

最近、Webページからざっくりメインコンテンツっぽいものを探し出すプログラムを作成しましたので得られた知見についてまとめてみます。本文などの情報を利用せずに汎用的にメインコンテンツを探したかったので、Elementの位置、幅、高さ(以下rect)等の視覚的な情報を使用して抽出してみました。具体的には
- puppeteerでページをスクレイピングして各Elementの情報をまとめたツリー構造を作る
- Elementにスコアを付けて尤もらしいものをメインコンテンツとする
というステップで抽出します。
メインコンテンツを抽出する完全なコードについてはgistのサンプルを参照してください。
ページのスクレイピング
puppeteerを使ってページをスクレイピングします。最初にdomツリーを探索して必要な情報をjsonとて抽出します。視覚的な情最新のとして各Elementごとにrectの情報を取得します。それと合わせてElementのnodeName,
xpath, attributes, childrenを保存してきます(TypeScript上のインターフェースは以下を参照)。
interface Tree {
nodeName: string;
xpath: string;
attrs: { [key: string]: string };
x: number;
y: number;
width: number;
height: number;
children: this[];
}
準備
まずは、puppeteerでお決まりのコードを準備します。ブラウザ起動、タブを開く、ユーザエージェントなどの設定をして対象のWebページに訪問の工程まで。
import * as puppeteer from "puppeteer";
export async function parse(url: string) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const options = {
viewport: {
width: 1024,
height: 600,
},
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36",
};
await page.emulate(options);
await page.goto(url);
}
ページサイズを調整する
次に、ページサイズをサイト作成者が実際に見せたい幅(と高さ)に調整します。具体的にはページのスクロールバーがちょうど出ない状態になるまでちょっとずつページ幅を広げてゆきます。
async function waitRendering(page: puppeteer.Page, wait: number) {
return await page.evaluate(async wait => {
await new Promise(resolve => setTimeout(resolve, wait));
await new Promise(resolve => (window as any).requestIdleCallback(resolve, { timeout: 5000 }));
}, wait);
}
async function getPageSize(page: puppeteer.Page) {
return await page.evaluate(() => [
document.documentElement.scrollWidth, document.documentElement.scrollHeight
]) as [number, number];
}
async function fixPageSize(page: puppeteer.Page, options: EmulateOptions) {
let n = 50;
await waitRendering(page, 50);
let [w, h] = await getPageSize(page);
options.viewport.width = w;
options.viewport.height = h;
while (n--) {
options.viewport.width = w;
await page.emulate(options);
await waitRendering(page, 50);
const [nw, nh] = await getPageSize(page);
if (w >= nw) break;
w = nw;
h = nh;
}
return [w, h];
}
export async function parse(url: string) {
// ...
const [width, height] = await fixPageSize(page, options);
}
※ ページの高さに関しては無限スクロールみたいなものがあるとキリがないので追いかけません。
DOMの探索
DOMの探索は実際にブラウザ(page.evaluate)内でJavaScriptを動かして行います。以降のコードは ブラウザで動かすコード部分 に挿入します。
async function createTree(url: string) {
/* 中略 */
return await page.evaluate(() => {
/* ブラウザで動かすコード */
}) as Tree;
}
まずはDOM探索用のクラスDomTreeWrapperを作ります。視覚的な情報としてDomTreeWrapperは対象のElementが見えているか(visible)、箱の情報(rect)と、子供のDomTreeWrapperのリスト(children)を持たせます。最終的にはTreeとしてエクスポートします。
class DomTreeWrapper {
visible: boolean;
rect: Rect;
children: DomTreeWrapper[];
constructor(
private el: HTMLElement, // 実際のElement
private parentRect: Rect, // 後述
)
}
Elementが見えているかどうかの判定
メインコンテンツを抽出するときに見えていないElementは邪魔でしかないので以下のようなルールで取り除きます。
