスクトップには表示されません。
Seleniumのドキュメントはこちら
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.chrome.webdriver
pip install selenium
動作するコード
# coding: UTF-8
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ブラウザのオプションを格納する変数をもらってきます。
options = Options()
# Headlessモードを有効にする(コメントアウトするとブラウザが実際に立ち上がります)
options.set_headless(True)
# ブラウザを起動する
driver = webdriver.Chrome(chrome_options=options)
# ブラウザでアクセスする
driver.get("file:///Users/admin/Desktop/index.html")
# HTMLを文字コードをUTF-8に変換してから取得します。
html = driver.page_source.encode('utf-8')
# parse the response
soup = BeautifulSoup(html, "html.parser")
print soup.select_one("#heikin")
<div id="heikin"><p data-reactid=".0">114514</p></div>
正しく動きましたね。これでJavaScriptにも対応しました。
これでも対応出来ない場合はJavaScriptが最後まで実行される前にHTMLを取得している可能性があるので、取り敢えずSleepを入れたりドキュメントにあるオプションを使えばどうにかなります。(適当)
結論
Google Chrome最強
わかりにくいところや、解説不足、誤字脱字は編集リクエスト、コメントにてお願いします。
このサイトのWebスクレイピングってどうすんの!ってのも募集します。
ありがとうございました。
こちらもどうぞ
Python Webスクレイピング 実践入門
【毎秒1万リクエスト!?】Go言語で始める爆速Webスクレイピング【Golang】
【初心者向け】Re:ゼロから始める遺伝的アルゴリズム【人工知能】
