
この記事はMackerel Advent Calendar 2017の15日目の記事です。
昨日は @mattn さんの Mackerel で Oracle のパフォーマンスを監視する という素晴らしい記事でした!
はじめに
Mackerel を 利用し始めて半年ほど経ったので、自分が担当しているサービスで監視がどのように変わったか、
自分の監視に対するポジションやスタンスがどう変わったか、というのを書いてみようと思います。
Mackerelに関しては高度な活用記事が多いのですが、こういう「普通に監視しています」という記事があっても良いのではないかな、と思って書き始めたものであり、個人の見解です。
所属する組織を代表するものではありません。
祝! Mackerel を 導入 
2017.5~ トライアル開始 ということで、正式利用を開始してから大体半年経過することになります。
この半年の間に担当サービス運用で改善されたことをまとめてみます。
サービスの監視が変わった
運用業務にはいろいろな側面がありますが、すべての運用業務に通奏低音のように関わってくるベースとなるものが監視ですね。
障害の検知から、改善の効果測定、キャパシティプランニングまで、どれも日常的な監視があってこその活動です。
この「監視」のうち「24時間監視体制」以外の部分を開発チームに引き寄せることができました。
具体的に、特にどういう変化があったかを列挙してみます。
URL 外形監視 で 安心できるようになった。
特定のURLにアクセスして、応答の内容やステータスコード、応答時間にSSL証明書の有効期限まで監視してくれます。
外形監視の結果をみれば、「少なくともこの画面は表示できている」とか、「もうWebの画面を表示するのにすら問題が発生している」ということが一目でわかり、次の一手が早くなります。
また、継続的にレスポンスタイムを監視してくれているので、パフォーマンスに問題がないかという観点でも有用です。
リッチなグラフで新しい体験を
Mackerelのグラフは、非常にキレイで見やすいと評判です。
柔軟に期間を変更することで、スケールも変化
たとえばこんなグラフがありますが
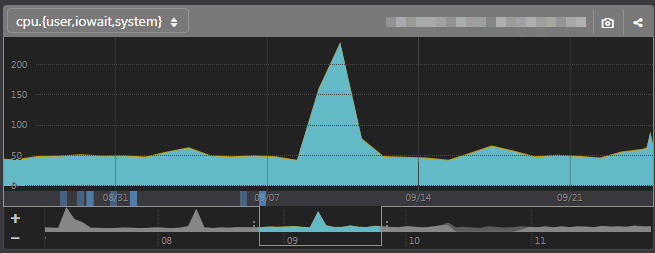
期間の中にスパイク(というにはちょっと太めに見えますがスパイクなのです)があると、小さな変化がつぶれてしまっています。
Mackerelなら柔軟に期間を設定できるので、スパイクを避けてグラフを表示できます。
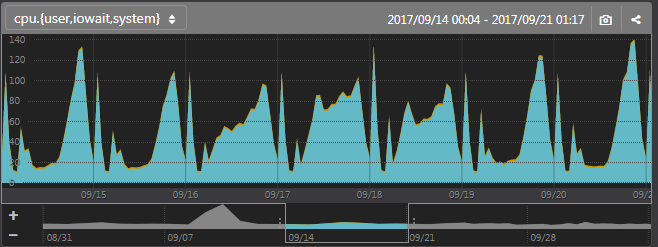
振り返りの際など、少し遠い過去のやらかしに引きずられずに、比較的最近のことについてきちんと振り返ることができます。
Active/Standby がfailoverしてもシームレスなグラフ
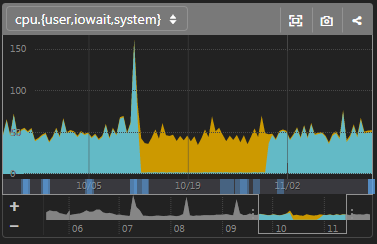
色が変わっているところでfailoverをしています。
このように、ホストごとのグラフを並べて脳内で重ね合わせなくても、きちんとロールごとにグラフを表示してくれて便利です。
式のグラフで...