- metaタグなどのそもそも非表示のElement
- display: noneなどで非表示になっている
- Elementが透明
- z-indexがマイナス
- 幅or高さが0でoverflow: hidden
- 実際のサイズを無理矢理とったが、幅or高さが0
- Elementがページの枠外にある
完全には取り除けないかもしれませんが、実用的にはこのくらいで十分でしょう。
class DomTreeWrapper {
constructor(
private el: HTMLElement,
private parentRect: Rect,
) {
const computed = window.getComputedStyle(el);
const r = el.getBoundingClientRect();
const sourceRect = {
x: r.left,
y: r.top,
width: r.width,
height: r.height,
};
this.visible = this.setupVisible(sourceRect, computed);
}
private setupVisible(sourceRect: Rect, computed: CSSStyleDeclaration) {
if (/META|SCRIPT|LINK|STYLE|IFRAME/.test(this.el.nodeName)) return false;
// Elementが非表示
if (computed.display === "none" ||
computed.visibility === "hidden" ||
computed.visibility === "collapse" ||
(this.el.nodeName === "INPUT" && (this.el as HTMLInputElement).type === "hidden")) {
return false;
}
// Elementが透明
if (computed.opacity === "0") return false;
// z-indexがマイナス
if (computed.zIndex && +computed.zIndex < 0) return false;
// 幅or高さが0でoverflow: hidden
let { x, y, width, height } = sourceRect;
if (width === 0 && (computed.overflow === "hidden" || computed.overflowY === "hidden")) return false;
if (height === 0 && (computed.overflow === "hidden" || computed.overflowX === "hidden")) return false;
// 幅高さを無理やり取る
const origPosition = this.el.style.position;
this.el.style.position = "absolute";
const r = this.el.getBoundingClientRect();
this.el.style.position = origPosition;
width = r.width;
height = r.height;
// それでも幅or高さが0
if (width === 0 || height === 0) return false;
// Elementがページの枠外にある
const documentWidth = document.documentElement.scrollWidth;
const documentHeight = document.documentElement.scrollHeight;
if (x + width <= 0) return false;
if (x >= documentWidth) return false;
if (y + height <= 0) return false;
if (y >= documentHeight) return false;
return true;
}
}
Elementの正しい幅と高さを取得する
次に、Elementの見た目上の正しい幅と高さを取得します。基本はgetBoundingClientRect()で値がとれますが、以下のケースの場合は修正します。
- なぜか幅or高さが0になるパターンになるときに無理矢理とってくる
- ページ全体、overflow: hidden or auto or scrollが設定されているrectでcropする
class DomTreeWrapper {
// ...
// 親の箱でcrop(ページ全体 or overflow: autoとか)
private crop(rect: Rect) {
let { x, y, width, height } = rect;
const r = this.parentRect;
const left = Math.max(x, r.x);
const top = Math.max(y, r.y);
const right = Math.min(x + width, r.x + r.width);
const bottom = Math.min(y + height, r.y + r.height);
x = left;
y = top;
width = right - left;
height = bottom - top;
return { x, y, width, height };
}
// 見えている子Elementの取得
private getVisibleChildren(rect: Rect) {
return [...this.el.children as any as HTMLElement[]] // なんかエラー出るので
.map(el => new DomTreeWrapper(el, rect))
.filter(dtw => dtw.visible);
}
private setupRect(sourceRect: Rect, computed: CSSStyleDeclaration) {
