
TL;DR: ホリデーシーズンなのでコードや技術の説明は無しです。ディープラーニングの基本知識を得たばかりの人間がスクラッチからモデルを作り、エンジニアとして別の仕事をしながら当時のstate of the artの性能を出すところまで作り込んで得た知見のまとめです。
目次:
・どうやって情報を得るか
・tensorflowでスクラッチから作る場合の注意点・陥りやすいポイント
・モデルの性能が伸び悩んだ時に試すべきこと
・モチベーションを維持するには
概要
単画像超解像と言われる技術があります。これは解像度の低い画像の解像度を引き上げる技術です。例えば最近はスマホやタブレットなどの表示用デバイスの解像度も高くなり、古い時代用のコンテンツでは解像度が低くて粗が目立ってしまいます。これを綺麗にしたり、あるいはセキュリティカメラなどで拡大した不鮮明な画像を鮮明にしたりできます。
非常に需要の高い技術ですが、2014-15年よりディープラーニング(DL)を使った手法が他よりも良い性能を出し始めました。GoogleのRAISRやTwitterのGANベースのモデルなども発表されて結構話題になっている分野です。また超解像の性能を競うNTIREというコンテストもありGoogleやnVidia、twitterなどがスポンサーとして名を連ねています。去年・今年では単眼超解像についてはDLを使った論文ばかりです。
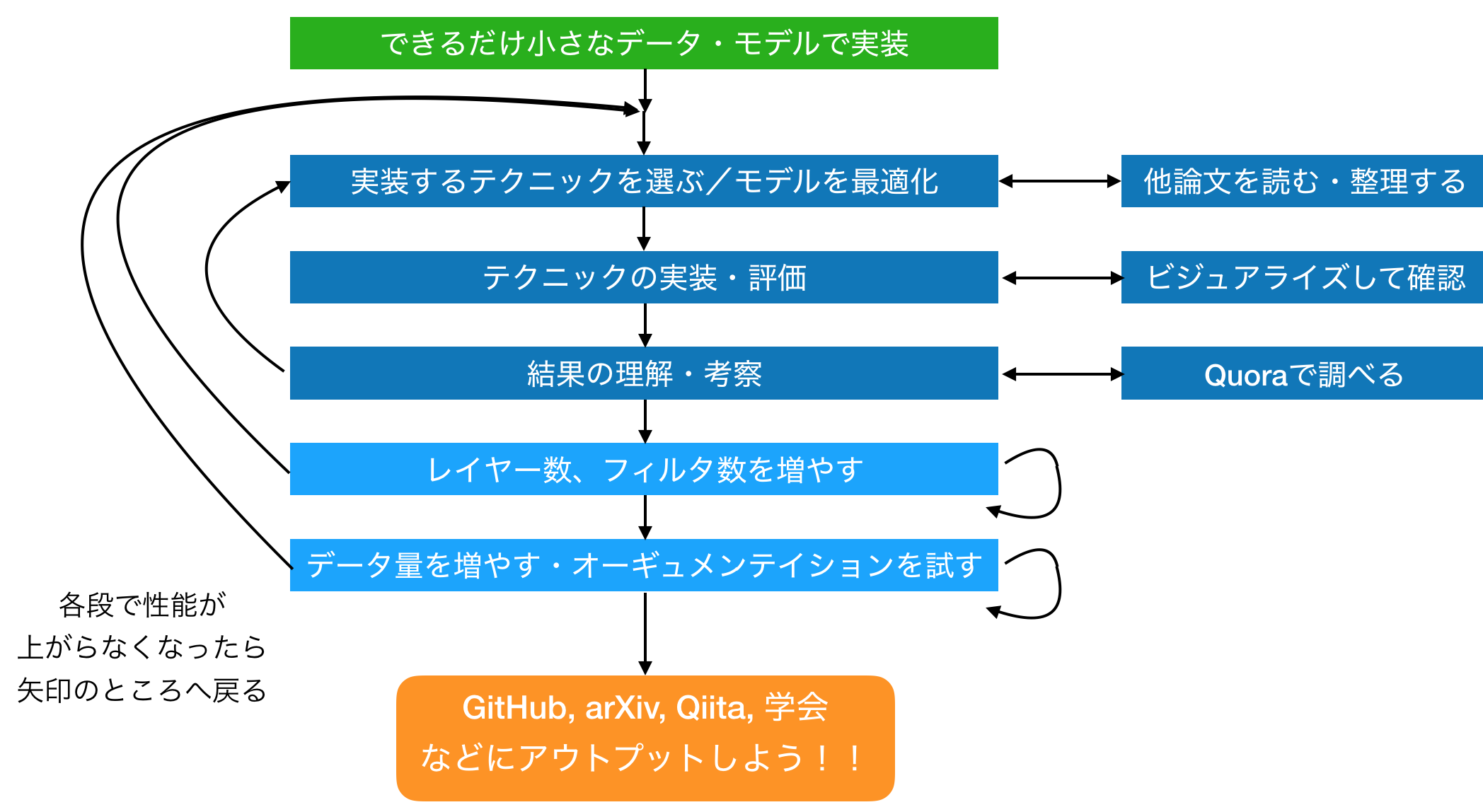
僕はとある先生よりきっかけをもらいある論文をtensroflowで実装することに挑戦しました。それから自前のモデルを作り始めて半年ぐらいかけて改良し最後は論文として出すことができgithubにあげたモデルもぼちぼちスターやイシューを上げてもらえるようになったのでその辺りをまとめてみました。下図が大まかなイメージです。
僕自身エンジニアとして20年ぐらいやってきたのですが、最初はロボット制御をやり、それから画像処理->分散処理->ウェブ開発->iOSなどその時の興味に合わせて分野を変えていたら結局専門性がなくなってしまっていることに気がついたのでした。歳を取ってみると専門がないことがじわじわと悩みに感じるのです。そこでもう一度じっくり学んでみたいと感じたのがDL/Tensorlowでした。
1. どうやって情報を得るか(まず何をやるか)
まず英語に慣れる
