
digdagのretryは大変便利です。
例えば、それなりの確率で500statusをレスポンスしてくるAPI 1 にrequestを送る処理を含むscriptを実行するtaskを作るようなケースでも、実際に動作させるcodeにリトライを仕込まなくても自動でtask単位でretryさせることができます(もちろんoperatorの処理結果がErorrにならないとダメですが)。
ですが、最近いろいろと検証していたところ、_retry を定義する階層の違いによって、retry時の挙動に違いがあることに気づいたので、検証した結果をまとめてみます。
動作検証した環境
$ digdag --version
0.9.21
$ java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
パターン別retryの挙動まとめ
なお、全てdigdag serverにpushしたworkflowをdigdag startで実行する方法で動作検証を行いました。
忙しい人用まとめ
-
_retryを定義している階層と同じ階層に複数のtaskがあると、Errorになったtaskの後続taskもretry時に実行されるという挙動をするので注意が必要 - workflow(.digファイル)の一番上の階層で定義した
_retryはそのworkflowを直接実行した時しか適用されない。call operatorで他のworkflowから実行される場合は無視されるので注意が必要。 - retryする対象を確実に限定するためには、operatorのみが定義されているtaskの中に
_retryを定義して使うのが無難
1. workflowが1つのdigファイルのみで構成されている場合
1.1 実行するworkflowのtopに _retry を定義した場合
_retry: 3
+success1:
echo>: 'success1'
+success2:
echo>: 'success2'
+fail:
sh>: exit 1;