let { x, y, width, height } = sourceRect;
// 稀に幅or高さが0になってしまうやつの対応
if (width === 0 || height === 0) {
// なぜか位置がおかしなところに行く場合があるので子Elementから取得
const children = this.getVisibleChildren(this.parentRect);
if (children.length) {
const r = children[0].rect;
x = r.x;
y = r.y;
}
// 幅と高さ修正
const origPosition = this.el.style.position;
this.el.style.position = "absolute";
const r = this.el.getBoundingClientRect();
width = r.width;
height = r.height;
this.el.style.position = origPosition;
}
return this.crop({ x, y, width, height });
}
再帰的に子Elementを探索する
再帰的に子Elementを探索するコードを追加します。現在探索しているElementにoverflow: hidden or auto or scrollが付いていたらこのElementでcropするようにします。
class DomTreeWrapper {
visible: boolean;
rect: Rect;
children: DomTreeWrapper[];
constructor(
private el: HTMLElement,
private parentRect: Rect,
) {
/* 中略 */
const crop = ["overflow", "overflowX", "overflowY"].some((k: any) => /hidden|auto|scroll/.test(computed[k]));
this.children = this.getVisibleChildren(crop ? this.rect : this.parentRect);
}
}
Treeにエクスポートする
最後にTreeにエクスポートして完成です。
class DomTreeWrapper {
private getAttrs() {
const attrs: { [key: string]: string } = {};
for (let i = 0; i < this.el.attributes.length; ++i) {
const { name, value } = this.el.attributes.item(i);
attrs[name] = value;
}
return attrs;
}
exportTree(): Tree {
return {
nodeName: this.el.nodeName,
...this.rect,
attrs: this.getAttrs(),
xpath: getXPathForElement(this.el), // https://stackoverflow.com/questions/2661818/javascript-get-xpath-of-a-node 参照
children: this.children.map(child => child.exportTree()),
};
}
}
const domTreeWrapper = new DomTreeWrapper(document.body, {
x: 0,
y: 0,
width: document.documentElement.scrollWidth,
height: document.documentElement.scrollHeight,
});
return domTreeWrapper.exportTree();
メインコンテンツを抽出する
改めてざっくり定義しますと、ブログ記事の記事本文、検索ページでいうところの検索結果のような視覚的にメインっぽいなーという部分をメインコンテンツとします。そういうものはWebページ上のどんな場所にあるか。例外はありますが、大体は以下のパターンに当てはまるかと思います。
- 1カラムでヘッダー、メインコンテンツ、フッター
- 2〜カラムでヘッダー、サイドバー、メインコンテンツ、フッター
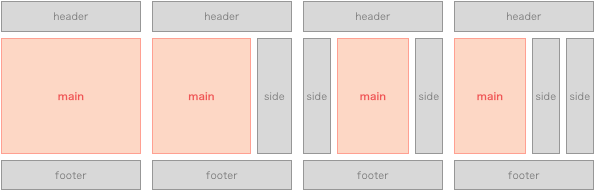
ここからなんとなくメインコンテンツってのはどういうものかを考えます。まずは中身を考慮せずにメインコンテンツを箱(ただの視覚的な情報)として考えます。
- x方向でみたら真ん中あたりにありそう
- y方向でみたら上の方にありそう
- 幅は50~80%くらいものが多そう
- 高さがあったほうがよさそう
さらにdomツリーの構造から
- header,aside,footer,navなどは除外できそう
- mainまたはその子孫の中にメインコンテンツがありそう
のようなことが予想できます。これをコードとして記述できればメインコンテンツ抽出ができそうです。
スコアを付ける
メインコンテンツっぽさを表現するためにスコアをつけます。上で考えたもので使えそうなものそれぞれにスコアをつけて掛け算したものを最終的なスコアにして、高いものほどメインコンテンツっぽいということにします。
export interface Score {
totalScore: number; // 以下を掛け算したもの
xScore: number; // x方向でみたら真ん中あたりにありそう
yScore: number; // y方向でみたら上の方にありそう
widthScore: number; // 幅は50~80%くらいものが多そう
heightScore: number; // 高さがあったほうがよさそう
domScore: number; // 要素の情報を使用
}
各Treeにスコアを付けて、配列に突っ込んで、高いほうからlimit件返す
MainContentDetectorを定義します。
import { Tree, Rect } from "./simple-scraper";
// ...