何は無くとも英語への苦手意識をなくすことは必須になります。基礎的な部分の学習であれば国内の情報・講座がもっとも効率が良いと思いますが、後でしっかりと応用し自分でモデルを作ることを考えると英語のリソースへのアクセスは必須です。
学生時代に外国語の単位を落としまくっていたような僕には、Quoraで慣れるのが一番良かったです。ポピュラーになっている質問や回答は非常に面白く、また文章が短くまとまっています。逆にブログや論文などを一気に読むのは大変でした。
論文
コンピュータビジョン勉強会などの論文読み会やブログなどでとりあげられた論文をピックアップして読みこみます。どのような手法を使ったら性能が上がったのか、どんなデータセットを使っているのか。その論文のベースとなるアイデア/論文は何か、などを整理して文書化してみます。そうするとまだ自分が理解できてない点が見えてくるのでその部分を読み直します。
およそほとんどの論文は何か別の既存の論文のアイデアや技術を使っていますから、その基になった論文を読み始め結局3本目、4本目の論文も読み始めることになると思います。ですが、沢山の論文を読むよりもまず一つの論文を7割方理解できるようになるところまで進めたほうが応用力はつくと思います。それぞれの問題でどのようなアーキテクチャ・テクニックが重要なのかなんとなくイメージがついてくると思います。
基本的な技術要素への解説はQuoraからポインタを得る
論文やブログなどを読んでいると基本的な用語が分かってきますが、そのままではなかなか応用できません。それらを実際にもっと詳しく知ろうとする時はQuoraで検索してみるのがオススメです。ここでは初心者っぽい人に対してプロのエンジニア/リサーチャーが分かりやすく回答してくれているのでその技術の本質的な理解に役立ちます。色々な人の回答が見れるので自分のバックグラウドや知識量に合った説明を見つけられる可能性が高いです。
例えばその技術が本質的にどんな意味を持っているのか、内部でどんな計算をしているのか、似ている他の技術との違いは何なのか。自分の持った疑問はほぼ全てここで既に質問されていたといっても過言ではありません。
2. スクラッチからモデルを作る場合の注意点・陥りやすいポイント
用意したデータ、正規化の方法に間違いがある
→ ベンチマークを作る
