
この記事は Go Advent Calendar 2017 の記事です。
アダムとイブ
男と女が寄りそうとどうなるのか。これは神様がアダムとイブという異なる性を地に授けた時から既に決まっている事なのもしれません。

このお題を解き明かしたい。Go 言語を使って。
ネタとしては以下の記事を参考にしました。
どうしたら「彼女」から「奥さん」になれるかを『Word2Vec』に聞いてみた | 人工知能ニュースメディア AINOW
男と女が寄りそう事。それはつまり「男」というベクトルと「女」というベクトルが合わさった時にどの様な結果が得られるのかという事なのです。
そこで今回は「男」というワードと「女」というワードのベクトルを合成する為に word2vec を使ってこのお題を調べてみようと思います。
word2vec とは
自然言語処理を行う手法の一つとして word2vec があります。word2vec は2014年、Google によって発表された多次元ベクトルで表された連続する単語から、その合成された単語を予測する仕組みの事を言います。
word2vec の仕組みの詳細については以下の URL が一番丁寧で適切に解説されています。
Word2Vec のニューラルネットワーク学習過程を理解する · けんごのお屋敷
後継に doc2vec という物もありますが今回は word2vec で。
学習データの作成
word2vec を使うにはまず学習させる必要があります。男と女の事なら発言小町に聞くしかありません。発言小町の「男女カテゴリ」でアクセスが多い順にソートしたページからスクレイピングして本文を拝借してみます。Go でスクレイピングと言えば goquery が有名ですね。
https://github.com/PuerkitoBio/goquery
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"time"
"golang.org/x/text/encoding/japanese"
"github.com/PuerkitoBio/goquery"
)
func topicList() ([]string, error) {
resp, err := http.Get("http://komachi.yomiuri.co.jp/?g=04&o=2")
if err != nil {
return nil, err
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(japanese.ShiftJIS.NewDecoder().Reader(resp.Body))
if err != nil {
return nil, err
}
uris := []string{}
doc.Find(".topicslist .hd a").Each(func(n int, s *goquery.Selection) {
href, ok := s.Attr("href")
if !ok {
return
}
uris = append(uris, "http://komachi.yomiuri.co.jp"+href)
})
return uris, nil
}
func saveTopic(filename string, uri string) error {
resp, err := http.Get(uri)
if err != nil {
return err
}
defer resp.Body.Close()
doc, err := goquery.NewDocumentFromReader(japanese.ShiftJIS.NewDecoder().Reader(resp.Body))
if err != nil {
return err
}
text := doc.Find("#topiccontent p").First().Text()
err = ioutil.WriteFile(filename, []byte(text), 0644)
if err != nil {
return err
}
return nil
}
func main() {
uris, err := topicList()
if err != nil {
log.Fatal(err)
}
for n, uri := range uris {
log.Println(uri)
err = saveTopic(fmt.Sprintf("data/data%03d.txt", n+1), uri)
if err != nil {
log.Fatal(err)
}
time.Sleep(5 * time.Second)
}
}
これで本文をテキストで得られます。ただし word2vec に入力データとして投入する為には、単語でなければなりません。そこで得られたテキストを分かち書きに直す必要がある訳です。Go で形態素解析と言えば kagome ですね。
package main
import (
"bufio"
"fmt"
"log"
"os"
"strings"
"github.com/ikawaha/kagome/tokenizer"
)
func main() {
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
text := strings.TrimSpace(scanner.Text())
if text == "" {
continue
}
tokens := tokenizer.New().Tokenize(text)
n := 0
for _, token := range tokens {
features := token.Features()
if len(features) == 0 || token.Surface == "BOS" || token.Surface == "EOS" {
continue
}
if n > 0 {
fmt.Print(" ")
}
if features[6] == "*" {
fmt.Print(token.Surface)
} else {
fmt.Print(features[6])
}
n++
}
fmt.Println()
}
if scanner.Err() != nil {