export interface ScoredTree extends Tree {
score: Score;
}
export interface MainContentSummary {
nodeName: string;
xpath: string;
attrs: { [key: string]: string};
score: Score;
rect: Rect;
}
class MainContentDetector {
constructor(
private root: Tree,
private documentWidth: number,
private documentHeight: number,
) { }
detect(limit = 5): MainContentSummary[] {
const trees: ScoredTree[] = [];
const applyScore = (t: ScoredTree, domScore: number) => {
const xScore = this.calcXScore(t);
const yScore = this.calcYScore(t);
const widthScore = this.calcWidthScore(t);
const heightScore = this.calcHeightScore(t);
t.score = {
totalScore: xScore * yScore * widthScore * heightScore * domScore,
xScore,
yScore,
widthScore,
heightScore,
depthScore,
};
trees.push(t);
t.children.forEach(child => applyScore(child, domScore));
}
this.root.children.forEach(c => applyScore(c as ScoredTree, 1));
return trees.map(t => ({
nodeName: t.nodeName,
xpath: t.xpath,
attrs: t.attrs,
score: t.score,
rect: {
x: t.x,
y: t.y,
width: t.width,
height: t.height,
},
})).sort((a, b) => b.score.totalScore - a.score.totalScore).slice(0, limit);
}
}
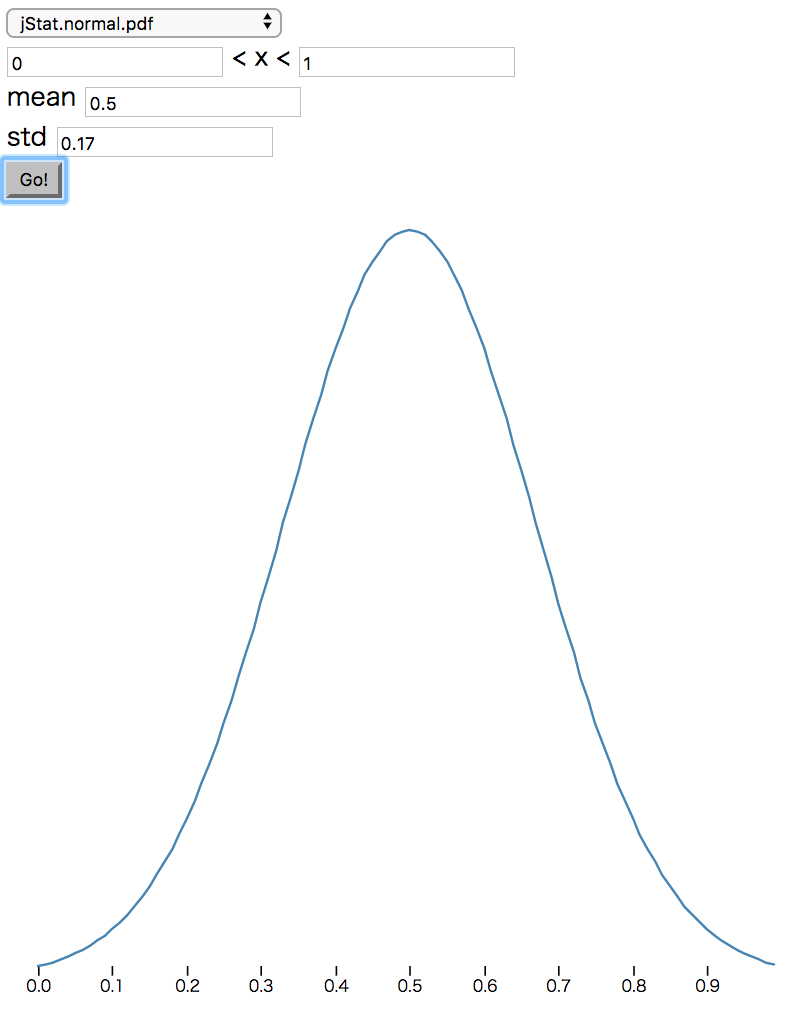
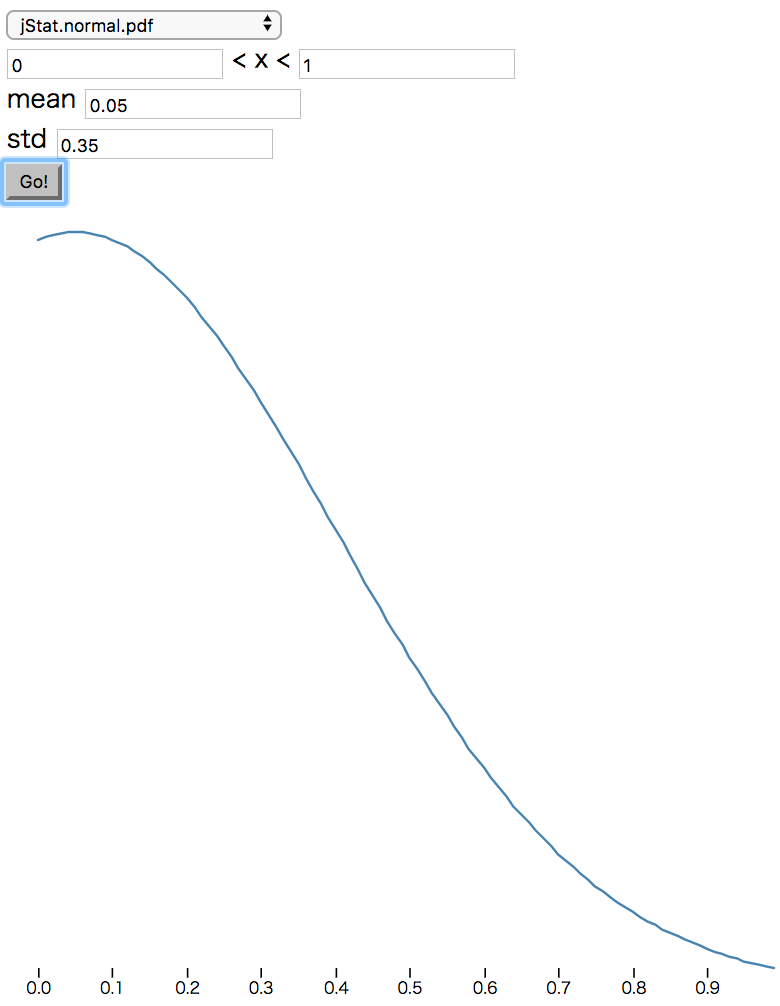
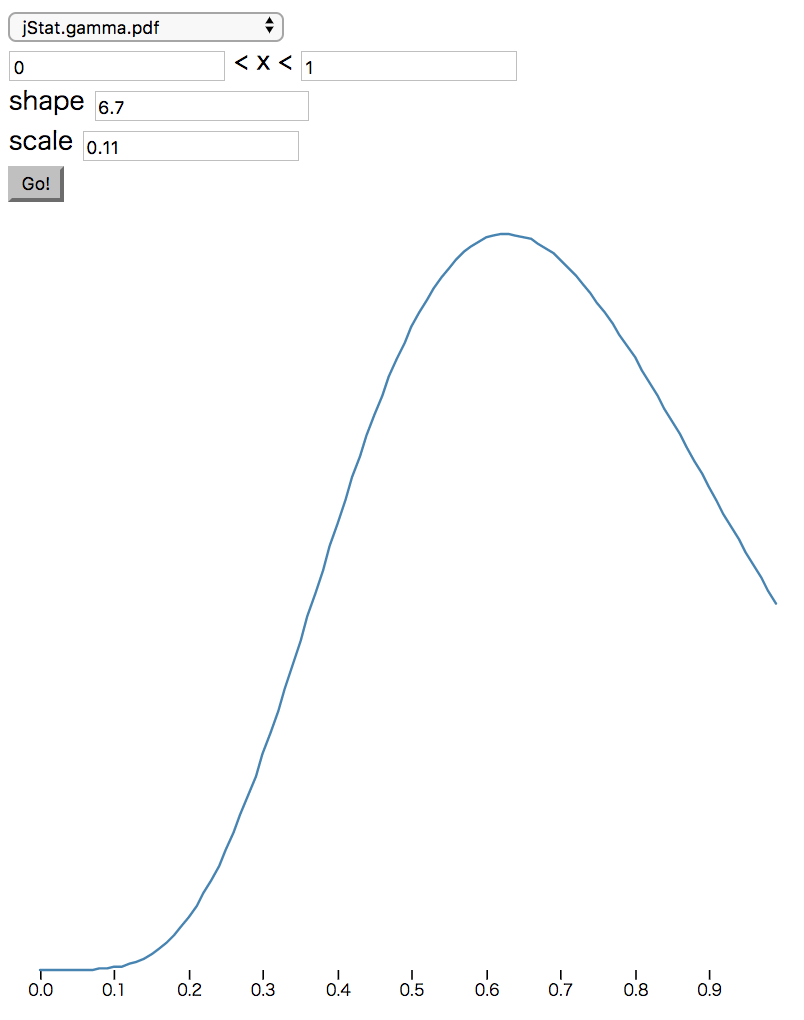
次に、calcXScoreなどの項目ごとにスコアを計算するメソッドを実装します。各項目についてフィットしてそうな確率密度関数を適用して適当に重み付けをして返します。
import { jStat } from "jStat";
const _xFn = jStat.normal(0.5, 0.35);
const _yFn = jStat.normal(0.05, 0.35);
const _widthFn = jStat.gamma(6.7, 0.11);
const distributions = {
x: (x: number) => _xFn.pdf(x),
y: (y: number) => y === 0 ? .5 : _yFn.pdf(y), // 上に張り付いているのはちょい下げたい
width: (w: number) => _widthFn.pdf(w),
height: (h: number) => Math.min(h, 0.9), // ここだけ雑だがなんだかんだでこれがマシだった
}
// 適当に重みをつける
const weights = {
x: 1,
y: 1,
width: 2.5,
height: 1,
};
// ...
class MainContentDetector
// ...
private calcXScore(t: Tree) {
return Math.pow(distributions.x((t.x + t.width / 2) / this.documentWidth), weights.x);
}
private calcYScore(t: Tree) {
