
はじめに
こんにちは、Speeeでデータサイエンティストをしている@To_Murakamiと申します。エンジニアではないのですが、コーディングを含めた分析例を発信しようと思い、企業のAdvent Calendarに参加させていただきました。
12月も暮れに差し掛かってきましたね。本日は、Word2Vec(ワードトゥベック)という自然言語処理を活用した分析例を紹介します。
このロジックを実装した目的は、ことばの表記ゆれ(類義語)発見器みたいなのを作ってみたいと思ったからです。なぜ、Word2Vecからことばの表記ゆれが分かるのでしょうか?仕組みの概要(下記)が分かると、理由を理解できます。
Word2Vecの仕組み(簡単に)
Word2Vecとは言葉通り、単語をベクトル化したものです。ベクトル化した中身には当然数字が入ります。つまり、単語という言語データを数値化することができるのです!
数値化の仕組みは、ニューラル・ネットワークによる学習と次元圧縮です。

上の図はCBOW(Continuous Bug-of-words)という代表的なモデルを例にしています。入力の段階での各単語は、One-hotベクトルといって、「"ある"か、"ない"かのフラグ」を"0/1"で表現します。ここでは、「寒い」という単語のベクトル化を学習で算出します。CBOWでは、前後数語の情報も取り込み、投射層に送られます。投射層からニューラル・ネットワークで重みつきの学習をし、出力として、単語ベクトルが算出されます。出力のベクトルの次元数と入力の次元数は異なっても構いません。モデル化のときに指定することができます。(投射層へ前後何語投入するかもコントロール可能です。)
こうして、各単語ベクトルが算出されます。ベクトルを構成するひとつひとつの数字が単語の意味や特徴を示します。これを支える思想は、「同じような意味や使われ方を示す単語は、同じような単語の並びで登場する」という前提です。この前提を受け入れるとすると、ベクトルの近しい単語同士は、似た意味を包含すると仮説づけることができます。表記ゆれの似た単語や、意味の同じ類義語ではベクトルが近しいでしょうから、コサイン類似度といった尺度で抽出できると予想できます。
※半年ほど前に関連する記事を投稿しました。参照ください。
http://qiita.com/To_Murakami/items/6bd5638689166ec4821c
近しい単語は取れてきたのか?
実際に、仕組みの項における読みは当たるのでしょうか?美容記事11000記事をクローリングし、コーパスを作成して、検証してみました。
結論を言うと、期待以上に似た単語を抽出できました!以下、複数のサンプル例を挙げさせていただきます。
<<例1: 「ダイエット」>>

「ダイエット方法」や「ダイエット法」はまさに今回の目的にドンピシャなアウトプットです。
「近さ」は2単語ベクトルのコサイン類似度で評価しています(上記の"score")。言葉の並びが同じようなパターンほど、類似度が高くなります。
「ダイエット方法」は表記ゆれで「ダイエット」と同じ意味合いです。「痩せる」、「減量」といったことばもダイエットと同じ目的・意味合いを有しており、高い類似度を示しています。
<<例2: 「おしゃれ」>>
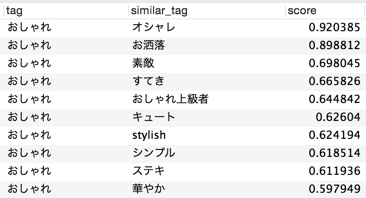
やはり、表記ゆれで同義の「オシャレ」「お洒落」が高い類似度を示します。次いで、「おしゃれ」に対する印象や評価を示す単語が続きます。
<<例3: 「メイク」>>

メイクのような広範な単語については、具体的なメイクを示す単語が上位に来ます(同じような文脈で使われるため)。
<<例4: 「宮崎あおい」>>

宮崎あおいが世の人からどのような立ち位置で見られているか、分かります(^_^;)
<<例5: 「デニム」>>

同じボトムスに当たる服装も表示されますが、デニムと相性のいい上半身のコーディネイトも教えてくれます。
<<例6: 「デブ」>>

容赦ないですね(^_^;)
<<例7: 「クリスマス」>>
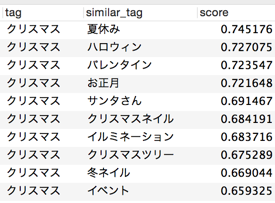
美容関連記事だからか、行事イベント系の単語が列挙されました。コーパスが特定の個人ブログとかだと、アウトプットが変わってくるのかもしれません。
工夫したこと
データの前処理に力を入れることにより、アウトプットの内容がぐっと良くなります。前処理とは形態素解析のことです。不要な単語を削除し、欲しい単語になるように文字列を区切ることができるようになります。
①辞書の拡充
「mecab-ipadic-NEologd」を最新にして学習しました(これは多くの方が知っていると思います)。
NEologdに加えて、独自のロジックで取得した未知語ユーザ辞書を加えました。ユーザ辞書で商品名など、固有名詞かつ最新語を加えました。
②ストップワード
ベクトル化の評価対象にしない単語リストをストップワードとして加えました。1文字の文字列や汎用語を除いた形になります。
実装
gensimというライブラリを使いました。
gensimを使えば、実質わずか数行で実装することができます。ちょー便利♪
※DBによるI/Oのところは省略しています。
#!/usr/bin/python
# -*- coding: utf-8 -*-
from gensim.models import word2vec
import cython
from sqlalchemy import *
import pandas as pd
# fetch taglist from DB
engine_my = create_engine('mysql+mysqldb://pass:user@IP:port/db?charset=utf8&use_unicode=0',echo=False)
connection = engine_my.connect()
cur = connection.execute("select distinct(name) from tag;")
tags = []
for row in cur:
# need to decode into python unicode because db preserves strings as utf-8
# need to treat character sets altogether in one format
tags.append(row["name"].decode('utf-8'))
connection.close()
# Import text file and make a corpus
data = word2vec.Text8Corpus('text_morpho.txt')
# Train input data by Word2Vec(in option below, take CBOW method)
# Take about 5 min when training ~11000 documents
model = word2vec.Word2Vec(data, size=100, window=5, min_count=5, workers=2)
# Save temporary files
model.save("W2V.model")
# make similar word list (dict type)
similar_words = []
for tag in tags:
try:
similar_word = model.most_similar(positive=tag)
for i in range(10):
similar = {}
similar['tag'] = tag
similar['similar_tag'] = similar_word[i][0]
similar['score'] = similar_word[i][1]
similar_words.append(similar)
except:
pass
# Conver dict into DataFrame to filter data easily
df_similar = pd.DataFrame.from_dict(similar_words)
df_similar_filtered = df_similar[df_similar['similar_tag'].isin(tags)]
df_similar = df_similar.ix[:,['tag', 'similar_tag', 'score']]
