

Word(ワード)のデータの中身見たことありますか?Wordデータの断片化問題

情報管理LOGの@yoshinonです。
書類作成などでかなり日常的に使われているWordですが、これのデータの中身を見たことがありますか?案外サクッと見られてしまうのです。今回はデータの中身を見る方法から、さらにそのデータの中身の断片化問題まで含めて取り上げたいと思います。
【 ワードのデータの中身見たことありますか?Wordデータの断片化問題 】 1.Wordファイルのデータの中身を見る方法 2.Word本体のデータを見てみる 3.WindowsにおけるWordファイルの断片化問題 |
まずはWordファイルのデータの中身を見てみたいと思います。
Wordファイルは、XMLデータの集合体だというのは意外と有名な話です。これを見るためには、一度Wordファイルをzipに直します。この直接圧縮するのではなく、拡張子をzipに変えるだけにしてください。
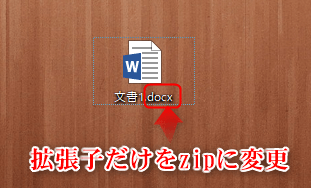
zipファイルに変更されました。

今度は、それを解凍ソフトで解凍します。

そうすると、Wordファイルの中身を見ることができるなのです。
Wordファイルの中身はこんな感じです。
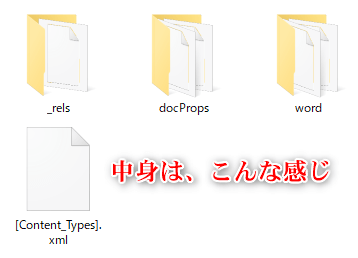
Wordのファイルツリーはこのような形になっています。
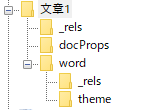
さて、先程中身を取り出したWordファイルの文章は、どこに入力されているのかというと…ここに格納されています。
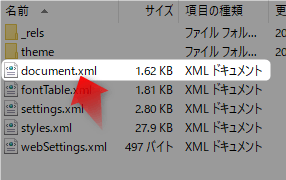
これをメモ帳で開けてみます。
そうすると、中身を見ることができるのです。
出てきた中身は、このようになっています。まさにXMLで定義されたファイルになっていますね(しかもあまり美しくない)。

私は、Wordファイルには、かなり致命的な欠陥があると思っています。たぶん、Wordで長文執筆した人は経験があるのではないかと思うのですが、書けば書くほど、どんどん重たくなってくるという問題が発生します。
これは、Wordファイルの断片化が起こっていると考えられます。
これについては、実は既に指摘されていたりします。
昨年、話題になった記事です。

Wordさんは今日もおつかれです - Qiita

この記事では、MacのWordについて取り上げられてますが、ウィンドウズのWordにおいても(ここまで酷くはないけど)同様であると考えられます。
先ほどのファイルに「Wordファイル断片化」と書き加えたモノ。

| <w:body> | |
| <w:p w:rsidR="00F91171" w:rsidRDefault="00FB5B5A"> | |
| <w:r> | |
| <w:t>ワードファイルの実験です。</w:t> | |
| </w:r> | |
| </w:p> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"/> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"> | |
| <w:pPr> | |
| <w:rPr> | |
| <w:rFonts w:hint="eastAsia"/> | |
| </w:rPr> | |
| </w:pPr> | |
| <w:r> | |
| <w:t>Word</w:t> | |
| </w:r> | |
| <w:r> | |
| <w:t>ファイル断片化</w:t> | |
| </w:r> | |
| <w:bookmarkStart w:id="0" w:name="_GoBack"/> | |
| <w:bookmarkEnd w:id="0"/> | |
| </w:p> | |
| <w:sectPr w:rsidR="002171AD"><w:pgSz w:w="11906" w:h="16838"/> | |
| <w:pgMar w:top="1985" w:right="1701" w:bottom="1701" w:left="1701" w:header="851" w:footer="992" w:gutter="0"/> | |
| <w:cols w:space="425"/> | |
| <w:docGrid w:type="lines" w:linePitch="360"/> | |
| </w:sectPr> | |
| </w:body> |
その後に、「Wordファイル断片化」の文章の間に「の」を加えて、「Wordファイルの断片化」としてみます。そうすると…