log.Fatal(scanner.Err())
}
}
標準入力から得た行を tokenizer で解析します。これを使うと例えば
ここで履物を脱いで下さい
このテキストから以下のテキストが出力されます。
ここ で 履物 を 脱ぐ で 下さる
個々のワードは空白で区切られます。

さっそく発言小町から得たテキストを分かち書きに直します。(ワカチコワカチコー♪)
$ ls --sort data/data*.txt | sort | xargs cat | ./wakachi > all.wak
出来上がったデータを word2vec に食わせるのですが、実は Go で実装された word2vec もあります。
https://github.com/koji-ohki-1974/word2vec
こちらも色々と試してみたのですが、オリジナル版の実装と異なる結果が得られてしまったので、残念ながらここだけ Go でない実装を使います。
先ほど作った分かち書き文書の各単語をベクトル化します。
$ word2vec -binary 0 -threads 1 -cbow 0 -alpha 0.025 -size 100 -min-count 1 -window 10 -hs 1 -negative 0 \
-train all.wak -output data.model
negative: 0
TrainModel
Starting training using file all.wak
LearnVocabFromTrainFile
SortVocab
Vocab size: 3580
Words in train file: 39858
InitNet
CreateBinaryTree
TrainModelThread
Alpha: 0.002485 Progress: 95.08% Words/thread/sec: 23.69k
出力された data.model には以下の様に単語とそれが指すベクトル値が出力されています。
お金 0.113968 0.111524 -0.057632 -0.006930 0.121999 0.008002 -0.310006 -0.098203 -0.071975 ... 略
彼女 0.228713 -0.056997 0.054521 -0.200337 -0.033304 -0.024358 -0.044285 -0.150410 0.028349 ... 略
理由 0.238914 -0.029254 -0.065014 -0.030943 0.325596 -0.016095 -0.086502 -0.015941 -0.049553 ... 略
単語の加算器を作る
次にこの単語に対するベクトルを加算する仕組みを作ります。まずはこの word2vec が出力したフォーマットを読み取る必要があります。word2vec のモデルフォーマットは簡単で以下の様な形式になっています。
137 100
</s> 0.004003 0.004419 -0.003830 ... 略
を 0.002280 -0.004953 0.004315 ... 略
は -0.004434 -0.003260 0.003485 ... 略
で -0.004731 0.002778 0.001338 ... 略
先頭はボキャブラリのサイズとレイヤ1(多段の学習域の最初の部分)のサイズ。また word2vec のフォーマットにはテキストフォーマットとバイナリフォーマットがあります。テキストフォーマットは
137 100
</s> [ベクトルデータ]
このベクトルデータ部が空白セパレートの可視の数値ですが、バイナリフォーマットは32bit浮動小数点のバイナリ(セパレータ無し)というだけの違いです。テキストフォーマットを読み込むのであれば以下のコードになります。
func LoadText(r io.Reader) (Model, error) {
scanner := bufio.NewScanner(r)
result := Model{}
for scanner.Scan() {
token := strings.Split(strings.TrimSpace(scanner.Text()), " ")
if len(token) < 3 || token[0] == "</s>" {
continue
}
vec := []float64{}
for i := 1; i < len(token); i++ {
val, err := strconv.ParseFloat(token[i], 64)
if err != nil {
return nil, err
}
vec = append(vec, val)
}
result = append(result, &Vector{
word: token[0],
vec: vec,
elems: []string{token[0]},
})
}
if err := scanner.Err(); err != nil {
return nil, err
}
return result, nil
}
Vector struct に元の単語を slice で格納していますが、これは以降で予測単語を抽出する際に自らの単語を含まない様にする為です。例えば A と B という単語の加算を行った時に予測単語として A が最上位に来てしまうと本末転倒になってしまいますね。
データが読み込めたら加算処理を書きます。とは言っても線形代数でしかないですが。
func (lhs *Vector) Add(rhs *Vector) *Vector {
if lhs == nil {
return rhs
}
if rhs == nil {
return lhs
}
l := min(len(lhs.vec), len(rhs.vec))
vec := make([]float64, l)
copy(vec, lhs.vec)
saxpy(l, 1, rhs.vec, 1, vec, 1)
elems := make([]string, len(lhs.elems)+len(rhs.elems))
elems = append(elems, rhs.elems...)
elems = append(elems, lhs.elems...)