「実験的機能」というエクスキューズが付いていますが、式のグラフはめっちゃ便利です。
慣れるまではちょっと難しく感じるかもしれないので、「実験的機能」のエクスキューズが取れたあとに使い倒すためにも、今のうちから、いろいろ試してみるのがよいと思っています。
未来予測
Mackerel ブログ でも紹介されています。
データベースのディスク残量など、時間とともに増加(または減少)するようなメトリックの場合、線形回帰でメトリックの値がXXに到達するまでの期間 を グラフにして監視することができます。
過去比較
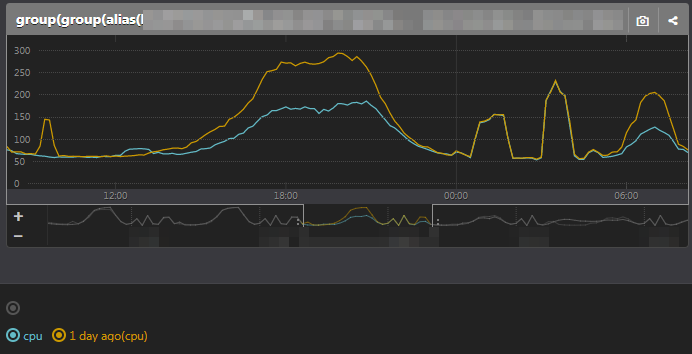
とある性能改善をリリースした翌日に、1日前とCPU使用率を重ねてみた結果です。
効果がキレイに見えています。
いろいろ。
いろいろやってます。
- ELBのbackend_4xx,backend_5xxをパーセンテージにして監視していたり(CloudWatchだとcount数しか取れないので)
- ELBのRequest Countを7日移動平均にして前月と重ねていたり(季節変動の大きいサービスなので、本当は1年前と重ねたいがまだ半年しかつかっていない……)
- custom.linux.usersの値をstackで重ねて1画面でサービスのオペレーション状況を表示したり
「グラフをチャンネルに投稿」でみんなで対応
Mackerel 導入以前
パフォーマンス監視のグラフやログを見ながら何かに気がついた人が、関係しそうな人に実際に声をかけながら、声が届く範囲のメンバーで対応を行うことが多かった。
対応する(できる)メンバーは人数的にも限られており、調査や対応に集中してしまって情報共有が遅れがちになるという問題があった。
Mackerel 導入以後
MackerelだとAlertにひっかかればもちろん通知されますし、「まだWARNINGにもなっていないけれど、動きがいつもと違う」とかそういう気にかかるグラフもシュッと共有してみんなで見るようになりました。
グラフの共有は、カメラのアイコンをクリックして共有先のチャンネルを選ぶだけ。実に2クリックでOK。(チャンネルの選び方によっては4クリック以上かかりますが……)
基本的には目の数が増えれば見るところも増えますし、考える脳みその数も増えますので、危険をより事前に察知できるようになってきているように思えます。
(以前のデータがないので、定量的な成果として報告しづらいのが残念です。
とにかく監視データを収集するのは、なにかあったときに起きる前と比較するためだというのを痛感します)
グラフアノテーションでデプロイの記録を監視に入れる
よく事例紹介でもみるやつですが、デプロイの際に自動的にサービスアノテーションをつけるようにしています。
グラフの傾向が急に変わっている箇所など、「このデプロイが原因かもしれない」というのがグラフとセットになっているので振り返りの際などとても便利です。
監視項目が足りない?
日々の運用業務をしていると、監視を育てたくなってきます。
たとえば、障害の対応をしていくなかで、予防のために監視すべき項目が浮かび上がってくることがあります。
「この項目監視してないの?」「今後のために監視するようにしよう」
でも、どうやって監視したら……?
今まで自分で監視項目を設定したことがあるどころか、どんな項目が監視されていて、どうしたら監視項目を追加できるのかなんて1つも知らないでただアプリケーションコードを書いていた自分でもできるの……?
プラグイン調べた?
公式プラグイン集、イイの揃ってます。これを入れてみることで、今まで気にしていなかったけど見ておくと後々嬉しいメトリックなんかもあって知見が広がります。
担当サービスで使っているのは……
- mackerel-plugin-linux
- io, network, process, interrupt など、 Linux を 使っているならとりあえず見ておきたい、と思うようなメトリックが一式入っていて便利
- mackerel-plugin-accesslog
- レスポンスステータスを数/パーセンテージで集計してくれるところが特におきにいり
- mackerel-plugin-postgres
- クラスタのサイズやread/writeから、トランザクションとコネクションの状況、デッドロックの検知もまでと良い感じに監視できる。でも、もっといろいろやりたいのでContributeも視野。(autovacuumとか監視したい)
- mackerel-plugin-jvm
- GC関連のメトリックは何かあったときに振り返れる状態にしておきたい
- mackerel-plugin-redis
- 担当サービスのRedis は割と緩く使っているので今まで特段問題になったことはないですが、こういうのは何かが起こる前に入れておくべきもの
- mackerel-plugin-multicore
- というのはもちろんこのプラグインに対する前振り。1コア当たりの負荷を小さく見積もりすぎて失敗を起こした、と予想したあとに入れてみたら一目瞭然だった。
Mackerelプラグインアドベントカレンダー も毎日楽しみに読んでいますし、「このプラグインちゃんといれておかないと」と気づかされることも多いです。
なければ簡単に作れる!
コードを書くのはむしろアプリケーションエンジニアの本分です。
思いついたことはすぐに試してみることができます。
自作プラグイン編
Mackerelのプラグインを作るの、じつは簡単です。
もちろん、公式プラグイン集にMergeしていただけるような、というとハードルが上がってきますが、自分でゆるく使うプラグインをつくるという面で言えば、(メトリックプラグインなら)「名前・値・時刻(エポック)」をタブで区切って標準出力に出すコマンドさえ作れればよいのです。
もっと言ってしまえば、シェルスクリプトでechoすればいいんです。
あとはmackerel-agent.confを書いておけばよろしくやってくれます。
サービスメトリック編
いわゆるプラグインはホストごとにインストールしますよね。
それで、メトリックもホストのメトリックとして取得されますよね。
そういうのじゃなくて、サービス全体の指標として欲しい数字ありますよね。
たとえば、ログイン(試行)回数とか、そういうやつ。
ホストメトリックよりはちょっと複雑になりますが、値を収集して、名前と値と時刻をJSONにしてAPIにPOSTしたらそれでOKです。
簡単ですね。
あとは……
運用環境だけでなく、開発環境やステージング環境にMackerelを導入することで、危険を事前察知したいという気持ちがあります。
また、Mackerelは元々サーバー管理が出自ということもあり、利用しているサーバーすべてにagentを導入して管理対象にしていく方が幸せ度は高まるように感じています。
(今のところ、 ![]() の問題との折り合い)
の問題との折り合い)
おわりに。
とりとめもないのですが、だれかが入れてくれたMuninのグラフをみることはある、程度のアプリケーションエンジニアが、Mackerelを使い始めて半年すぎるころには監視を育てるのが楽しくなっていたよ、というのを伝えたくてMackerelでよかったことを書き連ねてみました。
明日は @vanityangel さんの記事です!