return Math.pow(distributions.y(t.y / this.documentHeight), weights.y);
}
private calcWidthScore(t: Tree) {
return Math.pow(distributions.width(t.width / this.documentWidth), weights.width);
}
private calcHeightScore(t: Tree) {
return Math.pow(distributions.height(t.height / this.documentHeight), weights.height);
}
}
※ jStatはjsで統計的な計算を行うためのライブラリです。Distributions - jStat Documentationあたりを参照してください。あと、パラメータを調整するためにjstat distributions demo - Plunkerを作りました(各項目のグラフは以下図を参照)。
| x | y | width | height |
|---|---|---|---|
 |
 |
 |
省略 |
Elementの情報を使用する
基本的には上で付けたスコアで判定しますが、精度をあげるためにElementの情報を使ってさらに絞り込みます。
要素名、idが明らかにメインっぽい
要素名、idが明らかにメインっぽいもの(classはちょっと安全目に見て使わないでおく)の配下にあるElementのスコアが高くなるようにします。
// メインっぽいか
function isMain(t: Tree) {
return (
t.nodeName === "MAIN" ||
(t.attrs.id && /main/i.test(t.attrs.id))
);
}
// ...
class MainContentDetector
// ...
detect(limit = 5): MainContent[] {
const trees: ScoredTree[] = [];
const applyScore = (t: ScoredTree, domScore: number) => {
if(isMain(t)) domScore *= 2; // 雑に増やす
// ...