最初はDLを使わずに既存のアルゴリズムをsklearnなどから引っ張ってきて試しにこれで動かしてみます。例えば超解像なら既存の画像拡大アルゴリズムを使ったり、あるいは自分で考えたシンプルなアルゴリズムで試しにデータを処理して検証します。ここでリーズナブルな性能が出なければ用意しているデータに問題があったり処理の枠組みのどこかに問題があることになります。また、他のアルゴリズムで得られた性能の値はDLのモデルを評価する上で良いベンチマーキングになります。
作成したグラフに間違いがある
→シンプルな1層だけのモデルを作って試す
tensorflowは独特なところがあって、作成した演算アルゴリズムやデータは全てコンピューテイショングラフの中に格納されています。そのままでは計算中のウェイトや出力の値も見ることができません。慣れないうちはかなり厄介です。
tensorboardでグラフを見れば計算グラフのバグは発見しやすいのですが、そのためには変数名のスコープをうまく設定したり、tensorboard上で余分なグラフを非表示にしたりなどのコツが必要です。
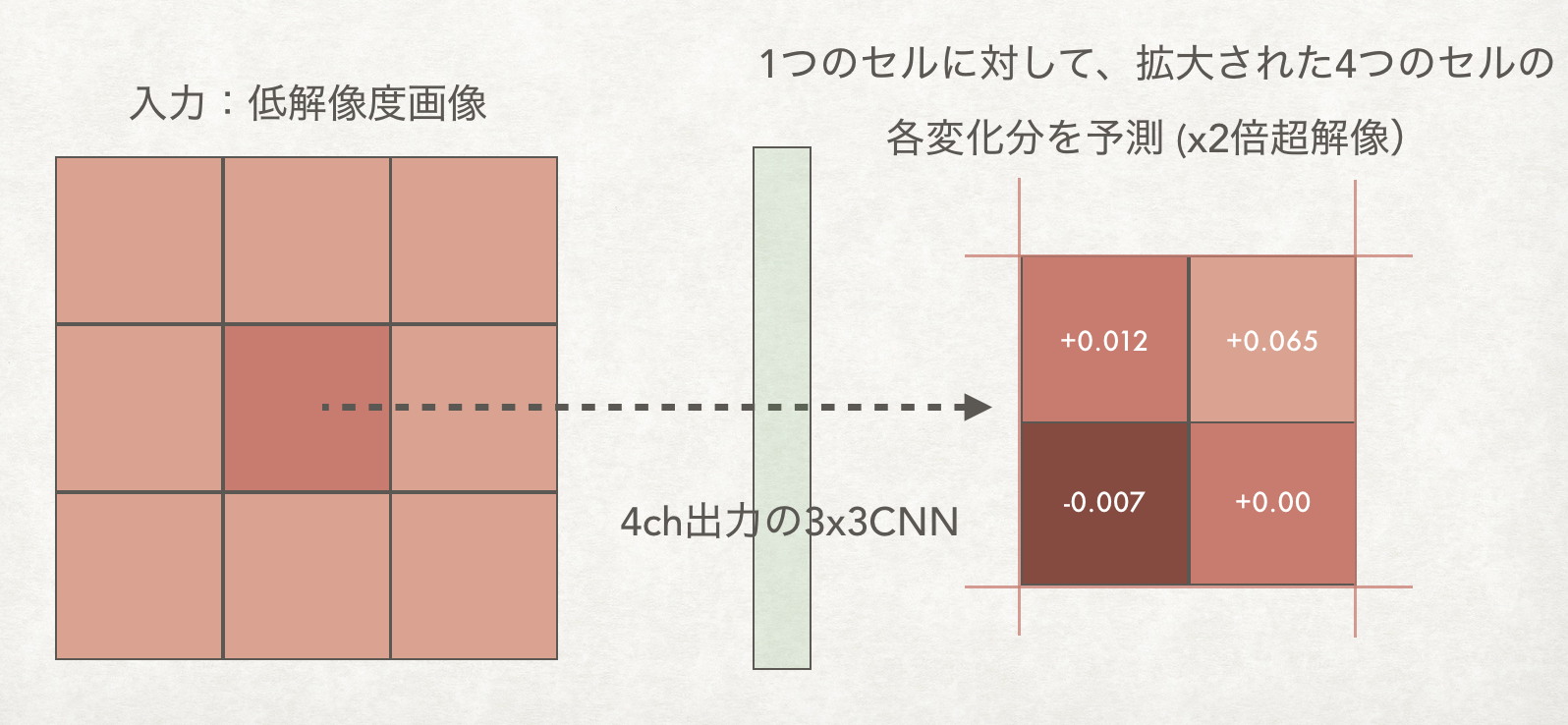
下図は僕が一番最初に作ってみた3x3のCNNです。周囲の画像のピクセル情報を使って高解像版となる4つのピクセル値を推定し解像度をあげるモデルです。まずはこういったできるだけシンプルなモデルで正しく学習されることを確かめるところから始めるのが良いです。そこから順にレイヤーやフィルタ数を増加させ、頭打ちになったらDrop OutやResidual、Skip Connection、Batch Normalizationなどの各種技術を追加して試します。
モデルのポテンシャル(表現力)が足りない
->過学習させてポテンシャルを測る
トレーニングデータをそのままテストデータとして学習をさせてみます。するとモデルは過学習するので通常よりもずっと良い値が出るはずです。個人的にはこれをそのモデルが出せる最高性能(ポテンシャル)として参考にしています。データを沢山用意する必要がないのでCPUベースで評価することもできて便利です。過学習状態で性能が出ないようであればそのモデルのポテンシャルが足りないことになり、その場合はレイヤーを増やしたりデータの正規化を検討する必要があると思います。
うまくいくはずなんだけど動かない
->GPU環境で網羅的にアーキテクチャ/パラメータを試す??