| <w:body> | |
| <w:p w:rsidR="00F91171" w:rsidRDefault="00FB5B5A"> | |
| <w:r> | |
| <w:t>ワードファイルの実験です。</w:t> | |
| </w:r> | |
| </w:p> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"/> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"> | |
| <w:pPr> | |
| <w:rPr> | |
| <w:rFonts w:hint="eastAsia"/> | |
| </w:rPr> | |
| </w:pPr> | |
| <w:r> | |
| <w:t>Word</w:t> | |
| </w:r> | |
| <w:r> | |
| <w:t>ファイル</w:t> | |
| </w:r> | |
| <w:r w:rsidR="008A19CA"> | |
| <w:t>の</w:t> | |
| </w:r> | |
| <w:bookmarkStart w:id="0" w:name="_GoBack"/> | |
| <w:bookmarkEnd w:id="0"/> | |
| <w:r> | |
| <w:t>断片化</w:t> | |
| </w:r> | |
| </w:p> | |
| <w:sectPr w:rsidR="002171AD"> | |
| <w:pgSz w:w="11906" w:h="16838"/> | |
| <w:pgMar w:top="1985" w:right="1701" w:bottom="1701" w:left="1701" w:header="851" w:footer="992" w:gutter="0"/> | |
| <w:cols w:space="425"/> | |
| <w:docGrid w:type="lines" w:linePitch="360"/> | |
| </w:sectPr> | |
| </w:body> |
ただ単に書式も何も変えずに「の」を加えただけにもかかわらず、余計なタグが付け加わっていることが分かります。 文章作成時にカット&ペースを繰り返したり、文章の途中に文字を加えたりするなどすると余計なタグがどんどん付け加わってくるのです。これに、さらに書式を変更したりすると、もっとカオスなことになってくるというのは、容易に想像がつきますね?
さらに、「Wordファイル断片化」を「Wordのファイルの断片化問題」と文章中に挿入してみると…

| <w:body> | |
| <w:p w:rsidR="00F91171" w:rsidRDefault="00FB5B5A"> | |
| <w:r> | |
| <w:t>ワードファイルの実験です。</w:t> | |
| </w:r> | |
| </w:p> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"/> | |
| <w:p w:rsidR="002171AD" w:rsidRDefault="002171AD"> | |
| <w:r> | |
| <w:t>Word</w:t> | |
| </w:r> | |
| <w:r w:rsidR="009E27EA"> | |
| <w:t>の</w:t> | |
| </w:r> | |
| <w:r> | |
| <w:t>ファイル</w:t> | |
| </w:r> | |
| <w:r w:rsidR="009E27EA"> | |
| <w:t>の</w:t> | |
| </w:r> | |
| <w:r> | |
| <w:t>断片化</w:t> | |
| </w:r> | |
| <w:r w:rsidR="009E27EA"> | |
| <w:t>問題</w:t> | |
| </w:r> | |
| <w:bookmarkStart w:id="0" w:name="_GoBack"/> | |
| <w:bookmarkEnd w:id="0"/> | |
| </w:p> | |
| <w:sectPr w:rsidR="002171AD"> | |
| <w:pgSz w:w="11906" w:h="16838"/> | |
| <w:pgMar w:top="1985" w:right="1701" w:bottom="1701" w:left="1701" w:header="851" w:footer="992" w:gutter="0"/> | |
| <w:cols w:space="425"/> | |
| <w:docGrid w:type="lines" w:linePitch="360"/> | |
| </w:sectPr> | |
| </w:body> |
となるのです。
たったこれだけでも、こうなるのですから、長文になるとお察しですね。
どうしてこういう仕様にしたのやら…
そもそもどうしてXMLでデータを組もうとしたのか…と言っても始まらないかもしれないのですが、初期のOfficeの制作者陣は、まさかこんなにもこの技術が引っ張られるとも考えていなかったのかもしれません。とはいえ、こうやってファイルの中身がどんどん意味もなく重たくなってくる問題は、いずれかの時期に解消してもらいたいものだと思います。少なくとも、タグクリーン機能でも良いから付けてもらえると嬉しいですよね。
例の「東ロボくん」の研究が、関するまとまった形の本になりました!

- 関連記事
-
- Word(ワード)のデータの中身見たことありますか?Wordデータの断片化問題
- Apple PayにiPhoneのアプリだけでSuicaを入れてみた
- iPhoneのためにBluetoothイヤフォンを買いました
Zenback読み込み中です。