正直、ほぼこれを作り込んだらできるんじゃないかっていう噂もありますね。
不必要なElementを除外する
nodeNameとサイズなどをみて明らかにこれはないな、というのは除外します。
// mainになりそうなnodeNameか(最低限)
function isElementNameValid(t: Tree) {
return !/^(NAV|ASIDE|HEADER|FOOTER|H[1-6]|P|BLOCKQUOTE|PRE|A|THEAD|TFOOT|TH|DD|DT|MENU)$/.test(t.nodeName);
}
// ...
class MainContentDetector
// 小さすぎるものを除外
private isElementTooSmall(t: Tree) {
return t.width * t.height < this.documentWidth * this.documentHeight * 0.05;
}
private filterElement(t: Tree) {
return isElementNameValid(t) && !this.isElementTooSmall(t) && !hasNonMainContent(t);
}
detect(limit = 5): MainContent[] {
// ...
return trees.filter(child => this.filterElement(child)).map(/* ... */).slice(0, limit);
}
}
不必要なネストを避ける
デザインとかCMSの都合上ネストしているだけみたいなのを避けるようにします。
// デザインとかCMSの都合上ネストしているだけみたいなのを判定
isSkippable(t: Tree): boolean {
if (t.children.length !== 1) return false;
const [c] = t.children;
return Math.abs(t.x - c.x) < SKIP_THRESHOLD &&
Math.abs(t.y - c.y) < SKIP_THRESHOLD &&
Math.abs(t.width - c.width) < SKIP_THRESHOLD &&
Math.abs(t.height - c.height) < SKIP_THRESHOLD;
}
// ...
class MainContentDetector
// ...
detect(limit = 5): MainContent[] {
const trees: ScoredTree[] = [];
const applyScore = (t: ScoredTree, domScore: number) => {
// ...
if (isSkippable(t)) {
// スキップできそうならすぐに直下に行く
applyScore(t.children[0], domScore);
return;
}
// ...
もうちょっと使えるものがあるかもしれませんが、綺麗に実装できる範囲だとこんなもんだと思います。
検証用に可視化してみる
実装はできましたが検証するのが面倒です(Webページ開いて、jsonみて、開発者ツールで探して・・・みたいな)。なので、puppeteerでスクリーンショットをとって半透明の四角でメインコンテンツっぽいところをオーバーレイします。