return &Vector{
word: rhs.word + " + " + lhs.word,
vec: vec,
elems: elems,
}
}
入力データの考察
今回で試してみて分かった事としては
入力データ(今回であれば発言小町の記事)では極力ノーマライズしない
という事です。空白や改行は構わないのですが句読点やカッコなど単語としてふさわしくない物を初めから除外すると、それだけでその他の単語のベクトルが変わってしまうからです。例えば
主人が「今日は飲み会」と言ってました
このカッコも実は重要なのです。これを分かち書きして word2vec に食わせた物と、カッコを取り払って word2vec に食わせた物だと、同じ「主人」であってもベクトルが変わるという事です。

何度も試したい → repl サイコー

さて何時もの事なのですが、そろそろ横道にそれる時間がやってきました。今回これを実装していて何度も何度も結果を試す必要があったのですが、なにぶんその度にソースを書きかえたり足し算や引き算を変えてみたりと、なかなか大変だったのです。機械学習は巨大なデータとマシンリソースと、そして時間をあぶくの様に使いますね。こりゃ repl を実装すべきなんじゃね?と思ったので 発言小町専用repl を作ってみようと思いました。やりたい事は以下の通りです。
> 男 + 女
これを実装するには字句解析と構文解析を行う必要があります(ちょっとアナタそこ強引だなとか言わない)。Go で構文解析ツールとしてはオフィシャルが提供する goyacc がありますが、字句解析ツールは提供されていません。今回は Go で C コンパイラを作ったりしている あの 変態 奇才 cznic 氏が開発している golex を使いました。単語の定義としては UTF-8 な文字というルールでしかありませんので定義は以下の様になりました。
%{
... 略 ...
func clazz(r rune) int {
if r < 0 || unicode.IsSpace(r) || r == '+' || r == '-' {
return int(r)
}
return 0x80
}
func newLexer(model w2v.Model, src *bufio.Reader) *lexer {
f := token.NewFileSet().AddFile("w2v", -1, 1<<31-1)
lx, err := lex.New(f, bufio.NewReader(src), lex.RuneClass(clazz))
if err != nil {
panic(err)
}
return &lexer{Lexer: lx, model: model}
}
func (l *lexer) Lex(lval *yySymType) int {
c := l.Enter()
%}
%yyc c
%yyn c = l.Next()
%yym l.Mark()
wordChar \x80
word {wordChar}+
%%
c = l.Rule0()
[ \t\r]+
{word}
s := strings.TrimSpace(string(l.TokenBytes(nil)))
if s != "" {
if lval.value = l.model.Find(s); lval.value == nil {
l.Error(fmt.Sprintf("%q not found", s))
lval = nil
}
return VALUE
}
%%
if c, ok := l.Abort(); ok { return int(c) }
goto yyAction
}
これを golex に食わせて字句解析器を作って貰います。
$ golex -o tokenizer.go tokenizer.l
どの様な仕組みで unicode 文字を認識しているかはソースを確認下さい。また構文解析器の定義は以下の通り。
%{
... 略 ...
%}
%union{
value *w2v.Vector
}
%token VALUE
%left '-' '+'
%type <value> VALUE, exp
%%
input: /* empty */
| input line
;
line: '\n'
| exp {
yylex.(*yylexer).vector = $1
}
;
exp: VALUE { $$ = $1 }
| exp '+' exp { $$ = $1.Add($3) }
| exp '-' exp { $$ = $1.Sub($3) }
;
%%
今回は足し算と引き算しか用意していません。興味のある方は 女 + (王様 - 男) の様にカッコの実装をしてみても面白いかもしれません。こちらも goyacc に食わせて構文解析器を作って貰います。
$ goyacc -o expr.go expr.y
このパーサを使った実装は以下の様になりました。
func newEval(model w2v.Model) *eval {
return &eval{
model: model,
}
}
func (e *eval) Do(s string) (*w2v.Vector, error) {
lexer := newLexer(e.model, bufio.NewReader(strings.NewReader(s+"\n")))
if r := yyParse(lexer); r == 0 {
return lexer.vector, lexer.err
}
return nil, lexer.err
}
予測単語の抽出
さて、合成した結果から予測単語を得ます。全てのベクトルはメモリ上に上げられているのでその中から近い単語を得る工程になります。以下の方法が考えられます。
- 距離の最近傍
- コサイン類似