+success3:
echo>: 'success3'
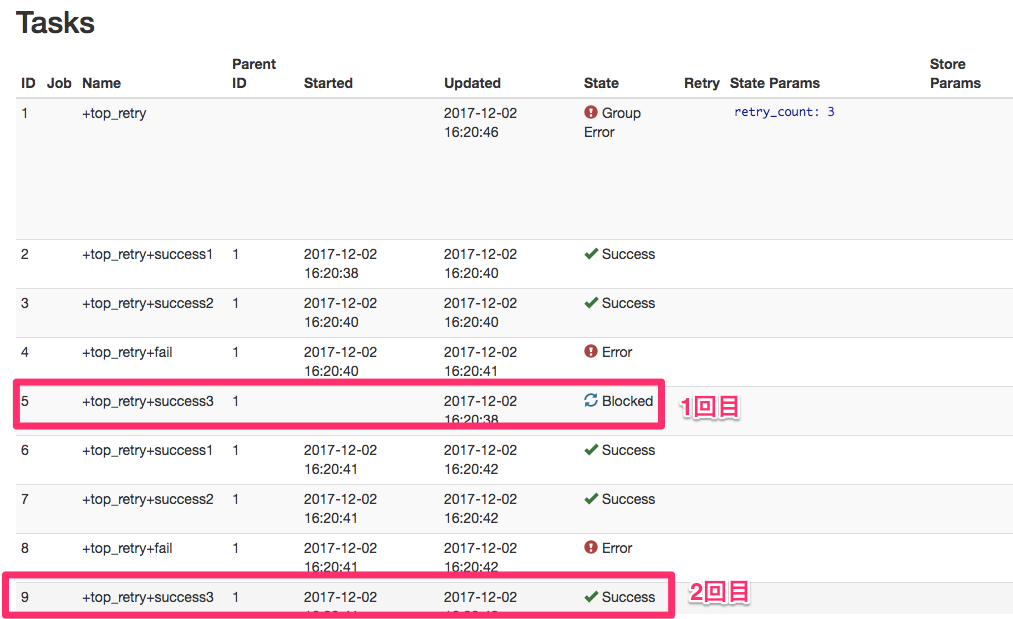
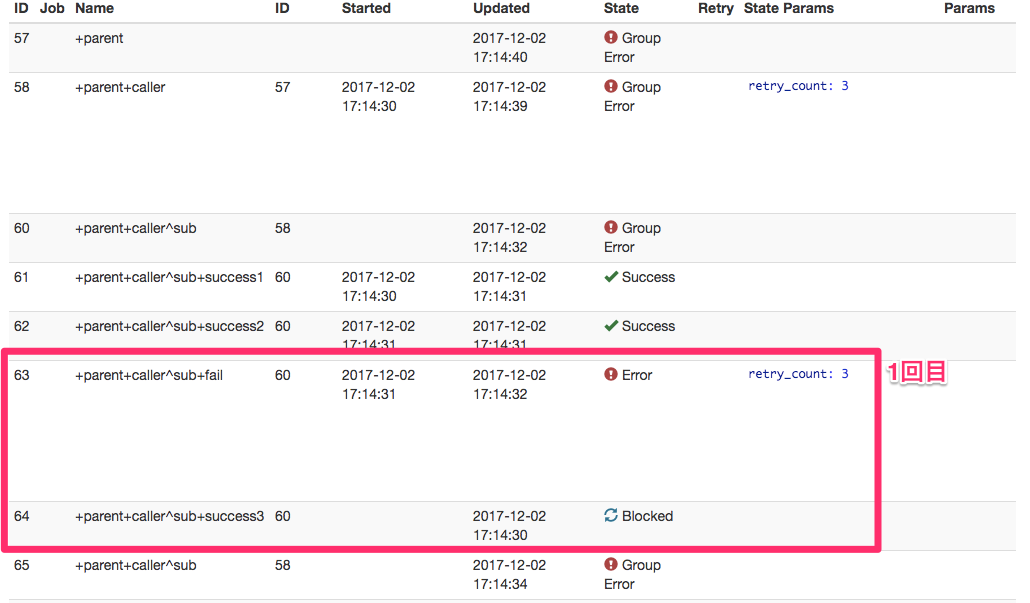
当初の想定では、+success3は実行されずに、 +success1 -> +success2 -> +fail というフローを4回(1回実行した後に3回最初からretryで計4回)繰り返してSessionがFailureで終わると予想していました。
しかし、一周目は想定通りでしたが、一度retryしてからの2週目以降では、+success3のtaskが実行されています。もし+success3 が、その前のタスクに依存していると正しく動作しなくなる問題が発生します。
1.2 taskの中に_retryを定義した場合
+success1:
echo>: 'success1'
+success2:
echo>: 'success2'
+fail:
_retry: 3
sh>: exit 1;
+success3:
echo>: 'success3'
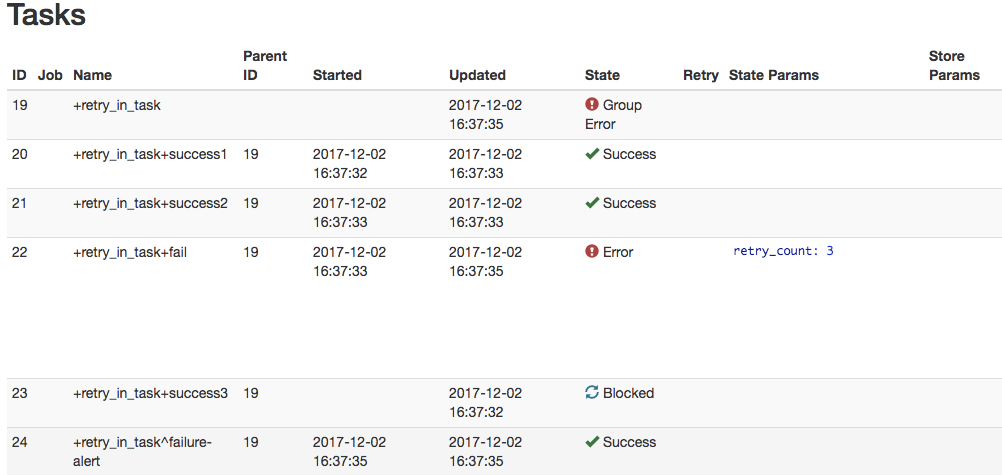
+failでのみretryが発生し、後続の +success3 は実行されずに終了しました。
1.3 taskの中に_retryを定義した上で、かつそのtask内のnestしたtaskがErorrになる場合
今度はnestしたtaskがErrorになった場合を試してみます。
+success1:
echo>: 'success1'
+success2:
echo>: 'success2'
+fail:
_retry: 3
+nested_success1:
echo>: 'nested_success1'
+nested_success2:
echo>: 'nested_success2'
+nested_fail:
sh>: exit 1;
+nested_success3:
echo>: 'nested_success3'
+success3:
echo>: 'success3'
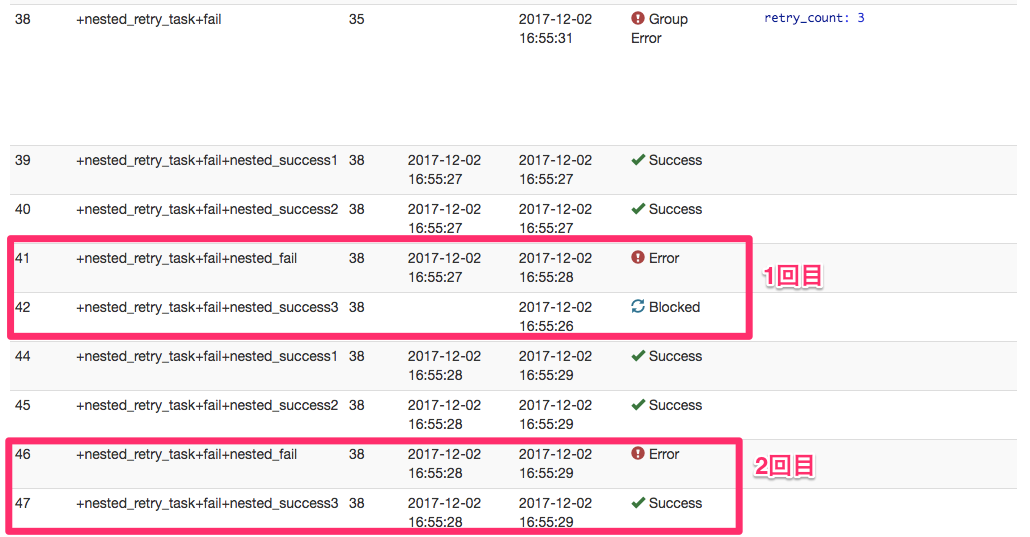
1.1と1.2の組み合わせのような挙動をしました。
同じ階層にある +nested_success1 , +nested_success2 , +nested_fail, +nested_success3は、初回は +nested_success3 がblockされますが、その後は実行されています。これは1.1と同じ挙動です。
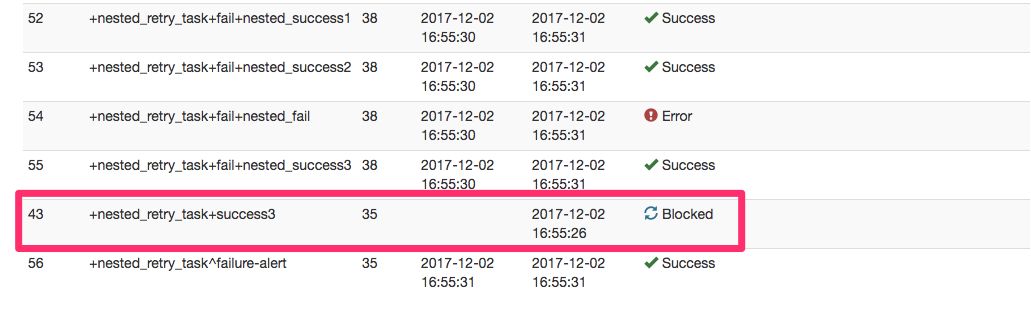
また、 +success3 はblockedで実行されませんでした。これは1.2と同じ挙動です。
2. workflowが複数のdigファイルで構成されていてcall operatorで別のworkflowを実行している場合
2.1 呼び出し側のtaskに _retry を定義した場合
+caller:
_retry: 3
call>: child.dig
+nyanko:
echo>: 'nya-n'
+success1:
echo>: 'success1'
+success2:
echo>: 'success2'
+fail:
_retry: 3
sh>: exit 1;
+success3:
echo>: 'success3'
child.digの+failがErrorとなっていますが、その後続taskである +success3 は毎回Blockedとなり実行されていません。
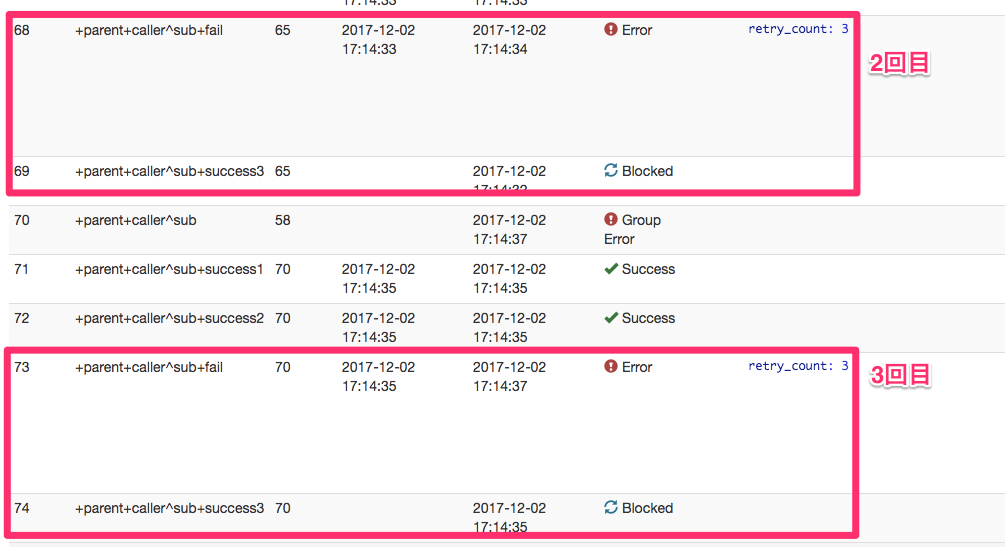
また、parent.dig側の一番最後のtaskである +nyanko もBlockedとなり実行されていません。
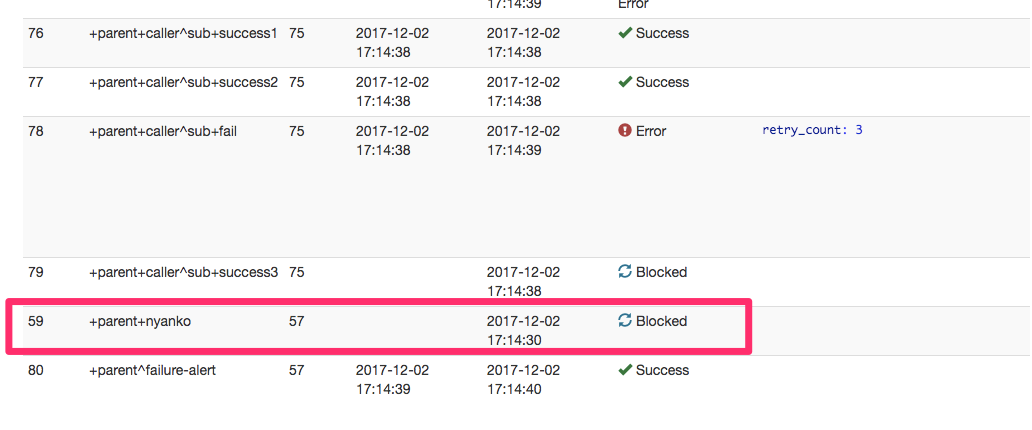
2.2 呼び出される側のworkflowのtopに _retry を定義した場合