まずは、スクレイピングする関数でスクリーンショットをとれるようにします。
export async function parse(url: string, screenshotOpt?: puppeteer.ScreenshotOptions) {
// ...
const tree = await createTree(page);
if (screenshotOpt) await page.screenshot(screenshotOpt);
// ...
}
オーバーレイ表示用のhtmlを吐き出します。
import { createTree, parse } from "./simple-scraper";
import { detectMainContent } from "./simple-maincontents";
import * as fs from "fs";
const url = process.argv[2];
(async () => {
const { tree, documentWidth, documentHeight } = await parse(url, { fullPage: true, path: "screenshot.png" });
const mainContents = detectMainContent(tree, documentWidth, documentHeight);
const { rect, xpath } = mainContents[0];
fs.writeFileSync("out.html", `
<div style="position: relative;">
<img src="screenshot.png">
<div style="
position: absolute;
background-color: rgba(126, 185, 255, 0.3);
left: ${rect.x}px;
top: ${rect.y}px;
width: ${rect.width}px;
height: ${rect.height}px;
">${xpath}</div>
</div>
`, "utf8");
})();
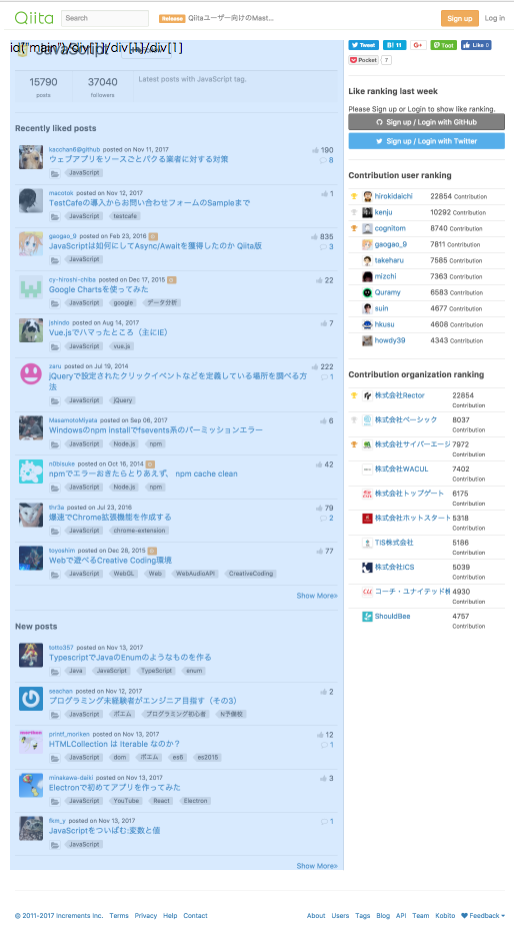
代表的なレイアウトで検証してみます。
| 1カラム(弊社HP) | 2カラム(Qiita タグ一覧) | 3カラム中央メイン(niconicoトップ) |
|---|---|---|
 |
 |
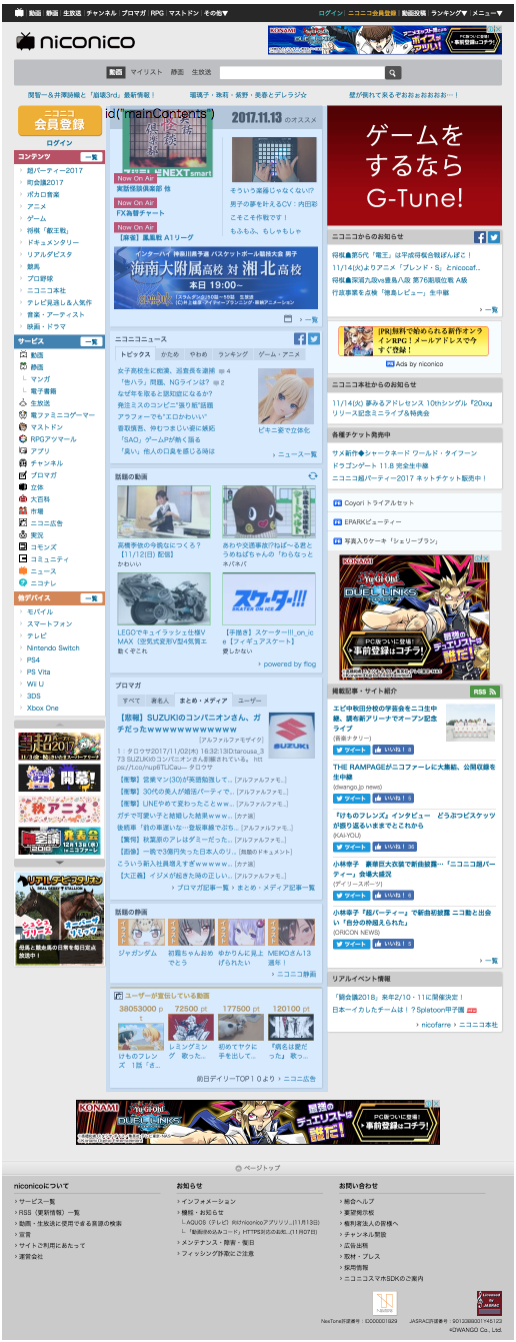 |
できてそうな感じがします。ただ、Amazonを例に上げますが、実装上Elementが分割されているものはダメですね。

もう少し大量のサイトで検証する必要ありますが、時間がないのでここまで。
まとめ
本文に依存しないメインコンテンツ抽出の実装を行いました。要するに、サイト作成者の気持ちになってコンテンツをどこに置くか予想するだけなので考え方は応用できるのではないかと思います。あと、特徴量はどんなものを使えば良さそうか肌感をつかんだので機械学習的なことをするとより良いものができそうです。