
Chainer Advent Calendar 2017 2日目です。
まえがき
画像認識や音声認識で深層ニューラルネットワークの威力が目立ち始めた頃、何故か(結構親和性が高そうな)音楽情報処理(MIR)の分野ではそっち方面での動きは鈍く、応用してみた論文も言うほど目覚ましい成果は無かった印象でした。そんなMIR界もようやくDeepLearningブームが来ているようで、Deepな論文がどっかんどっかん投稿され、ビッグなデータセットが公開され、MIREX(音楽情報処理アルゴリズムのコンテスト的なやつ)でも勝ちはじめ、ISMIR(音楽情報処理の国際学会)の冒頭演説でネタにされる位には流行るようになりました。
というわけで今年のISMIRの深層学習関連発表から比較的わかりやすそうなものを選んで、Advent Calendarのネタにさせて頂くことにしました。本稿では音楽の歌声分離タスクをやってみます。
参考文献は:
Andreas Jansson, Eric J. Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, Tillman Weyde, Singing Voice Separation with Deep U-Net Convolutional Networks, Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), 2017.
Spotify発、今年のISMIRのProceedingに載っている論文です。ISMIRのBest Poster Presentation Awardにも選ばれました。
タスク概要
歌声分離、つまりミックスされた音源からボーカルパートを分離してカラオケ音源を作る、みたいなことができる技術ですね。AUDIONAMIX TRAX PROみたいなプロツールも販売されています。
学術的には音声Source Separationに属する分野で、従来ではNMF(非負行列因子分解、一つの行列を近似的に二つの非負行列の積に分解するアルゴリズム)等のアプローチが主流だったみたいですが、現在ではDeepLearningが優位と言われている分野です。
考え方はわりと単純で、音源のFFTスペクトログラムを入力として、入力と同じサイズの「マスク」をニューラルネットに計算してもらいます。マスクを元音源のスペクトログラムに掛けることで、ボーカル音声の成分だけが残ります。
ネットワーク構造
論文に掲載されている図を引用します。U-Netという名の通りUみたいな形をしてますね。
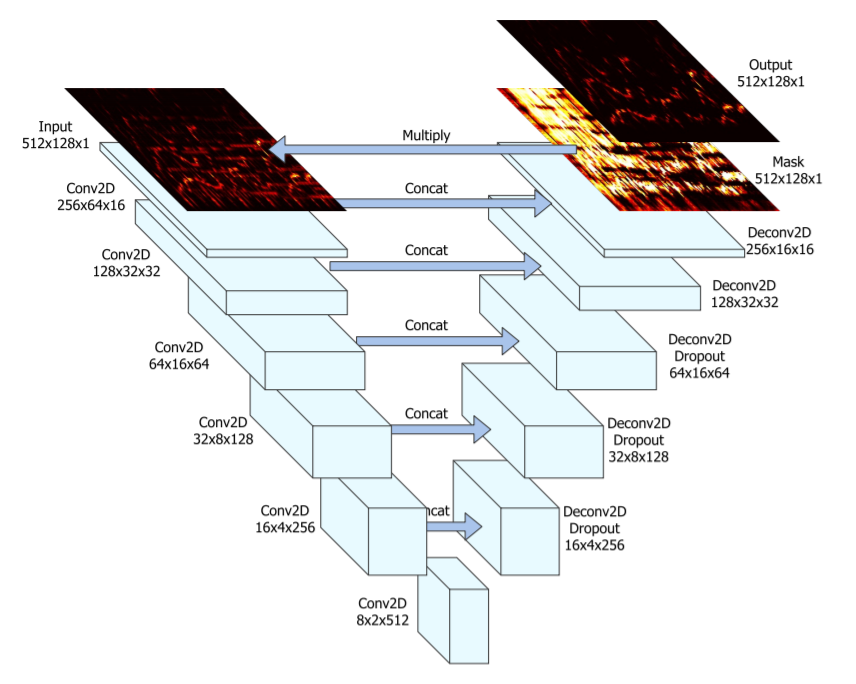
入力(ミックス音源)のスペクトログラムを何回かConvolutionして、また同じ回数Deconvolutionをして元のサイズの行列を出力する、bottleneckな畳み込みネットワークです。それに加えて各ConvolutionとDeconvolution層の出力をconcatしてskip connectionみたいな構造が組み込まれています。
pix2pixや、去年のカレンダーで話題のPaintsChainerもU-Netを使ってましたがほぼ似たようなものです。
入力と出力を掛けた結果と、ボーカル音声のスペクトログラム(正解)の差(ここではL1損失)が、損失関数になります。つまり元音源スペクトログラムと「マスク」を掛けると歌声だけ残るように、U-Netを学習させるという事です。
細かい設定は後のソースコードを参照。
データセット
学習の為には、ミックスされた音源と、ボーカルのみのバージョンが必要です。Spotifyは、自社のデータベースをクロールして、シンガー曲とそのinstrumental(オリジナル・カラオケとも呼ばれるアレ)版を集めることで大きなデータセット(論文によると20000曲以上)を構築することができました。この論文の勝因は結局そこなんでしょう。
自分の場合は、評価用に公開されている音源分離研究用のデータセットを使います。
- MedleyDB:音源分離、多重音音高解析タスクの評価用の、マルチトラックオーディオのデータセット。そのうちボーカルがある60曲ほどを使用します。