1.1と同じようなことが起きるかどうかも試してみます。
+caller:
call>: child2.dig
+nyanko:
echo>: 'nya-n'
_retry: 3
+success1:
echo>: 'success1'
+success2:
echo>: 'success2'
+fail:
sh>: exit 1;
+success3:
echo>: 'success3'
digdag-uiの画面上には Retry State Params に retry_count: 3 と表示されていますが、実際は一度もretryされずにworkflowが終了しました。どうやら、一番上の階層で定義された _retry は、そのworkflowを直接実行した時しか適用されないようです。
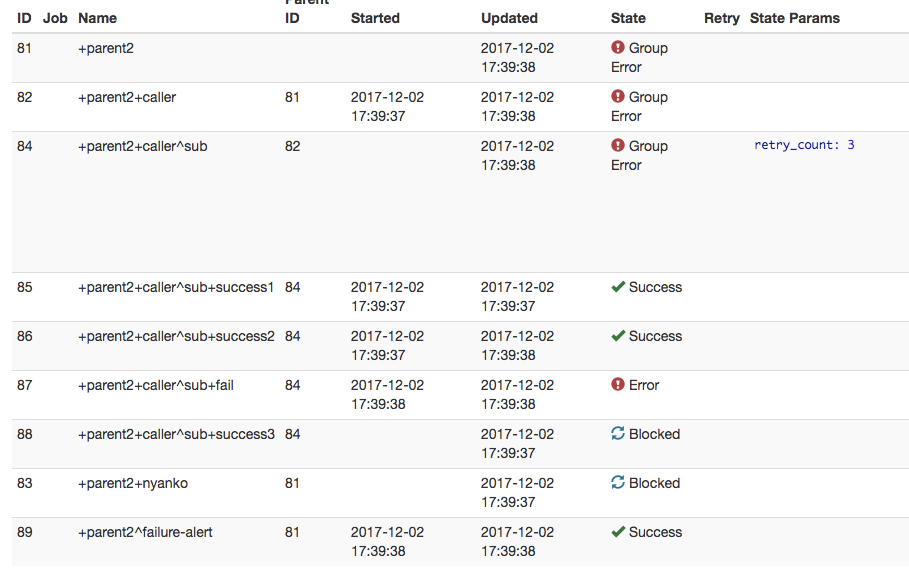
考察
-
_retryは複数のtaskを定義している階層と同じ階層に定義すると、retryによる実行時には、Errorになったtask以降のtaskも実行してしまう挙動をするようです。- これが仕様なのかバグなのかはまだ調査しきれていませんが、あとでissueを調べてみて、なければ出してみようと思います。
- digdag 0.9.21においては、以下の配慮が必要なように考えられます。(というか実際筆者はそうしています)
- retryする対象を分かりやすく指定するために、retryしたいtask単位で
_retryを定義する - 複数のtaskをまとめてretryしたい場合は、
_parallel: trueを併用している依存関係のないtaskのみの場合に限定する
- retryする対象を分かりやすく指定するために、retryしたいtask単位で
-
肌感ですが、BigQueryやGCSのAPIはそれなりにInternal Server Errorをレスポンスしてくる印象があるので、api clientでrequest投げる部分はretry処理込みで実装しないと危険という印象があります… ↩