だいぶモデルが動くようになってきてお目当のアーキテクチャを実装してみてもなかなかうまく性能が上がらない時があります。そうなるとGPU環境は必須です。パラメータが正しくなくてうまく機能していない場合に結構遭遇しました。あまり悩まずはまずは網羅的に力づくで試します。
僕はGTX 1080 Tiを使用しています。値段と性能のバランスではこれが一番だと思います。例えば上記の超解像技術のコンテストでは7-8割のチームがTitan Xを使用していますが残りのチームは1080 Tiを使っています。気軽に試してみるのならば1060の6GBのモデルが手頃で僕も最初の半年ぐらいはこれでやっていました。3Gのモデルだとちょっと大きなモデルを動かそうとするとGPUメモリはすぐに枯渇して動かなくなります。スピードが遅いだけなら良いですが全く動かないのは致命的なのでメモリはできるだけ大きいモデルがオススメです。
またAmazonなどのクラウド環境もスポットで試したりするのは手軽で良いです。昔書いた記事でCPU/GPU/Amazon EC2環境でのパフォーマンスを計測した記事がありますので良ければ参考にして下さい。
・tensorflow 各環境でのCPU / GPUベンチマーク結果
モデルの構造を拡張しすぎている/余分なアーキテクチャを使っている
->常に原理に立ち返る
一般的にはCNNモデルの性能が上がらなくなったらフィルタ数を増やしていき、それで上がらなくなったらレイヤー数を増やして代わりにフィルタ数を減らすと良いと言われています。またフィルタ数は入力層に近いほど少なく出力層に近いほど増やすと良い結果が出ると聞いていました。ですがこれはあくまで画像認識のタスクの場合です。
例えば超解像の場合は上記とは逆の結果が得られました。これは超解像は画像のディテールが大事なためレイヤーを経るごとに入力データの細部の情報が失われてしまうからだと捉えています。
たまたま出た良い結果/悪い結果に振り回されている
データ量を増やし試行回数を増やせば結果は落ち着くとはいえ、それでもやはり乱数値ベースなのでたまたま良い/悪い結果が出ることは多いです。そういったたまたま出た結果をベースに戦略を組み立てていてハマることが何度かありました。モデルが小さいうちは最低でも3回、できれば5回以上は試して結果のばらつきや平均値を元に判断する方が無難です。(ただしモデルやデータが大きくなり実験に1日以上かかるようになるとそうも言ってられないのですが)
3. モデルの性能が伸び悩んだ時に試すべきこと
データを増やす
ある程度モデルを複雑にしてポテンシャルを上げてもそれに見合うデータがないと性能は上がりません。よくある話ですがまずはデータの数、種類を増やすことを考えます。
ビジュアライズの優先項目
tensorboardにはできるだけ慣れることが大事です。詰まった場合は何故性能があがらないのかの理由を推察し突破口を探すわけですが、DLでは手がかりとなる情報が少ないのです。各種ウェイトやバイアス、損失値の変化だけでなく早めに色々なデータをビジュアライズできるようにして記録しておくと良いです。ただしあまり沢山tensorboadへの書き出しを行うと実験の速度が下がるので必要に応じてエキストラな項目はon/offするのが良いと思います。