- iKala:左に伴奏、右にボーカルパートが収録されている短めのステレオオーディオファイル200曲。
- DSD100:こちらもボーカル有のマルチトラックデータ100曲。train setとvalidate setに分かれてますが全部ぶっこみます。
- 手持ちのデレマスCD9枚から「オリジナル・カラオケ」がある18曲。元論文がやったように、楽曲からカラオケ音源のスペクトログラムを差し引いてボーカル版を作りました。
更に、異なる曲のボーカルと伴奏をランダムに足し合わせる、という手段でData augmentation(水増し)してあがいてみます。これでだいたい17時間分の学習用データが集まりました。
実装
ではこのU-Netを組んでみます。Chainer 3.0.0を使いました(たぶん2.xでも動きます)。
入力音声は16kHzにダウンサンプリングされ、窓サイズ1024でSTFTします。
Chainer定義だとこんな感じ。
class UNet(Chain):
def __init__(self):
super(UNet,self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(1,16,4,2,1)
self.norm1 = L.BatchNormalization(16)
self.conv2 = L.Convolution2D(16,32,4,2,1)
self.norm2 = L.BatchNormalization(32)
self.conv3 = L.Convolution2D(32,64,4,2,1)
self.norm3 = L.BatchNormalization(64)
self.conv4 = L.Convolution2D(64,128,4,2,1)
self.norm4 = L.BatchNormalization(128)
self.conv5 = L.Convolution2D(128,256,4,2,1)
self.norm5 = L.BatchNormalization(256)
self.conv6 = L.Convolution2D(256,512,4,2,1)
self.norm6 = L.BatchNormalization(512)
self.deconv1 = L.Deconvolution2D(512,256,4,2,1)
self.denorm1 = L.BatchNormalization(256)
self.deconv2 = L.Deconvolution2D(512,128,4,2,1)
self.denorm2 = L.BatchNormalization(128)
self.deconv3 = L.Deconvolution2D(256,64,4,2,1)
self.denorm3 = L.BatchNormalization(64)
self.deconv4 = L.Deconvolution2D(128,32,4,2,1)
self.denorm4 = L.BatchNormalization(32)
self.deconv5 = L.Deconvolution2D(64,16,4,2,1)
self.denorm5 = L.BatchNormalization(16)
self.deconv6 = L.Deconvolution2D(32,1,4,2,1)
def __call__(self,X):
h1 = F.leaky_relu(self.norm1(self.conv1(X)))
h2 = F.leaky_relu(self.norm2(self.conv2(h1)))
h3 = F.leaky_relu(self.norm3(self.conv3(h2)))
h4 = F.leaky_relu(self.norm4(self.conv4(h3)))
h5 = F.leaky_relu(self.norm5(self.conv5(h4)))
h6 = F.leaky_relu(self.norm6(self.conv6(h5)))