距離の最近傍であればベクトル間の距離が最少となる物を、コサイン類似であればベクトル同士のコサイン角度が1に近い物が結果として抽出すべき単語になります。色々と試してみたのですが単語が成すベクトルの1点が少しでも突飛に出ていたりすると最近傍では途端に欲しい結果で無くなる事が多かったです。今回はコサイン類似を使いました。コサイン類似の実装は以下の通り。
func (lhs *Vector) Cosine(rhs *Vector) float64 {
n := 0
llhs := len(lhs.vec)
lrhs := len(rhs.vec)
n = max(llhs, lrhs)
svec, slhs, srhs := 0.0, 0.0, 0.0
for i := 0; i < n; i++ {
if i >= llhs {
srhs += math.Pow(rhs.vec[i], 2.0)
} else if i >= lrhs {
slhs += math.Pow(lhs.vec[i], 2.0)
} else {
svec += lhs.vec[i] * rhs.vec[i]
slhs += math.Pow(lhs.vec[i], 2.0)
srhs += math.Pow(rhs.vec[i], 2.0)
}
}
if slhs == 0 || srhs == 0 {
return 0.0
}
return svec / (math.Sqrt(slhs) * math.Sqrt(srhs))
}
あとは加算により得られた Vector から候補を幾つか表示するコードを書きます。ここで初めて不必要な単語を除外します。kagome を使って形態素解析し、結果としてふさわしくない物を除外しています。
var ignoreType = []string{
"フィラー",
"記号",
"動詞",
"感動詞",
"助詞",
"助動詞",
"副詞",
"接続詞",
"連体詞",
}
func ignore(features []string) bool {
if len(features) < 7 {
return true
}
for _, v := range ignoreType {
if features[0] == v {
return true
}
}
if features[1] == "接尾" || features[1] == "非自立" {
return true
}
if features[0] == "名詞" && features[1] == "数" {
return true
}
return false
}
func filter(model *w2v.Model) {
var n w2v.Model
t := tokenizer.New()
for _, v := range *model {
word := v.Word()
if re.MatchString(word) {
continue
}
tokens := t.Tokenize(word)
bad := false
for _, token := range tokens {
features := token.Features()
if len(features) == 0 || features[0] == "BOS" || features[0] == "EOS" {
continue
}
if ignore(features) {
bad = true
break
}
}
if bad {
continue
}
n = append(n, v)
}
*model = n
}
fatih/color を使って結果表示に色を付けたりなど、ここでこだわりを出しておきます。(頑張るのはここじゃない)
男と女はどうなるのか
repl が出来たのでさっそく試したいと思います。
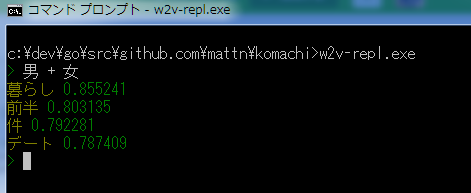
男と女が寄りそうと「暮らし」が生まれる事が分かりました。同棲でしょうか...
ついでなので色々遊んでみます。
> 夫婦 - 夫
ボーナス 0.415349
後半 0.405464
代 0.405224
キャリア 0.391846
夫婦から夫が居なくなるとボーナスが残るらしいです。世知辛いですね。
> 夫 + 彼女
劣等 0.788170
妻 0.744930
他 0.705807
いま 0.696272
夫に彼女ができると劣等感が生まれるのでしょうか?
> 男 + 夜
ひどい 0.708606
勝手 0.705874
とこ 0.701821
今回 0.676985
男の夜は勝手でひどい。なるほど。ちなみに Wikipedia のデータ(2GB以上)をダウンロードして分かち書きして word2vec したモデル(生成までに2時間、失敗3度で計6時間)を使って、「酒+涙+男+女」を問い合わせてみましたが「河島英五」は出てきませんでした。残念。
結果の揺らぎは学習データの質や量に大きく依存します。
おまけ
上記で作ったコマンド、w2v-repl にクエリモードを付け、Vim から呼び出せる様にしておきました。同梱している Vim プラグインを導入し
:W2V 男 + 女
といった様に実行すると男と女から連想される単語を検索してくれます。モデルの作り方によっては便利かもしれないですし、ゴミになるかもしれません。
まとめ
今回は、男と女が寄りそうとどうなるのかについて調べ「暮らし」が生まれる事が分かりました。また word2vec を使う事で単語の予測が行えるので、例えば検索単語からユーザが欲しい情報を予測して提供するといったレコメンデーションもそんなに難しくない事が分かりました。word2vec 便利。
書いたソースコードは以下に置いておきます。
https://github.com/mattn/go-w2v
※kagome の辞書も同梱しているのでバイナリサイズは結構大きくなります。