- トレーニング/テスト時の損失変化 学習が正しく進んでいるか、過学習していないか
- 各レイヤーのウェイト、バイアス 適切な分散を保っているか、各値がまだ収束していないのに学習が終わっていないか
- 各レイヤーの出力値 各レイヤーごとに値の範囲が適切かどうか、初期値の設定は正しいか
- 各データ/ピクセルの損失値の分布 どのようなデータをうまく学習できていないのか、そもそも異常な入力データが混ざっていないか
論文を漁り使われているテクニックをリストアップする
論文には細かいテクニックや、各種の実験用のパラメータ、使ったデータなど全てが公開されています。基本的なモデルのアーキテクチャも重要ですがそのモデル/データにあったパラメータや構成を選ばないと性能は上がらないことが多いです。それらの細かい情報はブログや記事、書籍などには載っていません。各論文の実験の項目にまとまって載ってますのでこれらを見ていくだけで大きなヒントが得られます。
例えば単純に出力を定数倍するだけのレイヤーやシャッフルするレイヤーなどもあって、これらを使うとレイヤーを深くしてもうまく学習できるようになったりします。こういった小技は結構重要なのですが通常の教科書的な講座には載っていません。
各種テクニックを片っぱしから試す
下記に僕が最初の数ヶ月ぐらいで実際に実装して試したテクニックです。スクラッチから作る場合はまずはあまり考えずに全て試してみて、それらが本質的にどんな内容でどんな効果を持っているかを種類や効果ごとに整理しまとめます。ただしモデルや与えるデータの規模、あるいは利用するテクニックの組み合わせによって有効度合いが変わってくるので柔軟に考えることが必要です。
[ 下の表はあくまで僕のモデルに対する効果であって一般的な効用ではないことに留意下さい ]
| 効果 大 | 効果 中 | 効果 小 | 効果 極小-無し |
|---|---|---|---|
| ResNet (残渣項の学習) | オプティマイザの変更 (TanH, ReLU, Leaky ReLU Parametric ReLU) | SGD, mini batchのサイズ変更 | Batch Normalization (意外) |
| データ オーギュメンテーション | ファインチューニング | 入力データの正規化 | Dilated CNN |
| Skip Connection | 初期値の変更(Heの初期化 Xavierの初期化、Truncated Normal等) | 入力の多チャンネル化、 ガイド情報の入力 | 隠れ層出力の正規化 |
| Network In Network | Transposed CNN | ウェイトのL2 正則化 | Early Stopping |
| Drop out | 簡易アンサンブルモデル | ||
| Feature Optimization |
レイヤーを増やす
僕の場合は何度も実験を繰り返しているうちに段々とコツがつかめてきました。