dh = F.relu(F.dropout(self.denorm1(self.deconv1(h6))))
dh = F.relu(F.dropout(self.denorm2(self.deconv2(F.concat((dh,h5))))))
dh = F.relu(F.dropout(self.denorm3(self.deconv3(F.concat((dh,h4))))))
dh = F.relu(self.denorm4(self.deconv4(F.concat((dh,h3)))))
dh = F.relu(self.denorm5(self.deconv5(F.concat((dh,h2)))))
dh = F.sigmoid(self.deconv6(F.concat((dh,h1))))
return dh
class UNetTrainmodel(Chain):
def __init__(self,unet):
super(UNetTrainmodel,self).__init__()
with self.init_scope():
self.unet = unet
def __call__(self,X,T):
O = self.unet(X)
self.loss = F.mean_absolute_error(X*O,T)
return self.loss
学習を容易にするためにスペクトログラムを[0,1]の範囲に正規化するのですが、その際オリジナル音源とボーカルパートの数値比を変えないよう注意する必要があります(ボーカルの音量を一致させる為)。同じ数値で割ること。
そのスペクトログラムからランダムに一定長分切り取った部分をNNに入力して学習を行います。
以上は学習のやり方でしたが、実際に分離を行う際はオリジナル音源のmagnitude spectrogramにU-Netが出力したmaskを掛ければ、ボーカル部分のmagnitude spectrogramが求められます。但しinverseSTFTで音声信号に戻すにはphase情報も含んだ複素数スペクトログラムが必要です。この場合スペクトログラムにオリジナル音源のphaseをそのまま掛けることで最終的なスペクトログラムが求められます。
逆に伴奏部分を復元したい場合は元音源のmagnitude spectrogramに逆のマスク(すなわち1-mask)を掛ければよし。つまりニューラルネットが計算したmask行列がボーカル分離の「境目」の役割を果たしている訳ですね。
研究室に少しお金を出して貰ってクラウドサービスAliYunのGPUインスタンスで学習を行いました。NVIDIA Tesla M40一台で、ロスがだいたい収束するまでかかった時間はおよそ6時間。
ソースコードはGithubに上げましたのでご参考程度にどうぞ。外部ライブラリはchainer、cupyとlibrosaのみです。(dhgrsさん、pep8直してくださりありがとうございました!)
実験
訓練データセットにない、RWC-POPデータセットから適当に3曲選んで歌声分離をやらせてみました。それぞれ30秒間ほど聞いてみましょう。
びっくりするほど綺麗に分かれましたね(三曲目だけちょっと微妙)。その他にも巷の流行曲でやってみたのですがどれもかなりうまくいってました。
お試しWebアプリをつくってみた
色んな音源で試してほしいので、オンラインで歌声分離をお試しできるサイトを作ってみました。
http://unetvocalsep.herokuapp.com/
ドラッグ&ドロップで音源をアップロードすればサーバーがボーカルを分離してくれるはず。.wavしか扱わないので注意。
シングルコアの雑魚サーバーなので、編集ソフトを使って音源を短くするなりあらかじめリサンプリング(16kHz)するなり、気を遣っていただけると助かります。サーバーが落ちたりしてたら教えてください。
まとめ
初心者がchainerで歌声分離してみた。わりとできた。
というタイトルは自重しましたが率直な感想ではあります。
今後もDeepLearningな手法に限らず色んなMIRタスクで遊んでいきたいと思っています。