論文を読んでいて高い性能を出すモデルの共通点もそうだったのですが、シンプルな構造ながらできるだけそれを沢山重ねて10層、20層、30層とディープなモデルにするのが高い性能を出すコツでした。ただし最初はいきなりディープなモデルを作ってみてもうまく学習させることができません。
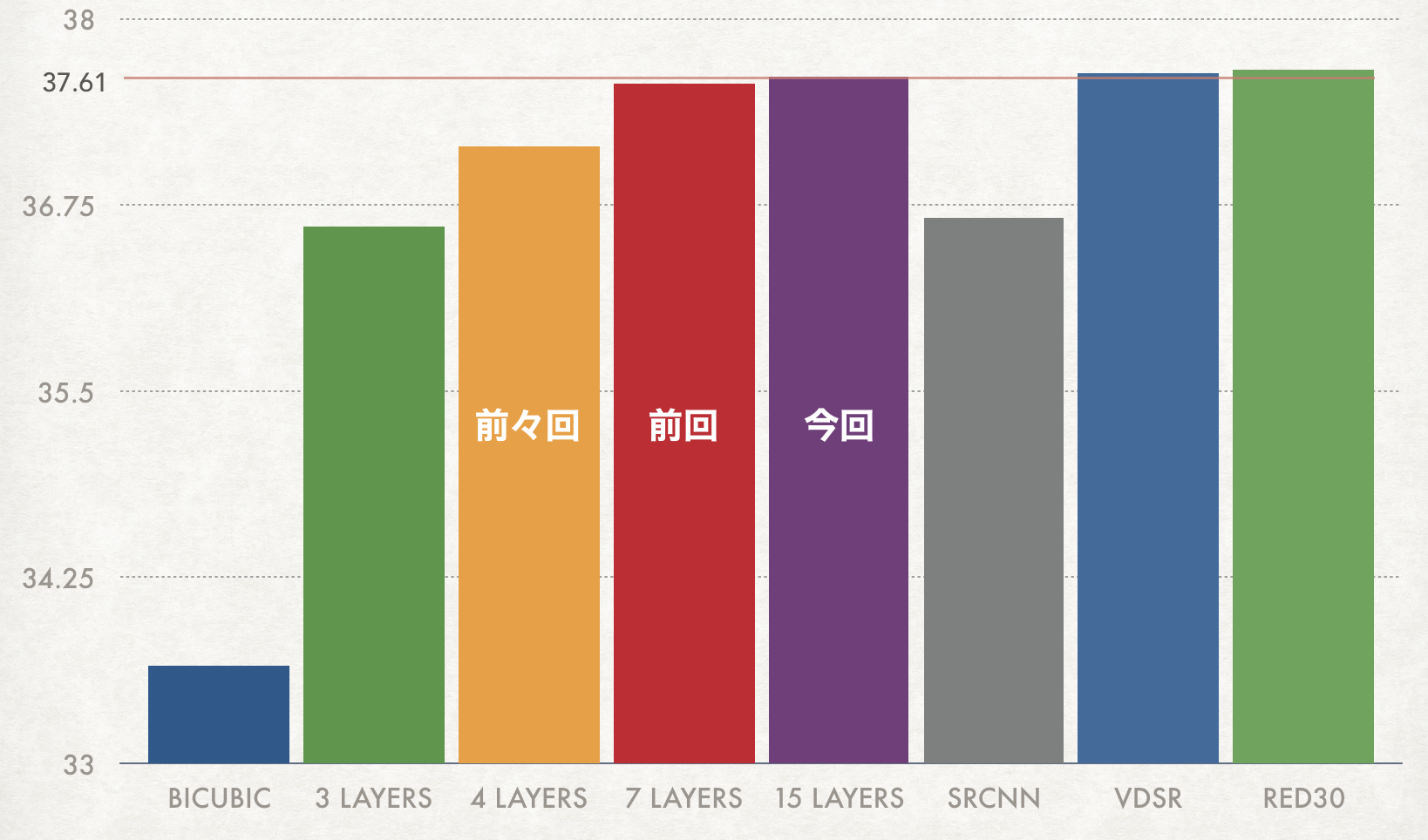
僕の場合は最初は4層ぐらいのモデルで性能が頭打ちになり、そこへskip connectionやデータオーギュメンテイションなどを導入し性能を上げました。そしてレイヤーを増やしても性能が出なくなった所でさらに必要なテクニックを導入していくことを繰り返していました。そうすることで自分の問題とモデルに必要なテクニック・パラメータの組み合わせを短い時間で探りながら実装していけます。下の図はレイヤーを増やすことで性能(縦軸)が上昇し徐々に既存のモデルに追いついていった時に作成したグラフです。(一番左が既存簡易アルゴリズムの性能で、右3つがライバルとなる論文の性能です)
4. モチベーションを維持するためには
僕は最初はディープラーニング=非線形な要素を何層かスタックさせるだけでこれほど性能に違いが出るのか全く理解できていませんでした。「何故性能が出るのか?」この問いに答えを出し実感を得るのは長い道のりです。実は仕事を続けながらいかにしてモチベーションを維持するかというの一番書きたかったことかもしれません。
2週間に1度ぐらいの割合でまとめを書く
フォーマットを決めてその期間で行なった実験・考察のまとめを必ず文書や図、グラフにして残しておきます。実験が長くなるので昔に考えていたことやアイデアを忘れてしまうからというのもありますが、基本的には物事の中途でも満足感を得ることが重要です。
僕の場合はまず 1.この半月にやったこと、2.各実験の結果、3.考察、4.次の半月でやることをフォーマット化してまとめていました。下記が2016年11月30日から2017年5月31日までの僕の書いたまとめスライドです。総計235枚なので1日に1毎以上のペースで書き貯めた計算になります。

メンター/協力者を探す
一人でやっていては絶対に続きません。僕の場合は非常にラッキーなことに画像処理界で非常に有名な先生に時間をとってもらうことができ、2週間かあるいは1月に一度、45分-1時間ほど実験の内容を報告してコメントをもらうことができました。
仲間内の勉強会でも良いですし、ブログでも良いですし、定期的に他者へアウトプットしてフィードバックをもらうことがとても大事です。その期間までに結果をまとめないといけないプレッシャーにもなりますし、やはり良い結果が出たら一緒に喜んでもらう人が必要なのではないかと思います。

今年のまとめとしてアドベントカレンダーに書きたかった内容は以上です。
上記で書いたような半月〜月に一度のまとめは時々お休みしながら今も書き続けていて、上記のリストよりもさらに沢山のテクニックを試し、モデルへの抜本的な改良も続けさらに上のレベルの学会での採択を目指しています。
なかなかコードや技術の説明ではない文章を書くのは苦手なので、次は何かしらの技術解説の記事が書けたらと思います。長文を読んで頂いた皆様ありがとうございました。ちょっと早いですが、メリークリスマス!!